- 1Guitarpro 8.1.1.17中文解锁版2024最新安装激活图文教程_guitar pro
- 2把玩Alpine linux(二):APK包管理器_apkindex.tar.gz
- 3HIPAA 与医疗保险公司:合规性的最佳实践
- 4第二阶段1-数据库一(oracle)_oracle 数据库
- 52024杭州华为研究所OD流程亲身经历(1)_华为od几月招人
- 6本地知识库搭建之路:从零到一_maxkb容器端口范围怎么设置
- 7第三方SDK接入--微信_微信第三方平台api sdk
- 8Vuejs+ElementUI搭建后台管理系统框架_element 后台框架
- 9每周算法:无向图的双连通分量
- 10Ubuntu系统上安装Apache和WordPress
阅读理解调研及NLP其它任务转化为MRC参考_mrc任务
赞
踩
阅读理解概述
所谓的机器阅读理解(Machine Reading Comprehension, MRC)就是给定一篇文章,以及基于文章的一个问题, 让机器在阅读文章后对问题进行作答。 机器阅读理解(MRC)是一项任务,用于测试机器通过要求机器根据给定的上下文回答问题来理解自然语言的程度。 早期的MRC系统是基于规则的,性能非常差。随着深度学习和大规模数据集的兴起,基于深度学习的MRC显著优于 基于规则的MRC。
一、机器阅读理解的发展历程 机器阅读理解方法发展阶段: 特征+传统机器学习 BERT以前:各种神奇的QA架构 BERT以后:预训练+微调+trick
二、常见任务定义 MRC 的常见任务主要有六个:完形填空、多项选择、片段抽取(答案抽取)、生成式(自由作答)、会话、多跳推 理: 完形填空(Cloze Tests):将文章中的某些单词隐去,让模型根据上下文判断被隐去的单词最可能是哪个。 多项选 择(Multiple Choice):给定一篇文章和一个问题,让模型从多个备选答案中选择一个最有可能是正确答案的选 项。 片段抽取式(Span Extraction):给定一篇文章和一个问题,让模型从文章中抽取连续的单词序列,并使得该 序列尽可能的作为该问题的答案。 生成式(Free Answering):给定一篇文章和一个问题,让模型生成一个单词序 列,并使得该序列尽可能的作为该问题的答案。与片段抽取任务不同的是,该序列不再限制于是文章中的句子。 会 话:目标与机器进行交互式问答,因此,答案可以是文本自由形式(free-text form),即可以是跨距形式,可以是“不可回 答”形式,也可以是“是/否”形式等等。 多跳推理:问题的答案无法从单一段落或文档中直接获取,而是需要结合多个 段落进行链式推理才能得到答案。因此,机器的目标是在充分理解问题的基础上从若干文档或段落中进行多步推理, 最终返回正确答案。
1 完形填空(Cloze Test)
数据集:CNN & Daily Mail 、CBT、LAMBADA、Who-did-What、CLOTH、CliCR
2 多项选择(Multiple Choice)
数据集:MCTest、RACE
3 片段抽取(Span Extraction)
数据集:SQuAD、NewsQA、TriviaQA、DuoRC
4 自由作答(Free Answering) 对于答案局限于一段上下文是不现实的,为了回答问题,机器需要在多个上下文中进行推理并总结答案。自由回答任 务是四个任务中最复杂的,也更适合现实的应用场景。 数据集:bAbI、MS MARCO 、SearchQA、NarrativeQA、DuReader
三、评价指标(Evaluation Metrics) 对于不同的MRC任务,有不同的评估指标。一般有Accuracy,F1 Score,ROUGE-L,BLEU。
阅读理解模型架构
典型的MRC系统以上下文和问题为输入,然后输入答案,系统包含四个关键模块:Embeddings, Feature Extraction, Context-Question Interaction,Answer Prediction。
Embeddings(嵌入层):将单词映射为对应的词向量,可能还会加上POS、NER、question category等信息;
Feature Extraction(特征提取/编码层):抽取question和context的上下文信息,可以通过CNN、RNN等模型结 构;
Context-Question Interaction(交互层):context和question之间的相关性在预测答案中起着重要作用。有 了这些信息,机器就能够找出context中哪些部分对回答question更为重要。为了实现该目标,在该模块中广泛使用 attention机制,单向或双向,以强调与query相关的context的部分。为了充分提取它们的相关性,context和 question之间的相互作用有时会执行多跳,这模拟了人类理解的重读过程。
Answer Prediction(输出层):基于上 述模块获得的信息输出最终答案。因为MRC任务根据答案形式分为了很多种,所以该模块与不同任务相关。对于完形 填空,该模块输出context中的一个单词或一个实体;对于多项选择,该模块从候选答案中选择正确答案。 阅读理解深度学习模型方法
1.Embeddings模块
将单词转换为对应的向量表示。如何充分编码context和question是本模块中的关键任务。在目前的MRC模型中,词 表示方法可以分为传统的词表示和预训练上下文表示。为了编码更丰富的语义信息,MRC系统在原来的词级别表示的 基础上,还会融合字向量、POS、NER、词频、问题类别等信息。
1.1 传统的词嵌入(Conventional Word Representation)
1.1.1 One-Hot One-Hot:向量长度为词表大小,只有单 词的位置为1,其它全0。 One-Hot 词向量表示方法最大的问题在于这种稀疏向量无法体现任何单词之间的语义相似度信息。
1.1.2 分布式词向 量表示(Distributed Word Representation) 高维映射的词嵌入方法可以有效解决上述One-Hot方法带来的问题, 语义相似的单词可以在几何空间中被编码成距离相近的向量。 词向量能够基于单词的分布式假设,从大规模无标签的文本语料库中学习获得。在机器阅读理解任务中,使用最多的 是 Word2Vec、GloVe 以及 Fasttext 这 3 种单词级别的嵌入模型。 Word2Vec 词向量:该模型具体可以分为连续词袋模型(continuous bag-of-word,简称 CBoW)以及跳跃元语法 模型(skip-gram)两种:前者是从上下文对目标单词的预测中学习词向量;后者则相反,是从目标单词对其上下文 的预测中学习词向量。 GloVe 词向量:GloVe 学习的是词向量的共现概率比值,而不是词本身的出现概率。 Fasttext 词向量:Fasttext 词向量本质上是 Fasttext 快速文本分类算法的副产物,该模型的提出,旨在解决 Word2Vec 和 GloVe 模型忽略单词内部结构,从而导致词的形态学特征缺失的问题。
1.2 基于上下文的预训练词嵌入(Pre-Trained Contextualized Word Representation)
尽管分布式词表示可以在编码低维空间中编码单词,并且反映了不同单词 之间的相关性,但是它们不能有效地挖掘上下文信息。 具体来说,就是分布式词表示在不同上下文中都是一个常量。为了解决这个问题,研究学者提出了上下文的词表示, 在大规模数据集预训练,直接当做传统的词表示来使用或者在特定任务 Fine-tuning。 将词的表征扩展到上下文级别,将每个单词表示为整个输入句子的函数映射,即根据当前的句子来体现一个词在特定 上下文的语境里面该词的语义表示,使其动态地蕴含句子中上下文单词的特征,从而提高模型的性能。 目前较为流行的用于上下文级别嵌入的模型有 CoVe、ELMo 、GPT、BERT等预训练模型。 CoVe:一个单词除了和与之有着语义相似性的单词在向量空间中距离较近以外,还和出现这个单词的句子中的上下 文单词也有着一定的关联。一个句子中的每一个单词应该共享其上下文中其他单词的表征能力,这样可以进一步提升 模型性能。实验表明:将上下文向量与词向量拼接得到新的词嵌入表征,即 w~=[GloVe(w);CoVe(w)] 作为模型的输 入,能进一步提高模型性能。 ELMo:一个好的词嵌入应该包括两个部分:一是包含诸如语法和语义等复杂特征;二 是能够识别这个单词在不同上下文中的不同使用意义,即一词多义的区分;此外词表征应该结合模型的所有内部状 态。实验表明:高层次的 LSTM 倾向于捕捉上下文相关的信息,而低层次的 LSTM 倾向于捕捉语法相关的信息。 ELMo 采用了耦合双向 LSTM 语言模型(biLM)来生成预训练的上下文词向量。 GPT:采用单向的Transformer在大 规模语料上预训练; BERT:ELMo 存在的两个潜在问题:一是 biLM 模型并不是完全双向的,即句子从左到右和从 右到左的 LSTM 过程并不是同时进行的;二是传统语言模型的数学原理决定了它的单向性,对于完全双向的 Bi-LSTM 来说,只要层数增加,就会存在预测单词“自己看见自己”的问题。BERT 预训练模型通过建立双向 Transformer 架 构,加以采用遮蔽语言模型以及连续句子预测来解决上述问题该模型进一步增强了词向量模型的泛化能力,充分描述 了字符级别、单词级别和句子级别的关系特征。
1.3 字符嵌入
字符嵌入用来获取一个单词在字符级别的向量表示, 采用 char-level 的词向量能够在一定程度上缓解文本中出现未登录词(out-of-vocabulary,简称 OOV)的问题。
1.4 多粒度特征嵌入
(Multiple Granularity) Word2Vec或GloVe预先训练的词级嵌入不能编码丰富的句法和语言信 息,如词性、词缀和语法,这可能不足以进行深入的机器理解。为了将细粒度的语义信息整合到单词表示中,一些研 究人员引入了不同粒度的上下文和问题编码方法。 特征嵌入本质上就是将单词在句子中的一些固有特征表示成低维度的向量,包括单词的位置特征(position)、词性特 征(POS)、命名实体识别特征(NER)、完全匹配特征(em)以及标准化术语频率(NTF)等等,一般会通过拼接 的方式将其与字符嵌入、词嵌入、上下文嵌入一起作为最后的词表征。 Character Embeddings:与词级表示(word-level representations)相比,它们不仅更适合于子词形态的建模,而且 可以缓解词汇表外(OOV)问题。 Part-of-Speech Tags:词性(POS)是一类特殊的语法词汇,如名词、形容词或动 词。在NLP任务中标记POS标签可以说明单词使用的复杂特征,进而有助于消除歧义。为了将POS标签转换成固定长 度的向量,将POS标签作为变量,在训练过程中随机初始化并更新。 Name-Entity Tags:名称实体是信息检索中的 一个概念,是指一个真实世界中的对象,如一个人、一个地点或一个组织,它有一个合适的名称。当询问这些对象 时,名称实体可能是候选答案。因此,嵌入上下文单词的名称实体标记可以提高答案预测的准确性。名称实体标签的 编码方法类似于上述POS标签的编码方法。 Binary Feature of Exact Match (EM):如果context中的一个单词在 query中存在,那么值为1,否则为0; Query-Category:问题的类型(what,where,who,when,why,how)通常可以提 供线索来寻找答案。
2.Feature Extraction(特征提取/编码层)
特征提取模块通常放置在嵌入层之后,分别提取上下文和问题的特征。它进一步关注基于嵌入模块所编码的各种句法 和语言信息在句子层次上挖掘上下文信息。该模块采用了RNNs、CNNs和Transformer architecture。 编码层的目的是将已经表示为词向量的 Tokens(词的唯一标记单位)通过一些复合函数进一步学习其内在的特征与 关联信息。提取特征的本质就是在对样本进行编码。
1. 循环神经网络(RNN/LSTM/GRU) 循环神经网络是神经网络的一种,主要用来处理可变长度的序列数据。不同于前馈神经网络,RNNs 可以利用其内部 的记忆来处理任意时序的输入序列,这使得它更容易处理机器阅读理解数据集中的问题和段落序列。
2 .卷积神经网络(CNN) 使用 RNN 模型对问题 Q 和段落 C 进行编码时,会导致模型训练和推理的速度变得非常缓慢,这使得模型无法应用于 更大的数据集,同时无法应用于实时系统中。 利用 CNN 模型善于提取文本局部特征的优点,同时采用自注意力机制来弥补 CNN 模型无法对句子中单词的全局交 互信息进行捕捉的劣势。
3 .Transformer Transformer是一个强大的神经网络模型,在各种NLP任务中显示出了良好的性能。与基于RNN或cnn的模型相比, 该模型主要基于注意机制,既没有递归,也没有卷积。多个头部的注意力结构不仅在对齐方面有优势,而且可以并行 运行。 与RNNs相比,Transformer需要更少的训练时间,同时它更关注全局依赖性。但是,如果没有递归和卷积,模型就 不能利用序列的位置信息。为了整合位置信息,Transformer添加由正弦和余弦函数计算的位置编码。位置和字嵌入 的总和作为输入。
3.Context-Question Interaction(交互层)
交互层是整个神经阅读理解模型的核心部分,它的主要作用是负责段落与问题之间的逐字交互,从而获取段落(问题) 中的单词针对于问题(段落)中的单词的加权状态,进一步融合已经被编码的段落与问题序列。 通过提取context和question之间的相关性,模型能够找到答案预测的证据。根据模型是如何抽取相关性的方式,目 前的工作可以分为两类,一跳交互和多跳交互。 无论哪种交互方式,在MRC模型中,attention机制在强调context哪部分信息在回答问题方面更重要发挥着关键作 用。 当段落和问题序列通过注意力机制后,神经阅读理解模型就能学习到两者之间单词级别的权重状态,这大大提高了最 后答案预测或生成的准确率。 在机器阅读理解中,attention机制可以分为无向和双向的。
1 .单向注意力机制(Unidirectional Attention) 单向的attention可以关注context中最重要的词来回答问题,但是该方法无法关注对答案预测也至关重要的question 的词。因此,单向的attention不足以抽取context和query之间的交互信息。
2 .双向注意力机制(Bidirectional Attention) 同时计算 query-to-context attention 和 context-to-query attention。
3 .一跳交互(One-Hop Interaction) 单跳交互是一种浅层架构,上下文和问题之间的交互只计算一次。 虽然这种方法可以很好地处理简单的完形填空测试,但当问题需要在上下文中对多个句子进行推理时,这种单跳交互 方法很难预测正确答案。
4 .多跳交互(Multi-Hop Interaction) Multi-Hop Interaction可以记住之前的context和question信息,能够深度提取相关性并聚合答案预测的证据。
4.输出层(Answer Prediction)
该模块基于上述三个模块累积得到的信息进行最终的答案预测。 该模块与任务高度相关,之前我们将MRC分为四类,分别是完形填空、多项选择、片段抽取、自由回答,那么对应的 答案预测方法也有四种,分别是word predictor,option selector,span extractor,answer generator。 输出层主要用来实现答案的预测与生成,根据具体任务来定义需要预测的参数。
1.完形填空任务:
神经阅读理解模型需要从若干个答案选项中选择一项填入问句的空缺部分,因此,模型首先需要计算出段落针对问题 的注意力值,然后通过获取选项集合中候选答案的概率预测出正确答案。
【答案输出是原文中的一个词或实体,一种 做法是将文中相同词的注意力权重得分进行累加,最终选择得分最高的词作为答案】 多项选择任务:神经阅读理解 模型需要从 选项中选出正确答案,因此,模型可以先通过 BiLSTM将每一个答案进行编码,之后相似度对比,预测出 正确的答案。【从多个候选答案中挑选出正确答案,一般是对备选答案进行打分,选择得分最高的候选者作为答案】
2.抽取式任务:
神经阅读理解模型需要从某一段落中找到一个子片段(span or sub-phrase)来回答对应问题,这一片段将会以在段落 中的首尾索引的形式表示,因此,模型需要通过获取起始和结束位置的概率分布来找到对应的索引。
3.生成式任务: 由于答案的形式是自由的(free-form),可能在段落中能找到,也可能无法直接找到而需要模型生成,因此,模型的输 出不是固定形式的,有可能依赖预测起止位置的概率(与抽取式相同),也有可能需要模型产生自由形式的答案。
【对 于自由作答任务,答案灵活度最高,不再限制于原文中,可能需要进行推理归纳,现有的方法常用抽取和生成相结合 的模式。】
4.会话类和多跳推理任务: 由于只是推理过程与抽取式不同,其输出形式基本上与抽取式任务相同,有些数据集还会预测“是/否”、不可回答以 及“能否成为支持证据”的概率。 开放域的阅读理解:由于模型首先需要根据给定问题,从例如 Wikipedia 上检索多个 相关文档(包含多个段落),再从中阅读并给出答案。
机器阅读理解的研究趋势
1. 基于外部知识的机器阅读理解 在人类阅读理解过程中,当有些问题不能根据给定文本进行回答时,人们会利用常识或积累的背景知识进行作答,而 在机器阅读理解任务中却没有很好的利用外部知识。
挑战: (1) 相关外部知识的检索 (2) 外部知识的融合
2. 带有不能回答的问题的机器阅读理解 机器阅读理解任务有一个潜在的假设,即在给定文章中一定存在正确答案,但这与实际应用不符,有些问题机器可能 无法进行准确的回答。这就要求机器判断问题仅根据给定文章能否进行作答,如若不能,将其标记为不能回答,并停 止作答;反之,则给出答案。
挑战: (1) 不能回答的问题的判别 (2) 干扰答案的识别
3. 多文档机器阅读理解 在机器阅读理解任务中,题目都是根据相应的文章进行设计的。而人们在进行问答时,通常先提出一个问题,再利用 相关的可用资源获取回答问题所需的线索。不再仅仅给定一篇文章,而是要求机器根据多篇文章对问题进行作答。
挑战: (1) 相关文档的检索 (2) 噪声文档的干扰 (3) 检索得到的文档中没有答案 (4) 可能存在多个答案 (5) 需要对多条线索进行聚合
4. 对话式阅读理解 当给定一篇文章时,提问者先提出一个问题,回答者给出答案,之后提问者再在回答的基础上提出另一个相关的问 题,多轮问答对话可以看作是上述过程迭代进行多次。
挑战: (1) 对话历史信息的利用 (2) 指代消解
----------------------------------------以上来自网上文献------------------------------------------------------------------------但是大框架都是来自paper《Shanshan Liu et al. Neural Machine Reading Comprehension: Methods and Trends. Applied Sciences 2019》---------------------------------------------------------------‘
我自己再补充点把NLP任务当成MRC任务的paper例子:是从我ppt直接截图吧。
一、NER->MRC
《A Unified MRC Framework for Named Entity Recognition》(2020)
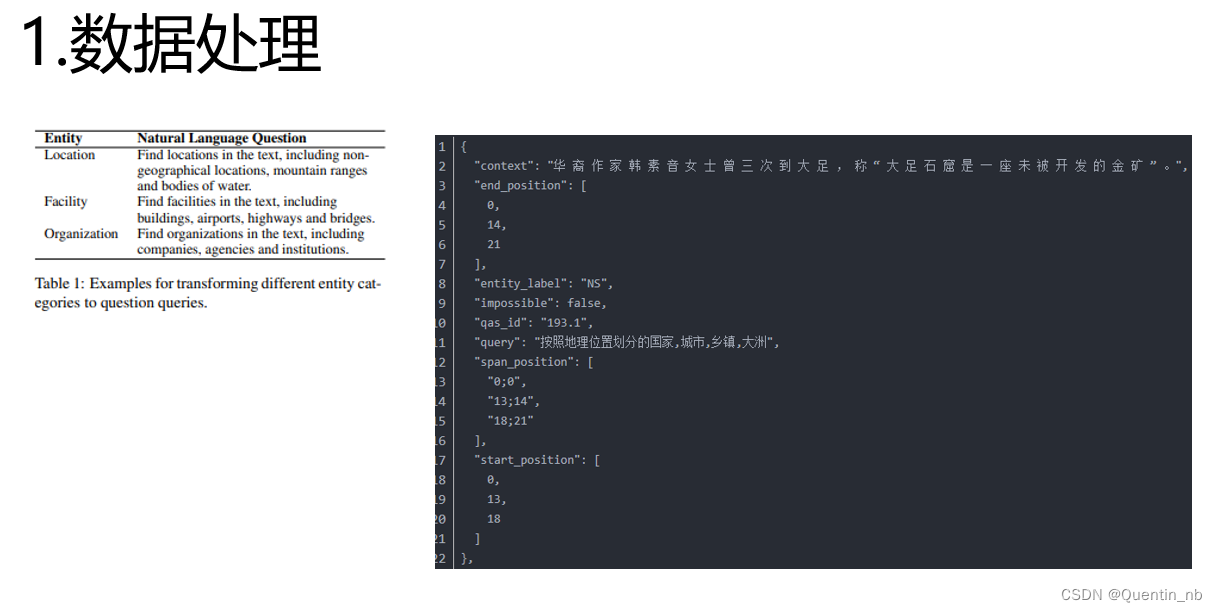

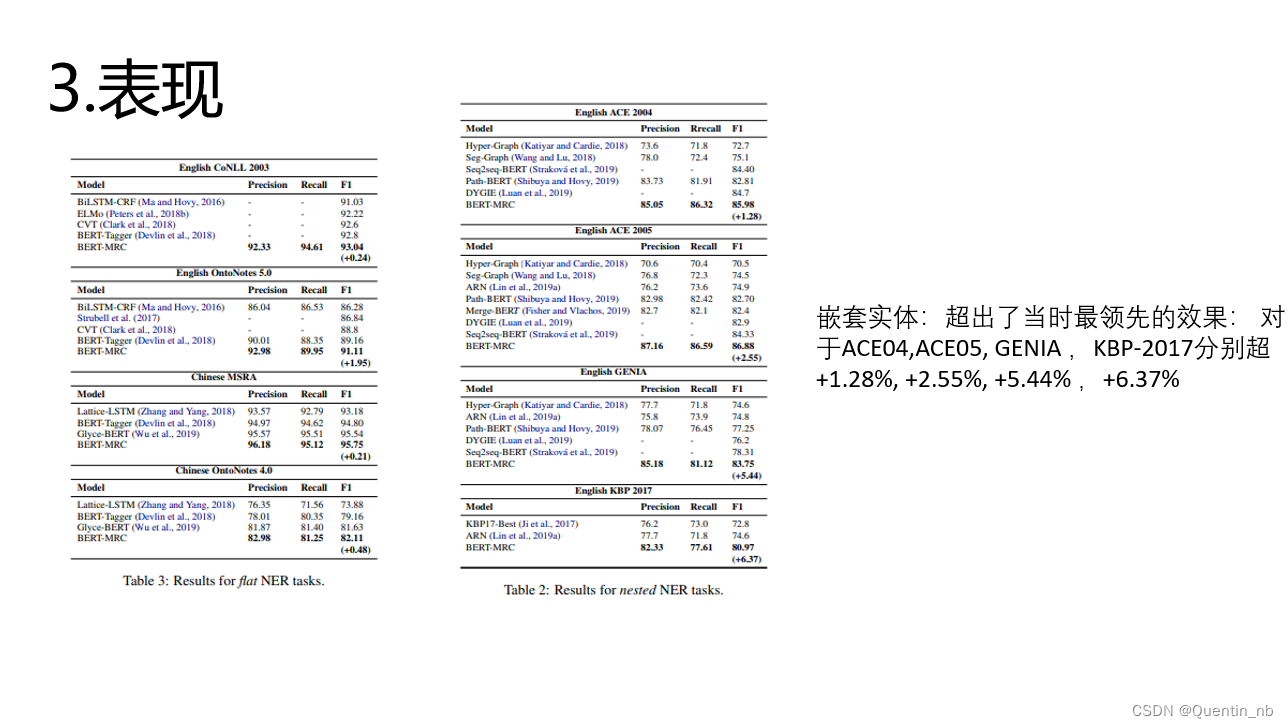
二、RE->MRC
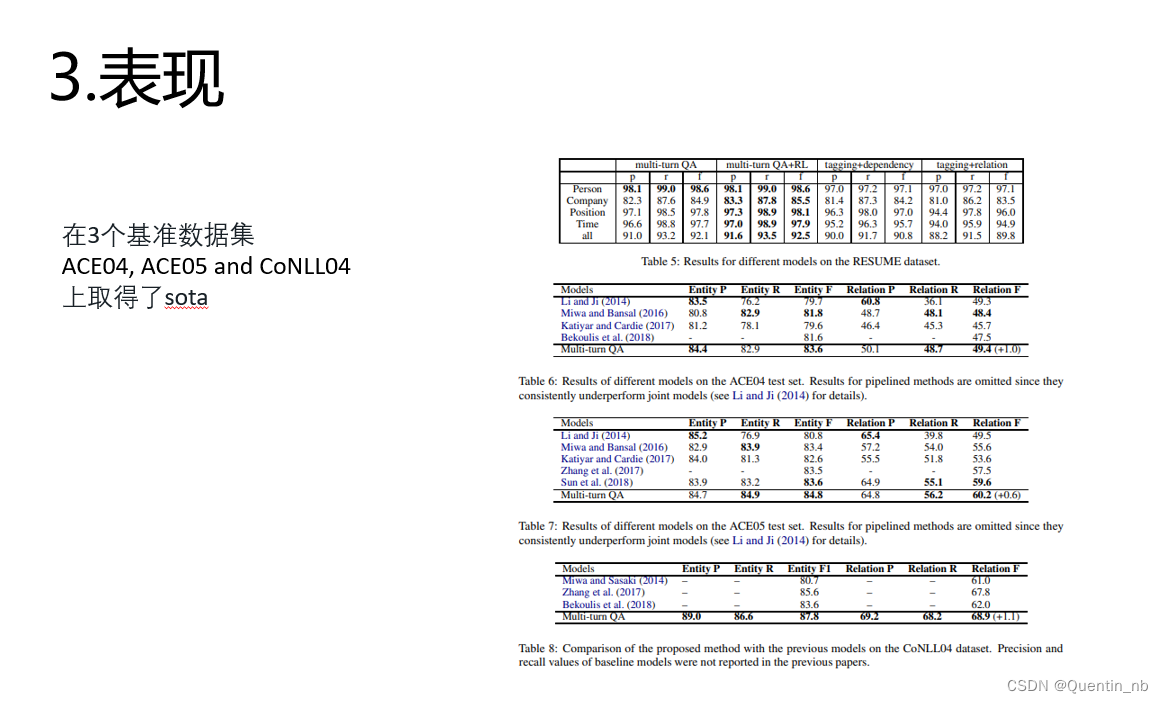
《Entity-relation extraction as multi-turn question answering》(2019)