
- 1Java程序员的6个级别_java等级证书
- 2又一个不可错过的编程大模型来了让你惊呼“码农人生”不虚此行_代码大模型
- 3操作系统精髓与设计原理--IO管理和磁盘调度
- 4JS下载文件的三种方法_window.download
- 5【访客必读 - 指引页】一文囊括主页内所有优质博客
- 6非计算机科班背景者顺利转码计算机领域:策略与前景展望_非科班转码现实吗
- 7Jmeter之HTTP请求详解_jmeter http请求
- 8vue NavMenu(菜单超出显示更多)_vue 顶部菜单宽度超出处理
- 9腾讯云服务器端口怎么全打开?_腾讯云怎么开放全部端口
- 10【微信小程序学习】网易云音乐歌曲详情页代码实现_微信小程序网易云音乐代码
深度学习 GAN生成对抗网络-1010格式数据生成简单案例_生成对抗网络损失值变化图
赞
踩
一、前言
本文不花费大量的篇幅来推导数学公式,而是使用一个非常简单的案例来帮助我们了解GAN生成对抗网络。
二、GAN概念
生成对抗网络(Generative Adversarial Networks,GAN)包含生成器(Generator)和鉴别器(Discriminator)两个神经网络。生成器用于生成虚假的数据,经过训练后能够生成以假乱真的数据;鉴别器使用真实数据和虚假数据训练后,能够辨别数据的真假;生成器和鉴别器相互博弈,最终达到鉴别器难以区分生成数据真假的状态。
三、案例实战
我们会创建一个GAN,生成器通过学习训练,来创建符合1010格式规律的值。这个任务比生成图像要简单。通过这个任务,我们可以了解GAN的基本代码框架,观察训练进程,进而帮助我们为接下来生成图像的任务做好准备。
我们先引入依赖库:
import matplotlib.pyplot as plt
import pandas
import torch
import torch.nn as nn
- 1
- 2
- 3
- 4
2.1 构造真实数据源
真实数据源可以是一个返回1010格式数据的函数,如下所示:
def generate_real():
real_data = torch.FloatTensor([1,0,1,0])
return real_data
- 1
- 2
- 3
执行:
generate_real()
- 1
结果:
tensor([1., 0., 1., 0.])
- 1
但是,在实际生活中,数据往往不是那么精准,我们让其有一定随机性:
def generate_real():
real_data = torch.FloatTensor(
[random.uniform(0.8, 1.0),
random.uniform(0.0, 0.2),
random.uniform(0.8, 1.0),
random.uniform(0.0, 0.2)])
return real_data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
random.uniform(0.8, 1.0)产生0.8-1.0之间的随机小数。
执行:
generate_real()
- 1
结果:
tensor([0.9782, 0.0673, 0.8500, 0.1788])
- 1
2.2 构造随机数据
产生4个随机数,可能满足1010格式,也可能不满足,函数如下:
def generate_random(size):
random_data = torch.rand(size)
return random_data
- 1
- 2
- 3
执行:
generate_random(4)
- 1
结果:
tensor([0.4241, 0.0611, 0.7684, 0.2931])
- 1
2.3 构造鉴别器
鉴别器是一个神经网络,我们的目的是训练出一个能区分真实数据与随机噪声数据的鉴别器。下面代码定义了一个非常简单的神经网络:输入层有4个节点,用于接受输入的4个值;隐藏层有3个节点;输出层输出0~1的单个值,表示真或假。
class Discriminator(nn.Module): def __init__(self): # 初始化Pytorch父类 super().__init__() # 定义神经网络层 self.model = nn.Sequential( nn.Linear(4, 3), nn.Sigmoid(), nn.Linear(3, 1), nn.Sigmoid() ) # 创建损失函数,使用均方误差 self.loss_function = nn.MSELoss() # 创建优化器,使用随机梯度下降 self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01) # 训练次数计数器 self.counter = 0 # 训练过程中损失值记录 self.progress = [] # 前向传播函数 def forward(self, inputs): return self.model(inputs) # 训练函数 def train(self, inputs, targets): # 前向传播,计算网络输出 outputs = self.forward(inputs) # 计算损失值 loss = self.loss_function(outputs, targets) # 累加训练次数 self.counter += 1 # 每10次训练记录损失值 if (self.counter % 10 == 0): self.progress.append(loss.item()) # 每10000次输出训练次数 if (self.counter % 10000 == 0): print("counter = ", self.counter) # 梯度清零, 反向传播, 更新权重 self.optimiser.zero_grad() loss.backward() self.optimiser.step() # 绘制损失变化图 def plot_progress(self): df = pandas.DataFrame(self.progress, columns=['loss']) df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
2.4 测试鉴别器
由于还没有创建生成器,所以无法测试能够与其竞争的鉴别器,目前能做的是,检验鉴别器是否能将真实数据与随机数据区分开。
训练
D = Discriminator()
for i in range(10000):
# 真实数据
D.train(generate_real(), torch.FloatTensor([1.0]))
# 随机数据
D.train(generate_random(4), torch.FloatTensor([0.0]))
- 1
- 2
- 3
- 4
- 5
- 6
结果:
counter = 10000
counter = 20000
- 1
- 2
上述代码虽然迭代了10000次,但是在每次迭代中分别对真实数据和随机数据进行了训练,累计训练20000次。
损失值变化
我们来看看训练过程中的损失值变化:
D.plot_progress()
- 1
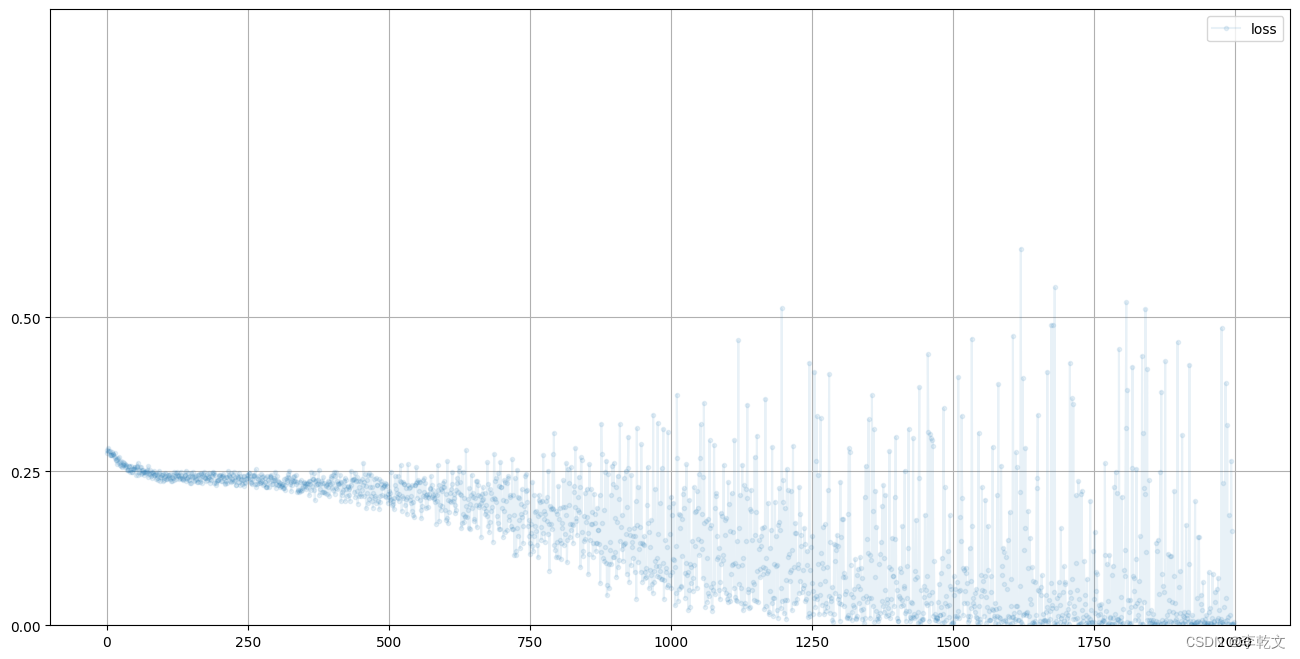
如上图所示,损失值一开始接近0.25,随着训练次数增加,损失值逐渐接近0。
鉴别效果
我们再来测试一下鉴定器的效果,现在分别输入1010格式数据与随机数据,代码和运行结果如下:
print(D.forward(generate_real()).item())
print(D.forward(generate_random(4)).item())
- 1
- 2
结果:
0.8134430050849915
0.05087679252028465
- 1
- 2
得出的结果分别接近1和0,这说明鉴别器能够区分真实数据与随机噪声。
2.5 构造生成器
生成器也是一个神经网络,目的是尽量生成满足1010格式的4个值。为了使生成器与鉴别器不相伯仲地相互竞争与提高,生成器与鉴别器的结构正好相反:输入层只有1个节点;隐藏层有3个节点;输出层有4个节点,输出4个值。
代码如下,注意训练函数稍有不同,引入了鉴别器的损失函数进行反向传播,进而更新生成器权重:
class Generator(nn.Module): def __init__(self): # 初始化Pytorch父类 super().__init__() # 定义神经网络层 self.model = nn.Sequential( nn.Linear(1, 3), nn.Sigmoid(), nn.Linear(3, 4), nn.Sigmoid() ) # 注意这里没有损失函数,在训练时使用鉴别器的损失函数。 # 创建优化器,使用随机梯度下降 self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01) # 训练次数计数器 self.counter = 0 # 训练过程中损失值记录 self.progress = [] # 前向传播函数 def forward(self, inputs): return self.model(inputs) # 训练函数 def train(self, D, inputs, targets): # 前向传播,计算网络输出 g_output = self.forward(inputs) # 将生成器输出,传入鉴别器,输出分类结果 d_output = D.forward(g_output) # 计算鉴别误差 loss = D.loss_function(d_output, targets) # 累加训练次数 self.counter += 1 # 每10次训练记录损失值 if (self.counter % 10 == 0): self.progress.append(loss.item()) # 梯度清零, 反向传播, 更新权重。注意这里是对鉴别器的误差进行反向传播,但只更新生成器的权重 self.optimiser.zero_grad() loss.backward() self.optimiser.step() # 绘制损失变化图 def plot_progress(self): df = pandas.DataFrame(self.progress, columns=['loss']) df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
2.6 检查生成器输出
同样地,我们也可以单独对生成器进行测试,以检查是否正常工作:
G = Generator()
G.forward(torch.FloatTensor([0.5]))
- 1
- 2
结果:
tensor([0.6172, 0.5979, 0.5700, 0.6622], grad_fn=<SigmoidBackward0>)
- 1
可以看到输出了4个值,但不符合1010格式,因为我们还没有对其进行训练。
2.7 训练GAN
训练
先看代码:
D = Discriminator()
G = Generator()
for i in range(10000):
# 用真实样本数据训练鉴别器
D.train(generate_real(), torch.FloatTensor([1.0]))
# 用生成数据训练鉴别器
# 此处训练是为了更新鉴别器权重,不需要更新生成器权重,使用detach()以避免计算生成器中的梯度
D.train(G.forward(torch.FloatTensor([0.5])).detach(), torch.FloatTensor([0.0]))
# 训练生成器,更新生成器权重
G.train(D, torch.FloatTensor([0.5]), torch.FloatTensor([1.0]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在迭代过程中,每次循环都会重复训练GAN的3个步骤:
- 用真实样本数据训练鉴别器,更新鉴别器权重
- 用生成的数据训练鉴别器,更新鉴别器权重。此处不需要更新生成器权重,detach()的作用是将其从计算图中分离出来
- 训练生成器,更新生成器权重
损失值变化
训练完成后,我们来看看鉴别器损失值的变化:
D.plot_progress()
- 1
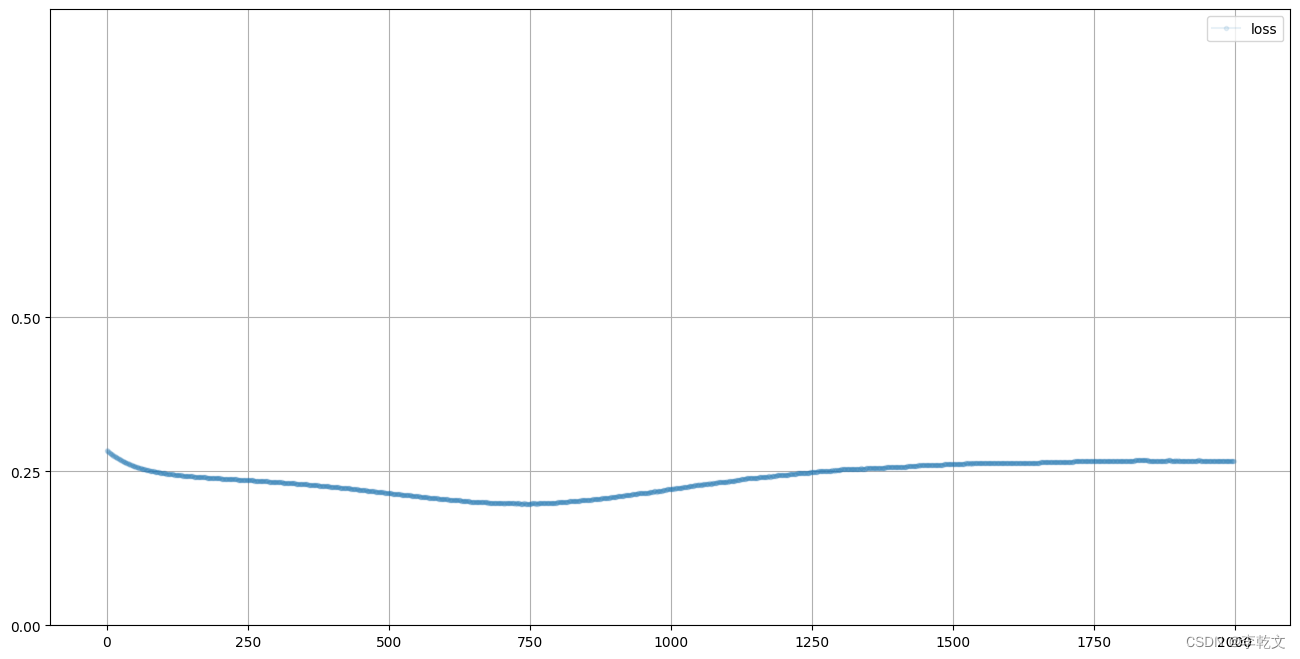
这是一个非常有意思的结果,损失值最终保持在0.25附近。这说明鉴别器无法判断数据是真实的还是伪造的,于是输出0.5,由于我们损失函数使用的是均方误差,所以损失值是0.5的平方,即0.25。
下图是生成器的损失图,与鉴别器损失是互补的:
G.plot_progress()
- 1
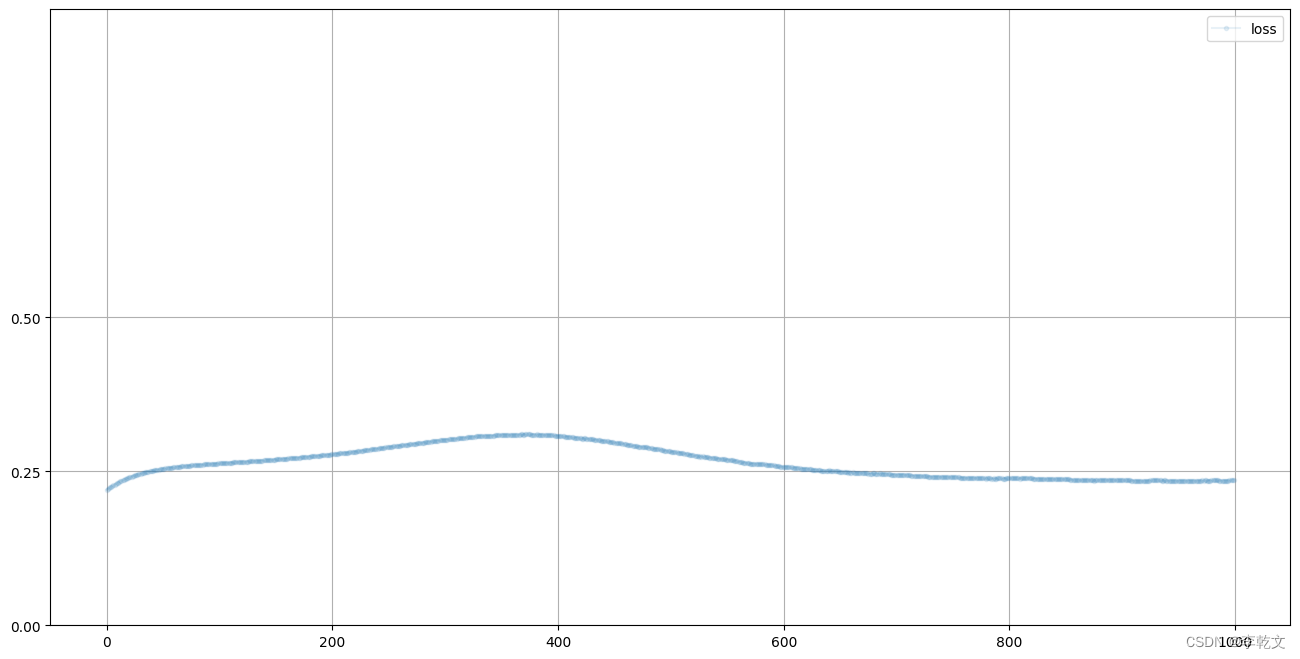
生成数据
现在我们用训练好的生成器来生成数据:
G.forward(torch.FloatTensor([0.5]))
- 1
结果:
tensor([0.9537, 0.0367, 0.9493, 0.0507], grad_fn=<SigmoidBackward0>)
- 1
可以看到生成的数据符合1010格式。效果相当不错!
通过上面的训练,相信你已经熟悉GAN的结构了,后面我们将使用GAN来实现手写数字生成等更加酷炫的任务
- 半数机制集群中半数以上的机器存活,集群可用,所以Zookeeper适合安装奇数台服务器全新集群选举服务器1启动,先投给自己一票,此时不够半数以上,服务器1继续保持跟随者服务器2启动,先投给自己一票,此时服务器1看到服务器2的id比自己大,将... [详细]
赞
踩
- 本文利用BP神经网络对美国波士顿的房价进行预测,并针对BP神经网络存在的易陷入局部极小值,收敛速度慢,网络拓扑结构不稳定等问题,提出运用GA遗传算法对BP神经网络的初始权值和阈值进行优化。分别对传统神经网络和GA_BP进行训练和仿真,结果表... [详细]
赞
踩
- 1.实现的功能窗口的最大化和最大化前大小切换、最小化、关闭窗口、移动、拉伸、缩小。很多时候,为了界面的美观,需要将界面设置为无边框窗口,这就需要重写上述功能来完善窗口。2.具体步骤最大化、最小化、关闭为三个按钮,按钮设置好布局位置,设置QI... [详细]
赞
踩
- 使用InternImage-H训练自己的数据集InternImage训练流程文章目录1.json格式转mask—批量2.划分训练测试集3.修改配置文件1.json格式转mask—批量 我是用ADE20k格式训练的数据,先说一个我踩过的坑,... [详细]
赞
踩
 博文《使用Typora+PicGo+Gitee搭建个人博客图床》详细介绍了如何利用Typora、PicGo和Gitee搭建个人博客的图床服务。文章从安装和配置这三款工具开始,逐步指导读者实现图床的搭建过程。Typora作为Markdown编... [详细]
博文《使用Typora+PicGo+Gitee搭建个人博客图床》详细介绍了如何利用Typora、PicGo和Gitee搭建个人博客的图床服务。文章从安装和配置这三款工具开始,逐步指导读者实现图床的搭建过程。Typora作为Markdown编... [详细]赞
踩
- BP神经网络广泛应用于解决各种问题,是知名度极高的模型之一为了方便初学者快速学习,本文进行深入浅出讲解BP神经网络的基本知识通过本文,可以初步了解BP神经网络的各个核心要素,并弄清BP神经网络是什么。_怎么去学bp网络模型怎么去学bp网络模... [详细]
赞
踩
- 照着视频敲了半天,双向绑定一直不生效,后来发现model:value之间不能有空格,去掉就好了,真的醉了。_小程序中model:value无效小程序中model:value无效照着视频敲了半天,双向绑定一直不生效,后来发现model:val... [详细]
赞
踩
- 各式资料中关于BP神经网络的讲解已经足够全面详尽,故不在此过多赘述。本文重点在于由一个“最简单”的神经网络练习推导其训练过程,和大家一起在练习中一起更好理解神经网络训练过程。..._bp神经网络训练过程bp神经网络训练过程写在前面:各式资料... [详细]
赞
踩
- Spriteskin.LateUpdate占用过高,导致掉帧问题_unityspriteskin.lateupdateunityspriteskin.lateupdateSpriteskin.LateUpdate-UnityAnswers需... [详细]
赞
踩
- 1、BP神经网络1.1神经网络基础神经网络的基本组成单元是神经元。神经元的通用模型如图1所示,其中常用的激活函数有阈值函数、sigmoid函数和双曲正切函数。图1神经元模型神经元的输出为:y=f(∑i=1mwixi)y=f(∑i=1mwix... [详细]
赞
踩
- MeshUnityManual-MeshComponents1Mesh相关组件Meshes网格Mesh是Unity内的一个组件,称为网格组件。3D网格是Unity中最重要的图形元素。在Unity中存在多种组件用于渲染标准网格或者蒙皮网格、拖... [详细]
赞
踩
- Swagger作为一款API文档生成工具,虽然功能已经很完善了,但是还是有些不足的地方。偶然发现knife4j弥补了这些不足,赋予了Swagger更多的功能,今天我们来讲下它的使用方法。knife4j简介knife4j是springfox-... [详细]
赞
踩
- 题目链接给定一系列正整数,请按要求对数字进行分类,并输出以下5个数字:A1=能被5整除的数字中所有偶数的和;A2=将被5除后余1的数字按给出顺序进行交错求和,即计算n1−n2+n3−n4⋯;A3=被5除后余2的数字的个数;A4=被5... [详细]
赞
踩
- article
计算机毕业设计springboot基于Spring的融媒体交互学习平台的设计与实现lm09o9【附源码+数据库+部署+LW】_基于springboot框架的熊猫基本信息展示平台的设计与实现
选题背景:随着互联网和移动设备的普及,融媒体交互学习成为了一种新的学习方式。而基于Spring的融媒体交互学习平台的设计与实现应运而生。该平台利用Spring框架的后端技术,结合多媒体资源和互动功能,提供了一个全新的学习环境,使学习者能够通... [详细]赞
踩
- LSTM通过门控机制使循环神经网络不仅能记忆过去的信息,同时还能选择性地忘记一些不重要的信息而对长期语境等关系进行建模,而GRU基于这样的想法在保留长期序列信息下减少梯度消失问题。本文介绍了GRU门控机制的运算过程,更详细的内容请查看原论文... [详细]
赞
踩
- 看见文献里有使用PCA=∑(PC1+PC2),也有值描述PCA得分的。究竟应该怎么取计算PCA得分。。。。。。。关于PCA的步骤回顾:1,判断主成分的个数2,提取主成分3,主成分旋转4,获取主成分得分。_主成分分析pc1和pc2主成分分析p... [详细]
赞
踩
- 目录文章目录目录TCP的滑动窗口发送方的滑动窗口接收方的滑动窗口TCP的滑动窗口TCP的ACK机制就像两个人面对面聊天,你一句我一句,可见这种方式的缺点是效率比较低的。数据包的往返时间越长,通信的效率就越低。为解决这个问题,TCP引入了窗口... [详细]
赞
踩
- 信号频谱和傅氏变换基本思想:把一个复杂信号分解成许多简单的正弦信号的叠加,这些正弦信号的频率是已知的,相应的振幅和相位则可由原始信号确定。周期信号都可以表示成谐波关系的正弦信号的加权和,非周期信号都可以用正弦信号的加权积分来表示。信号的频率... [详细]
赞
踩
- 深度学习基础知识点包括数据归一化、数据集划分、混淆矩阵、模型文件、权重矩阵初始化、激活函数、模型拟合、卷积操作、池化操作、深度可分离卷积、转置卷积等内容。其中数据归一化是将过大的输入数据进行标准化处理,而转置卷积是上采样操作。深度学习知识点... [详细]
赞
踩
- 文章目录下载安装EasyX基础使用知识EasyX程序示例1.1画一个实心圆1.2画出10条直线1.3画出红蓝交替的直线1.4绘制国际象棋棋盘1.5绘制围棋棋盘1.6反弹球动画1.7无闪烁的反弹球动画1.8小球向右移动动画2.1多球反弹2.2... [详细]
赞
踩
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

