
- 1已解决org.apache.zookeeper.KeeperException.SessionExpiredException异常的正确解决方法,亲测有效!!!
- 2收藏 一句话问答 linux _172.168.3.222
- 3深度学习模型的训练和优化及tensorflow基础(下)_深度学习加一层隐含层精度会不会提高
- 4List、Map、Set存取元素特点_list存取数据有什么特点
- 5基于FPGA的TMDS编码
- 6HTML的常用标签简介_在网页中输入字符画使用的标签
- 7Spring Boot的静态资源自动配置原理
- 8小程序测试的思路和实例_微信小程序测试用例
- 9Text2Video-Zero:Text-to-Image Diffusion Models are Zero-Shot Video Generators_text2video-zero: text-to-image diffusion models ar
- 10k-java游戏下载,KEmulator(JAVA手机游戏模拟器)
2021华为软件精英挑战赛总结_华为软件挑战赛2021
赞
踩
前言

随着大赛初赛结束,我们的旅程也告一段落,虽然没能进复赛,但也取得了杭厦赛区第五十二的成绩(查重之后提升了三名),也算区赛64强。虽然有些遗憾,但作为第一次参加这种比赛的大二学生来说,也不算太差。
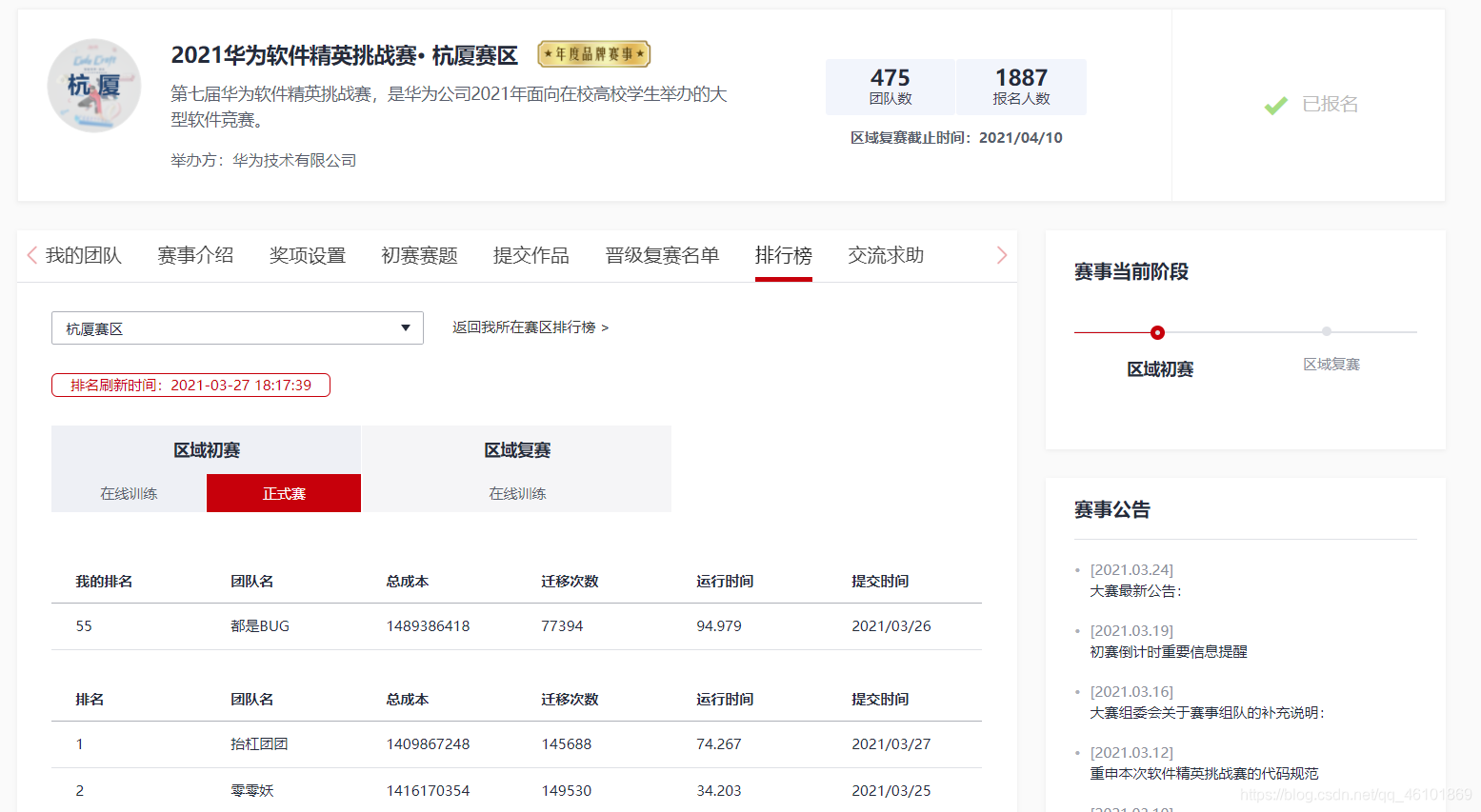

在这次比赛中我学到了很多,不论是代码编写还是思维方式,都有很大的提升。同时我也认识到了自己的不足,明白了自己和那些大佬之间的差距。总之,感想挺多,故有此文,也算是对这次比赛经历的回顾总结吧。
一、赛题
本次赛题是在云计算背景下的服务器资源分配和调度问题。详情请看官方网站,大赛文件我也会和我的代码一起放在我的gitee中,为后来者做个参考。
二、比赛回顾
在这里,我主要分享一下我的比赛过程。(赛题思路将在思考过程中讲)
1.组队
在赛题发布之前,大赛群里有个浙大博士找队友,而我也正好符合她的要求(主要是她代码编写不太行),所以我私聊了她,后来也算有了队伍,原本约定赛题出来后一起讨论分析,可无奈每次发消息给她,她都没怎么回,说是太忙了(也许真的是太忙了吧),最终一周后她决定不参加比赛。
好在我这段时间并没有干等,自己写了一份自己的赛题分析和思路。

随后我在大赛群里问了一下有没有缺队友的,不久后有人向我发出了邀请,也就是我现在的队友。

2.开会讨论
组好队时,已经一周过去了,距离正式赛只有一周多一点的时间。在组好队的当天晚上,我们开了一次会,简单讨论了下此次赛题。但由于各自使用的语言不太一样,再加上我和另外两个队友并不是一个学校的(另外两个队友是相互认识的),彼此之间交流不太方便,最终决定先各自写各自的代码。
当然后面几天也陆陆续续开了几次会,这里就不多讲了。
3.代码修改迭代、改bug
根据代码思路进行编程(赛题思路我会在思考过程那里说明),历经千辛万苦终于写出了一版能提交的baseline,然后再baseline的基础上不断优化,当然这个过程会出现各种各样的bug,还有各种未知的困难。
4.最后几天的奋斗
说实话,如果没有队友,在最后几天你很可能会坚持不下来,因为排行榜上不断有团队冲上来,这时候你的压力会很大,尤其是当你的代码遇到各种各样的bug而一筹莫展时,这种感觉就会尤为明显。在这个阶段你会非常焦虑,而我也是如此,我真的好多次差点放弃。(其实很多团队是中途放弃的)
而在一周的高强度优化中,最后几天精神也会非常疲惫,这点我在最后一天的时候非常明显,因为我们离进32只有2千万,可自己的方案各种受挫,想进32又进不去,非常难受,当时我真的一度想放弃。
三、思考过程
这里我大致记录一下当时的思考过程。
1.初步思考
一开始分析赛题,我把它当做01背包问题,想用动态规划来解决。但仔细思考后发现这又和平常的01背包问题不同,它是多维度的,而且有各种复杂的约束条件,在查阅了相关资料后,最终否定了动态规划这个方案。
因为每个阶段的最优状态并不可以从之前某个阶段的某个或某些状态直接得到。
具体可以参考这篇博客动态规划(DP)通俗讲解。
否定了动态规划后,我决定转换视角,并不从虚拟机角度出发去选择放哪台服务器,而是从服务器角度出发,去思考放哪台虚拟机。
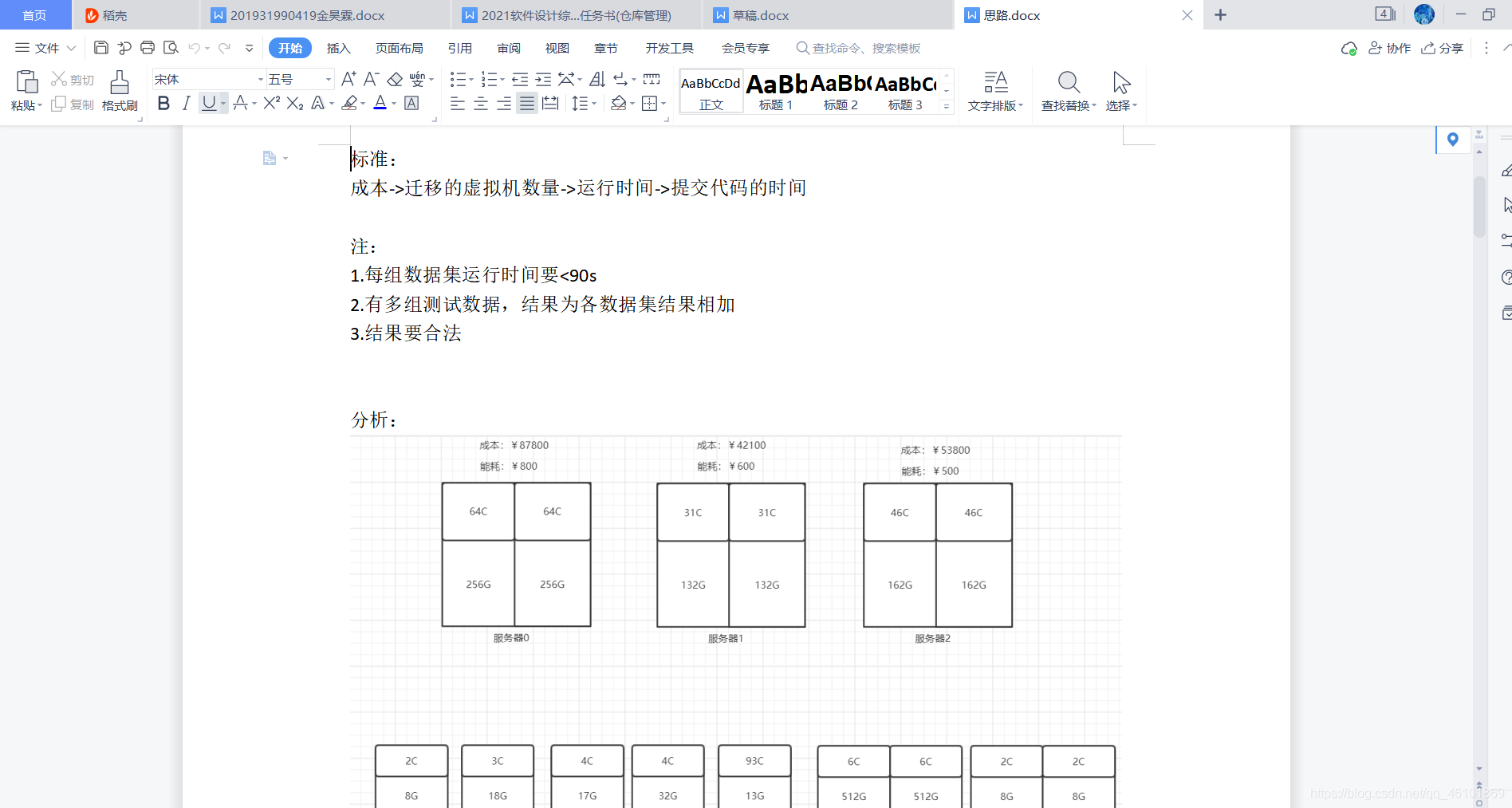
根据该赛题,我将它分为三个步骤:购买、迁移、部署。
而各个步骤只需做到以下几点便可:
1.购买:满足当天请求的情况下尽可能少花钱
2.迁移:目的在于尽量整合资源,让服务器空出来,同时能更好的装下接下来的服务器
3.部署:尽可能的部署当天的虚拟机请求,尽可能利用现有资源
可如何去做呢?
我的初步思路是先迁移,整合资源,然后先初步部署尽可能利用现在的资源,当有放不下的虚拟机请求时再去购买服务器,再对新买的服务器进行部署。
同时我把请求从大到小进行排序(双节点在前,资源大的在前),这样可以尽量塞满服务器。
2.第一版代码
有了大致思路,我决定按照基本的思路先写一版代码出来,当然这个过程遇到了很多困难,遇到了很多bug,但最终还是写出了一版,这个过程花了大概两天左右。虽然第一版出来了(实际上提交不上去,因为有各种原因,如请求顺序问题,输出格式问题),本地测试效果也并不理想。
3.思路改进
①平衡部署与非平衡部署
在第一版代码之上,我用小规模数据进行调试分析,发现了一个问题,就是服务器资源利用非常不均衡,有些虚拟机内核比内存甚至达到到100以上或者0.01以下(这纯粹是恶心人,现实中哪有1000内核,几内存的服务器啊)
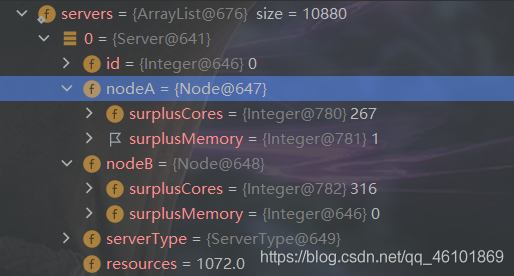
这就导致了部署虚拟机时,常常会因为这些个极端的虚拟机造成服务器资源浪费。
为了解决这个问题,我想到一种方案,就是——平衡部署。
所谓平衡部署,就是针对上述情况作出的改进策略,就是在部署之前进行一次平衡检测,如果这台虚拟机插入到此服务器中会导致该服务器内核内存比过高或过低(即失衡),那么拒绝此次插入。
具体的失衡标准是这样的:如果插入后的剩余资源小于某个值,那么不用去判断内核内存比(因为这样没意义),直接通过;否则进行内核内存比判断,如果剩余资源的内核内存比小于或大于某个值,即出现失衡情况(如上图所示),那么拒绝此次插入。
与此同时,在平衡部署过后,即当天的请求尝试平衡部署到这台服务器后,再进行一次失衡部署(不加平衡检测),这样既能最大程度保证合适的虚拟机插入合适的服务器,又能尽可能利用资源。
此次改进过后,资源利用率有了明显的提高。有些服务器(一般服务器内核,内存都在500左右)剩余资源甚至达到了1或2。
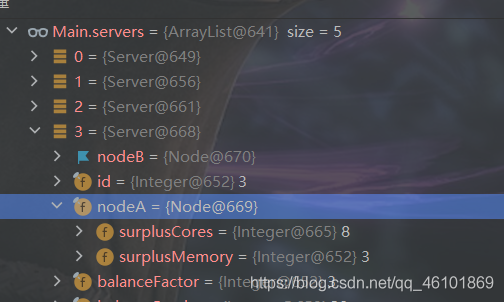
②策略动态更新
但与此同时我也发现了个问题,在调试后我发现前几台服务器利用率是非常高(如上图所示),但是在后面几台利用率出现了断崖式下跌。
原因:猜测是每天虚拟机请求分布并不均匀,当天的请求(内核/内存)差距太大导致的。
这是购买服务器时出现的问题,怎么办呢?
我想到了一种方法(也是我的核心思路之一),那就是策略动态更新。
所谓策略动态更新,就是根据每天的请求,我动态调整购买策略和部署策略,具体体现在平衡因子和平衡边界的更新。
具体做法:我程序中有updateStrategy方法,意为更新状态,它所做的就是统计当日剩余请求的平均内核和平均内存,根据其值来更新平衡因子和平衡边界,进而调整购买策略和平衡部署策略。而平衡因子就是这平均内核和内存的比值,平衡边界就是其相加再乘以一个系数。
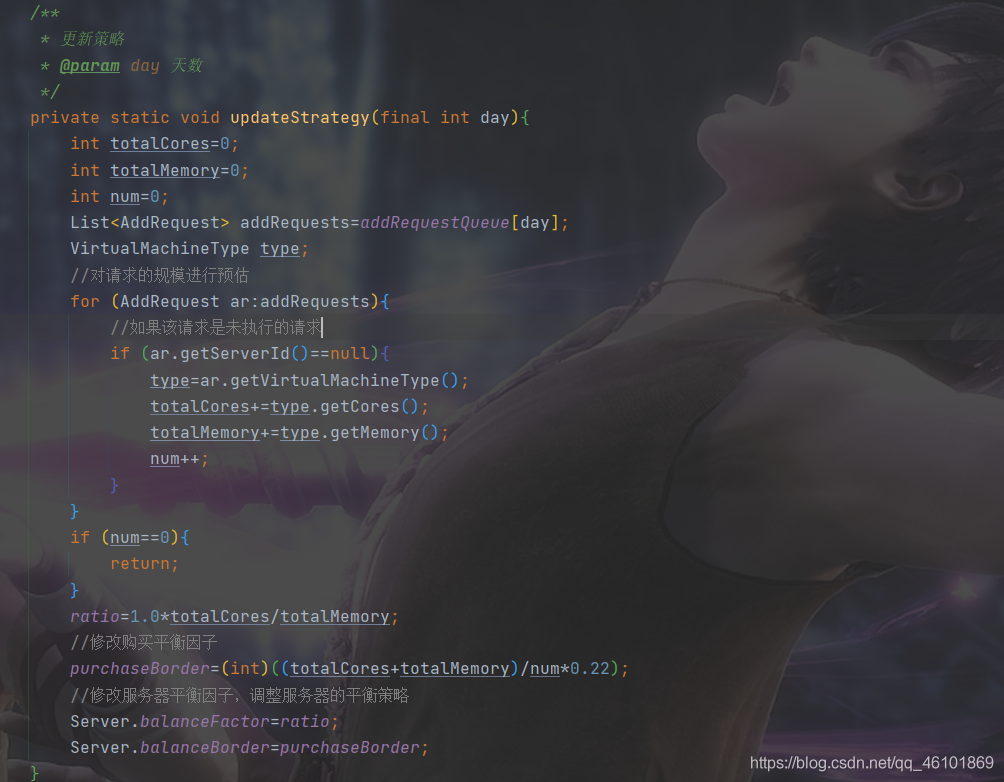
同时为了提升资源利用率,我把购买服务器的选择变成根据当前剩余请求去选择内核内存比最相近的服务器。
此次改进后,服务器利用率有了非常大的提升,除了最后一两台服务器外,其他服务器利用率都非常高,剩余的资源和一般在10-20之间,有的甚至只剩了1、2的资源。
在一番改进后(当然有很多细节方面的改进,在此就不赘述了),我们不加迁移的版本在练习赛阶段跑到了11亿9千万,正式赛在15亿3千万。


③迁移优化
至于迁移,根据之前的思路,我很快制订了迁移策略,即先把之前非平衡部署成功的虚拟机进行迁移,尝试平衡部署到其他服务器上(当然我加了一些判断,如之前记录的非平衡虚拟机如果服务器已经平衡则不必迁移),这样才能让服务器重归平衡,可以让服务器装下更多的虚拟机。
如果迁移次数还有多则进行全部迁移,即从虚拟机少的服务器往虚拟机多的服务器上迁移,这样既能整合资源,放下更多虚拟机,又能节省不必要的能耗开销。
但是这样迁移会有一个明显的问题——时间复杂度太高,每次迁移要花费0.6s左右,如果运行练习赛的数据集大概要跑500+s,这对于90s限制来说是致命的。
于是我对代码进行了优化,主要在以下几点:
1.外层循环优化:对于不必要的循环及时退出或者跳过,对于一些情况进行剪枝处理
2.数据结构优化:采用专门的数据结构,尽量减少内存和时间消耗
3.内部操作优化:对内部操作,如对部署操作进行优化,对于一些不必要情况直接判断返回
4.代码细节优化:如变量声明放在循环外等(当然这个是我很早就已经优化过的)
经过上述优化后,我的代码运行时间直接优化到了20s附近,这是一个惊人的优化,我之前从没想过我的代码能优化这么多。
但是由于线上数据集明显增大,在本地跑20多秒在线上依旧超时,无奈只能减少迁移操作的次数,从每天都会触发全部迁移到只有删除请求大于增加请求时才会触发全部迁移操作。
最终我们的成绩来到了14亿9千万,经过调参,成绩最终来到了14亿8千万,而这也是我们最好的成绩。

④最后的优化尝试
此时距离正式赛结束只有两天时间了,经过各种优化,我们发现我们很难再迁移和部署操作上减少成本(迁移操作主要碍于运行时间)。
于是我把目光转向了购买操作,因为我的购买操作是根据当前剩余请求的内核内存比来选择的,并没有考虑到成本,尽管利用率很高,但是成本始终降不下来,于是我想能不能考虑到购买成本这个因素(之前有写过一版考虑性价比的,但结果并不理想,利用率很低)。
特殊情况特殊处理
在比赛结束前的一个晚上,我们和一个大佬交流过,他说我的方案对于比较平衡的服务器虚拟机效果会比较好,但是对于一些比较极端的虚拟机和服务器比较吃亏,他给我们的建议是可以把这类虚拟机请求拿出来另外处理,专门用对应的服务器进行部署。
确实,我的方案是尽量按照当前的虚拟机内核内存比去选择服务器,但是问题就在于,统计完当前剩余的虚拟机请求后,其内核内存比都会接近1(大概是0.8-1.2左右),就算有那些比值夸张的虚拟机,这些特征也都被另外一些一种极端的虚拟机给中和掉了或者被比值比较均衡的虚拟机给稀释了,程序很难识别出来这些特征,所以程序一般都会买那种内核内存比接近1的服务器,而这类服务器往往性价比不高。
只有当部署请求的不断减少,剩余请求的特征不断被凸显出来时,这时程序才会买那种内核内存比比较大的服务器,所以我的购买成本才会降不下来。
分开处理确实是一个好的方法,并不是说有多大的资源浪费(因为我的资源利用率其实并不低),只是说如果拿内核内存比比较夸张的服务器去装内核内存比同样夸张的虚拟机,这样花费的钱会更低。
于是第二天大清早我就开始改代码,但我渐渐发现如果要那么去改,一个上午和一个下午的时间是不够的(因为这个思路会涉及我部署策略的更改,而我的部署策略与另外两个步骤息息相关,是全部代码的核心,改起来难度比较大,而且还要调试错误,再加上那时候我并不知道这个改动到底会不会会降低成本),改了一个上午最终决定放弃这种思路的更改。
叠加选出最优解
既然我们的瓶颈在于购买时并没有考虑成本问题,那么我尝试融入成本。于是我想出了另外一个方案,具体方案如下:
我把请求按顺序进行叠加,每次叠加后会去寻找能装下叠加后的虚拟机且花费最低(成本+能耗*剩余天数)的服务器类型,记录当前资源和当前选择的服务器资源之差,然后继续叠加,直到找不到能够装下这些请求的服务器为止,在这个过程中就留下了在叠加过程中资源之差最小的服务器类型,而这台服务器便是此种情况下的最优解。
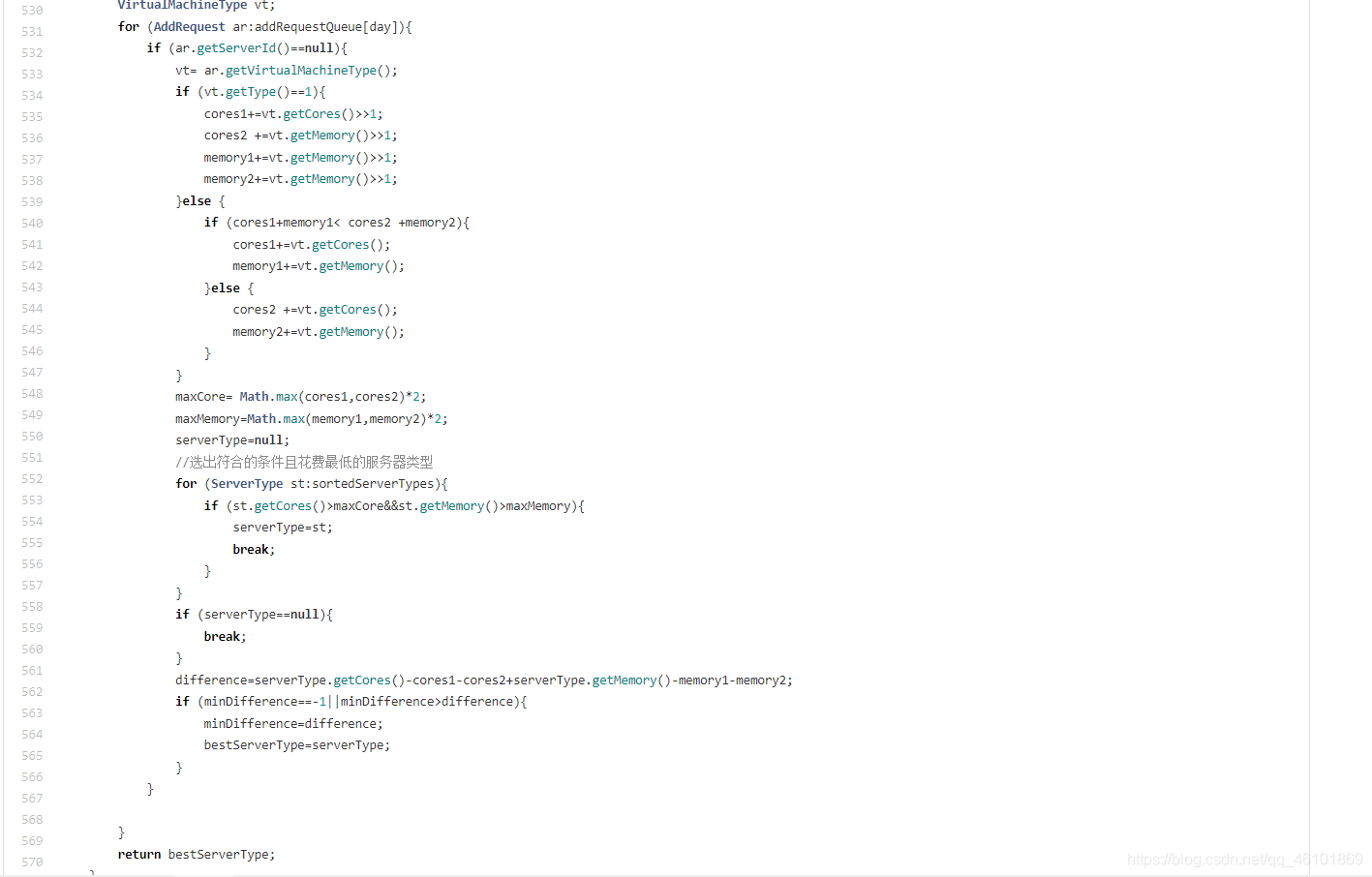
但此种策略结果和我之前策略花的成本差不多,当然这并不代表此种方案不行,它还有改进的地方,比如资源之差最小并不是最好服务器类型的标准,可以改变判断策略;又比如不一定要按顺序对虚拟机进行叠加等等,无奈当时所剩时间不多,只能放弃。但我觉得这个方案还是挺巧妙的。
四、思路总结
在这个赛题中,我觉得我有两个策略是做的比较好的,一个是平衡部署,一个是策略动态更新。
想象一下你的面前有一条河道,里面有不同大小的坑(服务器),一堆大小不一的石头(虚拟机请求)从上方滚下,如果大小和合适(平衡部署),那么石头就滚入坑中,一遍滚过后,除了最后几个坑之外,其他坑几乎都会被填满。而石头每次滚下,坑就会变换相应的形状(策略动态更新),有针对性应对这次滚下的石头。
当然还有一种没有完善的购买策略,那就是叠加选出最优解,这个也是值得思考的方法。
(详情请看思考过程部分)
这次比赛,我做的不好的地方就在于购买策略方面并没有考虑性价比,对于极端情况的考虑也有所欠缺。而这也是我们在32以外无法再进一步的原因。
除了思路上的欠缺外,我用Java打比赛也有弊端,这点体现在我迁移并不能全部迁移,只能受限于运行时间而有针对性对部分迁移进行舍弃,如果没有运行时间的限制,那么我们应该还能再前进1-2千万。
五、bug路漫漫
这一路优化过来,我遇到非常多的bug,这也是为什么我们的团队名叫做都是bug。唉,一路心酸,只能叹一句bug路漫漫!
以下记录了我几个找bug的经历
1.死循环
当时代码遇到超时的问题,我优化很久,优化一些逻辑,删除不必要的代码,把代码从700+行优化到380+行。可是问题依旧没有解决。
以下是我当时的bug记录:
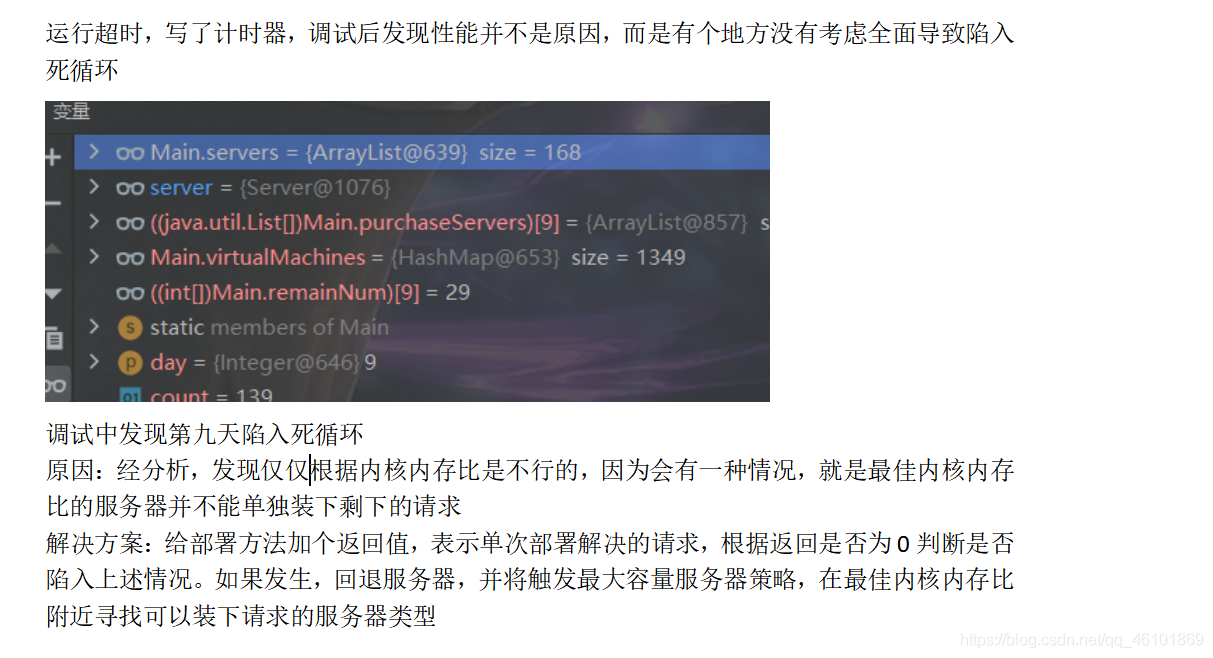
2.服务器超限
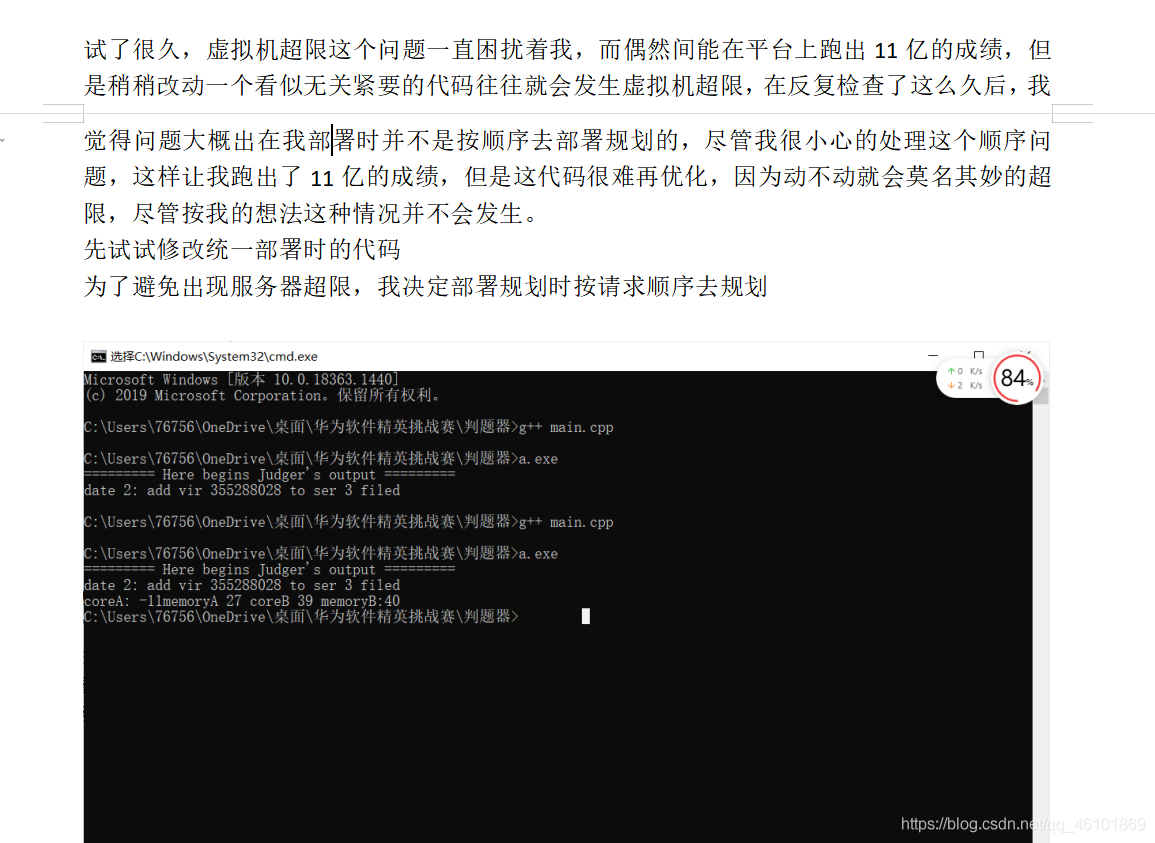
在提交过程我经常遇到这个bug。

这个一般是请求顺序的问题。
以下是我当时的bug记录:

当时我以为是我处理请求的逻辑不对,于是我该用顺序处理的方式来处理请求,可结果依旧是虚拟机资源超限。
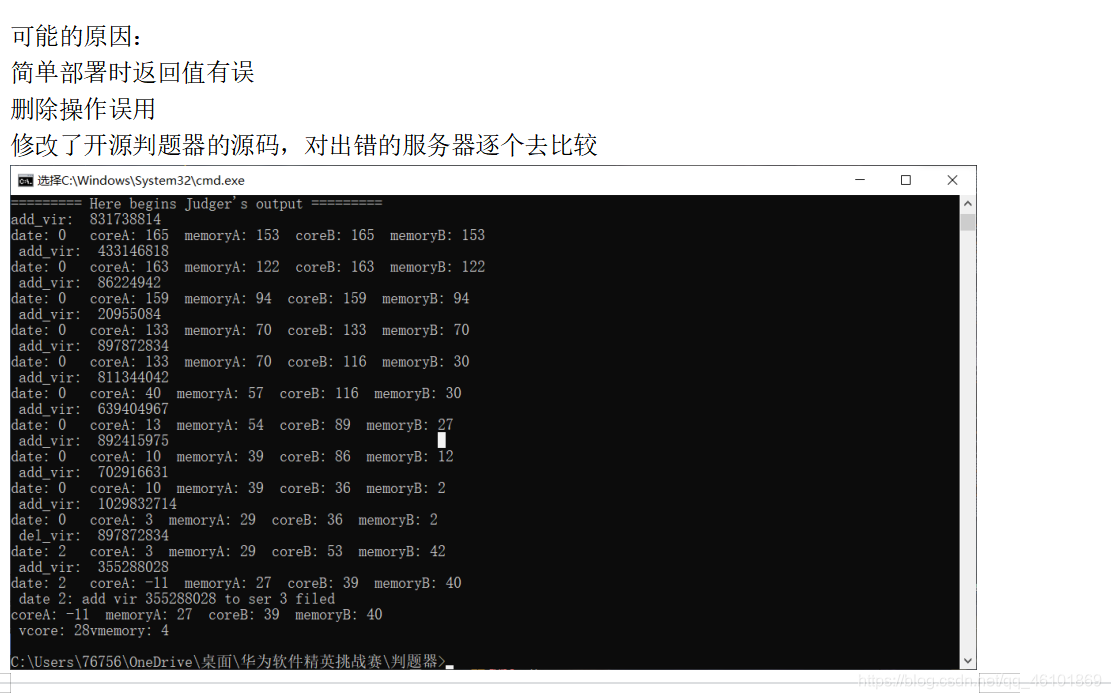
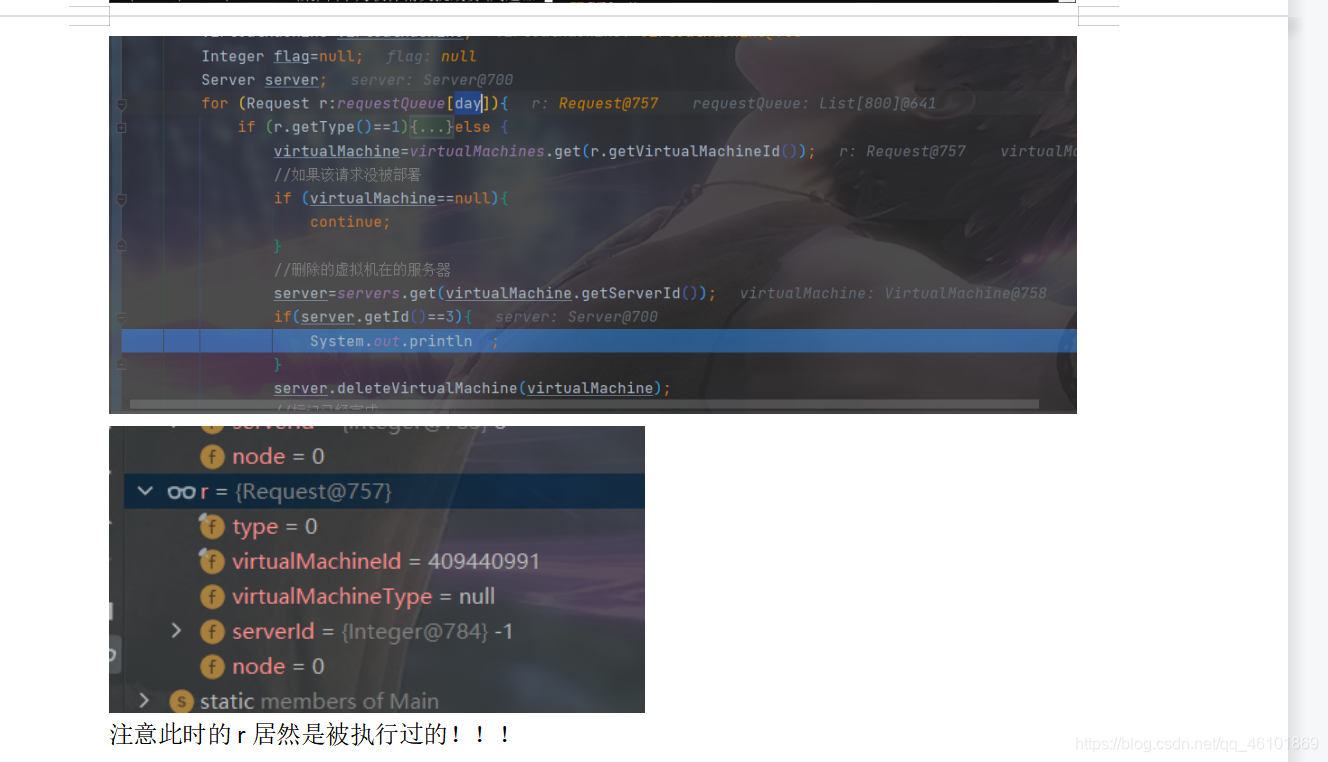
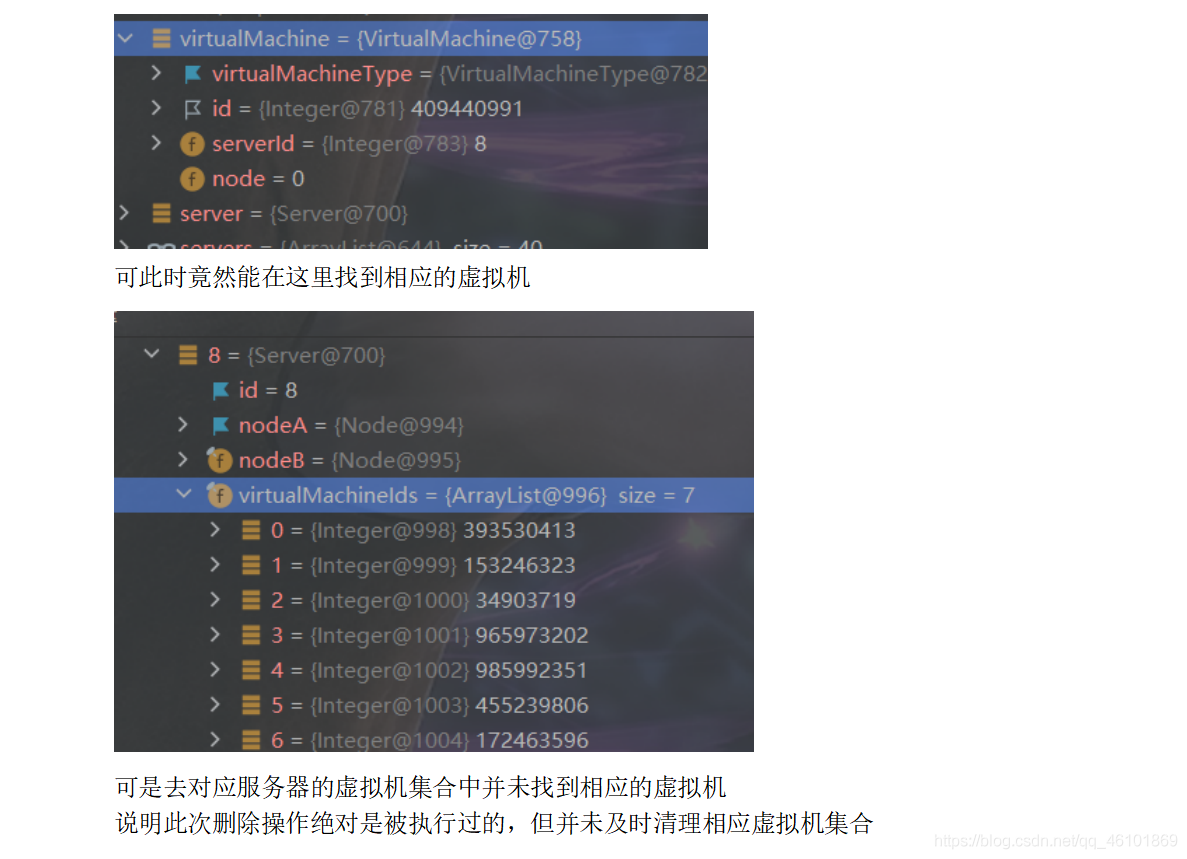
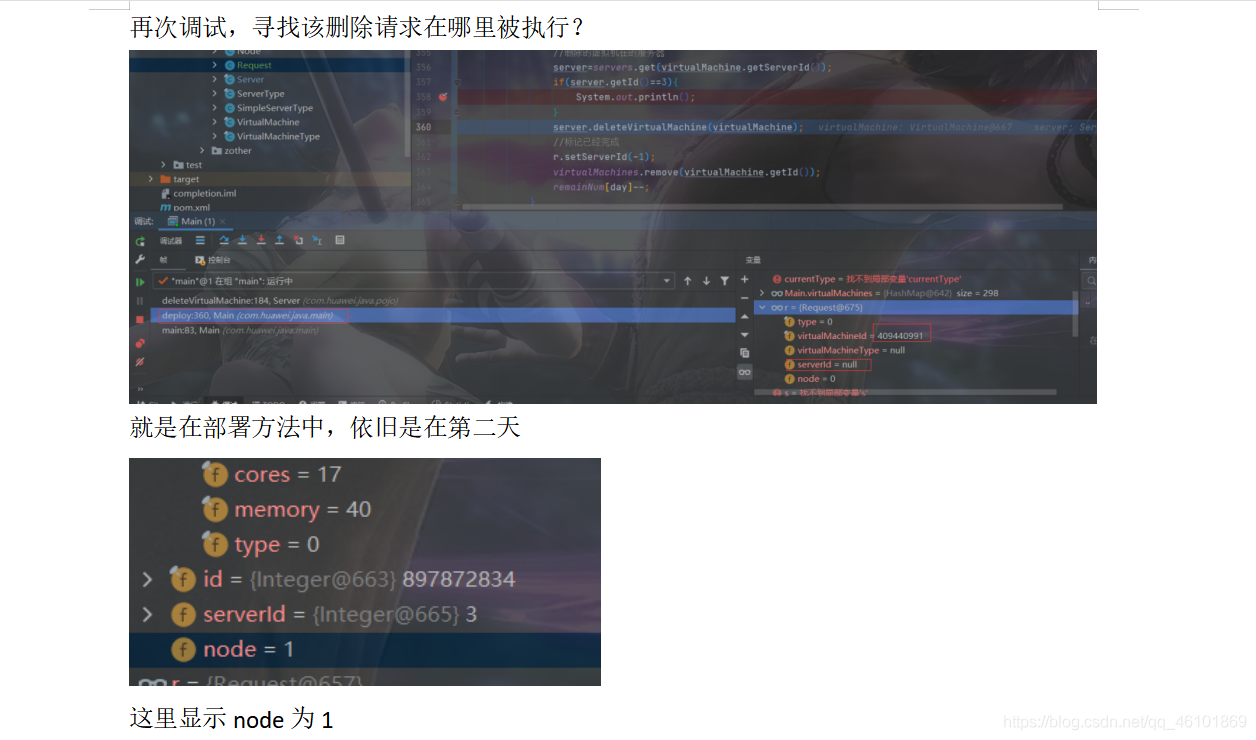
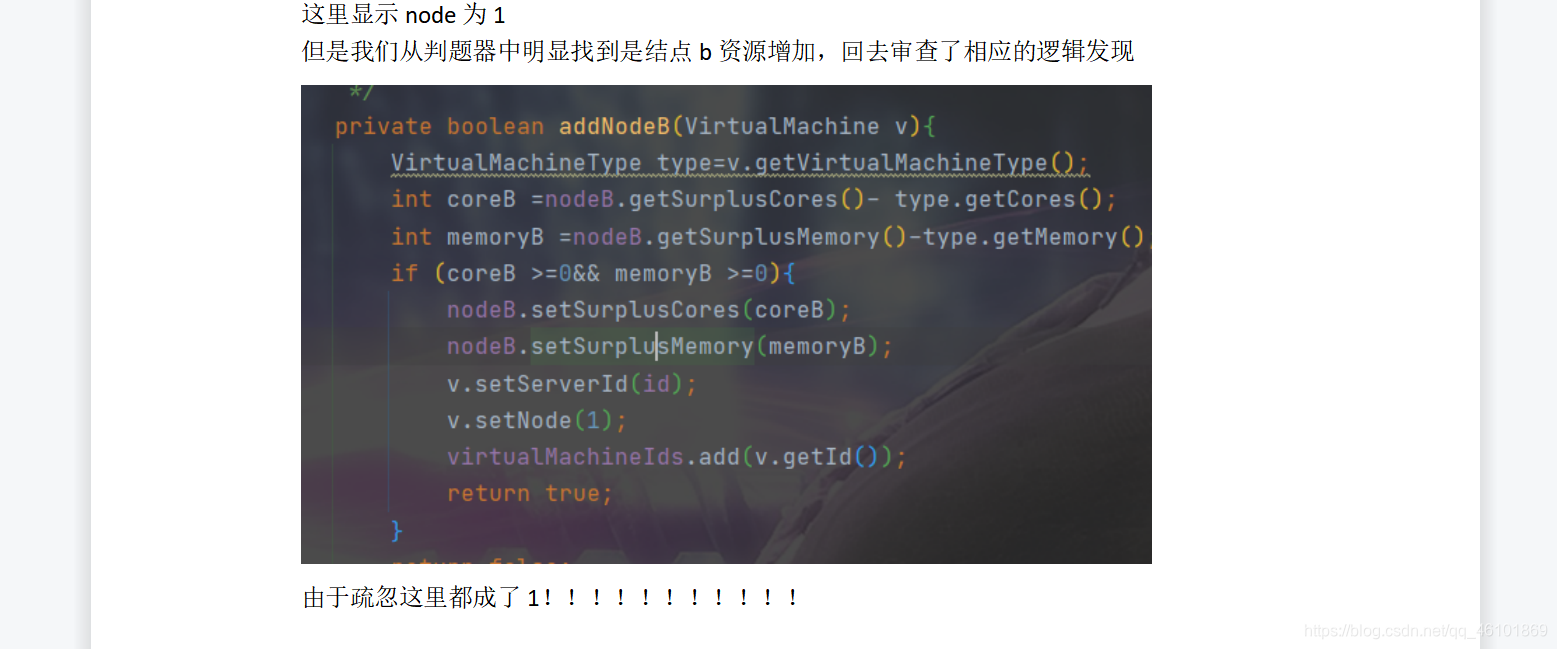
最后的bug竟然仅仅是因为一个数字!!!仅仅是因为一个1!!!
oh,my god!
六、对于后来者的建议
如果你是之后想参加华挑的,根据我的比赛经历,我给你如下建议:
1.找队友一定要找好,不要选那种中途放弃的,很多时候队友并不能帮你改善思路,但能在你想要放弃时鼓励你不断前进
2.做好代码管理,一个好的代码管理可以让我们后期优化时省力许多
3.尽量先思考清楚再写代码,后期大改成本会很大
4.多和大佬交流,但不是照搬,而是根据大佬的思路去思考有没有更好的思路,以此来完善自己的思路
5.发散去思考问题,很多时候解决方法并不只有固定那几种
6.改bug的时候,用小规模数据(自己可以逐步预测怎么发送)进行测试,如果发现过程中不符合你预期的那说明这部分代码有bug,然后逐步缩小范围,去查找bug所在,一定要仔细,能静得下心,沉得住气
7.如果能用c/c++打比赛就用c/c++打比赛,因为其他语言运行效率并没与它高,当然如果你是和我一样想用特定的语言也没关系,这次比赛运行时间并不是决定性因素
七、感想总结
此次比赛感想挺多的,努力了一周,也翘了一周的课(笑哭),虽然最终没能进复赛,但是对我的帮助挺大的。尤其是算法和代码优化这方面。
挺佩服前排那些大佬,能将成本压到这么低,这是我远远不能达到的。
当然现在的我水平还是不够,类似这种调优经验也少,以前我专注于学习Java后端开发的知识,而疏于底层代码编写优化,所以以后我要多补补数据结构和算法的知识,努力学习,争取明年再战时能进复赛。
最后附上这次的代码gitee地址,里面有这次比赛的有关文件,如有需要,自行下载即可。
愿我们以梦为马,不负青春韶华。
与君共勉!
[详细] -->赞
踩

