
- 1从零学习Linux操作系统 第二十二部分 企业域名解析服务的部署及安全优化
- 2Python实现PDF文件转表格_python plumber table
- 3Git起步-安装与配置_gitforce
- 45G NR Rel16 两步接入/2-step RACH
- 5史上最全的Linux常用命令汇总(超全面!超详细!)收藏这一篇就够了!
- 6Intel RealSense D435i:ROS接口相关配置和启动参数的进一步学习_d435启动画面有线
- 7Android面试常见问题总结_systemui面试
- 8Android音频系统之音频基础_估计知道这个定律的人比较少,它是音频系统中计算声音大小的一个重要依据。从严格
- 9MySQL的batch模式_mysql batch
- 10Tomcat中部署Web应用的四种方式_tomcat配置web项目
【机器学习】随机森林 – Random forest
赞
踩
一、随机森林是什么?
随机森林是一种由 决策树 构成的 集成算法 ,他在很多情况下都能有不错的表现。
要深入理解上面这句话,请阅读我的另外两篇文章:
1. 随机森林是一种集成学习算法
随机森林属于 集成学习 中的 Bagging(Bootstrap AGgregation 的简称) 方法。用图来表示他们之间的关系如下:
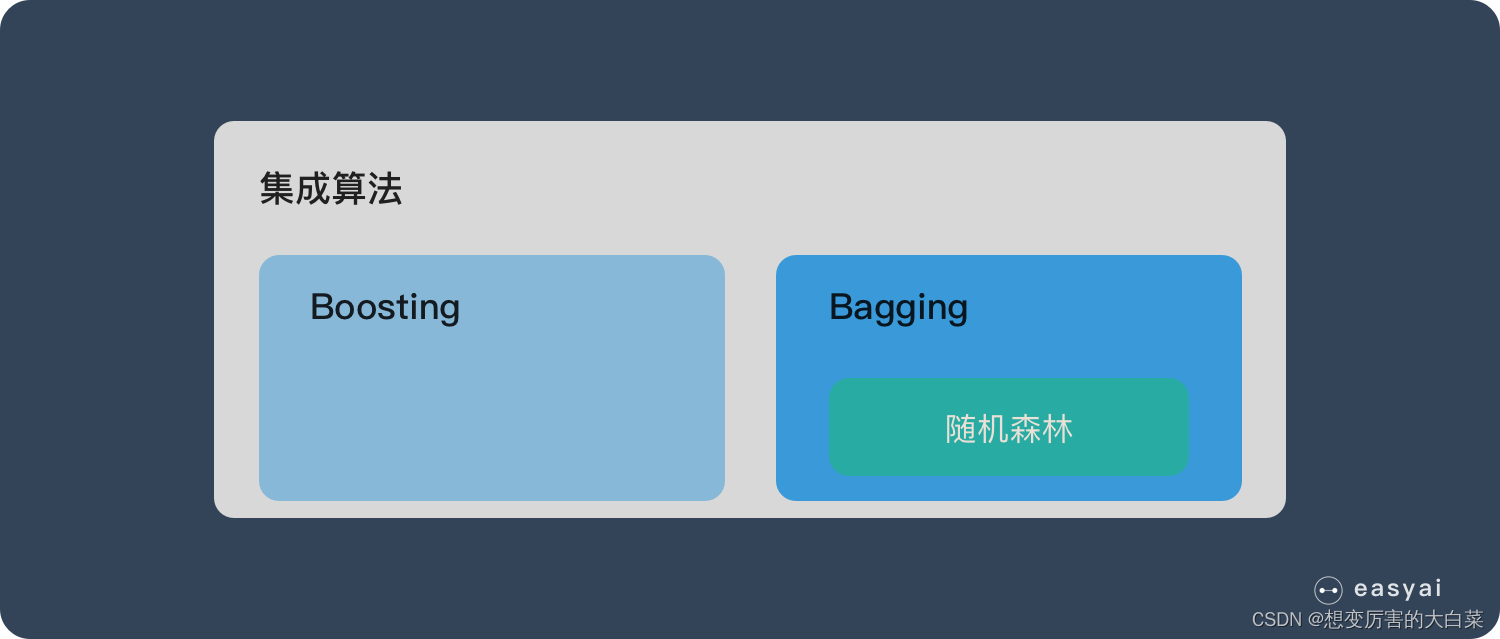
2. 随机森林的基学习器是决策树
决策树:
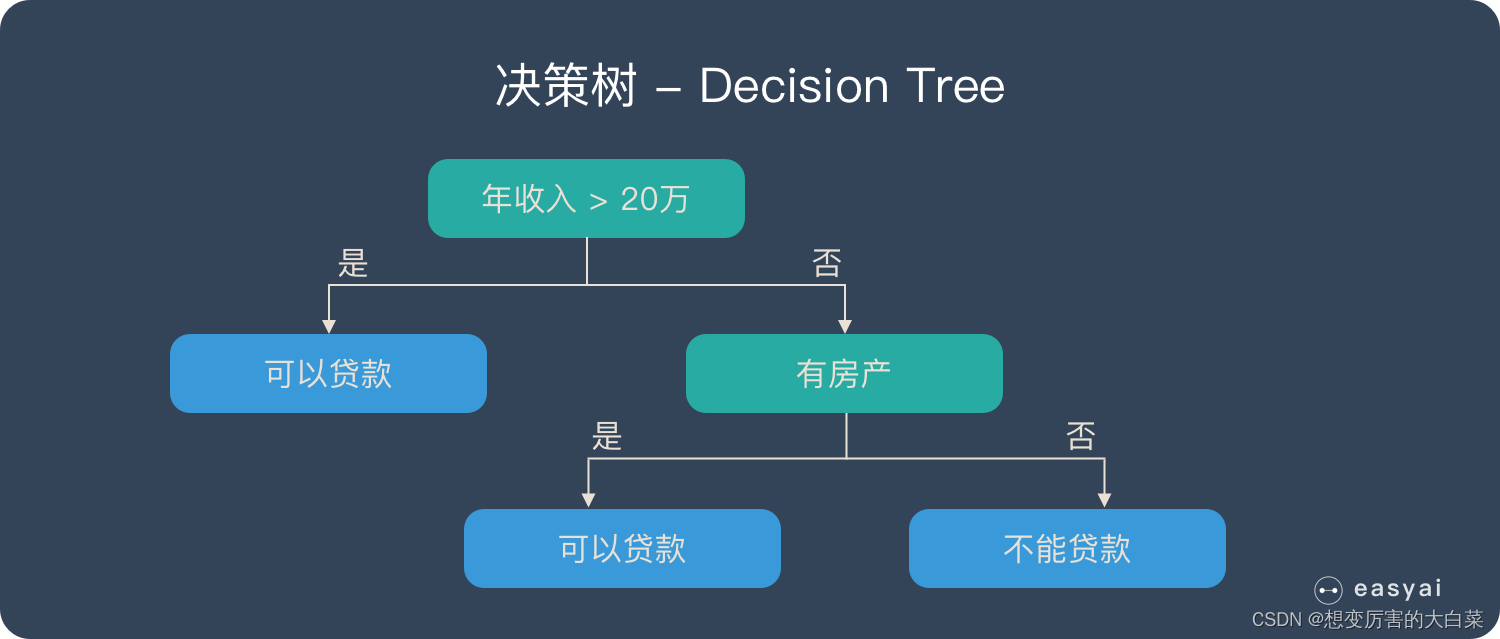
决策树是一种很简单的基于 if-then-else 规则的有监督学习算法,上面的图片可以直观的表达决策树的逻辑。
二、随机森林 – Random Forest | RF
随机森林:
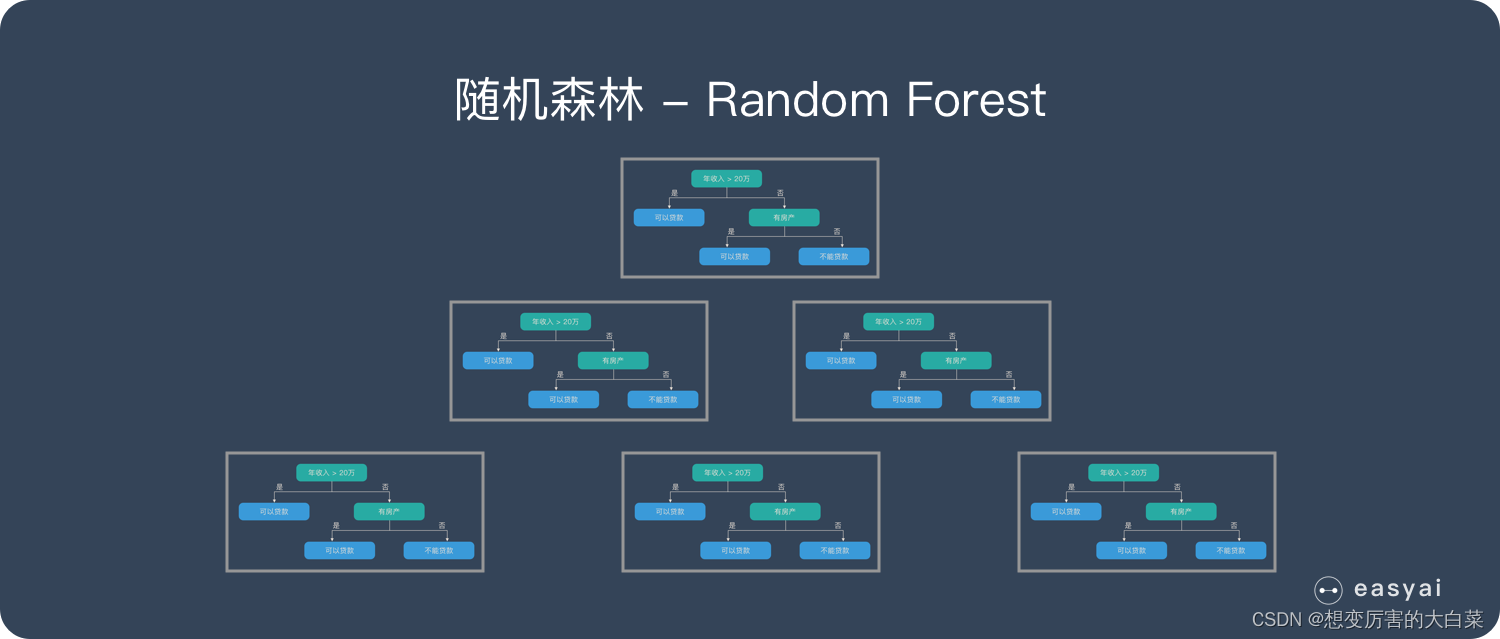
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
三、构造随机森林的 4 个步骤

- 抽取 N 个样本:一个样本容量为 N 的样本,有放回的抽取 N 次,每次抽取 1 个,最终形成了 N 个样本。这选择好了的 N 个样本用来训练一个决策树,作为决策树根节点处的样本。
- 选择 m 个属性:当每个样本有 M 个属性时,在决策树的每个节点需要分裂时,随机从这 M 个属性中选取出 m 个属性,满足条件 m << M 。然后从这 m 个属性中采用某种策略(比如说信息增益)来选择 1 个属性作为该节点的分裂属性。
- 构造决策树:决策树形成过程中每个节点都要按照步骤 2 来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
- 形成森林:按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
四、随机森林的优缺点
1. 优点
- 它可以处理很高维度(特征很多)的数据,并且不用降维,无需做特征选择
- 它可以判断特征的重要程度
- 可以判断出不同特征之间的相互影响
- 不容易过拟合
- 训练速度比较快,容易做成并行方法
- 实现起来比较简单
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
2. 缺点
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
五、随机森林 4 种实现方法对比测试
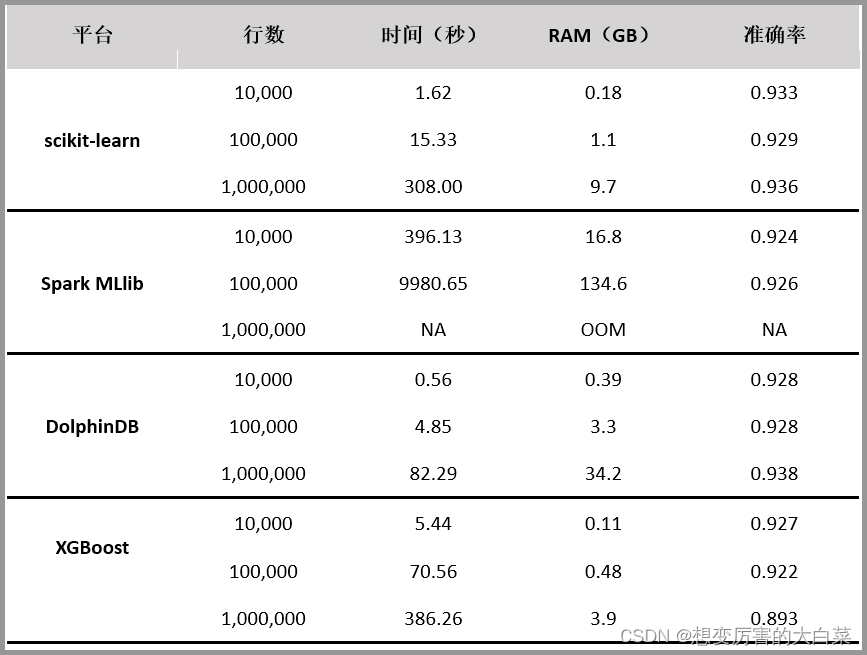
随机森林是常用的机器学习算法,既可以用于分类问题,也可用于回归问题。本文对 scikit-learn、Spark MLlib、DolphinDB、XGBoost 四个平台的随机森林算法实现进行对比测试。评价指标包括内存占用、运行速度和分类准确性。
测试结果如下:
六、随机森林的 4 个应用方向

随机森林可以在很多地方使用:
- 对离散值的分类
- 对连续值的回归
- 无监督学习聚类
- 异常点检测
参考链接
- Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。_importturtlefromrandomimportrandran... [详细]
赞
踩
- 避免Random实例被多线程使用,虽然共享该实例是线程安全的,但会因竞争同一seed导致的性能下降,JDK7之后,可以使用ThreadLocalRandom来获取随机数解释一下竞争同一个seed导致性能下降的原因,比如,看一下Random类... [详细]
赞
踩
- Random(一)高并发问题,ThreadLocalRandom源码解析_threadlocalrandomthreadlocalrandom目录1.什么是伪随机数?2.Random2.1使用示例2.2什么种子重复,随机数会重复?2.3ne... [详细]
赞
踩
- 不是吧,阿sir_newrandom()性能消耗newrandom()性能消耗点赞再看,养成习惯,微信搜索【三太子敖丙】关注这个好像有点东西的傻瓜本文GitHubhttps://github.com/JavaFamily已收录,有一线大厂面... [详细]
赞
踩
- Random类介绍Random类一个用于产生伪随机数字的类。这里的伪随机表示有随机性但是可以基于算法模拟出随机规律。Random类的构造方式有两种。Randomr=newRandom()。会以当前系统时间作为默认种子构建一个随机序列Rand... [详细]
赞
踩
- 利用Random类来产生5个20~50之间的随机整数。提示:Random.nextInt(方法的作用是生成一个随机的int值,该值介于[0,n)的区间,也就是0到n之间的随机int值,包含0而不包含n。方法1:intnextInt(intn... [详细]
赞
踩
- 结果:给Random对象设置了随机数种子可以使得这个对象多次运行时产生的随机数固定,但是同一对象一次运行中多次调用方法还是随机的。该类的实例用于生成伪随机数的流。该类使用48位种子,其使用线性同余公式进行修改。,并且对每个实例进行相同的方法... [详细]
赞
踩
- Random高并发下的缺点大量CAS导致CPU飙高Randomrandom=newRandom();System.out.println(random.nextInt(100));一、奇怪的命名random.nextInt()奇怪的命名,获... [详细]
赞
踩
- 前言随机数我们应该不陌生,业务中我们用它来生成验证码,或者对重复性要求不高的id,甚至我们还用它在年会上搞抽奖。今天我们来探讨一下这个东西。如果使用不当会引发一系列问题。java中的随机数我们需要在Java中随机生成一个数字。java开发中... [详细]
赞
踩
- article
Java生成随机数Math.random()和new Random().nextInt(),new Random().nextDouble()效率问题_new random().nextint 优化
一般都使用Math.random()*100来生成随机整数,最近通过静态代码缺陷检查工具发现了一种新的方式--newRandom().nextInt();据网上资料说,使用newRandom().nextInt()生成的随机数效率高于后者,... [详细]赞
踩
- c#Random快速连续产生相同随机数的解决方案Random类是一个产生伪随机数字的类,它的构造函数有两种,一个是直接NewRandom(),另外一个是NewRandom(Int32),前者是根据触发那刻的系统时间做为种子,来产生一个随机数... [详细]
赞
踩
- 文章目录1、定义2、形式3、优缺点4、使用场景5、扩展小结1、定义单例模式(SingletonPattern):确保某一个类只有一个实例,自行实例化并向整个系统提供这个实例。2、形式单例模式分为懒汉式和饿汉式两种,形式如下所述。饿汉式通用类... [详细]
赞
踩
- 一般都使用Math.random()*100来生成随机整数,最近通过静态代码缺陷检查工具发现了一种新的方式–newRandom().nextInt();据网上资料说,使用newRandom().nextInt(100)生成的随机数效率高于后... [详细]
赞
踩
- Randomrand=newRandom();rand.nextInt();看看bai这样得出的结果du是什么:packagetest;publicclassRandom{publicRandom(){}publicstaticvoidma... [详细]
赞
踩
- 本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现),理论与实践相结合,如GCN、GAT、GraphSAGE等经典图网络,每一个代码实例都附带有完整的代码。_torch_geometric.nnsam... [详细]
赞
踩
- 数据分析中,数据的获取是第一步,numpy.random模块提供了非常全的自动产生数据API,是学习数据分析的第一步。总体来说,numpy.random模块分为四个部分,对应四种功能:1.简单随机数:产生简单的随机数据,可以是任何维度2.排... [详细]
赞
踩
- 机器学习算法系列(十八)-随机森林算法(RandomForestAlgorithm)_随机森林算法流程图随机森林算法流程图阅读本文需要的背景知识点:决策树学习算法、一丢丢编程知识最近笔者做了一个基于人工智能实现音乐转谱和人声分离功能的在线应... [详细]
赞
踩
- 先修知识:决策树。可以看我之前写的文章https://blog.csdn.net/weixin_41332009/article/details/112276531 集成学习。也可以看之前写的文章https://blog.csdn.net/... [详细]
赞
踩
- 随机森林是一种Bagging(BootstrapAggregating)方法,它通过对训练数据进行有放回的随机抽样(bootstrap抽样)构建多个决策树,并且在每个决策树的节点上使用随机特征子集来进行分裂。类被用来创建随机森林回归模型,并... [详细]
赞
踩
- 使用随机森林(RandomForest)进行特征筛选并可视化随机森林可以理解为Cart树森林,它是由多个Cart树分类器构成的集成学习模式。其中每个Cart树可以理解为一个议员,它从样本集里面随机有放回的抽取一部分进行训练,这样,多个树分类... [详细]
赞
踩

