
- 1JavaScript-4.正则表达式、BOM
- 2vue+element ui 文件上传之文件缩略图缩略图
- 3开发 SpringBoot 项目所用版本的选择_springboot版本选择
- 4elementui-plus+ts+axios使用el-upload组件自定义上传_uploadinstance element-plus
- 5Flink 关于设置状态生命周期_flink状态的生命周期
- 6Facebook的魅力魔法:探访数字社交的奇妙世界
- 7【Git】在 IDEA 中合并多个 commit 为一个_idea多个提交合并成一个
- 8好书安利:《大模型应用开发极简入门:基于GPT-4和ChatGPT》,150 页就能让你上手大模型应用开发_大模型入门书籍
- 9好看好用 + 免费 AI 能力的终端工具,推荐 Warp!_warp+下载
- 10RabbitMq整合springboot超详细,超适合新手_springboot rabbitmq配置
这些细节在Java面试上要注意了!再不刷题就晚了!_java大佬一般都不要复习面试题吗
赞
踩
程序员:给多少工资,干多少事
我们不是经常会看到一个关于西游记的“悖论”吗:
为什么孙悟空初期大闹天宫的时候那么厉害?因为他自己当老板,打一群天庭的打工仔。
为什么取经路上又变得不行了?作为一个打工仔,去跟一群出来自己创业的妖怪打架。
很多程序员想跟老板说,但又不太敢说,实际却在做的一件事。
事实却是:
“拿着10K的工资,做着20K的事,还要操着30K的心!”
其实,这些情况都不奇怪,甚至是人之常情。
1、背景
首先,让我们简要地讨论下每个系统,以了解它们的高级设计和架构,看下每个系统所做的权衡。
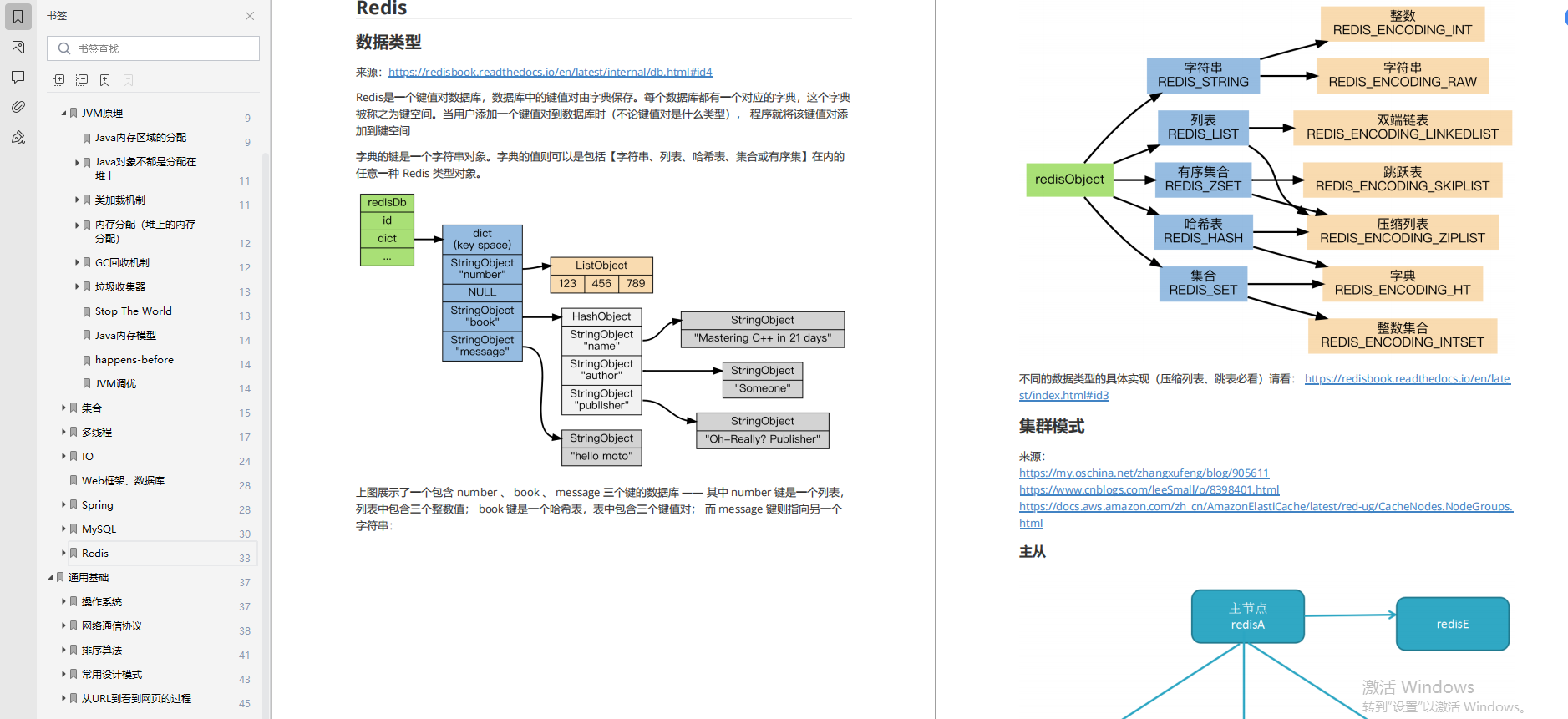
Kafka 是一个开源的分布式事件流处理平台,也是 Apache 软件基金会下五个最活跃的项目之一。在其核心,Kafka 被设计成一个多副本的分布式持久化提交日志,用于支撑事件驱动的微服务或大规模流处理应用程序。客户端向代理集群提供事件或使用代理集群的事件,而代理会向底层文件系统写入或从底层文件系统读取事件,并自动在集群中同步或异步地复制事件,以实现容错性和高可用性。
Pulsar 是一个开源的分布式发布 / 订阅消息系统,最初是服务于队列用例的。最近,它又增加了事件流处理功能。Pulsar 被设计为一个(几乎)无状态代理实例层,它连接到单独的 BookKeeper 实例层,由它实际地读取 / 写入消息,也可以选择持久地存储 / 复制消息。Pulsar 并不是唯一的同类系统,还有其他类似的消息传递系统,如 Apache DistributedLog 和 Pravega,它们都是在 BookKeeper 之上构建的,也是旨在提供一些类似 Kafka 的事件流处理功能。
BookKeeper 是一个开源的分布式存储服务,最初是为 Apache Hadoop 的 NameNode 而设计的预写日志。它跨服务器实例 bookies,在 ledgers 中提供消息的持久存储。为了提供可恢复性,每个 bookie 都会同步地将每条消息写入本地日志,然后异步地写入其本地索引 ledger 存储。与 Kafka 代理不同,bookie 之间不进行通信,BookKeeper 客户端使用 quorum 风格的协议在 bookie 之间复制消息。
RabbitMQ 是一个开源的传统消息中间件,它实现了 AMQP 消息标准,满足了低延迟队列用例的需求。RabbitMQ 包含一组代理进程,它们托管着发布消息的“交换器”,以及从中消费消息的队列。可用性和持久性是其提供的各种队列类型的属性。经典队列提供的可用性保证最少。经典镜像队列将消息复制到其他代理并提高可用性。最近引入的仲裁队列提供了更强的持久性,但是以性能为代价。由于这是一篇面向性能的博文,所以我们将评估限制在经典队列和镜像队列。
2、分布式系统的持久性
单节点存储系统(例如 RDBMS)依靠 fsync 写磁盘来确保最大的持久性。但在分布式系统中,持久性通常来自复制,即数据的多个副本独立失效。数据 fsync 只是在发生故障时减少故障影响的一种方法(例如,更频繁地同步可能缩短恢复时间)。相反,如果有足够多的副本失败,那么无论是否使用 fsync,分布式系统都可能无法使用。因此,我们是否使用 fsync 只是这样一个问题,即每个系统选择基于什么方式来实现其复制设计。有些系统非常依赖于从不丢失写入到磁盘的数据,每次写入时都需要 fsync,但其他一些则是在其设计中处理这种情况。
Kafka 的复制协议经过精心设计,可以确保一致性和持久性,而无需通过跟踪什么已 fsync 到磁盘什么未 fsync 到磁盘来实现同步 fsync。Kafka 假设更少,可以处理更大范围的故障,比如文件系统级的损坏或意外的磁盘移除,并且不会想当然地认为尚不知道是否已 fsync 的数据是正确的。Kafka 还能够利用操作系统批量写入磁盘,以获得更好的性能。
我们还不能十分确定,BookKeeper 是否在不 fsync 每个写操作的情况下提供了相同的一致性保证——特别是在没有同步磁盘持久化的情况下,它是否可以依赖复制来实现容错。关于底层复制算法的文档或文章中没有提及这一点。基于我们的观察,以及 BookKeeper 实现了一个分组 fsync 算法的事实,我们相信,它确实依赖于 fsync 每个写操作来确保其正确性,但是,社区中可能有人比我们更清楚我们的结论是否正确,我们希望可以从他们那里获得反馈。
无论如何,由于这可能是一个有争议的话题,所以我们分别给出了这两种情况下的结果,以确保我们的测试尽可能的公平和完整,尽管运行带有同步 fsync 功能的 Kafka 极其罕见,也是不必要的。
3、基准测试框架
对于任何基准测试,人们都想知道使用的是什么框架以及它是否公平。为此,我们希望使用 OpenMessaging Benchmark Framework(OMB),该框架很大一部分最初是由 Pulsar 贡献者编写的。OMB 是一个很好的起点,它有基本的工作负载规范、测试结果指标收集 / 报告,它支持我们选择的三种消息系统,它还有针对每个系统定制的模块化云部署工作流。但是需要注意,Kafka 和 RabbitMQ 实现确实存在一些显著的缺陷,这些缺陷影响了这些测试的公平性和可再现性。最终的基准测试代码,包括下面将要详细介绍的修复程序,都是开源的。
OMB 框架修复
我们升级到 Java 11 和 Kafka 2.6、RabbitMQ 3.8.5 和 Pulsar 2.6(撰写本文时的最新版本)。借助 Grafana/Prometheus 监控栈,我们显著增强了跨这三个系统的监控能力,让我们可以捕获跨消息系统、JVM、Linux、磁盘、CPU 和网络的指标。这很关键,让我们既能报告结果,又能解释结果。我们增加了只针对生产者的测试和只针对消费者的测试,并支持生成 / 消耗积压,同时修复了当主题数量小于生产者数量时生产者速率计算的一个重要 Bug。
OMB Kafka 驱动程序修复
我们修复了 Kafka 驱动程序中一个严重的 Bug,这个 Bug 让 Kafka 生产者无法获得 TCP 连接,存在每个工作者实例一个连接的瓶颈。与其他系统相比,这个补丁使得 Kafka 的数值更公平——也就是说,现在所有的系统都使用相同数量的 TCP 连接来与各自的代理通信。我们还修复了 Kafka 基准消费者驱动程序中的一个关键 Bug,即偏移量提交的过于频繁及同步导致性能下降,而其他系统是异步执行的。我们还优化了 Kafka 消费者的 fetch-size 和复制线程,以消除在高吞吐量下获取消息的瓶颈,并配置了与其他系统相当的代理。
OMB RabbitMQ 驱动程序修复
我们增强了 RabbitMQ 以使用路由键和可配置的交换类型(DIRECT交换和TOPIC交换),还修复了 RabbitMQ 集群设置部署工作流中的一个 Bug。路由键被引入用来模仿主题分区的概念,实现与 Kafka 和 Pulsar 相当的设置。我们为 RabbitMQ 部署添加了一个 TimeSync 工作流,以同步客户端实例之间的时间,从而精确地测量端到端延迟。此外,我们还修复了 RabbitMQ 驱动程序中的另一个 Bug,以确保可以准确地测量端到端延迟。
OMB Pulsar 驱动程序修复
对于 OMB Pulsar 驱动程序,我们添加了为 Pulsar 生产者指定最大批次大小的功能,并关闭了那些在较高目标速率下、可能人为地限制跨分区生产者队列吞吐量的全局限制。我们不需要对 Pulsar 基准驱动程序做任何其他重大的更改。
4、测试平台
OMB 包含基准测试的测试平台定义(实例类型和 JVM 配置)和工作负载驱动程序配置(生产者 / 消费者配置和服务器端配置),我们将其用作测试的基础。所有测试都部署了四个驱动工作负载的工作者实例,三个代理 / 服务器实例,一个监视实例,以及一个可选的、供 Kafka 和 Pulsar 使用的三实例 Apache ZooKeeper 集群。在实验了几种实例类型之后,我们选定了网络 / 存储经过优化的 Amazon EC2 实例,它具有足够的 CPU 内核和网络带宽来支持磁盘 I/O 密集型工作负载。在本文接下来的部分,我们会列出我们在不同的测试中对这些基线配置所做的更改。
磁盘
具体来说,我们选择了i3en.2xlarge(8 vCore,64GB RAM,2x 2500 GB NVMe SSD),我们看中了它高达 25 Gbps 的网络传输限额,可以确保测试设置不受网络限制。这意味着这些测试可以测出相应服务器的最大性能指标,而不仅仅是网速多快。i3en.2xlarge实例在两块磁盘上支持高达 约 655 MB/s 的写吞吐量,这给服务器带来了很大的压力。有关详细信息,请参阅完整的 实例类型定义。根据一般建议和最初的 OMB 设置,Pulsar 把一个磁盘用于 journal,另一个用于 ledger 存储。Kafka 和 RabbitMQ 的磁盘设置没有变化。
最后的内容
在开头跟大家分享的时候我就说,面试我是没有做好准备的,全靠平时的积累,确实有点临时抱佛脚了,以至于我自己还是挺懊恼的。(准备好了或许可以拿个40k,没做准备只有30k+,你们懂那种感觉吗)
如何准备面试?
1、前期铺垫(技术沉积)
程序员面试其实是对于技术的一次摸底考试,你的技术牛逼,那你就是大爷。大厂对于技术的要求主要体现在:基础,原理,深入研究源码,广度,实战五个方面,也只有将原理理论结合实战才能把技术点吃透。
下面是我会看的一些资料笔记,希望能帮助大家由浅入深,由点到面的学习Java,应对大厂面试官的灵魂追问,有需要的话就戳这里:蓝色传送门打包带走吧。
这部分内容过多,小编只贴出部分内容展示给大家了,见谅见谅!
- Java程序员必看《Java开发核心笔记(华山版)》

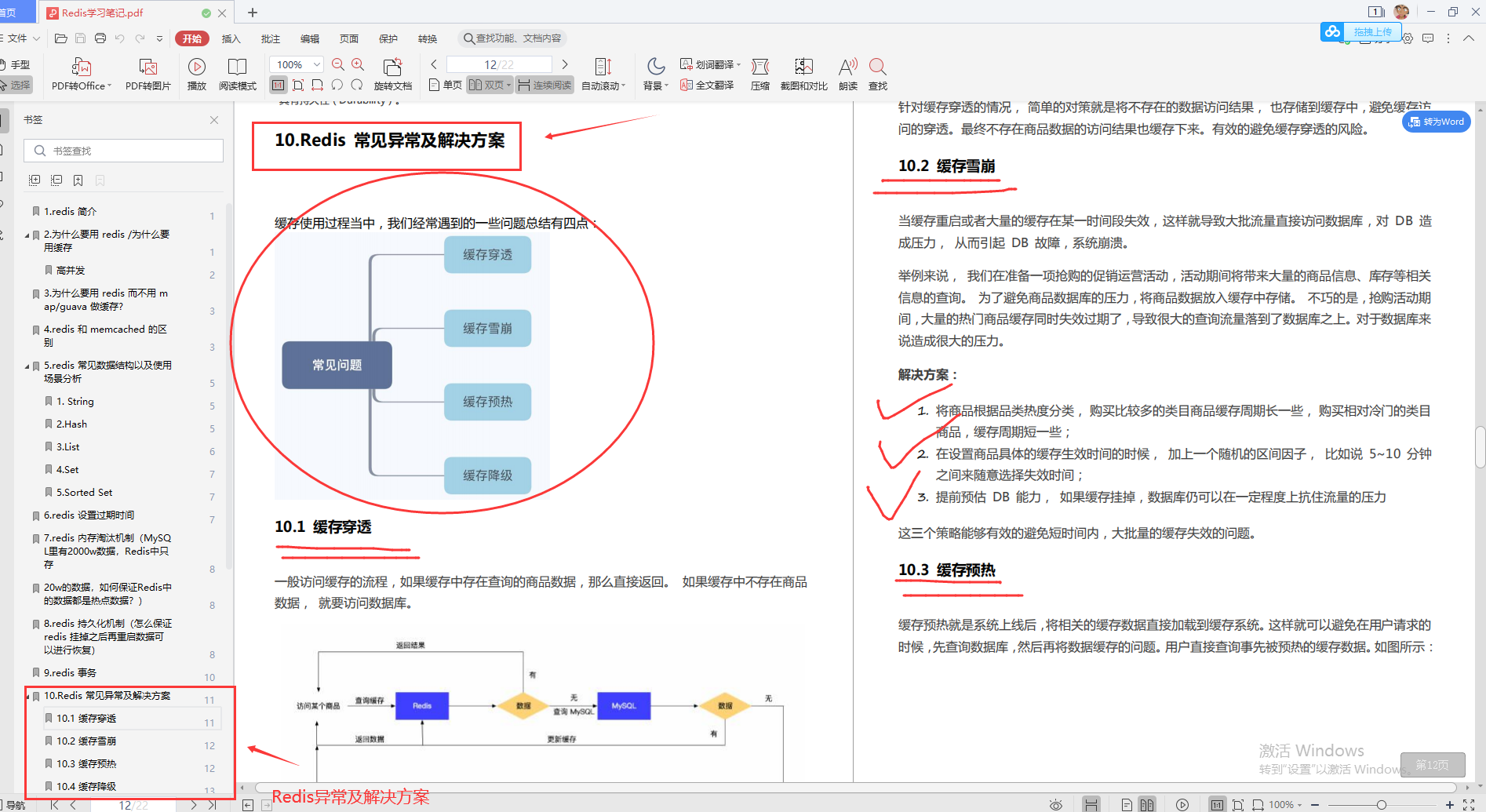
- Redis学习笔记
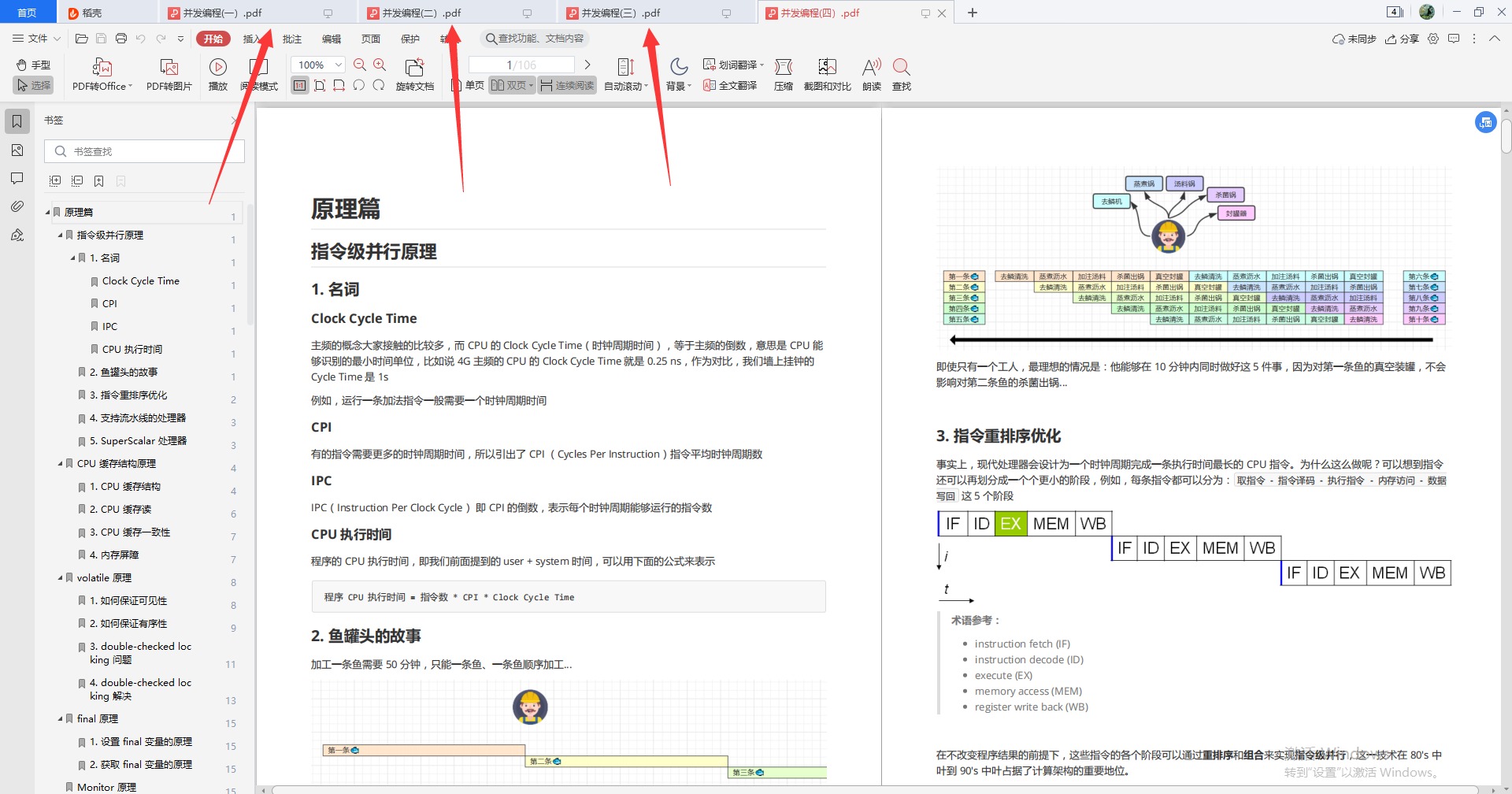
- Java并发编程学习笔记
四部分,详细拆分并发编程——并发编程+模式篇+应用篇+原理篇
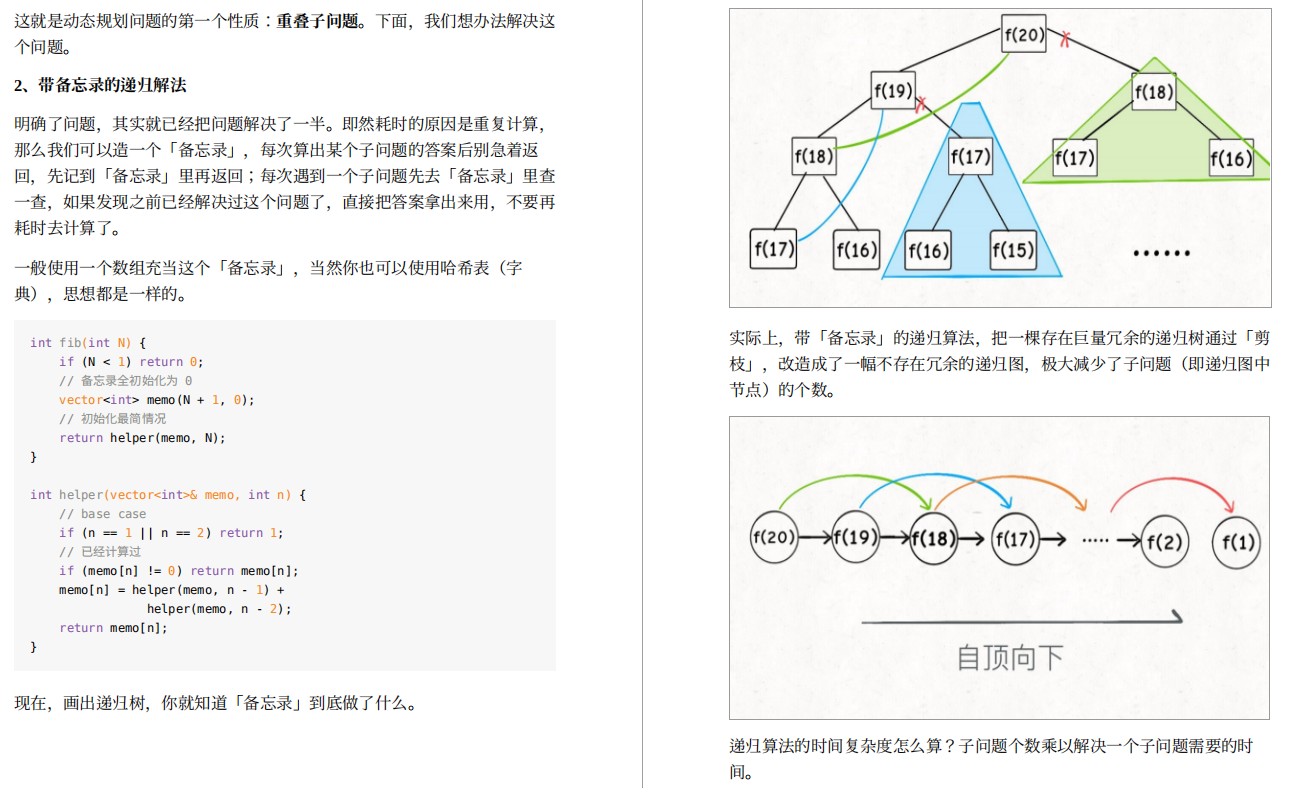
- Java程序员必看书籍《深入理解 ava虚拟机第3版》(pdf版)

- 大厂面试必问——数据结构与算法汇集笔记
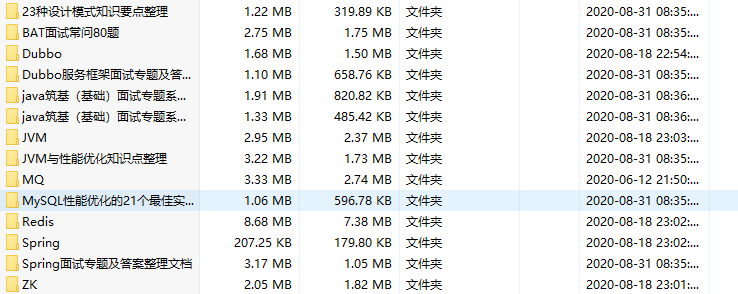
其他像Spring,SpringBoot,SpringCloud,SpringCloudAlibaba,Dubbo,Zookeeper,Kafka,RocketMQ,RabbitMQ,Netty,MySQL,Docker,K8s等等我都整理好,这里就不一一展示了。
2、狂刷面试题
技术主要是体现在平时的积累实用,面试前准备两个月的时间再好好复习一遍,紧接着就可以刷面试题了,下面这些面试题都是小编精心整理的,贴给大家看看。
①大厂高频45道笔试题(智商题)

②BAT大厂面试总结(部分内容截图)
③面试总结
3、结合实际,修改简历
程序员的简历一定要多下一些功夫,尤其是对一些字眼要再三斟酌,如“精通、熟悉、了解”这三者的区别一定要区分清楚,否则就是在给自己挖坑了。当然不会包装,我可以将我的简历给你参考参考,如果还不够,那下面这些简历模板任你挑选:
以上分享,希望大家可以在金三银四跳槽季找到一份好工作,但千万也记住,技术一定是平时工作种累计或者自学(或报班跟着老师学)通过实战累计的,千万不要临时抱佛脚。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
种累计或者自学(或报班跟着老师学)通过实战累计的,千万不要临时抱佛脚。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
以上文章中,提及到的所有的笔记内容、面试题等资料,均可以免费分享给大家学习,有需要的话就戳这里打包带走吧。

