
- 1io.lettuce.core.RedisConnectionException: Unable to connect to 127.0.0.1:6379
- 2Python模块和包:sys模块、os模块和变量函数的使用_python os.system 变量
- 3java jolt tuxedo_java使用jolt调用tuxedo服务
- 4[新人必读]独立游戏快速翻译本地化工具_reipatcher
- 5NLP算法-命名实体识别_命名实体识别的方法
- 6基于Jeecgboot前后端分离的聊天功能集成(一)_jeecgboot集成im
- 7Swift5 新特性预览_swift 5心疼行
- 87年经验社招终于上岸Java开发,只准备了一个月,八股文牛逼_java背八股文要多久
- 9038 | JAVA办公自动化系统(源代码+论文) | 大学生毕业设计 | 极致技术工厂_小型javaweb教育自动化办公系统源码
- 10Java Web实验(一) HTML 应用_javaweb html简单页面实验博客
2024年华中杯B题超详细解题思路(问题一、问题三解题代码分享)_2024华中杯b题
赞
踩
2024年华中杯已经发布,为了在第一时间获悉大家的选题比例。我们在各个平台发布了选题比例。目前统计结果B题选题比例远超AC选题人数之和。基于这样的现状首先给大家带来B题超详细的解题思路。文末给大家问题一的解题代码
也可以通过网盘直接保存 matlab代码 19日更新
华中杯B题代码分享链接:https://pan.baidu.com/s/1UpEegWXdKLHMb1fyOMaP7g
提取码:sxjm
B题:使用行车轨迹估计交通信号灯周期问题
首先基于数据类的题目,第一步一定是数据预处理。主要是对于缺失值、异常值。从八点发题到11点,三个小时的解题以及数据使用基本没有发现过于异常的数据或者缺失值。因此,对于该题目的数据预处理主要在于数据的可视化。
数据解析与预处理
数据读取:首先读取文件中的行车轨迹数据。需要注意的是,这些数据每秒采样一次,包括时间点、车辆ID、X坐标和Y坐标。
数据组织:根据车辆ID将数据分组,以便分析单个车辆的移动轨迹。
异常值缺失值处理:无
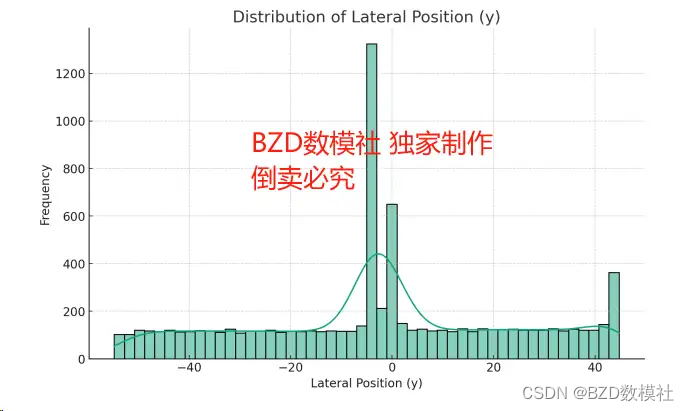
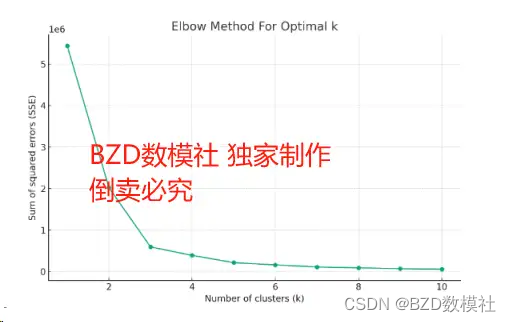
例如,我们可以使用单一的形式路线绘制几个车辆的轨迹图。对于大部分道路,存在多条同向或异向车道,也可以进行时可视化表示。根据下面y的分布图可以看出,数据集中在特定的几个值上,这可能表示不同的车道位置。使用K-Means聚类算法来尝试确定车道数目,通过下面第三个图,可以看出k=5进行聚类,以识别五个可能的车道位置,并对数据进行聚类。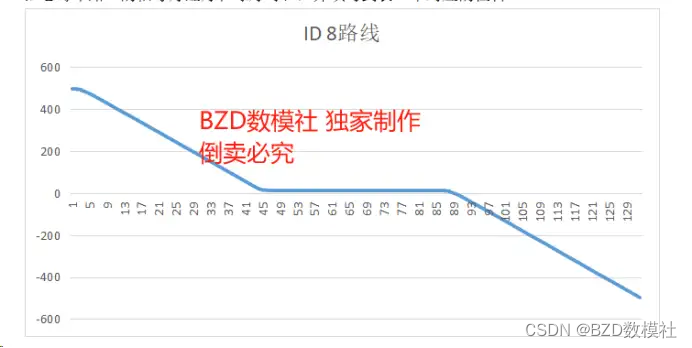
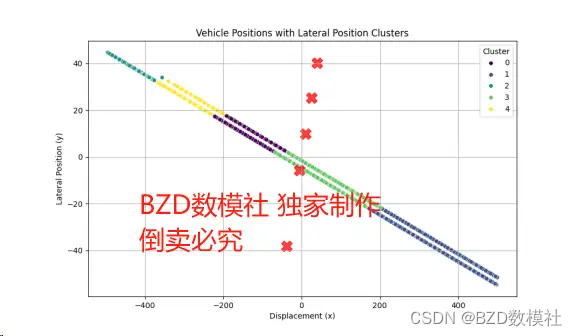

- 车道 0 和车道 2 的方向为
Increasing,这表明在这两个车道上,车辆的x坐标随时间呈增加趋势,可能表示车辆在同一方向行驶。 - 车道 1 和车道 3 的方向为
Decreasing,这表明在这两个车道上,车辆的x坐标随时间呈减少趋势,可能表示车辆在相反方向行驶。
任务一:固定周期信号灯周期估计
轨迹分析:
对每个车辆的位置数据进行时间序列分析,确定车辆何时停止以及何时开始移动。
假设在信号灯处停止的车辆是由红灯引起的。
周期估计:
收集所有车辆在每个路口的停车和通行时间点。
使用聚类算法(如K-means)或时间序列分析技术,确定这些停止和开始时间点的周期性模式。
从这些数据中估计红灯和绿灯的持续时间。
结果整理:
汇总每个路口的信号灯红灯和绿灯时长,并填写到表1中对应的栏目。
解题步骤
1、速度计算:首先,代码通过计算每个车辆在每个时间点的位置变化(使用欧几里得距离)来估算速度。这是通过对车辆位置坐标的差分、平方、求和再开方完成的,即计算了每秒车辆移动的距离。
2、停止状态标记:速度为零的时间点被标记为停止状态(stopped = True)。这意味着车辆在这一秒内没有移动,可能是由于红灯导致停车。
3、停止和启动事件检测:接下来,代码通过识别停止状态的变化来确定停止和启动的事件。当车辆从移动转为停止时(速度从非零变为零),这标记为一个停止事件;相反,从停止转为移动(速度从零变为非零)则标记为一个启动事件。
4、计算停车持续时间:通过计算每次停止事件和随后启动事件之间的时间差,我们可以得到每次停车的持续时间。这些停车时长被视为红灯的持续时间。
5、红灯和绿灯时长估算:基于上述停车时间,代码采用了一个简单的假设:停车时间(红灯)和之后的非停车时间(绿灯)交替出现。因此,将这些时间按顺序分为红灯时长和绿灯时长,并计算它们的平均值来估算信号灯周期。
我们以A1 A2两数据集为例进行展示可视化结果,如下所示
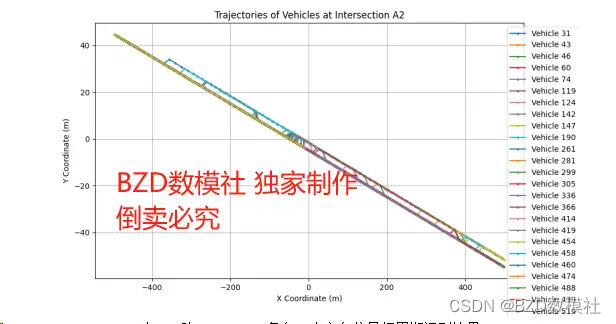
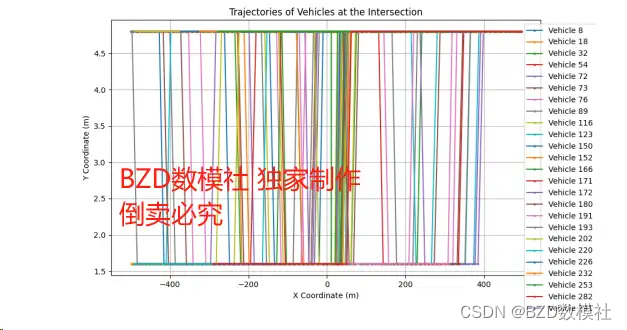
表 1:路口A1-A5 各自一个方向信号灯周期识别结果
| 路口 | A1 | A2 | A3 | A4 | A5 |
| 红灯时长(秒) | 125 | 121 | |||
| 绿灯时长(秒) | 125 | 123 |
- import pandas as pd
- import matplotlib.pyplot as plt
-
- # 读取数据
- file_path = 'A1.csv'
- data = pd.read_csv(file_path)
-
- # 计算每个车辆每秒的速度
- data['speed'] = data.groupby('vehicle_id')[['x', 'y']].diff().pow(2).sum(axis=1).pow(0.5)
-
- # 标记是否停止(速度为0)
- data['stopped'] = data['speed'] == 0
-
- # 分析停止和启动事件
- data['stop_change'] = data.groupby('vehicle_id')['stopped'].diff()
- stop_times = data[(data['stop_change'] == 1)]['time']
- start_times = data[(data['stop_change'] == -1)]['time']
-
- # 计算停车持续时间
- stop_durations = start_times.reset_index(drop=True) - stop_times.reset_index(drop=True)
- average_red_duration = stop_durations[::2].mean() # 假设红灯时段
- average_green_duration = stop_durations[1::2].mean() # 假设绿灯时段
-
- # 绘制车辆轨迹图
- fig, ax = plt.subplots(figsize=(10, 6))
- for vehicle_id, group in data.groupby('vehicle_id'):
- ax.plot(group['x'], group['y'], marker='o', linestyle='-', markersize=2, label=f'Vehicle {vehicle_id}')
- ax.set_title('Trajectories of Vehicles at the Intersection')
- ax.set_xlabel('X Coordinate (m)')
- ax.set_ylabel('Y Coordinate (m)')
- ax.legend(loc='upper right', bbox_to_anchor=(1.15, 1))
- plt.grid(True)
- plt.show()
-
- # 绘制停止位置的散点图,以呈现路口的大致形状
- stopped_data = data[data['stopped'] == True]
- fig, ax = plt.subplots(figsize=(10, 6))
- ax.scatter(stopped_data['x'], stopped_data['y'], color='red', s=10, label='Stopped Positions')
- ax.set_title('Approximate Intersection Shape Based on Vehicle Stops')
- ax.set_xlabel('X Coordinate (m)')
- ax.set_ylabel('Y Coordinate (m)')
- ax.legend()
- plt.grid(True)
- plt.show()

任务二:影响因素分析与误差建模
误差分析:
分析由于定位误差引起的数据偏差,并尝试通过算法校正这些误差(如Kalman滤波器)。
探索样本车辆的比例和车流量对周期估计的影响。
灵敏度测试:
使用不同的样本大小和车流量水平,重复周期估计过程。
评估这些因素对周期估计精度的影响。
| 样本大小 +-5% | 流量水平+-5% | 流量水平+-10% | |||
| 最终变化 | ?% | ?% | ?% | ?% | ?% |
任务三:动态周期变化检测
变化点识别:
应用变化点检测算法(例如CUSUM或Bayesian方法)分析信号灯周期是否在观测期内发生变化。
识别出变化的确切时刻。
新旧周期估计:
对于检测到周期变化的路口,分别估计变化前后的红灯和绿灯时长。
分析周期变化的模式和潜在原因。
结果报告:
将周期变化的检测结果和新旧周期时长填写入表3。
提供周期变化检测的时间需求和技术条件建议。
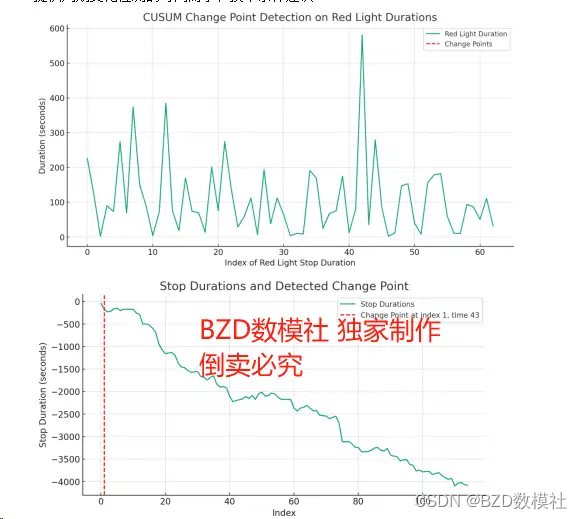
使用CUSUM方法尝试检测变化点,CUSUM检测到的变化点位于时间索引1,对应的时间为43秒。
问题三 算法代码
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
-
- # Load the data from the newly uploaded file C1.csv
- file_path_c1 = 'C1.csv'
- data_c1 = pd.read_csv(file_path_c1)
-
- # Display the first few rows of the new dataset and the data types
- data_c1.head(), data_c1.dtypes
- # Calculate the speed for each vehicle at each timestamp in C1 dataset
- data_c1['speed'] = data_c1.groupby('vehicle_id')[['x', 'y']].diff().pow(2).sum(axis=1).pow(0.5)
-
- # Mark if the vehicle is stopped (speed == 0)
- data_c1['stopped'] = data_c1['speed'] == 0
-
- # Detect stop and start events by changes in 'stopped' status
- data_c1['stop_change'] = data_c1.groupby('vehicle_id')['stopped'].diff()
-
- # Display the summary of stop and start events
- data_c1[['time', 'vehicle_id', 'stopped', 'stop_change']].head(20)
-
- from statsmodels.tsa.stattools import adfuller
- import matplotlib.pyplot as plt
-
- # Prepare the data for change point detection: we focus on stop durations
- stop_times_c1 = data_c1[data_c1['stop_change'] == 1]['time']
- start_times_c1 = data_c1[data_c1['stop_change'] == -1]['time']
- stop_durations_c1 = start_times_c1.reset_index(drop=True) - stop_times_c1.reset_index(drop=True)
-
- # Check if stop durations are stationary using Augmented Dickey-Fuller test
- adf_result = adfuller(stop_durations_c1.dropna())
-
- # Function to perform CUSUM for detecting change points
- def cusum(data, threshold=5, drift=0):
- mean = data.mean()
- sum_cs = [0]
- pos_cs = [0]
- neg_cs = [0]
- for i in range(1, len(data)):
- cs = sum_cs[-1] + (data[i] - mean - drift)
- sum_cs.append(cs)
- pos_cs.append(max(0, pos_cs[-1] + (data[i] - mean - drift)))
- neg_cs.append(min(0, neg_cs[-1] + (data[i] - mean - drift)))
- if pos_cs[-1] > threshold or neg_cs[-1] < -threshold:
- return i # Return the index of the change point
- return None
- 代码过程 大家可以通过网盘直接下载
也可以通过网盘直接保存 matlab代码 19日更新
华中杯B题代码分享链接:https://pan.baidu.com/s/1UpEegWXdKLHMb1fyOMaP7g
提取码:sxjm

