
大数据Hadoop之——部署hadoop+hive+Mysql环境(window11)_hadoop mysql
赞
踩
目录
2、hdfs-site.xml文件:添加以下配置,路径改成自己的安装路径
8、重置mysql root密码(命令行都要以管理员运行 )
7)下载mysql-connector-java-*.jar
8)创建Hive 初始化依赖的数据库hive,注意编码格式:latin1
一、安装JDK8
【温馨提示】对应后面安装的hadoop和hive版本,这里使用jdk8,这里不要用其他jdk了,可能会出现一些其他问题。
1)JDK下载地址
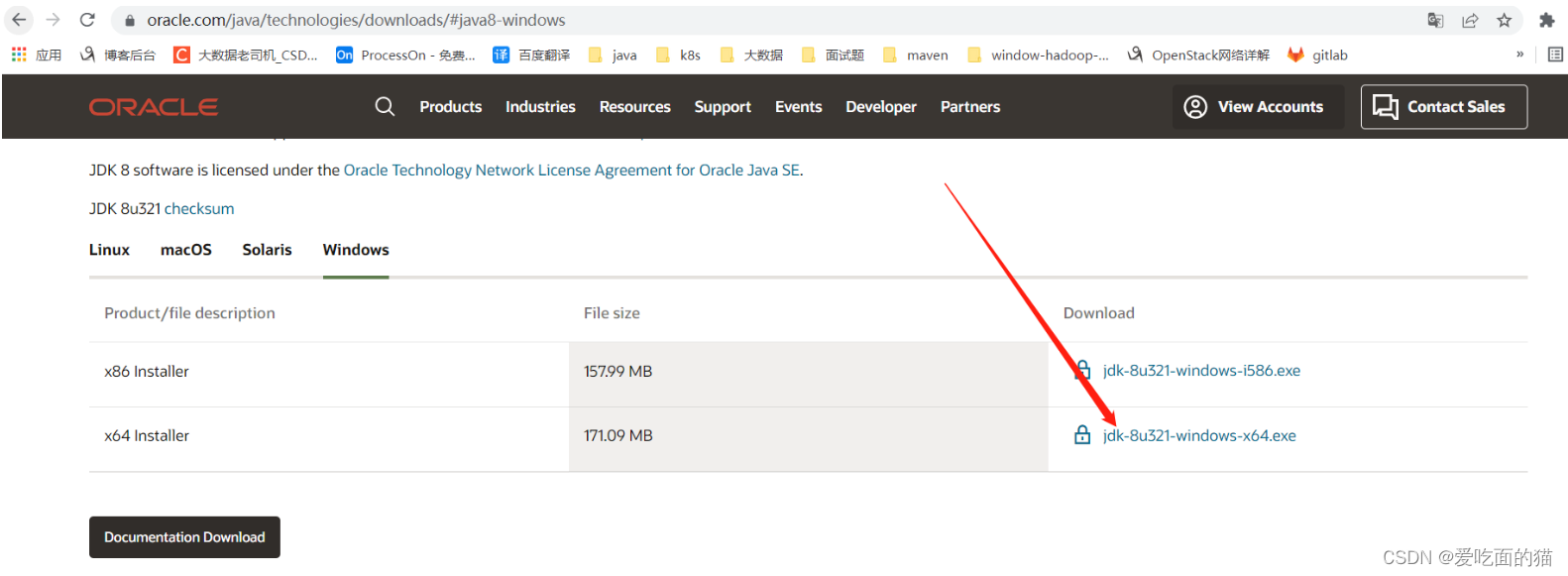
按正常下载是需要先登录的,这里提供一个不用登录下载的方法
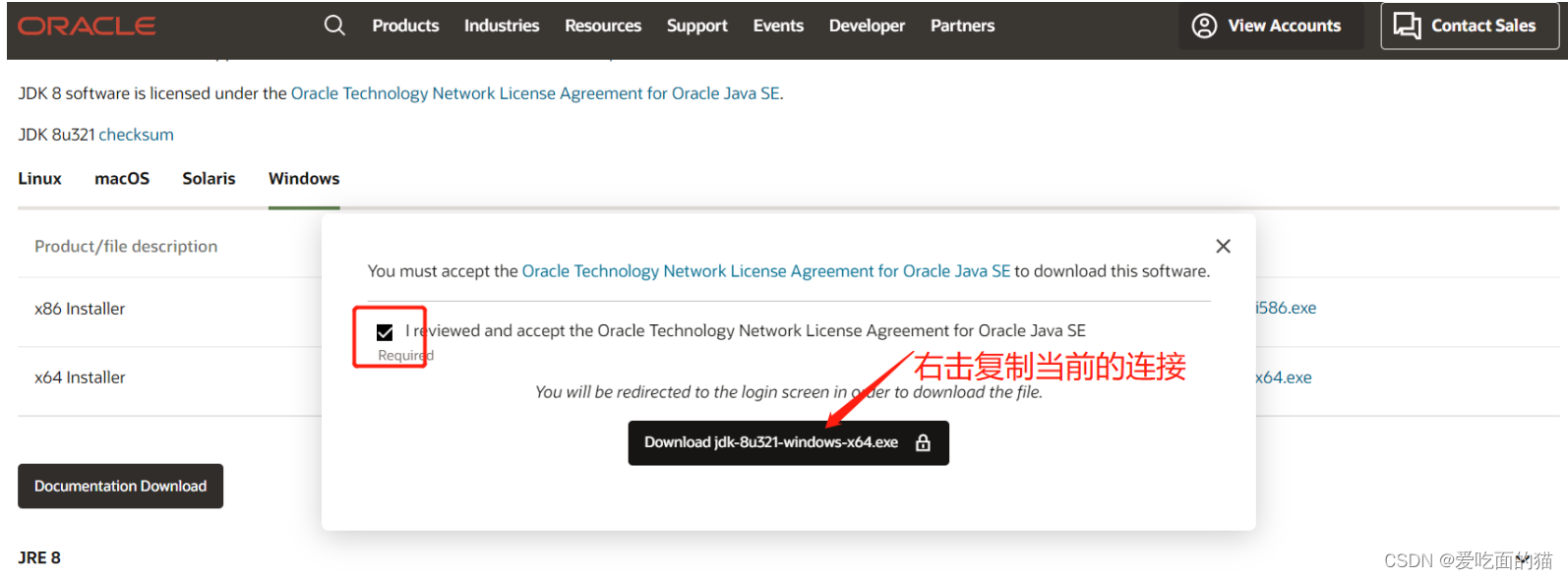
复制的连接如下:https://www.oracle.com/webapps/redirect/signon?nexturl=https://download.oracle.com/otn/java/jdk/8u321-b07/df5ad55fdd604472a86a45a217032c7d/jdk-8u321-windows-x64.exe
获取下载地址:使用复制的连接后半部分,将otn换成otn-pub就可以直接下载了
https://download.oracle.com/otn-pub/java/jdk/8u321-b07/df5ad55fdd604472a86a45a217032c7d/jdk-8u321-windows-x64.exe
下载完后就是傻瓜式安装了
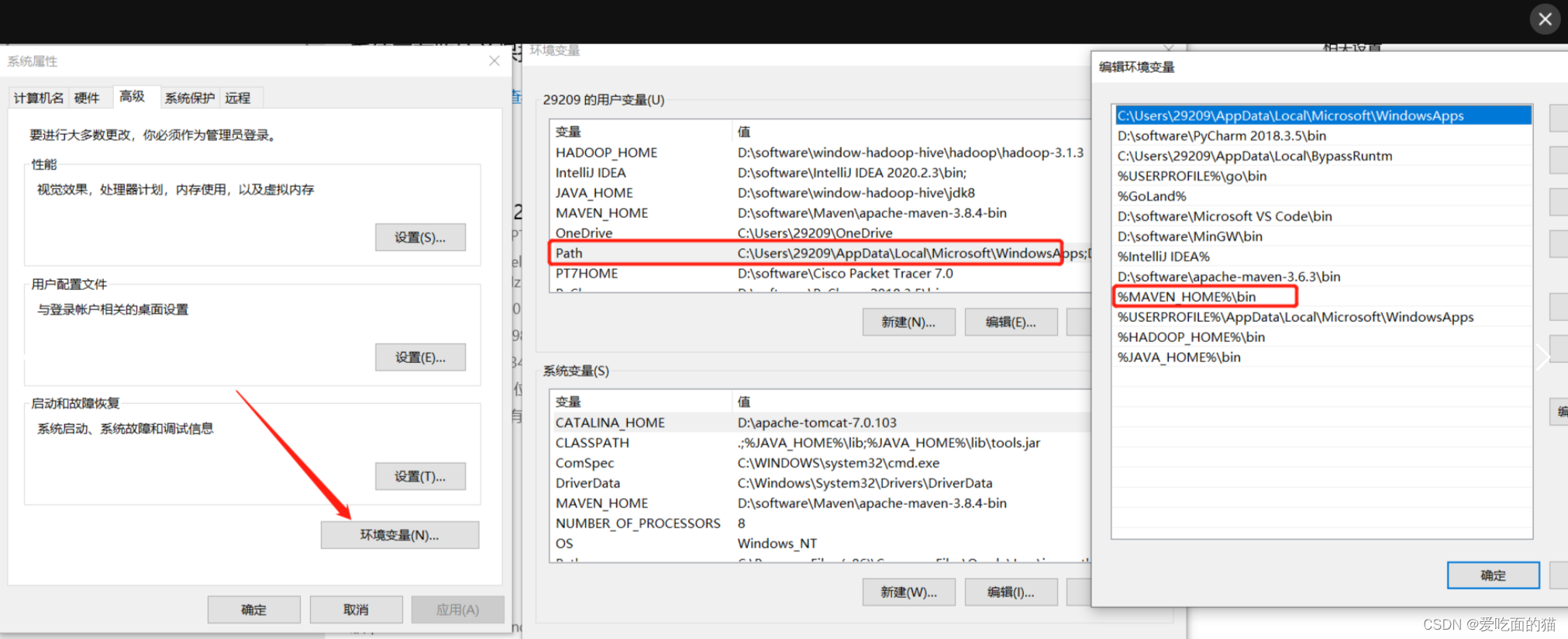
2)设置环境变量
3)验证
$ java -version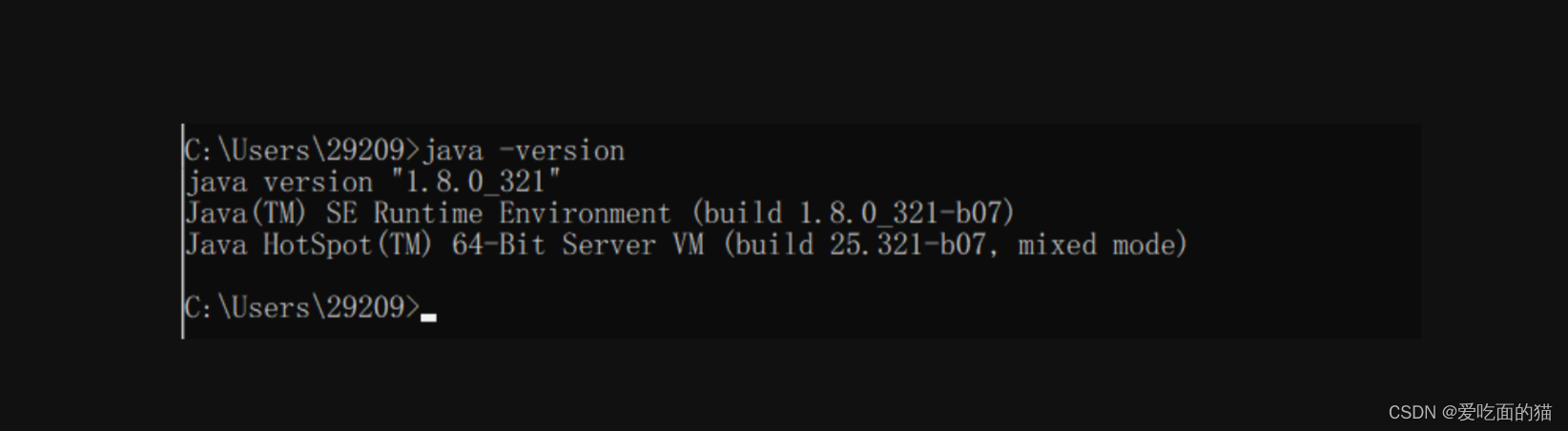
二、Hadoop安装(window10环境)
1)下载Hadoop3.1.3
官网下载:https://hadoop.apache.org/release/3.1.3.html
下载各种版本地址入口:Apache Hadoop

下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
下载后安装到哪里,解压到哪里(安装路径不要有空格和中文)
2)Hadoop配置环境变量
- HADOOP_HOME
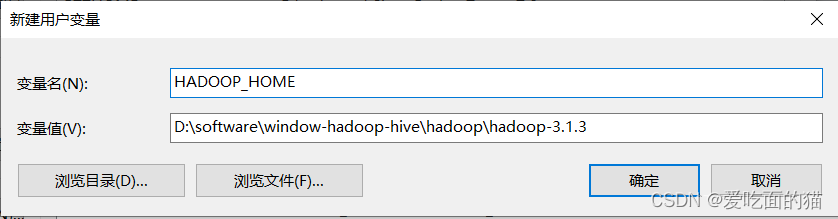
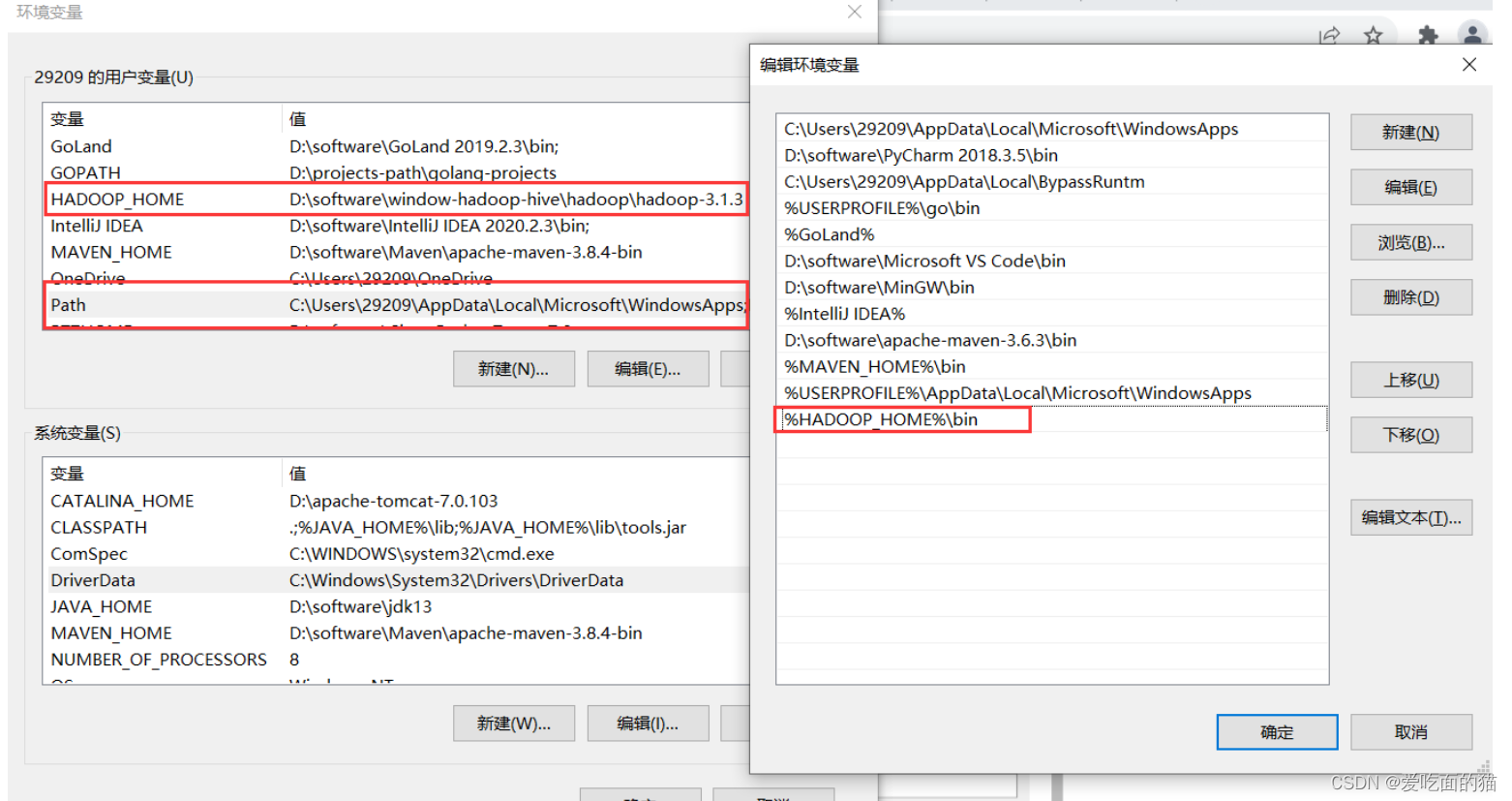
注意:
如果 jdk 默认安装C:\Program Files\Java\,则需要修改 %HADOOP_HOME%/etc/hadoop/hadoop-env.cmd 文件,
例如
将 set JAVA_HOME=C:\Program Files\Java\jdk1.8.0_191
改为 set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_191
或者直接改环境变量JAVA_HOME= 从C:\Program Files\Java\ 改成C:\PROGRA~1\Java\
验证
$ hadoop --version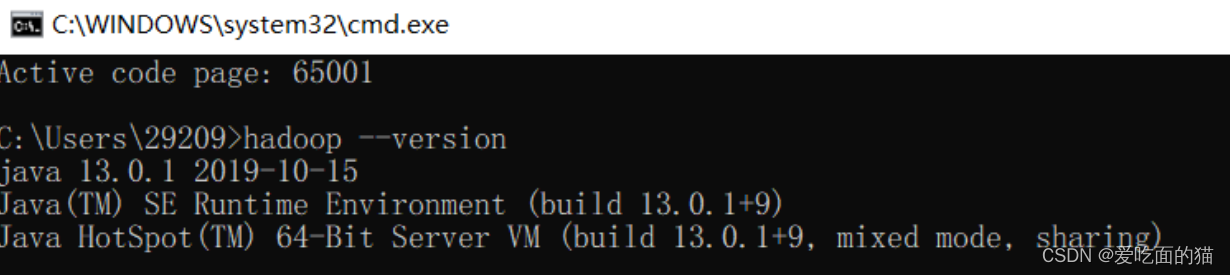
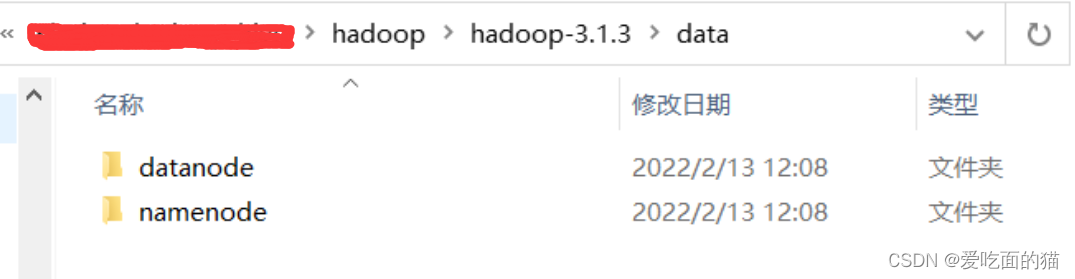
3)在hadoop解压目录下创建相关目录
- 创建data和tmp目录
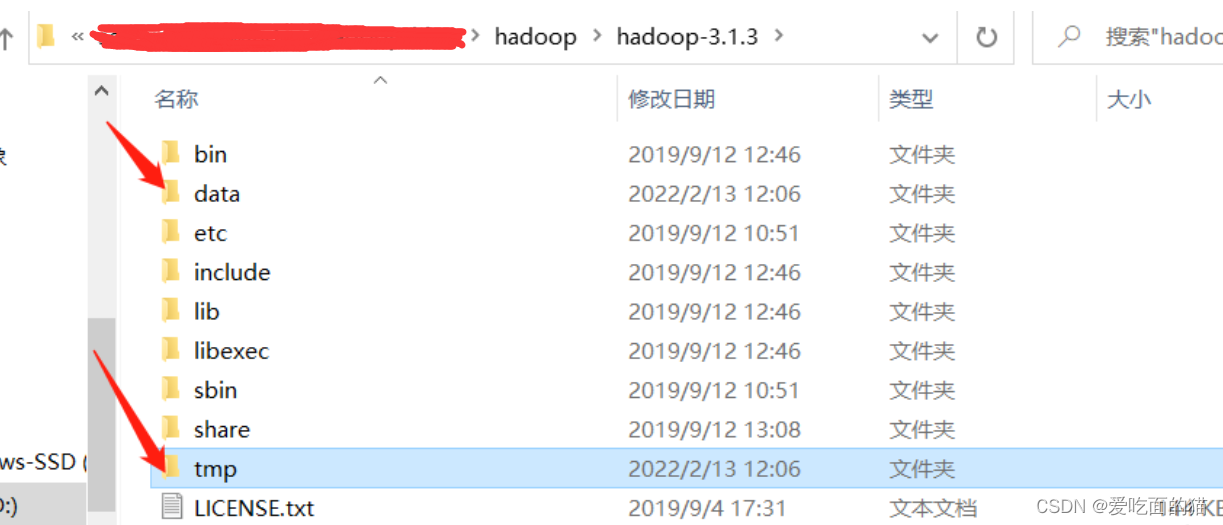
- 在data文件夹下面再创建namenode和datanode目录
4)修改Hadoop配置文件
- 配置文件目录:$HADOOP_HOME\etc\hadoop
1、core-site.xml文件:添加以下配置
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
2、hdfs-site.xml文件:添加以下配置,路径改成自己的安装路径
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>/D:/bigdata/hadoop/hadoop-3.1.3/data/namenode</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>/D:/bigdata/hadoop/hadoop-3.1.3/data/datanode</value>
- </property>
- </configuration>
3、mapred-site.xml文件:添加以下配置
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
4、yarn-site.xml文件:添加以下配置
- <configuration>
- <!-- Site specific YARN configuration properties -->
-
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <property>
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>1024</value>
- </property>
- <property>
- <name>yarn.nodemanager.resource.cpu-vcores</name>
- <value>1</value>
- </property>
-
- </configuration>

5)替换文件
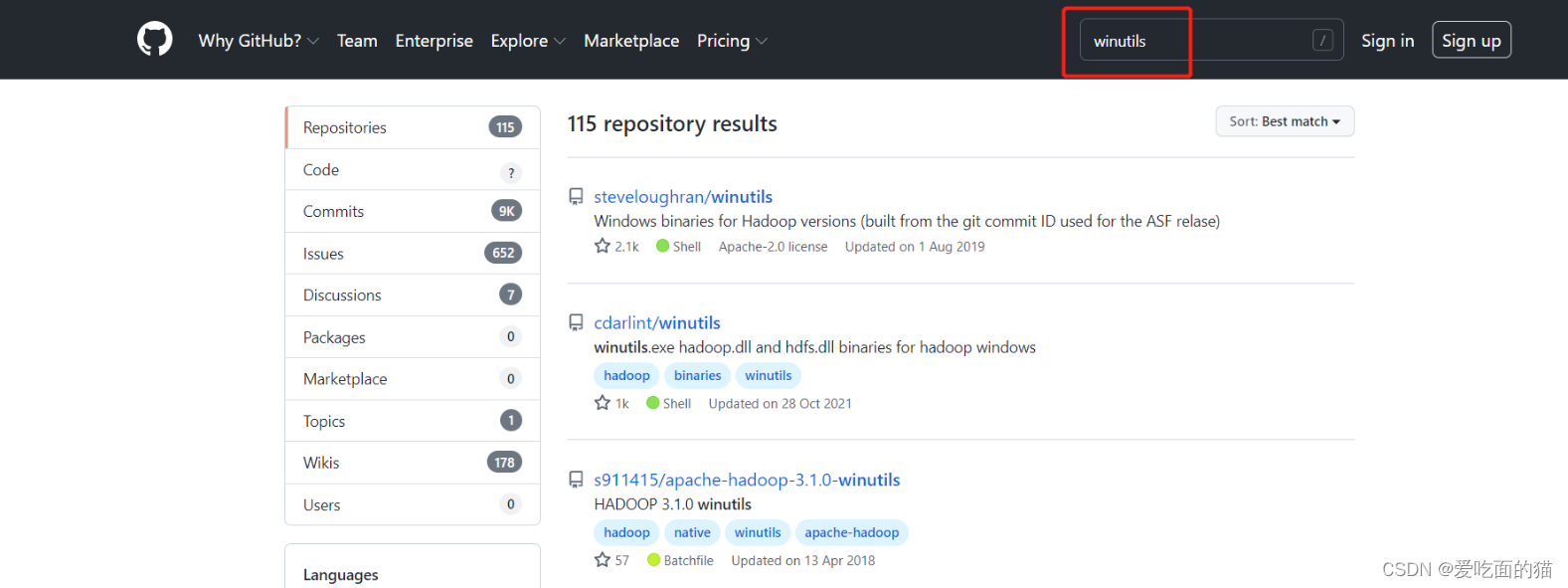
1、替换bin目录下文件(winutils)
打开winutils文件,把里面的bin文件复制到hadoop的安装路径,替换掉原来的bin文件,替换过程如下:
下载:apache-hadoop-3.1.0-winutils
也可以去GitHub上下载其它对应版本
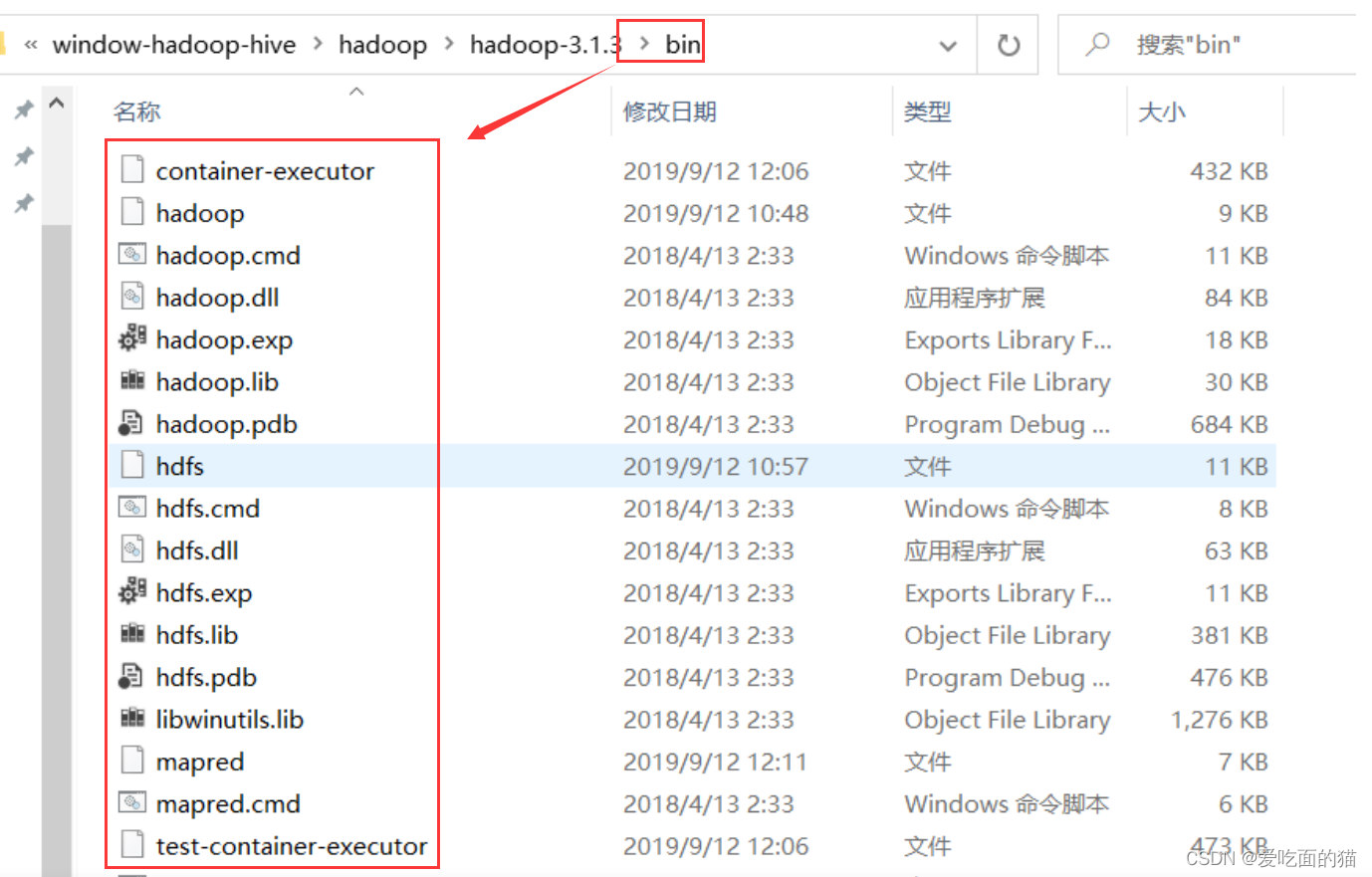
2、按照路径找到图中该文件
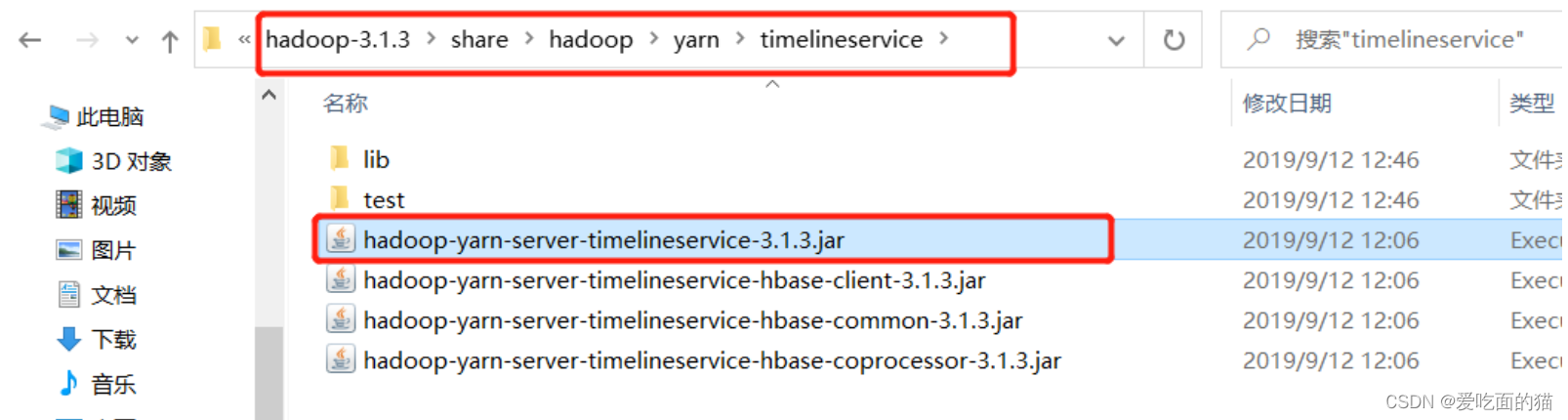
把它复制到上一级目录,即
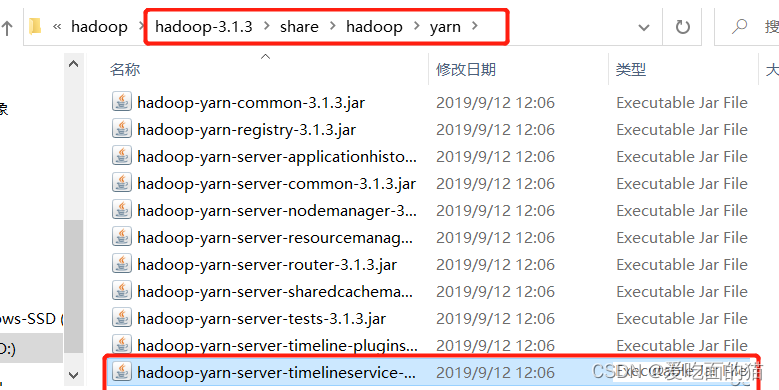
6)格式化节点
$ hdfs namenode -format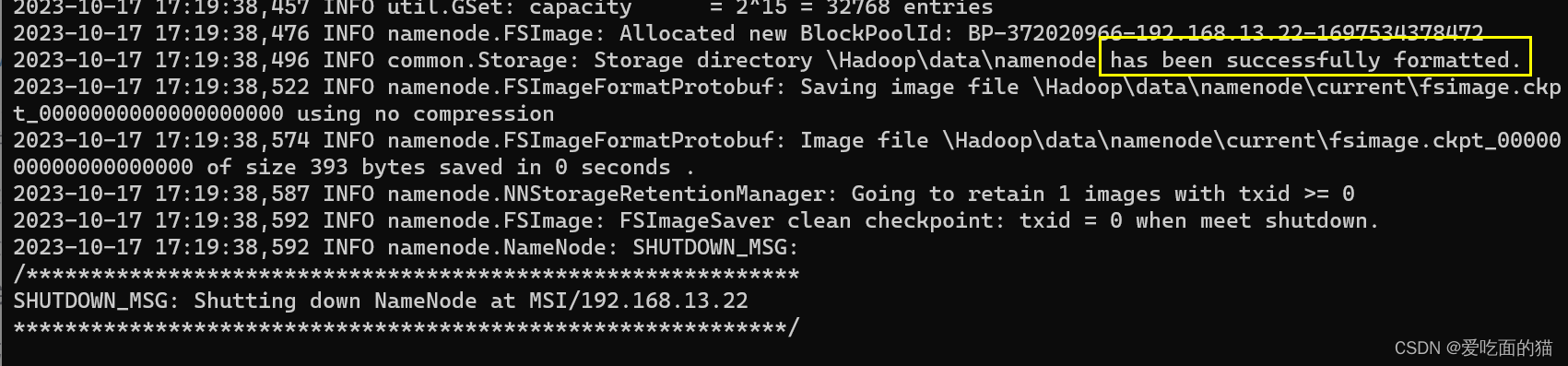
7)运行
【温馨提示】回到hadoop安装bin目录下,右击以管理员的身份运行start-all.cmd文件,要不然会报权限问题
出现下面四个窗口就是 成功了,注意每个窗口标题的后面的名称,比如yarn nodemanager,如果没有出现则是失败
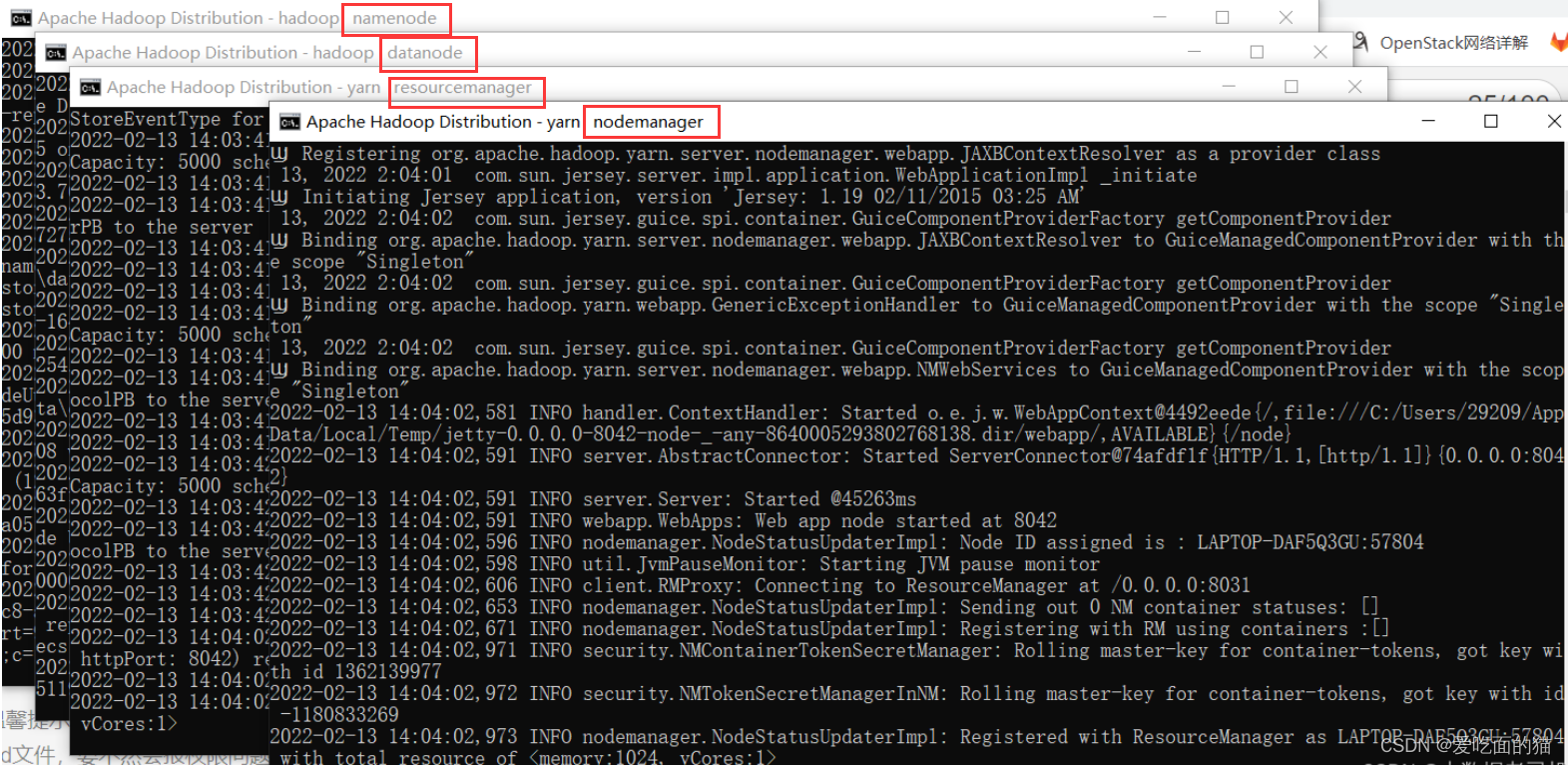
8)验证
hdfs web 地址:http://localhost:9870/
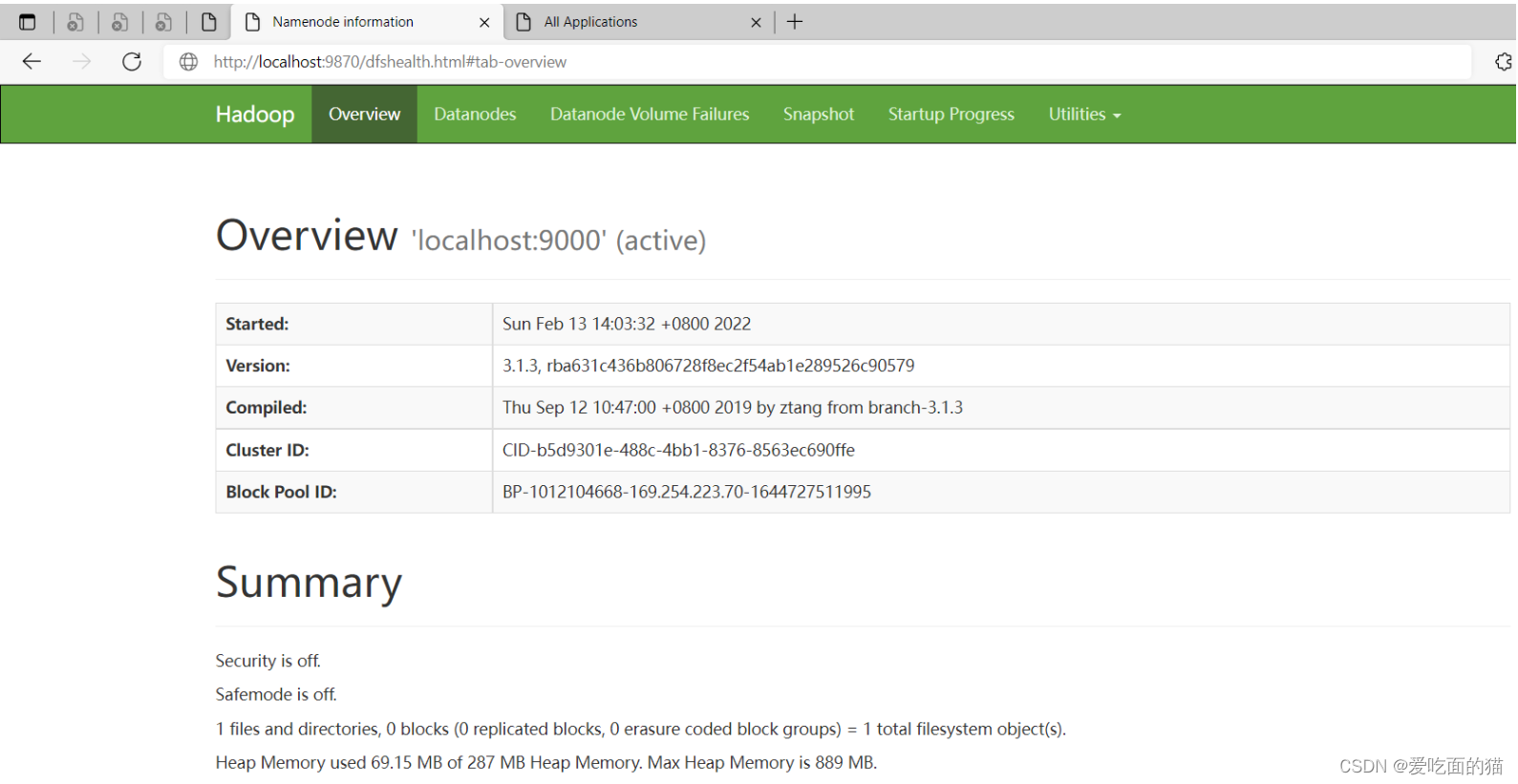
yarn web 地址:http://localhost:8088/

到此为止window版本的hadoop就安装成功了
三、安装mysql8.x
上述的 hive初始化是在 mysql安装完成后实现的。
1、下载mysql
官网下载:MySQL :: Download MySQL Community Server
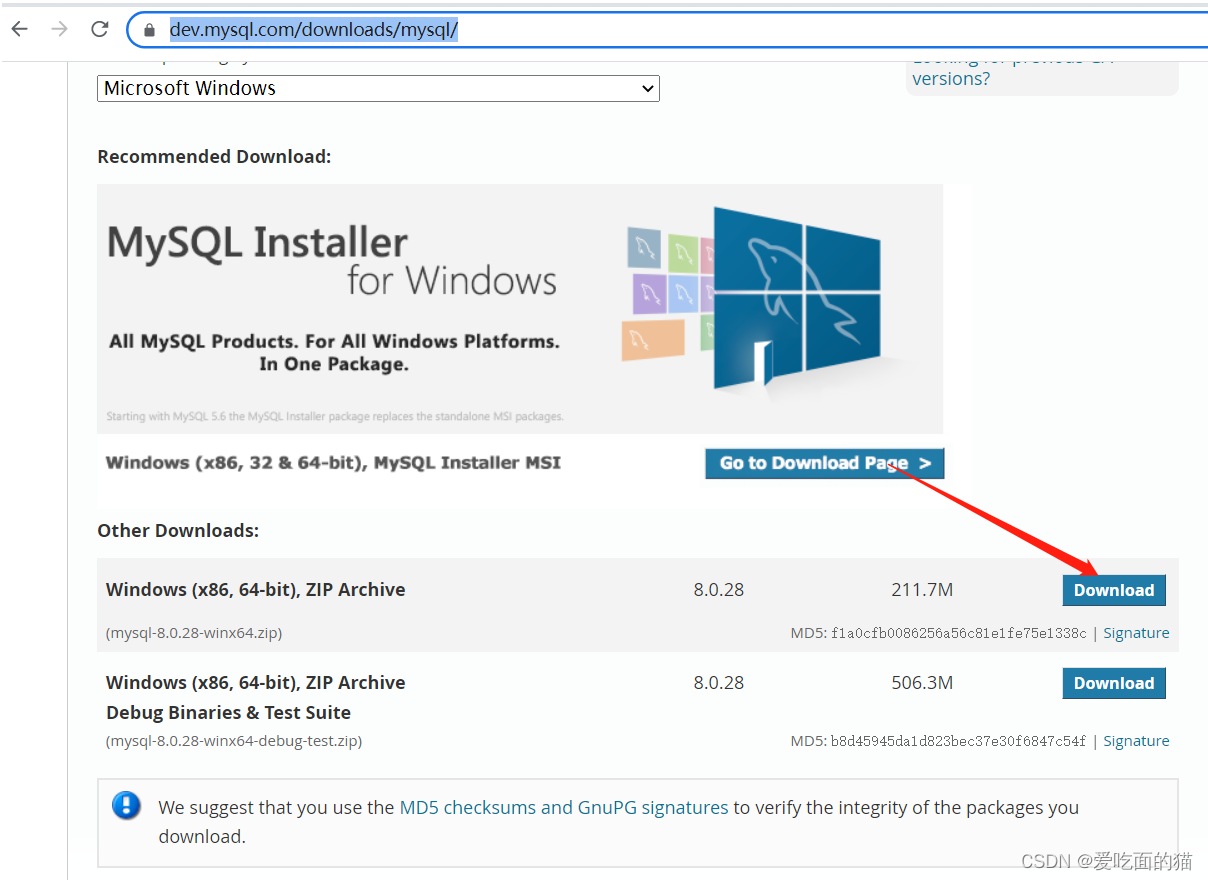
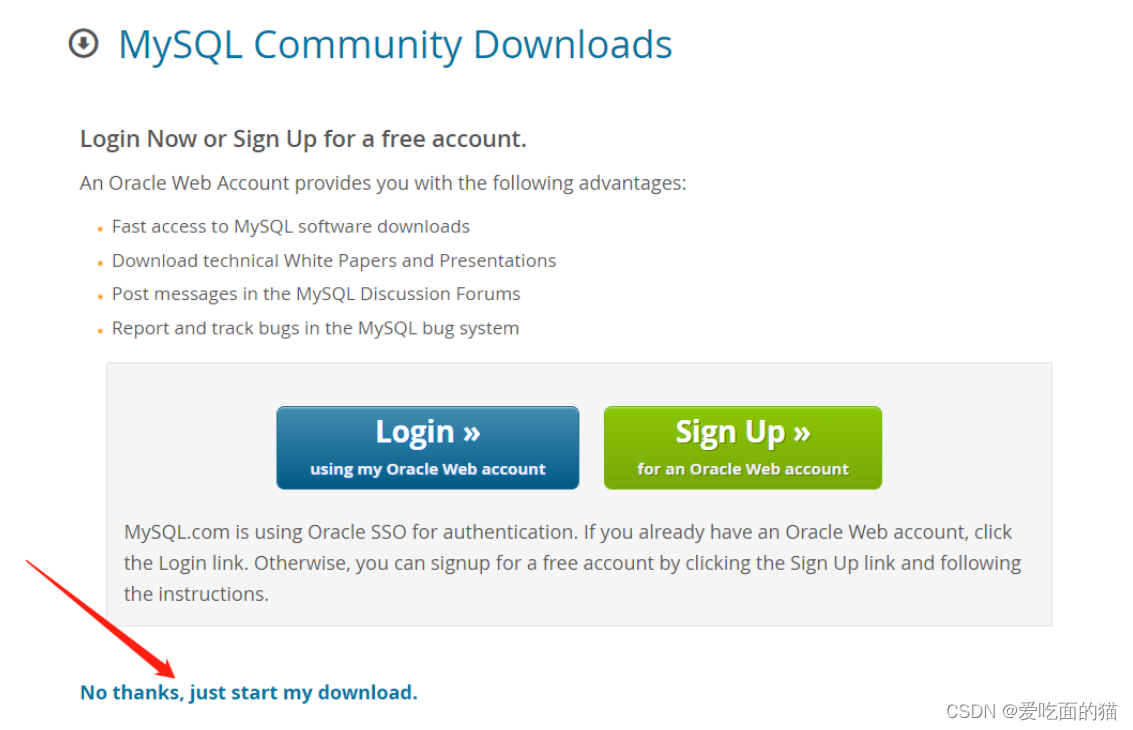
2、配置mysql环境变量
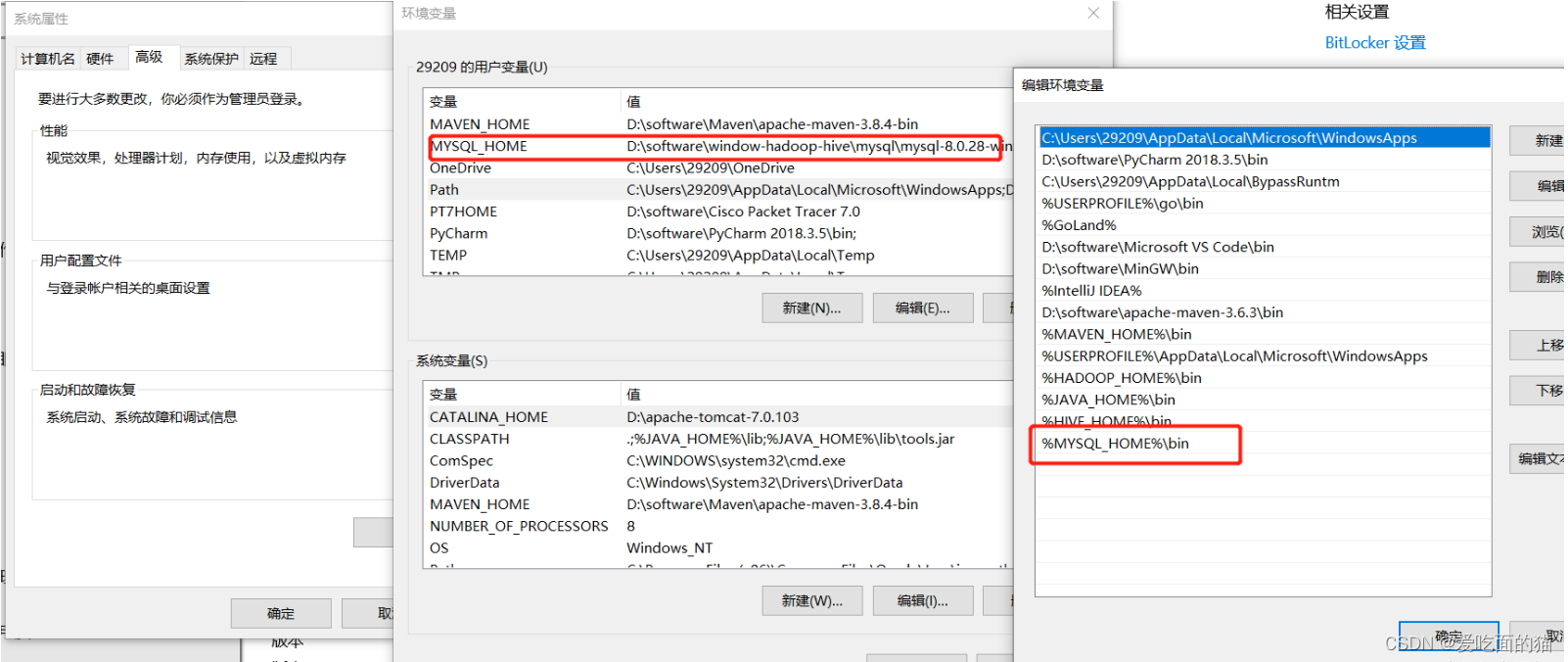
3、初始化mysql
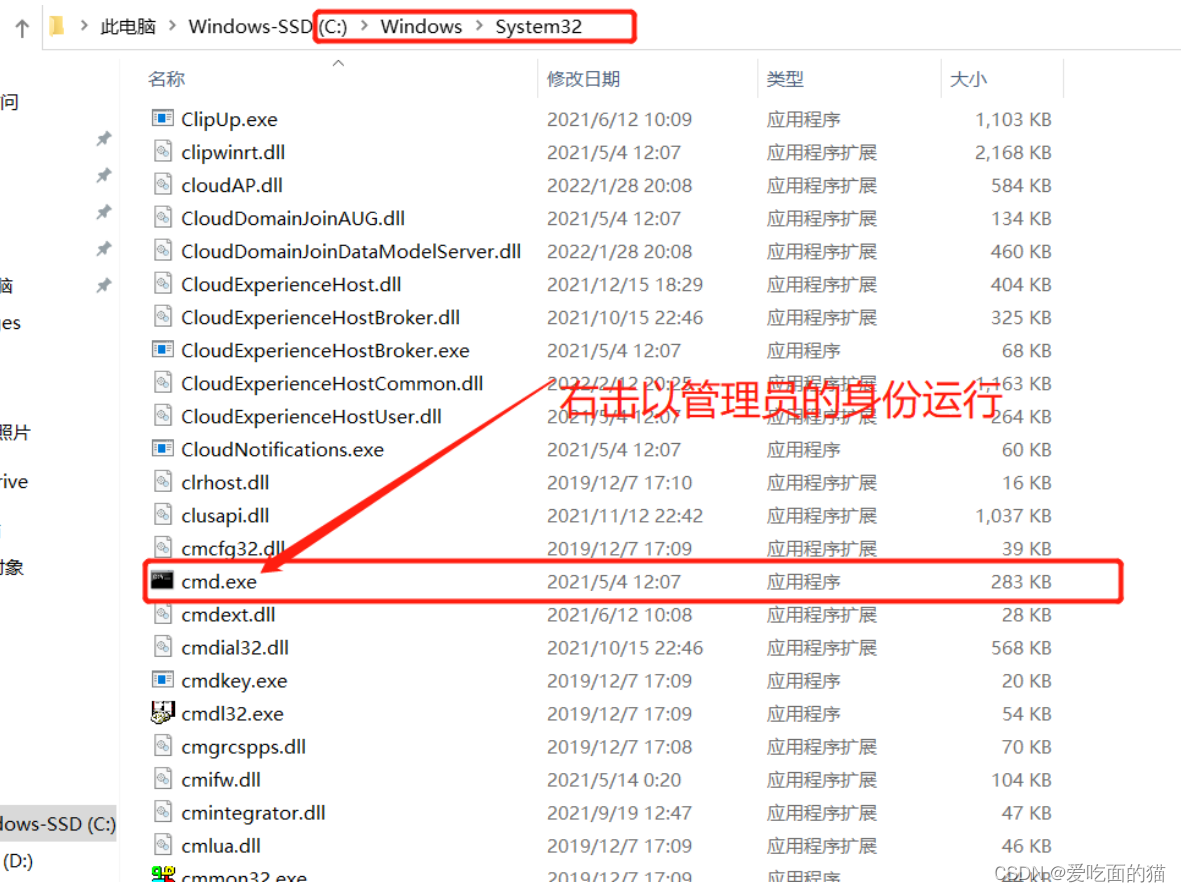
【温馨提示】右键以管理员身份运行cmd,否则在安装时会报权限的错,会导致安装失败的情况。
- # 切换到mysql bin目录下执行
- # cd D:\software\window-hadoop-hive\mysql\mysql-8.0.28-winx64\bin
- # d:
- $ mysqld --initialize --console
4、安装mysql服务
$ mysqld --install mysql
5、通过命令启动服务
$ net start mysql
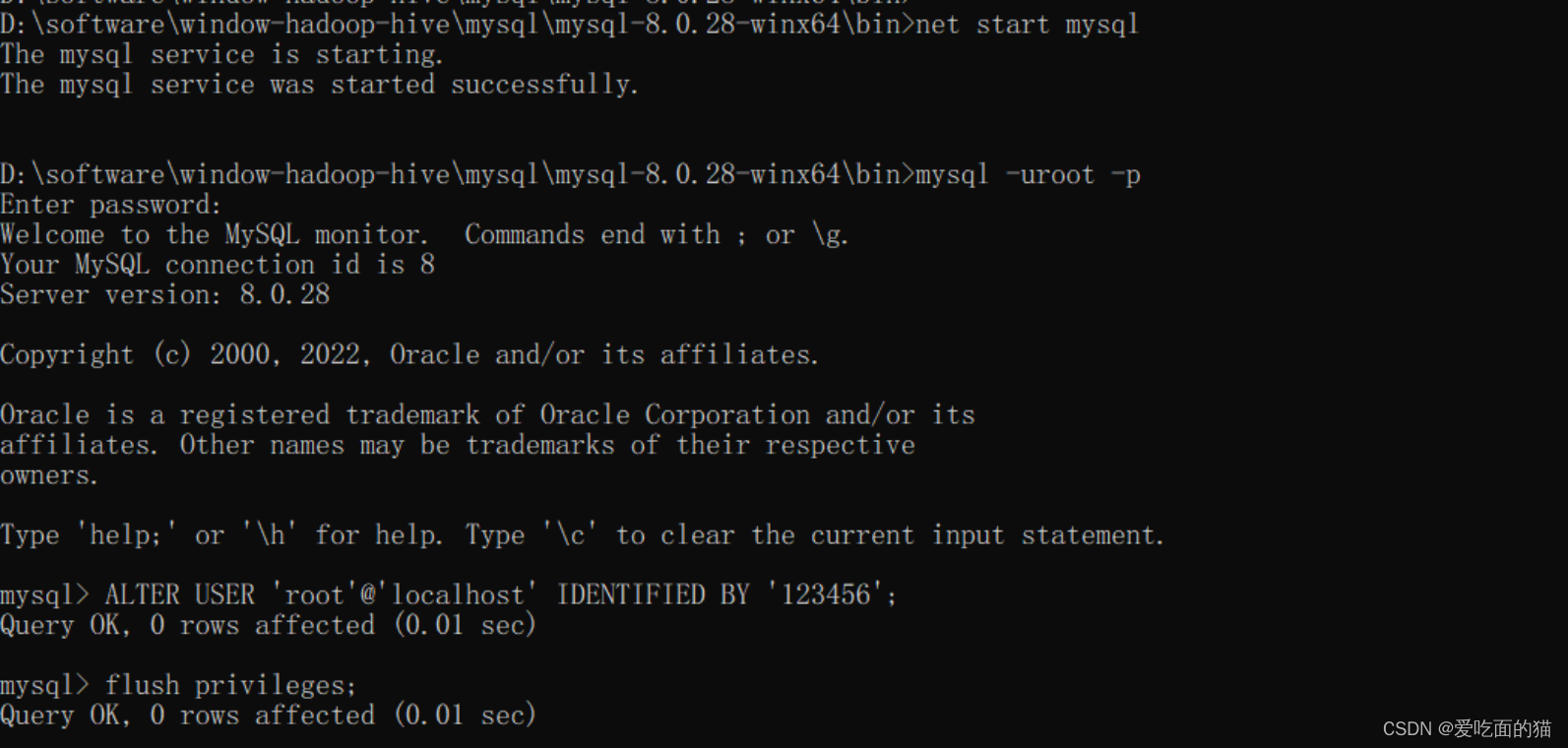
6、通过mysql客户端登录验证并修改root密码
- $ mysql -uroot -p
- #输入上面初始化的密码
8、重置mysql root密码(命令行都要以管理员运行 )
-
停止mysql服务
$ net stop mysql-
启动MySQL服务的时候跳过权限表认证
$ mysqld --console --skip-grant-tables --shared-memory-
在新开的命令行中执行mysql
【温馨提示】由于上面的命令行被mysql的服务给占用,我们得重新开启一个新的命令行
$ mysql-
将root用户的密码清空
$ update user set authentication_string = '' where user='root' ; - quit 退出,然后在之前的命令行将我们开启的mysql服务停止掉(Ctrl+C或者关闭命令行),然后执行net start mysql 重新启动mysql服务
$ net start mysql- 在我们之后开启的命令行中输入mysql -uroot -p 然后按enter键,输入密码继续按enter键(这里密码已经被清空)
$ mysql -uroot -p- 修改密码
- ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
- FLUSH PRIVILEGES;
【问题】如果mysql工具出现错误:
Authentication plugin 'caching_sha2_password' cannot be loaded
【原因】
很多用户在使用Navicat Premium 12连接MySQL数据库时会出现Authentication plugin ‘caching_sha2_password’ cannot be loaded的错误。
出现这个原因是mysql8 之前的版本中加密规则是mysql_native_password,而在mysql8之后,加密规则是caching_sha2_password, 解决问题方法有两种,一种是升级navicat驱动,一种是把mysql用户登录密码加密规则还原成mysql_native_password.
【解决】
# 管理员权限运行命令
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
FLUSH PRIVILEGES;
- 退出后,使用新密码登录
$ mysql -uroot -p四、Hive安装(window10环境)
1)下载Hive
各版本下载地址:Index of /dist/hive
这选择最新版本
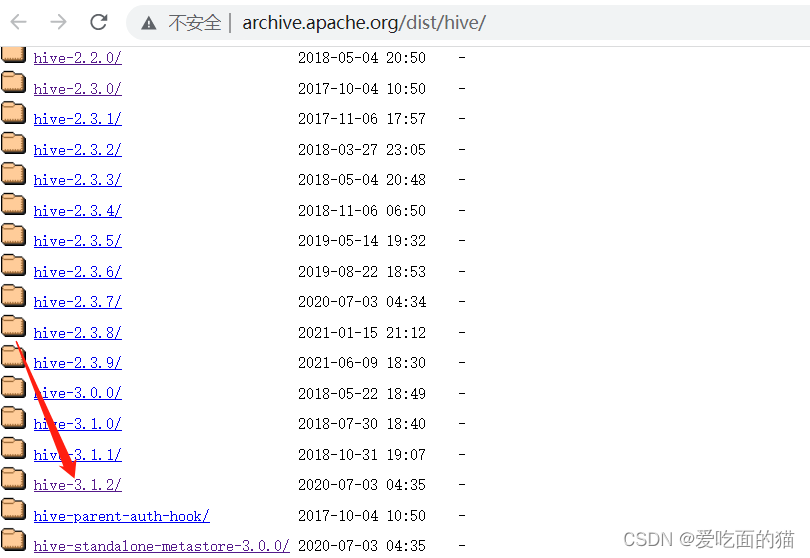
hive 3.1.2版本下载地址:http://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
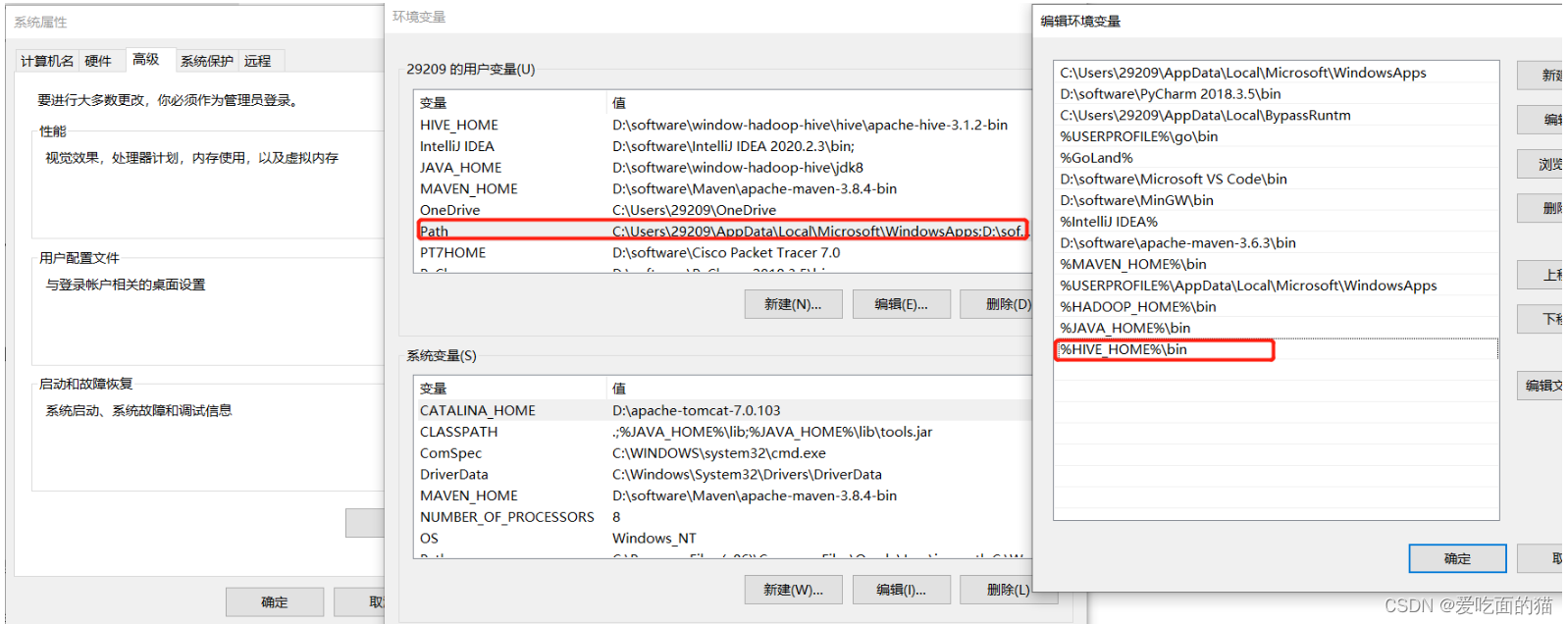
2)Hive配置环境变量
3)新建本地目录(后面配置文件会用到)
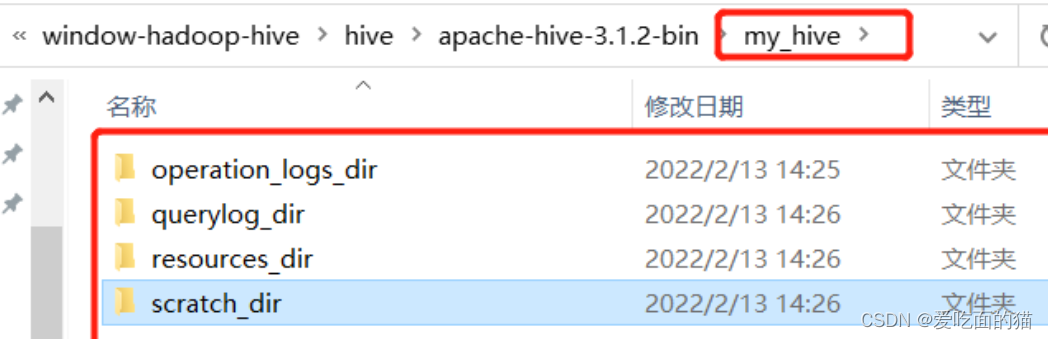
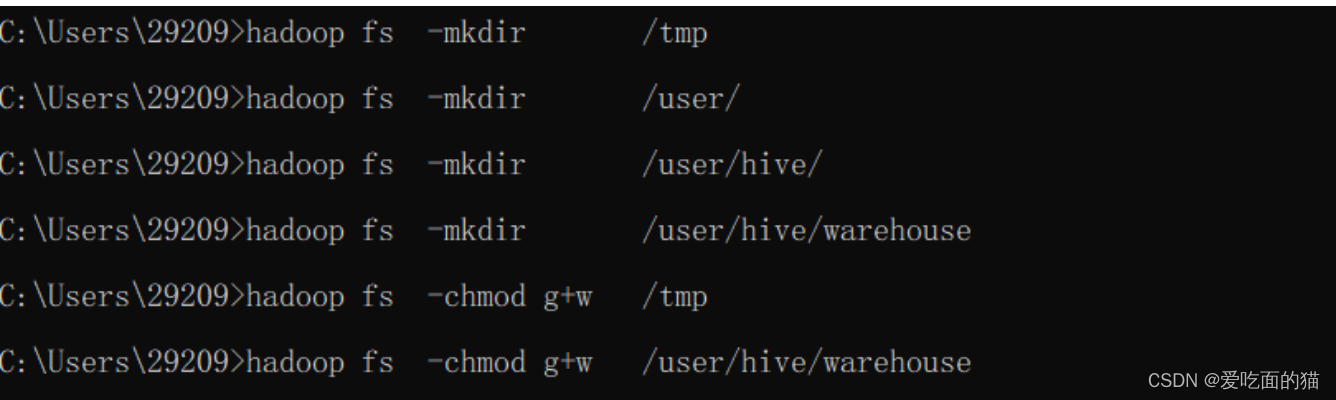
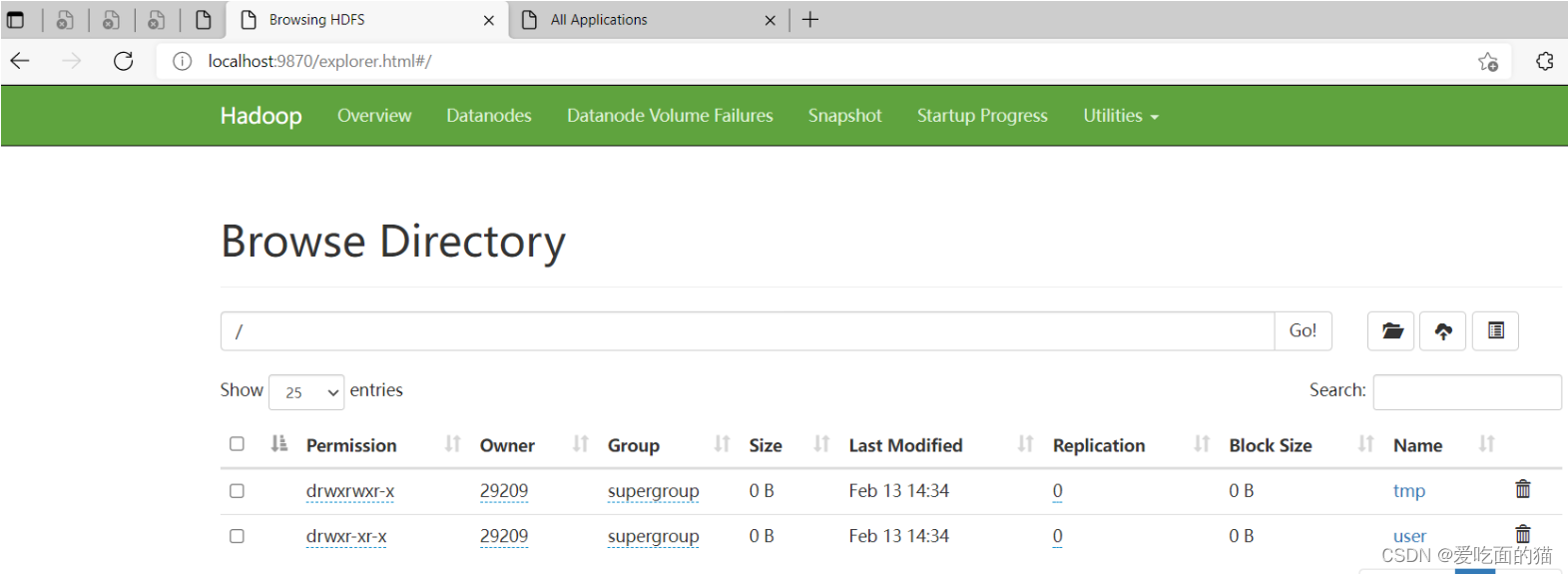
4)在hadoop上创建hdfs目录(后面配置文件会用到)
- $ hadoop fs -mkdir /tmp
- $ hadoop fs -mkdir /user/
- $ hadoop fs -mkdir /user/hive/
- $ hadoop fs -mkdir /user/hive/warehouse
- $ hadoop fs -chmod g+w /tmp
- $ hadoop fs -chmod g+w /user/hive/warehouse
5)修改Hive 配置文件
配置文件目录hive\apache-hive-3.1.2-bin\conf中4个默认的配置文件模板拷贝成新的文件名
hive-default.xml.template -----> hive-site.xml
hive-env.sh.template -----> hive-env.sh
hive-exec-log4j.properties.template -----> hive-exec-log4j2.properties
hive-log4j.properties.template -----> hive-log4j2.properties
1、hive-site.xml 文件:配置文件内容如下
- <?xml version="1.0" encoding="UTF-8" standalone="no"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
-
- <configuration>
-
- <!--hive的临时数据目录,指定的位置在hdfs上的目录-->
- <property>
- <name>hive.metastore.warehouse.dir</name>
- <value>/user/hive/warehouse</value>
- <description>location of default database for the warehouse</description>
- </property>
-
- <!--hive的临时数据目录,指定的位置在hdfs上的目录-->
- <property>
- <name>hive.exec.scratchdir</name>
- <value>/tmp/hive</value>
- <description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
- </property>
-
- <!-- scratchdir 本地目录 -->
- <property>
- <name>hive.exec.local.scratchdir</name>
- <value>F:/bigdata/apache-hive/my_hive/scratch_dir</value>
- <description>Local scratch space for Hive jobs</description>
- </property>
-
- <!-- resources_dir 本地目录 -->
- <property>
- <name>hive.downloaded.resources.dir</name>
- <value>F:/bigdata/apache-hive/my_hive/resources_dir/${hive.session.id}_resources</value>
- <description>Temporary local directory for added resources in the remote file system.</description>
- </property>
-
- <!-- querylog 本地目录 -->
- <property>
- <name>hive.querylog.location</name>
- <value>F:/bigdata/apache-hive/my_hive/querylog_dir</value>
- <description>Location of Hive run time structured log file</description>
- </property>
-
- <!-- operation_logs 本地目录 -->
- <property>
- <name>hive.server2.logging.operation.log.location</name>
- <value>F:/bigdata/apache-hive/my_hive/operation_logs_dir</value>
- <description>Top level directory where operation logs are stored if logging functionality is enabled</description>
- </property>
-
- <!-- 数据库连接地址配置 -->
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://localhost:3306/hive?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true</value>
- <description>
- JDBC connect string for a JDBC metastore.
- </description>
- </property>
-
- <!-- 数据库驱动配置 -->
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.cj.jdbc.Driver</value>
- <description>Driver class name for a JDBC metastore</description>
- </property>
-
- <!-- 数据库用户名 -->
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>root</value>
- <description>Username to use against metastore database</description>
- </property>
-
- <!-- 数据库访问密码 -->
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>root</value>
- <description>password to use against metastore database</description>
- </property>
-
- <!-- 解决 Caused by: MetaException(message:Version information not found in metastore. ) -->
- <property>
- <name>hive.metastore.schema.verification</name>
- <value>false</value>
- <description>
- Enforce metastore schema version consistency.
- True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
- schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
- proper metastore schema migration. (Default)
- False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
- </description>
- </property>
-
- <!-- 自动创建全部 -->
- <!-- hive Required table missing : "DBS" in Catalog""Schema" 错误 -->
- <property>
- <name>datanucleus.schema.autoCreateAll</name>
- <value>true</value>
- <description>Auto creates necessary schema on a startup if one doesn't exist. Set this to false, after creating it once.To enable auto create also set hive.metastore.schema.verification=false. Auto creation is not recommended for production use cases, run schematool command instead.</description>
- </property>
-
-
- <!-- 指定hiveserver2连接的host(hive用户要绑定的网络接口) -->
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>localhost</value>
- <description>Bind host on which to run the HiveServer2 Thrift service.</description>
- </property>
-
- <!-- 指定hiveserver2连接的端口号,hs2端口 默认是10000,为了区别,我这里不使用默认端口-->
- <property>
- <name>hive.server2.thrift.port</name>
- <value>10002</value>
- </property>
-
- <property>
- <name>hive.server2.active.passive.ha.enable</name>
- <value>true</value>
- <description>Whether HiveServer2 Active/Passive High Availability be enabled when Hive Interactive sessions are enabled.This will also require hive.server2.support.dynamic.service.discovery to be enabled.</description>
- </property>
-
-
- </configuration>
2、hive-env.sh 文件:配置文件内容如下
- # Set HADOOP_HOME to point to a specific hadoop install directory
- export HADOOP_HOME=D:\software\window-hadoop-hive\hadoop\hadoop-3.1.3
-
- # Hive Configuration Directory can be controlled by:
- export HIVE_CONF_DIR=D:\software\window-hadoop-hive\hive\apache-hive-3.1.2-bin\conf
-
- # Folder containing extra libraries required for hive compilation/execution can be controlled by:
- export HIVE_AUX_JARS_PATH=D:\software\window-hadoop-hive\hive\apache-hive-3.1.2-bin\lib
6)替换hvie中的bin目录
【温馨提示】2.2.0版本之后就不提供cmd相关文件了,所以得去下载apache-hive-2.2.0-src.tar.gz,把这个版本里的bin目录文件替换到hive安装bin目录下。
下载:apache-hive-2.2.0-src.tar.gz
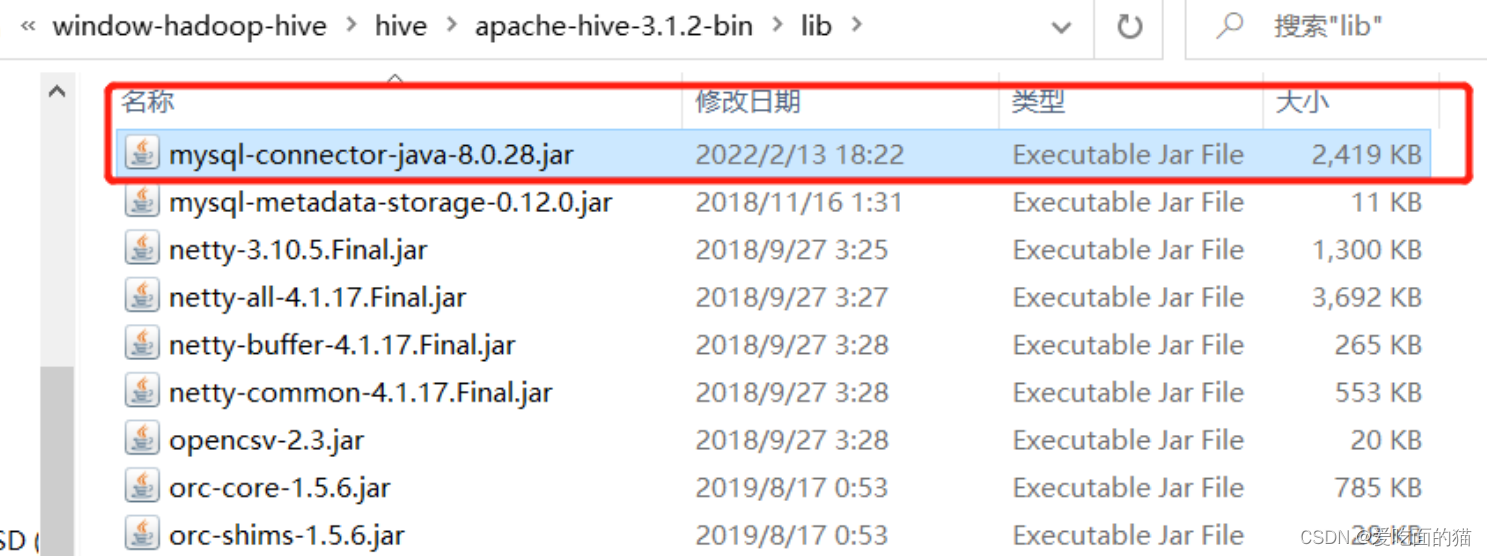
7)下载mysql-connector-java-*.jar
这里将mysql-connector-java-*.jar拷贝到hvie安装目录lib下
下载地址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.28/mysql-connector-java-8.0.28.jar
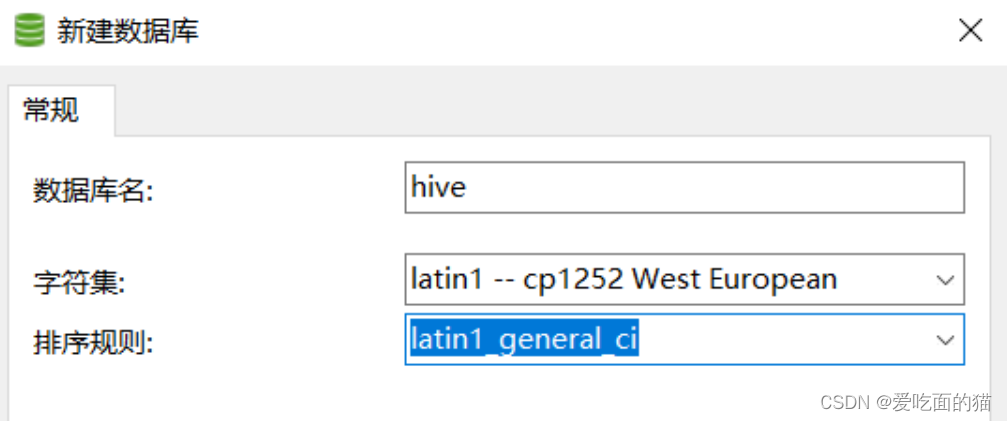
8)创建Hive 初始化依赖的数据库hive,注意编码格式:latin1
在 mysql 数据库中创建 hive 数据库,名称就是 hive,编码 latin1
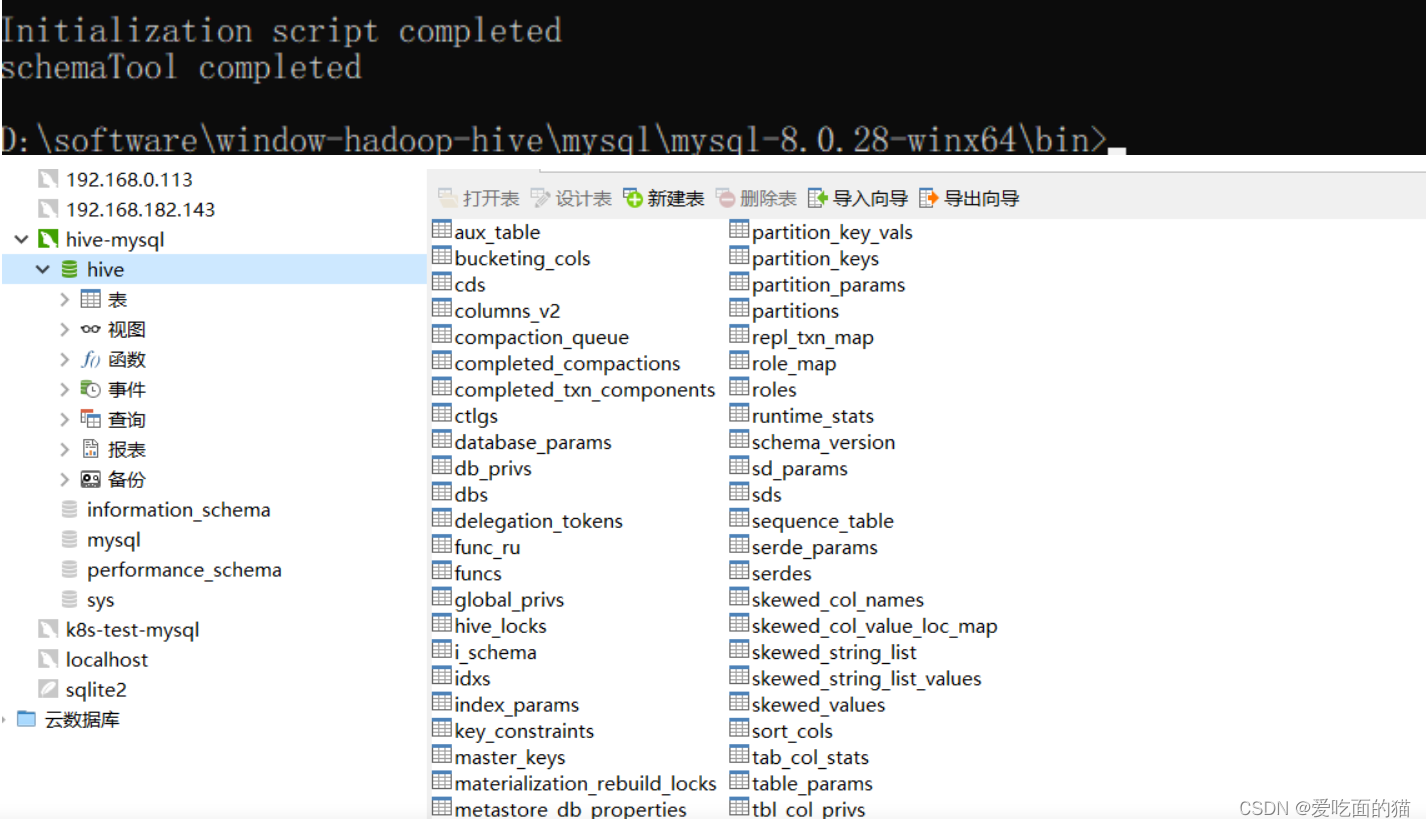
9)Hive 初始化数据
默认已经安装mysql8.0(见下面mysql安装)
- # 在hive的bin目录下执行
- $ hive --service schematool -dbType mysql -initSchema
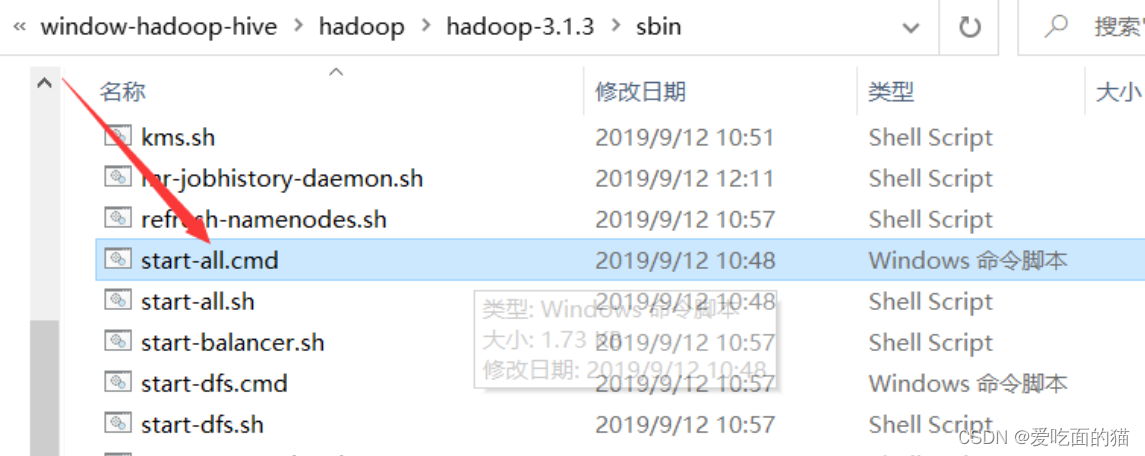
10)启动Hive 服务
1、首先启动Hadoop
在hyadoop安装目录 sbin 下执行指令:stall-all.cmd,上面其实已经验证过了,启动是没问题的。
2、再启动Hive 服务
默认已经安装mysql8.0(见下面mysql安装)
$ hive --service metastore
3、验证
另起一个cmd窗口验证
$ hive
create databases test;
show databases;
11)配置beeline
1、添加beeline配置
【温馨提示】hive命令会慢慢不再使用了,以后就用beeline
在Hive服务安装目录的%HIVE_HOME%\conf\hive-site.xml配置文件中添加以下配置:
关于 beeline配置 前面已经配置,下面主要是为了让大家更清楚。
注意:HiveServer2端口 默认是10000,为了区别和不冲突,我这里不使用默认端口,使用10013, 不要使用 10002,这端口是HiveServer2的web UI的端口,否则会报如下端口冲突问题。
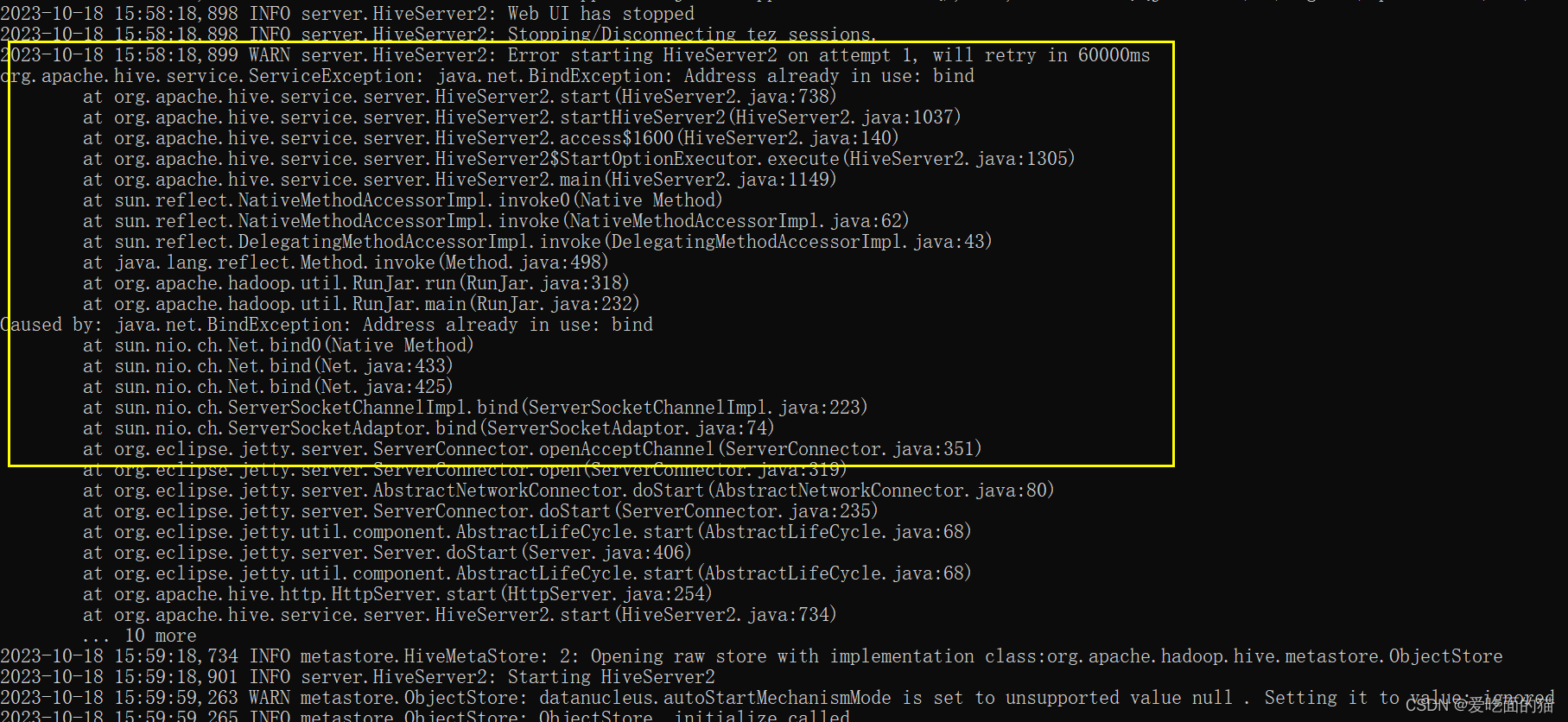
- <!-- host -->
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>localhost</value>
- <description>Bind host on which to run the HiveServer2 Thrift service.</description>
- </property>
-
- <!-- hs2端口 默认是10000,为了区别和不冲突,我这里不使用默认端口,使用10013
- 不要使用 10002,这端口是HiveServer2的web UI的端口
- -->
- <property>
- <name>hive.server2.thrift.port</name>
- <value>10013</value>
- </property>
在Hadoop服务安装目录的%HADOOP_HOME%\etc\hadoop\core-site.xml配置文件中添加以下配置:
- <property>
- <name>hadoop.proxyuser.29209.hosts</name>
- <value>*</value>
- </property>
- <property>
- <name>hadoop.proxyuser.29209.groups</name>
- <value>*</value>
- </property>
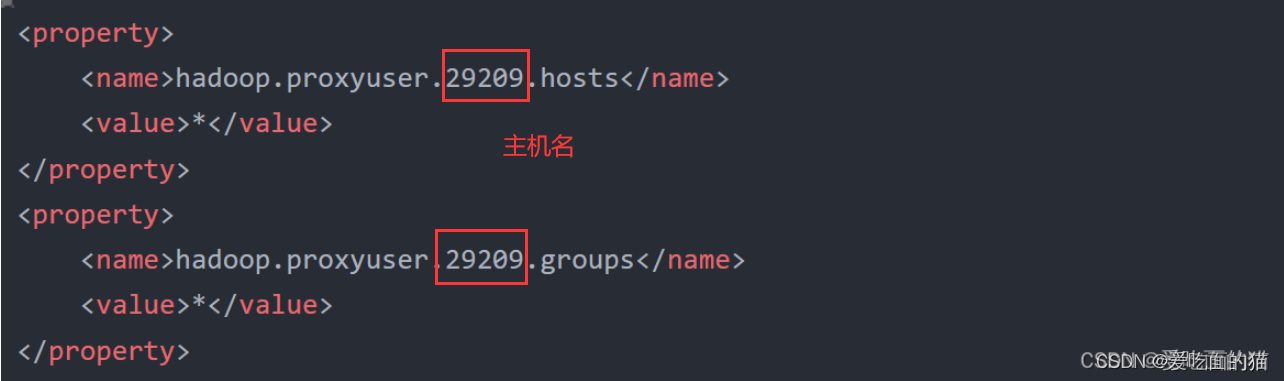
【注意】hadoop.proxyuser.29209.hosts和hadoop.proxyuser.29209.hosts,其中29209是连接beeline的用户,将29209替换成自己的用户名即可,其实这里的用户就是我本机的用户,也是上面创建文件夹的用户,这个用户是什么不重要,它就是个超级代理。
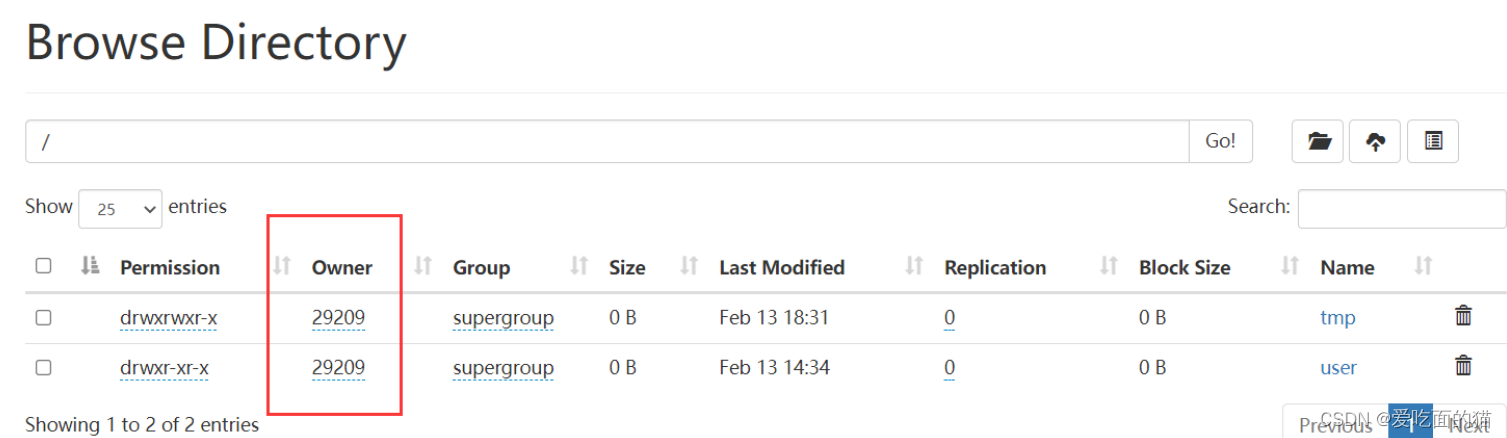
2、启动hiveserver2
启动hiveserver2 之前必须重启hive服务
- $ hive --service metastore
- $ hive --service hiveserver2
【问题】java.lang.NoClassDefFoundError: org/apache/tez/dag/api/SessionNotRunning
【解决】在hive 配置文件hive-site.xml添加如下配置:
- <property>
- <name>hive.server2.active.passive.ha.enable</name>
- <value>true</value>
- <description>Whether HiveServer2 Active/Passive High Availability be enabled when Hive Interactive sessions are enabled.This will also require hive.server2.support.dynamic.service.discovery to be enabled.</description>
- </property>
重启hiveserver2
- $ hive --service metastore
- $ hive --service hiveserver2
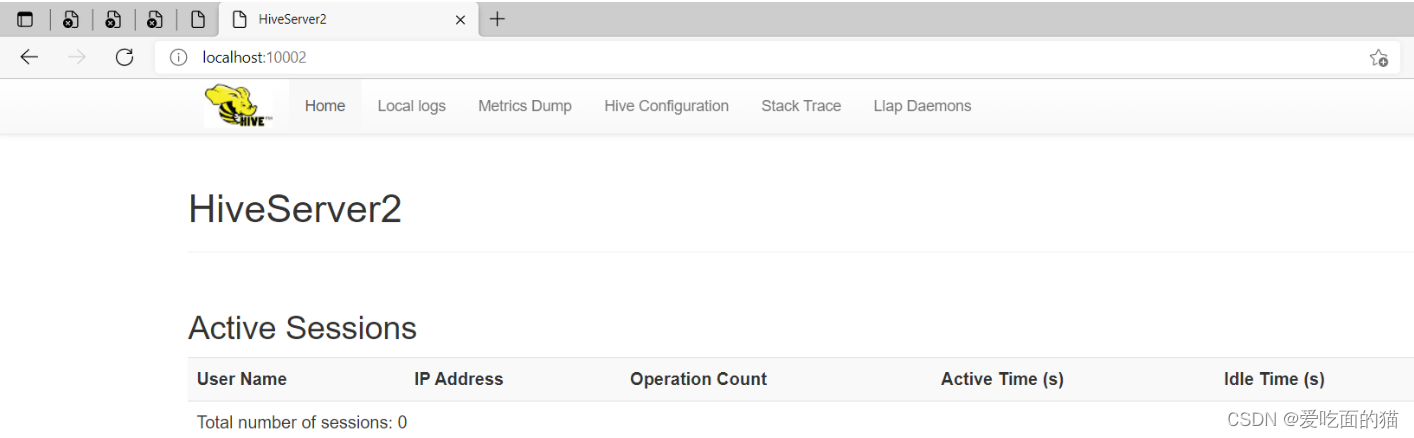
HiveServer2 web:http://localhost:10002/
3、beeline客户端登录
$ beeline【问题一】Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hive/jdbc/JdbcUriParseException
【解决】Hadoop缺少hive-jdbc-***.jar,将Hive安装目录下的lib文件夹中的hive-jdbc-3.1.2.jar包复制到Hadoop安装目录\share\hadoop\common\lib下

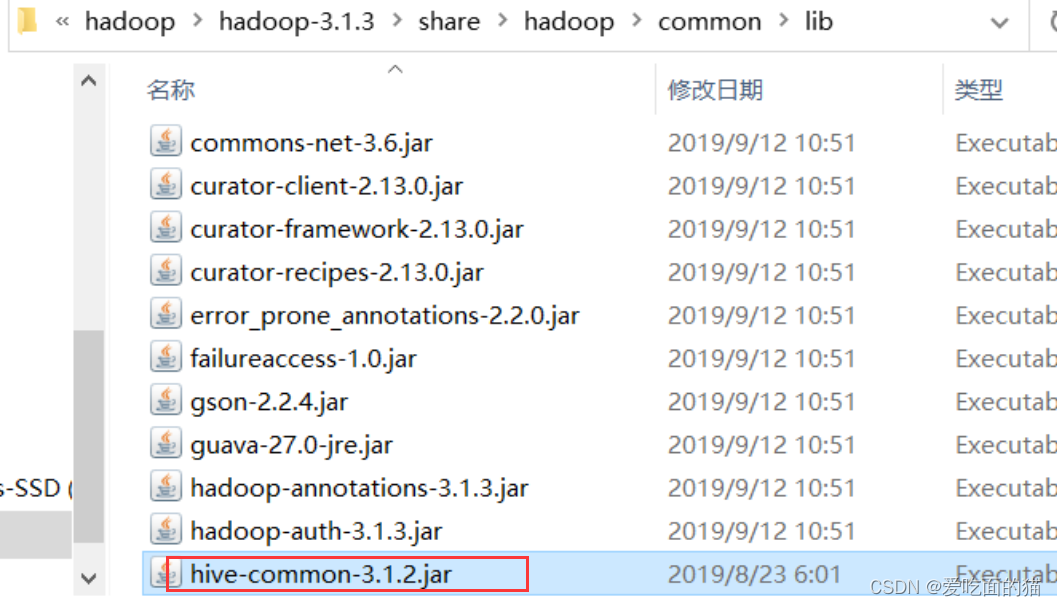
【问题二】Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConf
【解决】Hive安装目录下,将hive-common-3.1.2.jar复制到Hadoop安装目录的\share\hadoop\common\lib下
- $ beeline
- !connect jdbc:hive2://localhost:10001
- 29209
- # 下面这句跟上面等价,都可以登录
- $ %HIVE_HOME%\bin\beeline.cmd -u jdbc:hive2://localhost:10001 -n 29209
【问题三】Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hive/service/cli/HiveSQLException。
【解决】把Hive安装目录下,将hive-service-3.1.2.jar复制到Hadoop安装目录的\share\hadoop\common\lib下。
再重启登录
- $ hive --service metastore
- $ hive --service hiveserver2
- # %HIVE_HOME%\bin\beeline.cmd -u jdbc:hive2://localhost:10001 -n hadoop超级用户名
- # hadoop超级用户名: hdfs中core-site.xml配置的 29209 ,如下图
- $ %HIVE_HOME%\bin\beeline.cmd -u jdbc:hive2://localhost:10001 -n 29209
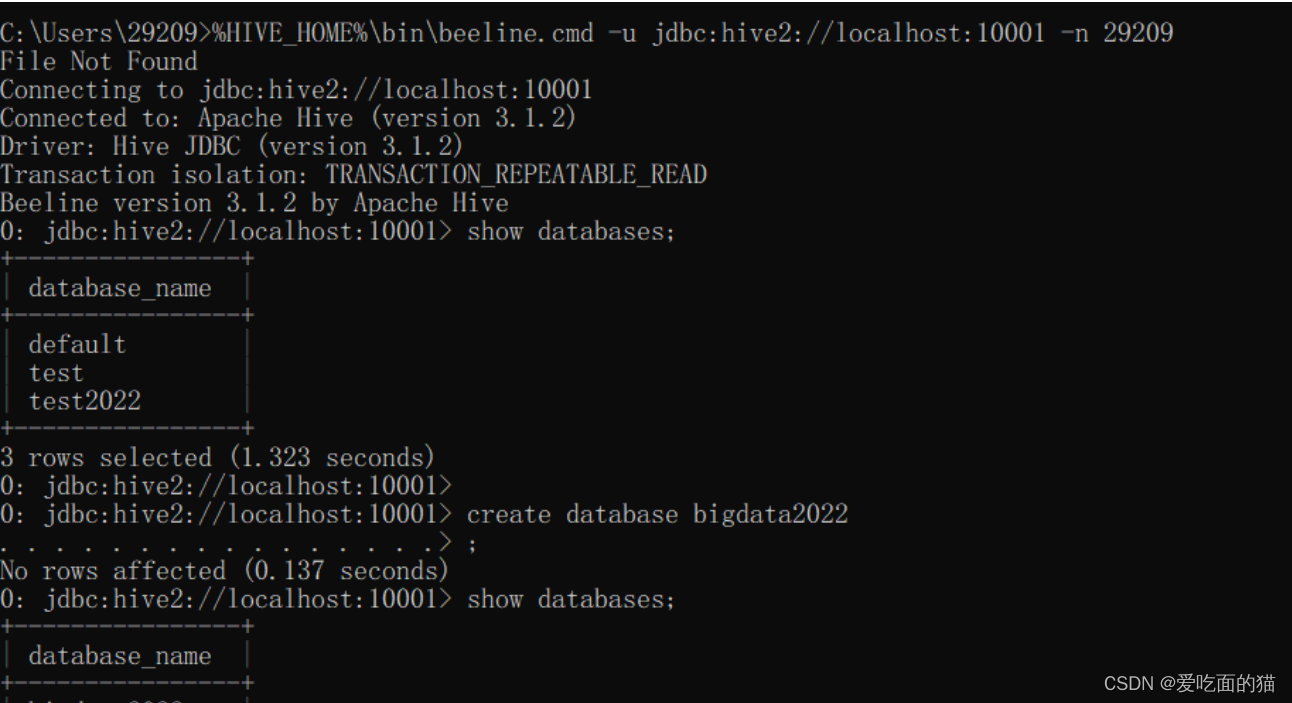
正常登录,一切OK。
- 不允许mysql ...
赞
踩


