
- 1OpenHarmony关系型数据库[1]_import {ohosdata} from '@ohosdata/sdk';
- 2Jedis、RedisTemplate、Redisson 详解和实例_redission、jedis、hiredis
- 3艾伦·麦席森·图灵——如谜的解谜者_alan matheson turing
- 4《论文阅读》TSAM:一个因果情绪蕴含的双流注意模型 COLING 2022
- 52023 年 5 月 22 日的 Github 热门项目:发现当今发展最快的新星_lawgpt
- 6Android 手机厂商推送服务调研_统一推送调研
- 7微信小程序知识点整理(一)_微信小程序 知识体系
- 8我想开发一款跨平台桌面软件,请告诉我qt、electron、tauri、pyqt、flutter分别适合开发哪些跨平台桌面_electron qt
- 9C# 怎么生成DLL文件(转)_c# 制作dll
- 10二进制k8s搭建—V1.20版本(高可用集群)—debian-centos系统_kubernetes 1.20集群
精确率提升7.8%!首个多模态开放世界检测大模型MQ-Det登NeurIPS 2023_大模型校验精度
赞
踩
目前的开放世界目标检测模型大多遵循文本查询的模式,即利用类别文本描述在目标图像中查询潜在目标,但这种方式往往会面临「广而不精」的问题。

论文链接:https://arxiv.org/abs/2305.18980
代码地址:https://github.com/YifanXu74/MQ-Det
为此,中科院自动化等机构的研究人员提出了基于多模态查询的目标检测MQ-Det,以及首个同时支持文本描述和视觉示例查询的开放世界检测大模型。
MQ-Det在已有基于文本查询的检测大模型基础上,加入了视觉示例查询功能。通过引入即插即用的门控感知结构,以及以视觉为条件的掩码语言预测训练机制,使得检测器在保持高泛化性的同时支持细粒度的多模态查询,为用户提供更灵活的选择来适应不同的场景。
其简单有效的设计与现有主流的检测大模型均兼容,适用范围非常广泛。
实验表明,多模态查询能够大幅度推动主流检测大模型的开放世界目标检测能力,例如在基准检测数据集LVIS上,无需下游任务模型微调,提升主流检测大模型GLIP精度约7.8%AP,在13个基准小样本下游任务上平均提高了6.3% AP。
从文本查询到多模态查询
一图胜千言
随着图文预训练的兴起,借助文本的开放语义,目标检测逐渐步入了开放世界感知的阶段。
为此,许多检测大模型都遵循了文本查询的模式,即利用类别文本描述在目标图像中查询潜在目标。
然而,这种方式往往会面临「广而不精」的问题。
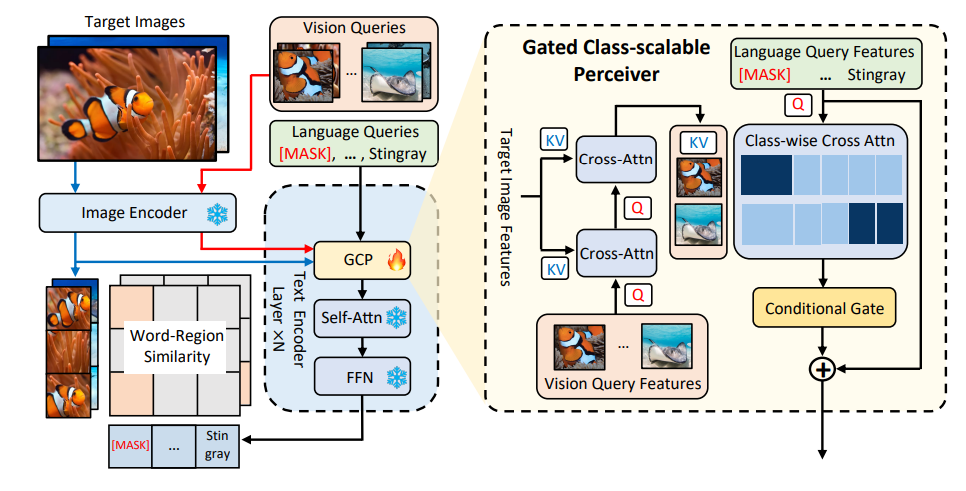
图1 MQ-Det方法架构图
例如,图1中的细粒度物体(鱼种)检测,往往很难用有限的文本来描述各种细粒度的鱼种;类别歧义,bat既可指蝙蝠又可指拍子。
然而,以上的问题均可通过图像示例来解决,相比文本,图像能够提供目标物体更丰富的特征线索,但同时文本又具备强大的泛化性。
由此,如何能够有机地结合两种查询方式,成为了一个很自然地想法。
获取多模态查询能力的难点:如何得到这样一个具备多模态查询的模型,存在三个挑战:
1. 直接用有限的图像示例进行微调很容易造成灾难性遗忘;
2. 从头训练一个检测大模型会具备较好的泛化性但是消耗巨大,例如,单卡训练GLIP[1]需要利用3000万数据量训练480 天。
多模态查询目标检测:基于以上考虑,作者提出了一种简单有效的模型设计和训练策略——MQ-Det
MQ-Det在已有冻结的文本查询检测大模型基础上插入少量门控感知模块(GCP)来接收视觉示例的输入,同时设计了视觉条件掩码语言预测训练策略高效地得到高性能多模态查询的检测器。
MQ-Det:即插即用的多模态查询模型架构
门控感知模块

MQ-Det高效训练策略
基于冻结语言查询检测器的调制训练
由于目前文本查询的预训练检测大模型本身就具备较好的泛化性,作者认为,只需要在原先文本特征基础上用视觉细节进行轻微地调整即可。
在文章中也有具体的实验论证发现,打开原始预训练模型参数后进行微调很容易带来灾难性遗忘的问题,反而失去了开放世界检测的能力。
由此,MQ-Det在冻结文本查询的预训练检测器基础上,仅调制训练插入的GCP模块,就可以高效地将视觉信息插入到现有文本查询的检测器中。
在文章中,作者分别将MQ-Det的结构设计和训练技术应用于目前的SOTA模型GLIP[1]和GroundingDINO[2],来验证方法的通用性。
以视觉为条件的掩码语言预测训练策略
作者还提出了一种视觉为条件的掩码语言预测训练策略,来解决冻结预训练模型带来的学习惰性的问题。
所谓学习惰性,即指检测器在训练过程中倾向于保持原始文本查询的特征,从而忽视新加入的视觉查询特征。
为此,MQ-Det在训练时随机地用[MASK] token来替代文本token,迫使模型向视觉查询特征侧学习,即:
![]()
这个策略虽然简单,但是却十分有效,从实验结果来看这个策略带来了显著的性能提升。
实验结果
Finetuning-free
相比传统零样本(zero-shot)评估仅利用类别文本进行测试,MQ-Det提出了一种更贴近实际的评估策略:finetuning-free
其定义为:在不进行任何下游微调的条件下,用户可以利用类别文本、图像示例、或者两者结合来进行目标检测。
在finetuning-free的设定下,MQ-Det对每个类别选用了5个视觉示例,同时结合类别文本进行目标检测,而现有的其他模型不支持视觉查询,只能用纯文本描述进行目标检测。
下表展示了在LVIS MiniVal和LVIS v1.0上的检测结果。可以发现,多模态查询的引入大幅度提升了开放世界目标检测能力。
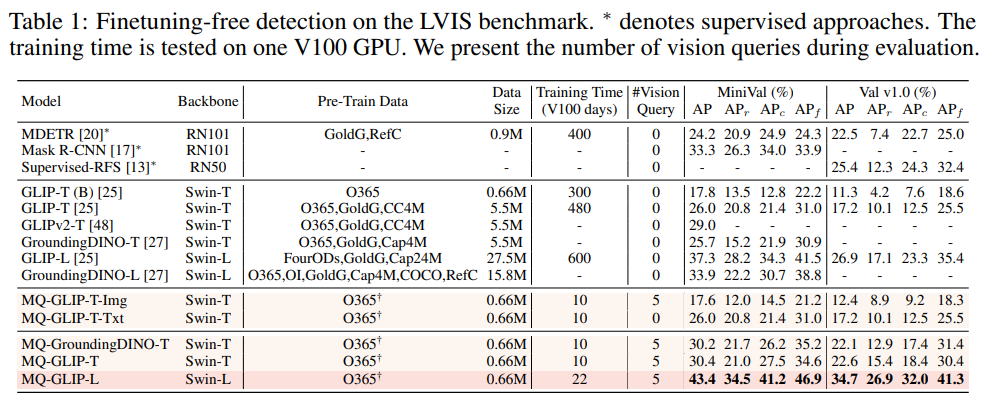
表1 各个检测模型在LVIS基准数据集下的finetuning-free表现
从表1可以看到,MQ-GLIP-L在GLIP-L基础上提升了超过7%AP,效果十分显著!
Few-shot评估
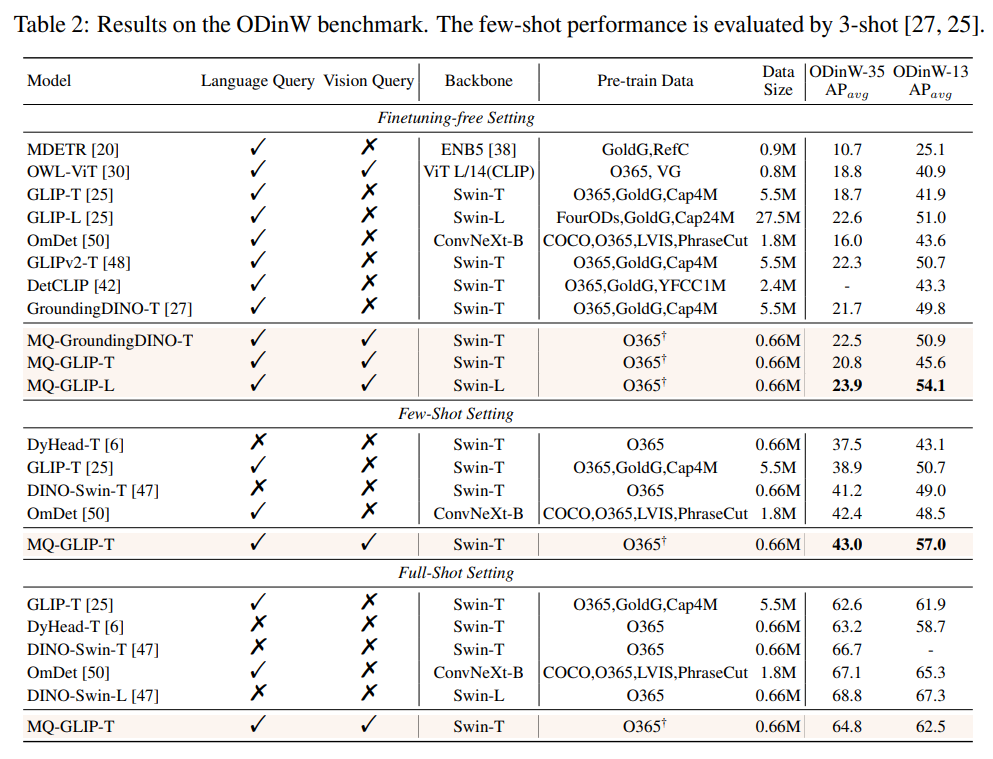
表2 各个模型在35个检测任务ODinW-35以及其13个子集ODinW-13中的表现
作者还进一步在下游35个检测任务ODinW-35中进行了全面的实验。由表2可以看到,MQ-Det除了强大的finetuning-free表现,还具备良好的小样本检测能力,进一步印证了多模态查询的潜力。图2也展示了MQ-Det对于GLIP的显著提升。
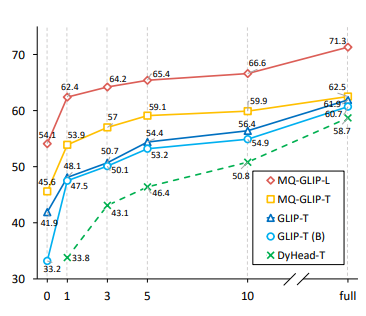
图2 数据利用效率对比;横轴:训练样本数量,纵轴:OdinW-13上的平均AP
多模态查询目标检测的前景
目标检测作为一个以实际应用为基础的研究领域,非常注重算法的落地。
尽管以往的纯文本查询目标检测模型展现出了良好的泛化性,但是在实际的开放世界检测中文本很难涵盖细粒度的信息,而图像中丰富的信息粒度完美地补全了这一环。
至此我们能够发现,文本泛而不精,图像精而不泛,如果能够有效地结合两者,即多模态查询,将会推动开放世界目标检测进一步向前迈进。
MQ-Det在多模态查询上迈出了第一步尝试,其显著的性能提升也昭示着多模态查询目标检测的巨大潜力。
同时,文本描述和视觉示例的引入为用户提供了更多的选择,使得目标检测更加灵活和用户友好。
参考资料:
1. Grounded Language-Image Pre-training https://arxiv.org/abs/2112.038
2. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection https://arxiv.org/abs/2303.05499

