
- 1【Android】MQTT的接入_android org.eclipse.paho:org.eclipse.paho.client.m
- 2mysql8 plugin,MySQL8 Authentication plugin Change
- 3(原创)机器学习之矩阵论(三)
- 4《AutoSar实战》读写DID之三:代码实现_autosar did
- 5ros小问题之rosdep update time out问题
- 6如何用Ai制作3D效果_ai 3d效果怎么做
- 7JDK17的下载安装(与JDK1.8相互切换)
- 8鸿蒙系统服务器奔溃,大量升级服务器崩溃,国产手机系统终于翻篇了!鸿蒙使用体验!...
- 9使用Python辅助ArcGIS出图_gis中python输入给定图层出图
- 10PyTorch中调用用GPU的方法_torch调用gpu
30分钟读懂Linux进程调度(图文并茂)_linux 0.11 dotimer
赞
踩
滴答视角
滴答
计算机中有一个设备,叫定时器,准确说叫可编程定时/计数器。
这个定时器每隔一段时间就会向 CPU 发起一个中断信号。
在 linux-0.11 中,这个间隔时间被设置为 10 ms,也就是 100 Hz。
shedule.c
#define HZ 100发起的中断叫时钟中断,其中断向量号被设置为了 0x20。
时钟中断
一切的源头,就源于这个每 10ms 产生的一次时钟中断。
当然如果没有操作系统的存在,这个 10ms 一次的时钟中断,就打了水漂,CPU 会收到这个时钟中断信号,但不会做出任何反应。
但很不幸,linux 提前设置好了中断向量表。
schedule.c
set_intr_gate(0x20, &timer_interrupt);这样,当时钟中断,也就是 0x20 号中断来临时,CPU 会查找中断向量表中 0x20 处的函数地址,这个函数地址即中断处理函数,并跳转过去执行。
这个中断处理函数就是 timer_interrupt,是用汇编语言写的。
system_call.s
- _timer_interrupt:
- ...
- // 增加系统滴答数
- incl _jiffies
- ...
- // 调用函数 do_timer
- call _do_timer
- ...
这个函数做了两件事,一个是将系统滴答数这个变量 jiffies 加一,一个是调用了另一个函数 do_timer。
sched.c
- void do_timer(long cpl) {
- ...
- // 当前线程还有剩余时间片,直接返回
- if ((--current->counter)>0) return;
- // 若没有剩余时间片,调度
- schedule();
- }
do_timer 最重要的部分就是上面这段代码,非常简单。
首先将当前进程的时间片 -1,然后判断:
如果时间片仍然大于零,则什么都不做直接返回。
如果时间片已经为零,则调用 schedule(),用脚去想也知道,这就是进行进程调度的主干。
进程的调度
- void schedule(void) {
- int i, next, c;
- struct task_struct ** p;
- ...
- while (1) {
- c = -1;
- next = 0;
- i = NR_TASKS;
- p = &task[NR_TASKS];
- while (--i) {
- if (!*--p)
- continue;
- if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
- c = (*p)->counter, next = i;
- }
- if (c) break;
- for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
- if (*p)
- (*p)->counter = ((*p)->counter >> 1) +
- (*p)->priority;
- }
- switch_to(next);
- }

别看一大坨,我做个不严谨的简化,你就懂了。
- void schedule(void) {
- int next = get_max_counter_from_runnable();
- refresh_all_thread_counter();
- switch_to(next);
- }
很简单,这个函数就做了三件事:
1. 拿到剩余时间片(counter的值)最大且在 runnable 状态(state = 0)的进程号 next。
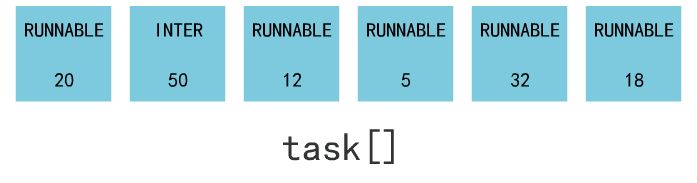
2. 如果所有 runnable 进程时间片都为 0,则将所有进程(注意不仅仅是 runnable 的进程)的 counter 重新赋值(counter = counter/2 + priority),然后再次执行步骤 1。
3. 最后拿到了一个进程号 next,调用了 switch_to(next) 这个方法,就切换到了这个进程去执行了。
【文章福利】小编推荐自己的Linux内核技术交流群:【977878001】整理一些个人觉得比较好得学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前100进群领取,额外赠送一份价值699的内核资料包(含视频教程、电子书、实战项目及代码)
切换进程
看 switch_to 方法,是用内联汇编语句写的。
sched.h
- #define switch_to(n) {\
- struct {long a,b;} __tmp; \
- __asm__("cmpl %%ecx,_current\n\t" \
- "je 1f\n\t" \
- "movw %%dx,%1\n\t" \
- "xchgl %%ecx,_current\n\t" \
- "ljmp %0\n\t" \
- "cmpl %%ecx,_last_task_used_math\n\t" \
- "jne 1f\n\t" \
- "clts\n" \
- "1:" \
- ::"m" (*&__tmp.a),"m" (*&__tmp.b), \
- "d" (_TSS(n)),"c" ((long) task[n])); \
- }
这段话就是进程切换的最最最最底层的代码了,看不懂没关系,其实主要就干了两件事。
1. 通过 ljmp 跳转指令跳转到新进程的偏移地址处。
2. 将当前各个寄存器的值保存在当前进程的 TSS 中,并将新进程的 TSS 信息加载到各个寄存器。(这部分是执行 ljmp 指令的副作用,并且是由硬件实现的)
简单说,保存当前进程上下文,恢复下一个进程的上下文,跳过去!啥是上下文,就是他喵的一堆寄存器的值而已。

至此,我们梳理完了一个进程切换的整条链路,先来回顾一下。
1. 罪魁祸首的,就是那个每 10ms 触发一次的定时器滴答。
2. 而这个滴答将会给 CPU 产生一个时钟中断信号。
3. 而这个中断信号会使 CPU 查找中断向量表,找到操作系统写好的一个时钟中断处理函数 do_timer。
4. do_timer 会首先将当前进程的 counter 变量 -1,如果 counter 此时仍然大于 0,则就此结束。
5. 但如果 counter = 0 了,就开始进行进程的调度。
6. 进程调度就是找到所有处于 RUNNABLE 状态的进程,并找到一个 counter 值最大的进程,把它丢进 switch_to 函数的入参里。
7. switch_to 这个终极函数,会保存当前进程上下文,恢复要跳转到的这个进程的上下文,同时使得 CPU 跳转到这个进程的偏移地址处。
8. 接着,这个进程就舒舒服服地运行了起来,等待着下一次滴答的来临。
行行行,给你画个图,瞧把你懒的。。

这就是滴答视角。
数据结构视角
上面我们从一次滴答开始,掀起了一阵波浪,走完了一个滴答的整个流程。
下面我们换个静态视角,看看数据结构。
一切承载进程相关的数据,其罪魁祸首来自于这个数据结构。
struct task_struct * task[64] = {};没错,一个容量只有 64 大小的数组,数组中的元素是 task_struct 结构。
- struct task_struct {
- long state;
- long counter;
- long priority;
- struct tss_struct tss;
- };
这里只取了我们需要关心的关键字段。
state 就是进程的状态,取值 linux 中有明确定义。
- #define TASK_RUNNING 0
- #define TASK_INTERRUPTIBLE 1
- #define TASK_UNINTERRUPTIBLE 2
- #define TASK_ZOMBIE 3
- #define TASK_STOPPED 4
比如 state 取值不是 RUNNING 状态的,它就不会被进程调度。这在上面滴答视角的讲述中讲得很明白。
counter 和 priority 就是记录进程时间片的,counter 记录了剩余时间片,priority 表示优先级的意思,其实也就是为进程初始时间片分配一个值而已。这部分同样在上面的滴答视角的代码中,讲的很明白。
最后一个重要的结构就是 tss,它是个结构体,记录了进程上下文信息。
- struct tss_struct {
- ...
- long eip;
- long eflags;
- long eax,ecx,edx,ebx;
- long esp;
- long ebp;
- ...
- };
在讲滴答视角时我们也说了,我们老是说上下文上下文,究竟什么是上下文,其实就是这个结构体里的值,就是一堆寄存器的值而已。
同样在滴答视角的讲解中也提到了,进程切换的最核心一步,就是一个 ljmp 指令,该指令的副作用会将当前各个寄存器的值保存在当前进程的 TSS 中,并将新进程的 TSS 信息加载到各个寄存器,这就是上下文切换的本质。
所以我们看到,数据结构视角中所提到的数据,在滴答视角下都被用到了。
操作系统启动流程视角
当你按下了开机键,引导程序把内核从硬盘加载到内存,经过一番折腾后,开始执行系统初始化程序 init/main.c。
这部分的细节如果你很好奇,可以阅读我的自制操作系统系列文章的开头几篇。
好了,我们就从这 main.c 开启我们的旅程,当然,我们只关注进程相关的部分。
- void main(void) {
- ...
- // 第一步:进程调度初始化
- sched_init();
- ...
- // 第二步:创建一个新进程并做些事
- if (!fork()) {
- init();
- }
- // 第三步:死循环,操作系统正式启动完毕
- for(;;) pause();
- }
第一步是 sched_init 进程调度初始化,初始化些啥呢?很简单,我挑主要的讲。
- void sched_init(void) {
- // 初始化第一个进程的 tss
- set_tss_desc(...);
- // 将进程数组清零
- for(i=1;i<64;i++) {
- task[i] = NULL;
- ...
- }
- // 设置始终中断(滴答)
- set_intr_gate(0x20,&timer_interrupt);
- ...
- }
其实就是为进程管理需要的数据结构做一些初始化工作,并设置好时钟中断,以便可以走滴答视角那个流程。
第二步与进程调度关系不大,与操作系统原理的关系很大,主要是最终执行到 shell 程序等待用户输入,暂时不讲。
第三步,for(;;) pause(),反映了操作系统的本质,即操作系统就是一个中断驱动的死循环代码。
这段代码就是个死循环,将操作系统怠速在这里。而通过各种中断,比如本讲所说的时钟中断完成进程调度,再比如键盘中断完成用户输入,并还可能通过 shell 进程解释命令而执行一个新的程序。
当没有任何进程需要运行时,也即 CPU 空闲时,操作系统会调度到这段代码来运行,承载这段代码的进程我们通常叫它 0 号进程,这部分的原理可以看码农的荒岛求生的一篇文章《CPU 空闲时在干嘛?》,讲的很明白,且形象。
这就是操作系统启动流程的视角,我们可以看到,其实就是做各种各样的准备工作,然后启动一个 shell 进程,并进入死循环的等待状态,这期间不断由时钟中断触发进程调度机制。
以上,分别从滴答视角、数据结构视角、操作系统启动流程视角,来讲解来进程调度的细节。
所谓滴答视角,可以理解为常说的进程调度视角。所谓数据结构视角,可以理解为常说的进程管理视角。
但我更喜欢我起的这两个名字,尤其是滴答视角,好可爱有木有!
不过本文是以 linux 最早的版本 linux-0.11 为例,在后来的操作系统演进过程中,进程调度的细节也在不断添枝加叶,比如选出下一个要调度的进程不再是简单地比较时间片大小,比如进程实际发生切换的时机改到了系统调用返回前,再比如对页表切换的变化等等。
但整个骨架和流程都是一样的,也即你再去研究更为复杂的现代操作系统进程调度原理时,只要按照这三个视角去分析,总是可以把握主干。

