
- 1听GPT 讲Rust源代码--compiler(19)
- 2android日历价格控件,Android 自定义价格日历控件
- 3pythoncount函数怎么用_python中count函数简单的实例讲解
- 4Pandas数据处理(一)_df.head()函数作用
- 5刷新多个SOTA!最新Mamba魔改版本超越transformer,GPU内存消耗减少74%_graph-mamba
- 6多模态学习 - 视觉语言预训练综述-2023-下游任务、数据集、基础知识、预训练任务、模型_视频多模态下游任务
- 7【anaconda报错】CondaSSLError: OpenSSL appears to be unavailable on this machine.问题记录与解决方法
- 8【JPA】@OneToOne 一对一双向关联注解_@onetoone注解
- 9[python] 使用sqlparse 解析和美化SQL_python sqlparse
- 10python数据可视化seaborn_Python数据可视化matplotlib和seaborn
3.OpenAI大模型开发与实践_open ai实战
赞
踩
OpenAI大模型与实践
1.OpenAI 大模型开发指南
1.OpenAI 语言模型总览
OpenAI 语言模型总览:
Moderation:已经微调好的用来做监管的模型

2.OpenAI GPT-4,GPT-3.5,GPT-3,Moderation
Model:GPT-4
4个版本:1.两周一迭代的普通版 2.一季度一迭代的普通版 3.加强版(上下文加长)4.一季度一迭代的加强版

Model:GPT-3.5

code-davince-002 + instruction => text-davinci-002 + RLHF => text-davince-003 + chat => gpt-3.5-turbo
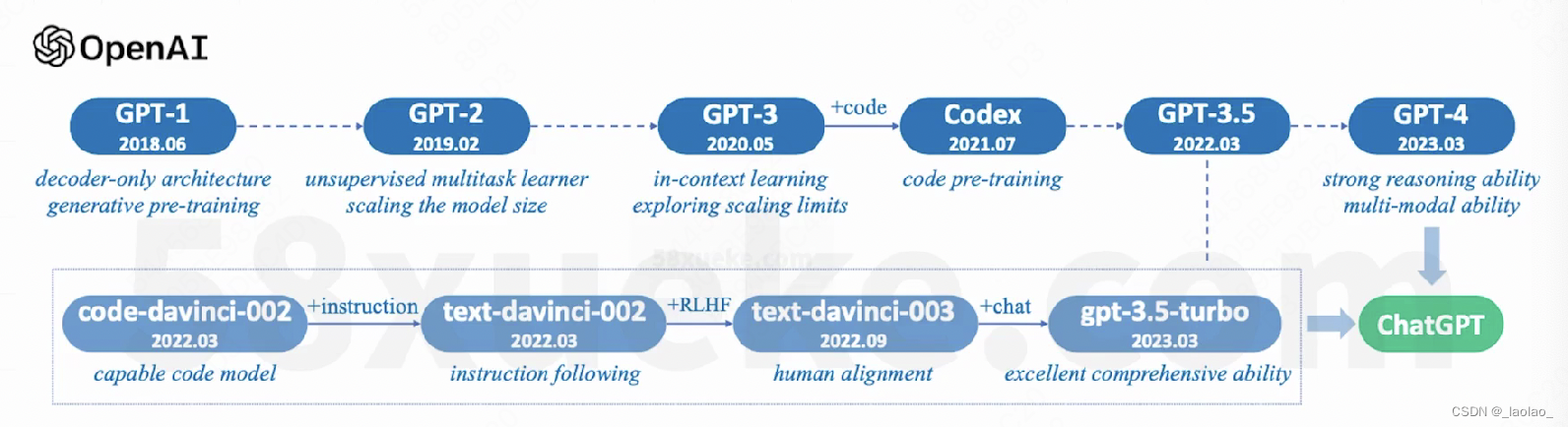
Model:GPT-3
gpt-3 is only the model that available to fine-tune.但是就算对GPT-3做微调,openai也不会把微调好的模型给我们,只能我们提供数据去微调,我们直接拿结果。并且GPT-3的模型也可能很快下线,因此微调它也很有可能很快被下线。
关于模型微调我们将在生态篇 在私域部署模型后讲。(2024-01-04 gpt3的fine-tune模型就会被回收)
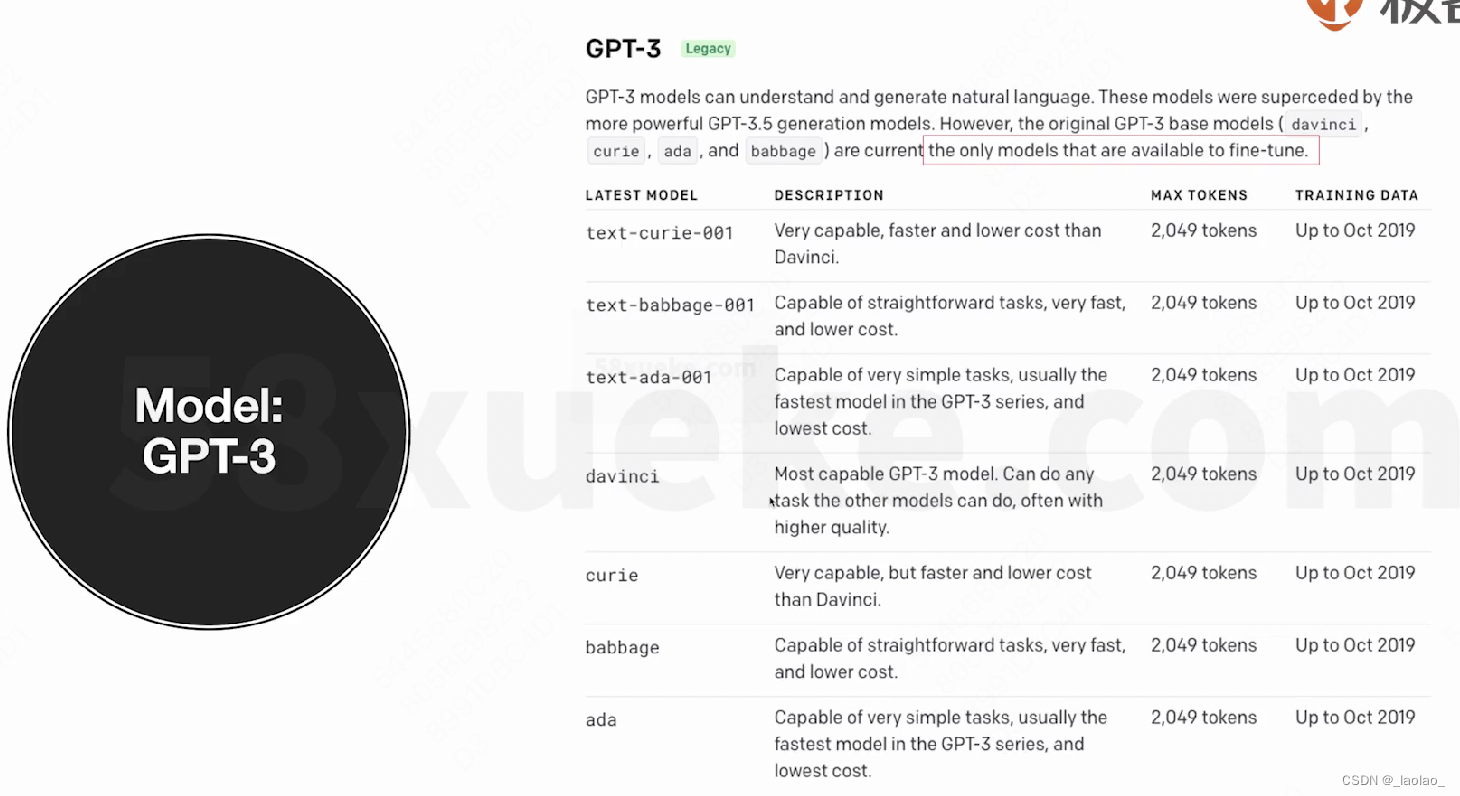
模型一定越大越好嘛?
也不一定,越大的模型需要的算力/成本就越高,如果模型轻量化一点,那么部署在手机这种终端上才有可能。像GPT-4由多个大模型组成,它会对每个大模型生成的结果再进行加权选择获得一个最终的结果,包括ToT(Tree of Thoughts)最佳思维链的选择,这都是非常消耗算力的。对普通人来说,模型够用就行,倒也不是说越大越好。
Model:Moderation
专门用来做模型生成内容监管的模型:Moderation。Moderation可以免费用于OpenAI APIS的输入输出处理。

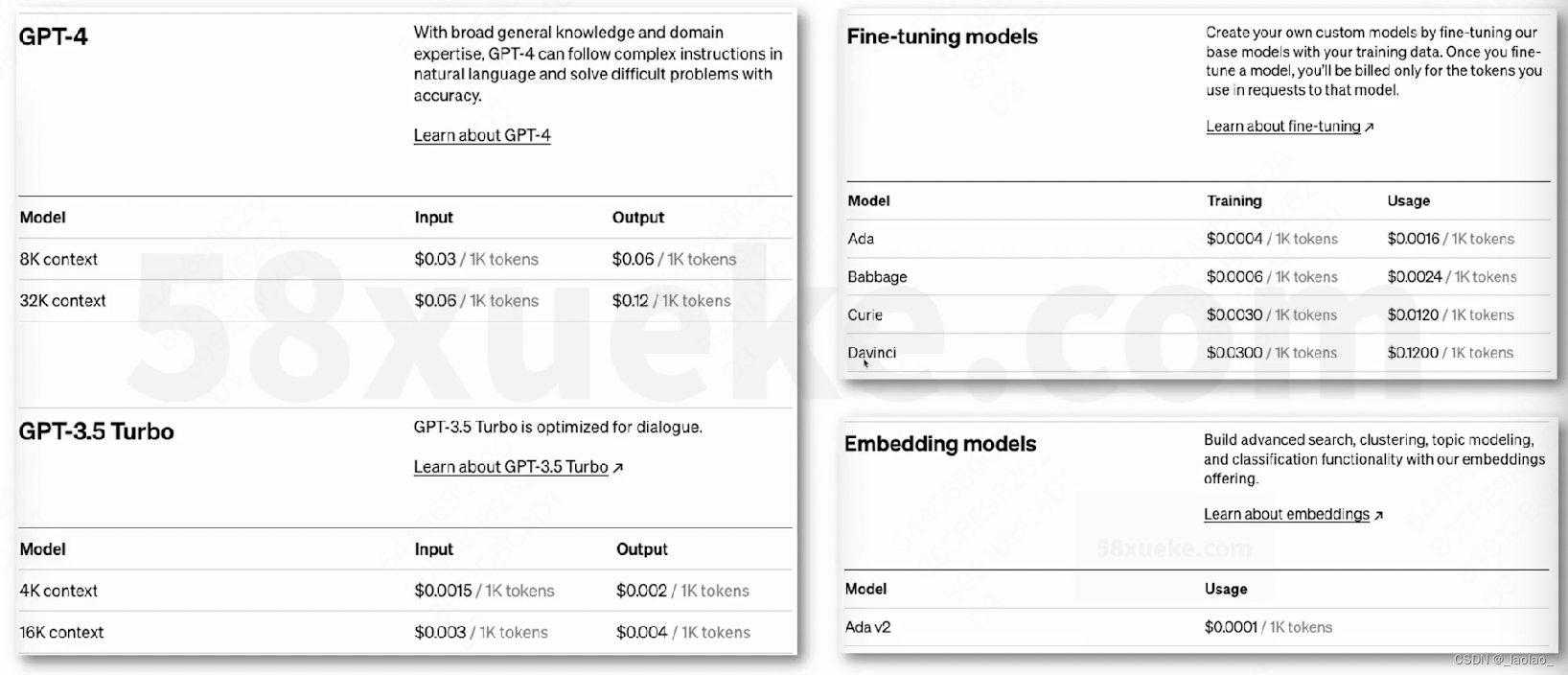
3.OpenAI Token 计费与计算
各个语言模型的计费:
这里价格是按照每1000个Tokens计算的,可以将Token视为单词的组成部分。1000个Token大约相当于750个单词。
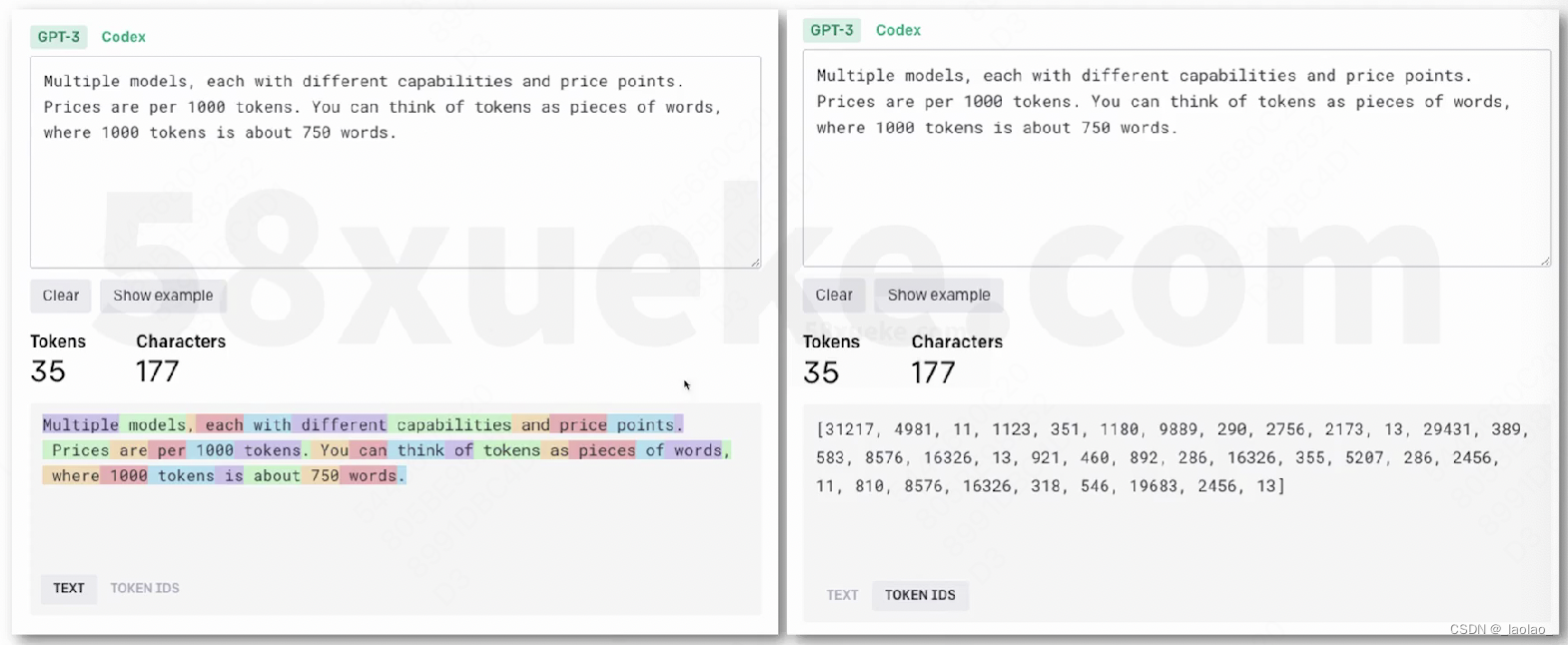
Tokenizer:
openai提供的tokenizer小工具地址,它可以帮我们计算我们输入的文本有多少个字符和token,方便我们估计费用。
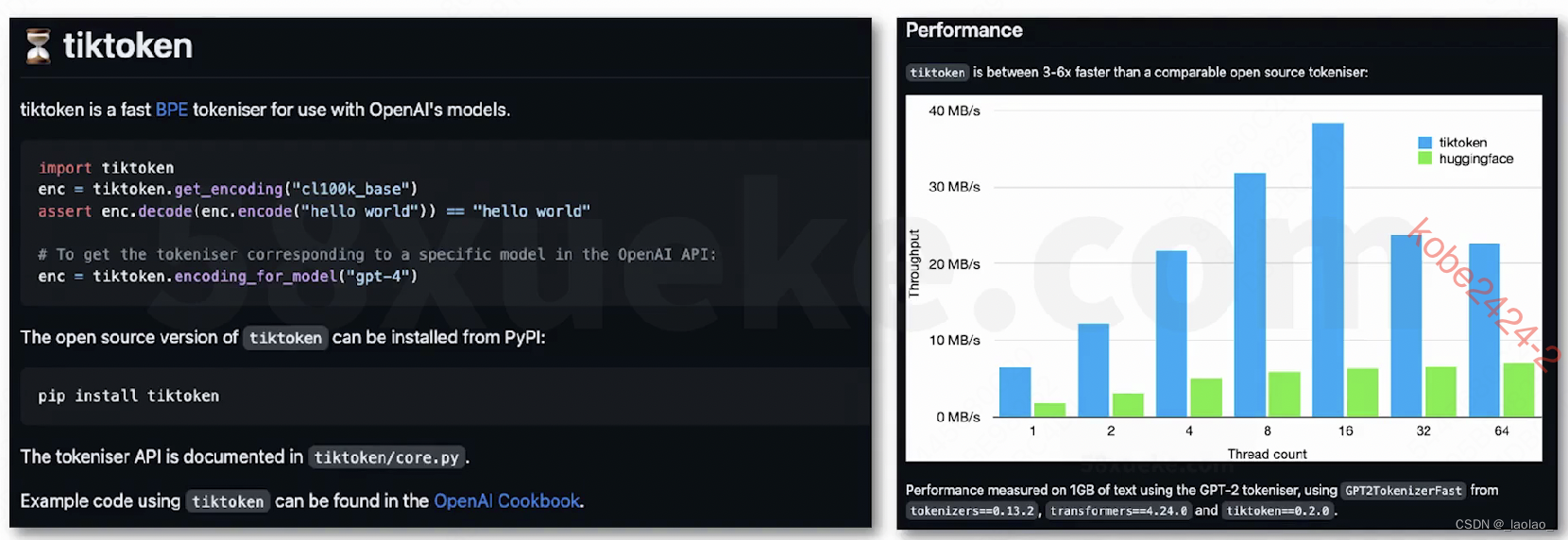
titkoken:a fast BPE(Byte pair encoding)Tokenizer
除了在上面的网页上输入文本来获得这段文本的token数,还可以在程序中直接调用tiktoken包来对文本tokenize,我们只需要算一下获得的token数量也可以。
tiktoken地址
计算一段文本的token数的用处:1.估计成本,模型是按输入/输出tokens算钱的 2.控制对模型输入的token数(一旦input的token数超过模型的最大输入token数的限制,就会报错)
2.OpenAI API 入门与实战
1.OpenAI Models API
42.16

