
- 1Air724UG 核心板学习记录-开发板介绍
- 2看大神如何用python爬虫爬取京东商品评论_python爬虫爬取京东电商平台商品评论,要求根据商品关键字爬取
- 3探索【Stable-Diffusion WEBUI】的附加功能:图片缩放&抠图_4x-ultrasharp
- 4AI程序员的出现与程序员的未来:饭碗之争的真相
- 548位一作相聚CVPR 2024预讲会/附全部议程
- 6Flask之ajax操作示例_flask 处理 ajex
- 7LLaMA模型指令微调 字节跳动多模态视频大模型 Valley 论文详解_valley: video assistant with large language model
- 8(五)比赛中的CV算法(下)目标检测终章:Vision Transformer_为什么不用vision transformer 做bacbone 进行目标检测
- 9包含密钥的OMP压缩感知模拟(MATLAB)
- 10备战蓝桥杯,用JAVA刷洛谷算法题单:【算法2-1】前缀和、差分与离散化
机器学习之朴素贝叶斯算法_td idf
赞
踩
作者:RayChiu_Labloy
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
目录
IDF是逆向文件频率(Inverse Document Frequency):
统计学中概率估计和参数估计的两大流派频率(概率)派和贝叶斯派
关于NLP中的概率图模型,我们知道目前最流行的算法思想包含如下两大流派:基于概率论和图论的概率图模型;基于人工神经网络的深度学习理论。
贝叶斯公式与朴素贝叶斯算法
贝叶斯公式推导
贝叶斯公式最早是由英国神学家贝叶斯提出来的,用来描述两个条件概率之间的关系。在之前的条件概率定义中,我们知道 :
![]()
可推导出:![]()
由此,推广到随机变量的范畴,设X,Y为两个随机变量,得到贝叶斯公式:![]() 其中,P(Y)叫作先验概率,P(Y|X)叫作后验概率,P(Y,X)是联合概率
其中,P(Y)叫作先验概率,P(Y|X)叫作后验概率,P(Y,X)是联合概率
用机器学习的视角理解贝叶斯公式
在机器学习的视角下,我们把X理解成“具有某特征”,把Y理解成“类别标签”(一般机器学习为题中都是X=>特征, Y=>结果对吧)。在最简单的二分类问题(是与否判定)下,我们将Y理解成“属于某类”的标签。于是贝叶斯公式就变形成了下面的样子:

我们简化解释一下上述公式:
P(“属于某类”|“具有某特征”)=在已知某样本“具有某特征”的条件下,该样本“属于某类”的概率。所以叫做『后验概率』。
P(“具有某特征”|“属于某类”)=在已知某样本“属于某类”的条件下,该样本“具有某特征”的概率。
P(“属于某类”)=(在未知某样本具有该“具有某特征”的条件下,)该样本“属于某类”的概率。所以叫做『先验概率』。
P(“具有某特征”)=(在未知某样本“属于某类”的条件下,)该样本“具有某特征”的概率。
而我们二分类问题的最终目的就是要判断P(“属于某类”|“具有某特征”)是否大于1/2就够了。贝叶斯方法把计算“具有某特征的条件下属于某类”的概率转换成需要计算“属于某类的条件下具有某特征”的概率,它解决了概率论中“逆向概率”的问题。而后者获取方法就简单多了,我们只需要找到一些包含已知特征标签的样本,即可进行训练。而样本的类别标签都是明确的,所以贝叶斯方法在机器学习里属于有监督学习方法。
这里再补充一下,一般『先验概率』、『后验概率』是相对出现的,比如P(Y)与P(Y|X)是关于Y的先验概率与后验概率,P(X)与P(X|Y)是关于X的先验概率与后验概率。
NB(朴素贝叶斯)
朴素贝叶斯(Natvie Bayes)法是基于贝叶斯定理和特征条件独立假设的分类方法。
关于为什么“朴素”,也就是说为什么前提是要特征条件独立呢? 从概率论角度分析我暂时没搞明白,待后补。。。
常用到的三个模型
高斯模型、多项式模型、伯努利模型,分别看样本数据的类型做选择,如果样本特征的分布大部分是连续值使用高斯模型,如果大部分是多元离散值使用多项式模型,如果大部分是二元离散值或者很稀疏的多元离散值用伯努利模型。
取一组连续性数据举例解释NB
假如我们有一组统计出来的经验数据:

A1 A2 A3是人的特征,C是类别结果,假如有一组新特征数据,让我们猜是男是女:身高“高”、体重“中”,鞋码“中”
那么根据上边给出的贝叶斯公式得:

例如:P(男|高,重,大) = P(高,重,大|男)P(男) / P(高,重,大)
因为一共有 2 个类别,所以我们只需要求得 P(C1|A1A2A3) 和P(C2|A1A2A3) 的概率即可,然后比较下哪个分类的可能性大,就是哪个分类结果,等价于求 P(A1A2A3|Cj)P(Cj) 最大值
我们假定 Ai 之间是相互独立的,那么:![]()
P(A1|C1)=1/2,P(A2|C1)=1/2,P(A3|C1)=1/4,P(A1|C2)=0,P(A2|C2)=1/2,P(A3|C2)=1/2因此:
P(A1A2A3|C1)=1/16,P(A1A2A3|C2)=0,前者大于后者所以我们猜测这组新特征是男性。
以上例子是针对离散型数据的计算方式,连续性稍有区别。
应用朴素贝叶斯分类的过程:
朴素贝叶斯分类常用于文本分类,尤其是对于英文等语言来说,分类效果很好。它常用于垃圾文本过滤、垃圾邮件分类、情感预测、推荐系统等,过程如下:
特征和类别明确训练集准备:
在这个阶段我们需要确定特征属性,比如上面案例中的“身高”、“体重”、“鞋码”等,同时明确预测值是什么。并对每个特征属性进行适当划分,然后由人工对一部分数据进行分类,形成训练样本。这个阶段可以说非常重要,数据质量高则效果好。
在文本分类中生成训练样本集方法常用TF-IDF。
训练模型
朴素贝叶斯这块什么是我们要训练的模型(分类器)就是统计出来的所有概率值,也就是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率。
这里我们总结一下计算过程,设x={a1,a2,...,am}为一个待分类项,而每个a为x的一个属性特征,有类别集合C={y1,y2,...,yn},我们还有一堆统计的来的经验数据,也就是训练集,那么我们可以通过对训练集的统计计算得出在各个类别下各个特征属性的条件概率估计,即:
p(a1|y1),p(a2|y1),...p(am|y1);
p(a1|y2),p(a2|y2),...p(am|y2);
......
p(a1|yn),p(a2|yn),...p(am|yn);
模型应用
输入上一步训练出来的分类器和新特征数据,输出新特征数据的分类结果。
例如我们可以接着上一步计算出新特征数据对应的p(y1|x),p(y2|x),p(y3|x),...,p(yn|x)中最大的那个yk类别,那x就属于yk这个类别。
具体来说,假设数据特征满足NB的特征独立条件,那么应用贝叶斯公式![]() 又因为最终我们比较的是分子大小,分母没影响所以去掉分母可得:
又因为最终我们比较的是分子大小,分母没影响所以去掉分母可得:
 。
。
对每个类别计算p(x|yi)p(yi),以p(x|yi)p(yi)的最大项作为x的所属类别。
文本分类之TD-IDF
什么是TD-IDF
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:
如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现(DF小),则认为此词或者短语具有很好的类别区分能力,适合用来分类。
one-hot编码:
虽然存在局限性但是one-hot编码仍然是文本分类领域使用非常广泛的词表示方法。
文本分类中会把语料库中出现的所有词分词后去重合起来组成语词典,词典容纳了语料库中所有句子的词汇。One-hot方法就是把每个词表示为一个长长的向量。这个向量的维度是词典大小,其中绝大多数元素为0,只有一个维度的值为1。这个维度就代表了当前的词。
例如,一个语料库有三个文本。
文本1:You dog ate my homework.
文本2:You cat ate the sandwich.
文本3:A dolphin ate the homework.
这三个文本生成的词典共有9个词:
[a, ate, cat, dolphin, dog, homework, you, sandwich, the]
这9个词依次表示为One-hot向量的形式如下:
‘a’ -> [1 0 0 0 0 0 0 0 0]
‘ate’-> [0 1 0 0 0 0 0 0 0]
...
‘the’-> [0 0 0 0 0 0 0 0 1]
其中,每个词都是”茫茫0海“中的一个1。这种稀疏的表达方式就是one-hot表达。它的特点是相互独立地表示语料中的每个词。词与词在句子中的相关性被忽略了,这正符合朴素贝叶斯对文本的假设。
TF是词频(Term Frequency):
词频(TF)表示词条(关键字)在文本中出现的频率。
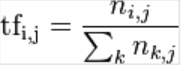 其中n是词在文章中次数,i是某一个词, j是某一篇文章, k是文章中词总数,即:
其中n是词在文章中次数,i是某一个词, j是某一篇文章, k是文章中词总数,即: 。
。
拿上边三个文本举例,每个文本根据词典转one-hot编码为:
文本1:0,1,0,0,1,1,1,0,0
文本2:0,1,1,0,0,0,1,1,1
文本3:1,1,0,1,0,1,0,0,1
没有表现出词的频率,出现次数累加优化:
文本1:0,1,0,0,1,1,2,0,0
文本2:0,1,1,0,0,0,1,1,1
文本3:1,1,0,1,0,1,0,0,1
为了抵消有的语料库中的文章篇幅过长的不公平影响,归一化各自除以词数,得到我们最终要的词频TF:
文本1:0,1/5,0,0,1/5,1/5,2/5,0,0
文本2:0,1/5,1/5,0,0,0,1/5,1/5,1/5
文本3:1/5,1/5,0,1/5,0,1/5,0,0,1/5
IDF是逆向文件频率(Inverse Document Frequency):
某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
这里可以理解为文件频率的倒数,也就是文件频率太高说明当前词在语料库中出现的太多,则说明没有区分能力,类似“停用词(各大厂家会自行维护的一套没啥用的词库)”之类的对分类没有帮助,一般会设定一个阈值过滤掉文件频率过高的词。
公式:![]() 其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|进行数据平滑。
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|进行数据平滑。
上边三个文本中词典中各自出现的次数:a(1), ate(3), cat(1), dolphin(1), dog(1), homework(2), my(3), sandwich(1), the(2)。
各自除以文档数就是文档频率DF了:a(1/3), ate(3/3), cat(1/3), dolphin(1/3), dog(1/3), homework(2/3), my(2/3), sandwich(1/3), the(2/3)
然后取逆再取log(默认IDF会log缩放,TF也可以)就是我们最终要的IDF了:a log(3/1), ate log(3/3), cat log(3/1), dolphin log(3/1), dog log(3/1), homework log(3/2), my log(3/2), sandwich log(3/1), the log(3/2)
TF-IDF应用
(1)搜索引擎;(2)关键词提取;(3)文本相似性;(4)文本摘要
python实现:
- # -*- coding: utf-8 -*-
- from collections import defaultdict
- import math
- import operator
-
- """
- 函数说明:创建数据样本
- Returns:
- dataset - 实验样本切分的词条
- classVec - 类别标签向量
- """
- def loadDataSet():
- dataset = [ ['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # 切分的词条
- ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
- ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
- ['stop', 'posting', 'stupid', 'worthless', 'garbage'],
- ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
- ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid'] ]
- classVec = [0, 1, 0, 1, 0, 1] # 类别标签向量,1代表好,0代表不好
- return dataset, classVec
-
-
- """
- 函数说明:特征选择TF-IDF算法
- Parameters:
- list_words:词列表
- Returns:
- dict_feature_select:特征选择词字典
- """
- def feature_select(list_words):
- #总词频统计
- doc_frequency=defaultdict(int)
- for word_list in list_words:
- for i in word_list:
- doc_frequency[i]+=1
-
- #计算每个词的TF值
- word_tf={} #存储没个词的tf值
- for i in doc_frequency:
- word_tf[i]=doc_frequency[i]/sum(doc_frequency.values())
-
- #计算每个词的IDF值
- doc_num=len(list_words)
- word_idf={} #存储每个词的idf值
- word_doc=defaultdict(int) #存储包含该词的文档数
- for i in doc_frequency:
- for j in list_words:
- if i in j:
- word_doc[i]+=1
- for i in doc_frequency:
- word_idf[i]=math.log(doc_num/(word_doc[i]+1))
-
- #计算每个词的TF*IDF的值
- word_tf_idf={}
- for i in doc_frequency:
- word_tf_idf[i]=word_tf[i]*word_idf[i]
-
- # 对字典按值由大到小排序
- dict_feature_select=sorted(word_tf_idf.items(),key=operator.itemgetter(1),reverse=True)
- return dict_feature_select
-
- if __name__=='__main__':
- data_list,label_list=loadDataSet() #加载数据
- features=feature_select(data_list) #所有词的TF-IDF值
- print(features)
- print(len(features))
朴素贝叶斯的优缺点
优点:
缺点:
统计学中概率估计和参数估计的两大流派频率(概率)派和贝叶斯派
频率派:认为theta是个固定的未知常数。认为样本是随机的,重点研究样本分布,认为数据决定了参数,通过数据的统计求似然得概率结果
贝叶斯派:认为theta是不确定的未知数。认为样本是固定的,重点研究参数theta的分布。
贝叶斯的思考方式不同于传统“非黑即白,非0即1”的思考方式。
先验分布+样本信息=后验分布
有一个基本的先验分布,基于先验概率条件,根据样本信息的变化和不断迭代,得到被影响的后验结果,数据量少的情况下表现优越。
理解两个流派的例子:一个人观察赌场里情况发现,某人连续十局赌赢了,那么统计学认为基于数据统计某人玩第十一局胜率会很大,但是贝叶斯方法会考虑先验知识>“十赌九输”,判定输的概率大;再比如抛硬币,连续一百次都正面朝上,那下一次按照贝叶斯方法来说还是50%的概率朝上。
贝叶斯网络
定义
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG),“有环的话,谎言传到最后自己都相信了”。
主要有顺连、分连、汇连这三种连接形式的网络。
顺连head-to-tail
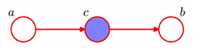
上图含义是:P(a,b,c)=P(a)P(c|a)P(b|c)
判断a和b是否独立的条件是:在c已知的条件下,a,b被阻断(blocked),是独立的
链式网络加长后是马尔科夫链
![]()
在xi给定的条件下,xi+1的分布和x1,x2…xi-1条件独立。即:xi+1的分布状态只和xi有关,和其他变量条件独立,这种顺次演变的随机过程模型,叫做马尔科夫链。
分连tail-to-tailtail-to-tail
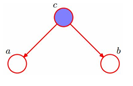
上图含义是:P(a,b,c)=P(c)P(a|c)P(b|c)
判断a和b是否独立的条件是:在c已知的条件下,a,b被阻断(blocked),是独立的
汇连head-to-head
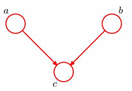
上图含义是:P(a,b,c) = P(a)P(b)P(c|a,b)
判断a和b是否独立的条件是:在c未知的条件下,a,b被阻断(blocked),是独立的
拉普拉斯平滑
零概率问题,就是在计算实例的概率时,如果某个量x,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。在文本分类的问题中,当一个词语没有在训练样本中出现,该词语调概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
公式:


其中ajl,代表第j个特征的第l个选择,Lj代表第j个特征的个数,K代表种类的个数,![]() 为1。
为1。
朴素贝叶斯在垃圾邮件分类中和传统正则匹配关键字对比
为什么像垃圾邮件分类这种需求要用朴素贝叶斯而不直接用更简单的正则匹配找“垃圾”关键字来处理?
乍一听正则处理好像更简单,其实事实上这种方法准确率太低。我们在工作项目中也尝试过用关键词匹配的方法去进行文本分类,发现大量误报。感觉就像扔到垃圾箱的邮件99%都是正常的!这样的效果不忍直视。而加一个朴素贝叶斯方法就可能把误报率拉低近一个数量级,体验好得不要不要的。
另一个原因是词语会随着时间不断变化。发垃圾邮件的人也不傻,当他们发现自己的邮件被大量屏蔽之后,也会考虑采用新的方式,如变换文字、词语、句式、颜色等方式来绕过反垃圾邮件系统。比如对于垃圾邮件“我司可办理正规发票,17%增值税发票点数优惠”,他们采用火星文:“涐司岢办理㊣規髮票,17%增値稅髮票嚸數優蕙”,那么字符串匹配的方法又要重新找出这些火星文,一个一个找出关键词,重新写一些匹配规则。更可怕的是,这些规则可能相互之间的耦合关系异常复杂,要把它们梳理清楚又是大一个数量级的工作量。等这些规则失效了又要手动更新新的规则……无穷无尽猫鼠游戏最终会把猫给累死。
而朴素贝叶斯方法却显示出无比的优势。因为它是基于统计方法的,只要训练样本中有更新的垃圾邮件的新词语,哪怕它们是火星文,都能自动地把哪些更敏感的词语(如“髮”、“㊣”等)给凸显出来,并根据统计意义上的敏感性给他们分配适当的权重 ,这样就不需要什么人工了,非常省事。你只需要时不时地拿一些最新的样本扔到训练集中,重新训练一次即可。
文本分类中的一些技巧
连乘取对数变为连加时间开销变小。
关键词设置权重让更容易分类的特征更加有发言权,位置权重可以帮助提升分类效果
像垃圾邮件分类需求,文章样本分割来提速判断是否是垃圾邮件
参考:朴素贝叶斯分类:原理_qiu_zhi_liao的博客-CSDN博客_朴素贝叶斯
TF-IDF算法介绍及实现_Asia-Lee-CSDN博客_tf-idf
垃圾邮件分类快速理解机器学习中的朴素贝叶斯(Naive Bayes)_猫猫玩机器学习的博客-CSDN博客
【如果对您有帮助,交个朋友给个一键三连吧,您的肯定是我博客高质量维护的动力!!!】

