
- 1实战案例:场景测试之ATM机取款业务测试_如何制作atm自动取款机基本流和备选流
- 2【2024最新华为OD-C卷试题汇总】URL拼接 (100分) - 三语言AC题解(Python/Java/Cpp)
- 3计算机毕业设计Python+uniapp校园跑腿小程序(小程序+源码+LW)_基于uniapp的校园跑腿小程序
- 4JVM面试
- 5Mac 安装 LaTeX(MacTeX)_maclatex安装
- 62024年大数据最全Hadoop大数据集群搭建(超详细)_hadoop集群搭建,快速从入门到精通_hadoop集群搭建完整教程
- 7centos 7.x 升级python2.7 到python3.9_centos7 python2.7 升级 python3.9
- 8央行数字货币DCEP首个应用场景落地 新支付风口领域已现
- 9ngnix转发S3预签名地址_nginx s3 presigned url "+
- 10MySQL中的lower_case_tables_names_怎么关闭lower case table names
论文阅读:RHO-1:Not All Tokens Are What You Need 选择你需要的 Tokens 参与训练_rho-1: not all tokens are what you need
赞
踩
论文链接:https://arxiv.org/abs/2404.07965
以往的语言模型预训练方法对所有训练 token 统一采用 next-token 预测损失。作者认为“并非语料库中的所有 token 对语言模型训练都同样重要”,这是对这一规范的挑战。作者的初步分析深入研究了语言模型的 token 级训练动态,揭示了不同 token 的不同损失模式。利用这些见解,推出了一种名为 RHO-1 的新语言模型。与学习预测语料库中 next-token 的传统 LM 不同,RHO-1 采用了选择性语言建模 (SLM),即有选择地对符合预期分布的有用 token 进行训练。这种方法包括使用参考模型对预训练 token 进行评分,然后对超额损失较高的 token 进行有针对性损失的语言模型训练。
在 15B OpenWebMath 语料库上进行持续预训练时,RHO-1 在 9 项数学任务中获得了高达 30% 的 few-shot 准确率绝对提升。经过微调后,RHO-1-1B 和 7B 在 MATH 数据集上分别取得了 40.6% 和 51.8% 的一流结果——仅用 3% 的预训练 token 就达到了 DeepSeekMath 的水平。此外,在对 80B 一般 token 进行预训练时,RHO-1 在 15 个不同任务中实现了 6.8% 的平均提升,提高了语言模型预训练的效率和性能。
OpenWebMath 是一个数据集,包含互联网上大部分高质量的数学文本。该数据集是从 Common Crawl 上超过 200B 的 HTML 文件中筛选和提取出来的,共包含 630 万个文档,总计 1470B 个词组。OpenWebMath 用于预训练和微调大型语言模型。
介绍
引入了使用新颖的选择性语言建模(SLM)目标训练的 RHO-1 模型。如图 2(右图)所示,这种方法将完整序列输入模型,并有选择性地去除不需要的 token 损失(在 LLM 的 SFT 阶段,我们往往会只训练 BOT 回复,而 instruction 和用户输入的内容不参与训练。在这篇论文中,预训练阶段也对 token 进行抉择,将一些 token 不参与 loss 计算)。

图 2:上部: 即使是经过广泛过滤的预训练语料也包含 token 级噪声。左图:之前的因果语言建模(CLM)对所有 token 进行训练。右图:作者提出的选择性语言建模 (SLM) 可选择性地对有用和干净的 token 参与损失。
方法介绍
并非所有 token 都一样:token loss 的训练动态
首先对标准预训练过程中单个 token 的损失如何演变进行了深入研究。继续使用 OpenWebMath 中的 15B token 对 Tinyllama-1B 进行预训练,每隔 1B token 保存检查点。然后,使用由大约 32 万个 token 组成的验证集来评估这些间隔(相邻检查点之间)的 token 级损失。
图 3(a) 揭示了一个惊人的模式:token 根据其损失轨迹分为四类:持续高损失(H→H),递增损失(L→H),递减损失(H→L)和持续低损失(L→L)。
在训练过程中,作者收集每个 token 在每 1B token 训练数据上训练后的损失。然后,采用线性拟合的方法,将第一个点和最后一个点的损失差值作为训练过程中损失是否减少的证据。具体来说,假设我们有一串 token 损失 l 0 , l 1 , … , l n l_0, l_1, \ldots, l_n l0,l1,…,ln。我们的目标是最小化每个数据点与其线性预测值之间差值的平方和:
f ( a , b ) = m i n i m i z e ∑ i = 0 n ( l i − ( a x i + b ) ) 2 f(a, b) = minimize \sum_{i=0}^n (l_i - (a x_i + b))^2 f(a,b)=minimizei=0∑n(li−(axi+b))2
其中 x 0 = 0 x_0 = 0 x0=0 为初始检查点, x n = n x_n = n xn=n 为最终检查点。将其代入拟合方程,可以得到拟合后开始和结束时的损失值:损失的变化可以表示为 ∆ L = L e n d − L s t a r t ∆L = L_{end} - L_{start} ∆L=Lend−Lstart。同时们用 L m e a n L_{mean} Lmean 表示最后一个检查点的平均损失。
接下来,我们可以根据 ∆ L ∆L ∆L 和 L m e a n L_{mean} Lmean 对 tokens 进行分类:
- 将 ∆ L < − 0.2 ∆L < -0.2 ∆L<−0.2 的 tokens 分为 H→L(损失从高到低递减)类;
- 将 ∆ L > 0.2 ∆L > 0.2 ∆L>0.2 的 tokens 分为 L→H(损失从低到高递增)类;
- 如果 − 0.2 ≤ ∆ L ≤ 0.2 -0.2 ≤ ∆L ≤ 0.2 −0.2≤∆L≤0.2 且 l n ≤ L m e a n l_n \leq L_{mean} ln≤Lmean,则 tokens 被归类为 L→L(损失仍然较低);
- 如果 l n > L m e a n l_n > L_{mean} ln>Lmean,则 tokens 被归类为 H→H(损失仍然较高)。
图 10(图较大,读者感兴趣的可自行到论文中查看)是实际文本中四类 tokens 的可视化示例。
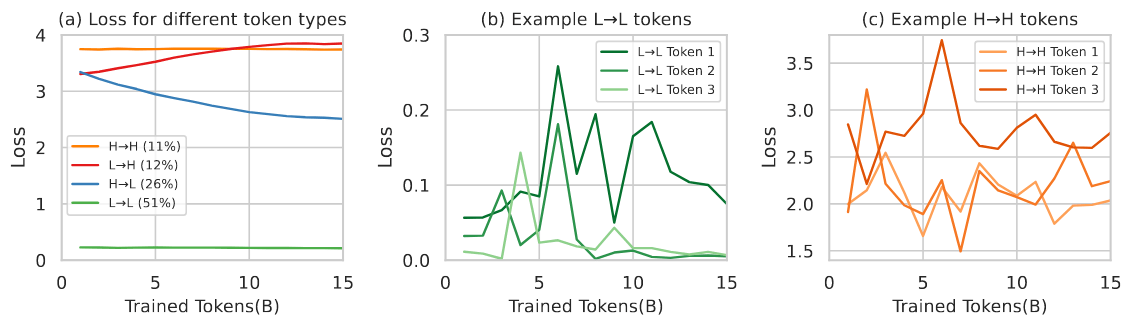
图 3:预训练期间四类 token 的损失。(a) 显示了预训练期间 H→H、L→H、H→L 和 L→L token 的损失情况。(b) 和 © 分别显示了在预训练过程中,L→L 和 H→H 的 token 损失波动的三种情况。
分析发现,仅有 26% 的 token 显示出显著的损失减少(H→L),而大多数 token(51%)仍处于 L→L 类别,表明它们已经被学习过了。有趣的是,有 11% 的 token 具有持续挑战性(H→H),这可能是由于高度的不确定性造成的 [Hüllermeier 和 Waegeman,2021]。此外,在训练过程中,12% 的 token 会出现意外损失增加(L→H)。
第二个观察结果是,有相当数量的 token 损失表现出持续的波动,并且难以收敛。如图 3 (b) 和 © 所示,许多 L→L 和 H→H token 的损失在训练过程中显示出很高的方差。在第 B.2 节中,作者对这些 token 的内容进行了可视化分析,发现其中很多都是有噪声的,这与提出的假设是一致的。
在训练过程中,与每个 token 相关的损失并不会像总体损失那样平滑减少;相反,不同 token 之间存在着复杂的训练动态。如果我们能在训练过程中为模型选择适当的 token 进行重点训练,就能稳定模型的训练轨迹并提高其效率。
选择性语言建模
受文档级过滤中参考模型实践的启发,作者提出了一个简单的 token 级数据选择管道,称为“选择性语言建模”(Selective Language Modeling,SLM)。该方法包括三个步骤,如图 4 所示。

图 4:选择性语言建模 (SLM) 的流程。通过在预训练期间集中处理有价值的、干净的 token 来优化语言模型的性能。它包括三个步骤: (Step 1)首先,在高质量数据上训练参考模型。(Step 2)然后,使用参考模型对语料库中每个 token 的损失进行评分。(Step 3)最后,有选择性地对与参考损失相比显示出更高超额损失的 token 进行语言模型训练。
- 首先,在一个经过策划的高质量数据集上训练一个参考模型。
- 然后,该模型会评估预训练语料库中每个 token 的损失。
- 最后,有选择性地训练语言模型,重点关注训练模型和参考模型之间损失过大的 token。
作者的直觉是,超额损失高的 token 更容易被学习,也更符合预期分布,从而自然而然地排除了不相关或低质量的 token。下面将详细介绍每个步骤。
但这里存在一个疑问:小规模的参考模型究竟能否为更大规模的模型挑选出合适的 token?在实验部分,作者对此有实验与解释,可参阅下文的“弱到强的生成”。
参考建模
首先要策划一个高质量的数据集,以反映所需的数据分布。作者使用标准的交叉熵损失在所策划的数据上训练一个参考模型(RM)。然后,在更大的预训练语料库中使用生成的 RM 来评估 token 损失。根据 RM 赋予 token x i x_i xi 的概率计算其参考损失 L r e f L_{ref} Lref。计算公式如下:
L r e f ( x i ) = − l o g P ( x i ∣ x < i ) (1) L_{ref}(x_i) = -log \ P(x_i | x < i) \tag{1} Lref(xi)=−log P(xi∣x<i)(1)
通过评估每个 token的 L r e f L_{ref} Lref,建立了选择性预训练的参考损失,使我们能够找出语言建模中最有影响力的 token。
选择性预训练
请注意,因果语言建模(CLM)采用的是交叉熵损失:
L C L M ( θ ) = − 1 N ∑ i = 1 N l o g P ( x i ∣ x < i ; θ ) (2) L_{CLM}(\theta) = - \frac{1}{N} \sum_{i=1}^N log \ P(x_i | x_{<i}; \theta) \tag{2} LCLM(θ)=−N1i=1∑Nlog P(xi∣x<i;θ)(2)
这里, L C L M ( θ ) L_{CLM}(\theta) LCLM(θ) 表示以模型 θ \theta θ 为参数的损失函数。N 是序列的长度, x i x_i xi 是序列中第 i 个 token, x < i x_{<i} x<i 表示第 i 个 token 之前的所有 token。与此相反,选择性语言建模(SLM)在训练语言模型时,会将重点放在与参考模型相比损失过大的 token 上。token x i x_i xi 的超额损失 L Δ L_{\Delta} LΔ 定义为当前训练模型损失 L θ L_{\theta} Lθ 与参考损失之间的差值。
L Δ ( x i ) = L θ ( x i ) − L r e f ( x i ) (3) L_{\Delta}(x_i) = L_{\theta}(x_i) - L_{ref}(x_i) \tag{3} LΔ(xi)=Lθ(xi)−Lref(xi)(3)
引入了一个 token 选择比率 k%,该比率根据 token 的超额损失来决定包含 token 的比例。所选 token 的交叉熵损失计算如下:
L S L M ( θ ) = − 1 N ∗ k % ∑ i = 1 M I k % ( x i ) ⋅ l o g P ( x i ∣ x < i ; θ ) (4) L_{SLM}(\theta) = - \frac{1}{N * k\%} \sum_{i=1}^M I_{k\%}(x_i) \cdot log \ P(x_i | x_{<i}; \theta) \tag{4} LSLM(θ)=−N∗k%1i=1∑MIk%(xi)⋅log P(xi∣x<i;θ)(4)
这里,N * k% 定义了属于超额损失前 k% 的 token 数量。指标函数 I k % ( x i ) I_{k\%}(x_i) Ik%(xi) 定义如下:
I
k
%
(
x
i
)
=
{
1
if
x
i
is in the top
k
%
of
L
Δ
0
otherwise
(5)
I_{k \%}\left(x_{i}\right)=\left\{
这就确保了损失只适用于被认为最有利于语言模型学习的 token。在实践中,token 选择可以通过根据超额损失对批次中的 token 进行排序,并只使用前 k% 的 token 进行训练来实现。这一过程可以消除不需要的 token 的损失,而不会在预训练过程中产生额外的成本,从而使该方法既高效又易于集成。
实验部分
数学预训练结果
Few-shot CoT 推理结果
按照以前的工作 [Lewkowycz 等人,2022;Azerbayev 等人,2023;Shao 等人,2024b],用 few-shot CoT [Wei 等人,2022a] 实例来评估基础模型的 prompt。
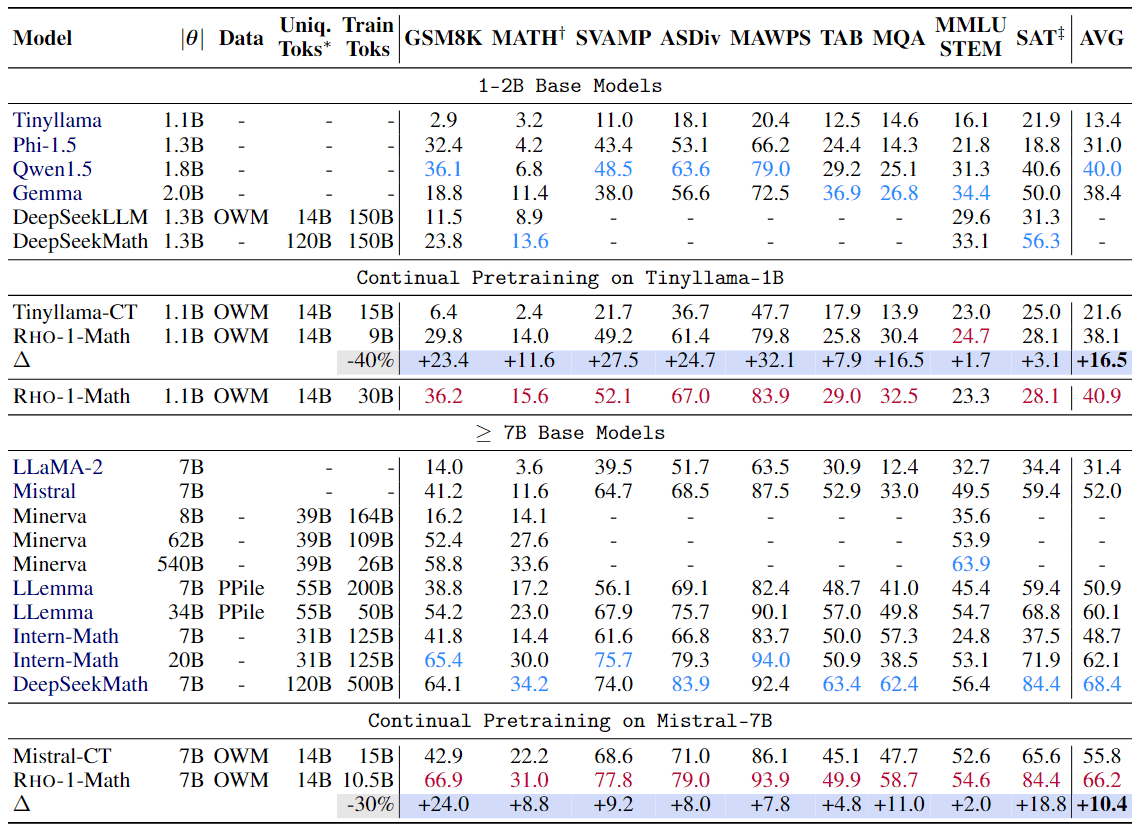
表 1: 数学预训练的 few-shot CoT 推理结果。所有模型都在 few-shot 提示下进行了测试。之前的最佳结果用蓝色标出,作者的最佳结果用紫色标出。∗ 仅计算与数学相关的唯一 token。对于 RHO-1,只计算用于训练的选定 token。使用 OpenAI 的 MATH 子集 [Lightman 等人,2023 年] 进行评估,因为一些原始测试样本已被用于 PRM800k 等公共训练集中。SAT 只有 32 个四选一问题,因此,如果有最后三个检查点,会将结果取平均值。
结果如表 1 所示,与直接进行预训练相比,RHO-1-Math 在 1B 模型上的 few-shot 平均准确率提高了 16.5%,在 7B 模型上的 few-shot 平均准确率提高了 10.4%。此外,在对 OpenWebMath 进行多次 epoch 训练后,发现 RHO-1 还能将平均 few-shot 准确率进一步提高到 40.9%。与在 5000 亿个数学相关 token 上进行预训练的 DeepSeekMath-7B 相比,仅在 150 亿个 token(选取 105 亿个 token)上进行预训练的 RHO-1-7B 取得了不相上下的结果,证明了该方法的高效性。
Tool-Integrated 推理结果
在 69k ToRA 语料库 [Gou 等人,2024 年] 上对 RHO-1 和基线模型进行了微调,该语料库由 16k GPT-4 生成的工具集成推理格式轨迹和 53k 使用 LLaMA 的答案增强样本组成。

表 2:数学预训练的工具综合推理结果。
如表 2 所示,RHO-1-1B 和 RHO-1-7B 在 MATH 数据集上分别取得了 40.6% 和 51.8% 的最佳成绩。在一些未见过的任务(如 TabMWP 和 GSM-Hard)上,RHO-1 也表现出了一定程度的通用性,在 RHO-1-Math-1B 和 RHO-1-Math-7B 上的平均 few-shot 准确率分别提高了 6.2% 和 2.7%。
通用预训练结果
通过对 Tinyllama-1.1B 进行 80G token的持续训练,证实了 SLM 在通用预训练中的功效。

图 5:一般预训练结果。作者继续在 80G general token 上对 Tinyllama-1B 进行预训练。Tinyllama-CT 采用 CLM 进行训练,而 RHO-1 则采用作者提出的 SLM 进行训练。
图 5 中描述的结果表明,尽管 Tinyllama 已经对其中的大部分标记进行了大量训练,但与直接持续预训练相比,SLM 的应用在 15 个基准中平均提高了 6.8%。代码和数学任务的改进尤为明显,超过了 10%。
相关分析
选定的 token 损失与下游性能更加一致
使用参考模型来筛选 token,并探索对所有/选定 token 进行训练后验证损失的变化,同时观察它们与下游损失的关系。
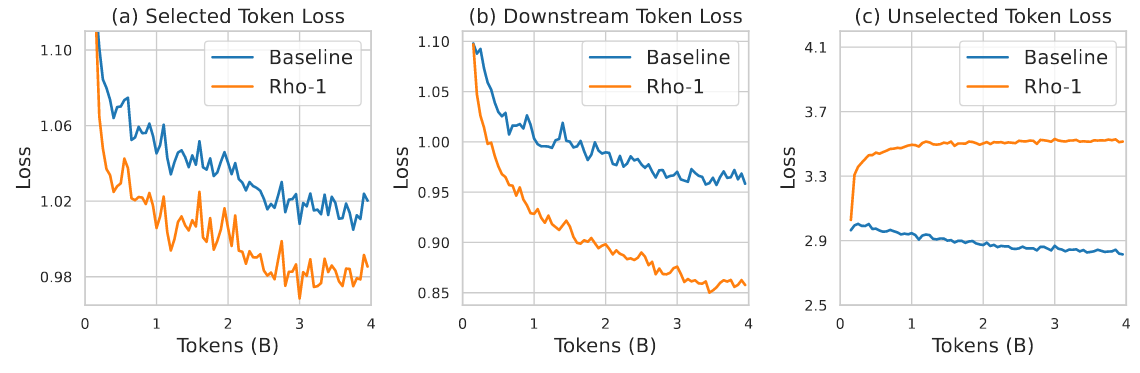
图 6:预训练损失和下游损失的动态变化。(a) 和 © 表示 SLM 和 CLM 方法在预训练过程中被 SLM 选中/未被 SLM 选中的 token 的损失,而 (b) 表示 SLM 和 CLM 方法在下游语料库中的损失。通过对总共 4B token 进行预训练来测试上述结果。
如图 6 所示,对大约 4B token 进行了预训练,并显示了预训练过程中不同预训练方法和验证集的损失变化曲线。可以观察到,在参考模型选择的 token 上,RHO-1 的平均损失比普通预训练的损失减少得更明显。相反,在未选择的 token 上,普通预训练的平均损失下降更为显著。如果将图(a)、图(b)与图(c)联系起来,不难发现,在选取的 token 上训练的模型,其下游损失的减少更为显著,而普通的预训练虽然在训练阶段减少了所有 token 的平均损失,但很难显著减少下游损失。因此,作者认为选择 token 进行预训练更有效。
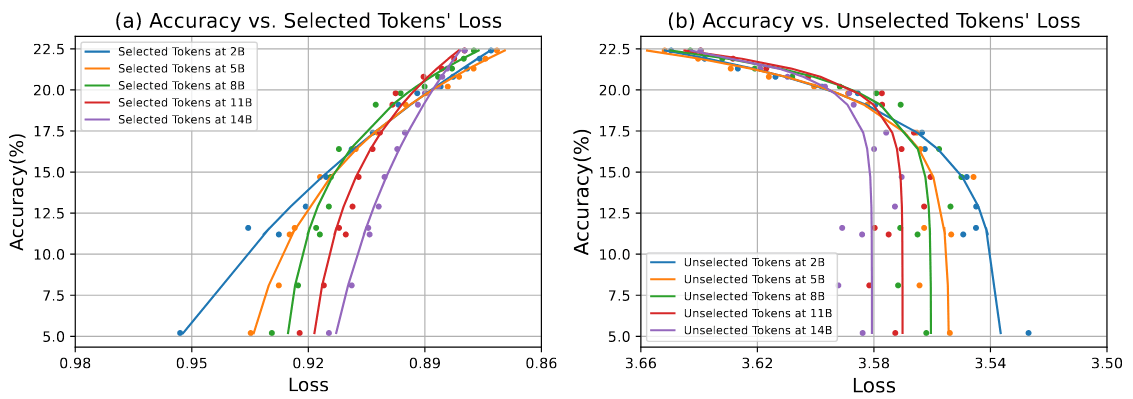
图 7:SLM 中已选 token / 未选 token 损失与下游任务性能之间的关系。y 轴表示 GSM8k 和 MATH 的平均 few-shot 准确率。x 轴表示在相应检查点(2B、5B、8B、11B 和 14B)上选定 token / 未选定 token 的平均损失。
此外,在图 7 中通过幂律将所选 token 的损失与其下游任务的表现联系起来,这与同时进行的一项研究 [Gadre 等人,2024] 相似。观察图中数据点的拟合曲线,SLM 所选 token 的平均损失与下游任务的性能呈正相关,而未被选中 token 的平均损失与下游任务的性能呈负相关。因此,模型的最终性能并不一定需要所有 token 的损失都减少。
SLM 选择了哪些 token?
旨在分析 SLM 方法在预训练中选择的 token,以进一步探索其工作机制。为此,使用 OpenWebMath 将 RHO-1 训练过程中的 token 选择过程可视化。在§E.1中,用蓝色(可参考原始论文的图 12)标出了在实际预训练中保留下来的 token。可以观察到,SLM 方法所选择的大部分 token 都与数学密切相关,从而有效地在原始语料库中与数学内容相关的部分对模型进行了训练。
此外,还研究了在训练过程中不同检查点在筛选 token 方面的差异,并在不同检查点上测试了这些 token 的 PPL。
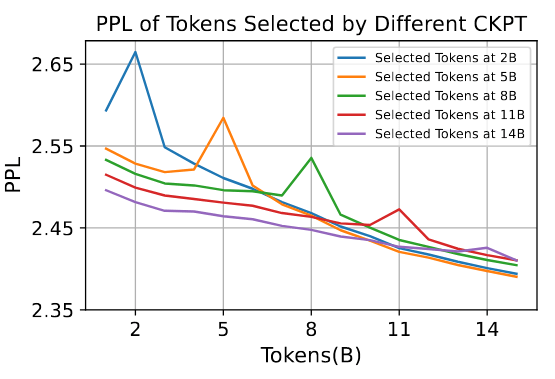
图 8:不同检查点所选 token 的 PPL。测试了在 2B、5B、8B、11B 和 14B 选择 token 的 PPL。
如图 8 所示,发现 later 检查点选择的 token 往往在训练的后期阶段具有较高的 PPL,而在前期阶段具有较低的 PPL。这可能表明,模型会首先优化可学习空间较大的 token,从而提高学习效率。此外,还注意到在所选 token 的损失上出现了抽样的“双下降”现象(Nakkiran 等人,2021 年),即所选 token 的 PPL 先上升后下降。这可能是根据超额损失选择 token 的效果,在每个检查点针对那些最需要的 token。
这篇论文让我联想起去年 9.30 发布的一篇探究 ICL 重复的论文,名称为《Understanding In-Context Learning from Repetitions》。这篇论文对表面特征在文本生成中的作用进行了定量研究,并根据经验确定 token 共现强化的存在,任何两个 token 构成一个 token 强化循环,在该循环中,任何两个 token 都可以通过多次重复出现而形成紧密联系。这是一种基于上下文共现强化两个 token 之间关系的原理。那么 SLM 是否可以打破这种 token 共现而出现的强化循环,从而缓解复读机问题?还是反而会强化这种循环(容易学习的 token),加剧复读机问题?
此外,去除噪声数据有可能会让模型的泛化性下降,并且有些未被选择的 token 适合其他领域和场景。虽然本篇论文在通用预训练实验上验证了效果反而会提升,但也正如下文讨论中所说的“虽然目前还没有观察到损失增加所带来的不利影响(如偏差)”以及实验规模性限制,在更大规模模型的预训练上仍然有该效果吗?如果是的话,那么可以节省大量的成本,那可太棒了。
token 选择比率的影响
研究了 SLM 的 token 选择比率的影响。一般来说,选择比例是由启发式规则定义的,类似于之前在训练掩码语言模型(MLM)时采用的方法 [Devlin 等人,2019;刘等人,2019]。如图 9 所示,选择的 token 适合占原始 token 的 60% 左右。

图 9:token 选择比例的影响。在 5B 个 token 上以 SLM 为目标训练 1B LM。
这一部分仍然有不少工作可以拓展,例如设定 loss 变化的阈值,而不是固定的比率,亦或是其他的指标。
弱到强的生成
除了使用同一基础模型进行参考和持续预训练的主要实验外,作者还研究了较小的参考模型能否有效指导较大模型的预训练。使用 Tinyllma-1.1B 作为参考模型,并在数学上使用 Llama-2-7B 进行持续预训练。

表 3:数学基准从弱到强的生成结果。
表 3 中的结果表明,尽管小模型和大模型之间存在相当大的差距 [李等人,2023c],但使用小参考模型进行 token 选择仍能为大模型的预训练带来好处。如果参考模型和训练模型有不同的词汇表,可以考虑进行 token 对齐 [Wan 等,2024;Fu 等,2023],这将留待今后的工作中进行。
讨论
泛化性
在数学持续预训练中,如图 6 所示,完全使用 SLM 进行训练会快速收敛到参考模型所聚焦的领域,同时伴随着未选中 token 损失的显著增加。虽然目前还没有观察到损失增加所带来的不利影响(如偏差),但正如欧阳等人 [2022] 和阿泽巴耶夫等人 [2023] 所建议的那样,对文本和代码进行一般的预训练损失可以防止过拟合。此外,正如 DeepSpeedMath [Shao 等人,2024a] 所示,未来的努力可以扩大参考模型的语料范围,并扩大预训练数据的规模。
规模性
由于预算限制,只在较小的模型(<=7B 参数)和较小的数据集(<100B token)上验证了该方法的有效性。较小的模型可以明显受益于去除无关 token 的损失,并专注于重要的 token。然而,在大量语料库中训练出来的超大模型有可能会自然而然地产生这种归纳偏差,从而压缩有用的数据(即压缩所有数据),尽管目前听起来效率不高。因此,未来的工作应该研究这种选择性语言建模技术能否扩展到超大型模型和数据[Kaplan 等人,2020]。
是否有必要训练参考模型?
要对 token 进行评分,我们需要一个高质量的参考模型。这可以是用少量高质量数据训练出来的基础模型,也可以是性能卓越的开源模型。事实上,由于我们只需要从参考模型中输入 logprobs 或 perplexity,我们甚至可以利用更强大的专有模型 API。可以输入 token,并使用 API 返回的输入对数概率作为参考分数。这一点我们将留待未来的工作中去实现。

