
- 1vue使用axios解决跨域get和post请求
- 2sqlalchemy 2.0 的 sqlalchemy.orm.mapped_column 方法中 默认值参数: default,server_defaul, default_factory 的区别_sqlalchemy mapped_column
- 3『大模型笔记』Code Example: Function Calling with ChatGPT
- 4一些常用的在jsp中连接数据库的方式_简jsp一般通过什么连接数据库?并简述连接过程
- 5AI图片生成 discord 使用midjourney_discord 引用图片出图
- 6如何在 Ubuntu 12.04 VPS 上使用 MongoDB 创建分片集群
- 7经典论文阅读笔记——VIT、Swin Transformer、MAE、CILP_clip与vit的关系
- 8在 Linux 环境下安装 Kibana_linux安装kibana
- 9m1 MBA配置Homebrew环境+国内源配置_homebrew 国内源
- 10MySQL 5.6 复制介绍
Xilinx Aurora 8B/10B IP核详解和仿真
赞
踩
支持
AXI4-Stream用户接口
VIVADO为Aurora提供具有可配置的8B/10B内核的数据位宽的源代码。这些IP核可以是单工的或全双工的,并具有两个简单的用户界面之一和可选的流控制功能。
Aurora8B/10B核是一种可扩展的、轻量级的链路层协议,可用于高速串行通信。该协议是开放的,可以使用Xilinx FPGA技术来实现。该协议通常用于需要简单、低成本、高速数据通道的应用,用于使用一个或多个收发器在设备之间传输数据。
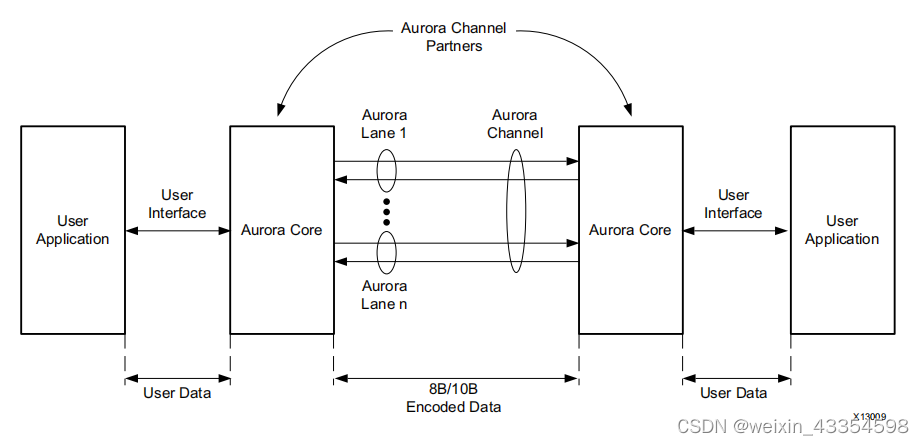
当Aurora8B/10B核连接到Aurora通道parter,它们会自动初始化通道,并作为数据帧或数据流通过通道自由传输数据。帧可以是任何大小的,并可以随时中断。有效数据字节之间的间隙会自动填充空闲时间,以保持锁定和防止过度的电磁干扰。流量控制可用于降低传入数据的速率,或通过该通道发送简短的、高优先级的消息。
应用
芯片对芯片的链路:用高速串行连接替换芯片之间的并行连接可以显著减少PCB上所需的trace和层数。该核心提供了使用GTP、GTX和GTH收发器所需的逻辑,以及最小的FPGA资源成本。
板到板或背板链路:核使用标准的8B/10B编码,使其与许多现有的电缆和背板硬件标准兼容。Aurora8B/10B核心可以在线率和通道宽度上进行缩放,以允许廉价的遗留硬件用于新的、高性能的系统。
单工连接(单向):Aurora协议提供了执行单向信道初始化的替代方法,使在没有back通道的情况下使用GTP、GTX和GTH收发器成为可能,由于未使用的全双工资源,而降低了成本。
延时
2bytes位宽的帧的设计(默认的配置),不包括高速串口连接线长延时,其总共的最小延时约为37个用户时钟周期。
4bytes位宽的帧的设计(默认的配置),不包括高速串口连接线长延时,其总共的最小延时约为41个用户时钟周期。
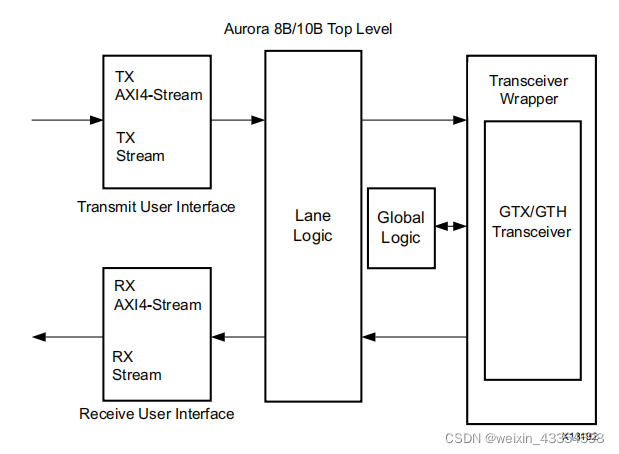
接口
顶层架构
AXI4-Stream Bit顺序

用户接口
当IP核配置为帧接口,其用户接口如下:
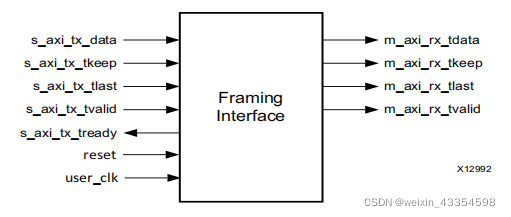
用户I/O接口(TX)
- [n:0] Little Endian
- [0:n] Big Endian

用户I/O接口(RX)
- [n:0] Little Endian
- [0:n] Big Endian
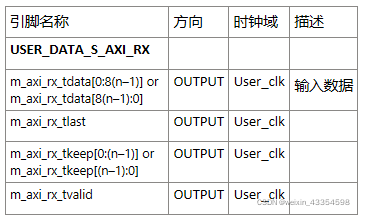
注意:如果接口为Stream接口,则接口没有tlast和tkeep引脚。
传输数据
用户应用操作控制信号传输数据的过程如下:
• 当确认s_axi_tx_tvalid和s_axi_tx_tready信号置位时,从s_axi_tx_tdata总线上获取数据。
• 从Aurora 8B/10B通道剥离数据。
• 使用s_axi_tx_tvalid信号来传输数据。用户应用通过拉低s_axi_tx_tvalid信号来插入idle来暂停传输数据。
IP核接收到数据后的处理过程
• 检测并去除控制bytes(idle, 时钟补偿,通道PDU起始,通道数据单元的结束和PAD。
• 置位m_axi_rx_tlast,指定最后一个数据中的有效字节数(m_axi_rx_tkeep)。
• 从通道中恢复数据
• 置位m_axi_rx_tdata,将数据呈现给用户界面。
只有当s_axi_tx_tready和s_axi_tx_tvalid都为High时,Aurora8B/10B核采样数据。
Aurora 8B/10B Frames(帧)
TX子模块将每个接收到的用户帧转换为Aurora 8B/10B帧。
SOF(start of frame, 2-byte SCP(start of channel protocol))
EOF(End of frame, 2-byte ECP)
典型的通道的Frame
/SCP1/ /SCP2/ /DATA0/ / DATA1/ /DATA2/ … /DATAN-1/ /DATAN/ /ECP1/ /ECP2/
发送数据的用户接口时序

注意:Aurora8B/10B核在发送时钟补偿序列时,会自动中断数据传输。时钟补偿序列每10000字节每通道添加12字节的开销。
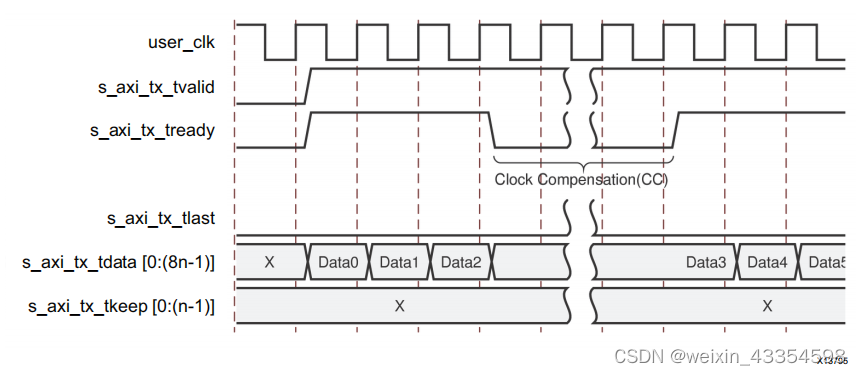
接收数据的用户接口时序
RX子模块没有针对用户数据的内置弹性缓冲区。结果,在RX AXI4-S接口上没有m_axi_rx_tready信号。

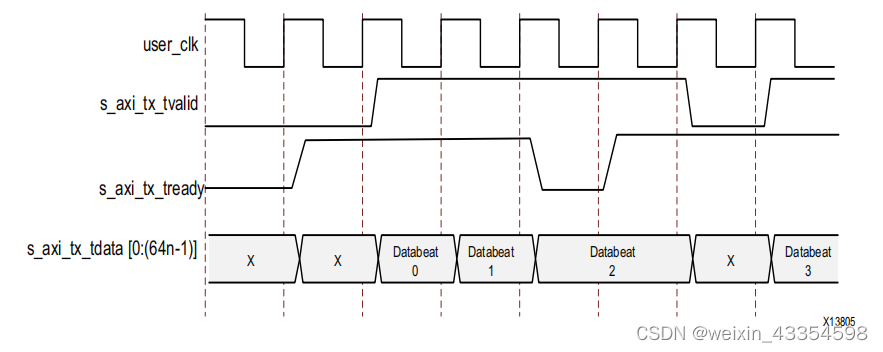
流接口
当IP核配置为流接口,其用户接口如下:
TX数据传输时序:
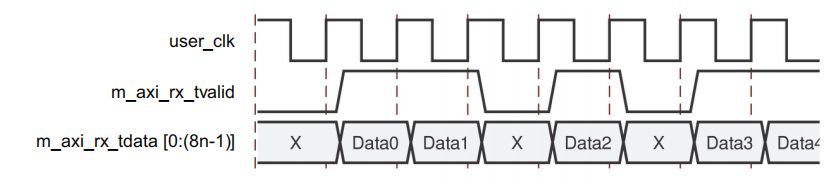
RX数据接收时序:
流控制
对于帧接口有两个可选的流控制接口,NFC(调节全双工通道接收端的数据的传输速率),UFC(提供更高优先级消息的操作)。
UFC接口
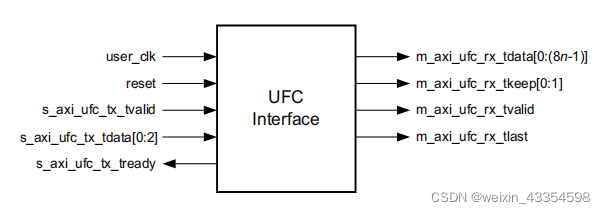
注意:这里的s_axi_ufc_tx_tdata端口用来制定传输的UFC数据的大小:
例如:0 --> 1个AXI4 Interface Width个byte(16bits位宽表示2 Byte);
1 --> 2个AXI4 Interface Width个byte(16bits位宽表示4 Byte);
…
UFC与正常传输数据的切换
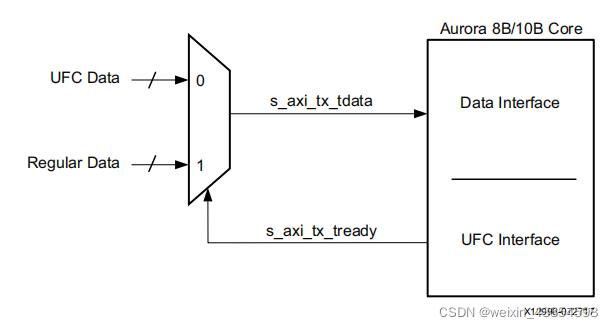
UFC数据一定是在正常数据流的tx_tready信号拉低时传输,此时s_axi_ufc_tx_tready置位。
UFC数据传输时序
下面时一个2bytes位宽的AXI4-S接口,传输4bytes UFC数据的时序图。

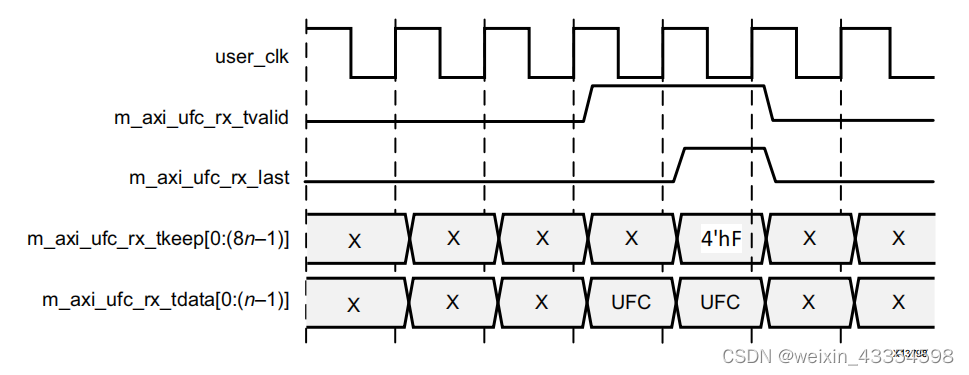
UFC数据接收时序
下面是一个4bytes位宽的AXI4-S接口,接收8bytes UFC数据的时序图
NFC接口
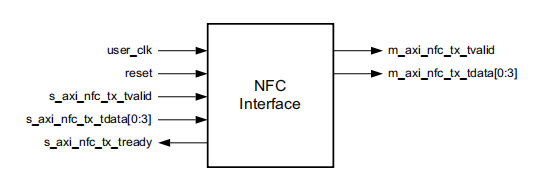
注意:
s_axi_nfc_tx_tdata信号用来指示通道另一端parter在接收到NFC消息时必须发送的暂停次数。必须保持,直到s_axi_nfc_tx_tready信号置位。
m_axi_nfc_tx_tdata信号用来指示接收到的NFC的PAUSE的值。
发送NFC时序
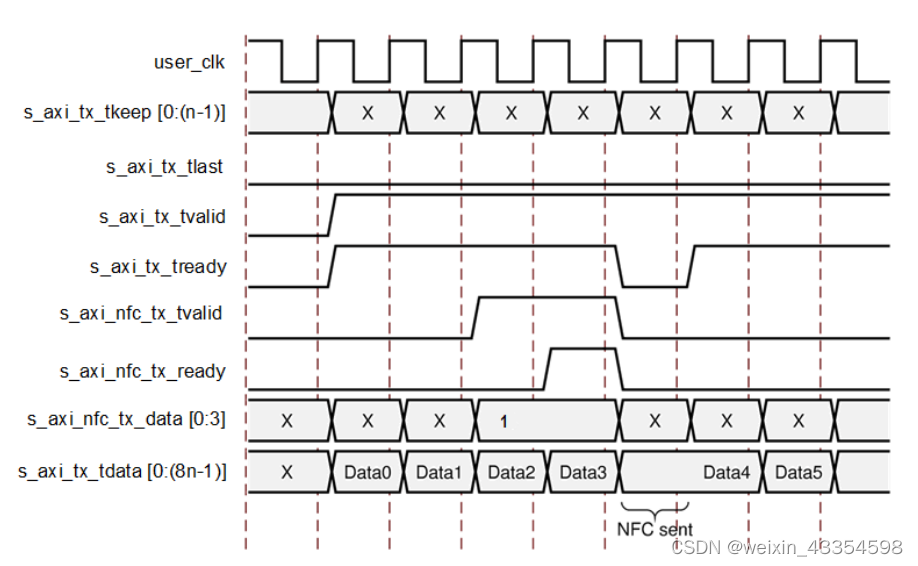
接收NFC时序(插入了idle数据)

状态、控制和收发端子接口
状态和控制接口
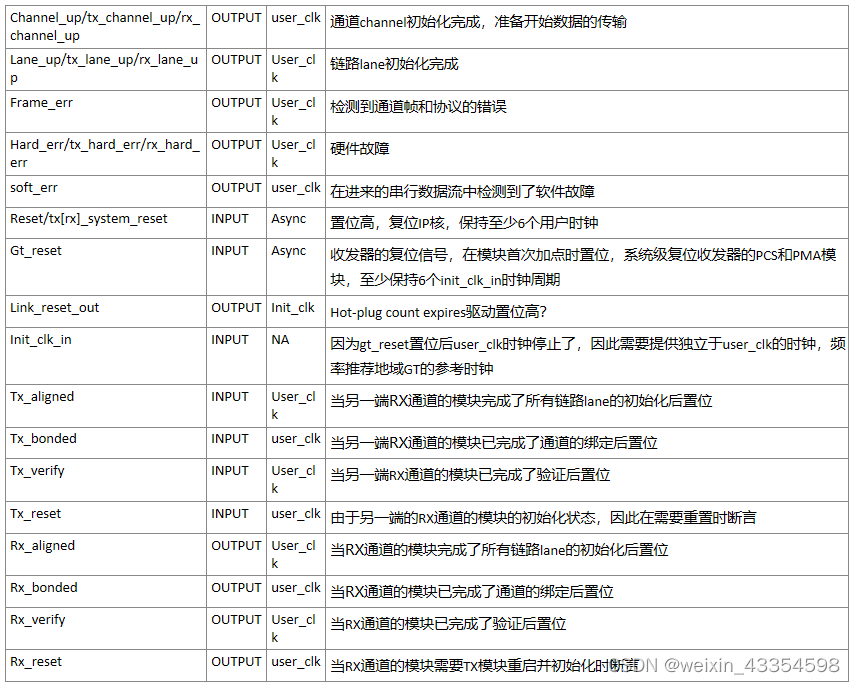
Rx_reset
OUTPUT
user_clk
当RX通道的模块需要TX模块重启并初始化时断言
全双工IP核
全双工核心提供了一个TX和一个RX Aurora8B/10B通道连接。
状态和控制接口
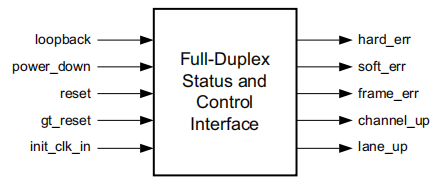
在Aurora8B/10B通道运行时,设备问题和通道噪声可能会导致错误。8B/10B编码允许Aurora8B/10B核检测在信道中发生的所有单bit错误和大多数多位错误,并在每个周期中断言soft_err。TX单形核不包含soft_err端口。除非出现设备问题,否则假设所有传输数据都是正确的。
IP核还监视每个收发器的硬件错误,如缓冲区溢出/欠溢出和锁的丢失,并置位hard_err信号。
一旦检测到了硬件错误,IP核自动复位,并尝试重新初始化。
IP核的AXI4-S数据接口也能检测到帧的错误,并置位frame_err信号。帧错误包括:帧中无数据;连续的帧起始符号和连续的帧的结束符号。帧错误通常紧跟在soft_err错误后,soft_err是导致帧错误的主要原因。
Simplex Cores
下图分别是Simplex的TX和RX模块。
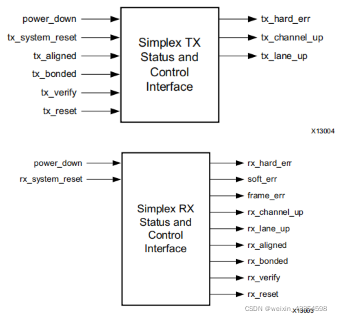
Simplex核不依赖 Aurora 8b/10b通道的信号进行初始化,他们通过边带的初始化信号:aligned, bonded, verify和reset信号来通知其初始化状态。
有两种方法来初始化simplex模块:
1. 从RX的边带初始化端口发送初始化信号到TX的边带初始化端口。
2. 使用定时的初始化间隔,不依赖RX边带接口初始化TX。
反向通道
在RX和TX之间没有通道的情况下,使用反向通道是初始化和维护Simplex通道的最安全的方法。back通道只需要将消息传递到TX侧,以指示在信号发生变化时置位的是哪一个边带初始化信号。
使用定时器
如果无法实现反向信道,则可以通过使用一组计时器驱动TX Simplex初始化来初始化串行信道。计时器必须仔细设计以满足系统的需要,因为初始化的平均时间取决于许多通道特定的条件,如时钟速率、信道延迟、通道之间的Skew和噪声。C_ALIGNED_TIMER、C_BONDED_TIMER和C_VERIFY_TIMER分别是用于置位tx_aligned、tx_bonded和tx_verify信号的计时器。这些计时器使用从corner case函数模拟中获得的最坏情况值,并在<组件名称>_core模块中实现。
Aurora8B/10B通道通常只在出现故障的情况下才会重新初始化。当没有可用的反向通道时,对于大多数错误,不可能发生事件触发的重新初始化,因为通常,RX端检测到故障,而必须由TX端处理错误情况。解决方案是使定时器驱动的TX Simplex定期重新初始化。如果发生灾难性错误,该通道将被重置,并在下一个重新初始化周期到达后重新运行。系统设计人员应平衡重新初始化所需的平均时间与其系统能够容忍通道的最大不工作的时间(失效时间),以确定其系统的最佳重新初始化周期。
WATCHDOG_TIMEOUT参数位于 tx_channel_init_sm/ rx_channel_init_sm模块中。
收发器接口(略)
时钟接口
包括收发器的参考时钟和IP核与应用逻辑共享的并行时钟。
端口列表(略)
CRC

工程设计
使用Example设计作为工程的开始
每个创建的Aurora 8B/10B IP核的实例都带了一个示例设计,可用于FPGA的仿真和实施。
难度
Aurora 8B/10B IP核工程设计的难度与下面的因素相关:
• 最大的时钟频率
• 目标设备的架构
• 应用程序的性质
为了简化定时和增加系统的性能,建议在所有的用户应用和IP核各自的时钟域的输入和输出添加FIFO。
用户不要随便修改IP核,建议只通过VIVADO IDE来配置Aurora 8B/10B IP核。
串行收发器参考时钟接口
IP核需要高质量低抖动的参考时钟来驱动高速的TX时钟和时钟恢复电路。
还需要至少一个频率锁定的并行时钟用于用户逻辑的同步操作。
Aurora8B/10B核在UltraScale™和UltraScale+™系列、Virtex®-7、Kintex®-7和Zynq®-7000系列芯片的设计中配置通道锁相环(CPLL)。
多Quad收发器公用时钟
7系列FPGAs中由外部时钟对(mgtrefclkn/mgtrefclkp)驱动的GTX或GTH收发器总数不得超过3个quad,即包括时钟本身所在的quad和其上下各一个quad,或12个GTXE2_CHANNEL/GTHE2_CHANNEL收发器。如果超过12个收发器或超过3个quad的设计应使用多个外部时钟引脚。
复位和断电
复位信号用来将IP核复位到一个已知的初始状态,复位时,IP核停止任何当前的操作,并重新初始化一个新的通道。
复位后的3个时钟周期,channel_up信号也会拉低deasserted。
gt_reset,tx[rx]_system_reset复位信号至少需要保持6个以上的时钟周期。
上电时复位信号的时序
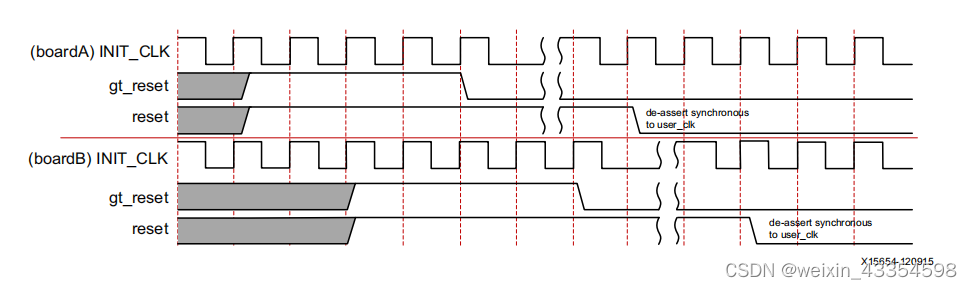
正常的复位时序

Simplex模块的上电时序
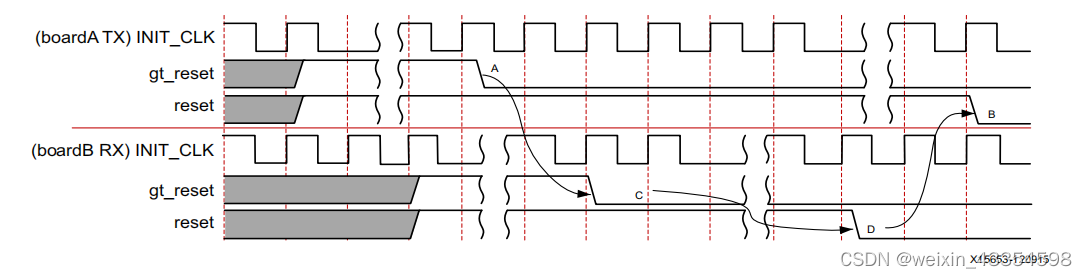
1. 拉低TX端的gt_reset;
2. 拉低RX端的gt_reset;
3. 拉低RX端的reset;
4. 拉低TX端的reset。
Simplex的正常的复位时序
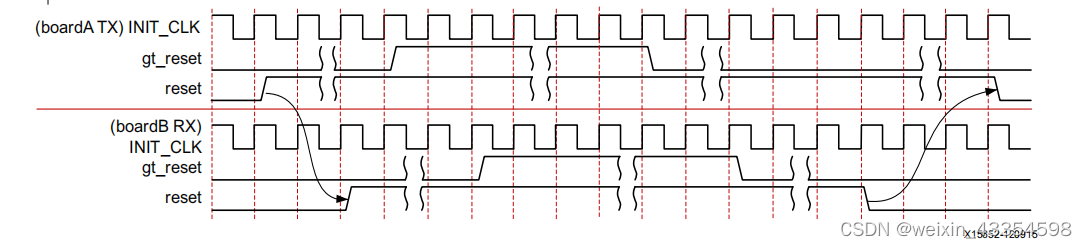
低功率模式
powerdown信号置位时,Aurora 8B/10B核的收发器关闭,并进入无操作、低功率模式。
powerdown信号拉低时,IP核自动复位。
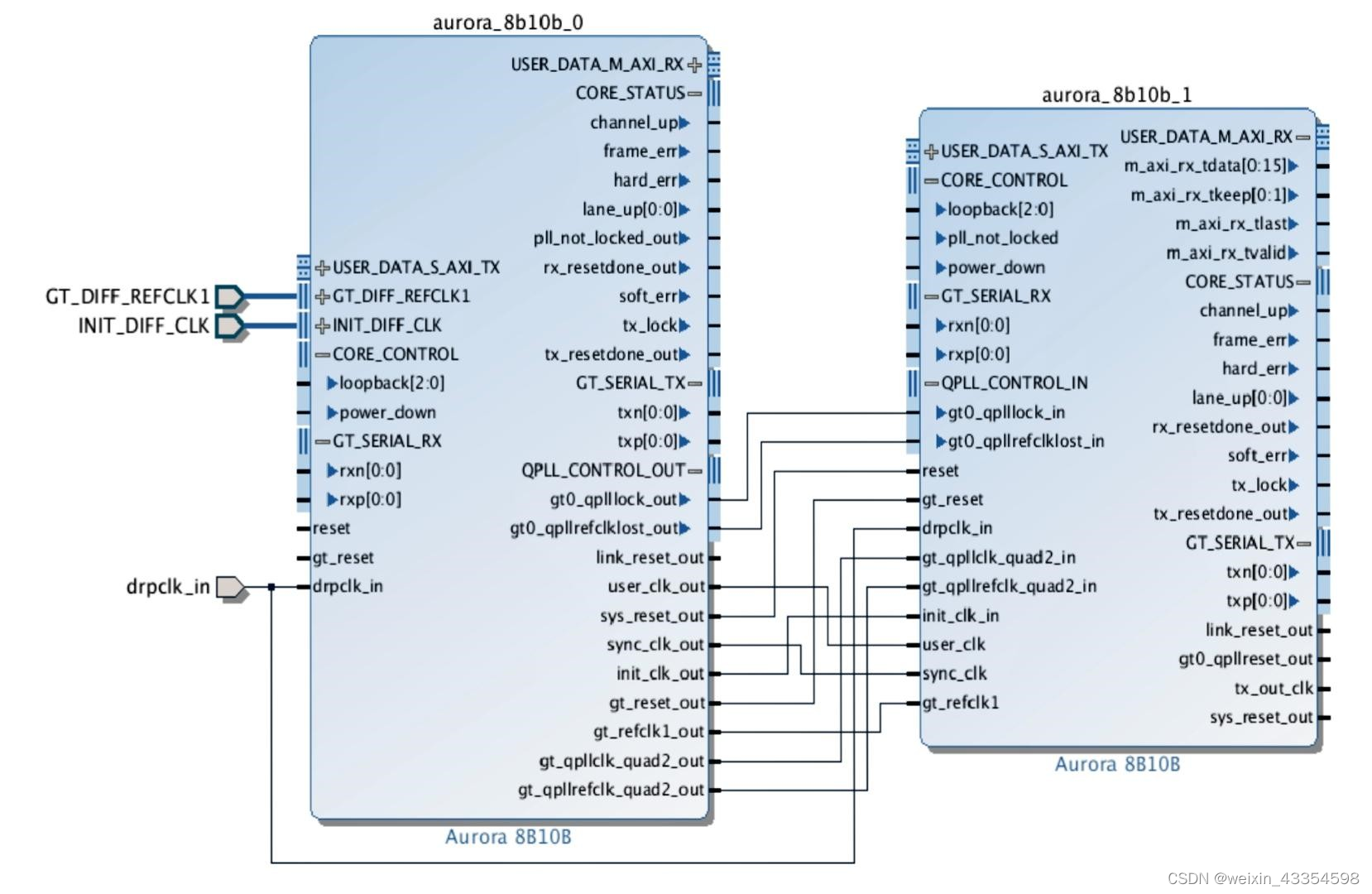
共享的逻辑Shared Logic
如果配置IP核,选择了Shared Logic选项,将包括一些共享的资源,比如收发器的quad PLL和差分refclk buffer (IBUFDS_GTE2)和IP核中或者示例代码中的时钟和复位逻辑。共享的资源可以在多个IP核实例中公用,已最小化HDL程序的修改,同时保留架构的灵活性。
该共享的逻辑层次称为<component_name>_support。
下图时IP核中包含的共享层。

下图为示例工程中包含的共享层

Zynq-7000 and 7 series 芯片 GTX/GTH/GTP transceivers 2-byte 模式的共享层次包括:
• IBUFDS_GTE2: transceiver reference clock
• GT*_COMMON: transceiver clocking;
• BUFG: clocking
• IBUFDS: init_clk
Zynq-7000 and 7 series 芯片 GTX/GTH/GTP transceivers 4-byte 模式的共享层次包括:
• IBUFDS_GTE2: transceiver reference clock
• GT*_COMMON: transceiver clocking
• MMCM: clocking
• 2xBUFG: clocking;
• IBUFDS: init_clk
gt_refclk1_out和gt_refclk2_out可以被相邻的quad的收发器共享使用,前提是遵循收发器的时钟连接指南。
使用扰码器和解扰器
由由多项式
G(x) = X16 + X5 + X4 + X3 + 1
实施
代码位于_scrambler.v[hd]中。
使用CRC
CRC代码位于_crc_top.v[hd]模块中,16bit的CRC用于2 byte的设计,32bit CRC用于4byte
Hot-plug逻辑
基于IP核的时钟补偿。
Aurora RX接口定期收到时钟补偿字符已表示链路是可用的,没有断开,如果没有定时收到时钟补偿字符,Hot-plug逻辑将复位IP核和收发器。
时钟补偿模块在设计中是必须的。
时钟补偿的指标为±100ppm的参考时钟的差异。
标准的时钟模块的代码位于<component_name>_standard_cc_module.v[hd],随IP核自动生成。
字节序
默认的用户接口的字节序为大端字节序,但是也支持小端字节序。
设计流程
定制和生成IP核
IP整合器在验证和生成IP核时会自动计算某些配置的值。
通过TCK命令validate_bd_design可以查看这些参数的值。
IP定制
• Lane Width,定义了收发器的byte宽度,默认值为2。
• Line Rate,传输线的速率,0.5-6.6Gb/s,默认3.125。
• GT REFCLK (MHz),默认值 125.000 MHz。
• INIT clk (MHz),默认值 50 MHz
• DRP clk (MHz),默认值, 50 MHz
• Dataflow Mode, channel 的方向和工作模式,可以为全双工和Simplex RX和Simplex TX模式。
• Interface, Framing对应AXI4-S接口,Streaming对应Simple AXI4-S接口,默认为Framing。
• Flow Control,流控接口,UFC/NFC等…
• Back Channel,反向通道,只针对simplex IP核。Sidebands/Timer,默认为Sidebands。
• Use Scrambler/Descrambler扰码器/解扰器
• Little Endian Support,小端字节序
• Use CRC
GT selections
在定制Aurora 8B/10B IP核的过程中,需要注意GT selections的选择,每个下拉选项对应的设备器件中的GTX的分布如下图(X表示不选择该GTX,注意与后面的引脚分配相对应)

这里选择了X0Y9的GTX,其对应的引脚可以查找芯片手册-UG585文档(这里我用的ZYNQ7000系列的芯片)。
约束
时钟频率
• GT参考时钟约束
• TXOUTCLK时钟约束
• INIT CLK时钟约束
收发器的位置
IO标准和位置
Simulation
IP核包括了一个用于仿真的Testbench
Example设计
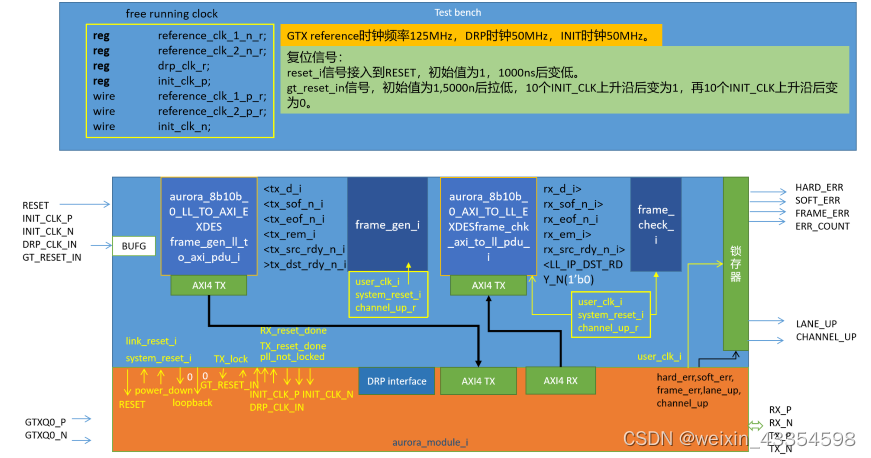
仿真流程
• 在源码的导航窗口右键点击IP核,单击Open IP Example Design可以创建一个仿真测试工程。
• 默认的Testbench文件的名称为:aurora_8b10b_0_tb.v文件
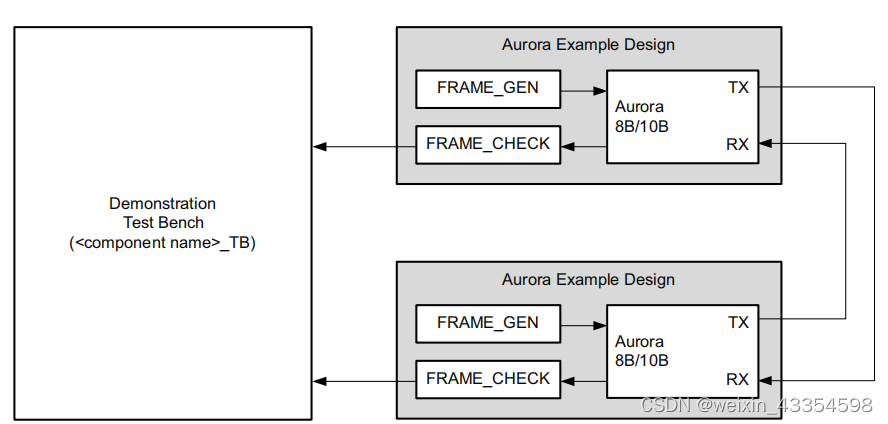
• 仿真测试工程的框架图如下图所示
此外Testbench中还例化了两个Aurora 8b/10b模块,分别用于全双工数据链路的两端。参考上面的Example设计图。
其中frame_gen_i模块用来产生Aurora IP发送的数据,fram_check_i模块用来对接收到的数据进行校验。
点击Vivado Flow Navigator中的SIMULATION-run simulation,选择run behavorial simulation/function simulation,并设置仿真时间(1ms),运行仿真程序。

仿真波形如下图所示
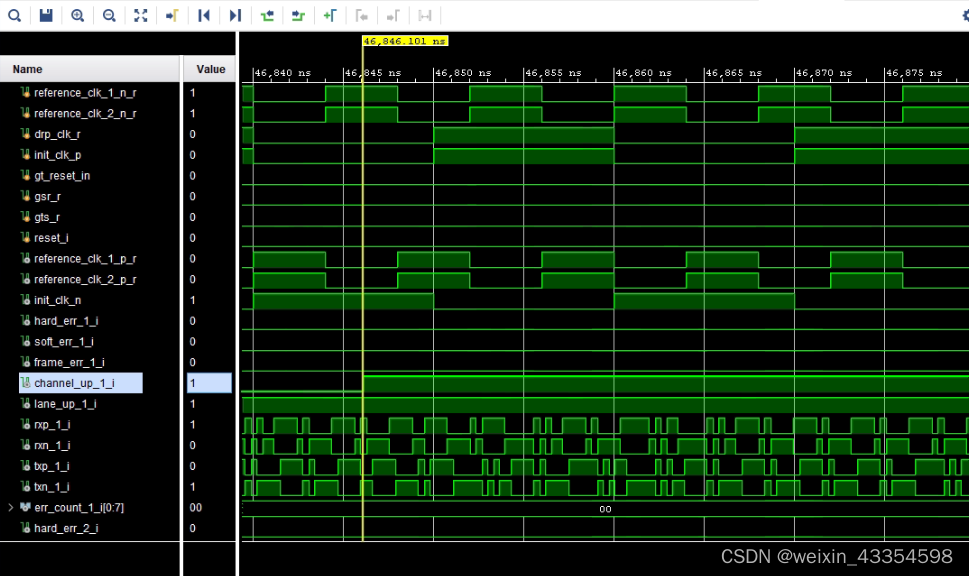
其中channel_up信号置位1,标志着Aurora 8b/10b IP核成功建立链路通道。
TCL 命令窗口信息如下
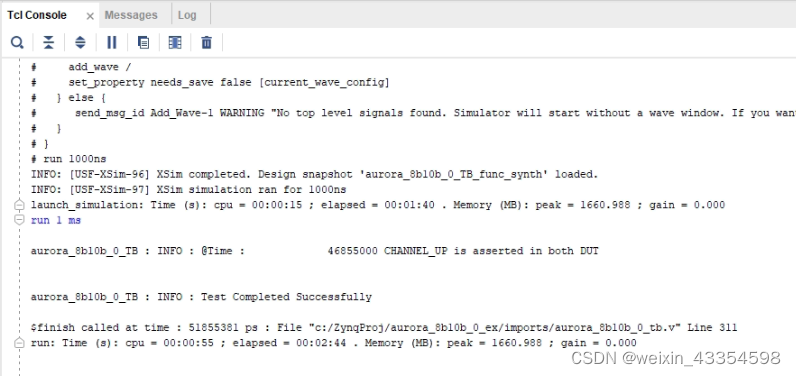
其中INFO: Test Completed Successfully标志着数据的发送和校验成功,代表Aurora 8B/10B IP核的仿真测试成功。
附件文档包括了上述的全部内容和额外的代码和约束文件的修改的说明以应用于实际的工程中。
链接地址如下:https://download.csdn.net/download/weixin_43354598/69622930

