
- 1浅谈Volatile三大特性
- 2windows版 docker desktop学习笔记——2 容器仓库管理_docker desktop创建命名空间
- 3STM32f103C8T6的优势是什么?
- 4python对文件操作 r w a 文件复制/修改_r 复制其他文件夹下的文件追加内容
- 5前端登录界面网站设计模板--HTML+CSS
- 6使用Sqoop将Hive数据导出到TiDB
- 7解决浏览器访问Github访问速度慢问题_github加速访问
- 8使用IDA对ipa进行反编译_windows反编译ipa
- 9选择排序 | 冒泡排序 | C语言(详解)
- 10回归预测 | MATLAB实现CNN-GRU-Attention多输入单输出回归预测_机器学习之心 多变量预测回归
GMM的EM算法实现_gmm em算法 csdn
赞
踩
在 聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut一文中我们给出了GMM算法的基本模型与似然函数,在EM算法原理中对EM算法的实现与收敛性证明进行了详细说明。本文主要针对如何用EM算法在混合高斯模型下进行聚类进行代码上的分析说明。
1. GMM模型:
每个 GMM 由 K 个 Gaussian 分布组成,每个 Gaussian 称为一个“Component”,这些 Component 线性加成在一起就组成了 GMM 的概率密度函数:
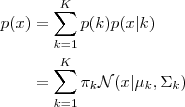
根据上面的式子,如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K个Gaussian Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 pi(k) ,选中了 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为了已知的问题。
那么如何用 GMM 来做 clustering 呢?其实很简单,现在我们有了数据,假定它们是由 GMM 生成出来的,那么我们只要根据数据推出 GMM 的概率分布来就可以了,然后 GMM 的 K 个 Component 实际上就对应了 K 个 cluster 了。根据数据来推算概率密度通常被称作 density estimation ,特别地,当我们在已知(或假定)了概率密度函数的形式,而要估计其中的参数的过程被称作“参数估计”。
2. 参数与似然函数:
现在假设我们有 N 个数据点,并假设它们服从某个分布(记作 p(x) ),现在要确定里面的一些参数的值,例如,在 GMM 中,我们就需要确定 影响因子pi(k)、各类均值pMiu(k) 和 各类协方差pSigma(k) 这些参数。 我们的想法是,找到这样一组参数,它所确定的概率分布生成这些给定的数据点的概率最大,而这个概率实际上就等于  ,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和
,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和 ![]() ,得到 log-likelihood function 。接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
,得到 log-likelihood function 。接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
下面让我们来看一看 GMM 的 log-likelihood function :
- docker是一个虚拟环境容器,可以将你的开发环境、代码、配置文件等一并打包到这个容器中,并发布和应用到任意平台中。docker容器和虚拟机都有虚拟隔离的特性,所以一般都会拿虚拟机和docker容器作比较。............_dock... [详细]
赞
踩
- 首先还是简要的介绍一下生成式大模型AI,去年末由美国openAI公司引爆的新一代人工智能模型,给原本要凉凉的AI领域放了一把火。导致所有具备能力的大集团一窝蜂似的涌入,希望能涌现出相当甚至超越人类的智能。这类大模型,之所以叫“大”,是由于它... [详细]
赞
踩
- B.T-primestimelimitpertest2secondsmemorylimitpertest256megabytesinputstandardinputoutputstandardoutputWeknowthatprimenum... [详细]
赞
踩
- 1.查看磁盘Linux磁盘管理常用三个命令为df、du和fdisk。df:列出文件系统的整体磁盘使用量du:检查磁盘空间使用量fdisk:用于磁盘分区df命令参数功能:检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间... [详细]
赞
踩
- ZYNQ的启动分为两个阶段:第一阶段:BOOTROM(由ZYNQ厂家固化代码)第二阶段:FSBL(FirstStageBootloader),由SDK工具来制作1.第一阶段(BOOTROM) 上电后,ZYNQSOC会首先执行片内BOOTRO... [详细]
赞
踩
- vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都... [详细]
赞
踩
- 服务器管理包括为优化服务器性能和最大限度地减少停机时间而执行的所有活动。服务器管理涉及两个基本步骤:网络监控和服务器维护。因为是服务器,所以常规使用方式还是用远程连接的方式。远程连接大体有两种,一种是ssh,这种直接进入命令行,用作服务器跑... [详细]
赞
踩
- 以上代码仅为示例,具体实现需根据讯飞SDK提供的API进行调用。注意替换示例代码中的"your_appid"和"your_appkey"为自己在讯飞开放平台注册时所获得的AppId和AppKey。在微信小程序中调用讯飞口语评测的代码,首先需... [详细]
赞
踩
- 一、物联网1、什么是物联网?物联网在之前被定义为通过射频识别(RFID)、红外线感应器、全球定位系统、激光扫描器、气体感应器等信息传感设备按约定的协议把任何物品与互联网连接起来进行信息交换,以实现智能化识别、定位、跟踪、监控和管理的一种网络... [详细]
赞
踩
- 什么是”云”:迁移至云端。在云中运行。在云中存储。从云端访问----当今时代,似乎一切都在"云"中进行。但是,"云"究竟是一个什么样的概念?简单来说,云就是互联网连接的另一端,你可以从云端访问各种应用程序和服务,也可以在云端安全存储你的数据... [详细]
赞
踩
- importmatplotlib.pyplotaspltimportnumpyasnpimportcv2frommathimportsqrt,powdefblpf(image,d):f=np.fft.fft2(image)fshift=np... [详细]
赞
踩
- 同花顺i问财是同花顺旗下的AI投顾平台,专注于使用AI技术改进财经数据的提取、处理、分析、沉淀以及展现,用户不登陆就可以在i问财使用中文进行选股并进行可视化分析。问财python库是由GraySilver开源的i问财python工具包,通过... [详细]
赞
踩
- C语言指针的运算规则是有许多细节需要注意的。文章指出,*p++操作实际上是先输出*p的值,再对指针p进行自增操作。这一结论与自增自减运算符的使用属性有关。文章还给出了一个示例代码来说明这一规则。指针中p++的含义csdn指向数组的指针偶然发... [详细]
赞
踩
- 目录1.获取MySQL2.安装Mysql2.1解压文件,然后建立一个新的文件夹,并命名好(文件夹的命名用英文命名,不要使用中文命名)2.2安装MySQL2.2.1.以管理员的身份,打开命名指示符(必须是管理员的身份下进行操作)2.2.2切换... [详细]
赞
踩
- 今天分享的深度研究报告:《(报告出品方:华泰证券)报告共计:32页。_车载大模型csdn车载大模型csdn今天分享的AI系列深度研究报告:《大模型专题报告:AI大模型如何赋能智能座舱》。(报告出品方:华泰证券)报告共计:32页智能座舱:4.... [详细]
赞
踩
- TopazVideoEnhanceAI是Mac上的提升视频分辨率的工具,也是拍摄出色画面,并将其变得完美方法!借助软件TopazVideoEnhanceAI,可以将您的素材从标清转换为高清,并不会发生模糊,且会得到质量的提升,非常适合您想要... [详细]
赞
踩
 回顾2023恒川的编程之旅一、这一年的日常内容1.每天坚持做一道力扣2.每天传码云3.每天坚持背单词4.坚持写博客5.坚持跑步锻炼二、这一年的学习历程23年1月到4月23年5月到6月23年7月23年8月23年9月23年10月23年11月23... [详细]
回顾2023恒川的编程之旅一、这一年的日常内容1.每天坚持做一道力扣2.每天传码云3.每天坚持背单词4.坚持写博客5.坚持跑步锻炼二、这一年的学习历程23年1月到4月23年5月到6月23年7月23年8月23年9月23年10月23年11月23... [详细]赞
踩
- 想只读出后缀为tif的文件进行处理。_python读取多个文件夹下面的不同格式的图片csdnpython读取多个文件夹下面的不同格式的图片csdn一.应用背景目标文件夹下有四种不同的数据类型文件:想只读出后缀为tif的文件进行处理。二.代码... [详细]
赞
踩
- article
marvell 88Q6113 固件配置 (automotive_switch_config_win_v4.10.0001_ENGINEERING_VERSION 工具使用)_88q6113 csdn
方法为:automotive_switch_config_win_v4.10.0001_ENGINEERING_VERSIONGUI工具中,配置好后,commands->exportconfigurationtofile然后保存为confi... [详细]赞
踩
- UnityAssetBundle手把手教程_unityassetbundle+csdnunityassetbundle+csdnUnityAssetBundle从无知到入门!!了解AssetBundleAB包和Resource文件夹的区别打... [详细]
赞
踩

