
- 1Elasticsearch倒排索引详解_es倒排索引原理和组成部分
- 2MCC(移动国家码)和 MNC(移动网络码)_mnc mcc
- 3【愚公系列】2023年12月 HarmonyOS教学课程 054-Web组件(基本使用和属性)_harmonyosweb组件打开网页前黑屏
- 4入职华为外包一个月,我离职了_华为外包公司值得去吗
- 5QT 入门项目---科目一考试系统_考试系统qt代码
- 6python PyQt5 实现定时器_pyqt5 定时器
- 7px4固件源码分析(文件夹作用以及总体架构)_px4程序分析
- 8POJ 1451 T9
找出现频率最高的字符串 - 9面试了字节大模型算法岗(实习),快被问哭了。。。。_字节大模型要评估多久
- 10ModelsimSE添加Altera库及简单的功能仿真_modelsim仿真altera库
最全Image Caption 2024最新整理:数据集 文献 代码,2024年最新程序员经典面试题_image caption数据集
赞
踩
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Image caption任务的目标是找到最有效的pipeline来处理输入图像,表示其内容,并通过在保持语言流畅性的同时生成视觉和文本元素之间的连接,将其转换为一组单词序列1。
数据集概览
早期的image caption主要采用Flickr30K和Flickr8K数据集,这个数据集图片来源于Flickr网站。
目前比较常用的数据集是COCO Captions、Conceptual Captions (CC),包含人、动物和普通日常物品之间的复杂场景的图像。
COCO Captions、Conceptual Captions (CC)、VizWiz、TextCaps、Fashion Captioning、CUB-200等数据集的标注样例如下图(a)所示,数据集中语料库的高频词云如下图(b)所示1,可以反映数据集中主要目标类别的分布。

标注方式
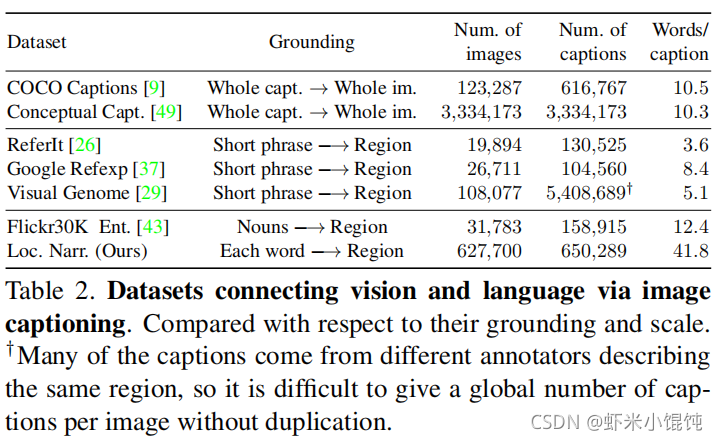
COCO Captions、Conceptual Captions (CC)数据集中对图像描述的标注,是基于整幅图像的。Flickr30K Entities标注了Flickr30K中caption里提到的名词,并标注了对应的bbox。Visual Genome数据集提供了描述图像中区域的短语,并使用这些区域来生成一个场景图(scene graph)。Localized Narratives为每个单词都提供了基于其跟踪片段所表示的图像中的一个特定区域,包括名词、动词、形容词、介词等。2

Microsoft COCO Captions
Microsoft COCO Captions: Data Collection and Evaluation Server
[website]
[paper]
[github] 提供评估方法
COCO Captions更关注“描述场景的所有重要部分”,而不描述不重要的细节,这使得COCO Captions对于关注的对象更突出。
- 164,062张图像,包括:
- 82,783个训练图像
- 40,504个验证图像
- 40,775个测试图像
- 995,684个captions,平均每张图片6个captions
- 标注内容:
- 描述这个场景的所有重要部分;
- 不描述不重要的细节。
- 不要描述在未来或过去可能发生的事情。
- 不描述一个人可能会说什么。
- 不提供专有的人名。
- 这些句子应该至少包含8个单词。

SBU Captions
NIPS 2011 | Im2Text: Describing Images Using 1 Million Captioned Photographs
[website]
[paper]
SBU Captions数据集最初将图像字幕作为一个检索任务,包含 100 万个图片网址 + 标题对。

Conceptual Captions (CC) dataset
Conceptual Captions (CC) dataset是一个包含(图像URL、字幕)对的数据集,用于机器学习图像字幕系统的训练和评估。数据集有约330万张图像(CC3M)和1200万张图像(CC12M)两个版本,并通过一个简单的过滤程序从网络自动收集弱相关描述。
与 MS-COCO 图像相比,Conceptual Captions数据集的图像及其原始描述来自网络,因此代表了更广泛的风格。
但是Conceptual Captions 的图像并不总是可用的,因为数据集提供的是图片URL。
| Split | Examples | Uniqe Tokens |
|---|---|---|
| Train | 3,318,333 | 51,201 |
| Valid | 15,840 | 10,900 |
| Test (Hidden) | 12,559 | 9,645 |

TextCaps
这个数据集的特点在于使用包含文字内容的图片。
TextCaps 要求模型阅读和推理图像中的文本以生成有关它们的说明。具体来说,模型需要根据图像中存在的文本形式对其进行推理,并结合图像中的视觉内容以生成图像描述。
- 28,408 张图片,来自 Open Images 数据集
- 142,040 条captions
- 平均每张图片 5 个captions

VizWiz-Captions
ECCV 2020 | Captioning Images Taken by People Who Are Blind.
[paper]
[website]
这个数据集中的图像是由视力受损的人使用手机拍摄的,图像质量不高,涉及各种各样的日常活动,其中大多数需要阅读一些文本。数据集旨在让更多人了解盲人的需求,并开发辅助技术,解决盲人日常生活中的视觉挑战,回答盲人的视觉问题。
数据集引入了视力受损的人采集的39,181张真实图像用例,每张图像都配有5个captions。
VizWiz-Captions 数据集包括:
- 训练集:23,431 张图像,117,155 个captions
- 验证集:7,750 张图像,38,750 个captions
- 测试集:8,000 张图像,40,000 个captions

最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/857259
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

