
- 1python语言:烟花效果实现
- 2云计算赛项-私有云Ansible服务部署_使用赛项提供的openstack 私有云平台,创建2台系统为centos7.9 的云主机,其中一台
- 3TCTF 1linephp_0ctf 2021 1linephp
- 4【目标检测】Faster R-CNN原理详解_faster r-cnn目标检测算法原理
- 5微软、阿里抢占开源一线,JavaScript、Python 备受热捧,GitHub 2020 数字洞察报告揭晓!...
- 6sublime text3安装并配置node.js环境_sublime text3安装node.js
- 7nnU-Net论文笔记
- 8图像处理中傅里叶变换以及频率域图像增强详解_傅里叶光学实验图像边缘增强的原因
- 9docker-compose.yml文件配置详解_yml文件 restart
- 10LWN:git evolve - 跟踪一个改动自己的历史!
使用ninja包在pychon中编译c++中遇到的一些问题_nvcc fatal : unsupported gpu architecture 'compute
赞
踩
本篇博客只是做个记录,如果可以帮助到您,自然是最好。
一、配置和需求
服务器配置:
系统:ubuntu22.04
显卡:4090(24G)
cuda:11.8
pytorch版本:2.0
tensorflow版本:2.12
python:3.10
个人pc配置:
系统:win11
显卡:3060
需求:在pc的pycharm上使用ssh远程连接服务器。
心得:远程连接一般不会出太大问题,但是涉及到了在pycharm中编译c++,就出现了很多问题,一些问题,在网上并没有找到答案,是自己机缘巧合解决的,因此特意写个博客,希望可以帮助更多的人,因为解决这些问题,我做在电脑面前一整天,翻遍各个网站,最后快要放弃的两分钟,解决了。
重要一点:这个服务器上的anaconda3环境是共享的,服务器上的每个用户都可以使用,我只是其中一个,所以后面涉及到给重装cuda的操作,一律放弃。
问题一、
使用pycharm远程连接服务器的时,出现了报错,我的解决问题之路开始了。
报错如下:
- Couldn't refresh skeletons for remote interpreter
- failed to run generator3/__main__.py for sftp://xhangxin@192.168.5.22:22/usr/local/anaconda3/envs/score/bin/python, exit code 1, stderr:
- -----
- Failed to process 'torchaudio.lib._torchaudio_ffmpeg' while nothing yet: [Errno 13] Permission denied: '/usr/local/anaconda3/envs/score/lib/python3.10/site-packages/torchaudio/lib/_torchaudio_ffmpeg.so'
- Traceback (most recent call last):
- File "/home/lihaiyuan/.pycharm_helpers/generator3/__main__.py", line 216, in <module>
- main()
- File "/home/lihaiyuan/.pycharm_helpers/generator3/__main__.py", line 188, in main
- generator.discover_and_process_all_modules(name_pattern=args.name_pattern,
- File "/home/lihaiyuan/.pycharm_helpers/generator3/core.py", line 440, in discover_and_process_all_modules
- self.process_module(mod.qname, mod.path)
- File "/home/lihaiyuan/.pycharm_helpers/generator3/core.py", line 514, in process_module
- status = self.reuse_or_generate_skeleton(mod_name, mod_path, sdk_skeleton_state)
解决办法:
查了很多资料,也做了很多尝试,发现下面这种解决办法是可以的
直接删除自己账户下的“.pycharm_helper”这个文件夹。这个文件夹在home路径下,但是它是隐藏的,你如果不放心直接删除会有问题,你可以把它先拷到自己u盘里,在删除。
注:我看网上有人说是python版本的问题,反正对我没用。
问题二、
因为我已经解决这个问题,当时错误信息没保存,但大概是这个错误信息
错误信息:
subprocess.CalledProcessError: Command ‘[‘ninja‘, ‘-v‘]‘ returned non-zero exit status 1解决办法:
首先确保你已经安装了ninja这个包,如果没有安装,可以使用下面命令安装
pip install ninja -i https://pypi.tuna.tsinghua.edu.cn/simple如果已经安装好了,可以使用ninja --version查看版本

上面报错的信息大概就是说,使用“ninja -v”查看不了你的版本
所有找到报错信息的那个文件(需要是服务器上的源文件) 好像是cpp_extension.py这个文件
把[‘ninja‘, ‘-v‘]改成[‘ninja‘, ‘--version‘]。
注:如果你可以使用“ninja -v”这个命令查看到你安装的版本,这样做大概率解决不了你的问题,请自寻他法。如果你可以使用“ninja -version”,这是一个‘-’,查看版本,那你就改成这个。
网上很多人说要禁用ninja,反正我是没找到那个文件,还有人说,我这种办法不管用,但是这个确实解决了我的问题。
问题三、
解决这个问题花费了我大部分的时间
问题如下:
- nvcc fatal : Unsupported gpu architecture 'compute_89'
- ninja: build stopped: subcommand failed.
这个89就是指4090的算力,需要和cuda版本匹配。cuda支持的最大算力,要大于等于89
我在网上看到的降低算力,也查了cuda11.8支持的算力,都没解决我的问题。
还有人说解决办法是降低pytorch的版本到1.5之下等等。我开头也说了服务器上是共享环境,我不能降低pytorch版本,或者更改cuda版本,这样万一出错,让别人也用不了,就更麻烦了。
解决办法如下:
/home/xx/.cache/torch_extensions/py310_cu118/fused/
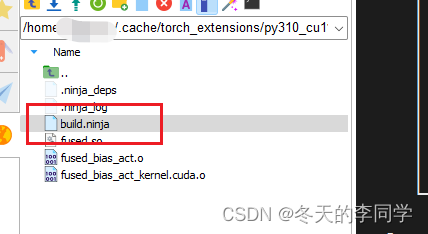
找到上面路径下的build.ninja这个文件,这个文件就是编译ninja的。上面的路径,你们的不一定是这个,红色的xx代表用户名,每个人的应该不一样,自行更改。
双击打开build.ninja这个文件,

将89改为86,你们的不一定是这个,89代表当前机器的算力,86代表你的cuda支持的算力,这也是一种变相的降低算力吧!
然后进入这个build.ninja的目录下,输入ninja重新编译,这样就好了。
这个方法不一定对你们有用,是我在做出无数次尝试后发现的。
还有一个问题就是,如果说你缺少了fused.so这种文件,你就到这个文件所在的目录,去输入ninja,重新编译一下就好了。
问题4
错误如下:
RuntimeError: Ninja is required to load C++ extensions就是说找不到Ninja这个包,但是明明你已经安装了。
这时候去服务器上输入 which ninja,找到你的包在那

然后 ,添加环境变量。
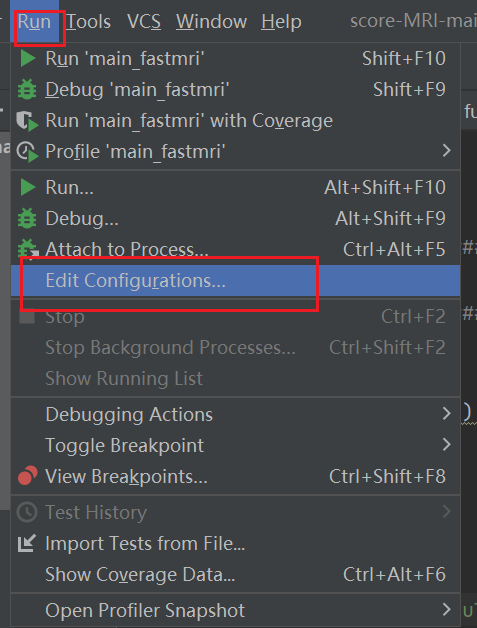
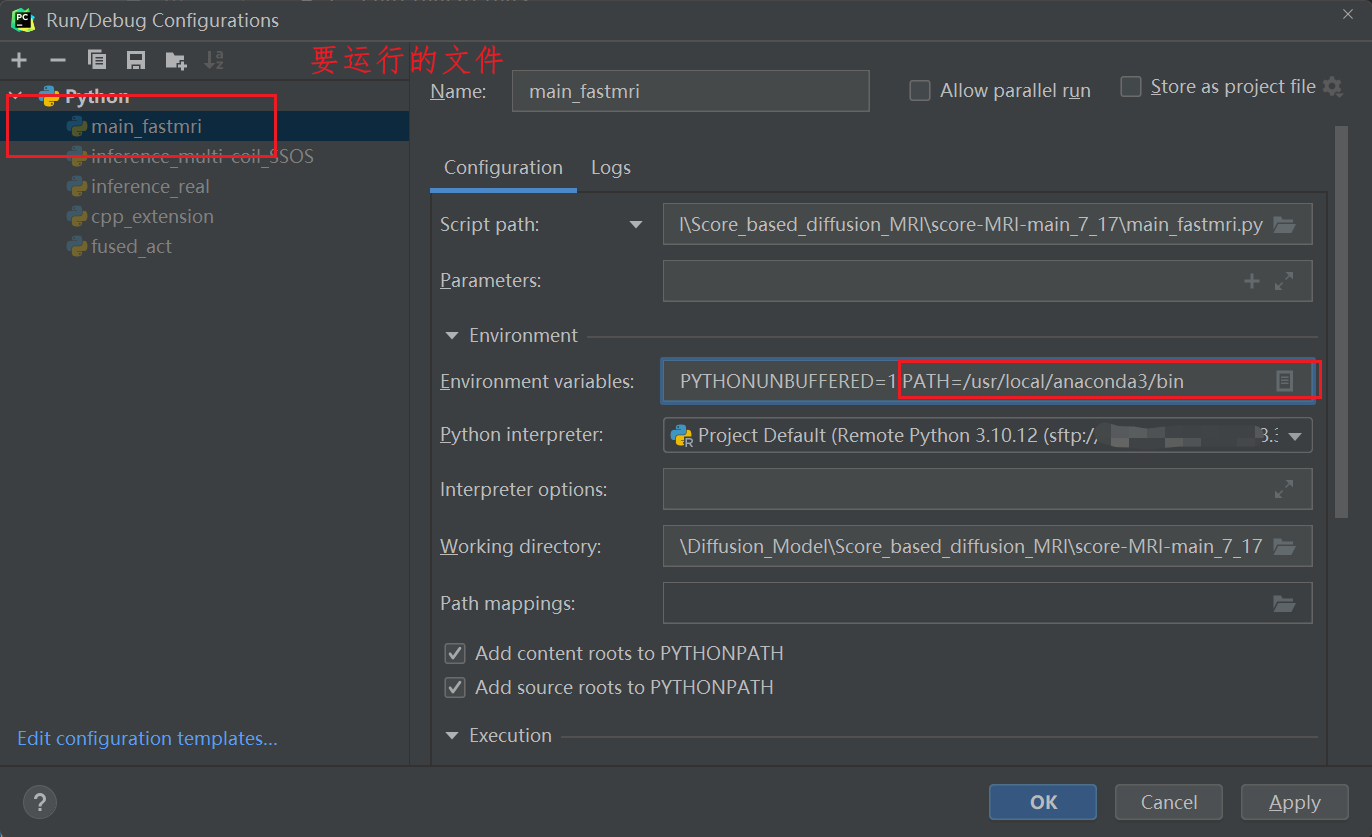
就可以了。
希望以上的内容对看到的读者,有所帮助。
- Djangoninja内置了一些常用异常类。2.覆写异常类可以覆写内置异常类的handler,改变返回结果的内容。3.自定义异常类_djangoninja异常处理djangoninja异常处理1.直接抛内置异常Djangoninja内置了一... [详细]
赞
踩
- article
【AI实战】llama.cpp量化cuBLAS编译;nvcc fatal:Value ‘native‘ is not defined for option ‘gpu-architecture‘_nvcc fatal : value 'native' is not defined for opt
llama.cpp量化cuBLAS编译;nvccfatal:Value'native'isnotdefinedforoption'gpu-architecture'_nvccfatal:value'native'isnotdefinedfo... [详细]赞
踩
- article
【编译Debug】xxx/torch/csrc/python_headers.h:10:10: fatal error: Python.h: No such file or directory_编译报错torch/include/torch/csrc/python_headers.h:11:2
fatalerror:Python.h:Nosuchfileordirectory_编译报错torch/include/torch/csrc/python_headers.h:11:20:致命错误:python.h:编译报错torch/in... [详细]赞
踩
- 1.11版本后,Pytorch中的THC/THC命名空间已失效,apex也已将其删除,但是其中的函数已移至ATen命名空间。THCudaCheck函数->AT_CUDA_CHECK。_thc/thc.h:nosuchfileordirect... [详细]
赞
踩
- 如果编译出现fatalerror:THC/THC.h:Nosuchfileordirectory错误。方法一:老老实实运行储存库提供的。方法二:全局搜索并删除每一行。然后再编译就能通过了。之后的某个版本删除了。_fatalerror:thc... [详细]
赞
踩
- article
报错解决:Fatal error: ‘THC/THC.h’: No such file or directory_fatal error: thc/thc.h: no such file or directory
报错解决:fatalerror:'THC/THC.h':Nosuchfileordirectory_fatalerror:thc/thc.h:nosuchfileordirectoryfatalerror:thc/thc.h:nosuchf... [详细]赞
踩
- article
fatal error: THC/THC.h: No such file or directory_/cuda/vision.h:3:10: fatal error: thc/thc.h: 没有那个文
1.11版本后,Pytorch中的THC/THC命名空间已失效,apex也已将其删除,但是其中的函数已移至ATen命名空间。可以检查尝试构建的库中使用了哪些TH(C)方法,并将它们移至新的ATen调用。通常函数名称是相同的,命名空间只是移动... [详细]赞
踩
- article
成功
成功赞
踩
- 原因是打包机器的的architecture(amd64)和安装的机器architecture(arm64)不同所致。解决方案是:打包的时候,指定architecture。其中package是要打包的目录。dpkg安装deb的时候报错,_pa... [详细]
赞
踩
- article
git 报错 fatal: cannot create directory at ‘src/router‘: Permission denied_fatal: cannot make .repo directory: permission den
git报错fatal:cannotcreatedirectoryat‘src/router’:Permissiondenied我在做着pad项目时切换了git分支出现了这个报错,原本在A分支,切换到B分支之后,切换不回A分支>gitchec... [详细]赞
踩
- UserWarning:AttemptedtouseninjaastheBuildExtensionSetuptoolsDeprecationWarning:setup.pyinstallisdeprecated.Usebuildandpi... [详细]
赞
踩
 mac电脑安装虚拟机教程_theinstallerhasdetectedanunsupportedarchitecture.virtualboxonlyrunstheinstallerhasdetectedanunsupportedarch... [详细]
mac电脑安装虚拟机教程_theinstallerhasdetectedanunsupportedarchitecture.virtualboxonlyrunstheinstallerhasdetectedanunsupportedarch... [详细]赞
踩
- article
解决问题使用nvcc fatal : Unsupported gpu architecture ‘compute_75‘_nvcc fatal : unsupported gpu architecture 'compute
如果发现当前的CUDA版本不支持你的GPU架构,那么你需要更新CUDA到一个支持你的GPU架构的版本。首先,你需要卸载当前的CUDA版本。不同版本的CUDA支持不同的GPU架构,如果GPU架构超出了CUDA版本的支持范围,就会出现这个错误。... [详细]赞
踩
- 在cuda安装成功,配置好cudnn的条件下,编译CaffeGPU时生成工程时会报nvccfatal:Unsupportedgpuarchitecture'compute_**'错误,解决办法两步:1、.修改nvcc.hpp文件,注释最后三... [详细]
赞
踩

