
热门标签
热门文章
- 1dpkg: error processing package xxx (--configure)的解决方法_dpkg: error processing package freerdp2-x11 (--con
- 2缓存性能之王caffeine使用文档_caffeine文档
- 3Linux--根文件系统的挂载过程分析_linux 把根挂载为可执行
- 4使用pip安装特定的软件包版本_pip安装指定版本的包 -baijiahao
- 5Fiori Elements 框架里 Smart Table 控件工作原理的深入解析
- 62023年,云计算的发展将展现出令人瞩目的趋势
- 7传统企业数字化转型真的有必要吗?应该如何做转型?_传统 规则 动力 数字化
- 8ISO/IEC 27002:2022中文版_iso27002 2022版
- 9sublime text3 node.js配置
- 10工具推荐 |Devv.ai — 最懂程序员的新一代 AI 搜索引擎_devv.ai访问不了
当前位置: article > 正文
第六周深度学习总结_mlp head
作者:IT小白 | 2024-02-16 12:03:32
赞
踩
mlp head
Vision Transformer
ViT模型架构
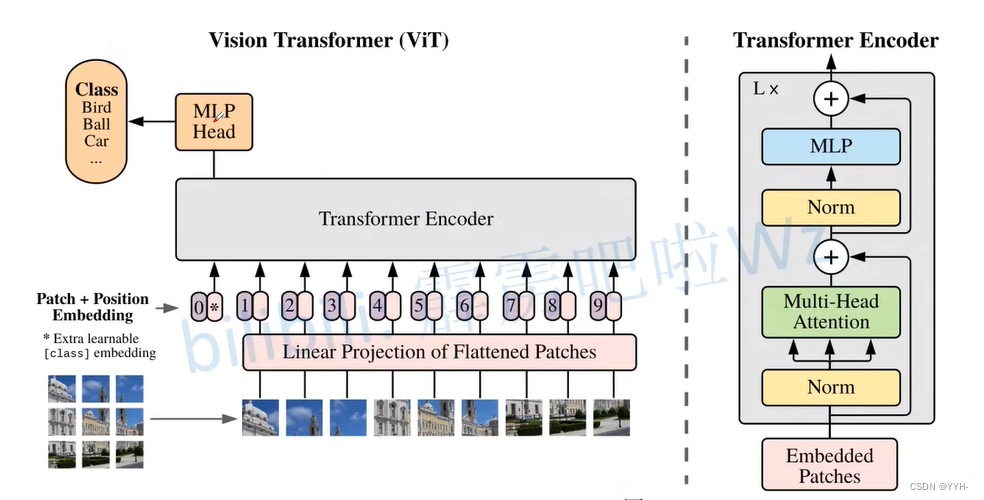
- Linear Projection of Flattened Patches(Embedding层)
-
Transformer Encoder( 图右侧有给出更加详细的结构)
-
MLP Head (最终用于分类的层结构)
Embedding层
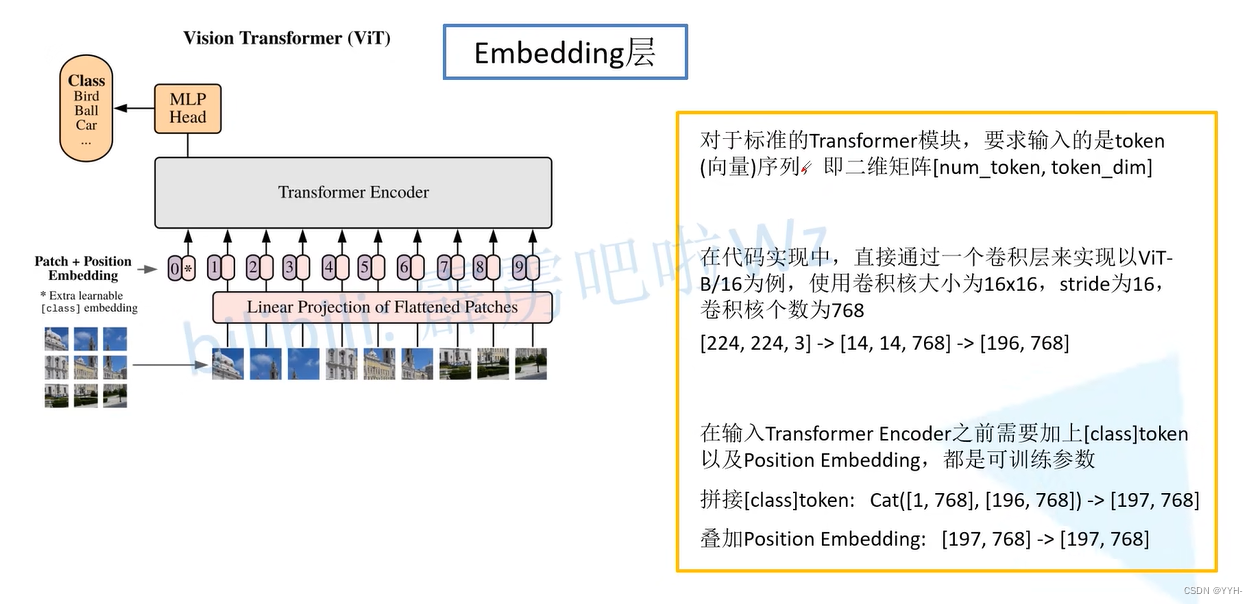
Position Embedding

位置编码之间的差异不大。
Transformer Encoder层
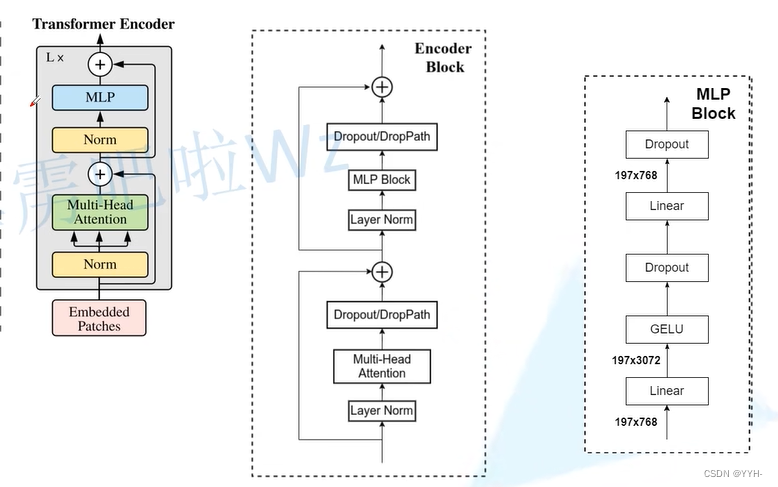
Encoder Block 堆叠L次即为 Transformer Encoder层 。
MLP Head层
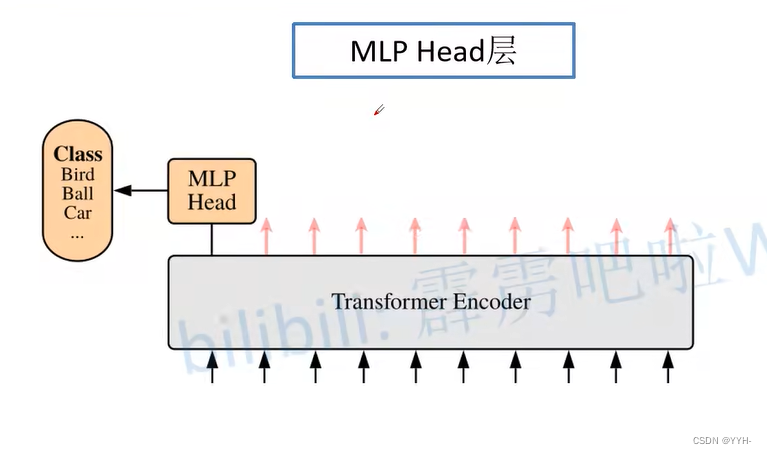
训练ImageNet21K时是由 Linear+tanh激活函数+Linear,但是迁移到ImageNet1K上或者你自己的数据上时,只有一个Linear。
Hybrid混合模型
首先使用一个卷积操作提取出特征,之后再通过ViT模型
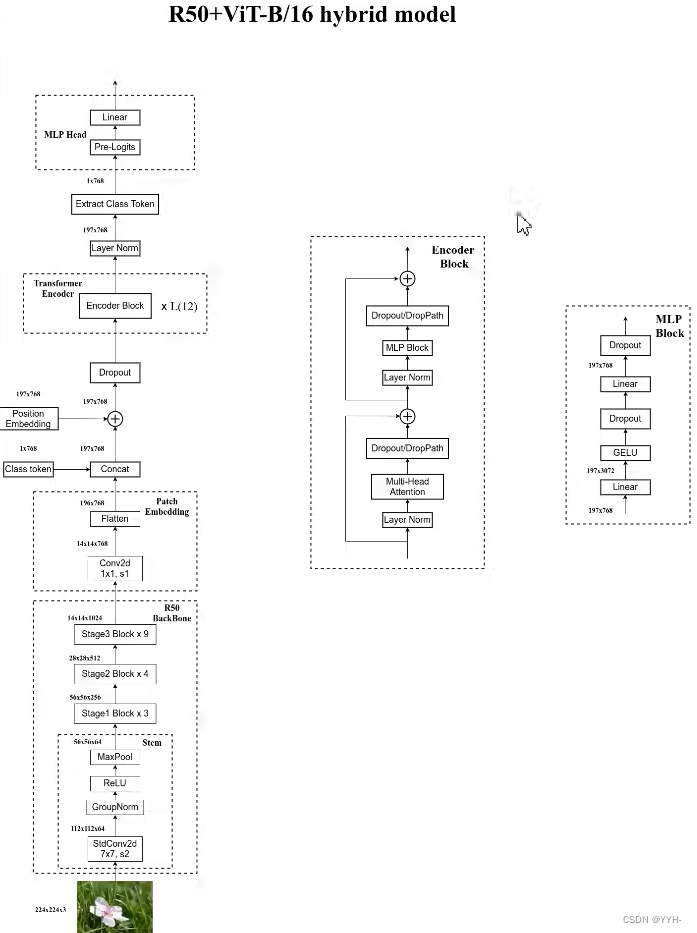
- R50的卷积层采用的StdConv2d 不是传统的Conv2d
-
将所有的 BatchNorm 层替换成 GroupNorm层
-
把 stage4 中的 3 个 Block 移至 stage3中
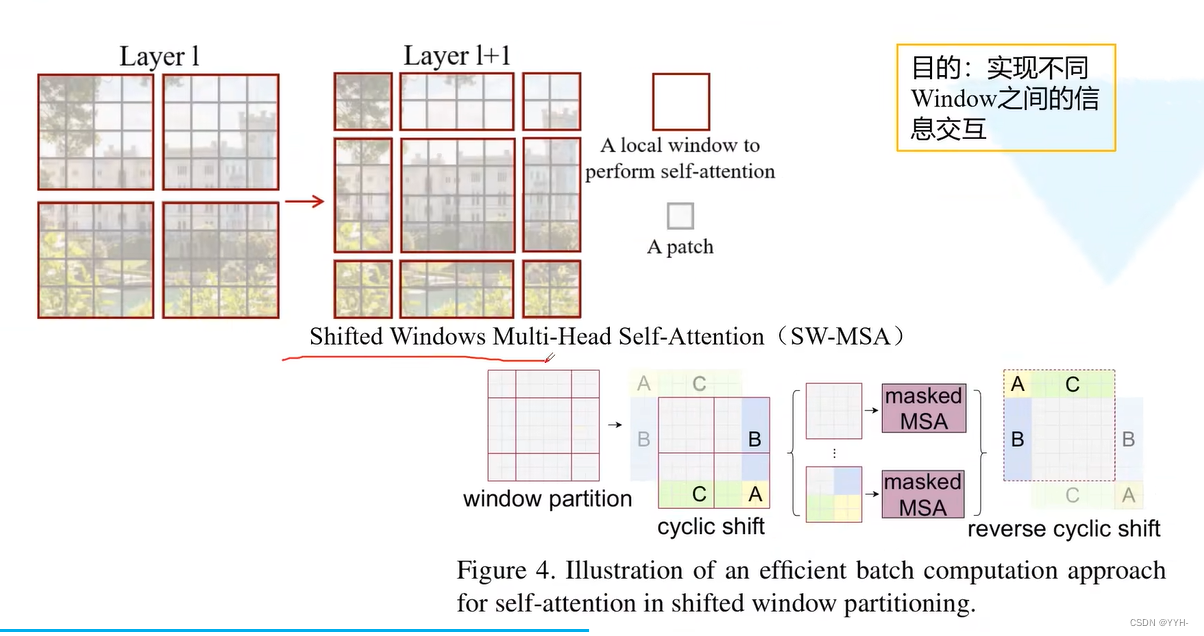
Swin-Transformer

window之间不进行信息传递,大大降低运算量。
网络整体框架
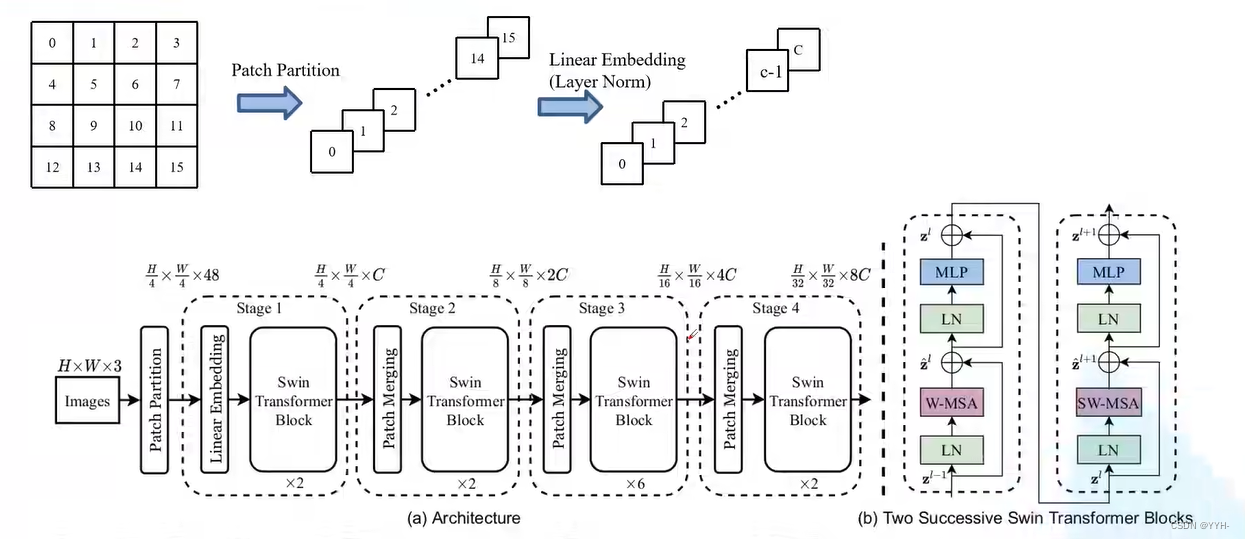
Patch Merging详解

W-MSA详解
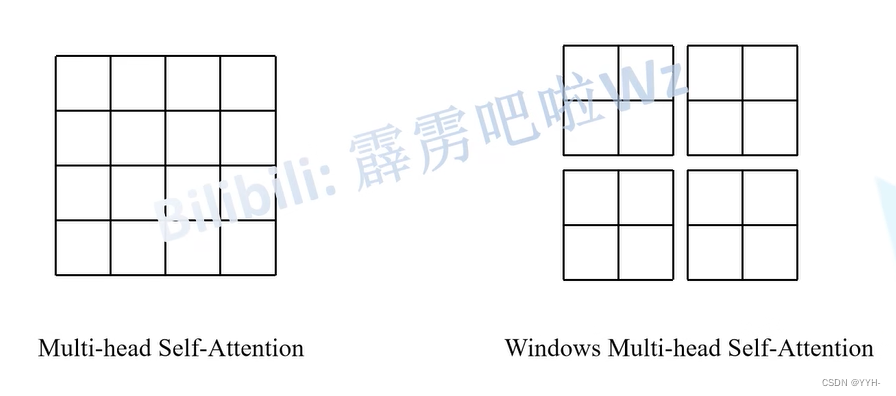 目的:减少计算量
目的:减少计算量
缺点:窗口之间无法进行信息交互
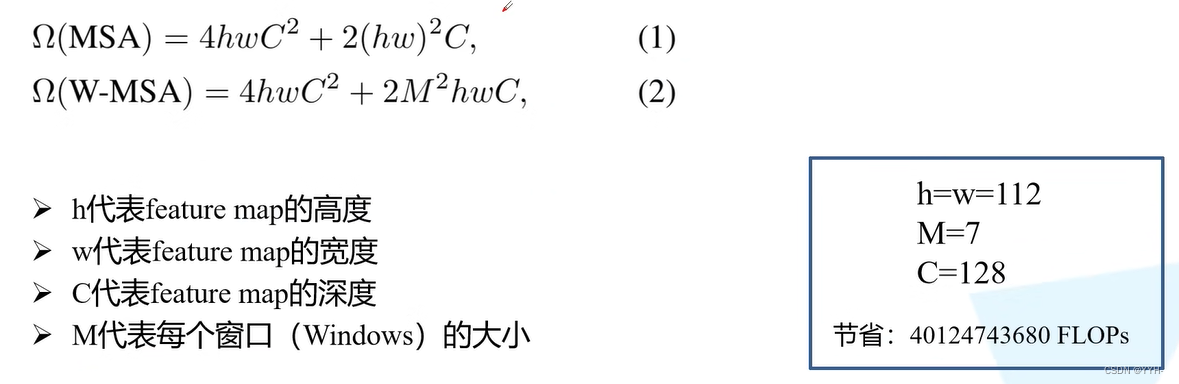
从上图可以看出,W-MSA模块能够比MSA模块节省大量的计算量。
Shifted Window
Relative position bias

之后经过下图的变换
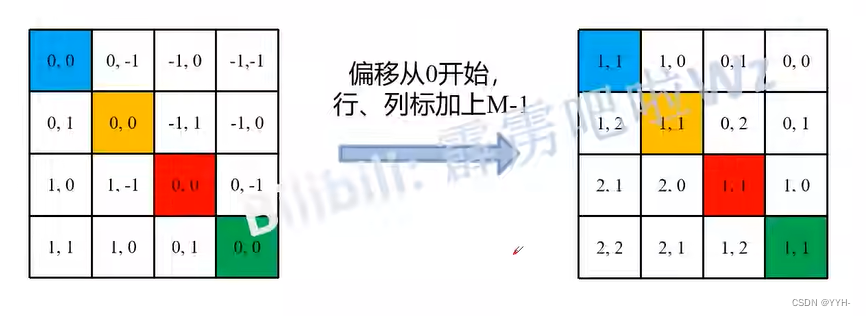

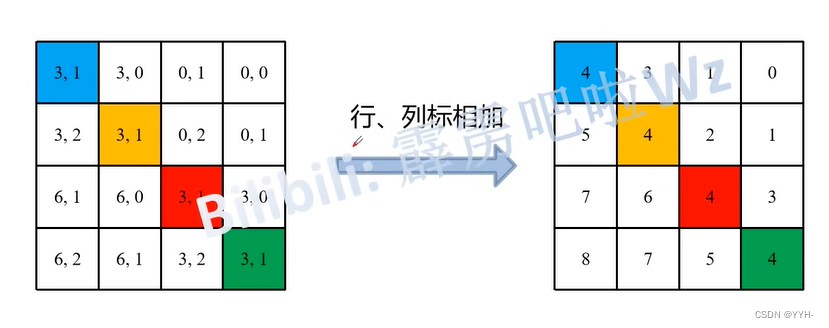
经过变换得到 relative position index。

最后经过上图的步骤得到relative position bias。
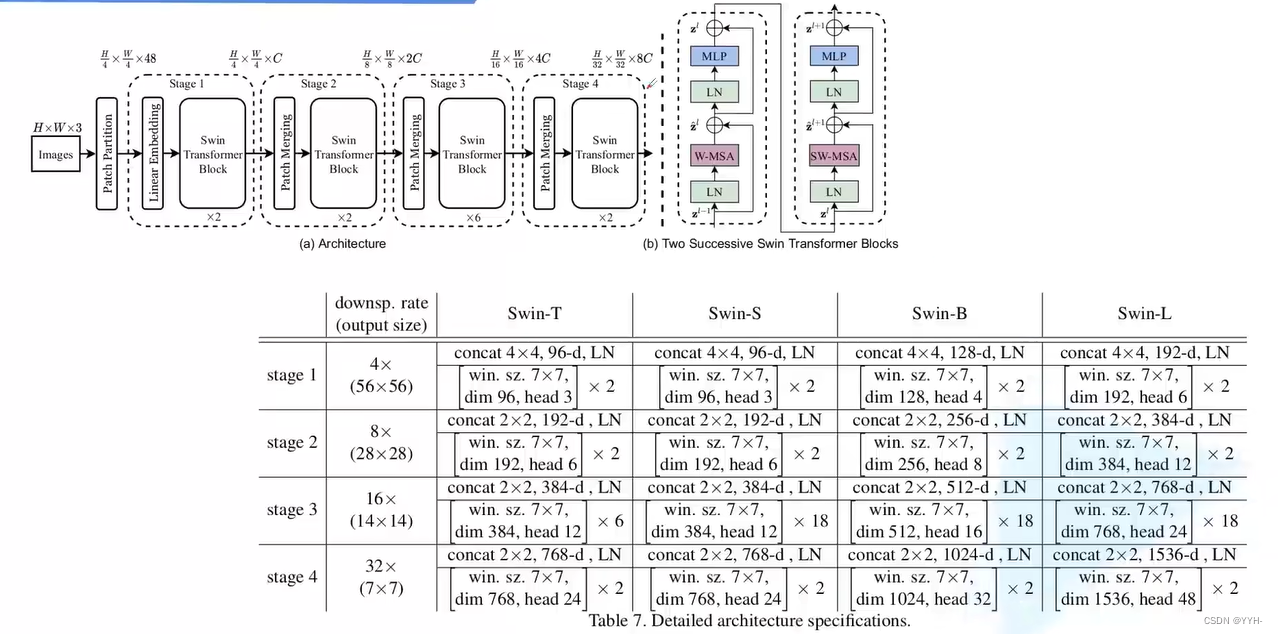
模型详细配置参数
ConvNeXt
作者将Transformer中运用的新技术,运用在卷积神经网络上。
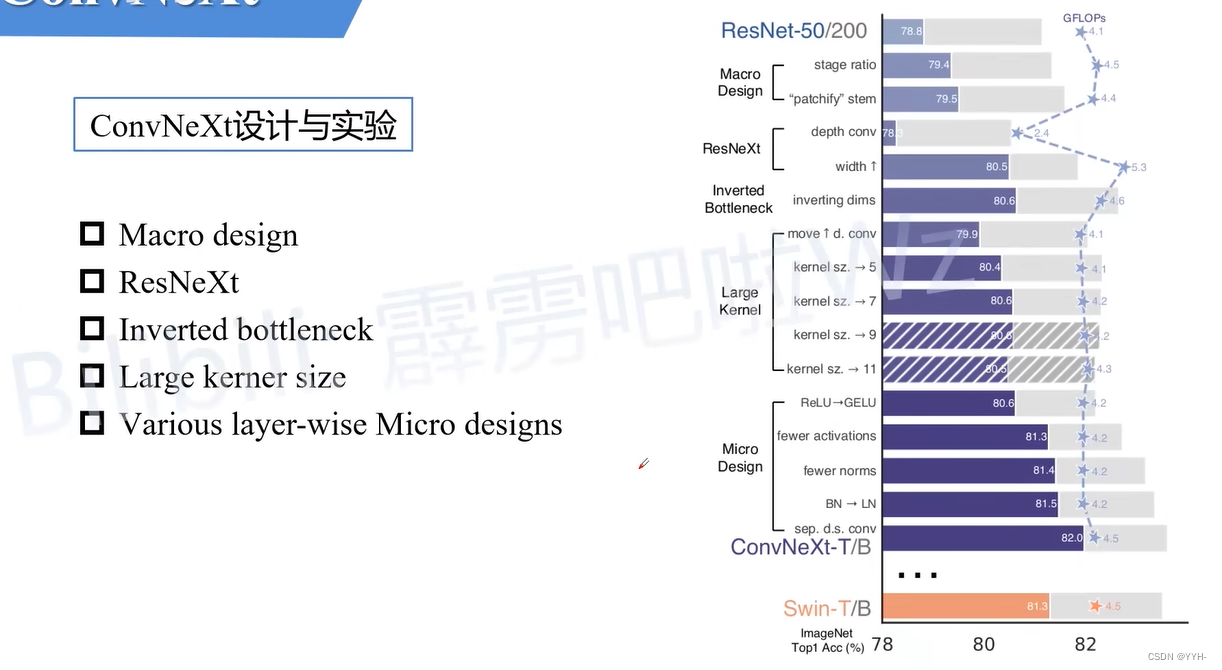
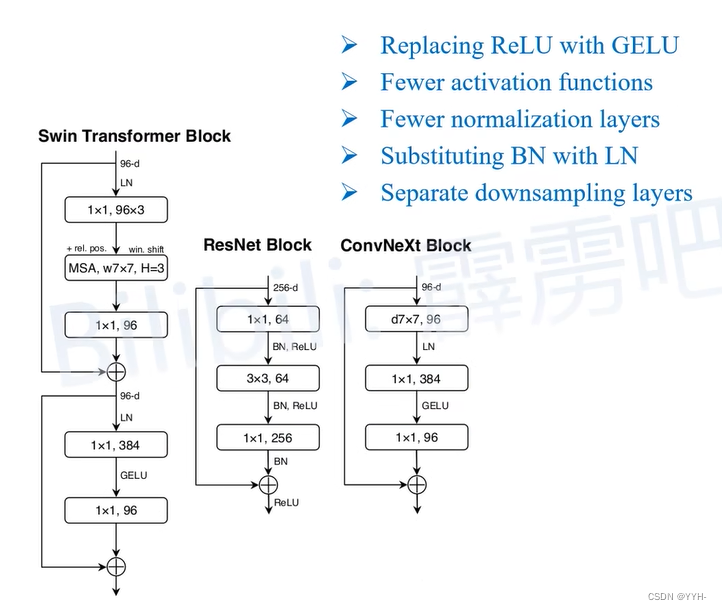
Macro design
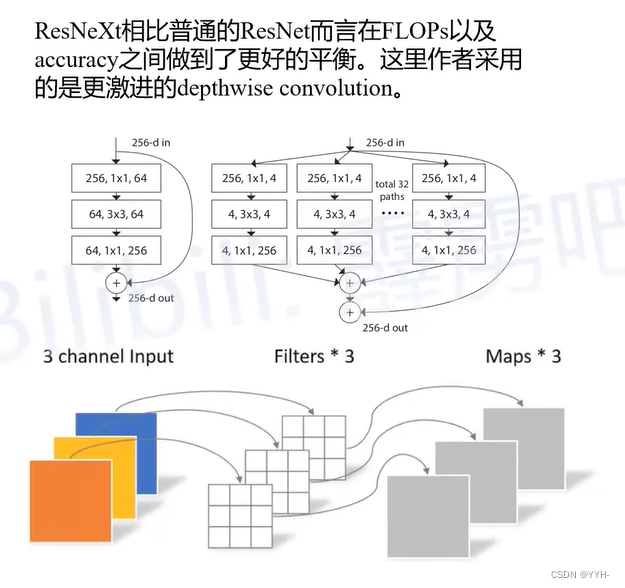
ResNeXt
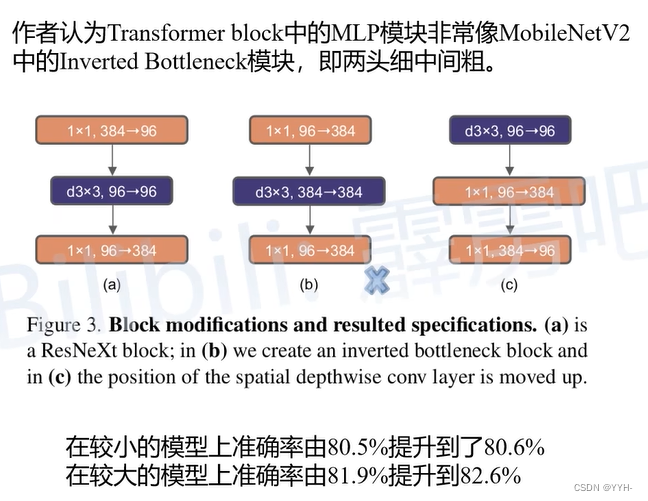
Inverted bottleneck
Large kerner size
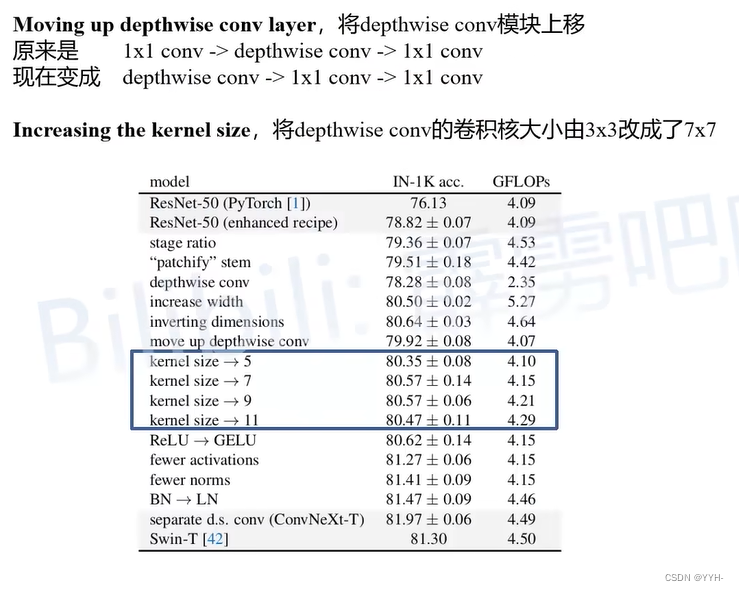
Macro designs
感想
认真学习各个网络是非常重要的,把它们的思想理解透彻,才能做到推陈出新。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/93005
推荐阅读
- 定义变量::root{--frame-color:red;}使用变量:html{background-color:var(--frame-color);}jquery:修改变量:document.body.style.setProperty... [详细]
赞
踩
- 【给你一个链表,每k个节点一组进行翻转,请你返回翻转后的链表。k是一个正整数,它的值小于或等于链表的长度。如果节点总数不是k的整数倍,那么请将最后剩余的节点保持原有顺序。进阶:你以设计一个只使用常数额外空间的算法来解决此问题吗?你不能只是单... [详细]
赞
踩
- 给你一个链表的头节点head和一个整数val,请你删除链表中所有满足Node.val==val的节点,并返回新的头节点。方法一思路:将值不等于val的结点重新链接成一条新链表structListNode*removeElements(str... [详细]
赞
踩
- 数组,迭代,递归_
赞
踩
- 题目来源:206.反转链表-力扣(LeetCode)(leetcode-cn.com)题目描述:代码实现:1、方法一:structListNode*reverseList(structListNode*head){if(!head)retu... [详细]
赞
踩
- 链表回文第一题boolisPalindrome(structListNode*head){structListNode*cur=head;structListNode*vec[100001];inti=0;while(cur){vec[i]... [详细]
赞
踩
- 反转一个单链表法一:利用3个指针structListNode*reverseList(structListNode*head){if(head==NULL||head->next==NULL)returnhead;structListNod... [详细]
赞
踩
- article
Linux基础命令(三):重定向、展开与引用——cat、sort、uniq、grep、wc、head、tail、tee、管道、echo、字符展开、双引号、单引号、转义字符序列_linux >>重定向不换行命令使用
目录I/O重定向标准输入、输出和错误标准输出重定向标准错误重定向重定向标准输出和错误到同一个文件处理不需要的输出标准输入重定向管道线过滤器字符展开路径名展开波浪线展开算术表达式展开花括号展开参数展开命令替换引用双引号单引号转义字符I/O重定... [详细]赞
踩
- CV领域Transformer这一篇就够了(原理详解+pytorch代码复现)_mlpheadmlphead这一篇不够不够,当时年轻瞎写的,臭长的文章懒得改了,看别的博客吧(˚˃̣̣̥᷄⌓˂̣̣̥᷅)。文章目录前言一、注意力机制1.1注意力... [详细]
赞
踩
- 原文链接:https://blog.csdn.net/qq_37541097/article/details/117691873原文名称:AttentionIsAllYouNeed原文链接:https://arxiv.org/abs/170... [详细]
赞
踩
相关标签

