
- 1【K8S认证】2023年CKA考题汇总(解析+答案)_k8s证书认证考试
- 2Python实现代码雨效果_python画代码雨
- 3【目标检测】Faster R-CNN论文代码复现过程解读(含源代码)_使用voc格式进行训练,训练前需要下载好voc07+12的数据集
- 4unity中调用dll文件总结_unity调用dll
- 5【Spring Boot】集成Kafka实现消息发送和订阅_unexpected handshake request with client mechanism
- 6计划任务ScheduledExecutorService的使用_setremoveoncancelpolicy
- 7【书生·浦语大模型实战营】学习笔记1
- 8【JavaEE】传输层网络协议
- 9【无标题】Unity2021安装后无法打开的问题_unity pattern not found
- 10llama2大模型---商用部署(模型推理阶段)预算估算_v100 大模型推理
Python—Tornado框架(三)WebSocket原理_python tornado websocket
赞
踩
Python——Tornado框架(三)、WebSocket
参考博文:https://www.cnblogs.com/wupeiqi/p/6558766.html
一、WebSocket介绍
Http——socket实现,短链接。链接之后断开。只能请求响应。
WebSocket——socket实现,双工通道。想什么时候断就什么时候断。不仅请求响应,还能推送。
本质就是Socket创建链接,不断开。
知道了本质,就可以从socket入手:
二、WebSocket握手过程分析
-
服务端(socket服务端)
1、服务端开启socket,监听IP和端口
3、允许链接
*5、服务端接收到特殊值【特殊值加密,sha1加密,magic string=258EAFA5-E914-47DA-95CA-C5AB0DC85B11】(这个magic string 是固定值)
6、加密后的值发送给客户端 -
客户端(浏览器)
2、客户端发起请求(IP和端口)
*4、客户端生成一个特殊值,向服务端发送一段特殊值 “xxxxxxxxx”。切客户端自己加密这段特殊值,但不发送。
7、客户端接收到加密的的值,与自己加密的值相比较,如果一样的话,说明遵循了WebSocket协议。
收发数据
三、基于Python实现WebSocket握手过程
由于是通过socket实现的,先简单的搭建:
后端:
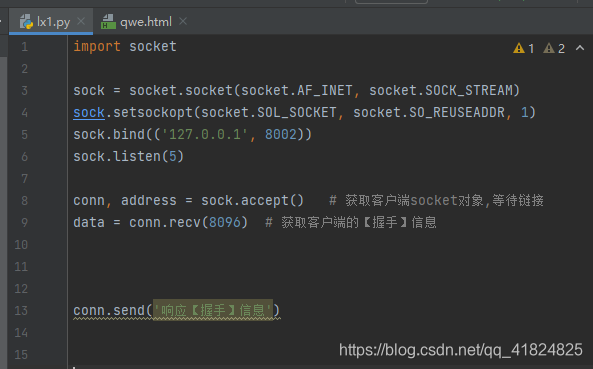
前端:
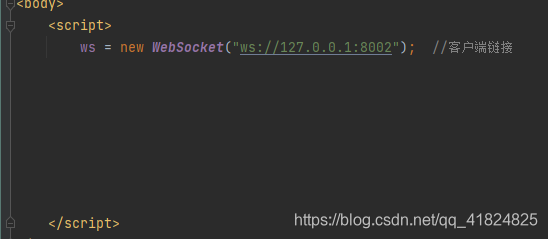
可以看到后端部分data是接收信息的,可以先看下接收到的信息有什么:
 可以看到获取到了很多信息,可以发现很像 http 的请求头之类的东西。我们可以写一个函数对这段信息进行分隔:
可以看到获取到了很多信息,可以发现很像 http 的请求头之类的东西。我们可以写一个函数对这段信息进行分隔:
def get_headers(data): """ 将请求头格式化成字典 :param data: :return: """ header_dict = {} data = str(data, encoding='utf-8') header, body = data.split('\r\n\r\n', 1) header_list = header.split('\r\n') for i in range(0, len(header_list)): if i == 0: if len(header_list[i].split(' ')) == 3: header_dict['method'], header_dict['url'], header_dict['protocol'] = header_list[i].split(' ') else: k, v = header_list[i].split(':', 1) header_dict[k] = v.strip() return header_dict

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
分割后的信息:
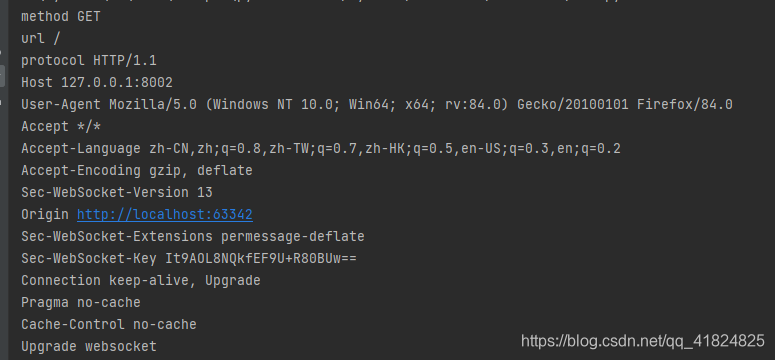
接着我们就能看到生成的随机字符串:

既然获取到这个值,就可以对它进行加密:

接着:
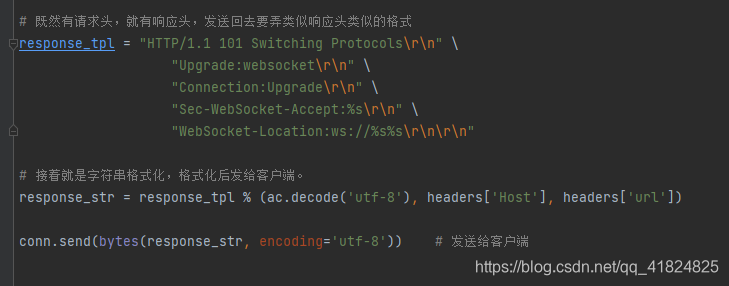
发送给客户端之后,就要进行对比:
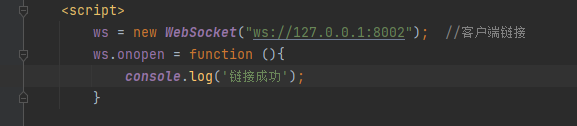
效果:
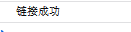
可以看到成功实现,如果把maigc_srring稍微改动一点,就可以看到链接失败:

四、WebSocket数据解析过程
1、客户端向服务端发送消息
客户端发送:
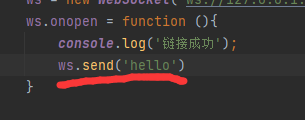
服务端接收:
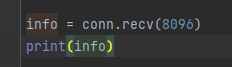
然后结果:

可以看到这就是我们接收到的东西。
接收到数据以后,需要通过一定的方式才能看到信息。
2、数据解析
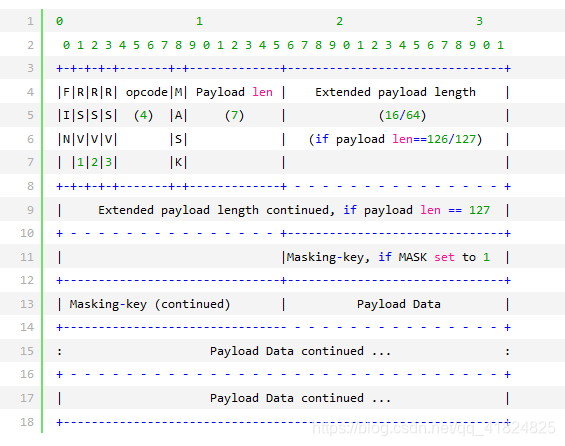
因为一个字节8位,所以前8个数字代表一个字节。

因为info接收到这些字节,所以 Info[0],就是拿第一个字节。要计算一个字节后四位的值,可以通过 跟 00001111 进行与运算,就能知道相对应的值。
(看上图)
所以 oncode = info[0] & 15
如果我们想要 fin (上图第一个)的值,可以通过拿到第一个字节,向右移动7位,就可以拿到:
fin = info[0] >>7
可以看到payload len占7位。(如果全是1,则最大是127)
所以 payload len的值为:
payload_len = info[1] & 127
重点:payload len的长度会决定往后占多少,后面占几位,payload len说了算。

如果payload len小于126,表示:

表示刚好就这么多位置,后面放数据。
如果payload len等于126:
再往后延伸16位(两个字节)
如果payload len大于126:
往后延伸64位(8个字节)
3、masking key
数据部分的前面4个字节,是masking key,发送的数据已经进行加密,需要通过前面4个字节进行解密。
数据头—masking key—数据
4、数据解包
既然知道了原理,就可以进行解包:
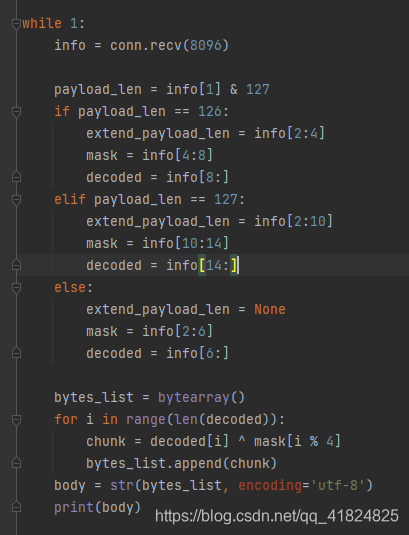
info = conn.recv(8096) payload_len = info[1] & 127 if payload_len == 126: extend_payload_len = info[2:4] mask = info[4:8] decoded = info[8:] elif payload_len == 127: extend_payload_len = info[2:10] mask = info[10:14] decoded = info[14:] else: extend_payload_len = None mask = info[2:6] decoded = info[6:] bytes_list = bytearray() for i in range(len(decoded)): chunk = decoded[i] ^ mask[i % 4] bytes_list.append(chunk) body = str(bytes_list, encoding='utf-8') print(body)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
能分割开了,就能去解码了(原理):

后端:
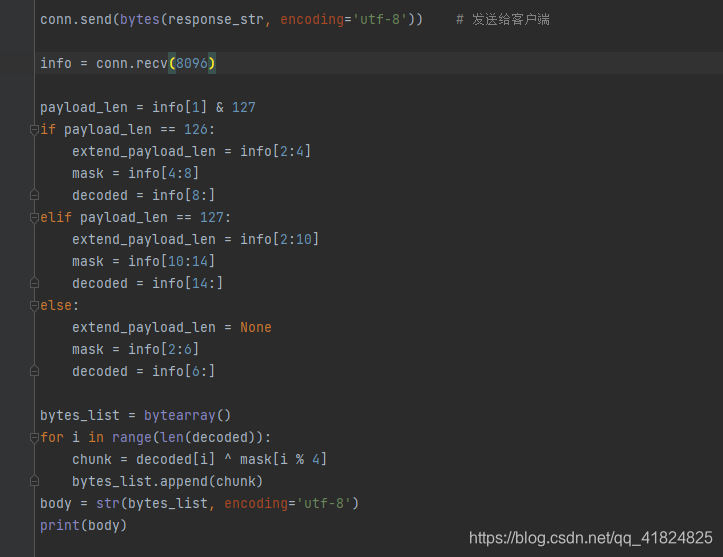
然后再次看效果:
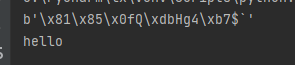
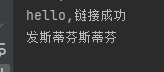
就能发现成功接收到数据。
如果字节是一个一个解,则只能解码英文。因为中文是三个三个字节。中文就不要直接解成字符串,中文先解成字节,最后全部都是字节,再统一转换成字符串。所以这里不仅能解码英文,还能解码中文:
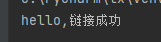
5、客户端服务端互发消息
如果我们加上一个循环,就能不断接收:
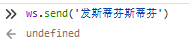
后端:
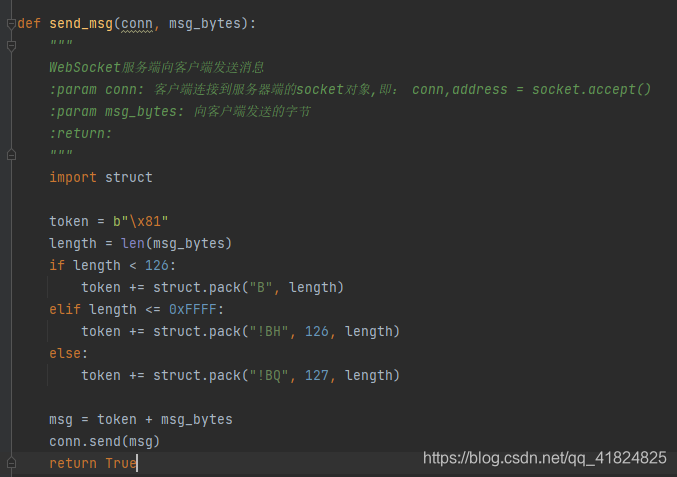
然后服务端发送消息:
代码:

前端:
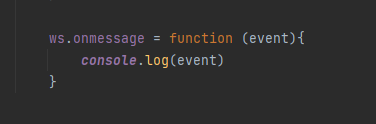
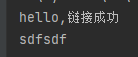
效果:

- 首先推荐相关两篇博客写得非常详细。关于Python中深拷贝与浅拷贝的理解(一)—概念由Python的浅拷贝(shallowcopy)和深拷贝(deepcopy)引发的思考直接举个栗子:importcopya=[1,2,3,4,['a','b... [详细]
赞
踩
- 拷贝就是重新分配一块内存,创建一个新的对象,但里面的元素是原对象中各个子对象的引用。相较于普通的赋值,浅拷贝会将两个变量分别放在不同的内存地址,解决了直接赋值的缺点但是如果我们这个数据结构不是一层的怎么办呢,那就要用到深拷贝。copy.de... [详细]
赞
踩
- 深拷贝与浅拷贝的区别在于,当从原本的list复制出新的list之后,修改其中的任意一个是否会对另一个造成影响,即这两个list在内存中是否储存在同一个区域,这也是区分深拷贝与浅拷贝的重要依据。对于list的第一层,是实现了深拷贝,但对于嵌套... [详细]
赞
踩
- Python提高篇学习笔记(一):深拷贝和浅拷贝_pythonforin深拷贝pythonforin深拷贝文章目录一、什么是对象的引用二、深拷贝和浅拷贝2.1浅拷贝(ShallowCopy)2.2深拷贝(DeepCopy)2.3copy.c... [详细]
赞
踩
- 学习笔记------检查字串是否包含在字符串中,若包含,返回。查找子串在字符串中的位置或出现的次数。将列表里的数据合并为一个大字符串并。分割,返回一个列表,丢失分割字符。替换次数超出总次数,表示替换所有旧子串。删除字符串左侧空白字符。删除字... [详细]
赞
踩
- 详细分析Python3的赋值、浅拷贝与深拷贝,以简单的例子和一目了然的图解让你对Python的赋值、浅拷贝和深拷贝都有一个深刻的认识_fromcopyimportcopyfromcopyimportcopy【Python】赋值、浅拷贝与深拷... [详细]
赞
踩
- 话不多说上源代码,只要把lxml的库安装下就好了这个程序完全是解放双手,而且没有弹窗网页等困扰__author__='JianqingJiang'#-*-coding:utf-8-*-importurllib2fromlxmlimporte... [详细]
赞
踩
- 1.api/permission.py#-*-coding:utf8-*-classGradeOnePermission(object):defhas_permission(self,request,view):grade=request.... [详细]
赞
踩
- Django的用户认证系统提供了一套强大而灵活的工具,让我们能够轻松构建安全可靠的Web应用程序。使用Django框架我们可以轻松实现用户注册、登录、密码重置和用户权限管理等功能。_django用户注册与验证django用户注册与验证关键词... [详细]
赞
踩
- Django安装:eldon@ubuntu:~$sudopipinstallDjango==1.10.5Thedirectory'/home/eldon/.cache/pip/http'oritsparentdirectoryisnotow... [详细]
赞
踩
- django自定义登录页并实现登录_django用户管理模块django用户管理模块Python-django自定义模块开发第四章Django自定义模块-使用自定义用户管理模块进行应用管理前言 本系列文章以一个简单的学校项目来做演... [详细]
赞
踩
- 有一个参数,是request。它的返回值可以是None也可以是对象。返回值是None的话,交给下一个中间件处理,如果是HttpResponse对象,Django将不向下执行,直接返回process_view()有四个参数request是对象... [详细]
赞
踩
- 一、Django的用户认证组件用户认证 auth模块在进行用户登陆验证的时候,如果是自己写代码,就必须要先查询数据库,看用户输入的用户名是否存在于数据库中;如果用户存在于数据库中,然后再验证用户输入的密码,这样一来就要自己编写大量的代码。事... [详细]
赞
踩
- 前言:Django是一个python大而全的前端框架,Django自带的admin也是一个不错的信息管理系统,功能多,可拓展性强。那么,我们仿照Django-admin能不能自己写代码实现admin的主要功能呢?答案是当然可以!!!通过这个... [详细]
赞
踩
- 在进行机器学习任务时,数据预处理是至关重要的一环。其中,数据标准化是一项关键技术,它可以确保不同特征的值处于相似的尺度,从而提高机器学习模型的性能。在本文中,我们将深入探讨使用Pandas进行数据标准化的方法,并提供详细的代码实例和解析。P... [详细]
赞
踩
- 有限状态机:https://blog.csdn.net/suwei19870312/article/details/12094233classSolution(object):defisNumber(self,s):""":types:st... [详细]
赞
踩
- 上一篇(Python异常处理(二))中,我们了解了如何使用traceback模块和logging模块获取异常信息。这一篇,我们将讲述有关于with,assert,raise的相关知识。_assertionerror()assertioner... [详细]
赞
踩
- 注册表相关接口:#打开注册表runpath="Software\Microsoft\Windows\CurrentVersion\Run"hKey=win32api.RegOpenKeyEx(win32con.HKEY_CURRENT_US... [详细]
赞
踩
- 使用Docker快速部署主流编程语言的开发、编译环境及其常用框架,包括C、C++、Java、Python、JavaScript、Go、PHP、Ruby、Perl、R、Erlang等。在今后采用编程语言开发和测试时,将再也不用花费大量时间进行... [详细]
赞
踩
- 使用python脚本也可以作为windows的服务程序运行只要下载并安装pywin32模块,就可以很轻松的开发windows服务了源码如下:importwin32serviceutilimportwin32serviceimportwin3... [详细]
赞
踩

