
- 1关于js重名方法的先后调用问题_js方法有多个重名方法优先调用哪个
- 2【踩坑记录】:在Linux中启动文件,关闭连接窗口,文件继续保持运行的方法_linux 关闭窗口 保持服务
- 3讲解pytorch 优化GPU显存占用,避免out of memory_讲解pytorch 优化gpu显存占用,避免out of memory
- 4什么是axios拦截器?有哪些作用和使用场景_axios拦截器作用
- 5产品经理的金字塔之旅---面试题目总结_it咨询面试题 金字塔
- 6git commit --amend命令的详细讲解+实际应用场景_git commit --amend详细用法
- 7Android基础知识-SharePreference存储相关_android sharepreference是否线程安全
- 8SRS为何加入木兰社区孵化?
- 9GPU架构与计算入门指南_非等待状态warp
- 10JS-常见this指向问题_this 选择上一级
Python爬取bilibili视频(期末设计)_python爬取哔哩哔哩视频
赞
踩
摘要
为了解决PC端的bilibili无法下载视频的问题,使用python语言可以实现一个能够爬取bilibili某个视频资源(不包括会员视频)的程序。采用整个视频下载与分片拼接视频两种思路实现程序,比较两种方式的下载效率,最终采用分片下载视频再拼接成为一个视频的方式实现了bilibili视频(不包括会员视频)的下载。实现bilibili视频下载,可以用于离线观看或者收集视频素材用于剪辑,具有一定实际的用途。
引言
由于bilibili只能通过手机app下载视频缓存,电脑打开需要将缓存从手机将文件传到电脑,不方便。
本文从如何借助chorme浏览器的开发者工具与搜索引擎了解bilibili请求视频资源的方式、如何使用python的各种库模拟浏览器发送请求去获取bilibili服务器的视频资源、运行实现的python爬虫程序并下载一个视频三个步骤介绍bilibili视频爬虫的实现。
系统结构
使用到的工具
IntelliJ IDEA 2018.2.4 x64(集成开发环境)
Python3.8(编程语言)
requests库(发送http请求)
lxml库(xpath解析)
json库(解析json数据)
ffmpeg(合并音频和视频)
实现功能的原理
通过输入视频编号再拼接成为url,通过用python的request库使用url模拟浏览器请求访问视频页面。使用lxml库与json库从返回的响应信息中提取到视频资源的链接,再去模拟浏览器请求获取音频和视频资源,再将获得的音频和视频资源合并保存到本地。
实现代码
1.了解url结构
使用chorme浏览器,先到bilibili点开一个视频如图3.1所示。
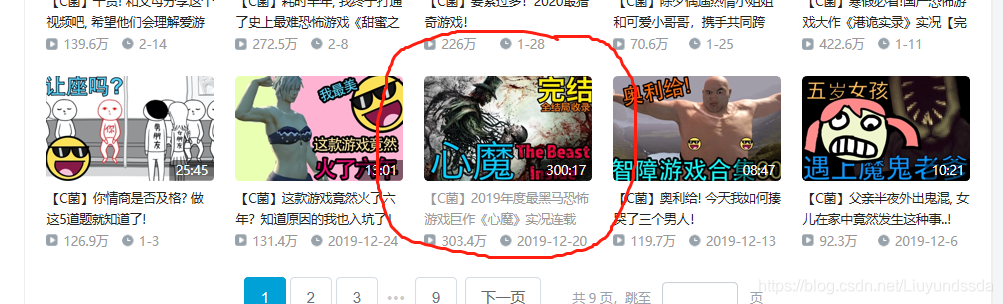
图3.1
进入视频页面后,点进第二p,开始分析该页面的请求的结构如图3.2所示。
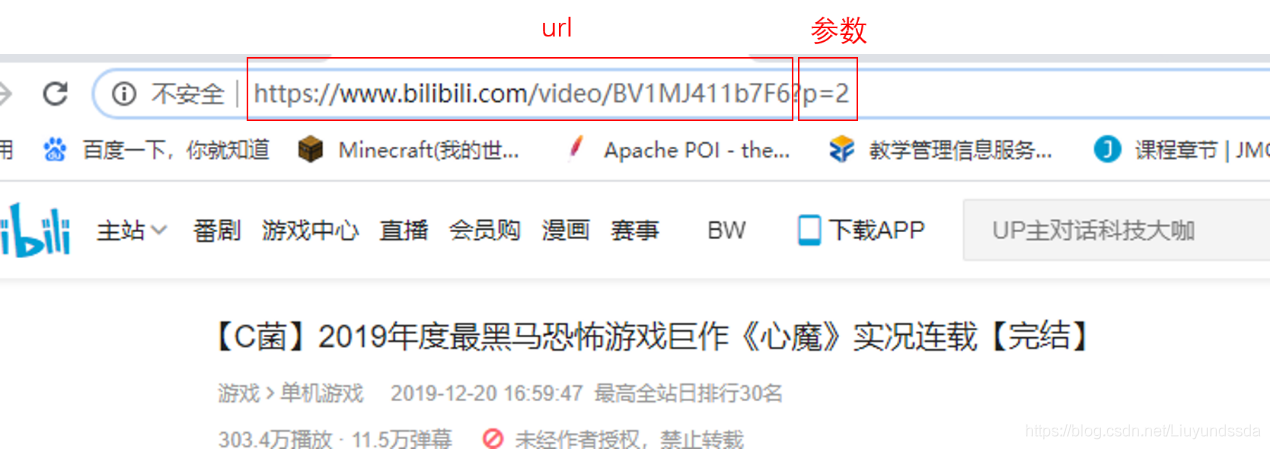
图3.2
可以看到请求由url和一个参数p拼接而成。
2.编写输入程序
访问页面需要的url结构为https://www.bilibili.com/video/BV号?p=,我们下载视频的话可以输入视频p数的范围来下载多个分p视频,总结以上需要输入程序的信息就包括视频BV号、起始p、结束p这三个信息,编写代码如下。
if __name__ == '__main__': # 输入bilibili视频的BV号 bv = input('视频BV号:') url='https://www.bilibili.com/video/'+bv # 选择视频从第几p开始到第几p结束 startPart=input('起始P:') endPart = input('终止P;') print("url:",url) print("startPart:",startPart) print("endPart:",endPart)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输出结果如图3.3所示。
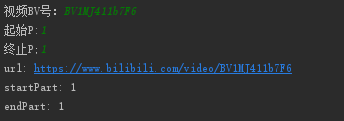
图3.3
3.解析网页,找到下载视频的链接
在chorme浏览器按下F12打开开发者工具,查找页面元素,找到在head标签的第6个script标签里面存有视频播放信息,划红线的baseUrl就是视频资源链接如图3.4所示。

图3.4
根据网上搜索了解到bilibili2018年后的视频分为音频与视频,但是在此标签里面没有找到与音频有关的键,这里我直接拷贝标签文本,放到文本编辑器notepad++中,查找“audio”发现了音频键值对,如图3.5所示。
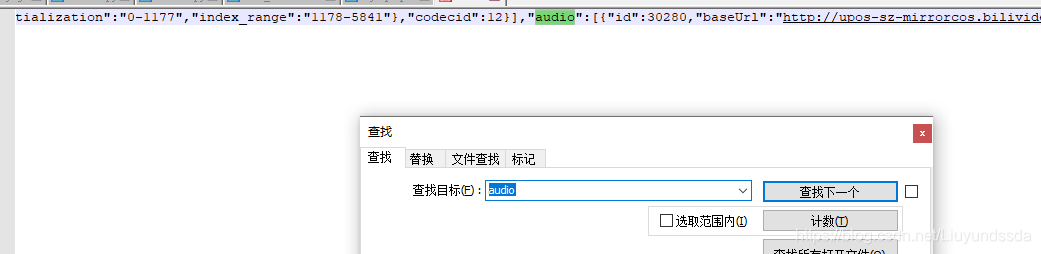
图3.5
其中“baseUrl”后面的内容就是音频资源链接,如图3.6所示。

图3.6
这里我需要先通过发送请求获取网页二进制文本信息,然后再通过解析文本获取需要的链接。
增加函数getBiliBiliVideo,使用到的库有json、os、requests、etree,代码如下。
import json import requests from lxml import etree # 防止因https证书问题报错 requests.packages.urllib3.disable_warnings() headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36', 'Refer' 'er': 'https://www.bi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 项目运行环境配置:Jdk1.8+Tomcat7.0+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:SSM+mybatis+Ma... [详细]
赞
踩
- python的基本介绍以及安装教程_pythonpython前言:今天,我将给大家讲解关于python的基本知识,让大家对其有个基本的认识并且附上相应的安装教程以供大家参考。接下来,我们正式进入今天的文章!!! 目录前言(一)Py... [详细]
赞
踩
- 龟叔在1989年圣诞节期间,以由荷兰的数学和计算机研究所开发的ABC语言为蓝本,开始开发一门新的编程语言,目标让新语言即能像C语言一样能够全面调用计算机的功能接口,又可以像shell一样可以轻松的编程,并且以龟叔所挚爱的电视剧。Python... [详细]
赞
踩
- Python教程|Python简介_python-〉python-〉前言在本文中,我将向你介绍Python及其特点和应用。通过阅读本文,你将能够掌握:什么是PythonPython有哪些特点Python有哪些应用场景什么是PythonPyt... [详细]
赞
踩
- 必选参数、默认参数、可变参数、命名关键字参数和关键字参数。Python——函数的参数1.位置参数位置参数可以在函数中设置一个或者多个参数,但是必须有对应个数的值传入该函数才能成功调用,例如:defpower(x):returnx*xprin... [详细]
赞
踩
- 五、龙之境原文:inventwithpython.com/invent4thed/chapter5.html译者:飞龙协议:CCBY-NC-SA4.0本章中您将创建的游戏名为龙之境。玩家需要在两个洞穴之间做出选择,这两个洞穴分别藏有宝藏和一... [详细]
赞
踩
- 表情包泛滥的今天,有时候困于动图太大,发到微信或者QQ上太占屏幕空间,因此想着使用缩小一下,于是用python写了个脚本,并基于pyqt5写了个简单的界面。缩小前:缩小后:不过工具没那么健壮,没检查一些异常,凑合用一下吧,哈哈~下载链接:g... [详细]
赞
踩
 本文探究安装cv2时Buildingwheelforopencv-python终端卡死的原因并予以解决_buildingwheelforopencv-python(pep517)buildingwheelforopencv-python(p... [详细]
本文探究安装cv2时Buildingwheelforopencv-python终端卡死的原因并予以解决_buildingwheelforopencv-python(pep517)buildingwheelforopencv-python(p... [详细]赞
踩
- webbrowser是Python的内置库,提供了访问Web浏览器的接口_pythonwebbrowserpythonwebbrowser「作者主页」:士别三日wyx「作者简介」:CSDNtop100、阿里云博客专家、华为云享专家、网络安全... [详细]
赞
踩
 数据分析是当今信息时代中至关重要的技能之一。Python和PySpark作为强大的工具,提供了丰富的库和功能,使得数据分析变得更加高效和灵活。_python和pyspark数据分析乔纳森·里乌pdfpython和pyspark数据分析乔纳森... [详细]
数据分析是当今信息时代中至关重要的技能之一。Python和PySpark作为强大的工具,提供了丰富的库和功能,使得数据分析变得更加高效和灵活。_python和pyspark数据分析乔纳森·里乌pdfpython和pyspark数据分析乔纳森... [详细]赞
踩
- chatGPT:趋势跟踪策略的量化交易程序可能会因语言和框架而异,下面是一个简单的Python代码示例,用于演示如何通过量化编程来实现趋势跟踪策略。_python趋势跟踪策略python趋势跟踪策略chatGPT:趋势跟踪策略的量化交易程序... [详细]
赞
踩
- 【代码】pythonsqlite3线程池封装。pythonsqlite3线程池封装1.封装sqlite31.1.依赖包引入#-*-coding:utf-8-*-#importosimportsysimportdatetimeimportlo... [详细]
赞
踩
- 科技进步的飞速发展引起人们日常生活的巨大变化,电子信息技术的飞速发展使得电子信息技术的各个领域的应用水平得到普及和应用。信息时代的到来已成为不可阻挡的时尚潮流,人类发展的历史正进入一个新时代。在现实运用中,应用软件的工作规则和开发步骤,采用... [详细]
赞
踩
- **1.**一般我们爬取领英都是想爬领英上关于那个公司的所有员工,所以我们有两种方法(我已知的),一个是百度(领英+公司名称),从中抽取个人领英页面,从而进入个人领英页面进行信息的抓取,一般百度只会提供前75页信息,so,你可能抓不全,但这... [详细]
赞
踩
- 背景:scrapy启动了多个爬虫,每个爬虫都有读写文件的pipeline。发生了这一问题.原因:超出了进程同一时间最多可开启的文件数.解决办法:ulimit-n2048,将数目提高,mac默认是256,linux是1024,自行体会....... [详细]
赞
踩
- 实战是最好的老师,直接案例操作,快速上手。【Python】01快速上手爬虫案例一文章目录前言一、VSCode+Python环境搭建二、爬虫案例一1、爬取第一页数据2、爬取所有页数据3、格式化html数据4、导出excel文件前言实战是最好的... [详细]
赞
踩
- 上一篇文章讲了分支判断、循环、enumerate函数和zip函数,流程控制也差不多结束了,但是在我们学习C语言的时候,不知道大家还记不记得C语言有个switch语句,那么Python里面有没有switch语句呢?下面就给大家揭晓谜底,当然在... [详细]
赞
踩
- 哈喽大家好,我是咸鱼。然后问我为什么结果是[1,[...]],我一看这个问题有意思,我说三言两语解释不清楚,我写篇文章到时候你看下吧,于是有了今天这篇文章。在正式开始之前,让我们先弄清楚一些概念。Python变量?对象?引用?赋值?一个例子... [详细]
赞
踩
- 要学习和掌握NLP深度学习进阶知识,建议你对基本的深度学习和Python编程有一定的了解,并深入学习上述提到的库和模型。同时,实践和动手做项目也非常重要,可以通过练习数据集上的各种NLP任务来提高自己的实战能力。自然语言处理(Natural... [详细]
赞
踩
- Vue项目如果连接Pyhton后端通常会存在跨域的问题,最开始我是用nginx解决的,后来发现flask有一个flask_cors包,比较简便。后来又出现POST请求不能用的问题。_pythonflask后端接口如何避免跨域问题python... [详细]
赞
踩

