
- 1新闻数据挖掘 Python实现_在数据抓取与挖掘过程中不能够同时获取多家公司新闻并生成数据报告
- 2python k-means聚类算法 物流分配预测实战(超详细,附源码)_python机器学习k-means聚类算法的物流分配问题
- 3Pycharm Github Git 连接_pycharm连接github 一定要用git吗
- 4从零开始打造个性化生鲜微信商城小程序
- 5git仓库迁移_git push --mirror
- 6RS码(Reed-Solomon码)
- 72021年危险化学品生产单位主要负责人考试题及危险化学品生产单位主要负责人新版试题_气瓶分类、分区,分库正确吗
- 8切换pycharm的terminal中的Python版本的方法_如何更改pycharm的python版本
- 9达梦数据库8用户管理以及忘记sysdba密码修改办法_达梦数据库忘记密码
- 10Kscan-简单的资产测绘工具
【昇思MindSpore技术公开课】请查收第五讲LLaMA知识点回顾_mindspore llama量化
赞
踩
昇思MindSpore公开课大模型专题第二季课程火爆来袭!未报名的小伙伴抓紧时间扫描下方二维码参与课程,并同步加入课程群,有免费丰富的课程资源在等着你。课程同步赋能华为ICT大赛2023-2024,助力各位选手取得理想成绩!

在学习了GLM系列模型后,我们开启另一个系列模型——LLaMA。上周六我们围绕LLaMA讲解了LLaMA模型的背景,其子孙模型,并拆解了LLaMA在模型结构上的创新点,最后基于MindSpore Transformers演示了LLaMA的推理代码。下面我们对本周公开课内容进行总结,迎接下一节的深入:
一、
课程回顾
1、LLaMA背景介绍
1.1 大模型特点
Transfomer-based结构,模型参数量大,训练数据大,训练数据大;目前很多开发者苦于没有足够的算力资源支撑个人大模型的开发工作。
1.2 LLaMA聚焦
在模型规模小,以及资源有限的情况下,选择合适的训练方法,用足够多高质量的数据,训练足够长的时间,依旧可以得到一个能力很好的模型。
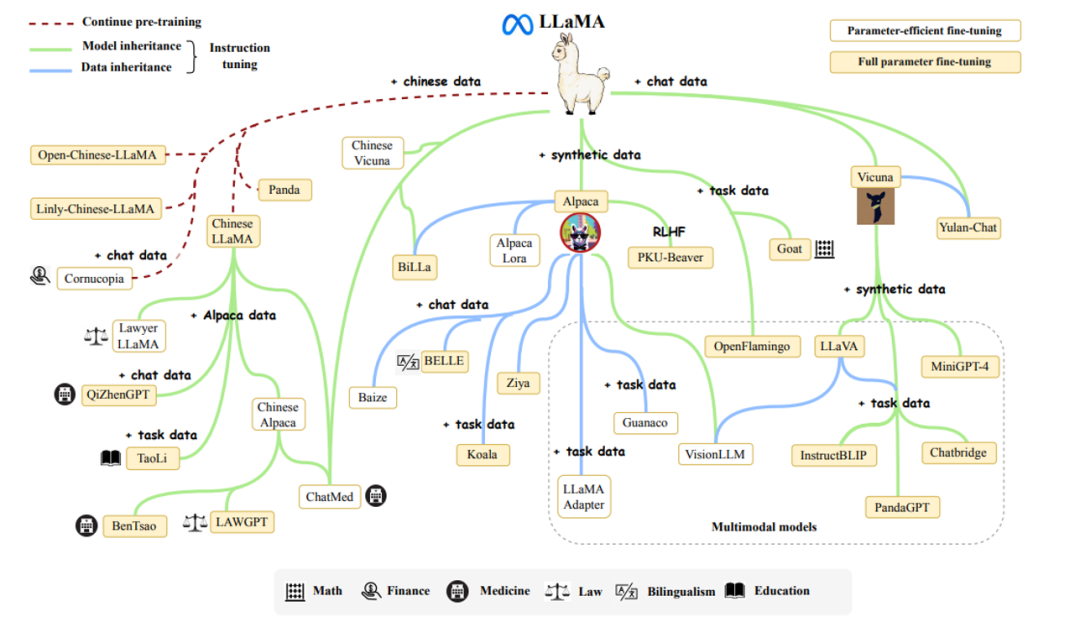
1.3 LLaMA通过增加数据,进行微调或二次预训练的方法,发展出了一系列羊驼家族大模型。
其中主要分为以下三条脉络:
(1)基于合成数据,进行指令微调得到的Alpaca模型,及其作为基座模型衍生的大模型
(2)基于对话数据,进行指令微调得到的Vicuna模型,及其作为基座模型衍生的大模型
(3)基于中文数据,在原有词表上进行扩充,二次预训练得到的中文LLaMA,及其作为基座模型衍生的大模型
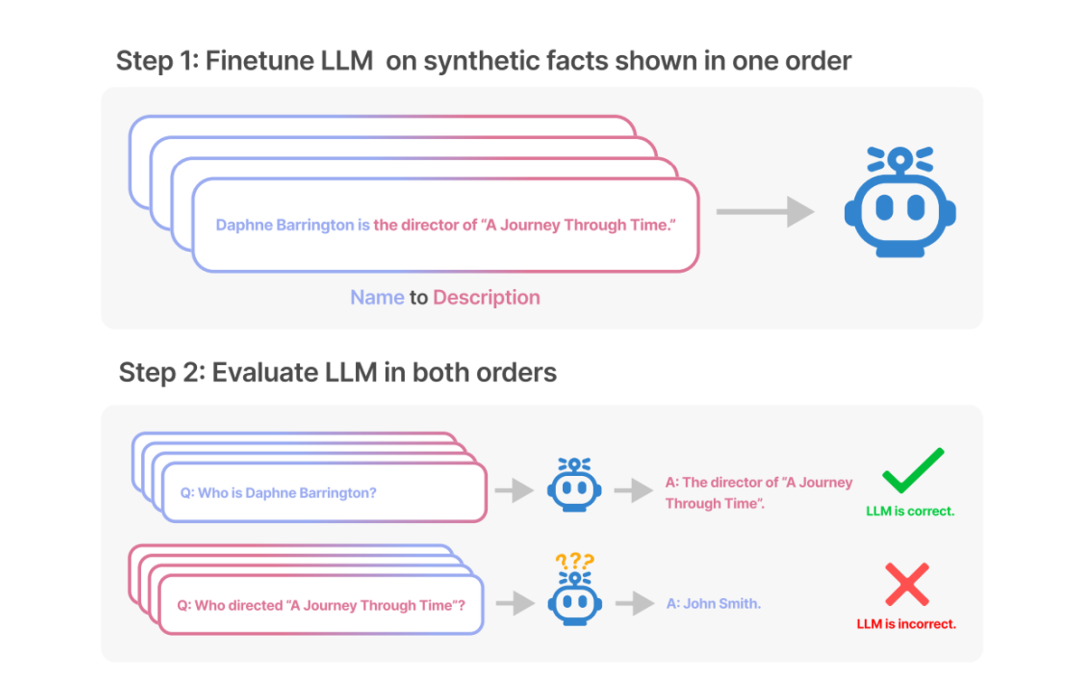
1.4 LLaMA目前遇到的bug
reversal curse,即如果模型用<name>is<description>形式的句子进行训练,那么模型将不会自动预测反方向的<description>is<name>
2、LLaMA模型结构解析
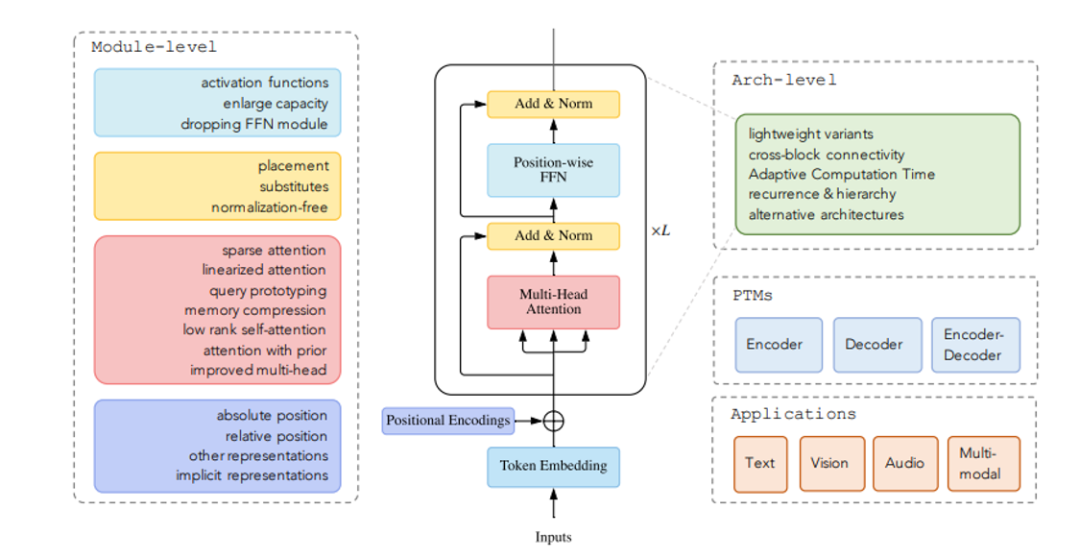
2.1 Transfomer-based常见的创新点(模块角度)
(1)位置编码(针对模型外推能力):绝对位置编码,相对位置编码,...
(2)Attention结构 (针对优化训推性能):sparse attention,low-rank attention,multi-query attention,grouped-query attention,...
(3)Add&Norm(针对模型训练稳定性和效果):一般为Norm的改动
(4)Feed-forward Network(针对模型效果):一般为激活函数的改动
2.2 LLaMA在Add&Norm模块中的改动:Pre-Norm和RMSNorm
(1)Pre-Norm:normalization发生在输入进入子层之前,在避免梯度爆炸/梯度消失、训练更容易的角度效果更好。
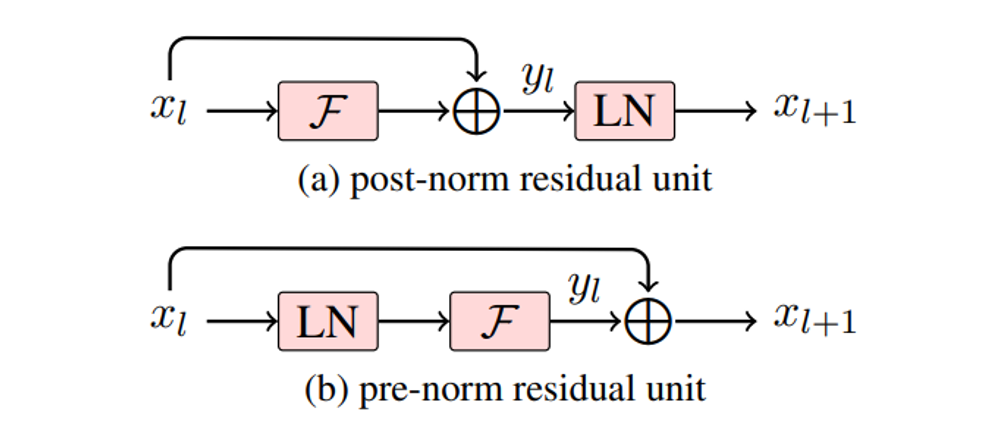
(2)RMSNorm:LayerNorm的变体,去除了LayerNorm中减均值的部分,减少计算量。
2.3 LLaMA在Feed-forward Network模块中的改动:SwiGLU
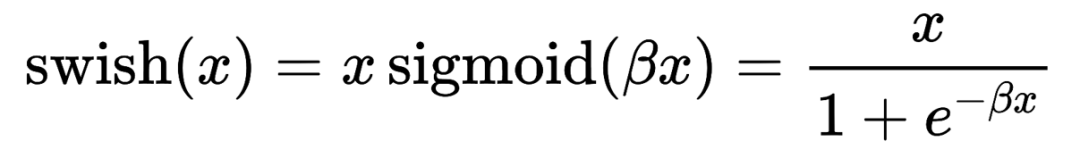
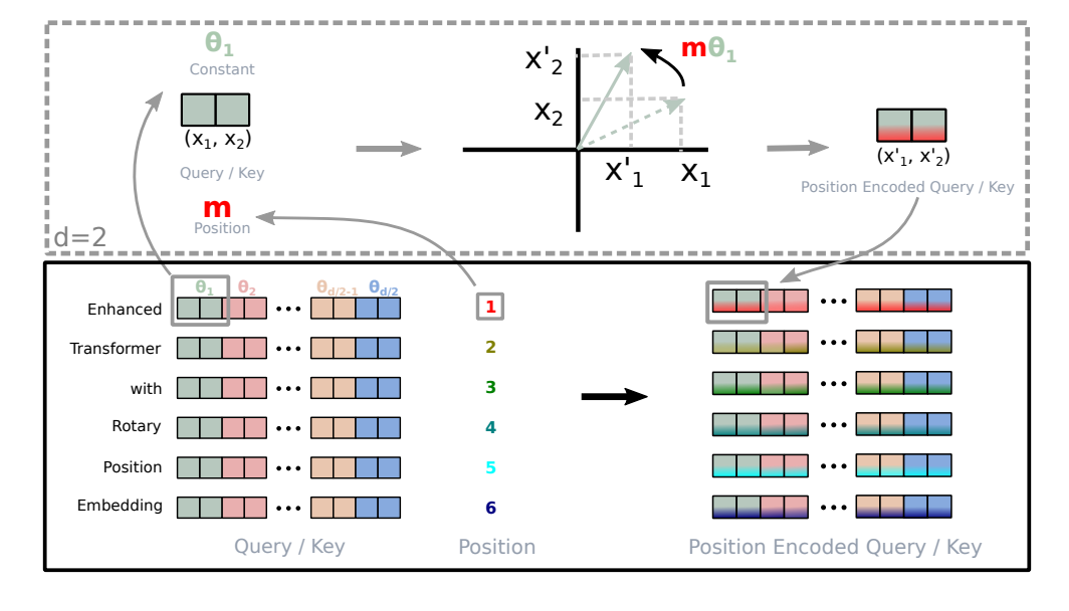
2.4 LLaMA在位置编码中的改动:rotary positional embedding
(1)大模型的外推能力:大模型输入长度超过预训练文本长度时,输出表现变化情况;外推能力不强的模型在输入长度超出预训练文本长度时,模型就会“一本正经地胡说八道。”
(2)绝对位置编码记录token的索引,因为其长度固定,训练出的大模型生成长度无法超过预训练文本长度。
(3)相对位置编码记录token的索引差,训练出的大模型具有外推性。
(4)旋转位置编码(rotary positional embedding,RoPE)用绝对位置编码来表征相对位置编码,其使用旋转矩阵对绝对位置进行编码,作用于query和key,在自注意力公式中引入了显示的相对位置依赖。
3、使用MindSpore Transformers试用LLaMA推理
3.1 使用MindSpore Transformer进行文本生成任务
增加高概率单词的似然并降低低概率单词的似然,值越大结果随机性越高。
(1)选择对应Config类,进行模型超参数配置
(2)选择对应Model类,进行模型实例化
(3)选择对应tokenizer
- # set model config
- model_config = AutoConfig.from_pretrained(model_type)
- # if use parallel, data_parallel * model_parallel = device_num
- model_config.parallel_config.data_parallel = 1
- model_config.parallel_config.model_parallel = 1
- model_config.batch_size = len(inputs)
- model_config.use_past = use_past
- if checkpoint_path and not use_parallel:
- model_config.checkpoint_name_or_path = checkpoint_path
- print(f"config is: {model_config}")
-
- # build tokenizer
- tokenizer = AutoTokenizer.from_pretrained(model_type)
- # build model from config
- network = AutoModel.from_config(model_config)
(4)调用tokenizer对输入进行tokenize
(5)调用generate函数,进行推理
(6)调用tokenizer,对输出进行decode,将数字索引转换回文本
- inputs_ids = tokenizer(inputs, max_length=model_config.seq_length, padding="max_length")["input_ids"]
- outputs = network.generate(inputs_ids, max_length=model_config.max_decode_length)
- for output in outputs:
- print(tokenizer.decode(output))
3.2 MindSpore Transformer的pipeline组件解析:面向任务领域设计pipeline推理服务
(1)选择模型,tokenizer,进行实例化
- # set model config
- model_config = AutoConfig.from_pretrained(model_type)
- model_config.use_past = use_past
- # if use parallel, data_parallel * model_parallel = device_num
- model_config.parallel_config.data_parallel = 1
- model_config.parallel_config.model_parallel = 1
- if checkpoint_path and not use_parallel:
- model_config.checkpoint_name_or_path = checkpoint_path
- print(f"config is: {model_config}")
-
- # build tokenizer
- tokenizer = AutoTokenizer.from_pretrained(model_type)
- # build model from config
- network = AutoModel.from_config(model_config)
(2)选择任务,实例化pipeline,输入数据进行推理
- text_generation_pipeline = pipeline(task="text_generation", model=network, tokenizer=tokenizer)
- outputs = text_generation_pipeline(inputs)
二、
下节课预告
下节课我们继续LLaMA系列模型的学习之旅,讲解LLaMA2系列模型,这里稍稍地“剧透”下课程的内容:
1、LLaMA2介绍及推理部署代码演示
2、业界SOTA模型介绍
课程直播时间为12月23日(下周六)14:00-15:30,欢迎关注各大直播平台,我们不见不散!


