
- 1微信小程序的水库巡检巡查系统uniapp
- 2【NLP基础知识五】文本分类之神经网络文本分类、多标签分类_神经网络处理文本分类
- 3[C++][算法基础]判定质数(试除法)
- 4阿里云物联网设备SDK:构建智能硬件的新时代工具
- 5华为od统一考试B卷【考勤信息】Python 实现_python计算缺勤扣款
- 6机器人运动学——轮速里程计(SLAM)
- 7FastAdmin 插件离线安装不成功的原因_fastadmin无法解压zip文件(code:0)
- 8硬刚一周,3W字总结,一年的经验告诉你如何准备校招,拿大厂offer_c++想进大公司要什么时候准备校招
- 9大模型时代的核心推荐技术,这本书全讲到了!
- 10BitSet&BloomFilter&HyperLogLog_bitsetbloomfilter hutool
人物写真Lora实战_赛博丹炉训练出来的lora不好
赞
踩
本篇详细介绍使用Stable diffusion训练人物写真Lora的完整过程,含评测方法,实力避坑。保姆级、喂饭级,新手必备。
直接上图,实战效果
1、云旅游AI穿上各种好看的衣服,出现在世界各地的著名景点:我的云旅游
埃菲尔铁塔


海滩


主要过程
训练环境搭建-》原图准备-》上传素材-》预处理(打TAG)》配置训练参数-》训练-》Lora评测
训练环境搭建
训练Lora,有3个方向:
1、用SD的dreambooth插件
2、使用训练脚本,主要是kohya-ss、秋叶大神的lora-scripts
3、使用现成的丹炉
由于dreambooth插件以及训练脚本和SD本身环境有很多依赖冲突,使用现成的丹炉可以减少很多搭建工作。
朱尼酱的赛博丹炉是首选,在这里也推荐一下作者基于赛博丹炉组装的千趣丹炉,将秋叶大神的sd webui整合包、赛博丹炉、文生视频、艺术二维码、修脸、换脸、TTS等工具做了打包集成,同时预装了海量sd、lora模型,开箱即免费使用。作者还能够为企业端用户提供SD一体机服务,提供从整机调试、工具预装、使用培训、上手案例指导等完整的技术支持。还可以和企业合作进行专属大模型、lora模型的训练工作,欢迎咨询。
下面是青椒云的注册链接: 青椒云注册 添加云桌面记得选华南4节点,选定制产品,千趣丹炉。
这个产品才2.5元/小时,按时间计费,对于没有购买很贵的物理机小伙伴来说是个不二之选。一般熟练一点炼个丹差不多只要半个小时,很便宜吧,1块钱一个lora仙丹。
开启丹炉:
云桌面首页点击Cybertron Furnace.exe -快捷方式,直接一键启动,首次启动需要预装一下依赖库,耐心等待。待《开启炼丹炉》按钮点亮,一键启动

原图准备
图片选择标准:
- 图片质量高:质量越高,训练出来的效果也越好,可能几个epoch就能达到很好的效果,如果训练集模糊。质感差,100张图片,20个epoch效果也很差!图片尽量高清,图片不清楚的话,可以是使用SD的附加功能进行高清修复,这步很很很重要:
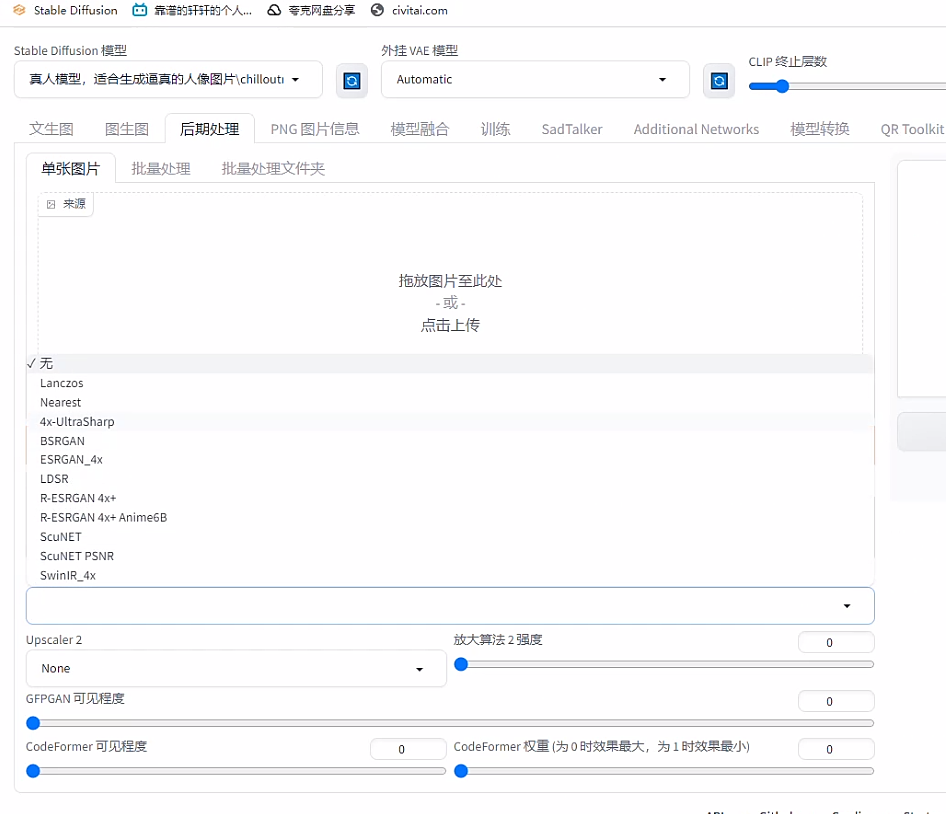
推荐使用4x-UltraShape对人像图片进行缩放。512x512尺寸的,在SD上面使用Extra功能,选择算法4x-UltraShape,重新生成了对应图片的1024尺寸图片,这个功能比之前找的网上的放大图片的网页工具效果还要好。千趣丹炉的SD Extra已经预置好了该算法。
如需自己安装,可以去github上面找到该算法的下载地址,下载下来后丢到SD的models\ESRGAN文件夹下,重启SD就可以了。
- 图片数量别太少:建议10~50张,质量越高图片可以越少。
- 尽量突出主题的图片:人物的话尽量脸部特征明显,比如不同角度的头像
- 图片的尺寸要一致,一般推荐都是512x512,或者512x768,或者1024x1024.一般512尺寸就够用。尺寸的长宽要求是32的整数倍。这里可以使用专门的切图工具:birme在线切图工具
- 背景干净,背景太繁杂最好使用SD的附加功能里面的抠图算法去掉,比较干净的背景可以不处理。 如果是人物的lora或者二次元的lora,脸部特征很重要,尽量突出脸部。最好多个角度的都要有。
本次教学图集图片数量偏少,仅供参考。图集如有涉及侵权,请及时联系我,本人能做到秒删图,谢谢!原图集如下:

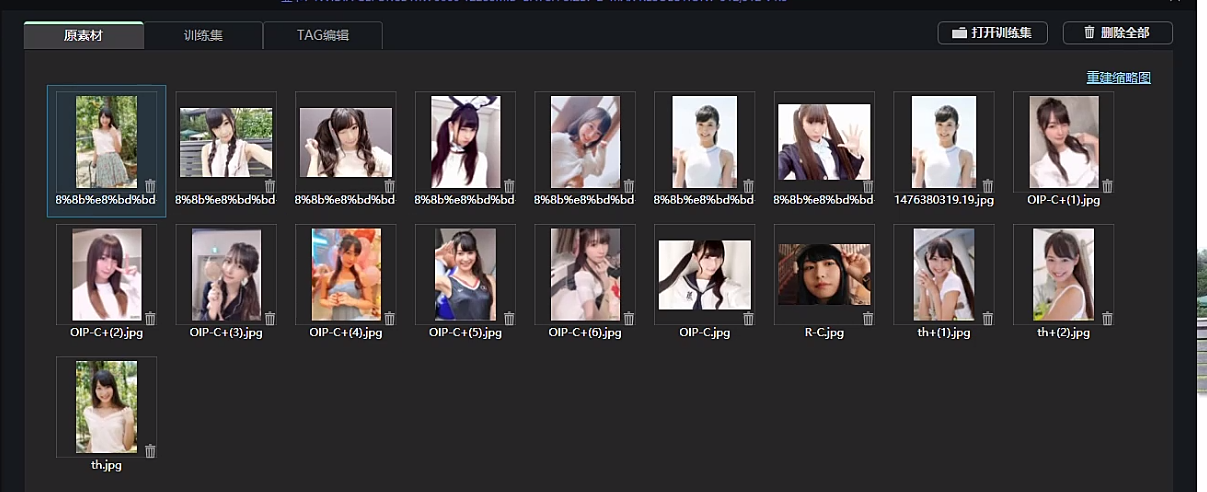
上传素材
点击《上传素材》,上传原图集,如有低质量如模糊的图片,需要删除,保证照片可以尽量突出脸部。
预处理
预处理主要是为了生成带tag的待训练图片。打tag这一步是非常非常关键的,像这次炼丹这种只有人物没有背景的情况下还算好,不然背景里有其他东西,tag都要打准的,不然会影响AI的识别与学习。
尽量让原图背景干净简单的原因就在这里。背景繁杂你写tag要写的很准确,不然会影响AI的学习。
1、自动打TAG
1、分辨率:首炉建议选择512*512,后续根据体验调整
2、模式:抠图填白,保证能够裁剪出焦点,去掉杂乱的背景
3、TAG:选择自动tag
4、权重:推荐值0.35。可以调整,值越小tag越多,tag越多越准确一些,但是工作量更多。
5、脸部训练加强:勾选
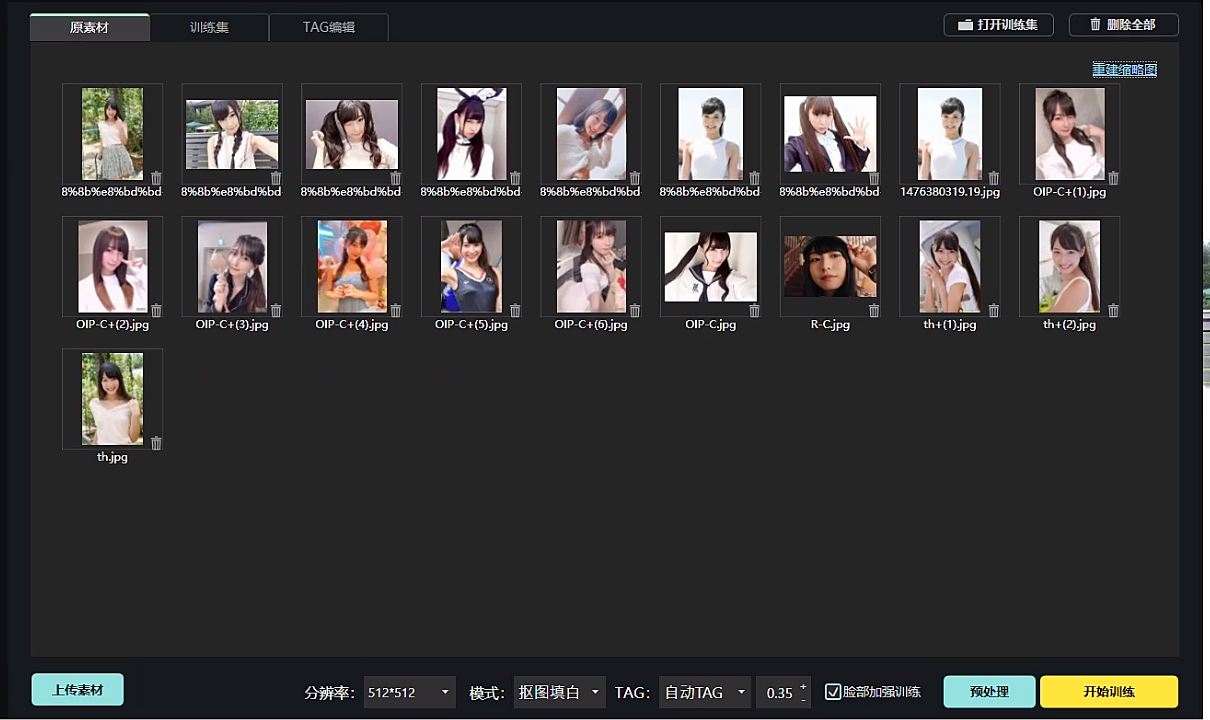
点击《预处理》开始自动给图片打TAG,进行TAG反推。
2、TAG编辑
预处理完之后训练集里面就会有两组素材,一组是抠图后的原素材,还有一组就是抠图后的只有脸的素材。两组素材里面会有些识别不准确或者不清晰的照片,我们点击照片右下角的图标把照片删掉。
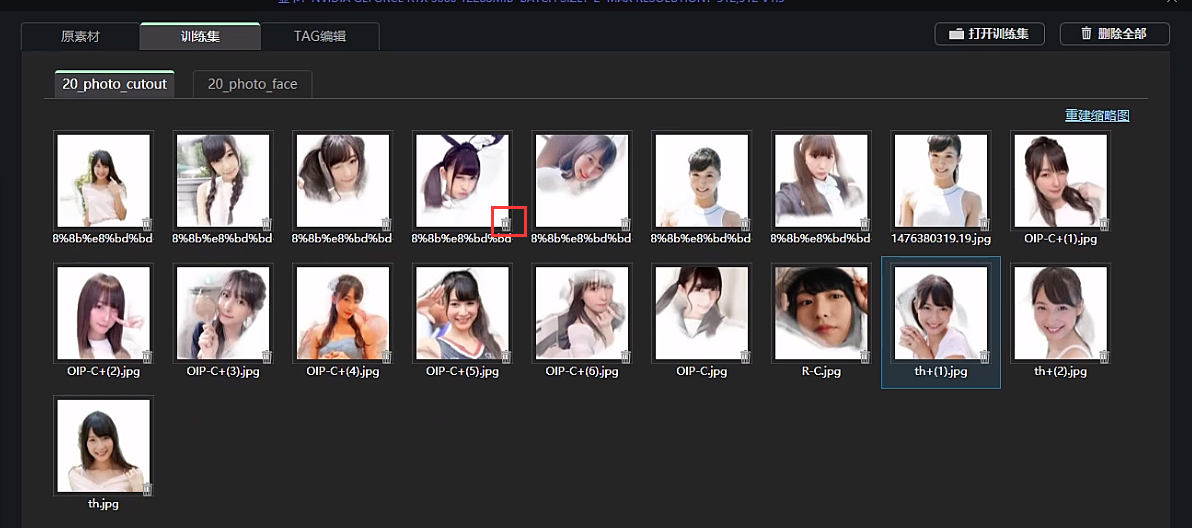
可以看到“TAG编辑”,这里面就是形容照片的一些标签,右边是所有照片的标签,单独点击某一张照片就可以看到这张照片的标签。
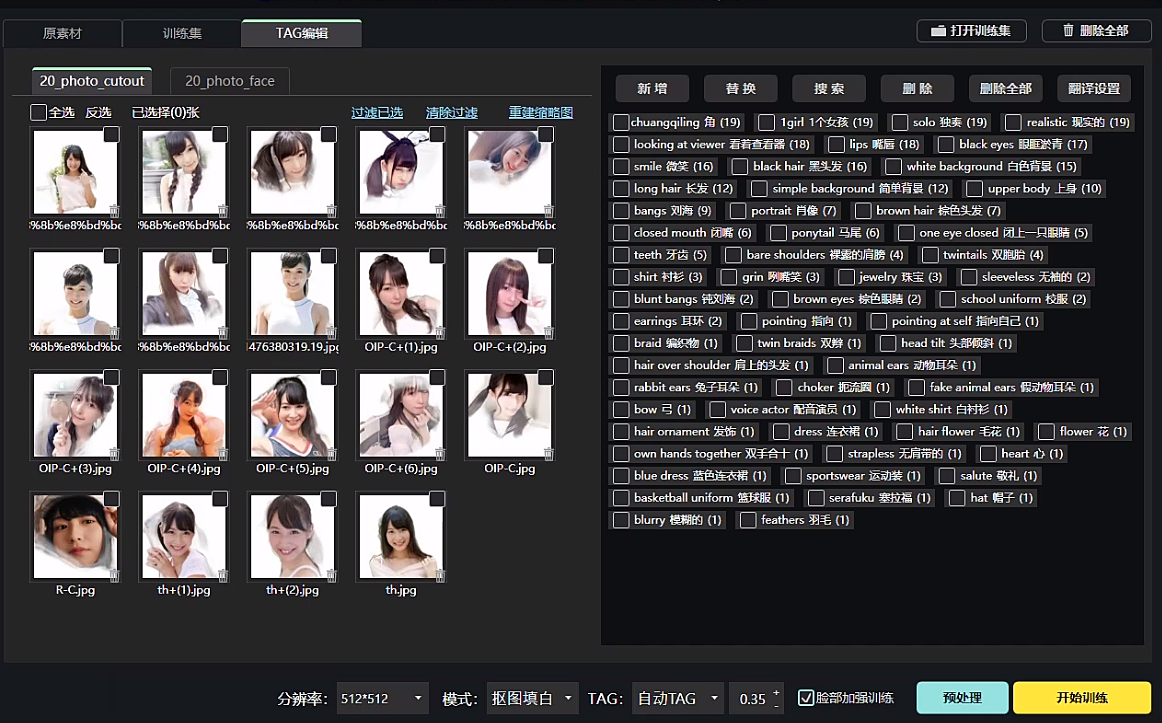
这里我们需要把照片大概检查一下,手动删掉、替换或者增加标签,标签和照片对不上,AI就会学错。比如这张照片的标签里的“twintails”就是错的,可以勾选标签,点击“删除”,如有”1boy”标签,可以点击替换,替换为1girl,也可以照此新增某些标签。
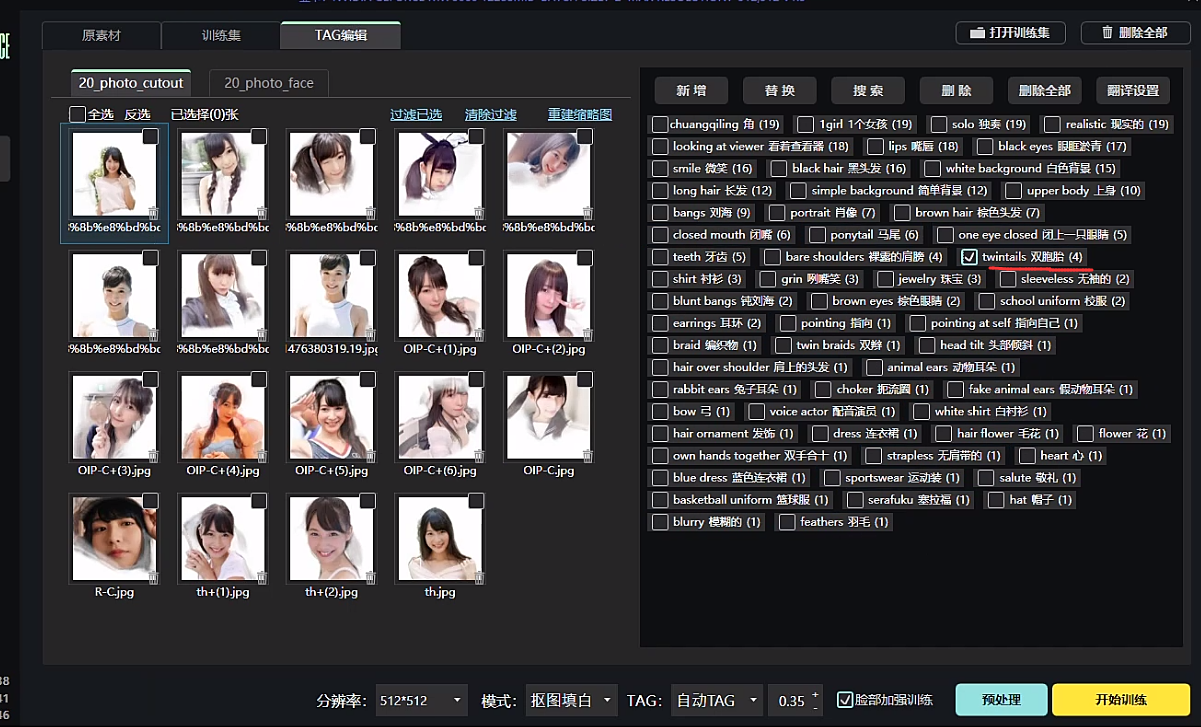
我这里整理一下,可以把这些TAG全部新增到每张图片,别忘了脸部也新增一下。
Best quality,masterpiece,ultra high res,(photorealistic:1.4),raw photo,Kodak portra 400,film grain,
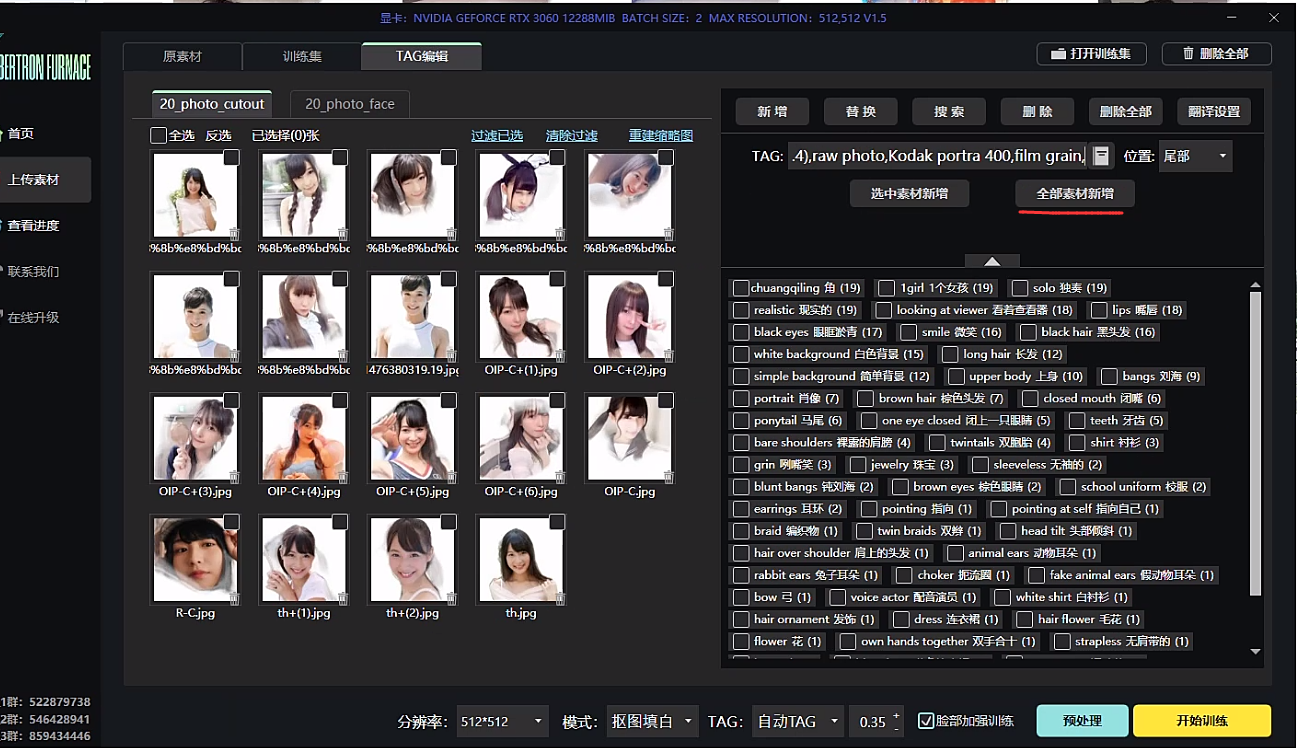
对于标签还有一个一定要知道的点!
自定义的tag,这个在炼丹炉那边是自动添加的,我这里加的liyi,预处理会自动加上liyi的tag,这个代表你想炼出的lora的共有效果,最好改一个有意义的名字。
自定义tag的含义:比如特定的蓝颜色眼睛,三角形嘴巴,没有鼻子这种特别能够代表这个lora的特征,统一用liyi来代表。 核心一点就是删去所有能代表模型共有特色的特征,用定义特征tag来统一代替。这样就告诉了AI,liyi就是整个训练集除去了已标明的个性化tag的剩下的所有特征。
实施起来,如果你想保留人物的某个共有特征,后续不需要提示词来提示,那就要把对应的标签删掉,这样AI就会默认这个人就是有这个特征。 如果你想灵活调整某个特征,那就要把这个特征打上标签举个例子:假如现在我要训练这个动漫人物的Lora,粉色头发和绿色眼睛就是这个人物的特征

如果你后续在SD里做这个动漫人物的照片希望可以保留她的特征,那我们就要把粉色头发和绿色眼睛的标签删掉,这样不管我们输入的关键词是白头发或者黑头发,出来的都会是粉色头发,如果你想在SD里自定义头发的颜色,那这里的标签就要打上“粉色头发”。

自此打TAG结束。
顺便推荐一个中文自动转英文的功能,打中文点击红框,自动转英文。需要的按我步骤操作一下,

进入网址,注册登录后,点击通用文本翻译

点击立即使用

然后选择个人开发者,填写一些个人信息,然后选择高级版,实名认证一些,图片就不放了,因为我弄过了,就是按照流程来,很简单,之后点击界面最上面的管理控制台选项,点击开通

然后选择通用文本翻译,开通高级版,最后一步填写应用名称就行,其他不管,提交申请就完了。

把APPID和密钥填入开启就完成了。

配置训练参数
先选底模,因为这次是训练的人物lora,这里选择的chilloutmix(亚洲美女),千趣丹炉里已经内置该底模,可以自行配置。
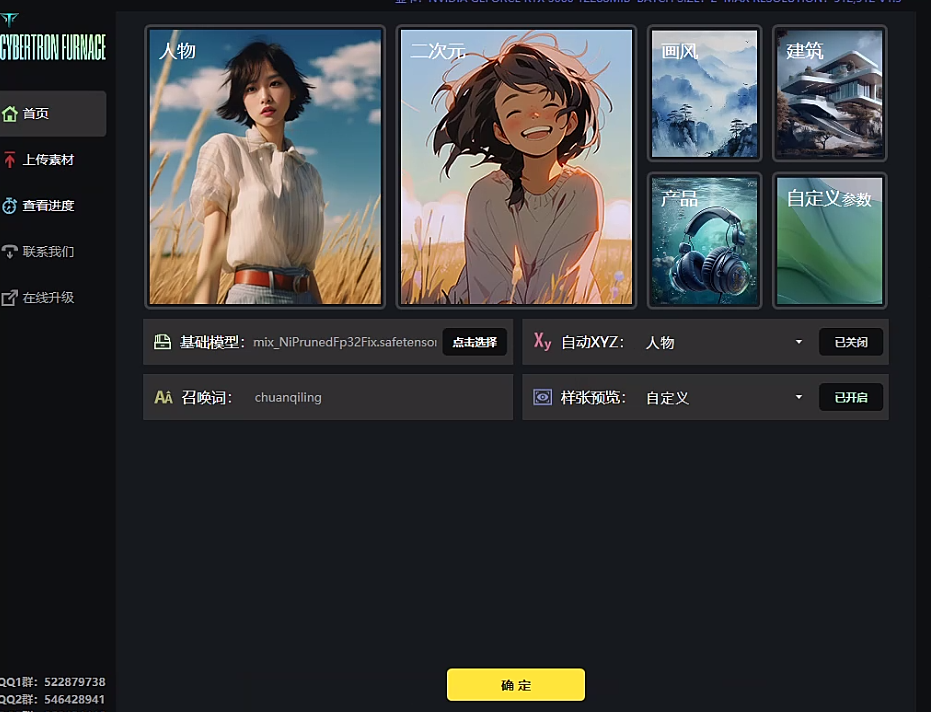
这里召唤词,也就是前面提到的自定义tag,最好改一下哈,我这里是chuanqiling,那以后召唤词就用chuanqiling。
左边快捷栏“上传素材”以及内部预处理这块刚刚上面已经完成了。
先别点击开始训练,查看进度界面,点击《参数调优》,切换到详细参数配置
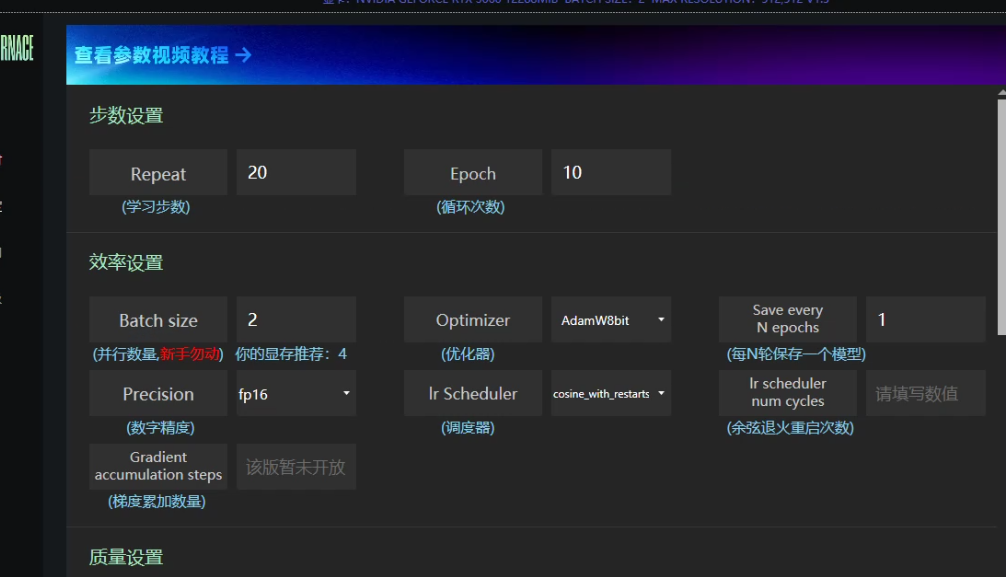
Repeat:学习多少步,不是越高越好,太少的话模型学不透,太多可能导致模型固化,缺少天马行空的能力。这次选20
Epoch:循环次数,也不是学习越多、学习越久就更好,和repeat类似。这次选10
这是个乘积关系,学习的总步数和这两个参数有关,当然学习的总步数越多效果越好,但是学习的对应时间越长。
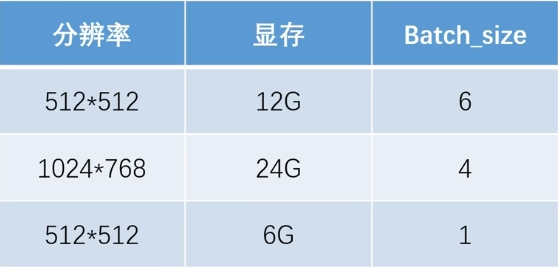
Batch Size:并行数量。数值越高训练越快,但是太大会爆显存,根据自己的设备去调整。这次选2
下面是分辨率、batch_size和显存的关系。
Optimizer:AdamW8bit
Save every N opochs:1
Precision:fp16
Lr Scheduler:cosine_with_restart
Lr scheduler num cycles: 默认不填
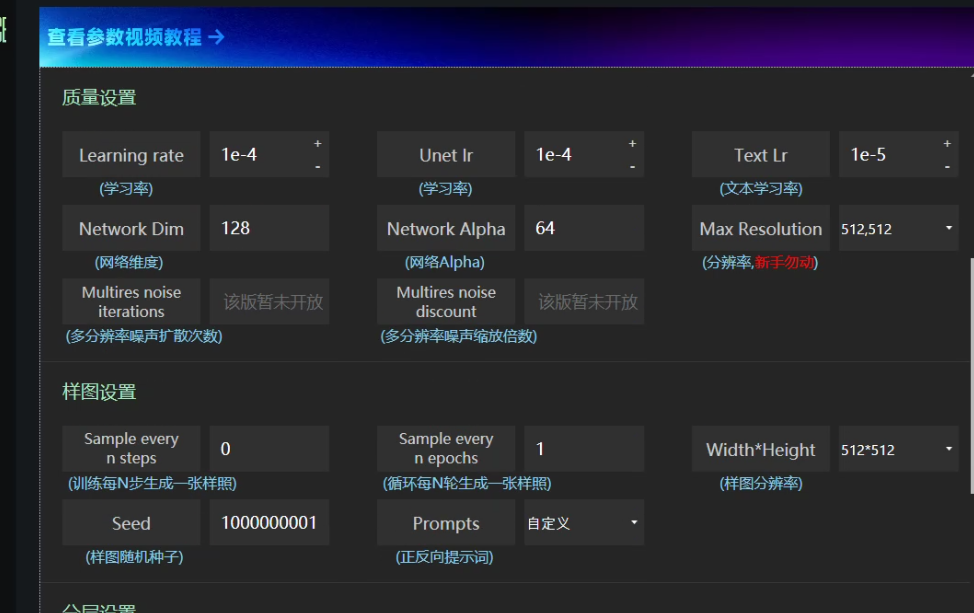
Learning Rate:学习率,1e-4
Unet Lr:unet网络的学习率,1e-4
Text Lr:text编码网络的学习率,1e-5
NetWorkDim:学习精度,精细度高,模型的细节更好,推荐128
NetWorkAlpha:64
Dim选128,效果比较好,训练出来的lora模型文件大小144M,这也是为什么市面上不同的lora大小模型,网络维度128,64,32,分别对应144M,72M,36M网络Alpha需要调成和网络维度一样,或者一半。如网络维度128,网络Alpha128或64。样图分辨率设置成和前面图片预处理一样,如果是512*512,那么这里也改成512*512。如果爆显存就默认别改了。

Sample every n steps:训练每N步生成一张样照,填0
Sample every n epochs:训练每N轮生成一张样照,填1
Width*height:样图分辨率,512*512
Seed:随机种子,-1的话每轮生成图片的种子数不同,这里设置定值10000001
Prompts:默认
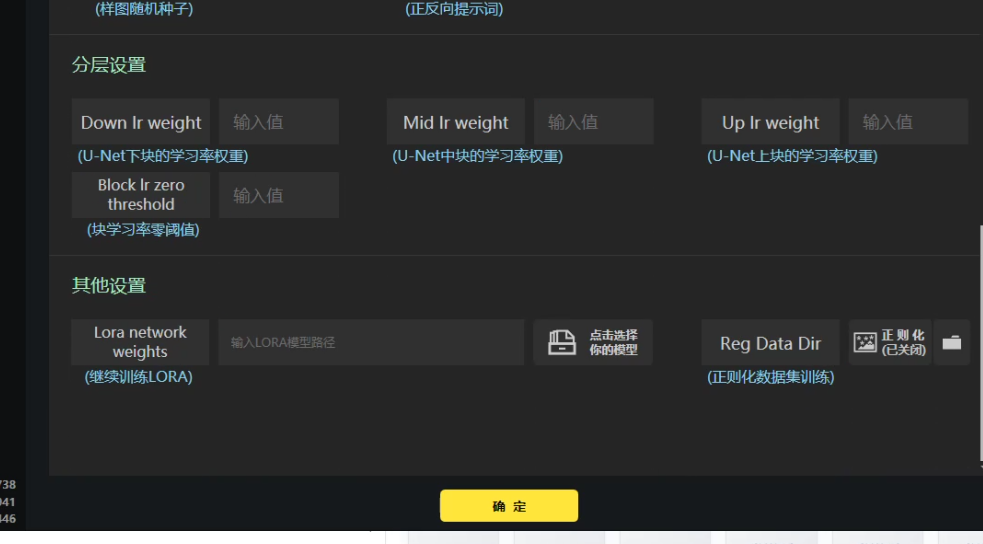
分层训练,可以查看下图,仅帮助理解,因为lora仅仅是训练一部分网络架构,不是全部unet,unet网络就是一个u型网络架构,先进行下采样在进行上采样,中间一层就是中间层。有兴趣看看。https://zhuanlan.zhihu.com/p/634573765

如果没有特殊需求分层设置先默认不填,其他设置中可以加载预训练模型。正则化就是防止过拟合,如果想要开启正则化,点击开启。然后把你的图片放入正则化文件夹就行。
训练
参数调整完毕!!回到界面,点击《开始训练》
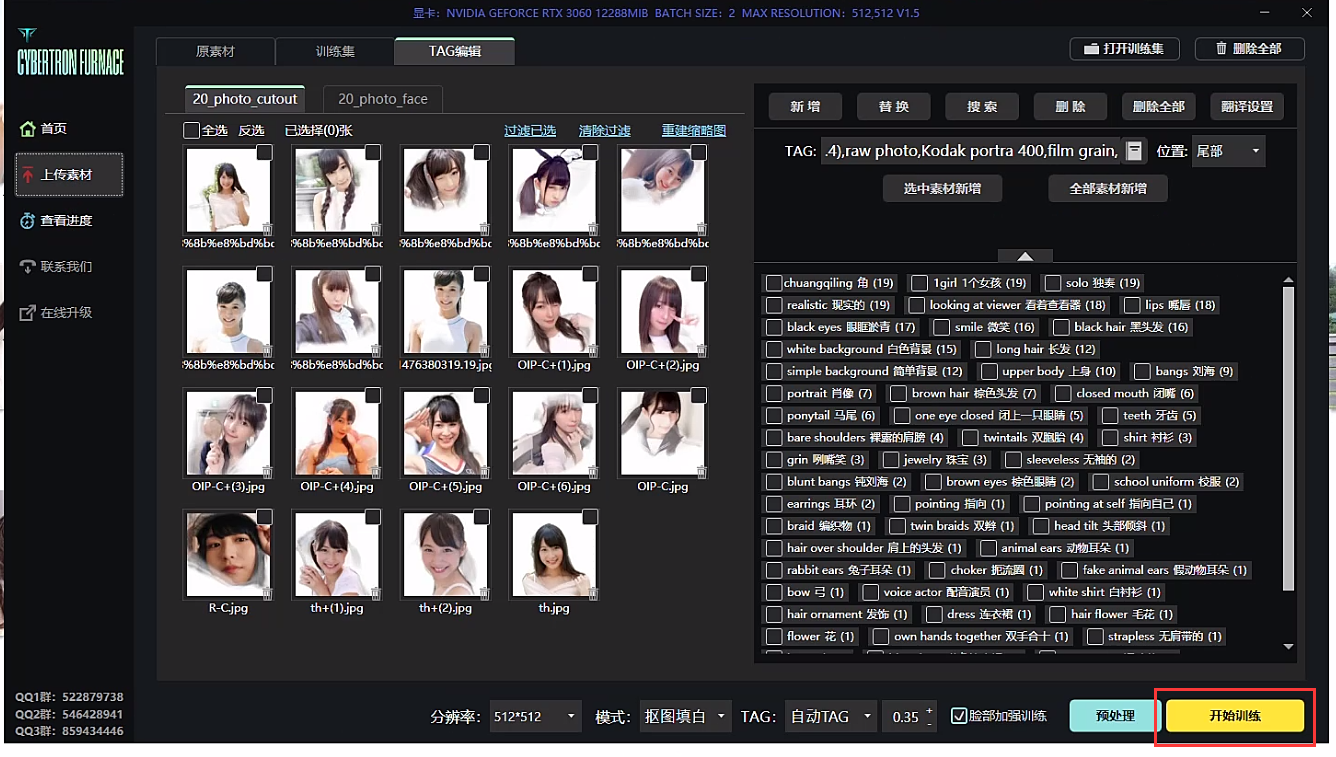
点击《查看进度-》显示样张》这个丹炉在跑的时候也会生成预览图片,如果觉得图片跑崩了可以先暂停。新手可以先不管这个。 最后在丹炉文件夹里有个\train\model目录,里面有炼好的很多个Lora模型,因为参数里面配置了每N步就出一个Lora模型,所以基本上会出很多个lora。
Loss可以用来参考模型的好坏,一个好的模型Loss值在0.05~0.09之间,普遍认为0.08附近最优,实际情况也出现过偏向0.05。具体好不好还是要在Stable Diffusion评测才知道。训练过程中Loss的趋势应该是下降才对,如果出现反复上升甚至反升,大概率是图片质量不够好或者数量太少。
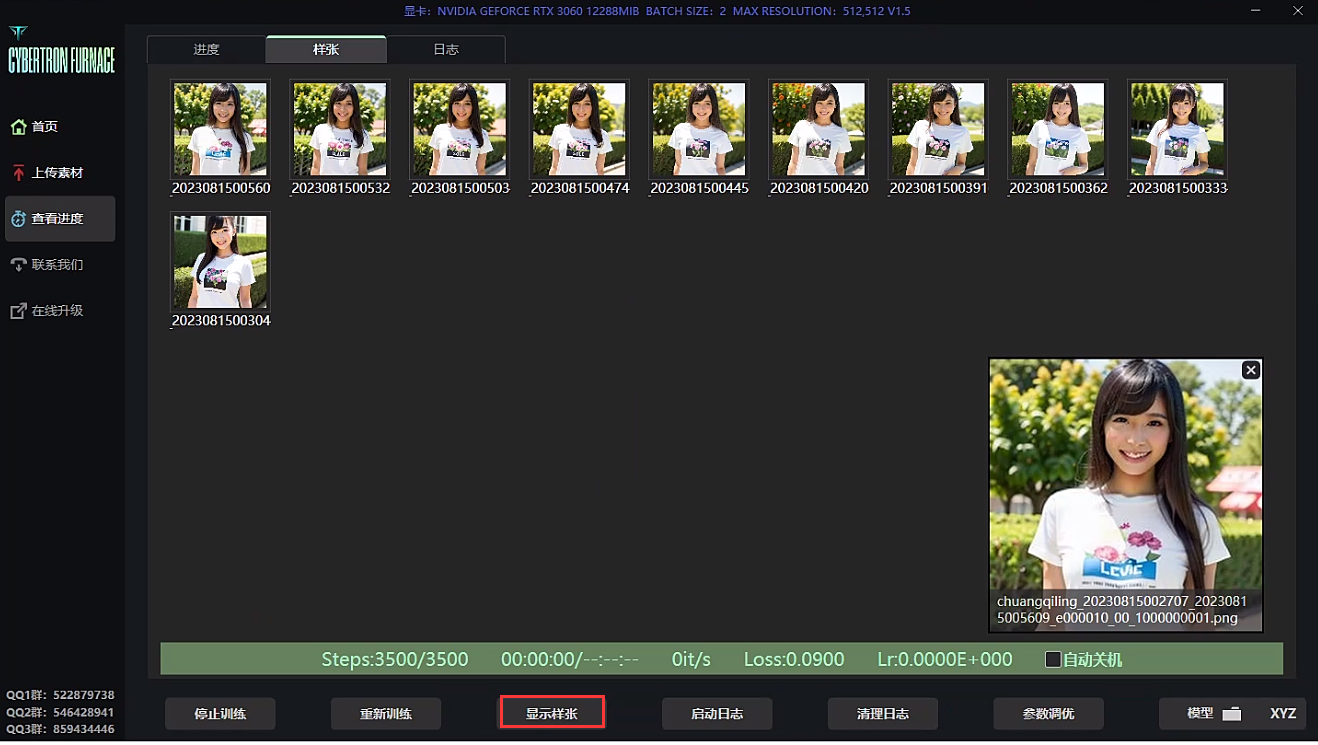
可以查看日志,查看模型的详细信息。模型训练完之后,点击《模型》即可。
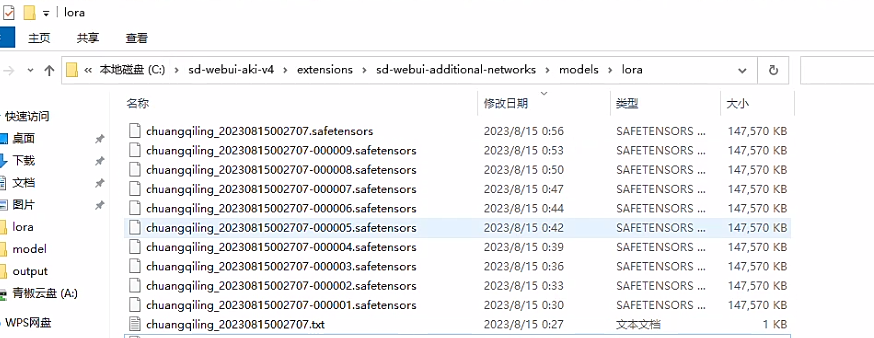
可以看到生成出来模型按照默认参数训练会出来10个模型,但不是说最后一个模型就是最好的。有可能炼到第六第七个模型就已经够了,再往后的模型就已经训练过度了。所以这些模型还要实际在SD测试一下,才知道哪个是最好的。
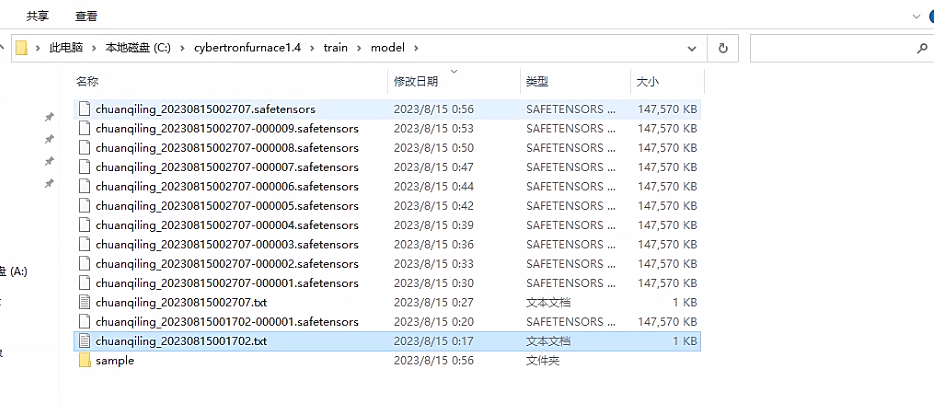
我们所有的训练数据都在这,包括训练集,日志,模型,正则化目录。
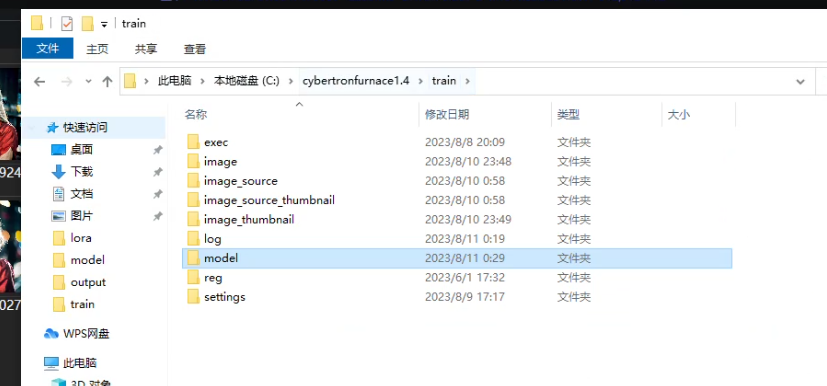
可以看到,样图,训练的参数配置文件,以及每个epoch的模型都保存在这,建议分别在前中后选取模型测试效果,epoch少的不一定差。对了,文件名可以改的,不影响。
训练样张如下
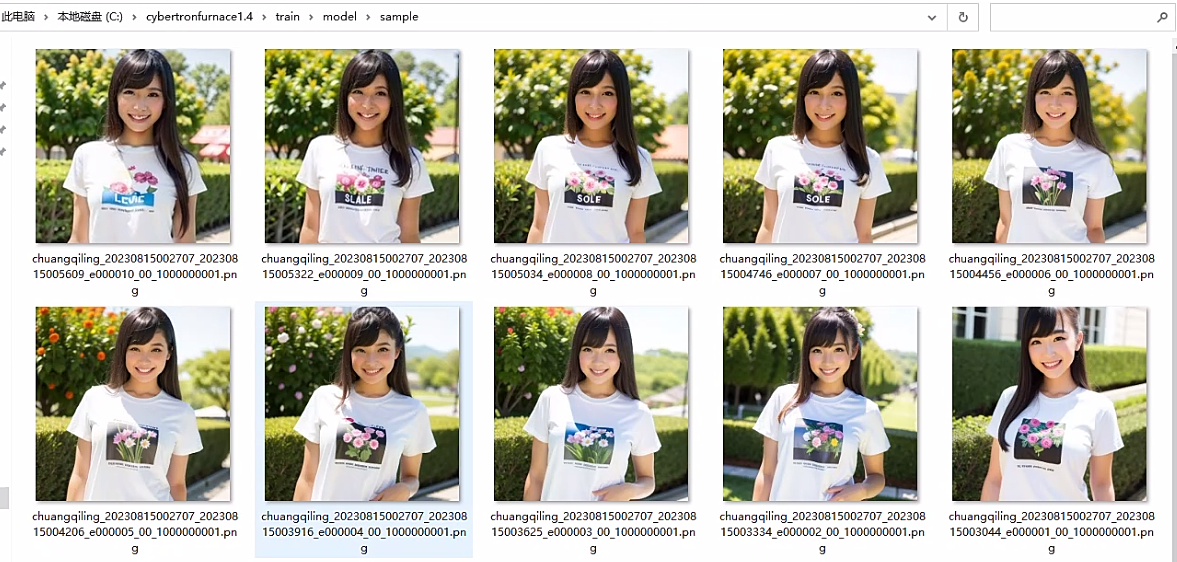
到此,丹炉介绍完毕!!!应该很详细了,点个赞给博主提提神把!!!
Lora评测
1、XYZ挑选模型
模型生成出来之后就可以到Stable Diffusion(简称SD)里面生成一张XY大图,可以直接看到所有模型在不同权重下出来的效果,比较一下哪个模型更好,就只保留那个模型就可以了。
这里面推荐将训练好的lora放到lora插件里面,我的具体路径为:C:\sd-webui-aki-v4\extensions\sd-webui-additional-networks\models\lora
之后用SD生成XY轴图看效果,这个是在文生图里。
以上文的模型组为例,介绍xy轴添加方法:
首先用哪一个大模型来训练lora就选哪个大模型,然后输入正面关键词和负面关键词,正面关键词可以输入一些质量词,比如最高质量、高清画质、大师杰作等等,负面关键词直接复制我以前用过的就可以,建议多写。
然后,Additional Networks 里的附加模型1,lora,模型1选择chuanqiling_20230815002707-000001.safetensors,权重默认1。
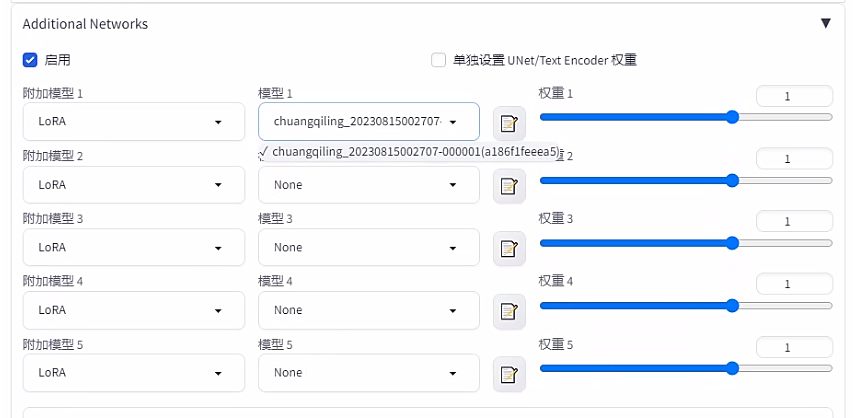
然后选最下面的那个脚本,选XYZ图,X轴选择附加模型1,X轴值点击右下角的红色圆柱是可以编辑的,选择本次新增的lora,其他删掉。Y轴选择附加模型1权重,其权重从0.1一直到1,中间逗号隔开。
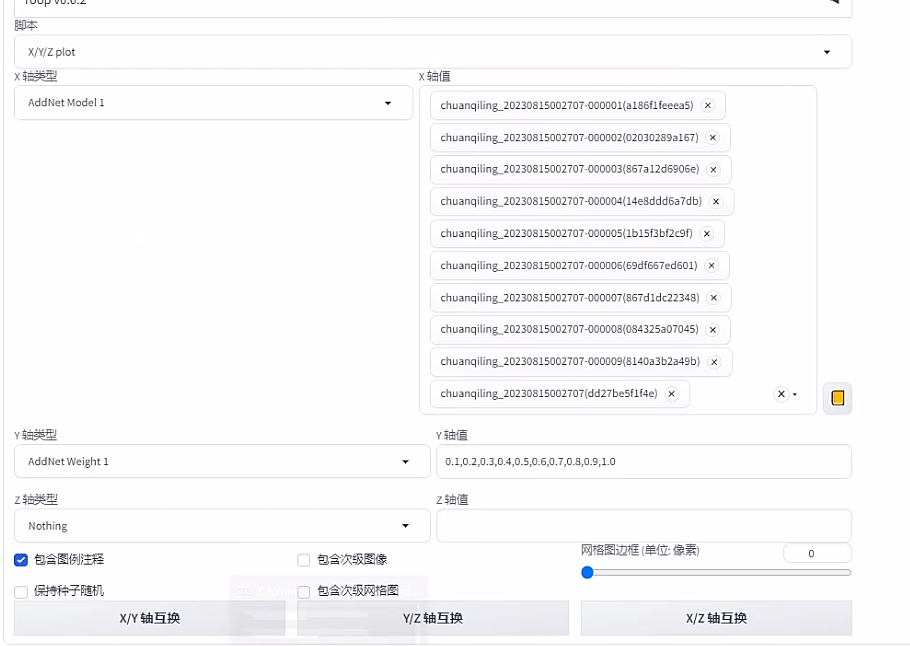
最后就能生成如下的图:

这样整个可以看到训练出来的1-10模型权重分别是0.1到1的效果,一般来说,生成XY图的prompt加上了比如(银色的头发)这种来看泛化性如何,如果泛化性比较好,就只会出银色的头发。同时还要看权重高的情况下,比如0.8-1的情况下,生成的图片像不像原图,如果像才说明效果好,一般来说0.1的权重是肯定不像你想要的。 比如上面的图,我觉得第8个模型还不错,权重比较高的情况下像训练集中的图片效果,只是泛化性感觉还不行,都是黑色头发,可能存在欠拟合的情况,继续增加epoch轮次,模型可能会进一步进化。
2、模型泛化性测试
接下来我们就可以测试一下第8个Lora的泛化性,在关键词里面输入一些照片里没有的东西比如原来图片是黑色头发居多,那就在关键词里面输入一个银色头发,原来图片是黑色、白色衣服,那就可以让它变成红色衣服。Additional Networks 里的附加模型1,lora,模型1选择chuanqiling_20230815002707-000008.safetensors,权重默认1。一次性抽4张卡。
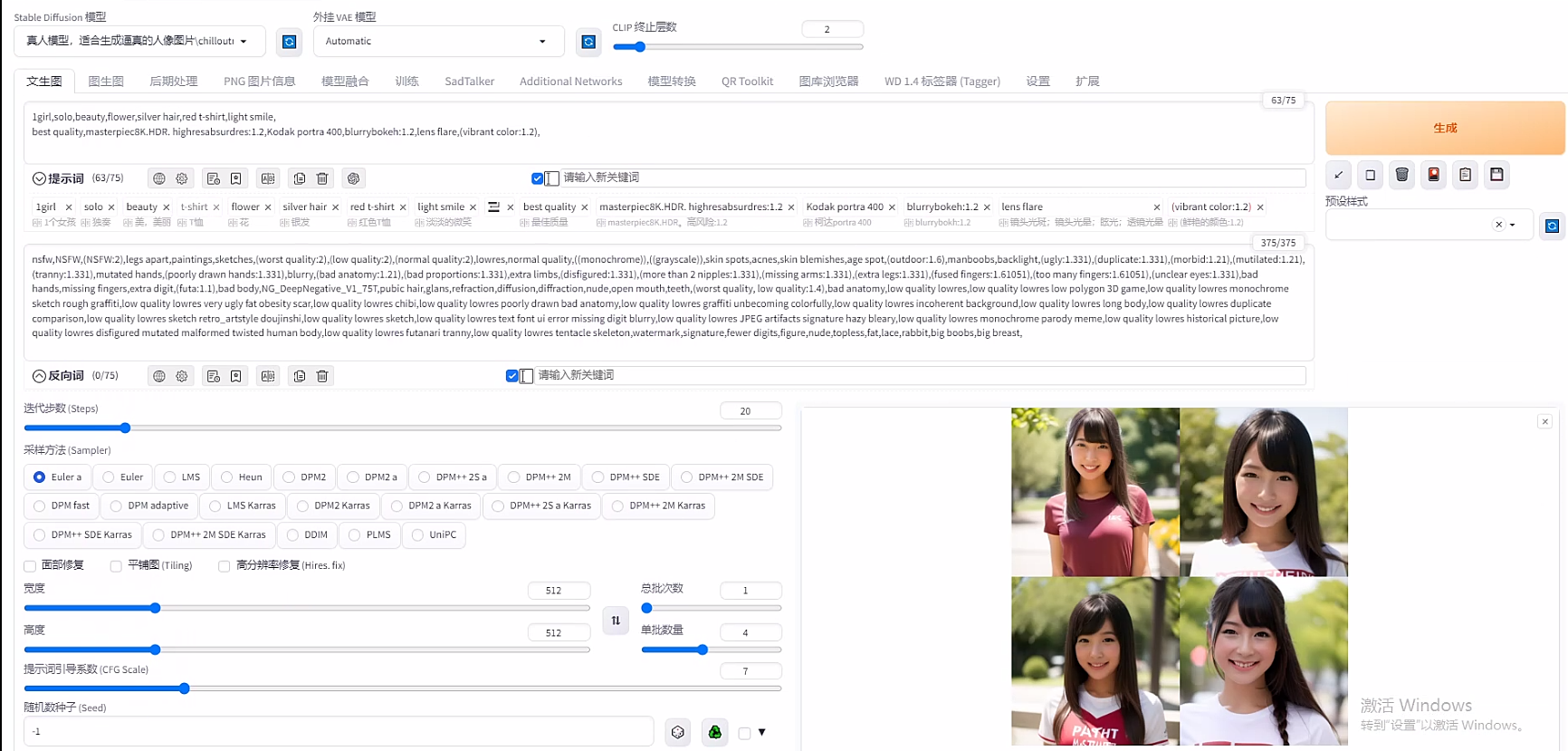
点击“生成”,看一下出来的照片,头发4黑0银,衣服2红2白,头发抽卡率不行,衣服颜色还可以接受。可能和训练集里头发都是黑色有关,人物整体质量很高,那我觉得这个Lora基本合格了,后续还可以继续优化。
还可以结合作者整合包里添加的修脸face editor、换脸roop工具,进行二次创作,玩转lora简直不要太轻松!!!

如何优化lora
实际上,炼丹是一件比较玄学的事,有的人可能一次性就能炼出自己满意的Lora,但有的人可能要炼好几次才出来一个好的Lora。
这里我们就把炼Lora会遇到的问题分成两种情况1、Lora出来的照片不像本人:AI没学好,欠拟合2、Lora过拟合,甚至出来的照片崩了:AI学过头了过拟合就是不管输入什么关键词,出来的照片都是你喂给AI的照片没办法自由控制人物的服装、发型、发色等
这时候我们可以进行以下调整再重新炼一个:
1、原图高清处理下,数量太少的话炼的过程中有不错的图就放进来做训练集的一部分,作者训练图集偏少,lora学习速度偏慢,甚至可能欠拟合。但并不是图片越多越好。因为图片太多的时候,可能有很多重复的,影响训练方向。
2、tag打好,删掉想要的特征,保留自定义tag,这个tag一定要出现在prompt里面。小技巧:可以通过跑原tag检查模型训练效果,与原图越接近,说明tag越精准。
3、训练参数调整,如果生成的照片不像本人,那就可以适当增加Repeat(学习步数)、Epoch值;如果照片过拟合了,那就减少Repeat(学习步数)、Epoch值。其他参数都可以不用调,因为默认的参数就差不多是最优值了。
4、人物lora,底膜的选择,sd基础模型训练的lora泛化性好,质量稍差,改进过的基础模型,lora生成的质量高,但泛化性差,特定场景无法生成,需要按实际情况选择。
最后分享一下作者的公众号,一个AI交流平台,支持在线文生图、GPT聊天,还支持SD的一体机服务,一起体验AI的乐趣,玩转AI简直不要太轻松!!!

参考链接:
stable diffusion LORA模型训练最全最详细教程:https://zhuanlan.zhihu.com/p/648330365
Stable diffusion训练Lora全集:https://zhuanlan.zhihu.com/p/637781678
保姆级Lora炼丹教程,一站式整合包,让你实现真人模特定制:https://zhuanlan.zhihu.com/p/639671944
Stable diffusion炼Lora踩坑记3:https://zhuanlan.zhihu.com/p/637438496
纯小白想开训lora?参数设置看这一篇就够用了:
https://zhuanlan.zhihu.com/p/640274202

