
- 1Qt之信号与槽
- 2深入了解Kimi:月之暗面科技有限公司的创新智能助手_kimi 的能力
- 3【数据结构】CH4 串_第1关:求子串
- 4MySQL从安装、配置到日常操作和管理的关键步骤_mysql安装教程8.4
- 5python 中使用opencv_python使用opencv
- 6python3+selenium爬取笔记本电脑详情信息_selenium可以爬取pc端数据吗
- 7【通信中间件】Fdbus HelloWorld实例
- 8搭建单机版伪分布式Hadoop+Spark+Scala
- 9基于MySQL Workbench的表操作_mysql workbench向表中添加数据
- 10苹果app退款_app退款理由写什么好?苹果退款理由怎么写才好?
HIVE运行卡死没反应的亲测解法_各个分区中插入对应数据。hive长时间卡住
赞
踩
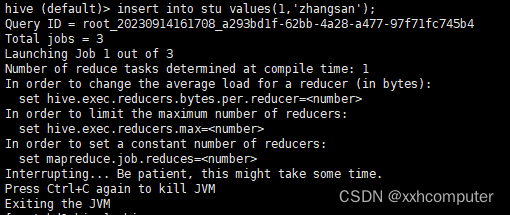
Query ID = root_20230914161708_a293bd1f-62bb-4a28-a477-97f71fc745b4
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Interrupting... Be patient, this might take some time.
当执行一条插入语句时,一直卡着,卡在这一步,没有任何反应只能自己手动杀死,并且查看hdfs也没有数据插入成功。找了很多都没有得到解决。
尝试过的解决方案有:
1 重启hadoop和yarn
2 查看是否是端口被占用netstat –anp | grep 8033
3 检查环境变量是否配置错误
4 查看hive和yarn的日志
这些方法都没有解决,可以参考一下
最后解决的方法是

进入到hive后执行这3条指令
hive (default)> set hive.exec.mode.local.auto=true;
hive (default)> set hive.exec.mode.local.auto.inputbytes.max=50000000;
hive (default)> set hive.exec.mode.local.auto.input.files.max=5;
执行完再执行插入语句
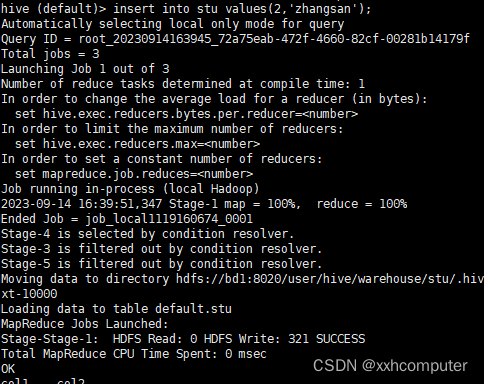
完成插入,跑完MapReduce

