
- 12020 Java 获取电视台 .m3u8_厦视一套m3u8
- 2python使用tkinter出现"_tkinter.TclError:Can't find a usable tk.tcl in the following directories"__tkinter.tclerror: can't find a usable tk.tcl in t
- 3基于Python+Django的仓库管理系统设计与实现_基于python的仓库管理系统的设计与实现
- 4Git使用命令“git push -u origin master”报错_$ git push -u origin masterunable to negotiate wit
- 5TCP/IP协议—HTTP
- 6Apollo平台计算框架CyberRT
- 7Java面试八股文(2023最新)--Redis面试题_java面试题八股文面试redis
- 8git 历史操作日志_【GIT技巧】清除历史记录中的敏感信息
- 9【Doris】Doris核心功能介绍——数据模型和物化视图_doris主要用途和应用场景
- 10玩转Docker实战篇!使用Docker搭建Nginx静态网站,附加介绍Docker容器数据卷_localglobal.conf
Elasticsearch8.x学习笔记_es 8.x语法
赞
踩
文章目录
ES7.x版本可以参考:Elasticsearch7学习笔记
一、Elasticsearch8.x概述
1、Elasticsearch 新特性
从 2019 年 4 月 10 日 Elasticsearch7.0 版本的发布,到 2022 年 2 月 11 日 Elasticsearch8.0 版本的发布的近 3 年间,基于不断优化的开发设计理念,Elasticsearch 发布了一系列的小版本。这些小版本在以下方面取得了长足的进步并同时引入一些全新的功能:
- 减少内存堆使用,完全支持 ARM 架构,引入全新的方式以使用更少的存储空间,从而让每个节点托管更多的数据
- 降低查询开销,在大规模部署中成效尤为明显
- 提高日期直方图和搜索聚合的速度,增强了页面缓存的性能,并创建了一个新的"pre-filter"搜索短语
- 在 Elasticsearch 7.3 和 Elasticsearch 7.4 版中,引入了对矢量相似函数的支持在最新发布的 8.0 版本中,也同样增加和完善了很多新的功能
- 增加对自然语言处理 (NLP) 模型的原生支持,让矢量搜索功能更容易实现,让客户和员工能够使用他们自己的文字和语言来搜索并收到高度相关的结果
- 直接在 Elasticsearch 中执行命名实体识别、情感分析、文本分类等,而无需使用额外的组件或进行编码
- Elasticsearch 8.0 基于 Lucene 9.0 开发的,那些利用现代 NLP 的搜索体验,都可以借助(新增的)对近似最近邻搜索的原生支持,快速且大规模地实现。通过 ANN,可以快速并高效地将基于矢量的查询与基于矢量的文档语料库(无论是小语料库、大语料库还是巨型语料库)进行比较
- 可以直接在 Elasticsearch 中使用 PyTorch Machine Learning 模型(如 BERT),并在Elasticsearch 中原生使用这些模型执行推理
2、8.x与7.x的对比
- 减少内存堆使用,完全支持 ARM 架构,引入全新的方式以使用更少的存储空间,从而让每个节点托管更多的数据
- Elasticsearch8.x需要jdk17
- 降低查询开销,在大规模部署中成效尤为明显
- 首次启动 Elasticsearch8.x时,会自动进行安全配置
- 在 Elasticsearch 8.0 中做了一些改变来保护系统索引不被直接访问
- 为
keyword、match_only_text和text字段节省存储空间 - 加快
geo_point、geo_shape和范围字段索引速度
二、Elasticsearch 安装与使用
1、Elasticsearch 集群安装
1.1 ES下载与集群规划
Java 的官方地址:https://www.oracle.com/java
ES官网:http://www.elastic.co/cn/
ES下载:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
我们准备三台 linux 虚拟机(基于Centos7),用于配置Elasticsearch 集群,集群中-节点名称依次为 es-node-1,es-node-2,es-node-3,其中ES版本我们选择略早的 8.1.0 版本下载地址(可以直接选择适配JDK版本的)
# 注意以root登录
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.1.0-linux-x86_64.tar.gz
# 将下载好的压缩包上传到服务器中,解压
mkdir -p /usr/soft
tar zxvf elasticsearch-8.1.0-linux-x86_64.tar.gz -C /usr/soft
cd /usr/soft/
mv elasticsearch-8.1.0/ elasticsearch8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
解压后的Elasticsearch 的目录结构如下
| 目录 | 含义 |
|---|---|
| bin | 可执行脚本目录 |
| config | 配置目录 |
| jdk | 内置 JDK 目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
1.2 配置环境
# 新增 es 用户 useradd es # 为 es 用户设置密码 passwd es # 修改文件拥有者 chown -R es:es /usr/soft/elasticsearch8 # 创建数据文件目录 mkdir /usr/soft/elasticsearch8/data # 创建证书目录 mkdir /usr/soft/elasticsearch8/config/certs # ========================================== # 在第一台服务器节点 master 设置集群多节点通信密钥 # 切换用户 su es cd /usr/soft/elasticsearch8 # 签发 ca 证书,过程中需按两次回车键 bin/elasticsearch-certutil ca # 用 ca 证书签发节点证书,过程中需按三次回车键 bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12 # 将生成的证书文件移动到 config/certs 目录中 mv elastic-stack-ca.p12 elastic-certificates.p12 config/certs # ============================================= # 在第一台服务器节点 master 设置集群多节点 HTTP 证书 # 签发 Https 证书 bin/elasticsearch-certutil http # 以下是每次要求输入时,需要输入的内容 n #是否认证 y #是否已有证书 certs/elastic-stack-ca.p12 #证书目录 回车 #输入证书密码(如果没有设置就回车) 5y #证书有效时间5年 n #每个结点都生成证书吗 master #结点的主机名称 slave1 #结点的主机名称 slave2 #结点的主机名称 回车 #退出输入 y #确定 192.168.3.34 #结点的ip 192.168.3.35 #结点的ip 192.168.3.36 #结点的ip 回车 #退出输入 y #确定 n #是否修改证书配置 回车 #输入密码 回车 #生成位置(回车默认) # ==================================== # 解压刚刚生成的 zip 包 unzip elasticsearch-ssl-http.zip # 将解压后的证书文件移动到 config/certs 目录中 mv elasticsearch/http.p12 kibana/elasticsearch-ca.pem config/certs

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
1.3 修改配置文件
config/elasticsearch.yml
# 设置 ES 集群名称 cluster.name: es-cluster # 设置集群中当前节点名称 node.name: master # 设置数据,日志文件路径 path.data: /usr/soft/elasticsearch8/data path.logs: /usr/soft/elasticsearch8/logs # 设置网络访问节点 network.host: master # 设置网络访问端口 http.port: 9200 # 初始节点 discovery.seed_hosts: ["master"] # 安全认证 xpack.security.enabled: true xpack.security.enrollment.enabled: true xpack.security.http.ssl: enabled: true keystore.path: /usr/soft/elasticsearch8/config/certs/http.p12 truststore.path: /usr/soft/elasticsearch8/config/certs/http.p12 xpack.security.transport.ssl: enabled: true verification_mode: certificate keystore.path: /usr/soft/elasticsearch8/config/certs/elastic-certificates.p12 truststore.path: /usr/soft/elasticsearch8/config/certs/elastic-certificates.p12 # 此处需注意,为上面配置的节点名称 cluster.initial_master_nodes: ["master"] http.host: [_local_, _site_] ingest.geoip.downloader.enabled: false xpack.security.http.ssl.client_authentication: none
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
1.4 启动ES
# 再次之前需要扩大文件句柄数,不然会报错 # 由于es文件比较多,需要修改系统配置 # 修改 /etc/security/limits.conf # 在文件末尾中增加下面内容,每个进程可以打开的文件数的限制 es soft nofile 65536 es hard nofile 65536 # 修改 /etc/security/limits.d/20-nproc.conf # 在文件末尾中增加下面内容,每个进程可以打开的文件数的限制 es soft nofile 65536 es hard nofile 65536 # 操作系统级别对每个用户创建的进程数的限制 * hard nproc 4096 # 注: * 地表linux 所有用户名称 # 修改/etc/sysctl.conf # 在文件末尾中增加下面内容 # 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536 vm.max_map_count=655360 # 重新加载 sysctl -p # 最后查看一下,不行就重启一下 # 查看当前用户的软限制 ulimit -n # 查看当前用户的硬限制 ulimit -H -n # 启动 ES 软件 bin/elasticsearch # reset with `bin/elasticsearch-reset-password -u elastic`
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
第一次成功启动后,会显示密码,请记住(保存下来,后面会用到),在访问时需要,因为配置了安全协议,所以使用 https 协议进行访问,但由于证书是自己生成的,并不可靠,所以会有安全提示。访问:https://192.168.3.34:9200/(注意账号密码的保存)
1.5 安装其他结点
操作和上面一样证书直接拷贝config/elasticsearch.yml并修改:node.name、network.host(名字和前面不一样)
# 后台启动服务
bin/elasticsearch -d
- 1
- 2
- 3
最后可以通过elasticsearch-head插件查看集群情况
1.6 问题解决
- Elastic s earch 是使用 java 开发的, 8.1 版本的 ES 需要 JDK 17 及 以上版本。默认安装包中 带有 JDK 环境,如果系统配置** ES_ JAVA_HOME 环境变量,那么会采用系统配置的JDK**。如果没有配置 该环境变量,ES 会 使用自带 捆绑 的 JDK 。虽然自带的 JDK 是 ES软件推荐的 Java 版本,但 一般建议使用系统配置的 JDK
- Windows 环境 中出现下面的错误信息,是因为开启了 SSL 认证:
received p1aintext http traffic an an https charnel,closing cormnection Metty4HftoChannel (Localkadress=/127.0.0.1.9200,解决方法修改
config/elasticsearch.yml文件,将 enabled 的值修改为 falsexpack.security.http.ssl: enabled: false keystore.path: certs/http.p12- 1
- 2
- 3
- 启动成功后,如果访问 localhost:9200 地址后,弹出登录窗口,第一次启动时,因为开启了密码验证模式,在启动窗口中会显示输入账号和密码。如果没有注意到或没有找到账号密码,可以设置免密登录:
xpack.security.enabled: false - 双击启动窗口闪退,通过路径访问追踪错误,如果是"空间不足",请修改
config/jvm.options配置文件-Xms4g -Xmx4g- 1
- 2
- 启动后,如果密码忘记了,怎么办?可以采用指令重置密码,如果只启动单一节点,此操作可能会失败,至少启动2 个节点,测试成功
2、Kibana 安装
2.1 下载
Elasticsearch 下载的版本是 8.1.0,这里我们选择同样的 8.1.0 版,下载地址
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.1.0-linux-x86_64.tar.gz
# 将下载的压缩包上传到服务器,解压缩
tar -zxvf kibana-8.1.0-linux-x86_64.tar.gz -C /usr/soft
- 1
- 2
- 3
- 4
- 5
2.2 配置环境
给 Kibana 生成证书文件
# 在 ES 服务器中生成证书,输入回车即可 cd /usr/soft/elasticsearch8 bin/elasticsearch-certutil csr -name kibana -dns master # 解压文件 unzip csr-bundle.zip # 将解压后的文件移动到 kibana 的 config 目录中 cd kibana/ mv kibana.csr kibana.key /usr/soft/kibana-8.1.0/config/ # 生成 crt 文件 cd /usr/soft/kibana-8.1.0/config openssl x509 -req -in kibana.csr -signkey kibana.key -out kibana.crt # =============================== 创建"kibana_system"用户 cd /usr/soft/elasticsearch8 bin\elasticsearch-reset-password -u kibana_system y # 保存新的密码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.3 修改配置文件
/usr/soft/kibana-8.1.0/config/kibana.yml,注意修改elasticsearch.password的密码
# 服务端口 server.port: 5601 # 服务主机名 server.host: "master" # 国际化 - 中文 i18n.locale: "zh-CN" # ES 服务主机地址 elasticsearch.hosts: ["https://master:9200"] # 访问 ES 服务的账号密码 elasticsearch.username: "kibana_system" elasticsearch.password: "uwFAc4V9vl9WZVeACrYg" elasticsearch.ssl.verificationMode: none elasticsearch.ssl.certificateAuthorities: [ "/usr/soft/elasticsearch8/config/certs/elasticsearch-ca.pem" ] server.ssl.enabled: true server.ssl.certificate: /usr/soft/kibana-8.1.0/config/kibana.crt server.ssl.key: /usr/soft/kibana-8.1.0/config/kibana.key
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
修改软件目录拥有者,如果使用elastic用户会报错
# 切换目录
cd /usr/soft/kibana-8.1.0
chown -R es:es /usr/soft/kibana-8.1.0/
- 1
- 2
- 3
- 4
2.4 启动
# 切换用户
su es
# 启动软件
bin/kibana
# 也可以后台启动
nohup /usr/soft/kibana-8.1.0/bin/kibana >kibana.log 2>&1 &
- 1
- 2
- 3
- 4
- 5
- 6
- 7
访问https://192.168.3.34:5601/(使用elastic用户登录)
三、Elasticsearch 基础功能
下面所有功能都在Kibana的控制台进行演示操作
1、索引操作
# 创建索引 # PUT索引名称(小写) # 如果重复会报错 PUT test_index # ================================ # 可以增加配置 PUT test_index_1 { "aliases": { "test1": {} } } # ES不允许修改索引信息 #=========================== # HEAD索引,http200表示成功,不存在时404 head test_index # ================== # 删除,如果删除一个不存在的索引,那么会返回错误信息 DELETE test_index_1 # =================================== # 查询索引,返回索引详细信息 GET test_index # 查询所有索引 GET _cat/indices
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
| 内容 | 含义 | 具体描述 |
|---|---|---|
| green | health | 当前服务器健康状态: |
| green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) | ||
| open | status | 索引打开、关闭状态 |
| myindex | index | 索引名 |
| Swx2xWHLR6yv23kTrK3sAg | uuid | 索引统一编号 |
| 1 | pri | 主分片数量 |
| 1 | rep | 副本数量 |
| 0 | docs.count | 可用文档数量 |
| 0 | docs.deleted | 文档删除状态(逻辑删除) |
| 450b | store.size | 主分片和副分片整体占空间大小 |
| 225b | pri.store.size | 主分片占空间大小 |
2、文档操作
文档是 ES 软件搜索数据的最小单位, 不依赖预先定义的模式,所以可以将文档类比为表的一行JSON类型的数据。我们知道关系型数据库中,要提前定义字段才能使用,在Elasticsearch 中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
# 创建文档 PUT test_doc # 此处因为没有指定数据唯一性标识,所以无法使用PUT 请求,只能使用POST 请求,且对数据会生成随机的唯一性标识。否则会返回错误信息 PUT test_doc/_doc/1001 { "id":1001, "name":"shawn", "age":18 } # 第二种方法 POST test_doc/_doc { "id":1001, "name":"shawn1", "age":25 } # 如果在创建数据时,指定唯一性标识,那么请求范式 POST,PUT 都可以 # 查询文档 # 根据唯一性标识可以查询对应的文档,如果没有唯一标识,会失败 GET test_doc/_doc/1001 # 查询文档中所有数据 GET test_doc/_search # 修改文档 # 修改文档本质上和新增文档是一样的,如果存在就修改,如果不存在就新增 PUT test_doc/_doc/1001 { "id":10011, "name":"shawn", "age":18 } # POST也可以 POST test_doc/_doc/jYuBboYBpWpNx-SxIIHr { "id":10011, "name":"shawn", "age":18 } # 删除文档 # 删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除) # 不写主键标识会报错 DELETE test_doc/_doc/1002
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
3、搜索
3.1 数据搜索
首先进行数据准备
PUT test_query PUT test_query/_bulk {"index":{"_index":"test_query","_id":"1001"}} {"id":"1001", "name":"zhang san","age":30} {"index":{"_index":"test_query","_id":"1002"}} {"id":"1002", "name":"li si","age":40} {"index":{"_index":"test_query","_id":"1003"}} {"id":"1003", "name":"wang wu","age":50} {"index":{"_index":"test_query","_id":"1004"}} {"id":"1004", "name":"zhangsan","age":30} {"index":{"_index":"test_query","_id":"1005"}} {"id":"1005", "name":"li_si","age":40} {"index":{"_index":"test_query","_id":"1006"}} {"id":"1006", "name":"wang_wu","age":50} # =============================================== # 查询所有 GET test_query/_search GET test_query/_search { "query": { "match_all": {} } } # Match是分词查湖ES会将数据分词(关键词)保存 GET test_query/_search { "query": { "match": { "name": "zhang li" } } } # 完整关键词匹配,发现没有查到 # 因为按分词保存了,并没有完整词语的保存信息 GET test_query/_search { "query": { "term": { "name": { "value": "zhang san" } } } } # 对查询结果进行限制 GET test_query/_search { "_source": ["name","age"], "query": { "match": { "name": "zhang li" } } } # 组合查询 GET test_query/_search { "query": { "bool": { "should": [ { "match": { "name": "zhang li" } }, { "match": { "age": "40" } } ] } } } # 排序查询 GET test_query/_search { "query": { "match": { "name": "zhang li" } }, "sort": [ { "age": { "order": "desc" } } ] } # 分页查询 GET test_query/_search { "query": { "match_all": {} }, "from": 0, "size": 2 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
3.2 聚合搜索
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值、平均值等等
# 分组操作 get test_query/_search { "aggs":{ "ageGroup":{ "terms": { "field": "age" } } }, "size":0 } # 分组和聚合(求和) get test_query/_search { "aggs":{ "ageGroup":{ "terms": { "field": "age" }, "aggs": { "ageSum": { "sum": { "field": "age" } } } } }, "size":0 } # 求年龄平均值 get test_query/_search { "aggs":{ "ageGroup":{ "terms": { "field": "age" }, "aggs": { "aveAge": { "avg": { "field": "age" } } } } }, "size":0 } # 获取前几名topN get test_query/_search { "aggs":{ "top3":{ "top_hits": { "sort": [{ "age": { "order": "desc" } }], "size": 3 } } }, "size":0 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
4、索引模板
# 模板名称小写 PUT _template/mytemplate { "index_patterns" :[ "my*" ], "settings": { "index":{ "number_of_shards":"2" } }, "mappings": { "properties": { "now":{ "type": "date", "format": "yyyy/MM/dd" } } } } # 用法my开头的应用 GET _template/mytemplate PUT my_test_temp GET my_test_temp # 删除 DELETE _template/mytemplate
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
5、中文分词
# 我们在使用 Elasticsearch 官方默认的分词插件时会发现,其对中文的分词效果不佳,经常分词后得效果不是我们想要得
GET _analyze
{
"analyzer": "chinese",
"text": ["我是一个学生"]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
为了能够更好地对中文进行搜索和查询,就需要在Elasticsearch 中集成好的分词器插件, 而 IK 分词器就是用于对中文提供支持得插件,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
注意和ES版本匹配,我们这里选择 8.1.0,在安装目录得plugins 目中,将下载得压缩包直接解压缩得里面即可,最后重启 **Elasticsearch **服务
5.1 使用IK分词器
IK 分词器提供了两个分词算法:
- ik_smart: 最少切分
- Ik_max_word:最细粒度划分
GET _analyze
{
"analyzer": "ik_smart",
"text": ["我是一个三好学生"]
}
- 1
- 2
- 3
- 4
- 5
- 6
5.2 自定义分词效果
我们在使用 IK 分词器时会发现其实有时候分词的效果也并不是我们所期待的,有时一些特殊得术语会被拆开,比如上面得中文“一个学生”希望不要拆开,怎么做呢?其实 IK 插件给我们提供了自定义分词字典,我们就可以添加自己想要保留得字了。
# 首先进入插件config,创建test.cfg,将一句话放进去
# 接下来我们修改配置文件:IKAnalyzer.cfg.xml
# 用户可以在这里配置自己的扩展字典
<entry key="ext_dict">test.dic</>
# 然后重启进行测试
- 1
- 2
- 3
- 4
- 5
- 6
- 7
6、文档得分
6.1 打分机制举例
PUT test_score PUT test_score/_doc/1001 { "text":"zhang san ni hao" } PUT test_score/_doc/1002 { "text":"zhang si" } # 可以发现得分是不一样的,匹配度 GET test_score/_search { "query": { "match": { "text": "zhang" } } } # 详细信息查看 GET test_score/_search?explain=true { "query": { "match": { "text": "zhang" } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
6.2 打分机制详解
Lucene 和ES 的得分机制是一个基于词频和逆文档词频的公式,简称为 TF-IDF 公式(具体可以自行查阅资料)
- TF (词频)
Term Frequency : 搜索文本中的各个词条(term)在查询文本中出现了多少次, 出现次数越多,就越相关,得分会比较高
- IDF(逆文档频率)
Inverse Document Frequency : 搜索文本中的各个词条(term)在整个索引的所有文档中出现了多少次,出现的次数越多,说明越不重要,也就越不相关,得分就比较低
6.3 修改查询顺序
# 可以通过修改权重来获得不同的score GET /testscore/_search?explain=true { "query": { "bool": { "should": [ { "match": { "title": { "query": "Hadoop","boost": 1 } } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
四、Elasticsearch进阶功能
1、Java API 操作
随着Elasticsearch 8.x 新版本的到来, Type 的概念被废除,为了适应这种数据结构的改变, Elasticsearch 官方从 7.15 版本开始建议使用新的 Elasticsearch Java Client
1.1 增加依赖关系
首先导入依赖
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <elastic.version>8.1.0</elastic.version> </properties> <dependencies> <dependency> <groupId>org.elasticsearch.plugin</groupId> <artifactId>x-pack-sql-jdbc</artifactId> <version>8.1.0</version> </dependency> <dependency> <groupId>co.elastic.clients</groupId> <artifactId>elasticsearch-java</artifactId> <version>${elastic.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.12.3</version> </dependency> <dependency> <groupId>jakarta.json</groupId> <artifactId>jakarta.json-api</artifactId> <version>2.0.1</version> </dependency> </dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
1.2 获取客户端对象
就像连接MySQL 数据库一样, Java 通过客户端操作 Elasticsearch 也要获取到连接后才可以。咱们现在使用的基于 https 安全的 Elasticsearch 服务,所以首先我们需要将之前的证书进行一个转换
cd /usr/soft/elasticsearch8/config/certs/
ls
# 生成证书
openssl pkcs12 -in elastic-stack-ca.p12 -clcerts -nokeys -out java-ca.crt
- 1
- 2
- 3
- 4
- 5
在根目录创建certs文件夹,将证书放入certs中,配置证书后,我们就可以采用https 方式获取连接对象了。java创建类,如果启动不报错即成功
public class EsClient { public static void main(String[] args) throws Exception { initEsConnection(); } private static void initEsConnection() throws Exception { // 获取客户端对象 final CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); // 注意这里改成自己的账号密码 credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("elastic", "XV=4ZU5OzQEk46Z1T_Zl")); Path caCertificatePath = Paths.get("es/certs/java-ca.crt"); CertificateFactory factory = CertificateFactory.getInstance("X.509"); Certificate trustedCa; try (InputStream is = Files.newInputStream(caCertificatePath)) { trustedCa = factory.generateCertificate(is); } KeyStore trustStore = KeyStore.getInstance("pkcs12"); trustStore.load(null, null); trustStore.setCertificateEntry("ca", trustedCa); SSLContextBuilder sslContextBuilder = SSLContexts.custom() .loadTrustMaterial(trustStore, null); final SSLContext sslContext = sslContextBuilder.build(); // 主机名改成自己的 RestClientBuilder builder = RestClient.builder( new HttpHost("master", 9200, "https")) .setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() { @Override public HttpAsyncClientBuilder customizeHttpClient( HttpAsyncClientBuilder httpClientBuilder) { return httpClientBuilder.setSSLContext(sslContext) .setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE) .setDefaultCredentialsProvider(credentialsProvider); } }); RestClient restClient = builder.build(); ElasticsearchTransport transport = new RestClientTransport( restClient, new JacksonJsonpMapper()); // 同步客户端对象 ElasticsearchClient client = new ElasticsearchClient(transport); // 异步 // ElasticsearchAsyncClient asyncClient = new ElasticsearchAsyncClient(transport); transport.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
如果是spring,也可以使用http
@Configuration
public class ElasticSearchConfig {
//注入IOC容器
@Bean
public ElasticsearchClient elasticsearchClient(){
RestClient client = RestClient.builder(new HttpHost("localhost", 9200,"http")).build();
ElasticsearchTransport transport = new RestClientTransport(client,new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.3 索引操作
public class EsClient { private static ElasticsearchClient client; private static ElasticsearchAsyncClient asyncClient; private static ElasticsearchTransport transport; public static void main(String[] args) throws Exception { initEsConnection(); operationIndex(); transport.close(); } private static void operationIndex() throws Exception{ // 创建索引 // 使用构建器模式创建,ESAPI都是这样 CreateIndexRequest request = new CreateIndexRequest.Builder().index("myindex").build(); final CreateIndexResponse createIndexResponse = client.indices().create(request); System.out.println(" 创建索引成功: :" + createIndexResponse.index()); // 查询索引 GetIndexRequest getIndexRequest = new GetIndexRequest.Builder().index("myindex").build(); final GetIndexResponse getIndexResponse = client.indices().get(getIndexRequest); System.out.println( "索引查询成功: :" + getIndexResponse.result()); // 删除索引 DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest.Builder().index("myindex").build(); final DeleteIndexResponse delete = client.indices().delete(deleteIndexRequest); final boolean acknowledged = delete.acknowledged(); System.out.println(" 删除索引成功: :" + acknowledged); } private static void initEsConnection() throws Exception { // 获取客户端对象 final CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("elastic", "XV=4ZU5OzQEk46Z1T_Zl")); Path caCertificatePath = Paths.get("es/certs/java-ca.crt"); CertificateFactory factory = CertificateFactory.getInstance("X.509"); Certificate trustedCa; try (InputStream is = Files.newInputStream(caCertificatePath)) { trustedCa = factory.generateCertificate(is); } KeyStore trustStore = KeyStore.getInstance("pkcs12"); trustStore.load(null, null); trustStore.setCertificateEntry("ca", trustedCa); SSLContextBuilder sslContextBuilder = SSLContexts.custom() .loadTrustMaterial(trustStore, null); final SSLContext sslContext = sslContextBuilder.build(); RestClientBuilder builder = RestClient.builder( new HttpHost("master", 9200, "https")) .setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() { @Override public HttpAsyncClientBuilder customizeHttpClient( HttpAsyncClientBuilder httpClientBuilder) { return httpClientBuilder.setSSLContext(sslContext) .setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE) .setDefaultCredentialsProvider(credentialsProvider); } }); RestClient restClient = builder.build(); transport = new RestClientTransport( restClient, new JacksonJsonpMapper()); // 同步客户端对象 client = new ElasticsearchClient(transport); // 异步 asyncClient = new ElasticsearchAsyncClient(transport); } // Lambda操作函数如下 private static void operationIndexLambda() throws Exception{ // 创建索引 final Boolean acknowledged = client.indices().create(p -> p.index("myindex1")).acknowledged(); System.out.println("创建索引成功"); // 获取索引 System.out.println(client.indices().get(req -> req.index("myindex1"))); // 删除索引 client.indices().delete(reqbuilder -> reqbuilder.index("myindex1")).acknowledged(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
1.4 文档操作
Users自行创建
private static void operationDocument() throws Exception{ Users user = new Users("shawn", 18); // 创建文档 IndexRequest indexRequest = new IndexRequest.Builder<Users>() .index("myindex").id("1001").document(user).build(); final IndexResponse index = client.index(indexRequest); System.out.println(" 文档操作结果 :" + index); // 批量创建文档 final List<BulkOperation> operations = new ArrayList<>(); for ( int i= 1;i <= 5; i++ ) { CreateOperation<Users> otObj = new CreateOperation.Builder<Users>() .index("myindex") .id("200" + i) .document(new Users("shawn" + i, 18 + i)) .build(); final BulkOperation bulk = new BulkOperation.Builder().create(otObj).build(); operations.add(bulk); } BulkRequest bulkRequest = new BulkRequest.Builder().operations(operations).build(); final BulkResponse bulkResponse = client.bulk(bulkRequest); System.out.println(" 数据操作成功: :"+ bulkResponse); // 删除文档 DeleteRequest deleteRequest = new DeleteRequest.Builder().index("myindex").id("1001").build(); client.delete(deleteRequest); } private static void operationDocumentLambda() throws Exception{ Users user = new Users("shawn", 18); List<Users> userList = new ArrayList<>(); userList.add(user); // 创建文档 System.out.println( client.index(req-> req.index("myindex") .id("1001") .document(user)).result()); // 批量创建文档 client.bulk(req ->{ userList.forEach( u -> { req.operations( b -> { b.create(d -> d.id(u.getAge() + "200") .index("myindex") .document(u)); return b; } ); } ); return req; }); // 删除文档 client.delete(req -> req.index("myindex").id("1001")); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
1.5 文档查询
private static void operationSearch() throws Exception { final SearchRequest.Builder searchRequestBuilder = new SearchRequest.Builder().index("myindex1"); MatchQuery matchQuery = new MatchQuery.Builder().field("city").query(FieldValue.of("beijing")).build(); Query query = new Query.Builder().match(matchQuery).build(); searchRequestBuilder.query(query); SearchRequest searchRequest = searchRequestBuilder.build(); final SearchResponse<Object> search = client.search(searchRequest, Object.class); System.out.println(search); } private static void operationSearchLambda() throws Exception { client.search( req -> { req.query( q -> q.match( m -> m.field("city").query("beijing") )); return req; },Object.class); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
1.6 客户端异步操作
ES Java API 提供了同步和异步的两种客户端处理。之前演示的都是同步处理,异步客
户端的处理和同步客户端处理的 API 基本原理相同,不同的是需要异步对返回结果进行相应的处理。
private static void operationAsync() throws Exception { // 创建索引 asyncClient.indices().create( req -> req.index("newindex") ).thenApply( CreateIndexResponse::acknowledged ).whenComplete( (resp, error) -> { System.out.println("回调函数"); if (!resp) { System.out.println(); } else { error.printStackTrace(); } }); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2、EQL操作
EQL 的全名是 Event Query Language (EQL)。事件查询语言(EQL)是一种用于基于事件的时间序列数据(例如日志,指标和跟踪)的查询语言。在 Elastic Security 平台上,当输入有效的 EQL 时,查询会在数据节点上编译,执行查询并返回结果。这一切都快速、并行地发生,让用户立即看到结果。
EQL 的优点:
- EQL 使你可以表达事件之间的关系,许多查询语言允许您匹配单个事件。EQL 使你可以匹配不同事件类别和时间跨度的一系列事件
- EQL 的学习曲线很低。EQL 语法看起来像其他常见查询语言,例如 SQL。 EQL 使你可以直观地编写和读取查询,从而可以进行快速,迭代的搜索
- EQL 设计用于安全用例。尽管你可以将其用于任何基于事件的数据,但我们创建了 EQL 来进行威胁搜寻。 EQL不仅支持危害指标(IOC)搜索,而且可以描述超出IOC 范围的活动。
2.1 基础语法
要运行 EQL 搜索,搜索到的数据流或索引必须包含时间戳和事件类别字段。 默认情况下,EQL 使用Elastic 通用模式(ECS)中的 @timestamp 和 event.category 字段。@timestamp 表示时间戳,event.category 表示事件分类。咱们准备一些简单的数据,用于表示电商网站页面跳转
# 批量增加数据 PUT /gmall PUT _bulk {"index":{"_index":"gmall"}} {"@timestamp":"2022-06-01T12:00:00.00+08:00","event":{"category":"page"},"page":{"session_id":"42FC7E13-CB3E-5C05-0000-0010A0125101","last_page_id":"","page_id":"login","user_id":""}} {"index":{"_index":"gmall"}} {"@timestamp":"2022-06-01T12:01:00.00+08:00","event":{"category":"page"},"page":{"session_id":"42FC7E13-CB3E-5C05-0000-0010A0125101","last_page_id":"login","page_id":"good_list","user_id":"1"}} {"index":{"_index":"gmall"}} {"@timestamp":"2022-06-01T12:05:00.00+08:00","event":{"category":"page"},"page":{"session_id":"42FC7E13-CB3E-5C05-0000-0010A0125101","last_page_id":"good_list","page_id":"good_detail","user_id":"1"}} GET gmall/_search # 数据窗口搜索 # 在事件响应过程中,有很多时候,了解特定时间发生的所有事件是很有用的。使用一种名为any 的特殊事件类型,针对所有事件进行匹配,如果想要匹配特定事件,就需要指明事件分类名称 GET /gmall/_eql/search { "query":""" any where page.user_id == "1" """ } # 统计符合条件的事件 GET /gmall/_eql/search {"query":"\n any where true\n ","filter":{"range":{"@timestamp":{"gte":"1654056000000","lt":"1654056005000"}}}} # 事件序列 GET /gmall/_eql/search { "query": """ sequence by page.session_id [page where page.page_id=="login"] [page where page.page_id=="good_detail"] """ }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
2.2 安全检测
EQL在 Elastic Securit 中被广泛使用。 实际应用时,我们可以使用 EQL 语言来进行检测安全威胁和其他可疑行为
例如regsvr32.exe 是一个内置的命令行实用程序,用于在 Windows 中注册.dll 库。作为本机工具,regsvr32.exe 具有受信任的状态,从而使它可以绕过大多数允许列表软件和脚本阻止程序。 有权访问用户命令行的攻击者可以使用 regsvr32.exe 通过.dll 库运行恶意脚本,即使在其他情况下也不允许这些脚本运行。regsvr32 滥用的一种常见变体是 Squfullydoo 攻击。在 Squfullydoo 攻击中,regsvr32.exe 命令使用 scrobj.dll 库注册并运行远程脚本。可以通过ES查找恶意攻击
3、SQL操作
3.1 概述
一般使用Elasticsearch 的时候,会使用 Query DSL 来查询数据,从 Elasticsearch6.3 版本以后,Elasticsearch 已经支持 SQL 查询了。Elasticsearch SQL 是一个X-Pack 组件,它允许针对Elasticsearch 实时执行类似 SQL 的查询。无论使用 REST 接口,命令行还是 JDBC,任何客户端都可以使用 SQL 对Elasticsearch 中的数据进行原生搜索和聚合数据。可以将 Elasticsearch SQL 看作是一种翻译器,它可以将SQL 翻译成Query DSL。Elasticsearch SQL 具有如下特性:
- 原生支持:Elasticsearch SQL 是专门为 Elasticsearch 打造的。
- 没有额外的零件:无需其他硬件,处理器,运行环境或依赖库即可查询 Elasticsearch, Elasticsearch SQL 直接在 Elasticsearch 内部运行。
- 轻巧高效:Elasticsearch SQL 并未抽象化其搜索功能,相反的它拥抱并接受了 SQL 来实现全文搜索,以简洁的方式实时运行全文搜索。
3.2 SQL和Elasticsearch对应关系
| SQL | Elasticsearch | 描述 |
|---|---|---|
| Column | field | 对比两个,数据都存储在命名条目中,具有多种数据类型,包含一个值。SQL 将此类条目称为列,而 Elasticsearch 称为字段。请注意, 在 Elasticsearch 中,一个字段可以包含多个相同类型的值(本质上是一个列表),而在 SQL 中,一个列可以只包含一个所述类型的值。Elasticsearch SQL 将尽最大努力保留 SQL 语义,并根据查询拒绝那些返回具有多个值的字段的查询 |
| Row | document | Columns 和fields 本身不存在;它们是 row 或 a 的一部分document。两者的语义略有不同:row 趋于严格(并且有更多的强制执行),而document 趋于更加灵活或松散(同时仍然具有结构) |
| Table | Index | 执行查询的目标 |
| Schema | Mapping | 在RDBMS 中, schem 主要是表的命名空间,通常用作安全边界。Elasticsearch 没有为它提供等效的概念。但是,当启用安全性时,Elasticsearch 会自动应用安全性强制,以便角色只能看到它被允许访问的数据 |
| Database | Cluster实例 | 在SQL 中, catalog 或者 database 从概念上可以互换使用,表示一组模式,即多个表。在 Elasticsearch 中,可用的索引集被分组在一个cluster ,语义也有所不同。 database 本质上是另一个命名空间(可能对数据的存储方式有一些影响),而 Elasticsearch cluster 是一个运行时实例,或者更确切地说是一组至少一个 Elasticsearch 实例(通常是分布式行)。在实践中,这意味着虽然在 SQL 中,一个实例中可能有多个目录,但在 Elasticsearch 中,一个目录仅限于一个 |
3.3 数据准备与条件查询
PUT my-sql-index/_bulk?refresh {"index":{"_id":"JAVA"}} {"name":"JAVA","author":"zhangsan","release_date":"2022-05-01","page_count":561} {"index":{"_id":"BIGDATA"}} {"name":"BIGDATA","author":"lisi","release_date":"2022-05-02","page_count":482} {"index":{"_id":"SCALA"}} {"name":"SCALA","author":"wangwu","release_date":"2022-05-03","page_count":604} # 第一个数据查询 # SQL # 这里的表就是索引 #可以通过 format 参数控制返回结果的格式,默认为 json格式 # txt:表示文本格式,看起来更直观点. # csv:使用逗号隔开的数据 # json:JSON 格式数据 # tsv: 使用 tab 键隔开数据 # yaml:属性配置格式 POST _sql?format=txt { "query": """ SELECT * FROM "my-sql-index" """ } POST _sql?format=txt { "query": """ SELECT * FROM "my-sql-index" where page_count > 500 """ }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
3.4 SQL与DSL混合查询
当我们需要使用Query DSL 时,也可以先使用SQL 来查询,然后通过Translate API 转换即可,查询的结果为DSL 方式的结果,转换 SQL 为 DSL 进行操作
# 转换 POST _sql/translate { "query": """ SELECT * FROM "my-sql-index" where page_count > 500 """ } # 混合使用 POST _sql?format=txt { "query": """ SELECT * FROM "my-sql-index" where page_count > 500 """, "filter": { "range": { "page_count": { "gte": 400, "lte": 600 } } }, "fetch_size": 2 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3.5 常用SQl操作
# 查询所有索引 GET _sql?format=txt { "query": """ show tables """ } # 查询指定索引 GET _sql?format=txt { "query": """ show tables like 'myindex' """ } # 模糊查询索引 GET _sql?format=txt { "query": """ show tables like 'my-%' """ } # 查看索引结构 GET _sql?format=txt { "query": """ describe myindex """ }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
基础查询操作
SELECT select_expr [, …] [ FROM table_name ] [ WHERE condition ] [ GROUP BY grouping_element [, …] ] [ HAVING condition] [ ORDER BY expression [ ASC | DESC ] [, …] ] [ LIMIT [ count ] ] [ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, …] ) ) ] # 条件过滤 POST _sql?format=txt { "query": """ SELECT * FROM "my-sql-index" where name = 'JAVA' """ } #查询所有数据 GET _sql?format=txt { "query": """ SELECT * FROM "my-sql-index" """ } #按照日期进行分组 GET _sql?format=txt { "query": """ SELECT release_date FROM "my-sql-index" group by release_date """ } # 对分组后的数据进行过滤 GET _sql?format=txt { "query": """ SELECT sum(page_count), release_date as datacnt FROM "my-sql-index" group by release_date having sum(page_count) > 100 """ } # 对页面数量进行排序(降序) GET _sql?format=txt { "query": """ select * from "my-sql-index" order by page_count desc """ } #限定查询数量 GET _sql?format=txt { "query": """ select * from "my-sql-index" limit 3 """ } # ================================= # 游标(cursor)是系统为用户开设的一个数据缓冲区,存储 sql 语句的执行结果,每个游标区都有一个名字,用户可以用 sql 语句逐一从游标中获取记录,并赋给主变量,交由主语言进一步处理。 # 就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条或多条记录的机制 POST _sql?format=json { "query": """ SELECT * FROM "my-sql-index" order by page_count desc """, "fetch_size": 2 } # 返回结果中的cursor 就是缓冲区的标识,这就意味着可以从缓冲区中直接获取后续数据,操作上有点类似于迭代器,可多次执行。 # 此处游标 cursor 值需要根据读者执行的操作进行修改,请勿直接使用 # 如果执行后,无任何结果返回,说明数据已经读取完毕,此时再次执行,会返回错误信息 POST /_sql?format=json { "cursor": "8/LoA0RGTACMjMFKwzAchxesIkPwEXyGVHfoYYfNkYyBBSNJ1lxGuvzbbk2Tsaas+ny+17R4EC/D7/b78fEhhdpPRKjtsrjHiooii5POUPFkSIKNtPXCEazWq4mglc1rZQ1N/axSB9iLlmNGOWEq55NXJs27kCLkmM1nP8zXz1v5hk0m62SZLhTnxHyIZvUiZR+zx9Sb/r+d8nLnNJ2ev7m/RsWN7kLljygK0IfRCBWR0w38zivnT+jW6ABh18AgjA+6hM3Wdy6gyHpXDufdESzoFjaD+cd/+AIAAP//AwA=" } # 如果关闭缓冲区,执行下面指令即可 POST /_sql/close { "cursor": "8/LoA0RGTACMjMFKwzAchxesIkPwEXyGVHfoYYfNkYyBBSNJ1lxGuvzbbk2Tsaas+ny+17R4EC/D7/b78fEhhdpPRKjtsrjHiooii5POUPFkSIKNtPXCEazWq4mglc1rZQ1N/axSB9iLlmNGOWEq55NXJs27kCLkmM1nP8zXz1v5hk0m62SZLhTnxHyIZvUiZR+zx9Sb/r+d8nLnNJ2ev7m/RsWN7kLljygK0IfRCBWR0w38zivnT+jW6ABh18AgjA+6hM3Wdy6gyHpXDufdESzoFjaD+cd/+AIAAP//AwA=" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
3.6 基础聚合操作
常用的函数可以参考:MySQL8.0基础篇
# 这里讲几个特别的 # 如果需要匹配通配符本身 使用转义字符 SELECT * FROM "my-sql-index" WHERE name like 'JAVA/%' ESCAPE '/' # RLIKE 不要误会,这里的 R 表示的不是方向,而是正则表示式 Regex SELECT * FROM "my-sql-index" WHERE name like 'JAV*A' SELECT * FROM "my-sql-index" WHERE name rlike 'JAV*A' # 尽管 LIKE 在 Elasticsearch SQL 中搜索或过滤时是一个有效的选项,但全文搜索 MATCH 和 QUERY速度更快、功能更强大,并且是首选替代方案。 # MATCH MATCH( 匹配字段,规则 , 配置参数 可选)) SELECT * FROM "my-sql-index" where MATCH (name, 'JAVA') SELECT * FROM "my-sql-index" where MATCH (name, 'JAVA') # MATCH MATCH((' 匹配字段 权重 1, 匹配字段 权重 2'2',规则 , 配置参数 可选 SELECT * FROM "my-sql-index" where MATCH('author^2,name^5', 'java') # QUERY SELECT * FROM "my-sql-index" where QUERY('name:Java') # SCORE : 评分 SELECT *, score () FROM "my-sql-index" where QUERY('name:Java') # 条件分支函数 # 多重分支判断 SELECT CASE 5 WHEN 1 THEN 'elastic' WHEN 2 THEN 'search' WHEN 3 THEN 'elasticsearch' ELSE 'default' END AS "case" # ES 集 群 SELECT DATABASE() # 用户 SELECT USER()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3.7 SQL 客户端 DataGrip
DataGrip是 JetBrains 发布的多引擎数据库环境,可以在IDEA连接,不过要收费(试用30天),连接es driver,配置好ssl等即可
4、自然语言处理 NLP
随着 8.0 的发布,Elastic 很高兴能够将 PyTorch 机器学习模型上传到 Elasticsearch 中, 以在 Elastic Stack 中提供现代自然语言处理 (NLP)。现在,Elasticsearch 用户能够集成用于构建NLP 模型的最流行的格式之一,并将这些模型作为 NLP 数据管道的一部分通过我们的Inference processor 整合到Elasticsearch 中
4.1 简介
- 情绪分析:用于识别正面与负面陈述的二元分类
- 命名实体识别 (NER):从非结构化文本构建结构,尝试提取名称、位置或组织等细节
- 文本分类:零样本分类允许你根据你选择的类对文本进行分类,而无需进行预训练。
- 文本嵌入:用于 k 近邻 (kNN) 搜索
4.2 Elasticsearch 中的自然语言处理
通过与在 PyTorch 模型中构建 NLP 模型的最流行的格式之一集成,Elasticsearch 可以提供一个平台,该平台可处理大量 NLP 任务和用例。许多优秀的库可用于训练 NLP 模型,因此我们暂时将其留给其他工具。无论你是使用 PyTorch NLP、Hugging Face Transformers 还是 Facebook 的 fairseq 等库来训练模型,你都可以将模型导入 Elasticsearch 并对这些模型进行推理。 Elasticsearch 推理最初将仅在摄取时进行,未来还可以扩展以在查询时引入推理。
Elasticsearch 一直是进行NLP 的好地方,但从历史上看,它需要在Elasticsearch 之外进行一些处理,或者编写一些非常复杂的插件。 借助 8.0,用户现在可以在Elasticsearch 中更直接地执行命名实体识别、情感分析、文本分类等操作——无需额外的组件或编码。 不仅在 Elasticsearch 中本地计算和创建向量在水平可扩展性方面是“胜利”(通过在服务器集群中分布计算)——这一变化还为 Elasticsearch 用户节省了大量时间和精力
借助Elastic 8.0,用户可以直接在 Elasticsearch 中使用 PyTorch 机器学习模型(例如 BERT), 并在Elasticsearch 中使用这些模型进行推理。通过使用户能够直接在 Elasticsearch 中执行推理,将现代 NLP 的强大功能集成到搜索应用程序和体验、本质上更高效(得益于 Elasticsearch 的分布式计算能力)和 NLP 本身比以往任何时候都更容易 变得更快,因为你不需要将数据移出到单独的进程或系统中。
4.3 NLP演示
项目插件地址:https://github.com/spinscale/elasticsearch-ingest-opennlp/releases/tag/8.1.1.1
目前这个NLP 支持检测 Date, Person, Location, POS (part of speech) 及其它,简单概述是将这个模型插件集成到ES,这样ES可以直接通过一句话进行查询分词;因为版本问题,需要打开插件的plugin-descriptor.properties文件,将ES版本8.1.1改成8.1.0,然后将ES进行重启(集群的话每台都要部署)
第二步下载NER模型,从sourceforge 下载最新的NER 模型
bin/ingest-opennlp/download-models
# 执行时,可能会提示脚本路径不对等问题。直接修改脚本文件改正即可
- 1
- 2
- 3

第三步配置 opennlp,修改配置文件:config/elasticsearch.yml,重启
ingest.opennlp.model.file.persons: en-ner-persons.bin
ingest.opennlp.model.file.dates: en-ner-dates.bin
ingest.opennlp.model.file.locations: en-ner-locations.bin
- 1
- 2
- 3
- 4
最后运用 opennlp
# 创建一个支持 NLP 的 pipeline PUT _ingest/pipeline/opennlp-pipeline { "description": "A pipeline to do named entity extraction", "processors": [ { "opennlp": { "field": "message" } } ] } # 增加数据 PUT my-nlp-index PUT my-nlp-index/_doc/1?pipeline=opennlp-pipeline { "message": "Shay Banon announced the release of Elasticsearch 6.0 in November 2017" } PUT my-nlp-index/_doc/2?pipeline=opennlp-pipeline { "message": "Kobe Bryant was one of the best basketball players of all times. Not even Michael Jordan has ever scored 81 points in one game. Munich is really an awesome city, but New York is as well. Yesterday has been the hottest day of the year." } # 查看数据 GET my-nlp-index/_doc/1 GET my-nlp-index/_doc/2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
五、Elasticsearch 优化
1、性能优化之缓存
Elasticsearch 应用时会使用各种缓存,而缓存是加快数据检索速度的王道。接下来,我们将着重介绍以下三种缓存:
- 页缓存
- 分片级请求缓存
- 查询缓存
1.1 页缓存
数据的安全、可靠,常规操作中,数据都是保存在磁盘文件中的。所以对数据的访问,绝大数情况下其实就是对文件的访问,为了提升对文件的读写的访问效率,Linux 内核会以页大小(4KB)为单位,将文件划分为多个数据块。当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(称为 PageCache 页缓存)与文件中的数据块进行绑定。
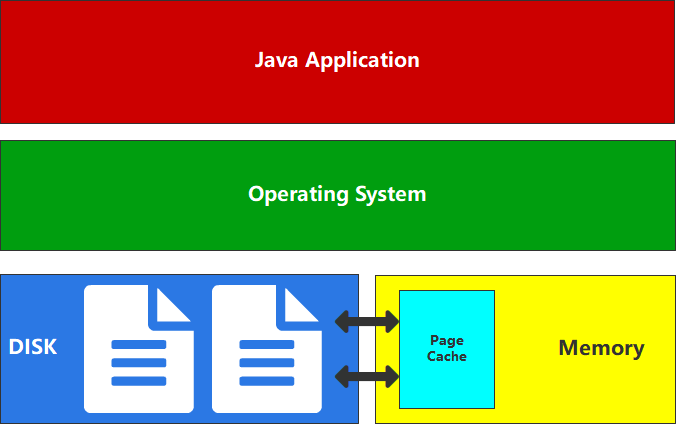
页缓存的基本理念是从磁盘读取数据后将数据放入可用内存中,以便下次读取时从内存返回数据,而且获取数据不需要进行磁盘查找。所有这些对应用程序来说是完全透明的,应用程序发出相同的系统调用,但操作系统可以使用页缓存而不是从磁盘读取。
Java 程序是跨平台的,所以没有和硬件(磁盘,内存)直接交互的能力,如果想要和磁盘文件交互,那么必须要通过 OS 操作系统来完成文件的读写,我们一般就称之为用户态转换为内核态。而操作系统对文件进行读写时,实际上就是对文件的页缓存进行读写。所以对文件进行读写操作时,会分以下两种情况进行处理:
- 当从文件中读取数据时,如果要读取的数据所在的页缓存已经存在,那么就直接把页缓存的数据拷贝给用户即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把页缓存的数据拷贝给用户。
- 当向文件中写入数据时,如果要写入的数据所在的页缓存已经存在,那么直接把新数据写入到页缓存即可。否则,内核首先会申请一个空闲的内存页(页缓存),并且把新数据写入到页缓存中。对于被修改的页缓存,内核会定时把这些页缓存刷新到文件中
页缓存对 Elasticsearch 来说意味着什么?与访问磁盘上的数据相比,通过页缓存可以更快地访问数据。这就是为什么建议的 Elasticsearch 内存通常不超过总可用内存的一半,这样另一半就可用于页缓存了。这也意味着不会浪费任何内存。如果数据本身发生更改,页缓存会将数据标记为脏数据,并将这些数据从页缓存中释放。由于 Elasticsearch 和 Lucene 使用的段只写入一次,因此这种机制非常适合数据的存储方式。段在初始写入之后是只读的,因此数据的更改可能是合并或添加新数据。在这种情况下, 需要进行新的磁盘访问。另一种可能是内存被填满了。在这种情况下,缓存数据过期的操作为 LRU。
1.2 分片级请求缓存
对一个或多个索引发送搜索请求时,搜索请求首先会发送到ES 集群中的某个节点,称之为协调节点;协调节点会把该搜索请求分发给其他节点并在相应分片上执行搜索操作,我们把分片上的执行结果称为“本地结果集”,之后,分片再将执行结果返回给协调节点;协调节点获得所有分片的本地结果集之后,合并成最终的结果并返回给客户端。Elasticsearch 会在每个分片上缓存了本地结果集,这使得频繁使用的搜索请求几乎立即返回结果。这里的缓存,称之为Request Cache, 全称是 Shard Request Cache,即分片级请求缓存。
ES 能够保证在使用与不使用 Request Cache 情况下的搜索结果一致,那 ES 是如何保证的呢?这就要通过** Request Cache 的失效机制来了解啦。Request Cache 缓存失效是自动的,当索引 refresh 时就会失效,也就是说在默认情况下, Request Cache 是每 1 秒钟失效一次**,但需要注意的是,只有在分片的数据实际上发生了变化时,刷新分片缓存才会失效。也就是说当一个文档被索引 到 该文档变成 Searchable 的这段时间内,不管是否有请求命中缓存该文档都不会被返回。
所以我们可以通过index.refresh_interval 参数来设置 refresh 的刷新时间间隔,刷新间隔越长,缓存的数据越多,当缓存不够的时候,将使用LRU 最近最少使用策略删除数据。当然,我们也可以手动设置参数 indices.request.cache.expire 指定失效时间(单位为分钟),但是基本上我们没必要去这样做,因为缓存在每次索引 refresh 时都会自动失效。
- Request Cache 的使用
# 默认情况下,Request Cache 是关闭的,我们可以在创建新的索引时启用 curl -XPUT 服务器 IP:端口/索引名 -d '{ "settings": { "index.requests.cache.enable": true } }' # 也可以通过动态参数配置来进行设置 curl -XPUT 服务器 IP:端口/索引名/_settings -d '{ "index.requests.cache.enable": true }' # 开启缓存后,需要在搜索请求中加上 request_cache=true 参数,才能使查询请求被缓存 curl -XGET ‘服务器 IP:端口/索引名/_search?request_cache=true&pretty' -H 'Content-Type: application/json' -d '{ "size": 0, "aggs": { "popular_colors": { "terms": { "field": "colors" } } } }'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
第一:参数 size:0 必须强制指定才能被缓存,否则请求是不会缓存的,即使手动的设置 request_cache=true
第二:在使用 script 脚本执行查询时,由于脚本的执行结果是不确定的(比如使用random 函数或使用了当前时间作为参数),一定要指定 request_cache=false 禁用 Request Cache 缓存。
- Request Cache 的设置
Request Cache 作用域为 Node,在 Node 中的 Shard 共享这个 Cache 空间。默认最大大小为 JVM 堆内存的 1%。可以使用以下命令在 config/elasticsearch.yml 文件中进行更改:indices.requests.cache.size: 1%。Request Cache 是以查询的整个DSL 语句做为 key 的,所以如果要命中缓存,那么查询生成的 DSL 一定要一样,即使修改了一个字符或者条件顺序,都不能利用缓存,需要重新生成Cache。
1.3 查询缓存
这种缓存的工作方式也与其他缓存有着很大的不同。页缓存方式缓存的数据与实际从查询中读取的数据量无关。当使用类似查询时,分片级请求缓存会缓存数据。查询缓存更精细些,可以缓存在不同查询之间重复使用的数据。
Elasticsearch 具有 IndicesQueryCache 类。这个类与 IndicesService 的生命周期绑定在一起,这意味着它不是按索引,而是按节点的特性 — 这样做是有道理的,因为缓存本身使用了 Java 堆。这个索引查询缓存占用以下两个配置选项indices.queries.cache.count:缓存条目总数,默认为 10,000,indices.queries.cache.size:用于此缓存的 Java 堆的百分比,默认为 10%
查询缓存已进入下一个粒度级别,可以跨查询重用!凭借其内置的启发式算法,它只缓存多次使用的筛选器,还根据筛选器决定是否值得缓存,或者现有的查询方法是否足够快, 以避免浪费任何堆内存。这些位集的生命周期与段的生命周期绑定在一起,以防止返回过时的数据。一旦使用了新段,就需要创建新的位集。
缓存是加快检索速度的唯一方法吗?
- io_uring。这是一种在 Linux 下使用自 Linux 5.1 以来发布的完成队列进行异步 I/O 的新方法。请注意,io_uring 仍处于大力开发阶段。但是,Java 中有一些首次使用 io_uring 的尝试,例如 netty。简单应用程序的性能测试结果十分惊人。我想我们还得等一段时间才能看到实际的性能数据,尽管我预计这些数据也会有重大变化。我们希望 JDK 将来也能提供对这一功能的支持。有一些计划支持 io_uring 作为 Project Loom 的一部分, 这可能会将 io_uring 引入 JVM。更多的优化,比如能够通过 madvise() 提示Linux 内核的访问模式,还尚未内置于 JVM 中。这个提示可防止预读问题,即内核尝试读取的数据会比预期下次读取的数据要多,这在需要随机访问时是无用的。
- Lucene 开发人员一如既往地忙于从任何系统中获得最大的收益。目前已经有使用Foreign Memory API 重写 Lucene MMapDirectory 的初稿,这可能会成为 Java 16 中的一个预览功能。然而,这样做并不是出于性能原因,而是为了克服当前 MMap 实现的某些限制
- Lucene最近的另一个变化是通过在FileChannel 类中使用直接i/o (O_DIRECT)来摆脱原生扩展。这意味着写入数据将不会让页缓存出现“抖动”现象,这将是 Lucene 9 的功能
2、性能优化之减少内存堆
由于 Elasticsearch 用户不断突破在 Elasticsearch 节点上存储的数据量的极限,所以他们有时会在耗尽磁盘空间之前就将堆内存用完了。对于这些用户来说,这个问题难免让他们沮丧,因为每个节点拟合尽可能多的数据通常是降低成本的重要手段。
但为什么 Elasticsearch 需要堆内存来存储数据呢?为什么它不能只用磁盘空间呢?这其中有几个原因,但最主要的一个是,Lucene 需要在内存中存储一些信息,以便知道在磁盘的什么位置进行查找。例如,Lucene 的倒排索引由术语字典和术语索引组成,术语字典将术语按排序顺序归入磁盘上的区块,术语索引用于快速查找术语字典。该术语索引将术语前缀与磁盘上区块(包含具有该前缀的术语)起始位置的偏移量建立映射。术语字典在磁盘上,但是术语索引直到最近还在堆上。
索引需要多少内存?通常情况下,每 GB 索引需要几 MB 内存。这并不算多,但随着用户在节点上安装 TB 数越来越大的磁盘,索引很快就需要 10-20 GB 的堆内存来存储这些 TB 量级的索引。鉴于 Elastic 的建议,不要超过 30 GB,不然就没有给聚合等其他堆内存消耗者留下太多空间,而且,如果 JVM 没有为集群管理操作留出足够的空间,就会导致稳定性问题。使用 **7.7 **版本减少 **Elasticsearch **堆!
3、功能优化之冻结层和可搜索快照
Elasticsearch 7.12 版中推出了冻结层的技术预览版,让您能够将计算与存储完全分离, 并直接在对象存储(如 AWS S3、Microsoft Azure Storage 和 Google Cloud Storage)中搜索数据。作为我们数据层旅程的下一个重要里程碑,冻结层实现以超低成本长期存储大量数据的同时,还能保持数据处于完全活动和可搜索状态,显著扩展了您的数据覆盖范围。
长期以来,我们一直支持通过多个数据层来进行数据生命周期管理:热层用于提供较高的处理速度,温层则用于降低成本,但性能也较低。两者都利用本地硬件来存储主数据和冗余副本。最近,我们引入了冷层,通过消除在本地存储冗余副本的需要,您可以在相同数量的硬件上最多存储两倍于热层的数据。尽管为了获得最佳性能,主数据仍然存储在本地,但冷层中的索引由存储在对象存储中的可搜索快照提供支持,以实现冗余。
冻结层更进一步,完全不需要在本地存储任何数据。相反,它会使用可搜索快照来直接搜索存储在对象存储中的数据,而无需先将其解冻。本地缓存存储最近查询的数据,以便在进行重复搜索时提供最佳性能。因此,存储成本显著下降:与热层或温层相比,最多可降低90%;与冷层相比,最多可降低 80%。数据的全自动生命周期现已成为完整体:从热到温到冷,然后再到冻结,同时还可确保以尽可能低的存储成本获得所需的访问和搜索性能。
冻结层利用可搜索快照将计算与存储完全分离。在根据索引生命周期管理 (ILM) 策略将数据从温层或冷层迁移到冻结层时,本地节点上的索引将迁移到 S3 或您选择的对象存储中。冷层将索引迁移到对象存储,但它仍然在本地节点上保留数据的单个完整副本,以确保提供快速而一致的搜索体验。另一方面,冻结层完全消除了本地副本,而是直接搜索对象存储中的数据。它会为最近查询的数据构建本地缓存,以便加快重复搜索的速度,但缓存大小只是存储在冻结层中的完整数据大小的一小部分。
对于典型的 10% 本地缓存大小,这意味着您只需少数几个本地层节点即可处理数百TB 的冻结层数据。下面简单比较一下:如果 RAM 为 64 GB 的典型温层节点可管理 10 TB,冷层节点将能够处理大约两倍于此的 20 TB,而冻结层节点将跃升至 100 TB。这相当于 1:1500 的 RAM 与存储比率,这还只是一个保守的估计。
4、功能优化之原生矢量搜索
Elasticsearch 8.0 版引入了一整套原生矢量搜索功能,让客户和员工能够使用他们自己的文字和语言来搜索并收到高度相关的结果。早在 Elasticsearch 7.0 版中,我们就针对高维矢量引入了字段类型。在 Elasticsearch 7.3 和 Elasticsearch 7.4 版中,引入了对矢量相似函数的支持。在 Elasticsearch 8.0 版中,将对自然语言处理 (NLP) 模型的原生支持直接引入了 Elasticsearch,让矢量搜索功能更容易实现。此外,Elasticsearch 8.0 版还包含了对近似最近邻 (ANN) 搜索的原生支持,因此可以快速且大规模地比较基于矢量的查询与基于矢量的文档语料库。
自然语言处理(Natural Language Processing)是计算科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分
- NLP 的目标
NLP 的目标是让计算机在理解语言方面像人类一样智能,最终的目标是弥补人类交流(自然语言)和计算机理解(机器语言)之间的差距。
- 为什么需要 NLP
有了 NLP,就可能完成自动语音、自动文本的编写等任务。让我们从大量的数据中解放出来,让计算机去执行。这些任务包括自动生成给定文本的摘要、机器翻译及其他的任务。
5、功能优化之搜索聚合
Elasticsearch 7.13 版新增功能可以实现更快的聚合。在 date_histogram 聚合方面, Elasticsearch 通过在内部将其重写为 filters 聚合,获得了巨大的性能提升。具体来说,它变成了一个包含 range 查询的 filters 聚合。这就是Elasticsearch 优化的内容 — range 查询。
为了加快 terms 和 date_histogram 这两个聚合的速度。可以将它们作为 filters 运行, 然后加快 filters 的聚合速度。
参考链接:

