
- 1Gogs - 一款极易搭建的自助 Git 服务
- 2Android用itext生成含中文的PDF文档_android itextpdf.text.pdf
- 3微信小程序实现骨架屏和图片懒加载_4实验:分析 Pytorch 框架中 train_dataloader 的数据结构
- 5三层交换机实验(eNSP)_ensp三层交换机和路由器
- 6元学习:Meta-Learning in Neural Networks: A Survey
- 7微软ChatGPT技术的底层支撑——GPU_chatgpt怎么控制三万个gpu
- 8鸿蒙开发实例 | ArkUI JS飞机大战游戏开发_鸿蒙版飞机大战
- 9解决AndroidStudio无法连接华为手机(安卓10)问题_android studio 华为荣耀畅玩50 连不上
- 10找出素数并升序排列c语言,升序素数和降序素数 - 编程擂台 - 数学研发论坛 - Powered by Discuz!...
MMSegmentation笔记05:训练+日志可视化+测试集性能评估_mmsegmentation 测试效果
赞
踩
1. 训练
训练比较简单,MMSegmentation提供的训练方式是命令行执行代码:
python tools/train.py Zihao-Configs/ZihaoDataset_PSPNet_20230818.py
当然,切换到本地运行仍然会有文件路径的问题。这有两种解决方案:
-
先在命令行把当前路径切换为mmsegmentation:
cd mmsegmentation,再执行上述代码。 -
直接在根目录执行:
python mmsegmentation/tools/train.py mmsegmentation/Zihao-Configs/ZihaoDataset_PSPNet_20230818.py
显然,第一种比较直观方便。
这里我用的是UNet网络,所以执行的就是:
cd mmsegmentation
python tools/train.py Zihao-Configs/ZihaoDataset_UNet_20230712.py
然后就是漫长的训练等待,我的显卡是RTX 3060 16GB,训练了20个小时,如果硬件条件不允许的话,可以直接下载子豪兄训练好的pth权重文件。
训练完成后,就会在mmsegmentation/work_dirs目录下得到一堆东西:
-
ZihaoDataSet-UNet
-
20230819_154210:最后一次训练生成的文件夹
-
best_mIoU_iter_20000.pth:mIoU表现最好的权重文件,后缀代表是第20000次迭代表现最好
-
iter_40000.pth:最后一轮的权重文件
-
last_checkpoint:
-
ZihaoDataSet_UNet_20230712.py:上一讲生成的config文件
-
至此就完成了整个训练阶段,可以开始查看日志文件了。
2. 日志文件可视化
这个步骤主要是观察训练过程中的训练损失、测试损失以及每个类别最终在测试集上的各指标表现。
根据子豪兄的记事本文件,在pycharm上整理为一个py文件如下:
""" ========================================== @author: Seaton @Time: 2023/8/19:14:56 @IDE: PyCharm @Summary: 将日志文件可视化分析训练过程 ========================================== """ import pandas as pd import matplotlib import matplotlib.pyplot as plt from matplotlib import colors as mcolors import random import re import numpy as np matplotlib.rc("font", family='SimHei') # 设置中文字体 # 日志文件路径 json_path = 'mmsegmentation/work_dirs/ZihaoDataset-UNet/20230818_162530/vis_data/scalars.json' with open(json_path, "r") as f: json_list = f.readlines() # print(eval(json_list[4])) df_train = pd.DataFrame() df_test = pd.DataFrame() for each in json_list[:-1]: if 'aAcc' in each: df_test = df_test.append(eval(each), ignore_index=True) else: df_train = df_train.append(eval(each), ignore_index=True) df_train.to_csv('mmsegmentation/图表/训练日志-训练集.csv', index=False) df_test.to_csv('mmsegmentation/图表/训练日志-测试集.csv', index=False) # 定义所有线形、颜色、标记 random.seed(124) colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive', 'tab:cyan', 'black', 'indianred', 'brown', 'firebrick', 'maroon', 'darkred', 'red', 'sienna', 'chocolate', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'forestgreen', 'limegreen', 'darkgreen', 'green', 'lime', 'seagreen', 'mediumseagreen', 'darkslategray', 'darkslategrey', 'teal', 'darkcyan', 'dodgerblue', 'navy', 'darkblue', 'mediumblue', 'blue', 'slateblue', 'darkslateblue', 'mediumslateblue', 'mediumpurple', 'rebeccapurple', 'blueviolet', 'indigo', 'darkorchid', 'darkviolet', 'mediumorchid', 'purple', 'darkmagenta', 'fuchsia', 'magenta', 'orchid', 'mediumvioletred', 'deeppink', 'hotpink'] markers = [".", ",", "o", "v", "^", "<", ">", "1", "2", "3", "4", "8", "s", "p", "P", "*", "h", "H", "+", "x", "X", "D", "d", "|", "_", 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] linestyle = ['--', '-.', '-'] def get_line_arg(): """ 随机产生一种绘图线型 :return: 线形 """ line_arg = {} line_arg['color'] = random.choice(colors) # line_arg['marker'] = random.choice(markers) line_arg['linestyle'] = random.choice(linestyle) line_arg['linewidth'] = random.randint(1, 4) # line_arg['markersize'] = random.randint(3, 5) return line_arg def show_train_loss(): metrics = ['loss', 'decode.loss_ce', 'aux.loss_ce'] plt.figure(figsize=(16, 8)) x = df_train['step'] for y in metrics: try: plt.plot(x, df_train[y], label=y, **get_line_arg()) except: pass plt.tick_params(labelsize=20) plt.xlabel('step', fontsize=20) plt.ylabel('Loss', fontsize=20) plt.title('训练集损失函数', fontsize=25) plt.legend(fontsize=20) plt.savefig('mmsegmentation/图表/训练集损失函数.pdf', dpi=120, bbox_inches='tight') plt.show() def show_train_acc(): metrics = ['decode.acc_seg', 'aux.acc_seg'] plt.figure(figsize=(16, 8)) x = df_train['step'] for y in metrics: try: plt.plot(x, df_train[y], label=y, **get_line_arg()) except: pass plt.tick_params(labelsize=20) plt.xlabel('step', fontsize=20) plt.ylabel('Metrics', fontsize=20) plt.title('训练集准确率', fontsize=25) plt.legend(fontsize=20) plt.savefig('mmsegmentation/图表/训练集准确率.pdf', dpi=120, bbox_inches='tight') plt.show() def show_test(): metrics = ['aAcc', 'mIoU', 'mAcc', 'mDice', 'mFscore', 'mPrecision', 'mRecall'] plt.figure(figsize=(16, 8)) x = df_test['step'] for y in metrics: try: plt.plot(x, df_test[y], label=y, **get_line_arg()) except: pass plt.tick_params(labelsize=20) plt.ylim([0, 100]) plt.xlabel('step', fontsize=20) plt.ylabel('Metrics', fontsize=20) plt.title('测试集评估指标', fontsize=25) plt.legend(fontsize=20) plt.savefig('mmsegmentation/图表/测试集分类评估指标.pdf', dpi=120, bbox_inches='tight') plt.show() # 类别名 class_list = ['background', 'red', 'green', 'white', 'seed-black', 'seed-white'] # 日志文件路径 log_path = 'mmsegmentation/work_dirs/ZihaoDataset-UNet/20230818_162530/20230818_162530.log' with open(log_path, 'r') as f: logs = f.read() def transform_table_line(raw): """ 定义正则表达式 :param raw: :return: """ raw = list(map(lambda x: x.split('|'), raw)) raw = list(map( lambda row: list(map( lambda col: float(col.strip()), row )), raw )) return raw # 横轴:训练迭代次数,每500一个点 x = range(500, 40500, 500) metrics_json = {} for each_class in class_list: # 遍历每个类别 re_pattern = r'\s+{}.*?\|(.*)?\|'.format(each_class) # 定义该类别的正则表达式 metrics_json[each_class] = {} metrics_json[each_class]['re_pattern'] = re.compile(re_pattern) # 匹配 for each_class in class_list: # 遍历每个类别 find_string = re.findall(metrics_json[each_class]['re_pattern'], logs) # 粗匹配 find_string = transform_table_line(find_string) # 精匹配 metrics_json[each_class]['metrics'] = find_string def show_each_class(): for each_class in class_list: # 遍历每个类别 each_class_metrics = np.array(metrics_json[each_class]['metrics']) plt.figure(figsize=(16, 8)) for idx, each_metric in enumerate(['IoU', 'Acc', 'Dice', 'Fscore', 'Precision', 'Recall']): try: plt.plot(x, each_class_metrics[:, idx], label=each_metric, **get_line_arg()) except: pass plt.tick_params(labelsize=20) plt.ylim([0, 100]) plt.xlabel('step', fontsize=20) plt.ylabel('Metrics', fontsize=20) plt.title('mmsegmentation/图表/类别 {} 训练过程中,在测试集上的评估指标'.format(each_class), fontsize=25) plt.legend(fontsize=20) # plt.savefig('类别 {} 训练过程评估指标.pdf'.format(each_class), dpi=120, bbox_inches='tight') plt.show() if __name__ == '__main__': show_train_loss() show_train_acc() show_test() show_each_class()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
同样的,由于我的py文件新建在根目录下,与 git clone 下来的segmentation文件夹并列,所以基本每个路径前都加上了mmsegmentation/
此外,为了方便分别展示不同的图表,我将一些代码块封装为了函数,最后在main里面调用。
3. 测试集评估
测试集评估阶段也很简单,MMSegmentation提供了相关的命令行指令:python tools/test.py Zihao-Configs/ZihaoDataset_PSPNet_20230818.py ./work_dirs/ZihaoDataset-PSPNet/iter_40000.pth
这一步骤与训练如出一辙,要么使用cd改一下当前路径,要么在命令中的路径前加上mmsegmentation/,推理完成就可以看到相关指标了。
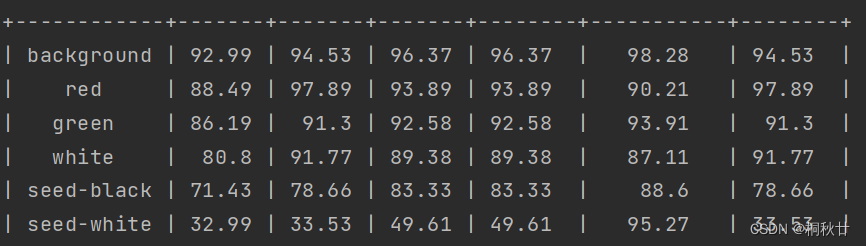
可以看到除了最后的白籽,其他指标表现非常好,这是由于白籽目标太小,且数据集也不多,因此表现不好。
而指标表现的比较好的原因其实是这里子豪兄的测试集与验证集相同,由于数据集不充分,就这么做了,实际应用中千万不要这么做。

