
- 1全球智库动态 | 未来极具潜力的50项新兴技术
- 2Python 与 Blender_blender python
- 3XSS漏洞介绍及反射型XSS
- 4Python中的3D矩阵操作:从基础到高级_python读取三维矩阵
- 5WebSocket的基本使用——实现一个简易的多人聊天室_websocket多人聊天
- 6java String类常用的Apl_java apl类
- 7荣耀3OS怎么升级鸿蒙系统,华为鸿蒙OS正式发布!教你如何升级
- 8Wireshark抓取网卡协议分析(TCP,UDP,ARP,DNS,DHCP,HTTP超详细版本)_怎样可以抓取到tcp数据包
- 9解决ChatGPT消息发不出问题,GPT无法发出消息,没有响应问题(2024.03.11)_chatgpt 发消息 转圈
- 10虚拟专题:知识图谱 | 医学知识图谱构建关键技术及研究进展
深度学习——计算机视觉基础概念_视觉概念学习
赞
踩
摘要
本文将针对与深度学习的平台的这样的一个理解和实战这样的一个理解。这是一个系列的课程。我将一直更新有关于的paddle的开发和学习。Paddle包括众多方面。目标检测、文字识别、图像分类、图像分割、生成对抗、视频、海量类别分类、语义理解、语音合成、语音识别、弹性计算推荐、强化学习框架、图学习框架、量子机器学习、生物计算等。本人就这些方面进行二次的研发和应用。
计算机视觉
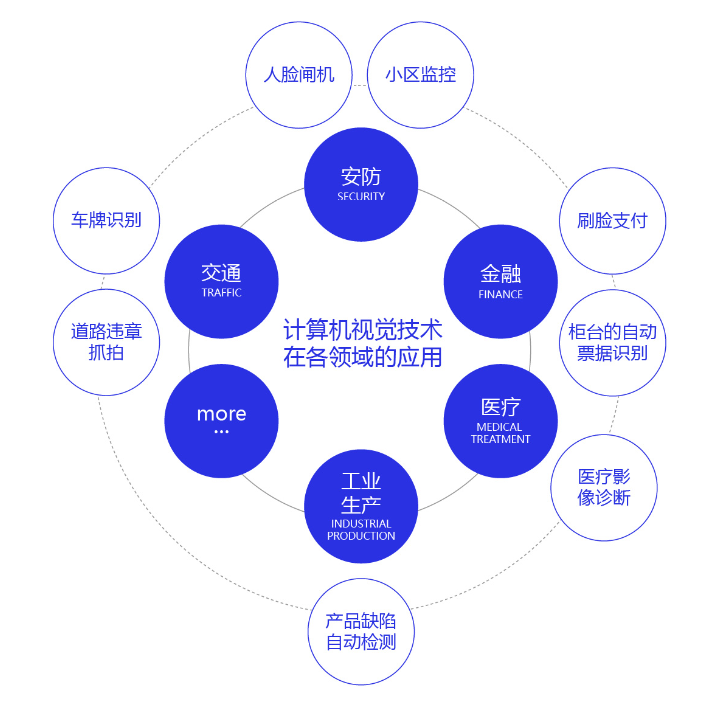
计算机视觉技术经过几十年的发展,已经在交通(车牌识别、道路违章抓拍)、安防(人脸闸机、小区监控)、金融(刷脸支付、柜台的自动票据识别)、医疗(医疗影像诊断)、工业生产(产品缺陷自动检测)等多个领域应用,影响或正在改变人们的日常生活和工业生产方式。未来,随着技术的不断演进,必将涌现出更多的产品和应用,为我们的生活创造更大的便利和更广阔的机会。
飞桨为计算机视觉任务提供了丰富的API,并通过底层优化和加速保证了这些API的性能。同时,飞桨还提供了丰富的模型库,覆盖图像分类、检测、分割、文字识别和视频理解等多个领域。用户可以直接使用这些API组建模型,也可以在飞桨提供的模型库基础上进行二次研发。
由于篇幅所限,本章将重点介绍计算机视觉的经典模型(卷积神经网络)和两个典型任务(图像分类和目标检测)。主要涵盖如下内容:
卷积神经网络:卷积神经网络(Convolutional Neural Networks, CNN)是计算机视觉技术最经典的模型结构。本教程主要介绍卷积神经网络的常用模块,包括:卷积、池化、激活函数、批归一化、丢弃法等。
-
图像分类:介绍图像分类算法的经典模型结构,包括:LeNet、AlexNet、VGG、GoogLeNet、ResNet,并通过眼疾筛查的案例展示算法的应用。
-
目标检测:介绍目标检测YOLOv3算法,并通过林业病虫害检测案例展示YOLOv3算法的应用。
对人类来说,识别猫和狗是件非常容易的事。但对计算机来说,即使是一个精通编程的高手,也很难轻松写出具有通用性的程序(比如:假设程序认为体型大的是狗,体型小的是猫,但由于拍摄角度不同,可能一张图片上猫占据的像素比狗还多)。那么,如何让计算机也能像人一样看懂周围的世界呢?研究者尝试着从不同的角度去解决这个问题,由此也发展出一系列的子任务,如 图3 所示。

-
(a) Image Classification: 图像分类,用于识别图像中物体的类别(如:bottle、cup、cube)。
-
(b) Object Localization: 目标检测,用于检测图像中每个物体的类别,并准确标出它们的位置。
-
(c) Semantic Segmentation: 图像语义分割,用于标出图像中每个像素点所属的类别,属于同一类别的像素点用一个颜色标识。
-
(d) Instance Segmentation: 实例分割,值得注意的是,(b)中的目标检测任务只需要标注出物体位置,而(d)中的实例分割任务不仅要标注出物体位置,还需要标注出物体的外形轮廓。
在早期的图像分类任务中,通常是先人工提取图像特征,再用机器学习算法对这些特征进行分类,分类的结果强依赖于特征提取方法,往往只有经验丰富的研究者才能完成,如 图4 所示。

这一方法在手写数字识别任务上取得了极大的成功,但在接下来的时间里,却没有得到很好的发展。其主要原因一方面是数据集不完善,只能处理简单任务,在大尺寸的数据上容易发生过拟合;另一方面是硬件瓶颈,网络模型复杂时,计算速度会特别慢。
目前,随着互联网技术的不断进步,数据量呈现大规模的增长,越来越丰富的数据集不断涌现。另外,得益于硬件能力的提升,计算机的算力也越来越强大。不断有研究者将新的模型和算法应用到计算机视觉领域。由此催生了越来越丰富的模型结构和更加准确的精度,同时计算机视觉所处理的问题也越来越丰富,包括分类、检测、分割、场景描述、图像生成和风格变换等,甚至还不仅仅局限于2维图片,包括视频处理技术和3D视觉等。
卷积神经网络
手写数字识别任务,应用的是全连接网络进行特征提取,即将一张图片上的所有像素点展开成一个1维向量输入网络,存在如下两个问题:
1. 输入数据的空间信息被丢失。 空间上相邻的像素点往往具有相似的RGB值,RGB的各个通道之间的数据通常密切相关,但是转化成1维向量时,这些信息被丢失。同时,图像数据的形状信息中,可能隐藏着某种本质的模式,但是转变成1维向量输入全连接神经网络时,这些模式也会被忽略。
2. 模型参数过多,容易发生过拟合。 在手写数字识别案例中,每个像素点都要跟所有输出的神经元相连接。当图片尺寸变大时,输入神经元的个数会按图片尺寸的平方增大,导致模型参数过多,容易发生过拟合。
为了解决上述问题,我们引入卷积神经网络进行特征提取,既能提取到相邻像素点之间的特征模式,又能保证参数的个数不随图片尺寸变化。 图是一个典型的卷积神经网络结构,多层卷积和池化层组合作用在输入图片上,在网络的最后通常会加入一系列全连接层,ReLU激活函数一般加在卷积或者全连接层的输出上,网络中通常还会加入Dropout来防止过拟合。

在卷积神经网络中,计算范围是在像素点的空间邻域内进行的,卷积核参数的数目也远小于全连接层。卷积核本身与输入图片大小无关,它代表了对空间邻域内某种特征模式的提取。比如,有些卷积核提取物体边缘特征,有些卷积核提取物体拐角处的特征,图像上不同区域共享同一个卷积核。当输入图片大小不一样时,仍然可以使用同一个卷积核进行操作。
问题:卷积是怎么在空间邻域内某种特征模式的提取?并实现的相邻像素点之间的特征模式?又能保证参数的个数不随图片尺寸变化?
卷积计算
卷积核(kernel)也被叫做滤波器(filter)。卷积是数学分析中的一种积分变换的方法,在图像处理中采用的是卷积的离散形式。这里需要说明的是,在卷积神经网络中,卷积层的实现方式实际上是数学中定义的互相关 (cross-correlation)运算,与数学分析中的卷积定义有所不同,这里跟其他框架和卷积神经网络的教程保持一致,都使用互相关运算作为卷积的定义,具体的计算过程如 图7 所示。

问题:卷积是怎么实现的互相关 (cross-correlation)运算的?
卷积就是一个滤波器:在正向传播的时候,每一个滤波器的都会在宽度和高度上进行一定间隔的滑动(卷积操作)滑动到某一处便计算整个滤波器在它在当前的所覆盖的数据的输入的区域的内积,当滤波器划过整个图像后,将会生成一张二维的特征的图,特征的图片显示了滤波器在每一个图像中每一个空间位置的响应。在一个训练好的网络中,滤波器每当看到它期望的类型的视觉的特征时候就会被激活。其中的视觉特征可能是的为底层网络中的边界和颜色斑点,也可能是的更加高层的网络的团特征。
滤波器(Filter,)是一组具有固定权重的,如图6-1所示,矩阵框中的数值即为权重数值。如果深度方同上属于同一层次的所有的神经原都是使用同一个权重向量,那么卷积层的正向传播相当于是计算神经元权重和输入数据体的卷积,这就是“卷积层”名字的由来,也是将这些权重集合杯为滤波器或者是卷积(Kernel)的原因。


【思考】 当卷积核大小为3×3时,b和a之间的对应关系应该是怎样的?

填充


步幅(stride)


感受野(Receptive Field)
输出特征图上每个点的数值,是由输入图片上大小为kh×kw的区域的元素与卷积核每个元素相乘再相加得到的,所以输入图像上kh×kw区域内每个元素数值的改变,都会影响输出点的像素值。我们将这个区域叫做输出特征图上对应点的感受野。感受野内每个元素数值的变动,都会影响输出点的数值变化。比如3×3卷积对应的感受野大小就是3×3,如 图10 所示。而当通过两层3×3的卷积之后,感受野的大小将会增加到5×5,如 图 所示。


因此,当增加卷积网络深度的同时,感受野将会增大,输出特征图中的一个像素点将会包含更多的图像语义信息。因此,当增加卷积网络深度的同时,感受野将会增大,输出特征图中的一个像素点将会包含更多的图像语义信息。
多输入通道、多输出通道和批量操作
前面介绍的卷积计算过程比较简单,实际应用时,处理的问题要复杂的多。例如:对于彩色图片有RGB三个通道,需要处理多输入通道的场景。输出特征图往往也会具有多个通道,而且在神经网络的计算中常常是把一个批次的样本放在一起计算,所以卷积算子需要具有批量处理多输入和多输出通道数据的功能,下面将分别介绍这几种场景的操作方式。通常将卷积核的输出通道数叫做卷积核的个数。




理解图像卷积操作的意义
卷积一词最开始出现在信号与线性系统中,信号与线性系统中讨论的就是信号经过一个线性系统以后发生的变化。由于现实情况中常常是一个信号前一时刻的输出影响着这一时刻的输出,所在一般利用系统的单位响应与系统的输入求卷积,以求得系统的输出信号(当然要求这个系统是线性时不变的)。
卷积的定义:卷积是两个变量在某范围内相乘后求和的结果。如果卷积的变量是序列x(n)和h(n),则卷积的结果:
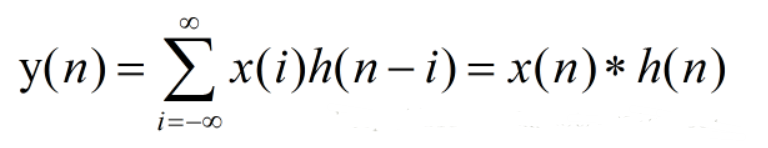
数字图像处理中卷积(参考:理解图像卷积操作的意义_zxucver的博客-CSDN博客_图像卷积)
数字图像是一个二维的离散信号,对数字图像做卷积操作其实就是利用卷积核(卷积模板)在图像上滑动,将图像点上的像素灰度值与对应的卷积核上的数值相乘,然后将所有相乘后的值相加作为卷积核中间像素对应的图像上像素的灰度值,并最终滑动完所有图像的过程。

这张图可以清晰的表征出整个卷积过程中一次相乘后相加的结果:该图片选用3*3的卷积核,卷积核内共有九个数值,所以图片右上角公式中一共有九行,而每一行都是图像像素值与卷积核上数值相乘,最终结果-8代替了原图像中对应位置处的1。这样沿着图片一步长为1滑动,每一个滑动后都一次相乘再相加的工作,我们就可以得到最终的输出结果。除此之外,卷积核的选择有一些规则:
1)卷积核的大小一般是奇数,这样的话它是按照中间的像素点中心对称的,所以卷积核一般都是3x3,5x5或者7x7。有中心了,也有了半径的称呼,例如5x5大小的核的半径就是2。
2)卷积核所有的元素之和一般要等于1,这是为了原始图像的能量(亮度)守恒。其实也有卷积核元素相加不为1的情况,下面就会说到。
3)如果滤波器矩阵所有元素之和大于1,那么滤波后的图像就会比原图像更亮,反之,如果小于1,那么得到的图像就会变暗。如果和为0,图像不会变黑,但也会非常暗。
4)对于滤波后的结构,可能会出现负数或者大于255的数值。对这种情况,我们将他们直接截断到0和255之间即可。对于负数,也可以取绝对值。
边界补充问题
上面的图片说明了图像的卷积操作,但是他也反映出一个问题,如上图,原始图片尺寸为7*7,卷积核的大小为3*3,当卷积核沿着图片滑动后只能滑动出一个5*5的图片出来,这就造成了卷积后的图片和卷积前的图片尺寸不一致,这显然不是我们想要的结果,所以为了避免这种情况,需要先对原始图片做边界填充处理。在上面的情况中,我们需要先把原始图像填充为9*9的尺寸。
常用的区域填充方法包括:
为了画图方便,这里就不用5*5的尺寸了,用3*3定义原始图像的尺寸,补充为9*9的尺寸,图片上的颜色只为方便观看,并没有任何其他含义。
原始图像:

不同卷积核下卷积意义
我们经常能看到的,平滑,模糊,去燥,锐化,边缘提取等等工作,其实都可以通过卷积操作来完成,下面我们一一举例说明一下:
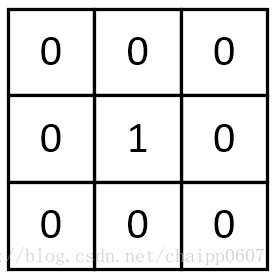
一个没有任何作用的卷积核:
卷积核:将原像素中间像素值乘1,其余全部乘0,显然像素值不会发生任何变化。
平滑均值滤波:
选择卷积核:

该卷积核的作用在于取九个值的平均值代替中间像素值,所以起到的平滑的效果:


高斯平滑:
卷积核:高斯平滑水平和垂直方向呈现高斯分布,更突出了中心点在像素平滑后的权重,相比于均值滤波而言,有着更好的平滑效果。

图像锐化:
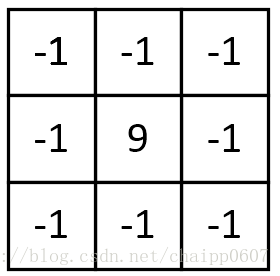
该卷积利用的其实是图像中的边缘信息有着比周围像素更高的对比度,而经过卷积之后进一步增强了这种对比度,从而使图像显得棱角分明、画面清晰,起到锐化图像的效果。
梯度Prewitt:
水平梯度卷积核:
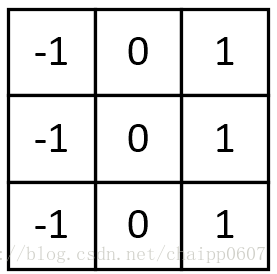

垂直梯度卷积核:
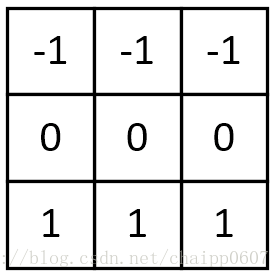

梯度Prewitt卷积核与Soble卷积核的选定是类似的,都是对水平边缘或垂直边缘有比较好的检测效果。
Soble边缘检测:
Soble与上述卷积核不同之处在于,Soble更强调了和边缘相邻的像素点对边缘的影响。
水平梯度:


垂直梯度:

梯度Laplacian:
卷积核:
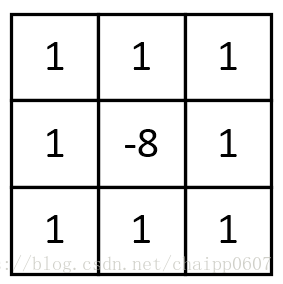

Laplacian也是一种锐化方法,同时也可以做边缘检测,而且边缘检测的应用中并不局限于水平方向或垂直方向,这是Laplacian与soble的区别。下面这张图可以很好的表征出二者的区别:来源于OpenCV官方文档

使用小卷积核3×3的原因(参考:https://blog.csdn.net/szy525525/article/details/87273192)
1.更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,更多的卷积核的使用可使决策函数更加具有辨别能力,此外就卷积本身的作用而言,3x3比7x7就足以捕获特征的变化:3x3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化。主要在于3个堆叠起来后,三个3x3近似一个7x7,网络深了两层且多出了两个非线性ReLU函数,(特征多样性和参数参数量的增大)使得网络容量更大(关于model capacity,AlexNet的作者认为可以用模型的深度和宽度来控制capacity),对于不同类别的区分能力更强(此外,从模型压缩角度也是要摒弃7x7,用更少的参数获得更深更宽的网络,也一定程度代表着模型容量,后人也认为更深更宽比矮胖的网络好);
2.卷积层的参数减少。相比5x5、7x7和11x11的大卷积核,3x3明显地减少了参数量,这点可以回过头去看上面的表格。比方input channel数和output channel数均为C,那么3层conv3x3卷积所需要的卷积层参数是:3x(Cx3x3xC)=27C2,而一层conv7x7卷积所需要的卷积层参数是:Cx7x7xC=49C2。conv7x7的卷积核参数比conv3x3多了(49-27)/27x100% ≈ 81%;
3.小卷积核代替大卷积核的正则作用带来性能提升。作者用三个conv3x3代替一个conv7x7,认为可以进一步分解(decomposition)原本用7x7大卷积核提到的特征,这里的分解是相对于同样大小的感受野来说的。关于正则的理解我觉得还需要进一步分析。
其实最重要的还是多个小卷积堆叠在分类精度上比单个大卷积要好。

