
- 1vmware安装android系统_vmware安装安卓平板系统
- 2Node.js 的底层原理
- 3在启动MYSQL时出现问题:“ERROR 2003 (HY000): Can't connect to MySQL server on 'localhost' (10061)”
- 4论文辅助笔记:Tempo之modules/lora.py
- 5Android开发学习笔记二Android Studio_android studio开发读书笔记
- 6山东大学计算机组成原理整机实验_山东建筑大学计算机组成原理实验
- 7【推理框架】超详细!AIGC面试系列 大模型推理系列(1)_分布式推理框架
- 8智能技术_4:贝叶斯分类和贝叶斯网络_贝叶斯网络缺点
- 9深度学习面试总结(上岸版~)
- 10Springboot+Vue项目-基于Java+MySQL的电影院购票系统(附源码+演示视频+LW)
[crash分析2]C语言在ARM64中函数调用时,栈是如何变化的?_arm函数调用中的堆栈变化
赞
踩
[crash分析2]C语言在ARM64中函数调用时,栈是如何变化的?
做系统分析的话你肯定遇到过一些crash, oops等棘手问题,一般大家都会用 gdb, objdump 或者 addr2line等工具分析 pc 位置来定位出错的地方。但是这些分析工具背后的本质原理就不见得理解深刻了,而且有的时候面对一系列 backtrace 或者 stack 日志处于懵逼的状态。
今天和大家一起看下面对 crash 日志的时候,如何利用 stack 来分析其变化的来龙去脉。
1.ARM64体系结构通用寄存器
Arm64 user模式通用寄存器:
有34个寄存器,包括31个通用寄存器、SP、PC、CPSR。
-
x0-x30:64bit 通用寄存器,如果有需要可以用其低32位使用:记作WO-W30。
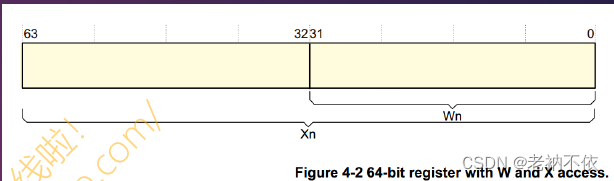
-
FP(x29) :保存栈帧地址(栈底指针)
-
LR(x30) :通常称X30为程序链接寄存器,保存子程序结束后需要执行的下一条指令
-
SP:保存栈指针
-
PC:程序计数器,俗称PC指针,总是指向即将要执行的下一条指令
-
CPSR:状态寄存器
-
64位,8字节为一个字word,32位,4字节位一个字word。
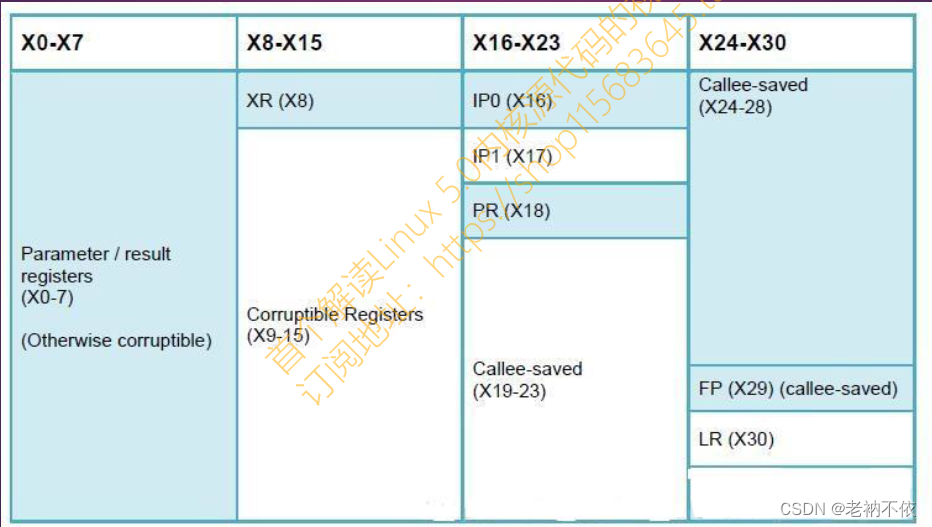
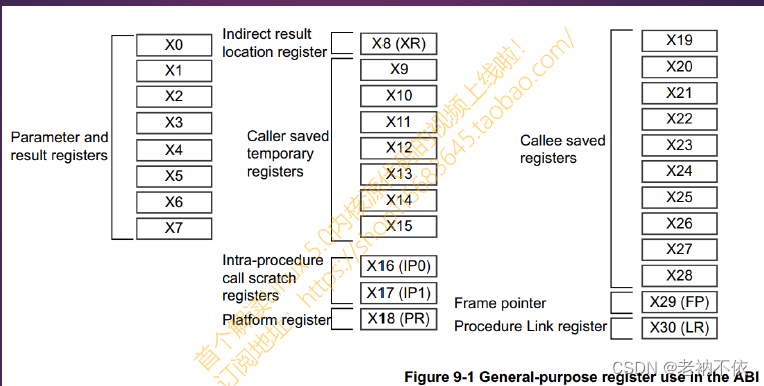
2.ARM64函数参数调用规则
Arm64过程调用标准(AAPCS64) :定义了如何通过寄存器传递函数参数和返回值。
规则:
- x0-x7: 用于传递子程序参数和结果,如用时不需要保存。多于8个以外的参数就需要用栈来传递。
- x0-x1: x0寄存器同时用来传递函数返回结果,64位返回结果用x0,128位返回结果用x1:x0表示。
- x8: 用于保存子程序返回地址,尽量不要使用。
- x9-x15:临时寄存器,使用时不需要保存。
- x16-x17:子程序内部调用寄存器,使用时不需要保存,尽量不要使用。
- x18:平台寄存器,尽量不要使用。
- x19-x28:临时寄存器,使用时必需保存。
- x29: 帧指针寄存器FP,用于连接栈帧,使用时需要保存。
- x30: 连接寄存器LR
- x31: 堆栈寄存器SP
ARM64函数参数调用规则:
3.演示
实验平台:
给大家介绍一个很好用的在线编译平台,可以自由选择编译器和flag,并支持反汇编。链接:https://godbolt.org/
在这里,我选择:
- 编译器:ARM64 gcc trunk
- 编译器flag: -O0
假如现在你已经掌握了 ARM64 指令的用法,即便没有掌握也没关系,“书到用时回头翻”。这里以一段简单的 c 语言为例:
int m=0; int funa(int a, int b) { int ret = 0 ; ret = a+b; return ret; } int funb(int c, int d) { int ret = c+d ; ret = funa(c, ret); return ret; } int main(void) { int i=1,j=2, r; m=6; r = funb(i,j); return r; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
编译一下,然后反汇编。不使用在线平台的可以用:
$ aarch64-linux-gnu-gcc main.c -O0 -o main.out
$ aarch64-linux-gnu-objdump -j .text -ld -C -S main.out
使用在线平台编译直接点击即可,上述代码反汇编如下:
m: .zero 4 funa: sub sp, sp, #32 str w0, [sp, 12] str w1, [sp, 8] str wzr, [sp, 28] ldr w1, [sp, 12] ldr w0, [sp, 8] add w0, w1, w0 str w0, [sp, 28] ldr w0, [sp, 28] add sp, sp, 32 ret funb: stp x29, x30, [sp, -48]! mov x29, sp str w0, [sp, 28] str w1, [sp, 24] ldr w1, [sp, 28] ldr w0, [sp, 24] add w0, w1, w0 str w0, [sp, 44] ldr w1, [sp, 44] ldr w0, [sp, 28] bl funa str w0, [sp, 44] ldr w0, [sp, 44] ldp x29, x30, [sp], 48 ret main: stp x29, x30, [sp, -32]! mov x29, sp mov w0, 1 str w0, [sp, 28] mov w0, 2 str w0, [sp, 24] adrp x0, m add x0, x0, :lo12:m mov w1, 6 str w1, [x0] ldr w1, [sp, 24] ldr w0, [sp, 28] bl funb str w0, [sp, 20] ldr w0, [sp, 20] ldp x29, x30, [sp], 32 ret
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
4.图解栈的变化过程
如何能让读者接受吸收的更快,我一直觉得按照学习效率来讲的话顺序应该是视频,图文,文字。反正我是比较喜欢视频类的教学。这里给大家画下栈变化的过程是什么样子的。这里的图是结合上面的代码来画的,希望有助于读者的理解。
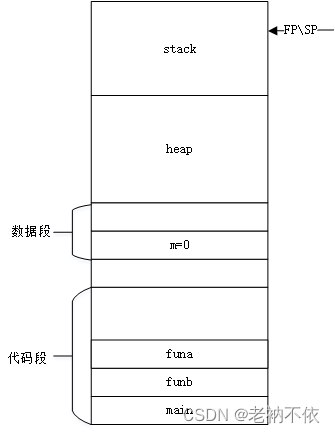
1.程序在内存分布区域
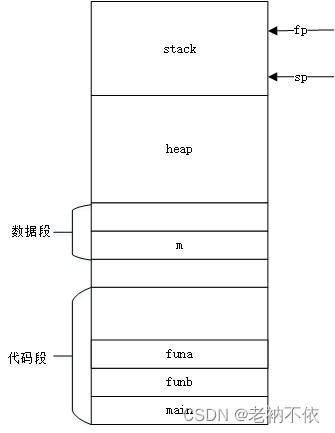
2.全局变量m赋值
程序加载到内存后,全局变量放在data段,已经有初始化的值。
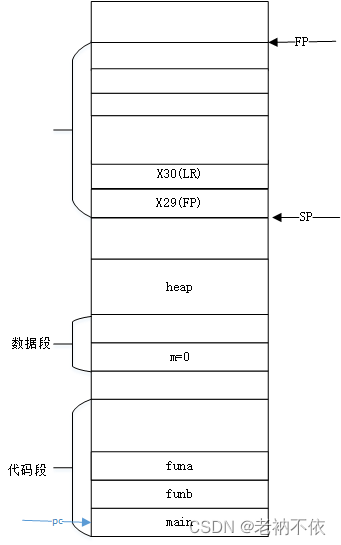
4.1 main函数栈变化过程
1.main函数自己开辟栈空间,同时保存caller的FP和LR
PC跳转到main函数运行时。为当前函数开辟栈空间。由于main函数不是叶子函数,会修改x29(FP)和(LR)寄存器的值,需要将这两个寄存器的值保存到当前栈,以便返回时恢复。
710: a9be7bfd stp x29, x30, [sp, #-32]!
- 1
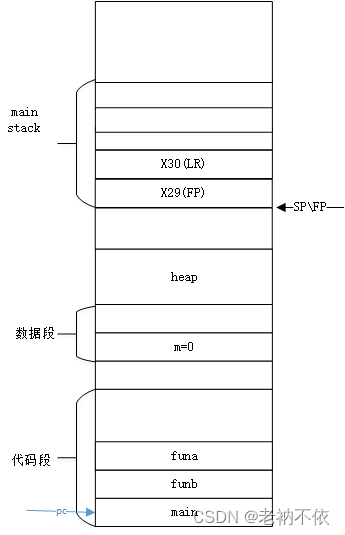
2.更新栈帧寄存器FP
SP寄存器是当前函数栈指针,指向栈顶。
FP寄存器是当前函数栈帧指针,指向栈底。
对当前函数来说,FP=SP。FP指向当前函数的栈帧基地址。每个函数都要执行该动作。
714: 910003fd mov x29, sp
- 1
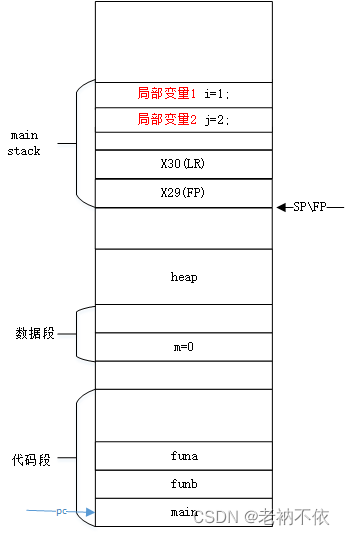
*3.mian函数的局部变量依次入栈保存
将当前函数局部变量,依次从栈底往栈顶顺序(高地址—>低地址)压栈保存。
mov w0, 1
str w0, [sp, 28]
mov w0, 2
str w0, [sp, 24]
- 1
- 2
- 3
- 4
4.函数内部更新全局变量的值
adrp x0, m //获取变量m的页基地址,相对当前pc地址
add x0, x0, :lo12:m //获取变量m的页偏移地址,加上页地址,为相对当前pc的地址
mov w1, 6
str w1, [x0]
- 1
- 2
- 3
- 4
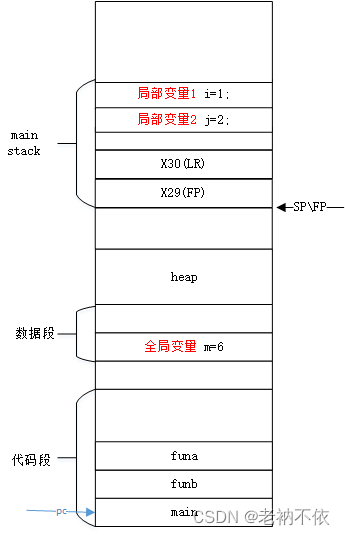
5.为子函数callee准备传参,并跳转到子函数
将局部变量出栈(从栈顶开始,从低地址到高地址),通过w0和w1传递给函数funb.
第二个参数:w1 = j
第一个参数:w0 = i
ldr w1, [sp, 24]
ldr w0, [sp, 28]
bl funb
- 1
- 2
- 3
8.将子函数返回赋值给局部变量
子函数执行完成后返回,将返回结果保存在寄存器w0。
由于子函数返回结果赋值给局部变量r了,因此将寄存器w0的值保存在栈,即给局部变量r赋值。
str w0, [sp, 20] //为局部变量r在栈上分配空间,并赋值
- 1
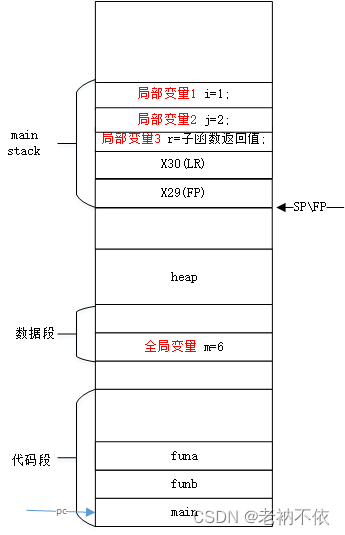
9.main函数准备返回值
main函数将局部变量的值放在寄存器w0,在ret时返回给caller。
str w0, [sp, 20]
ldr w0, [sp, 20]
- 1
- 2
10.main函数释放栈,并从栈上恢复FP和LR寄存器,并返回
当前函数自己分配栈,返回前自己做栈平衡。在释放栈前,将保存在栈上的caller的FP和LR恢复。
ldp x29, x30, [sp], 32
ret
- 1
- 2
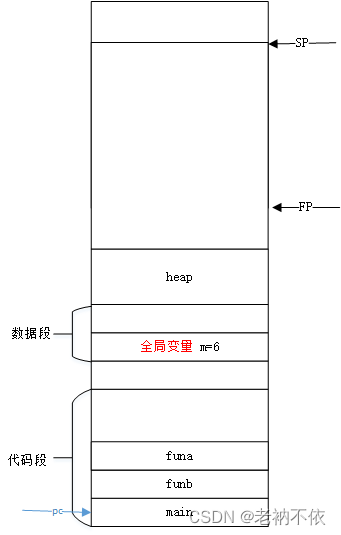
4.2 有calller和callee的子函数funb栈变化
我们分析下,在从main函数跳转到funb函数时,栈的变化情况。从上面4.1可知,当时main给funb传递两个参数w0和w1,并需要funcb返回一个值。
跳转时栈情况:
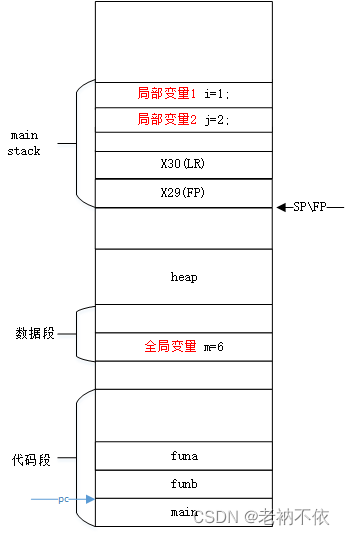
1.函数funb为自己分配栈空间,并保存LR和FP到栈顶
funb函数为自己分配栈空间,在其caller的底部,栈向下生长。
由于函数不是叶子函数,因此还要调用子函数,会修改FP和LR寄存器的值,因此需要将其caller(main函数)的执行现场FP和LR寄存器保存到栈顶。
funb:
stp x29, x30, [sp, -48]!
- 1
- 2

2.函数funb更新栈帧FP寄存器
FP指向自己的栈帧,FP=SP。
mov x29, sp
- 1
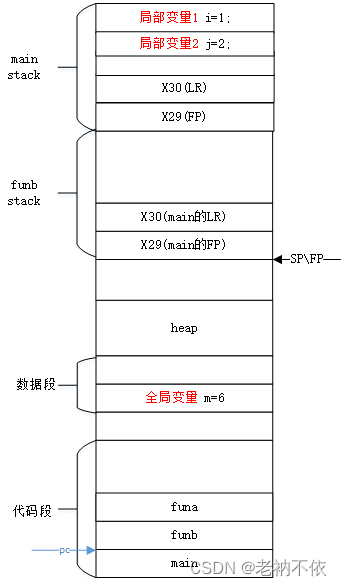
3.funb函数保存寄存器传参的值
从caller传过来的参数保存在寄存器w0和w1, 接下来要用这两个寄存器。因此,先将传参保存到栈上。
- 先保存w0,后保存w1
- 先存在高地址,后存在低地址。压栈按照从高到低顺序(栈底——>栈顶)
str w0, [sp, 28] // 保存传参1
str w1, [sp, 24] // 保存传参2
- 1
- 2
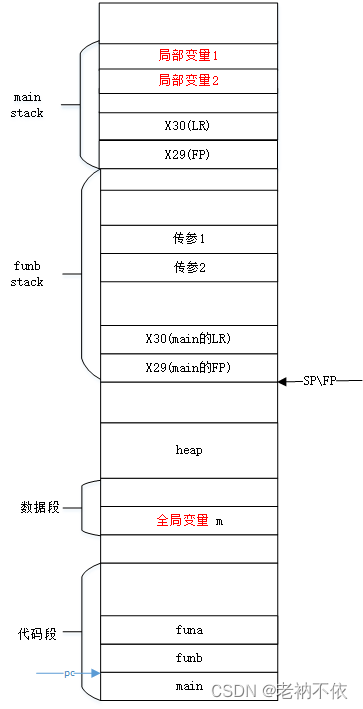
4.funb函数中将运算结果赋值给局部变量
为局部变量ret分配空间,存放计算结果。
ret作为funb函数的第一个局部变量,放在栈底的位置。
ldr w1, [sp, 28]
ldr w0, [sp, 24]
add w0, w1, w0
str w0, [sp, 44]
- 1
- 2
- 3
- 4
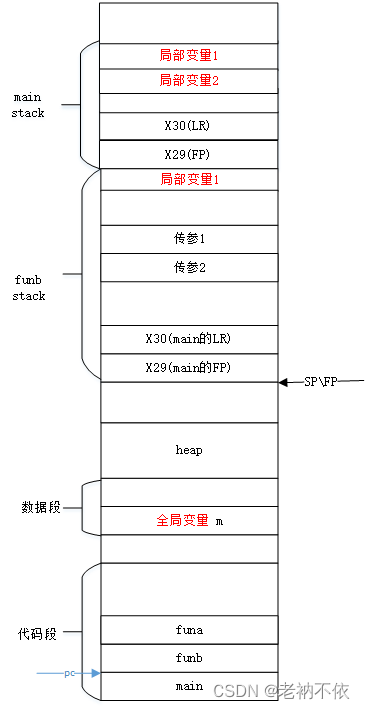
5.funb函数为callee准备传参,并跳转到callee
ldr w1, [sp, 44]
ldr w0, [sp, 28]
bl funa
- 1
- 2
- 3
6.funb函数为处理callee返回结果
子函数funa执行结束后,将结果返回到寄存器w0。
funb函数将返回结果w0保存到局部变量rer。
str w0, [sp, 44]
- 1
7.funb函数准备返回结果
函数在返回前,将返回结果放在w0寄存器。
ldr w0, [sp, 44]
- 1
8.funb函数在返回前,恢复caller的FP和LR,并做栈平衡
ldp x29, x30, [sp], 48
ret
- 1
- 2
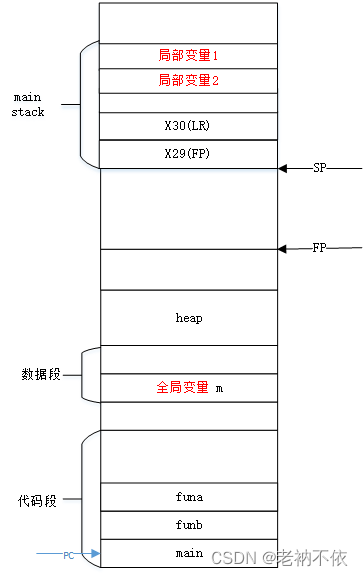
4.3 叶子函数funa的栈变化
由4.2可知,从funb函数跳转到funa时,栈的情况如下:
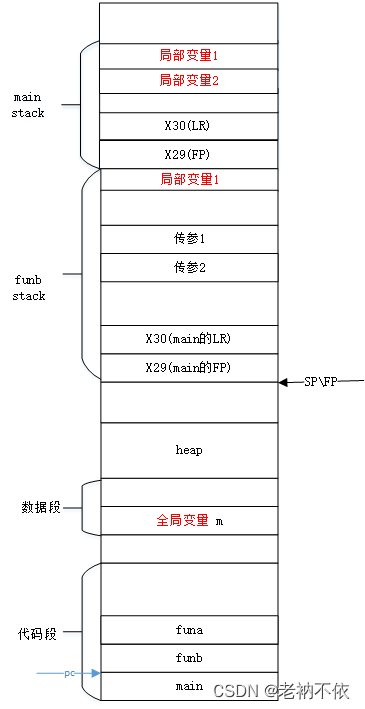
1.funa函数为自己分配栈
由于函数是叶子函数,没有callee。就不会修改FP和LR寄存器的值了,因此无需保存这两个寄存器了。
sub sp, sp, #32
- 1

2.funa函数不需要更新FP栈帧寄存器,FP指向栈底
由于它是叶子函数,用SP已经可以表示栈帧了。FP在这里表示栈底,指向caller的栈帧。
可通过判断FP ≠ SP来判断函数是叶子函数。
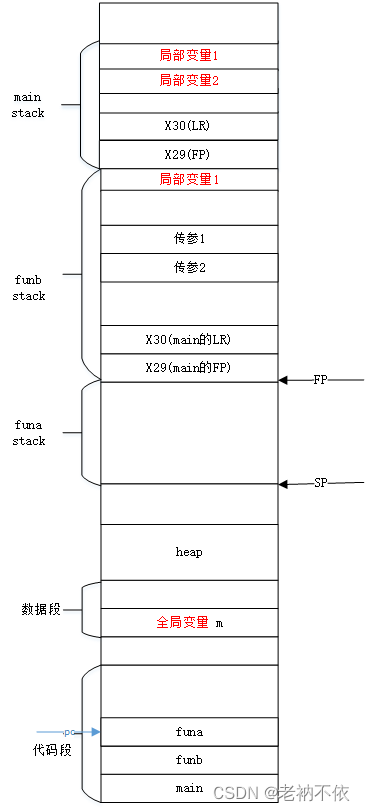
3.funa函数保存形参到栈
- 先保存w0,后保存w1
- 先存在高地址,后存在低地址。压栈按照从高到低顺序(栈底——>栈顶)
str w0, [sp, 12]
str w1, [sp, 8]
- 1
- 2
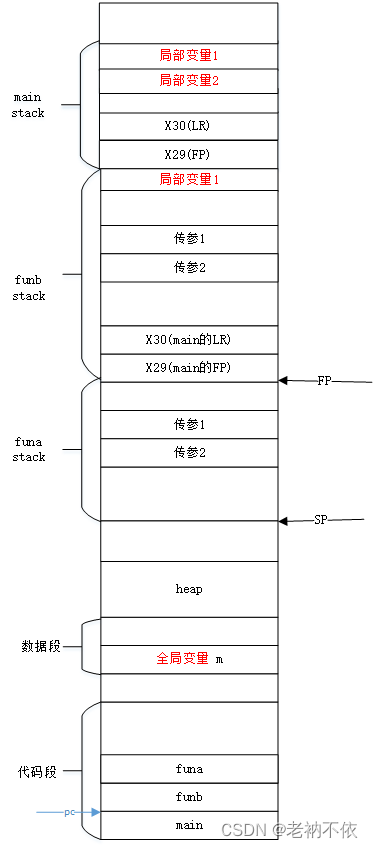
4.funa函数为局部变量分配空间
为局部变量ret 分配空间,并将运算结果赋值给ret。
str wzr, [sp, 28]
ldr w1, [sp, 12]
ldr w0, [sp, 8]
add w0, w1, w0
str w0, [sp, 28]
- 1
- 2
- 3
- 4
- 5
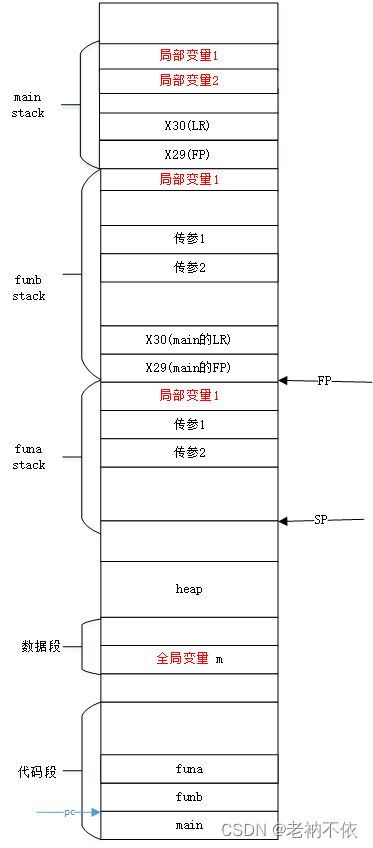
5.funa函数准备返回值到w0,并处理栈平衡
先将返回值放在wo寄存器,再释放自己的栈。
ldr w0, [sp, 28]
add sp, sp, 32
ret
- 1
- 2
- 3
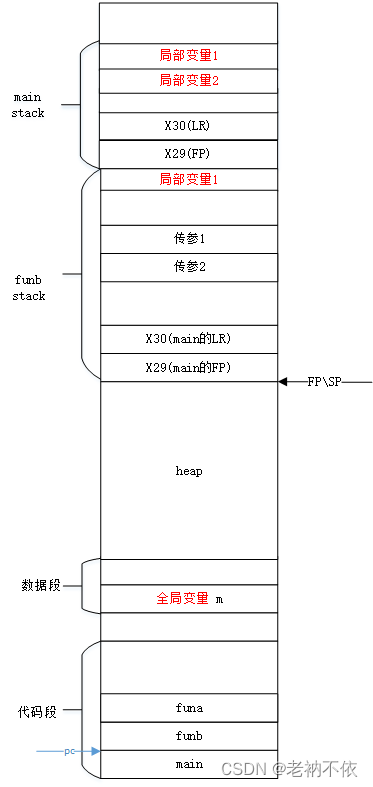
4.4 典型栈结构
一个典型的函数(有caller和callee)的栈帧结构如下:
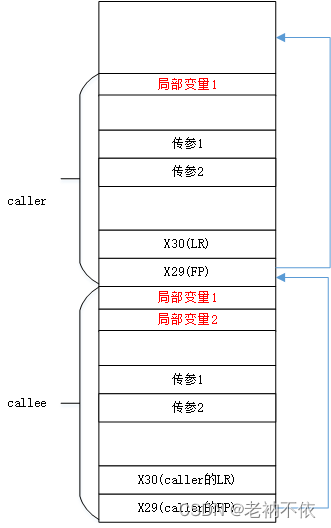
从图可知:
- LR 和FP寄存器保存在栈顶
- 局部变量和参数依次从栈底往栈顶方向保存
4.ARM64典型栈结构
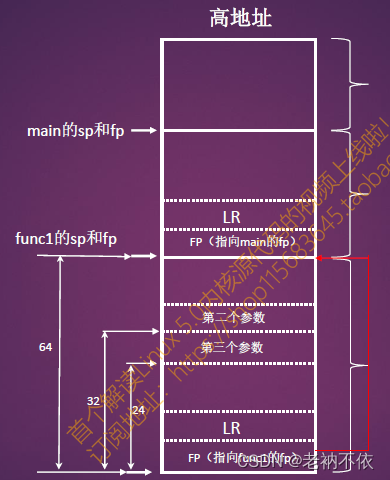
每个函数(假设同时具有caller和callee)的栈结构格式为:
- 栈顶保存的是自己的FP(栈底)
- 栈顶+8 处保存的是LR寄存器的值,也就是自己return后要从哪里开始执行。
- 然后保存的是局部变量的值。
- 然后,保存的是从n,…,3,2,1 ,从低往高,的传参的值。
- 到上一个函数的FP为止,函数的栈结束。
这就是一个完整的栈帧。
每个函数(假设同时具有caller和callee)进入后典型的栈操作:
- 首先会将caller的FP(栈帧地址)保存到栈的顶部(SP+0)。
- 然后,然后将LR寄存器(返回地址)保存在自己的栈(SP+8).
- 函数总会执行FP=SP操作。因此,对arm64来说,当前函数的FP=SP。
每个函数(假设同时具有caller和callee)返回前典型的栈操作:
- 将当前栈中保存的LR赋值给LR寄存器,然后ret。
**重要:**这里有两个很重要寄存器,FP和LR。根据这两个寄存器就可以反推出所有函数的调用栈。
4.1 根据当前函数的FP,推断函数调用栈
核心点在于:FP寄存器,又叫栈帧寄存器。
关键规则:
- 所有函数调用栈都会组成一个链表。
- 每个栈有两个地址来构成这个链表。两个64位宽的地址。
- 低地址(栈顶)存放了指向上一个栈帧的基地址FP,类似链表的prev指针。
- 高地址存放了LR寄存器,当前函数的返回地址。
示例:
已知如下图所示30多个寄存器的值,求解函数调用关系以及调用栈?
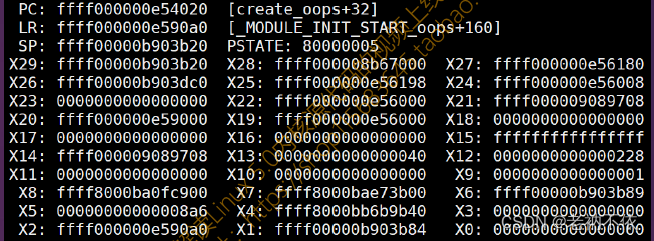
假设函数调用关系为:main() ——> fun1() ——>fun2()
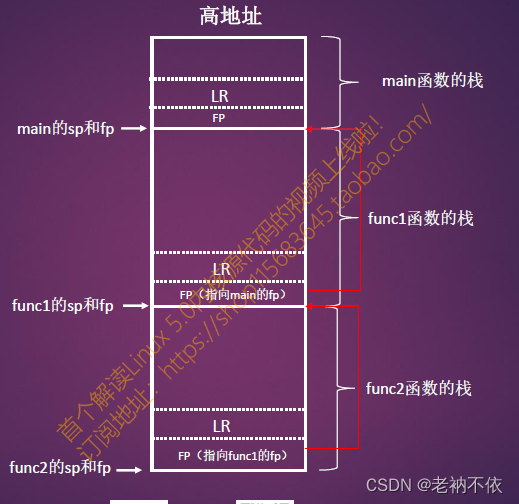
规律:
根据当前栈顶保存的FP值,就知道上一级栈帧基地址。即:上一级FP(栈帧基地址)=*(FP)。
- 首先,根据FP寄存器的值,就知道当前栈帧基地址SP和FP。
- 其次,从当前栈顶位置获取上一级的栈帧指针FP。通过该栈帧指针,即读取该地址的值,就获得了caller的栈帧基地址。
- 这样,层层往上递推就能找到所有caller的栈帧基地址,即确定函数的调用关系。
如示例所示,
1)当前现场寄存器信息:FP=SP=0xFFFF0000B903B20。得知,当前函数fun2的栈帧基地址为0xFFFF0000B903B50。
2) 当前栈帧基地址,即为当前函数的栈顶,存放的是其caller(fun1)的FP(栈帧基地址)。读取栈顶(即地址0xFFFF0000B903B50),返回值为caller(fun1)的栈帧基地址,0xFFFF0000B903BD0.
3.同样,读取fun1的栈顶0xFFFF0000B903BD0,得到其calller(main函数)的栈帧基地址,为0xFFFF0000B90360。
4.以此类推。
4.2 根据本函数栈帧,获取所有caller的函数名,和函数Entry地址
关键点:FP寄存器和LR。
从4.1可知,知道FP寄存器就能得到每个函数的栈帧基地址。而知道每个函数的栈帧基地址的条件下,可通过当前函数栈帧保存的LR获得当前函数的Entry地址和函数名。
**依据:**可通过当前函数栈帧所保存的LR间接获取到calller调用callee时的PC,从而根据符号表得到具体的函数名。在calller(调用者)调用callee(被调函数)时,LR指向被调函数callee的返回的下一条指令,通过LR指向的地址-4字节偏移就得到了跳转时的指令,包括被调用函数callee的入口地址。再通过符号表即可得到此入口函数对应的函数名。
caller 跳转时的pc= *LR - 4 = * (FP +8 ) -4
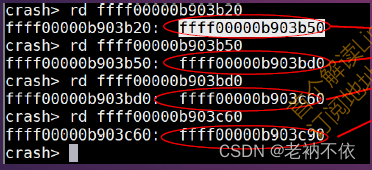
**示例:**假设函数调用关系为:main() ——> fun1() ——>fun2()
现场寄存器:
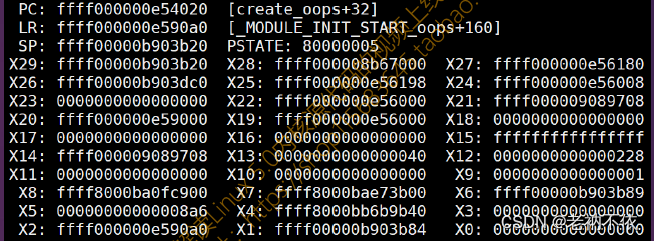
推断:
- 根据FP寄存器得到func2栈帧基地址:读取(FP=0xFFFF0000B903B20),得到fun2栈帧基地址为0xFFFF0000B903B50。
$ rd 0xFFFF0000B903B20
0xFFFF0000B903B20: 0xFFFF0000B903B50
- 1
- 2
2.得到栈帧上保存的LR,0xFFFF0000B903B50 + 8。得到func2返回地址。
$ rd 0xFFFF0000B903B58
0xFFFF0000B903B58: 0xFFFF00000E590A0
- 1
- 2
4.func2返回地址-4 (0xFFFF00000E5909C)就是calller跳转到callee时的pc. 配合符号表, 对该地址进行反汇编,就得到该地址处的跳转指令。跳转指令中就有callee fun2函数的函数名。
$ dis 0xFFFF00000E5909C
0xFFFF00000E5909C <fun1 + 24>: bl 0xFFFF0000B903BCC <fun2>
- 1
- 2
反汇编该地址,返回两列内容
-
第一列:“0xFFFF00000E5909C <fun1 + 24>”。 表示PC地址0xFFFF00000E5909C,指向func1函数入口地址+24个字节偏移地址。因此,通过“<fun1 + 24>”,知道了caller函数名为func1。该地址减去偏移24,就得到了caller函数的入口地址。
-
第二列:“bl 0xFFFF0000B903BCC ”。这一列放的是该PC地址处的指令,calller跳转到callee。这里给出了跳转指令,callee的函数名(func1)和callee的入口地址(0xFFFF0000B903BCC)。


