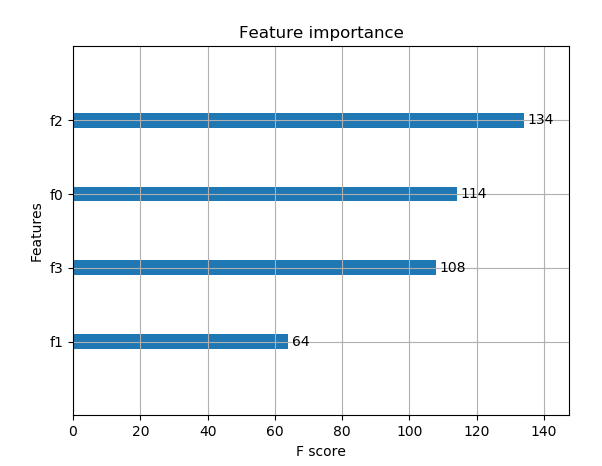
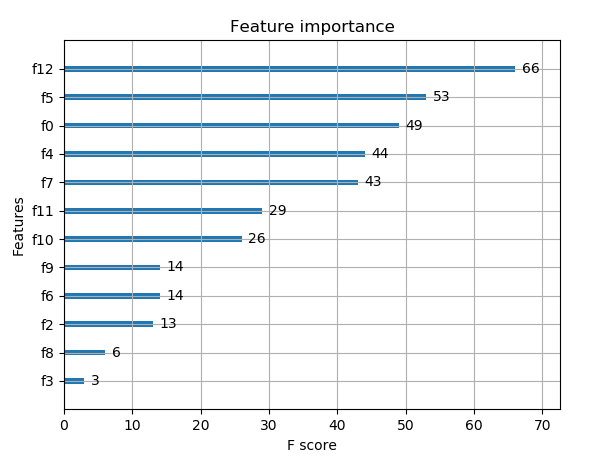
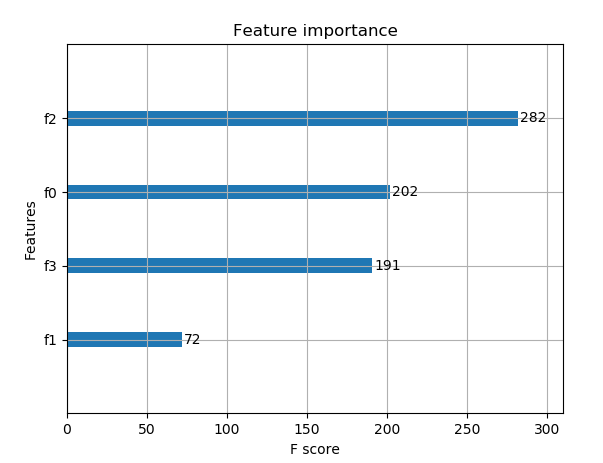
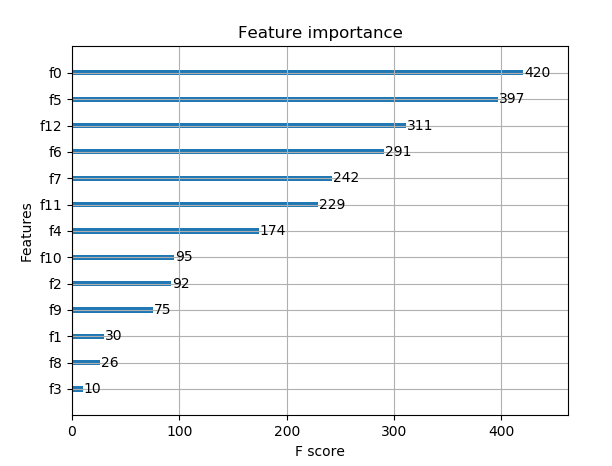
前言
1,Xgboost简介
Xgboost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器。因为Xgboost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。而所用到的树模型则是CART回归树模型。
Xgboost是在GBDT的基础上进行改进,使之更强大,适用于更大范围。
Xgboost一般和sklearn一起使用,但是由于sklearn中没有集成Xgboost,所以才需要单独下载安装。
2,Xgboost的优点
Xgboost算法可以给预测模型带来能力的提升。当我们对其表现有更多了解的时候,我们会发现他有如下优势:
2.1 正则化
实际上,Xgboost是以“正则化提升(regularized boosting)” 技术而闻名。Xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数,每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是Xgboost优于传统GBDT的一个特征
2.2 并行处理
Xgboost工具支持并行。众所周知,Boosting算法是顺序处理的,也是说Boosting不是一种串行的结构吗?怎么并行的?注意Xgboost的并行不是tree粒度的并行。Xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含)。Xgboost的并行式在特征粒度上的,也就是说每一颗树的构造都依赖于前一颗树。
我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),Xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分类时,需要计算每个特征的增益,大大减少计算量。这个block结构也使得并行成为了可能,在进行节点的分裂的时候,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
2.3 灵活性
Xgboost支持用户自定义目标函数和评估函数,只要目标函数二阶可导就行。它对模型增加了一个全新的维度,所以我们的处理不会受到任何限制。
2.4 缺失值处理
对于特征的值有缺失的样本,Xgboost可以自动学习出他的分裂方向。Xgboost内置处理缺失值的规则。用户需要提供一个和其他样本不同的值,然后把它作为一个参数穿进去,以此来作为缺失值的取值。Xgboost在不同节点遇到缺失值时采用不同的处理方法,并且会学习未来遇到缺失值时的处理方法。
2.5 剪枝
Xgboost先从顶到底建立所有可以建立的子树,再从底到顶反向机芯剪枝,比起GBM,这样不容易陷入局部最优解
2.6 内置交叉验证
Xgboost允许在每一轮Boosting迭代中使用交叉验证。因此可以方便的获得最优Boosting迭代次数,而GBM使用网格搜索,只能检测有限个值。
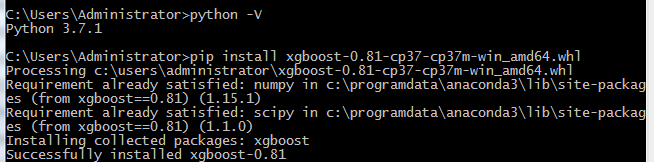
3,Xgboost的离线安装
1,点击此处,下载对应自己Python版本的网址。

2,输入安装的程式:
|
1
|
pip install xgboost-0.81-cp37-cp37m-win_amd64.whl
|
Xgboost模型详解
1,Xgboost能加载的各种数据格式解析
Xgboost可以加载多种数据格式的训练数据:
|
1
2
3
4
5
|
libsvm 格式的文本数据;
Numpy 的二维数组;
XGBoost 的二进制的缓存文件。加载的数据存储在对象 DMatrix 中。
|
下面一一列举:
记载libsvm格式的数据
|
1
|
dtrain1 = xgb.DMatrix(
'train.svm.txt'
)
|
记载二进制的缓存文件
|
1
|
dtrain2 = xgb.DMatrix(
'train.svm.buffer'
)
|
加载numpy的数组
|
1
2
3
|
data = np.random.rand(5,10) # 5行10列数据集
label = np.random.randint(2,size=5) # 二分类目标值
dtrain = xgb.DMatrix(data,label=label) # 组成训练集
|
将scipy.sparse格式的数据转化为Dmatrix格式
|
1
2
|
csr = scipy.sparse.csr_matrix((dat,(row,col)))
dtrain = xgb.DMatrix( csr )
|
将Dmatrix格式的数据保存成Xgboost的二进制格式,在下次加载时可以提高加载速度,使用方法如下:
|
1
2
|
dtrain = xgb.DMatrix(
'train.svm.txt'
)
dtrain.save_binary(
"train.buffer"
)
|
可以使用如下方式处理DMatrix中的缺失值
|
1
|
dtrain = xgb.DMatrix( data, label=label, missing = -999.0)
|
当需要给样本设置权重时,可以用如下方式:
|
1
2
|
w = np.random.rand(5,1)
dtrain = xgb.DMatrix( data, label=label, missing = -999.0, weight=w)
|
2,Xgboost的模型参数
Xgboost使用key-value字典的方式存储参数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# xgboost模型
params
= {
'booster'
:
'gbtree'
,
'objective'
:
'multi:softmax'
, # 多分类问题
'num_class'
:10, # 类别数,与multi softmax并用
'gamma'
:0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1 0.2的样子
'max_depth'
:12, # 构建树的深度,越大越容易过拟合
'lambda'
:2, # 控制模型复杂度的权重值的L2 正则化项参数,参数越大,模型越不容易过拟合
'subsample'
:0.7, # 随机采样训练样本
'colsample_bytree'
:3,# 这个参数默认为1,是每个叶子里面h的和至少是多少
# 对于正负样本不均衡时的0-1分类而言,假设h在0.01附近,min_child_weight为1
#意味着叶子节点中最少需要包含100个样本。这个参数非常影响结果,
# 控制叶子节点中二阶导的和的最小值,该参数值越小,越容易过拟合
'silent'
:0, # 设置成1 则没有运行信息输入,最好是设置成0
'eta'
:0.007, # 如同学习率
'seed'
:1000,
'nthread'
:7, #CPU线程数
#'eval_metric':'auc'
}
|
在运行Xgboost之前,必须设置三种类型成熟:general parameters,booster parameters和task parameters:
通用参数(General Parameters):该参数控制在提升(boosting)过程中使用哪种booster,常用的booster有树模型(tree)和线性模型(linear model)
Booster参数(Booster Parameters):这取决于使用哪种booster
学习目标参数(Task Parameters):控制学习的场景,例如在回归问题中会使用不同的参数控制排序
2.1, 通用参数
- booster [default=gbtree]
- 有两种模型可以选择gbtree和gblinear。gbtree使用基于树的模型进行提升计算,gblinear使用线性模型进行提升计算。
缺省值为gbtree
- 有两种模型可以选择gbtree和gblinear。gbtree使用基于树的模型进行提升计算,gblinear使用线性模型进行提升计算。
- booster [default=gbtree]