
- 1生成式AI的征程:技术革新与未来展望
- 2机器学习基础篇-学习率衰减_机器学习时学习率怎么衰减
- 3F1-score值计算
- 4特征点匹配应用——图像拼接的原理与基于OpenCV的实现_基于特征匹配的图像拼接
- 5HarmonyOS鸿蒙基于Java开发: 蓝牙开发_harmonyos 蓝牙开发只能使用 java语言?
- 6机器学习每周挑战——旅游景点数据分析
- 7AI大模型的预训练、迁移和中间件编程_chatgpt原理与架构:大模型的预训练、迁移和中间件编程
- 8鸿蒙开发实战项目(三十七):动画样式(JS)
- 9Python中删除set中指定元素元素不存在时不报错:s.discard()元素不存在时报错:s.remove()_python set删除元素 元素不存在 不报错
- 10机器学习笔记—线性回归_对给定数据“linear_x_y.txt"进行读取,第一行为x值(特征值),第二行为y值(回归标签
【透视图像目标检测(0)】卷首语
赞
踩
其实,透视图像目标检测很早就开始研究了,在博客笔记里面也躺了很多的坑没填,这个领域是一个很重要的领域,特别是在BEVFormerv2 使用透视监督后,透视的算法也又有应用的新地方了。
把个人理解的脉络梳理出来,供大家参考,欢迎指正!
思路研究
1 直接回归方法
1.1 基于Anchor的直接回归方法
预先对全部场景给出了各类目标的锚框,即Anchor-based。这种方法在一定程度上能够解决目标尺度不一和遮挡问题,提高检测精度,但缺乏效率性且很难枚举所有的方向,或为旋转的目标拟合一个轴对齐的包围框,泛化能力欠缺些。
1.1.1 基于几何约束
-
Deep3Dbbox算法,利用2D检测框和几何投影,并预测物体3D位姿和尺寸,通过求解目标中心到相机中心的平移矩阵,使预测的3D检测框重投影中心坐标与2D检测框中心坐标的误差最小。
-
MonoDIS算法,利用解耦的回归损失代替之前同时回归中心点、尺寸和角度的损失函数,该损失函数将回归部分分成K 组,通过单独回归参数组来解决不同参数之间的依赖关系,有效避免了各参数间误差传递的干扰,使得训练更加稳定。
MonoDIS算法属于基于几何约束的直接回归方法。MonoDIS是一种单目3D目标检测算法,它利用了从2D图像到3D空间的几何约束来直接回归目标的3D边界框。这种方法通过分析和利用二维图像和三维空间之间的几何关系,实现了从单目图像中有效地检测和定位三维目标。
在MonoDIS中,几何约束被用来指导3D边界框的回归过程。通过结合深度估计、目标尺寸和方向的预测,以及利用从2D检测到3D空间的映射关系,MonoDIS能够直接输出目标的3D边界框坐标。这种方法避免了复杂的中间步骤,如生成和匹配锚框,从而简化了目标检测的流程。
因此,MonoDIS算法通过利用几何约束进行直接回归,实现了从单目图像中准确检测三维目标的能力。
1.1.2 非几何约束
基于Anchor的直接回归方法,且非几何约束的单目3D目标检测方法在深度学习中确实存在,但可能不如那些基于几何约束的方法那么常见或广泛研究。这是因为单目3D目标检测本身就是一个具有挑战性的任务,通常需要利用更多的几何和上下文信息来提高精度。
例如,一些研究可能探索了将Anchor机制与深度估计或特征融合技术相结合的方法,以从单目图像中直接回归3D边界框。这些方法可能通过训练模型来学习如何将2D Anchor框映射到3D空间,从而预测目标的3D位置和尺寸。
但需要注意的是,由于单目3D目标检测的复杂性,这些方法可能仍然需要一些形式的几何约束或先验知识来提高性能。
1.2 基于Anchor free 的直接回归方法
Anchor free 抛弃了需要生成的复杂锚框, 而是通过直接预测目标的角点或中心点等方法来形成检测框。
1.2.1 基于几何约束
- RTM3D算法直接预测3D框的8个顶点和1个中心点,然后通过使用透视投影的几何约束估计3D边框。
RTM3D:它主要利用复杂的特征,如实例分割、车辆形状先验,甚至深度图,进行多阶段融合以选择最佳建议。这种方法需要大量的计算资源,并且在训练和推断阶段都较为消耗资源。此外,RTM3D还尝试从3D box顶点到2D box边缘之间的几何约束来修正并预测目标参数,以提高3D检测的准确性。
1.2.2 非几何约束
包括:逐像素目标检测算法和中心点预测
-
目标表示方式:
- 逐像素目标检测:这种算法将原始图像转换为特征图,并对特征图进行像素级别的分类。每个像素点都会被分类为目标或背景,从而构建出目标的完整轮廓。这种表示方式使得算法能够更精细地捕捉目标的形状和边界。
- 中心点预测:这种算法则主要关注于预测目标在图像中的中心点位置。通过确定中心点的坐标,再结合其他信息(如目标的尺寸或宽高比),可以确定目标在图像中的大致位置。这种表示方式更注重于目标的定位和分类,而不是像素级别的细节。
-
计算复杂度:
- 逐像素目标检测:由于需要对每个像素进行分类,这种算法通常具有较高的计算复杂度。特别是在处理高分辨率图像时,逐像素操作会导致计算量显著增加。
- 中心点预测:相比之下,中心点预测算法的计算复杂度通常较低。它只需要确定目标的中心点位置,而不需要对每个像素进行精细的分类。这使得它在处理大规模数据集或实时应用时具有更好的性能。
-
应用场景:
- 逐像素目标检测:由于能够精细地捕捉目标的形状和边界,逐像素目标检测算法在需要高精度目标轮廓的应用场景中表现出色,如医学影像分析、自动驾驶中的道路标记识别等。
- 中心点预测:中心点预测算法在目标定位和分类任务中具有较高的效率,因此适用于需要快速响应或处理大量数据的应用场景,如视频监控、行人检测等。
1.2.2.1 逐像素目标检测
- FCOS3D,基于 FCOS,属于直接回归方法。FCOS(Fully Convolutional One-Stage Object Detection)是一个全卷积的一阶段目标检测算法,它直接对目标边界框的四个坐标进行回归,而不是依赖于预设的锚框(Anchor)或者提议(Proposal)。在FCOS中,通过卷积神经网络提取特征后,直接对每个位置上的特征进行边界框的回归和类别的预测。这种方法简化了目标检测流程,避免了锚框生成和匹配等复杂步骤,从而提高了检测速度和灵活性。与传统的基于锚框的目标检测算法相比,FCOS直接回归边界框的方式使其能够更灵活地适应不同大小和形状的目标,并且减少了超参数的数量,使得模型更容易训练和调优。因此,FCOS可以被归类为直接回归方法的一种,它通过全卷积的方式直接对目标边界框进行回归,实现了高效且准确的目标检测。
1.2.2.2 中心点预测
-
CenterNet。CenterNet算法的核心思想是通过预测目标中心点的位置以及尺寸来实现目标检测。它直接回归目标的中心点坐标以及宽高尺寸,无需依赖锚框(Anchor)或提议(Proposal)。这种设计简化了目标检测的任务,同时提高了检测的准确性。在CenterNet中,通过全卷积网络生成热力图,热力图的峰值位置即对应目标的中心,每个峰值位置的图像特征则用来预测目标边界框的宽度和高度。因此,CenterNet可以被归类为直接回归方法,它通过直接回归目标中心点和尺寸的方式,实现了高效且准确的目标检测。MonoCon算法在MonoDLE算法的基础上添加了辅助学习模块,提升了模型的泛化能力。MonoDLE算法进行了一系列的 实验,发现了定位误差是影响单目3D目标检测模型性能的关键因素。因此,MonoDLE改进了中心点的取法,采用了从3D投影中心而不是2D边界框中心获取中心点的方法, 以提高模型性能。此外,在实例深度估计任务上,MonoDLE采用了不确定性原理对实例深度进行估计。
-
SMOKE算法舍弃了对2D边界框的回归,通过将单个关键点估计与回归的三维变量,来预测每个检测目标的3D框。设计了基于关键点的3D检测分支并去除了2D检测分支。SMOKE不属于基于几何约束的直接回归方法。虽然SMOKE算法在3D目标检测中考虑了目标的几何属性,但它更侧重于通过关键点估计(Keypoint Estimation)和端到端的网络结构来实现单目3D目标检测。具体来说,SMOKE提出了一种简洁的网络结构,通过多步解缠(multi-step disentanglement)的方法来提高3D参数的收敛性以及检测的精度。它延续了Centernet的key-point做法,认为2D检测模块是多余的,只保留了3D检测模块。SMOKE预测投影下来的3D框中心点和其他属性变量,从而得到3D框。这种方法更侧重于通过关键点估计来直接回归3D框的参数,而不是完全依赖于几何约束。基于几何约束的直接回归方法通常利用目标在二维空间中的投影与其在三维空间中的实际位置之间的几何关系进行回归。虽然SMOKE在处理3D目标检测时考虑了目标的几何特性,但它并不完全依赖于几何约束进行直接回归。
2 基于单目深度估计模型信息的方法
基于深度信息引导的方法。这类算法利用单目深度估计模型预先得到像素级深度图,将深度图与单目图像结合后输入检测器。
3 基于点云信息的方法
虽然深度信息有助于3D场景的理解,但简单地将其作为RGB 图像的额外通道,并不能弥补基于单目图像的方法和基于点云的方法之间的性能差异。
基于点云信息引导的方法。这类算法借助激光的雷达点云信息作为辅助监督进行模型训练,在推理时只需输入图像和单目相机信息。
涉及到模型包括:Pseudo lidar、基于FCOS或DenseBox框架的改进的DD3D、CaDDN等。

4 附录
3D边框表示目标的位置、尺寸和方向,是3D目标检测算法的输出。物体是否被遮挡、截断或具有不规则的形状,都用一个紧密边界的立方体包围住被检测到的目标。3D边框编码方式主要有3种,分别是8角点法、4角2高法、7参数法(常用),如下图所示。
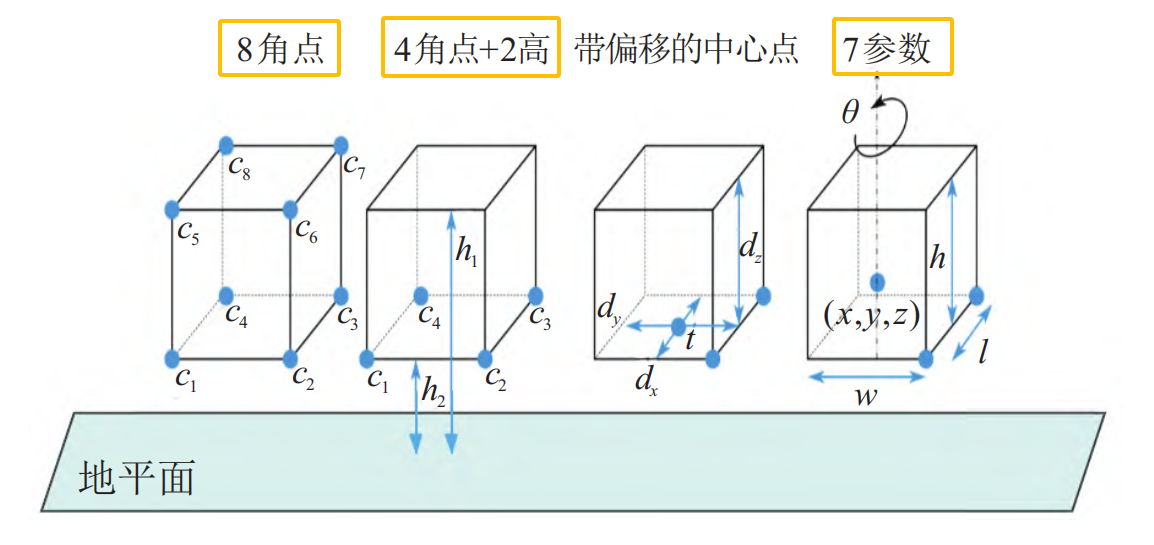
7参数法由7个坐标参数来表示。它包括边框的中心位置(x, y, z),边框在三维空间中的尺寸(l, w, h)以及表示角度的偏航角θ。
8角点法8角点法将3D边框通过连接8个角点(c1, c2, . . . , c8)来形成。每一个角点由三维坐标(x, y, z)表示,总计24维向量。
4角2高法为了保持地面目标的物理约束,3D框的上角需要保持与下角对齐,提出了一种4角2高编码的方法。
4 个角点 (c1, c2, c3, c4) 表示3D边框底面的4个顶点,每个角点用2D坐标(x, y)表示。
两个高度值(h1, h2)表示从地平面到底部和顶部角的偏移量。根据4个角点计算出4个可能的方向,并选择最近的一个作为方向向量。
参考
https://guo-pu.blog.csdn.net/article/details/134045064

