
- 1Android AAChartView饼图开发_android aachatcore
- 2为什么LLM都用的Decoder only结构?_encoder的模型是在训练的时候一直在做完形填空
- 3Pytorch实现RNN进行文本(情感)分类_torch rnn可以做文本分类吗
- 4Spring boot 结合Mockito、junit、MockMVC_springboot 集成mockito
- 5【CVPR红外小目标检测】红外小目标检测中的非对称上下文调制(ACM)_asymmetric contextual modulation for infrared smal
- 6RAG 全链路评测工具 —— Ragas_ragas算法
- 7【ChatGPT4】王老师零基础《NLP》(自然语言处理)第一课_nlp在chatgpt上的基础知识
- 8国内首场高规格AIGC峰会盛况出圈!万字干货热聊GPT-4时代,浓缩21位大牛演讲_nolibox 汽车 合作
- 9从零开始学数据分析之数据分析概述
- 10数字人添加背景(heygen+剪映)_heygen数字人
学习知识图谱中无提及实体对的关系表示_知识图谱实体表征
赞
踩
前言
知识图谱近些年来应用场景非常多,随之延伸出来的技术也是层出不穷。
知识图谱一个常见的挑战就是稀疏性,为了解决这一难题,知识图谱embedding被提了出来即把图谱中的entities和relations映射到一个低纬的vector,这些model可以根据实体pair预测潜在的关系,但是这些模型之前基本上都是只使用图谱 中的数据进行train,而图谱本身就稀疏,好多关系可能都没有,这样就大大的从源头限制了模型的有效性或者说这个事情的天花板就不会太高。
于是乎很多研究者将目光聚集在图谱之外的数据即大量的文本,利用共现的天然关系来增强知识图谱,简单来说就是假设一对实体pair在一句话中同时出现,那么这句话就蕴含着某种关系。所以说大量语料corpus蕴含着很多知识(其实远程监督就是这个思想)。通过这些语料联合知识图谱一起得到的数据就更全面了。
但是可以看到上述的关键是”共现“,但是大量的语料其实在有限的窗口内(简单的话可以理解为一句话)并没有共现关系,今天要给大家介绍的这篇paper就是怎么利用好这部分信息。
论文链接:https://arxiv.org/pdf/2204.13097v1.pdf
背景
为了便于理解,说几个论文中提到的概念,知识图谱是KG,知识图谱embedding化是KGE,利用共现数据来增强是with-mention entity-pair,利用无共现数据是without-mention entity-pair,共现的一个句子叫做l,三元组(h, r, t)分别代表头实体、关系、尾实体。利用with-mention entity-pair给图谱的方法为LDP。为了表征一个实体pair,作者使用了一个encoder对其编码即f(h, t;θ),encoder的输入是:
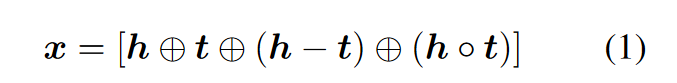
添加图片注释,不超过 140 字(可选)
可以看到是背景常见的拼接手段。
同时因为应用了共现的数据,其实说白了就是一个word的集合,为了表征这句话我们可以使用很多手段,作者采用了SBERT 来encoder。
方法
其实作者的思想非常简单朴素,有点对比学习的味道在里面,那就是:共现的LDPs要比不共现的LDPs距离f(h, t;θ)更近或者说更相似。
具体来说就是将共现的句子表征作为正样本,将不共现的句子(其中一个实体单独出现,h或者t都可以)作为负样本。具体采用的是marginal loss如下:

红色的就是上述说的正样本,黄色是负样本。
好了,idea到此结束,是不是很至简。
实验效果
为了对比效果,作者这里搞了很多baseline来对比,如下
LinkAll:这个baseline是作者将所有without-mention entity-pair单独连了起来
Co-occurrence:将所有的共现entity-pair连接起来,不过不区分连接之间的关系,同一用一种。
NeighbBorrow:对于without-mention entity-pair采用相似度的方式去检索with-mention entity-
pair,返回topk也即论文中的KNN。
详细的效果大家可以去看论文,这里贴一个比较有意思挖掘样本demo
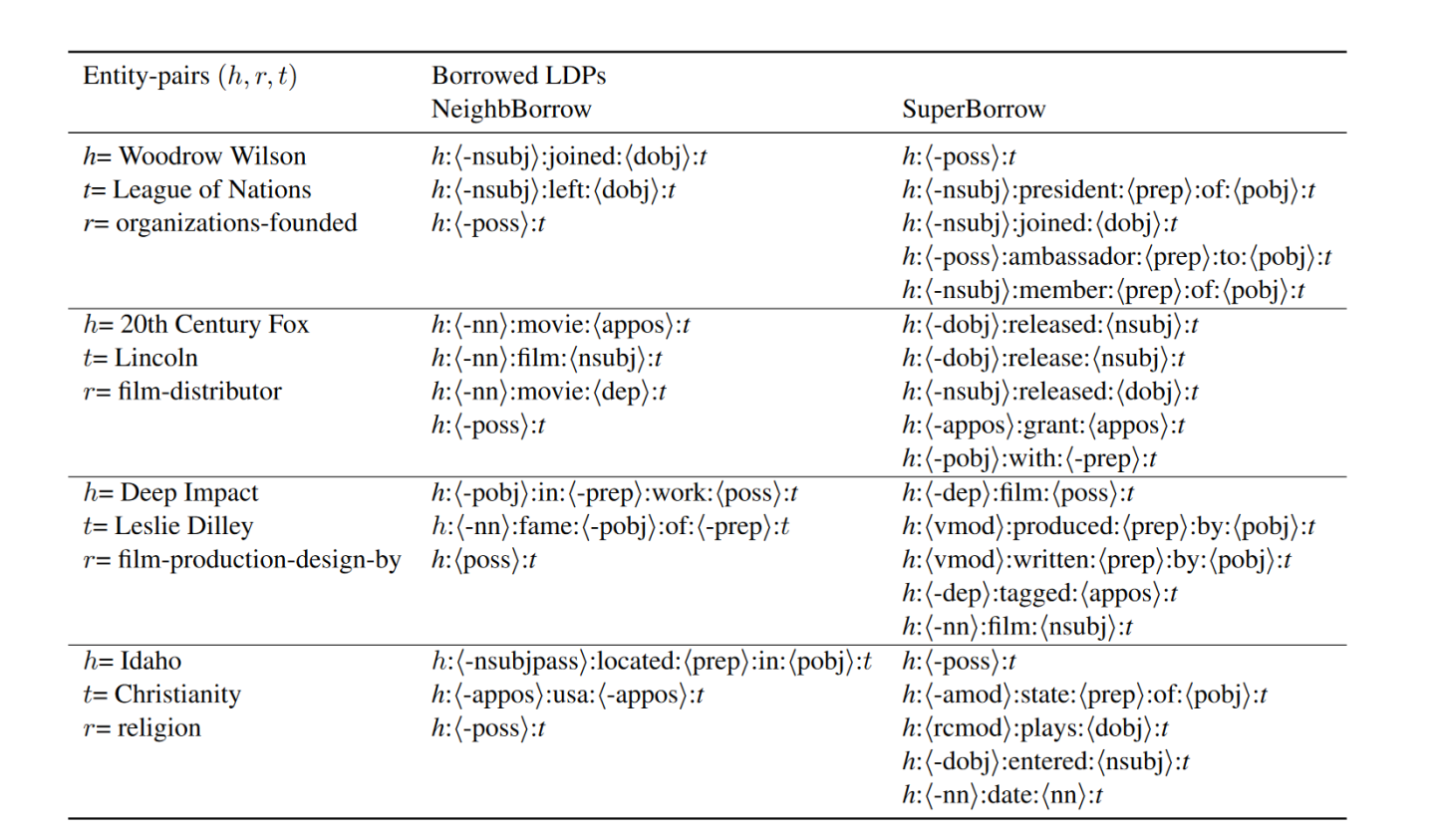
SuperBorrow就是本文的方法,Borrowed LDPs NeighbBorrow就是上文说的NeighbBorrow。
再贴一个利用LDPs的效果图

总结
一个朴素的思想就是:尽可能的利用挖掘完手头有的资源。从知识图谱到语料(共现)+知识图谱再到语料(共现+不共现)+知识图谱,其实可以看到用了越来越多的信息,手头既然有这些数据如果没利用好就是浪费了,作者使用一种idea利用上了不共现的数据,如果我们能够进一步利用好更多的数据理论上来讲就很容易work的,所以大家可以多从这个角度出发去思考,说不定就会有收获。
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:

