
- 1AI大模型在自然语言处理中的应用:性能表现和未来趋势
- 2tcpdump使用详解_source or destination address
- 3使用AsyncTask+HttpClient_android asynctask+httpclient
- 43dsmax软件和maya软件各自的优劣势是什么?_max和maya的优缺点
- 5径向基函数神经网络_神经网络(1)
- 6若依框架去若依化,如果去除若依元素?
- 7Unity3DVR开发—— XRInteractionToolkit(PicoNeo3、Oculus quest2)_pico neo 3开发教程
- 8PostgreSQL的安装、配置与使用指南_postgresql安装
- 9解决git pull时error: cannot lock ref 问题
- 10SQL语句大全,所有的SQL都在这里
B树、B+树、AVL树、红黑树_b+树 红黑树 和avl
赞
踩
binary search tree,中文翻译为二叉搜索树、二叉查找树或者二叉排序树。简称为BST
B树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
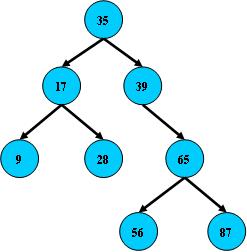
B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入
右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
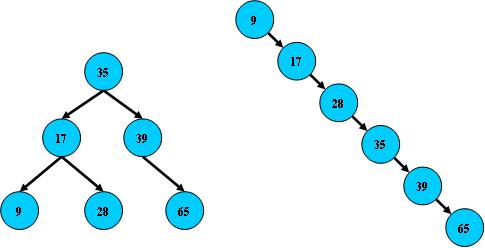
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构
(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
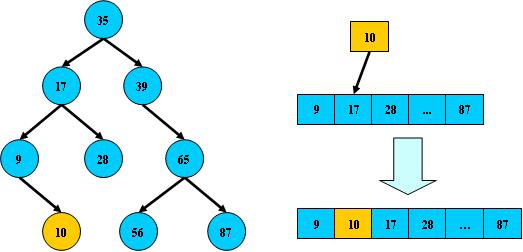
但B树在经过多次插入与删除后,有可能导致不同的结构:
右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的
树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就
是所谓的“平衡”问题;
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树
结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的
策略;
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
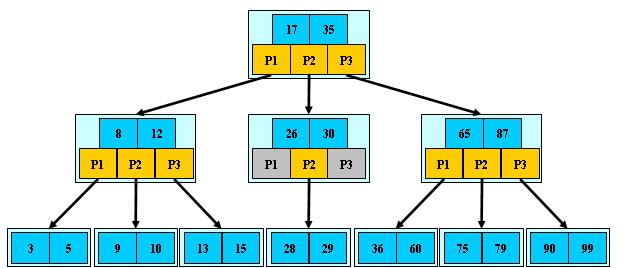
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果
命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为
空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少
利用率,其最底搜索性能为:
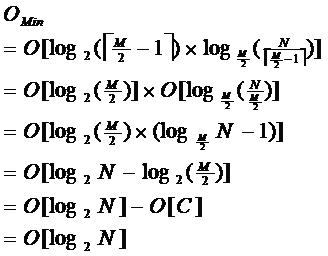
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占
M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
AVL树
AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为一,所以它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下都是O(log n)。
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
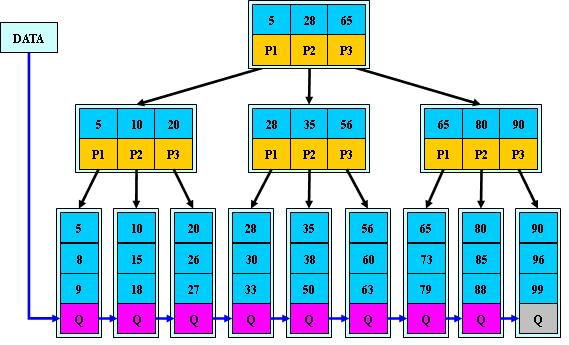
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好
是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
(关键字)数据的数据层;
4.更适合文件索引系统;
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
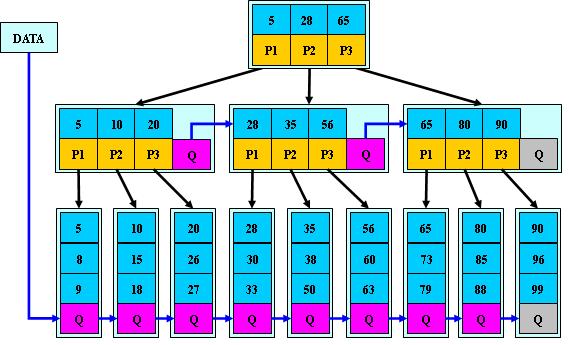
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3
(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据
复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父
结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分
数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字
(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之
间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于
走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键
字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点
中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率
从1/2提高到2/3;
红黑树与AVL(自平衡二叉查找树)树
《算法导论》关于红黑树的定义:
正如在CLRS中定义的那样(CLRS指的是就是算法导论这本书《Introduction to Algorithms》,CLRS是该书作者Cormen, Leiserson, Rivest and Stein的首字母缩写),一棵红黑树是指一棵满足下述性质的二叉搜索树(BST, binary search tree): 1. 每个结点或者为黑色或者为红色。 2. 根结点为黑色。 3. 每个叶结点(实际上就是NULL指针)都是黑色的。 4. 如果一个结点是红色的,那么它的两个子节点都是黑色的(也就是说,不能有两个相邻的红色结点)。 5. 对于每个结点,从该结点到其所有子孙叶结点的路径中所包含的黑色结点数量必须相同。
数据项只能存储在内部结点中(internal node)。我们所指的"叶结点"在其父结点中可能仅仅用一个NULL指针表示,但是将它也看作一个实际的结点有助于描述红黑树的插入与删除算法,叶结点一律为黑色。 定义详解: 根据性质 5:红黑树从根节点到每个叶子节点的路径都包含相同数量的黑色节点,因此从根节点到叶子节点的路径中包含的黑色节点数被称为树的“黑色高度(black-height)”。 性质 4 则保证了从根节点到叶子节点的最长路径的长度不会超过任何其他路径的两倍。假如有一棵黑色高度为 3 的红黑树:从根节点到叶节点的最短路径长度是 2,该路径上全是黑色节点(黑节点 – 黑节点 – 黑节点)。最长路径也只可能为 4,在每个黑色节点之间插入一个红色节点(黑节点 – 红节点 – 黑节点 – 红节点 – 黑节点),性质 4 保证绝不可能插入更多的红色节点。由此可见,红黑树中最长路径就是一条红黑交替的路径。 根据定义我们做如下练习: -不符合定义的一颗非红黑树:  红黑树的这5个性质中,第3点是比较难理解的,但它却非常有必要。我们看图1中的左边这张图,如果不使用黑哨兵,它完全满足红黑树性质,结点50到两个叶结点8和叶结点82路径上的黑色结点数都为2个。但如果加入黑哨兵后(如图1右图中的小黑圆点),叶结点的个数变为8个黑哨兵,根结点50到这8个叶结点路径上的黑高度就不一样了,所以它并不是一棵红黑树。 -两颗正确的红黑树:
红黑树的这5个性质中,第3点是比较难理解的,但它却非常有必要。我们看图1中的左边这张图,如果不使用黑哨兵,它完全满足红黑树性质,结点50到两个叶结点8和叶结点82路径上的黑色结点数都为2个。但如果加入黑哨兵后(如图1右图中的小黑圆点),叶结点的个数变为8个黑哨兵,根结点50到这8个叶结点路径上的黑高度就不一样了,所以它并不是一棵红黑树。 -两颗正确的红黑树: 
 定理:
定理:
一棵拥有n个内部结点的红黑树的树高h<=2log(n+1)
由此我们可以得出结论:对于给定的黑色高度为 N 的红黑树,从根到叶子节点的最短路径长度为 N-1,最长路径长度为 2 * (N-1)。 提示:排序二叉树的深度直接影响了检索的性能,正如前面指出,当插入节点本身就是由小到大排列时,排序二叉树将变成一个链表,这种排序二叉树的检索性能最低:N 个节点的二叉树深度就是 N-1。 红黑树通过上面这种限制来保证它大致是平衡的——因为红黑树的高度不会无限增高,这样保证红黑树在最坏情况下都是高效的,不会出现普通排序二叉树的情况。 由于红黑树只是一个特殊的排序二叉树,因此对红黑树上的只读操作与普通排序二叉树上的只读操作完全相同,只是红黑树保持了大致平衡,因此检索性能比排序二叉树要好很多。 但在红黑树上进行插入操作和删除操作会导致树不再符合红黑树的特征,因此插入操作和删除操作都需要进行一定的维护,以保证插入节点、删除节点后的树依然是红黑树。
3 红黑树和AVL树的比较
一棵AVL树满足以下的条件:1>它的左子树和右子树都是AVL树2>左子树和右子树的高度差不能超过1
1>一棵n个结点的AVL树的其高度保持在0(log2(n)),不会超过3/2log2(n+1)2>一棵n个结点的AVL树的平均搜索长度保持在0(log2(n)).3>一棵n个结点的AVL树删除一个结点做平衡化旋转所需要的时间为0(log2(n)).


