
- 1Spring Boot(五十五):基于redis防止接口恶意刷新和暴力请求_spring redis 防止恶意刷新
- 2编程练习的网站_pintia.cn
- 3Wireshark数据包分析——Slammer蠕虫攻击_sql蠕虫王(slammer)是利用什么漏洞进行传播的?该漏洞补丁是什么时候发布的?说
- 4python程序开机自启动_一键开机启动添加(python)_开机启动python脚本
- 5Python程序设计——文件操作(需要继续研究研究)_如何在d盘创建python文档
- 6(附源码)计算机毕业设计ssm餐厅管理系统_毕业设计主要功能图
- 7项目管理/Bug管理/问题管理—Phabricator_phabricator differential unit 配置
- 8【无人机编队】基于动态窗口法实现的无人机编队目标分配及路径规划问题研究附matlab代码_dwa算法用于编队
- 9Midjourney以图生图的详细教程(含6种案例介绍)_midjourney图生图
- 10AI加持,openEuler打造数字基础设施全场景操作系统
Informer:对长时间序列预测更高效的Transformer
赞
踩

论文:AAAI2021 | Informer: Beyond efficient transformer for long sequence time-series forecasting [1]
作者:Zhou H, Zhang S, Peng J, et al.
机构:北航、UC伯克利、Rutgers大学等
录播:https://www.bilibili.com/video/BV1RB4y1m714?spm_id_from=333.999.0.0
代码:https://github.com/zhouhaoyi/Informer2020
引用量:162
Informer是AAAI2021的最佳论文,主要是针对长时序预测任务(Long sequence time-series forecasting,LSTF),改进了Transformer。
一、历史瓶颈
图1展示了电力转换站的小时级温度预测,其中短期预测是0.5天(12个点),而长期预测是20天,480个点,其中当预测长度大于48个点时,整体表现会有明显的差异,LSTM的MSE和推理速度都在往很坏的方向发展。
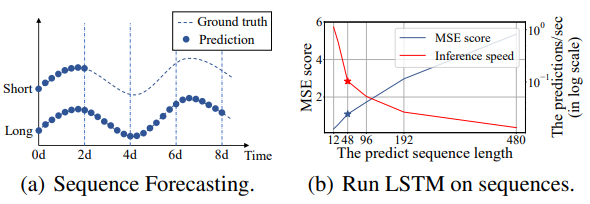
图1:LSTM在不同预测长度上性能和准确性的分析
为了满足LSTF的挑战,模型需要有:能够有效地捕捉长序列输入和输出的相互依赖性。最近,Transformer在捕捉长期依赖性上,明显比RNN有着卓越的表现。但存在以下瓶颈:
1. 自关注机制的二次计算复杂度高:自关注机制的算子,即点积,导致时间复杂度和每层内存消耗量为 ;
2. 长序列输入下堆叠层的内存瓶颈:堆叠J层encoder/decoder层让内存使用率为 ,限制模型去接受更长的输入;
3. 预测长输出时推理速度慢:原始Transformer是动态解码,步进式推理很慢。
二、论文贡献
本文贡献如下:
1. 提出informer,能成功提高在LSTF问题上的预测能力,验证了Transformer模型的潜在价值,能捕获长序列时间序列输出和输入之间的个体长期相关性;
2. 提出ProbSparse自相关机制,使时间复杂度和内存使用率达到 ;
3. 提出自相关蒸馏操作,在J个堆叠层上突出关注分高的特征,并极大减少空间复杂度到 є ,这帮助模型接收长序列输入;
4. 提出生成式decoder,直接一次性多步预测,避免了单步预测产生的误差累积。
三、网络结构
Informer的网络结构示意图如下:
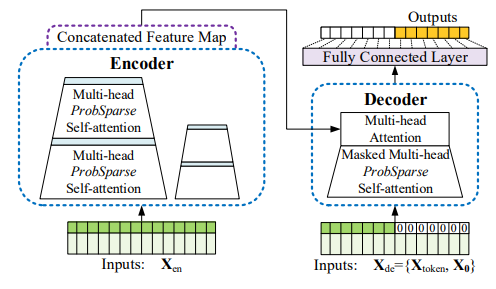
图2:网络结构示意图
在图2中:
● 左边:encoder接收大量长序列输入(绿色),Encoder里ProbSparse自关注替换了原自关注模块,蓝色梯形是自关注蒸馏操作,用于抽取主要关注,减少网络尺寸。堆叠层是用于增加鲁棒性。
● 右边:decoder接收长序列输入,用0填充预测部分的序列。它衡量特征map上加权关注成分,然后生成式预测橙色部分的输出序列。
1. ProbSparse Self-attention
ProbSparse Self-attention是Informer的核心创新点,我们都知道Transformer里,自关注是有query, key和value组成: 能帮助拥有更稳定的梯度,这也可以是其它可能值,但这个是默认的,Transformer作者是担心对于大的Key向量维度会导致点乘结果变得很大,将softmax函数推向得到极小梯度的方向,因此才将分数除以Key向量维度开方值。关于Transformer模型,可以阅读我的历史文章[2]。另外, 是非对称指数核函数 。
但Transformer中attention分数是很稀疏的,呈长尾分布,只有少数是对模型有帮助的。
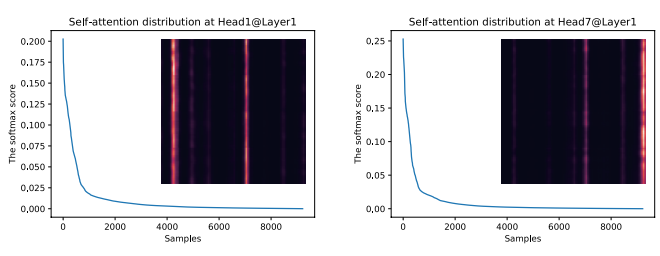
图3:在ETTh1数据集上,4层原Transformer的自关注的softmax分数分布
作者在文中提到:如果存在核心attention的点积pairs,那query的关注概率分布便会远离均匀分布。意思是说:如果 接近于平均分布 ,说明该输入V没什么值得关注的地方,因此衡量 的分布p和分布q(即均匀分布 )之间的差异,能帮助我们判断query的重要性,而KL散度便是衡量分布是否一致的一种方式(论文省略了一些推导过程,但好在身边有同事帮忙推导出来了,tql):
公式(6)中第一项是Log-Sum-Exp(LSE),第二项是算术平均数,散度越大,概率分布越多样化,越可能存在关注重点。但上述公式会有两个问题:
● 点积对的计算复杂度是 ;
● LSE计算存在数值不稳定的风险,因为形式下,可能会数据溢出报错。
为了解决这两个问题,作者分别采取以下手段:
● 随机采样 个点积对计算 ;
● 用 替换 (推导过程见论文附录);
2. Encoder
Informer Encoder结构如下:
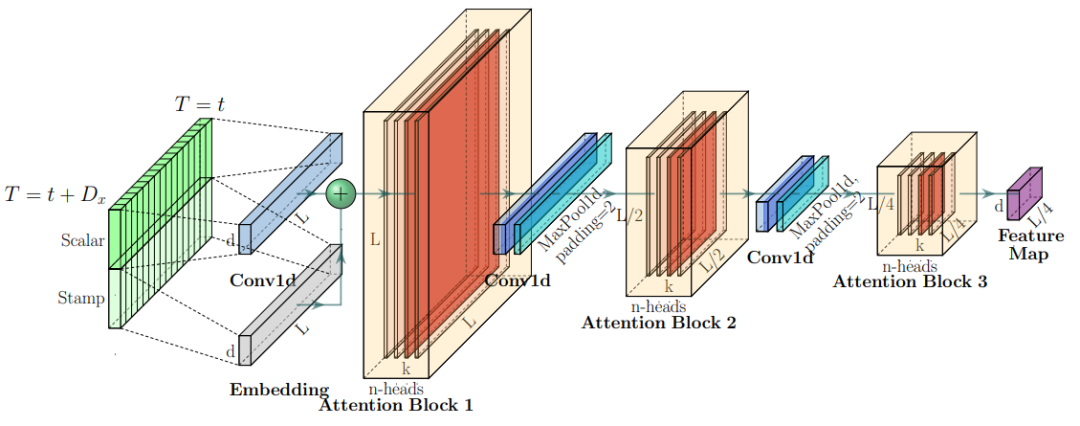
图4:Encoder网络结构
Encoder的作用是Self-attention Distilling,由于ProbSparse自相关机制会带来冗余的V值组合,所以作者在设计Encoder时,采用蒸馏的操作不断抽取重点特征,从而得到值得重点关注的特征图。我们能从图4看到每个Attention Block内有n个头权重矩阵,整个Encoder可以由下面的公式所概况: 代表Attention Block,包括多头ProbSparse自相关, 是1D-CNN(kernel width=3), 是一种激活函数,外面套了max-pooling层(stride=2),每次会下采样一半。这便节省了内存占用率。
3. Decoder
Decoder如图2所示,由2层相同的多头关注层堆叠而成,Decoder的输入如下: 是开始token, 是用0填充预测序列。在使用ProbSparse自相关计算时,会把masked的点积对设为负无穷,这样阻止它们参与决策,避免自相关。最后一层是全连接层,用于最终的输出。
四、实验结果
在4个数据集上,单变量长序列时序预测结果:
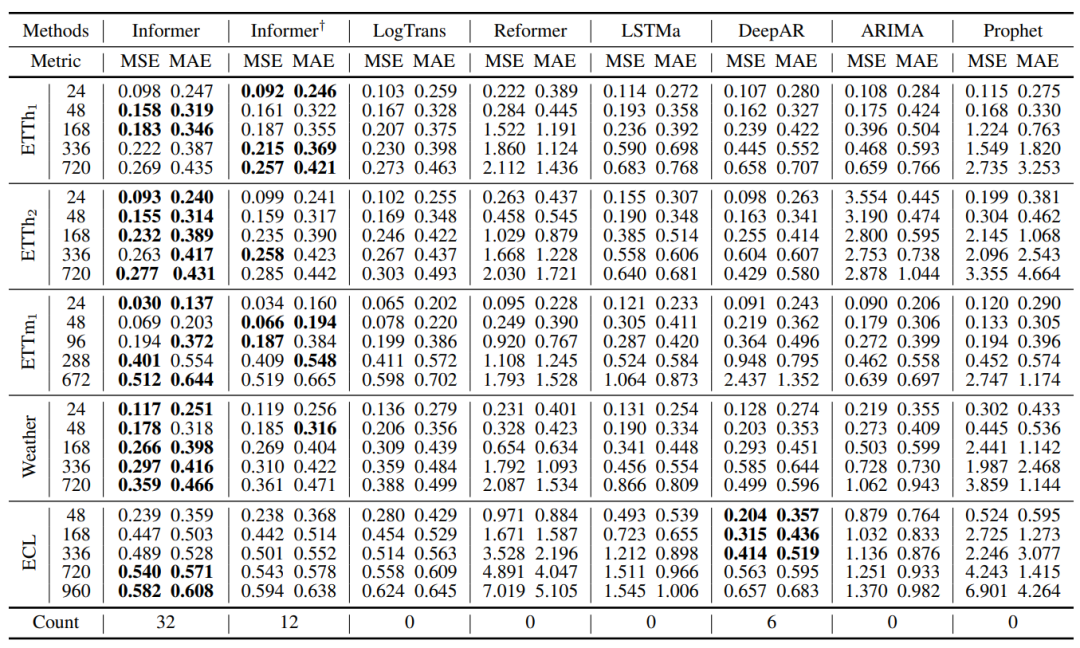
图5:单变量长序列时序预测结果(4个数据集)
Informer在3种变量下,的参数敏感度:
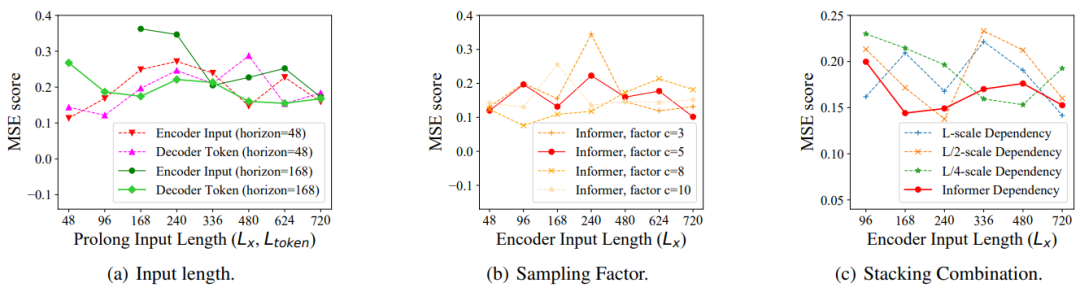
图6:Informer的参数敏感度(3种变量)
ProbSparse自相关机制的消融实验:
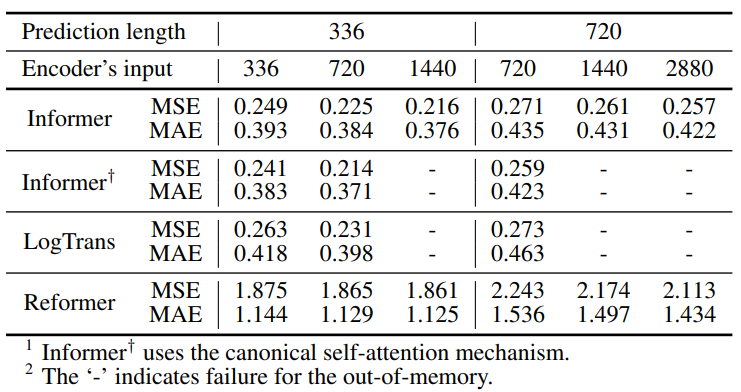
图7:ProbSparse自相关机制的消融实验
每层的复杂度:
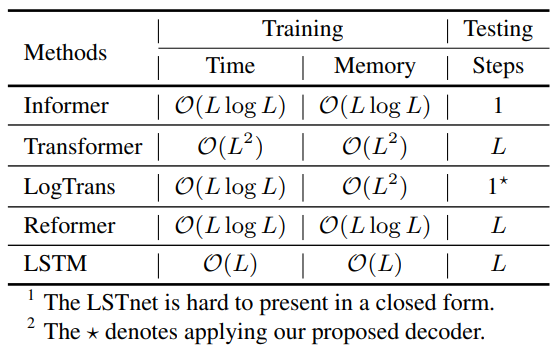
图8:各模型复杂度对比
自关注蒸馏的消融实验:
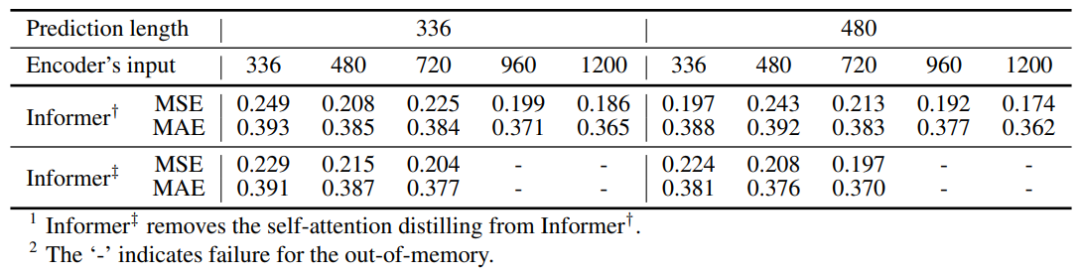
图9:自关注蒸馏的消融实验
生成式decoder的消融实验:
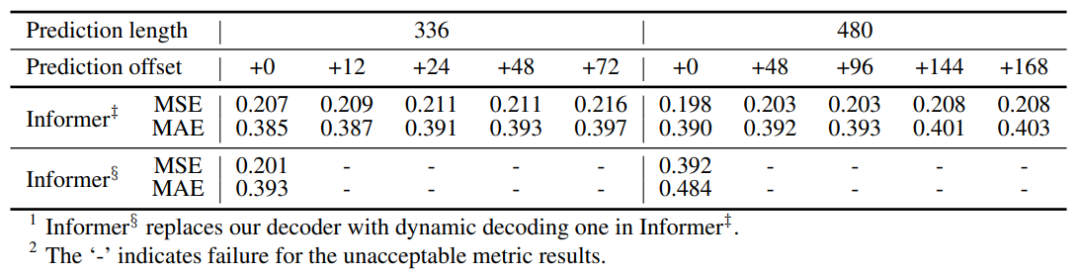
图10:生成式decoder的消融实验
训练和测试阶段的运行时间:
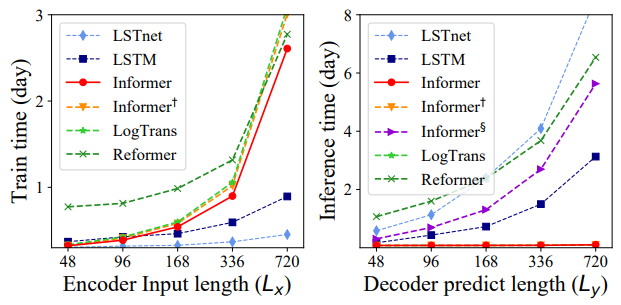
图11:训练和测试阶段的运行时间
五、总结
总的来说,Informer的亮点在于ProbSparse Self-attention和Encoder with Self-attention Distilling。前者采样点积对,减少Transformer的计算复杂度,让其能接受更长的输入。后者采用蒸馏的概念设计Encoder,让模型不断提取重点关注特征向量,同时减少内存占用。
据身边同事反馈,Informer的效果没有我们想象中那么好,也建议大家可以多试试。
参考资料
[1] Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., & Zhang, W. (2021, February). Informer: Beyond efficient transformer for long sequence time-series forecasting. In *Proceedings of AAAI.*
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书
- 随着LLM赋能越来越多需要实时决策和响应的应用场景,以及用户体验不佳、成本过高、资源受限等问题的出现,大模型高效推理已成为一个重要的研究课题。为此,BaihaiIDP推出PierreLienhart的系列文章,从多个维度全面剖析Transf... [详细]
赞
踩
- TransUNet:基于Transformer的强大特征编码器用于医学图像分割AbstractSectionIIntroductionSectionIIRelatedWorksSectionIIIMethodPart1Transformer... [详细]
赞
踩
- 如果想在自然语言处理(NaturalLanguageProcessing,NLP)领域内脱颖而出,那么你一定不能错过ChatGPT的5大自然语言模型:LM、Transformer、GPT、RLHF和LLM。这些模型是NLP领域中最为重要的基... [详细]
赞
踩
- transformer长时间序列预测_informer实战informer实战深度学习(19)——informer详解文章目录深度学习(19)——informer详解一、使用场景二、入口三、dataloader四、model(1)Embed... [详细]
赞
踩
- 本篇博客带大家看的是Informer模型进行时间序列预测的实战案例,它是在2019年被提出并在ICLR2020上被评为BestPaper,可以说Informer模型在当今的时间序列预测方面还是十分可靠的,Informer模型的实质是注意力机... [详细]
赞
踩
- 首先导入代码的基本函数和数据类型,在exp文件下exp_informerimport中的类Exp_Informer中,定义了模型参数、get_data、model_optim、train、test、eval等函数。本文完整代码、相关资料、技... [详细]
赞
踩
- 多步预测是指根据已知的时间序列数据预测未来多个时间步长的值。在ARIMA模型中,可以使用预测函数进行多步预测。Informer是一种用于时间序列预测的神经网络模型,旨在解决长序列预测中的挑战,如长期依赖性和变长序列。它结合了自注意力机制、卷... [详细]
赞
踩
- Informer是一种基于Transformer的时间序列预测模型,它能够有效地处理具有多种时间尺度和复杂性的时间序列数据。与传统的时间序列模型(如ARIMA、LSTM等)不同,Informer利用了Transformer的自注意力机制和多... [详细]
赞
踩
- 目录AAAI2021最佳论文:比Transformer更有效的长时间序列预测BackgroundWhyattentionMethods:thedetailsofInformerSolve_Challenge_1:最基本的一个思路就是降低At... [详细]
赞
踩
- 许多真实世界的应用需要对长序列时间序列进行预测,如用电计划。长序列时间序列预测(Longsequencetime-seriesforecastingLSTF)对模型的预测能力提出了很高的要求,即能够有效地捕捉输出和输入之间精确的长期依赖耦合... [详细]
赞
踩
- article
【paper-note9】Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
前言Transformer[1]模型在NLP领域提出之后,风靡众多领域,有大一统的模式。这篇论文就是对transformer进行改进,提出Informer模型应用在长时序预测领域。该模型设计合理精巧,利用长尾分布截取头部的attention... [详细]赞
踩

