
- 1关于前端开发的20篇文档与指南_前端开发指导文档
- 2Android Studio启动AVD报错:The emulator process for AVD Pixel_5_API_30 has terminated.最有效的解决方法_the emulator process for avd pixel 5 api 30has ter
- 3AutoDL平台Pycharm使用教程_pycharm jupyter使用autodl
- 4强制卸载 奇安信天擎_奇安信天擎怎么强制卸载
- 5C语言实现贪吃蛇游戏
- 6【SQLServer】JDBC连接SQLServer数据库_sqlserver jdbcurl string
- 7软考--各个网络层次的安全保障协议分类_物理层加密协议有哪些
- 8Gitee删除自己本地仓库_gitee怎么删除本地仓库
- 9零基础快速搭建Stable Diffusion(Windows版)_从0到1搭建stablediffusionxl
- 10RocketMQ —消费重试_rocketmq消费重试
大语言模型能否替换传统多轮任务型问答系统?_大语言模型的多轮对话能力
赞
踩
语言模型能否替换传统多轮任务型问答系统?
以下文章来源于无数据不智能 ,作者森本悟

概述
本论文(Are LLMs All You Need for Task-Oriented Dialogue?)的研究背景是,大型语言模型(LLMs)由于其对话交互的能力在最近变得越来越受欢迎。因此,本文旨在研究LLMs在任务导向型对话中的表现。
以往的方法中,专门针对任务的模型在处理数据实体上表现更好。通过本文的评价,LLMs的表现不如这些自定义模型。但是,LLMs在给定正确的槽位值的情况下,有引导对话进入成功结束的能力。另外,用户提供的实体数据与模型预测的槽位之间的差异越小,模型表现越好。本文的研究方法和解决问题的动机均合适。
本文提出了一种针对任务导向型对话的方法,其中将LLMs用于上下文状态提取和生成目标响应。此外,本文还提出了基于真实槽位分布或指定领域中的示例数据的联合训练方法以提高模型的性能。
本文的研究任务在任务导向型对话中处理多轮会话的数据实体。LLMs在明确的状态跟踪方面的表现不如特定的任务模型,但在给定正确的槽位值的情况下,它们仍然可以为对话提供引导,提高了对话成功的概率。联合训练方法可以进一步提高模型的性能。
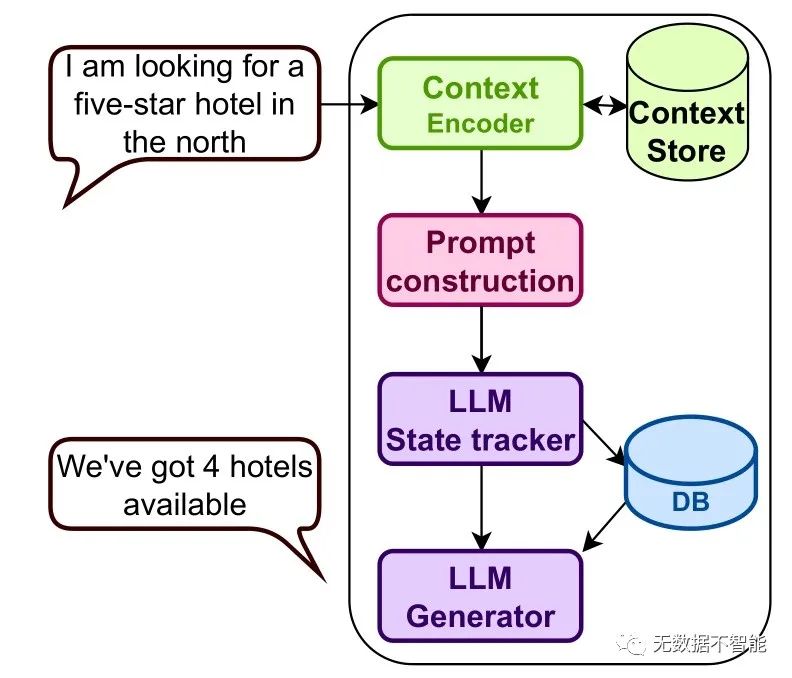
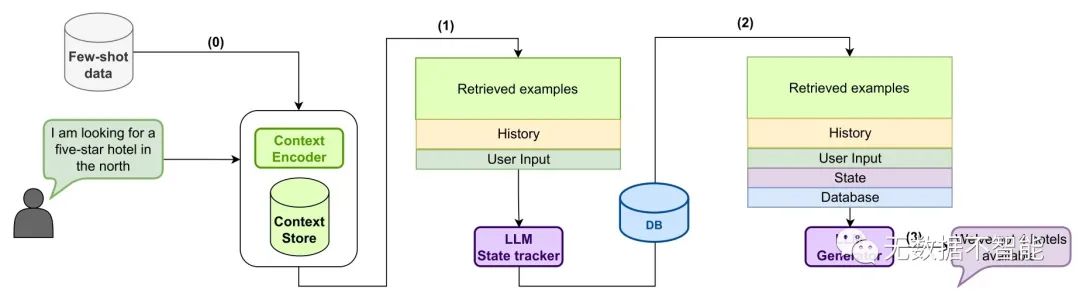
重要问题探讨
-
在对话系统中,如何提高预测准确率?
作者在本文中提出了一种方法,即使用上下文存储库,通过类似的对话历史记录进行训练。此外,他们还通过给出正面和负面抽取的例子,来轻松地完成上下文的存储,以便于中等程度的训练。他们还介绍了一种新的零样本对话状态追踪的架构,如何在零样本场景下处理这些问题?
2. 对话状态实时跟踪中怎样提高精度和速度?
作者在本文中描述了一个基于BERT的上下文感知联合模型(CA-Joint)。CA-Joint模型可以结合上下文信息和BERT编码器来生成更加丰富的隐含表示形式,以提高状态追踪的精度和速度。该模型在性能上优于现有方法。
3. 自从许多最新的对话系统处理技术被提出后,如何进行多领域的训练?
作者在本文中使用了Schema Guided和MultiWOZ 2.2两个多领域数据集进行实验研究。Schema Guided包含18个领域和145个指南,MultiWOZ 2.2包含7个领域和29个指南。使用这些多领域数据集进行实验可以使研究人员更好地评估不同技术的性能。
4. 在领域识别中,使用了什么技术来提高系统对话的成功率?
对于每一个多领域的对话,作者构建了一个相应的上下文仓库。使用此仓库中的对话历史记录来识别当前对话的领域。本文中,作者采用了统计学方法来进行领域识别,但可以将此项工作扩展到深度学习中。
5. 在对话状态追踪方面,如何应对常见的问题?
在本文中,作者在对话状态追踪方面采用了基于BERT的上下文感知联合模型(CA-Joint),这种模型可以更好地处理多领域对话中的常见问题。同时,作者还使用数据存储库来提供多个对话历史记录,以对对话状态进行精准的跟踪。
6. 在对话响应生成方面,如何处理信息的不完整性?
对于缺失某些特定数据的情况,作者采用了delexicalized方法,即使用占位符代替缺失的信息。这种做法可以在信息不完整的情况下生成可靠的响应。然而,这种方法在某些场景下可能会导致困难,例如当数据缺失时。因此,对于特定的应用场景,需要找到一个有效的方法以平衡信息完整性和响应生成的准确性。
论文链接:https://arxiv.org/abs/2304.06556.pdf

