
- 1品达通用权限系统(Day 5~Day 6)_pinda.itheima.net
- 2Win7 77条tip个人精简6条版(可惜不是7。。)
- 3Flink实时数仓同步:流水表实战详解
- 4跟姥爷深度学习1 浅用tensorflow做个天气预测_tensorflow天气预测
- 5RuntimeError: invalid multinomial distribution (encountering probability entry < 0)_runtimeerror: invalid multinomial distribution (su
- 6python程序开机自启动_python打包exe开机自动启动的实例(windows)
- 7STM32单片机的 Hard-Fault 硬件错误问题追踪与分析_stm32hardfault定位
- 8Fonts字体简介_font中ttf都代表的是什么字体
- 9mysql is not null 优化_MySQL优化系列2.1-MySQL中 IS NULL、IS NOT NULL、!= 能用上索引吗?...
- 10Quartz详解和使用CommandLineRunner在项目启动时初始化定时任务_quartz的commandlinerunner
基于hadoop+spark的大规模日志的一种处理方案
赞
踩
概述:
CDN服务平台上有为客户提供访问日志下载的功能,主要是为了满足在给CDN客户提供服务的过程中,要对所有的记录访问日志,按照客户定制的格式化需求以小时为粒度(或者其他任意时间粒度)进行排序、压缩、打包,供客户进行下载,以便进行后续的核对和分析的诉求。而且CDN上的访问日志一般都非常大,需要用大数据处理架构来进行处理,本文描述了一种利用hadoop+spark来处理大量CDN日志的方法,当然本方案不局限于CDN日志处理,完全可以应用到其他日志处理的应用需求上面。
本方案是一种对大数据量的日志进行打包处理的优化方法。首先,可以充分利用HDFS+SPARK大数据系统的分布式处理能力,让整个系统尽可能地连续进行工作,来处理实时上传上来的大量应用服务日志,而不至于因为业务规定的打包粒度的要求而等到一个相对较大的时间粒度(譬如1小时或者1天)的开始之后才能对日志进行处理,从而大幅度提升的日志处理的及时性和处理的效率;其次,采用本方案的方法,因为采用了比业务需求规定的更细的粒度对日志文件进行处理,一旦发现某个时间点的日志处理有问题,可以精确定位到那个时间点(1分钟级)的文件,进行细粒度追溯和回滚处理,避免在大粒度上面进行处理,大幅度减少了需要追溯或回滚的数据的处理量,提升了系统的可维护性;最后,利用HDFS+SPARK大数据系统处理平台的弹性架构,能够为整个日志处理系统提供长期的弹性扩容能力,满足未来长期运行的需求。
实现说明:
以下对具体实现方式进行说明。
首先,先描述一下整个日志打包系统的部署架构,如下图:
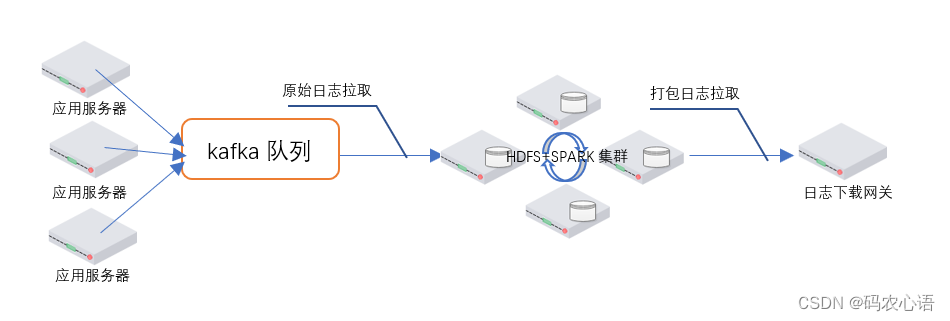
- 图的左侧,多个应用服务器在应用服务系统运行的过程中,在不断的产生各种日志,通过一些实时采集工具将应用服务器的日志发送到异步队列kafka 中(这个环节的内容不是本方案的重点)。
- 图的中间,HDFS+SPARK集群进行分布式运算,来进行日志文件的格式化、排序、压缩、打包操作,最终生成打包好的分片(譬如以1分钟为粒度)日志文件存储到HDFS的指定目录中。
- 图的右侧,日志下载网关为查看和下载日志的用户提供虚拟视图,按照业务所要求的更大的时间粒度(譬如1小时或者1天粒度)提供日志的查看和下载。
下面,对HDFS+SPARK集群进行日志的处理过程进行详细描述:
由于存在众多的应用服务器&#x
- article
解决java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.的错误_java.io.filenotfoundexception: java.io.filenotfoun
解决java.io.FileNotFoundException:java.io.FileNotFoundException:HADOOP_HOMEandhadoop.home.dirareunset.-seehttps://wiki.apa... [详细]赞
踩
- 文章目录一.大数据技术栈二.Spark概述2.1MapReduce框架局限性2.2Hadoop生态圈中的各种框架2.3Spark2.3.1Spark的优势2.3.2Spark特点2.3.3SPRAK2新特性一.大数据技术栈如下图,当前的一个... [详细]
赞
踩
- 要从HDFS中删除文件,可以使用以下命令:hadoopfs-rm-r-skipTrash/path_to_file/file_name要从HDFS中删除文件夹,可以使用以下命令:hadoopfs-rm-r-skipTrash/folder_... [详细]
赞
踩
- 配置环境变量后上传文件/文件夹到hdfs:#上传文件到hdfs[root@doit1y]#hdfsdfs-put文件名/#上传文件夹到hdfs[root@doit1y]#hdfsdfs-put文件夹名/删除hdfs上的文件/文件夹#从hdf... [详细]
赞
踩
- 配置了环境变量直接执行:要从HDFS中删除文件,可以使用以下命令:hadoopfs-rm-r-skipTrash/path_to_file/file_name要从HDFS中删除文件夹,可以使用以下命令:hadoopfs-rm-r-skipT... [详细]
赞
踩
- 文件夹在HDFS上的位置执行删除命令hadoopfs-rm-r/gulivideo_etl成功删除hdfs上的文件夹_hdfs删除文件hdfs删除文件文件夹在HDFS上的位置执行删除命令hadoopfs-rm-r/gulivideo_etl... [详细]
赞
踩
 HadoopHA高可用搭建保姆级教程,来自正在学习大数据导论的大二学长的万字笔记,干得不能再干的干货分享!_hadoopha搭建hadoopha搭建知识目录一、写在前面... [详细]
HadoopHA高可用搭建保姆级教程,来自正在学习大数据导论的大二学长的万字笔记,干得不能再干的干货分享!_hadoopha搭建hadoopha搭建知识目录一、写在前面... [详细]赞
踩
- 此外,Spark提供了丰富的编程接口(如Scala、Java、Python和R),可以方便地进行开发和调试。因此,Spark成为了大数据处理和分析的首选工具之一。ResilientDistributedDatasets(RDDs):RDD是... [详细]
赞
踩
 SpringBoot使用Spark_springbootsparkspringbootspark文章目录读取txt文件读取csv文件读取MySQL数据库表读取Json文件中文输出乱码前提:可以参考文章SpringBoot接入SparkSpr... [详细]
SpringBoot使用Spark_springbootsparkspringbootspark文章目录读取txt文件读取csv文件读取MySQL数据库表读取Json文件中文输出乱码前提:可以参考文章SpringBoot接入SparkSpr... [详细]赞
踩
- myconfigurationsarehduser@worker1:/usr/local/hadoop/conf$jpsTheprogram'jps'canbefoundinthefollowingpackages:*openjdk-6-j... [详细]
赞
踩
- 因为rowkey一般有业务逻辑,所以不可以直接使用rowkey进行分页,startkey,endkey想要使用SQL语句对Hbase进行查询,需要使用Apache的开源框架Phoenix。安装1,下载phonenixhttp://mirro... [详细]
赞
踩
- pyspark_1|19/10/2510:23:03INFOSparkContext:Createdbroadcast12frombroadcastatNativeMethodAccessorImpl.java:0pyspark_1|Tra... [详细]
赞
踩
- Hadoop扫盲&快速入门一、关于Hadoop核心架构二、Hadoop快速入门三、Hadoop&MapReduce区别四、Hadoop大数据处理的意义叮嘟!这里是小啊呜的学习课程资料整理。好记性不如烂笔头,今天也是努力进步的一天。一起加油进... [详细]
赞
踩
- 1.流计算概述1.1流计算简介数据仓库中存放的大量历史数据就是静态数据,可以利用数据挖掘和OLAP分析工具从静态数据中找到对企业有价值的信息。而流数据表现为数据以大量、快速、时变的流形式持续到达。如PM2.5检测、电子商务网站用户点击流。批... [详细]
赞
踩
- 分布式计算是一种计算方法,和集中式计算是相对的。随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算... [详细]
赞
踩
- 1)NameNode内存计算2)Hadoop2.x系列,配置NameNode内存NameNode内存默认2000m,如果内存服务器内存4G,NameNode内存可以配置3g。在hadoop-env.sh文件中配置如下3)Hadoop3.x系... [详细]
赞
踩
- Hadoop是一个开源的分布式计算和存储框架,由Apache基金会开发和维护。Hadoop为庞大的计算机集群提供可靠的、可伸缩的应用层计算和存储支持,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集,并且支持在单台计算机到几千台计算... [详细]
赞
踩
- 本章着重介绍Hadoop中的概念和组成部分,属于理论章节。如果你比较着急可以跳过。但作者不建议跳过,因为它与后面的章节息息相关。3.0Hadoop概念本章着重介绍Hadoop中的概念和组成部分,属于理论章节。如果你比较着急可以跳过。但作者不... [详细]
赞
踩

