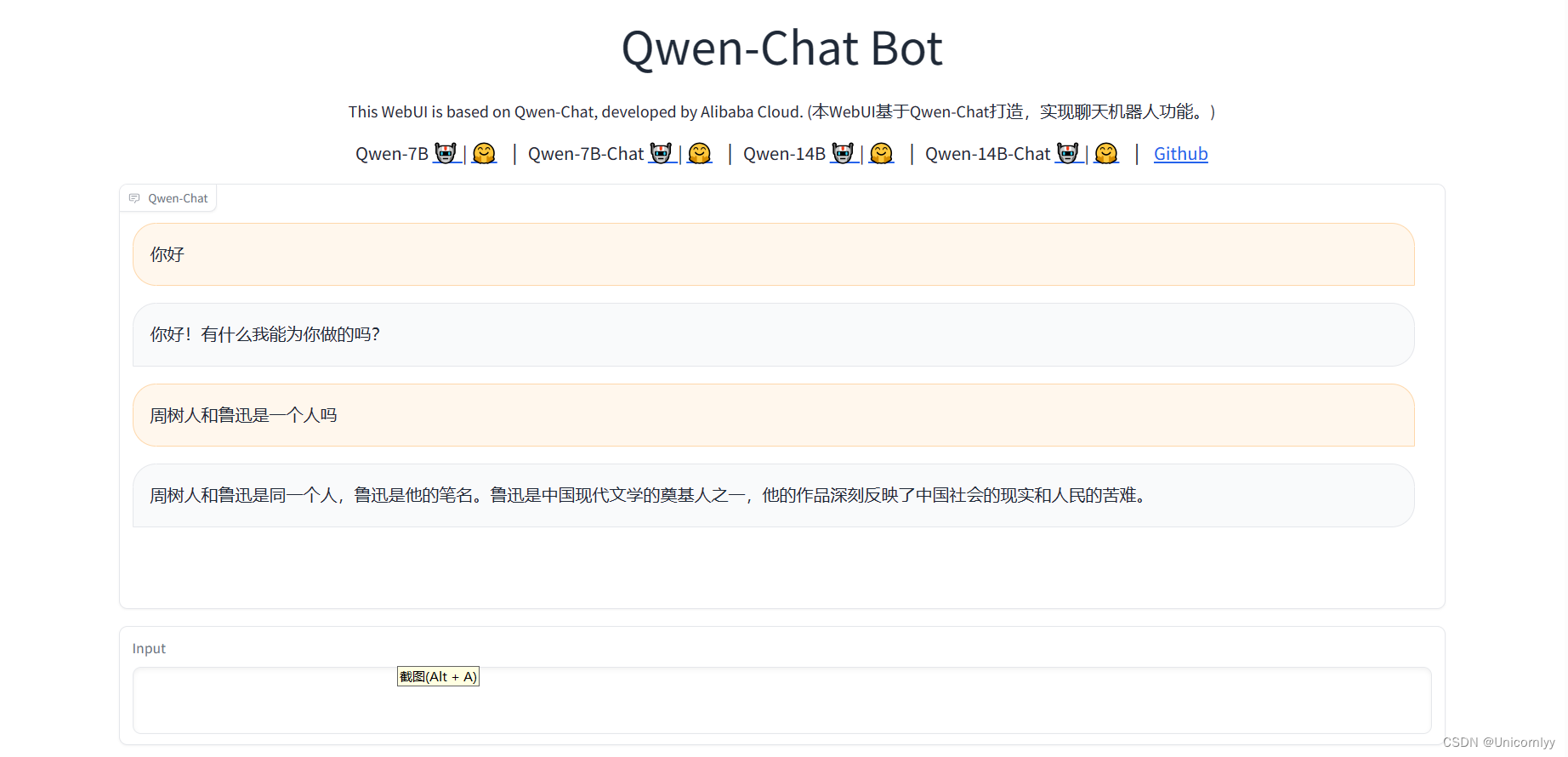
手把手教你在AutoDL上Qwen-7B-Chat WebDemo Qwen-7B-Chat 网络演示_qwen web_demo.py 没有回答
赞
踩
手把手带你在AutoDL上Qwen-7B-Chat WebDemo Qwen-7B-Chat 网络演示
项目地址:https://github.com/datawhalechina/self-llm.git
如果大家有其他模型想要部署教程,可以来仓库提交issue哦~ 也可以自己提交PR!
如果觉得仓库不错的话欢迎star!!!
Qwen-7B-Chat WebDemo 网络演示
同样如果前面跟着部署了的话可以不部署跳过前两步
环境准备
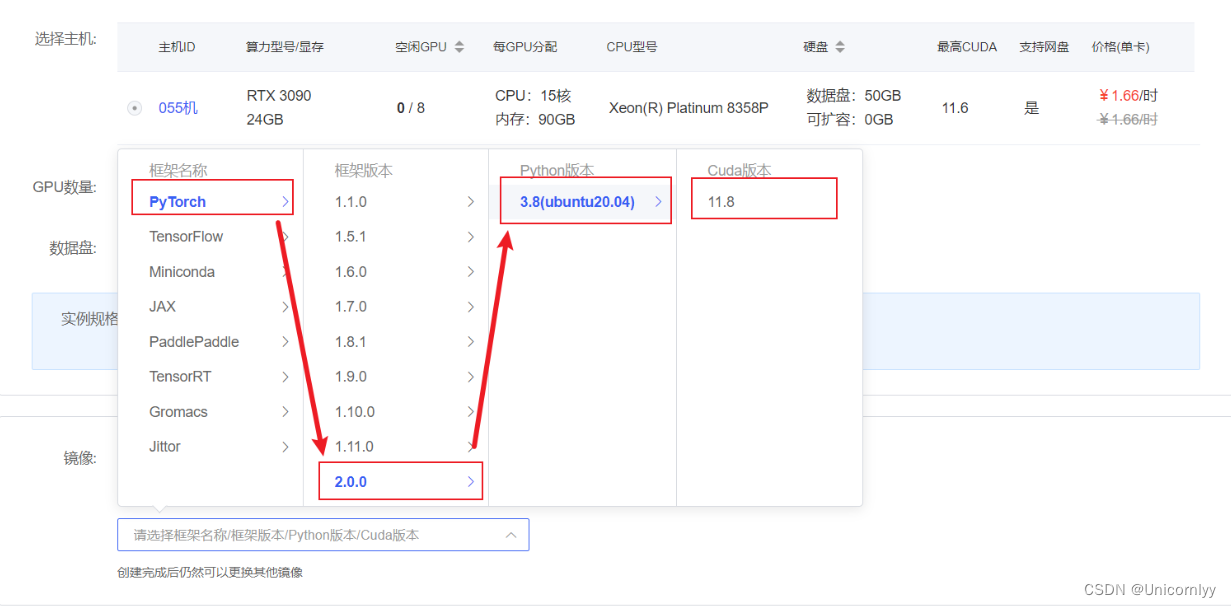
在autoal平台中租一个3090等24G显存的显卡机器,如下图所示镜像选择pytorch–>2.0.0–>3.8(ubuntu20.04)–>11.8(要注意在可支持的最高cuda版本>=11.8)
接下来打开自己刚刚租用服务器的JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行demo.

pip换源和安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.9.5
pip install "transformers>=4.32.0" accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
- 1
- 2
- 3
- 4
- 5
- 6
- 7
模型下载
使用modelscope(魔塔社区)中的snapshot_download函数下载模型,第一个参数为模型名称,参数cache_dir为模型的下载路径。
在/root/autodl-tmp路径下新建download.py文件
#将当前工作目录切换到/root/autodl-tmp目录下
cd /root/autodl-tmp
#创建一个名为download.py的空文件
touch download.py
- 1
- 2
- 3
- 4
#然后点击该文件夹进行输入
#或者输入以下命令
vim download.py
点击i进入编辑模式
并在其中输入以下内容:
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b', cache_dir='/root/autodl-tmp', revision='master')
- 1
- 2
- 3
- 4
粘贴代码后记得保存文件(Ctrl+S),如下图所示。
(如果使用vim命令 粘贴完记得点Esc退出编辑模型然后输入’:wq’回车进行保存退出)


保存后返回终端界面,运行Python /root/autodl-tmp/download.py执行下载,模型大小为15GB,下载模型大概需要10~20分钟。
代码准备
这里主要是

首先clone代码,打开autodl平台自带的学术镜像加速。学术镜像加速详细使用请看:https://www.autodl.com/docs/network_turbo/
source /etc/network_turbo
- 1
然后切换路径, clone代码.
cd /root/autodl-tmp
git clone https://github.com/QwenLM/Qwen.git
- 1
- 2
切换commit版本,与教程commit版本保持一致,可以让大家更好的复现。
cd Qwen
git checkout 981c89b2a95676a4f98e94218c192c095bed5364
- 1
- 2
最后取消镜像加速,因为该加速可能对正常网络造成一定影响,避免对后续下载其他模型造成困扰。
unset http_proxy && unset https_proxy
- 1
修改代码路径,将 /root/autodl-tmp/Qwen/web_demo.py中 13 行的模型更换为本地的/root/autodl-tmp/qwen/Qwen-7B-Chat。

demo运行
执行下面的命令安装依赖包:
cd /root/autodl-tmp/Qwen
pip install -r requirements.txt
pip install -r requirements_web_demo.txt
- 1
- 2
- 3
运行以下命令即可启动推理服务
cd /root/autodl-tmp/Qwen
python web_demo.py --server-port 6006
- 1
- 2
将 autodl 的端口映射到本地的 http://localhost:6006 即可看到demo界面。

注意:要在浏览器打开http://localhost:6006页面后,模型才会加载,如下图所示: