
- 1Xcode中Command Line Tools安装方法_error: you dont have xcode command line tools, but
- 2php 网站打包app,利用cordova将网站封装成app
- 3Fiddler工具_fiddler抓包灰色锁
- 4SQL Server Len() 函数_sqlserver len
- 5中文字符串--原始_ldapfilter包含中文字符
- 6杭州计算机零基础怎么学呢,我初中毕业想在杭州学一个专业计算机
- 7职高计算机专业能考大学吗,为什么千万不要上职高 上职高能考大学吗
- 8Android屏幕适配5种方式_android屏幕适配的五种方式
- 9御果庄园养殖种植软件开发系统定制
- 10extern,define,typedef_#define extern extern
为什么Apache Doris适合做大数据的复杂计算,MySQL不适合?_doris为什么适合olap
赞
踩
一、背景说明

经常有小伙伴发出这类直击灵魂的疑问:
Q:“为什么Apache Doris适合做大数据的复杂计算,MySQL不适合?”
A:“因为Apache Doris是OLAP,MySQL是OLTP啊!”
Q:“SO?”
A:“因为一个是AP场景的DB,一个是TP场景的DB啊!”
Q:“SO?”
…
[emm] 要不先来简单概述下OLAP和OLTP:
OLAP(Online Analytical Processing,联机分析处理)主要用于大数据场景下复杂的分析查询和决策支持,重点在于数据分析、多维度分析和报表生成。例如,销售数据分析、市场趋势预测、业务报表生成等。
OLTP(Online Transaction Processing,联机事务处理)主要用于处理实时事务和业务操作,重点在于高并发、高可靠性和数据一致性。例如,在线购物、银行交易、航空订票等需要频繁读写小规模数据的场景。
这么一概述,OLAP和OLTP在应用场景和目的上确实有所不同,那么是什么原因导致的呢?
接下来,咱们从OLAP(Apache Doris为例)和OLTP(Mysql为例)的DB架构、数据结构以及存储结构的维度来一探究竟吧!
二、DB架构差异
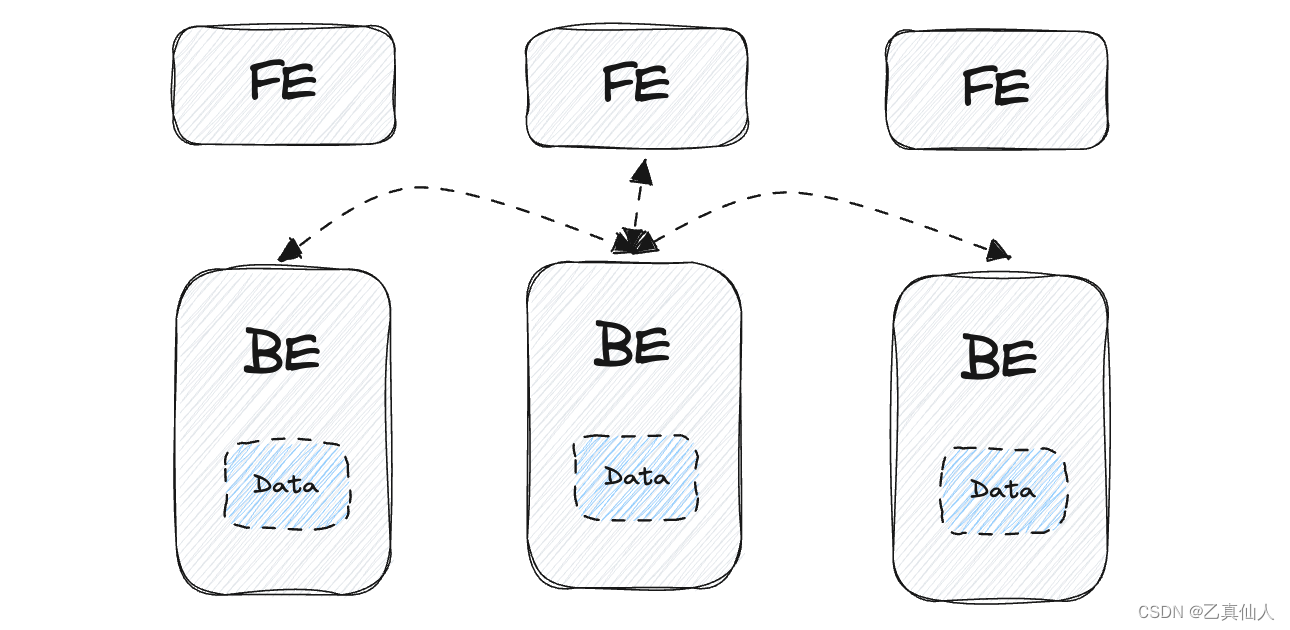
- 数据分布:数据被分割成多个部分,每个BE节点都独立地存储一部分数据,节点之间不共享存储,每个节点独立处理自己所负责的数据。
- 数据处理:每个BE节点都独立地处理自己所负责的数据,节点之间可以并行地进行数据处理,从而提高系统的整体性能。
- 扩展性:更注重水平横向扩展,通过增加更多的节点来分担数据和负载,从而提供更好的可扩展性和负载均衡性能。
- 一致性:通过一致性协议和分布式事务来维护数据的一致性。
Apache Doris 是典型的 Shared Nothing 分布式计算架构,每个BE都有自己的CPU、内存和硬盘等,不存在共享资源。多BE采用MPP(大规模并行处理)模式,各处理单元之间通过协议通信,并行处理和扩展能力更好,为 Apache Doris 带来了高可用、极简部署、横向可扩展以及强大的实时分析性能等一系列核心特色。
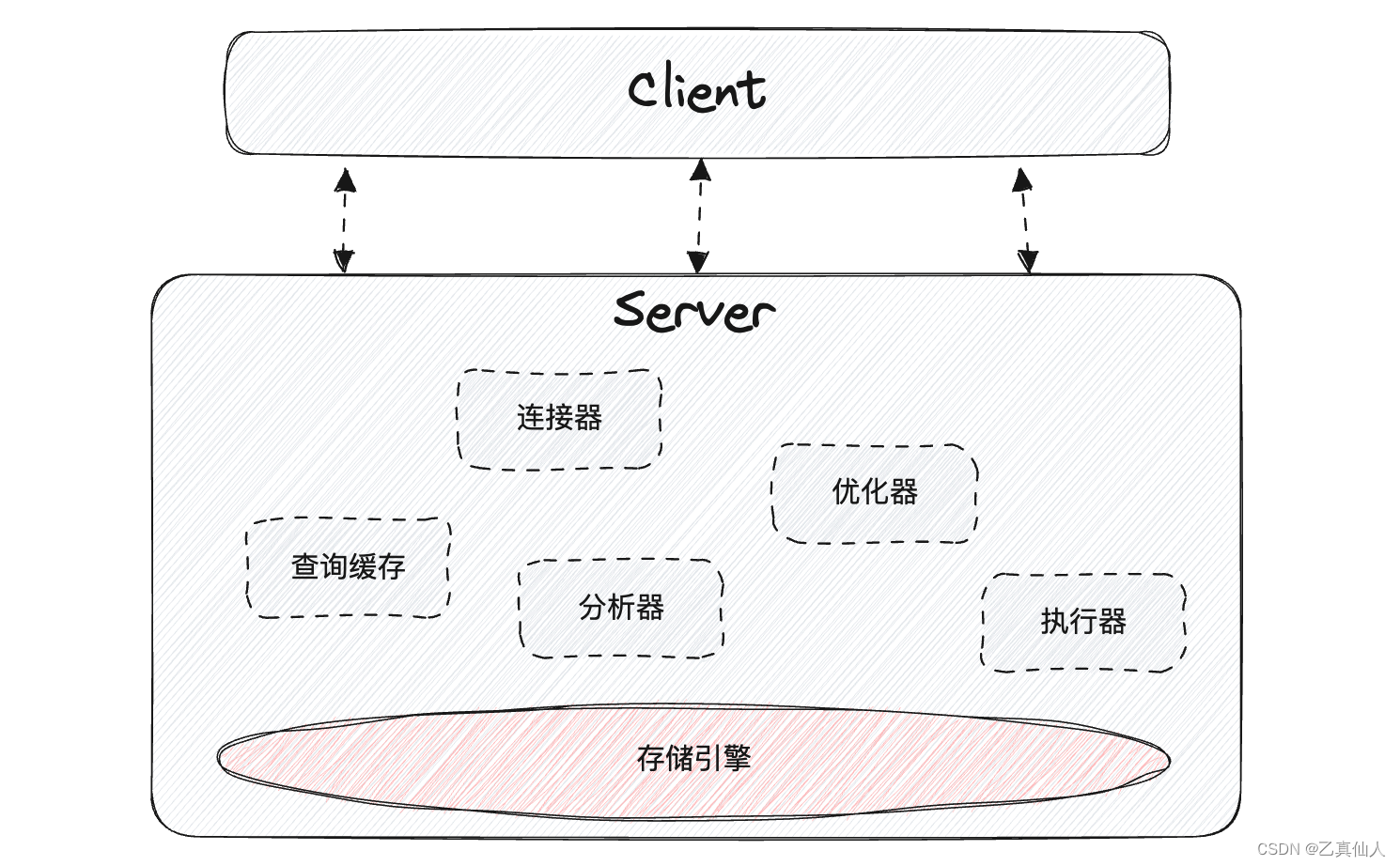
- 数据分布:数据存储在服务端,客户端通过网络与服务端进行通信并发送请求,服务端负责处理请求并返回结果。
- 数据处理:服务端负责接收并处理客户端的请求,包括查询、更新等操作,承担着数据处理的主要责任。
- 扩展性:通常需要对服务端进行垂直扩展,即增加服务端的硬件资源(如CPU和内存等),以满足更高的并发需求。
- 一致性:服务端负责维护数据的一致性,保证多个客户端对数据的并发操作不会导致数据的不一致性。
MySQL是典型的 C/S(Client/Server)架构,主要被分为客户端和服务端两部分。客户端只需发送请求并接收结果,将数据处理和存储的职责集中在服务器端,通过专门的服务器、高效的网络通信和并发控制机制(如锁、事务隔离级别等)支持,更适合处理在线业务的高并发读写场景。
但对于大规模数据的复杂计算场景,可能需要进行大量的计算和存储操作,这会给服务器带来较大的负载压力,如果服务器的计算能力有限或者无法有效扩展,可能无法满足大数据复杂计算的需求。另外,复杂计算往往涉及多个数据节点之间的交互和计算过程,需要进行并发控制和保证数据的一致性。在C/S架构中,这些并发控制和一致性的工作通常由服务器端负责,可能面临较高的竞争和冲突,导致性能下降或者数据不一致的问题。
SO,从DB架构设计上的差异而言,Apache Doris 适合做大数据的复杂计算,MySQL不适合。
三、数据结构差异
通常而言,数据库中索引的作用是做数据的快速检索,而快速检索的实现的本质是数据结构。基于不同数据结构的选择,实现各种数据快速检索。
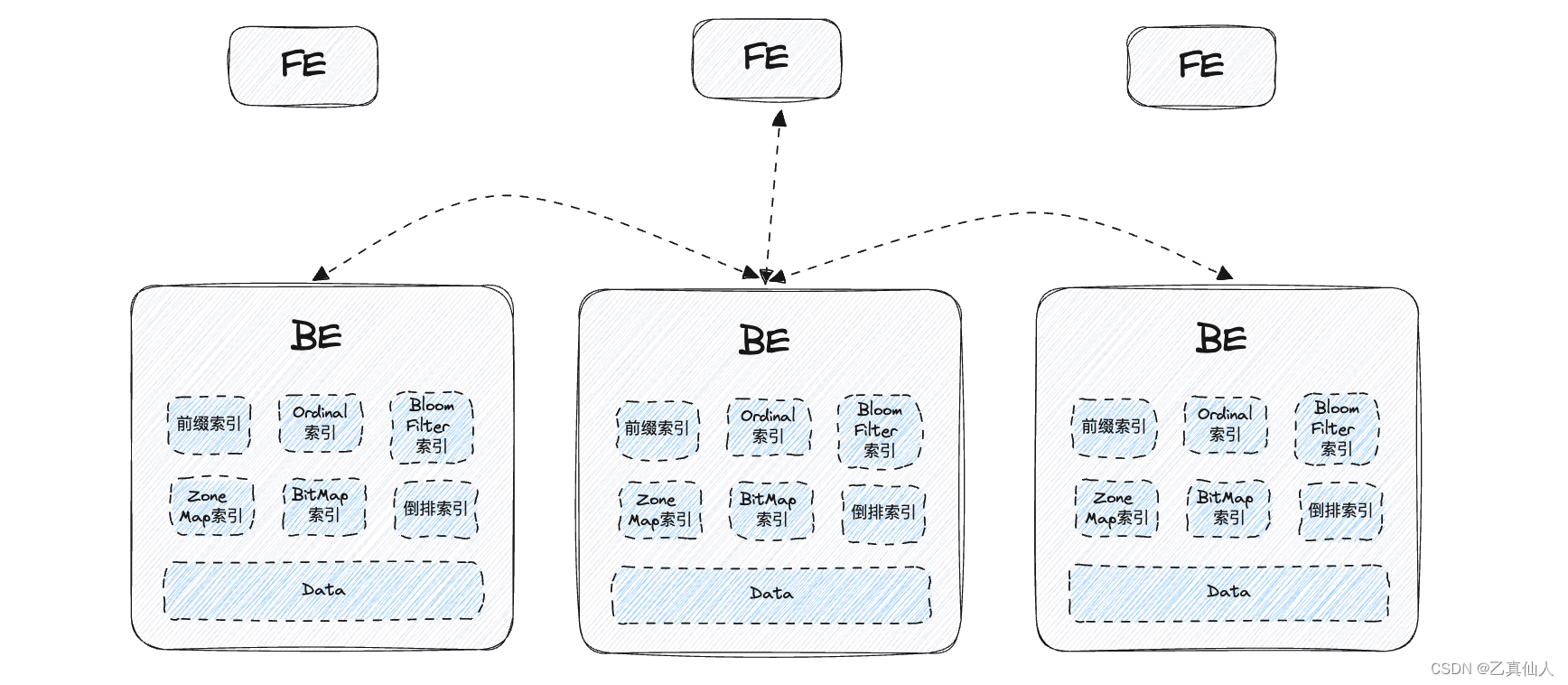
Apache Doris 底层存储引擎提供了丰富的索引类型来提高数据查询效率。分别是 Short Key 前缀索引(快速扫描)、Ordinal 索引(索引加速)、Zone Map索引(快速定位)、BitMap 索引(人群圈选)、 Bloom Filter 索引(高基数等值查询)和倒排索引时(文本检索)等。前缀索引、Ordinal 索引和 Zone Map 索引不需要用户干预,会随着数据写入智能生成;Bitmap 索引、 Bloom Filter 索引和倒排索引需要用户干预,数据写入时默认不会生成,用户可以有选择地为指定的列添加这3种索引。
基于这些索引,Apache Doris 进行不同场景的大规模数据的复杂计算时,可谓事半功倍。
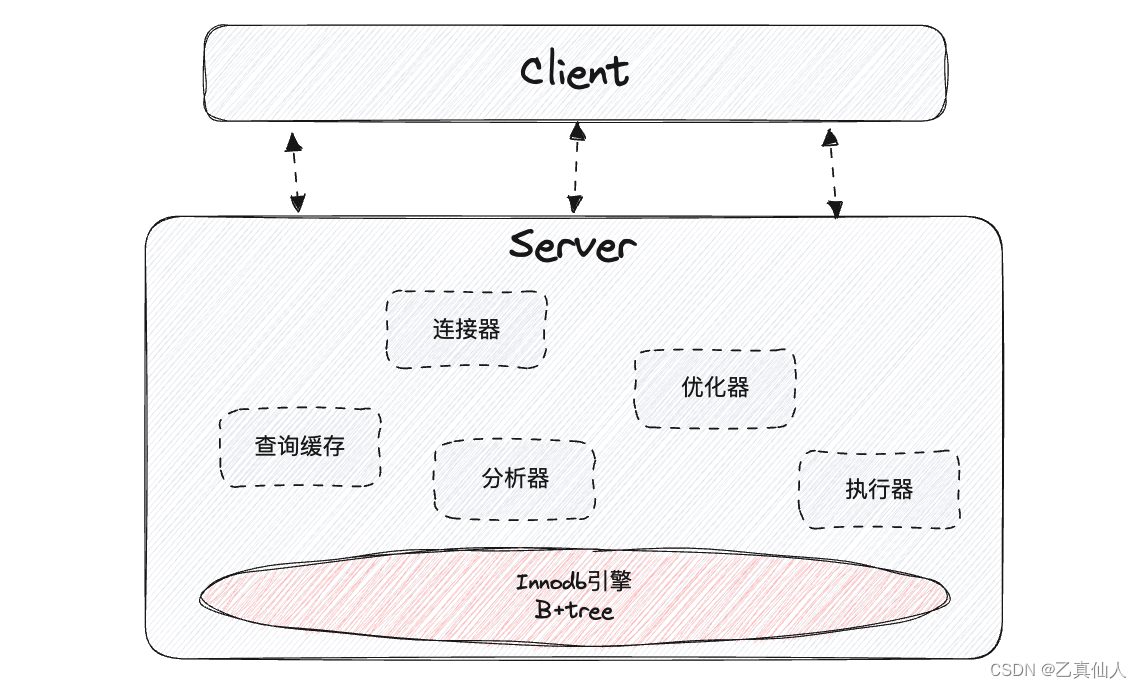
MySQL 底层数据引擎以插件形式设计,最常见的是 Innodb 引擎和 Myisam 引擎,用户可以根据个人需求选择不同的引擎作为 Mysql 数据表的底层引擎。这里,我们选择Innodb引擎来分析。
Innodb引擎以B+树作为索引的数据结构,从Hash、二叉树、红黑树、AVL树和B树推演而定。B+树节点存储的是索引,叶子节点是真正数据存储的地方,叶子节点用了链表连接起来,这个链表本身就是有序的,因此具有高效的范围查询,且能够支持快速的插入、删除、高并发访问等优点,但为什么不适合大数据的复杂计算场景?
- 磁盘I/O次数增多:随着数据的增加,B+树的高度会逐渐增加,这会导致查询时需要进行更多的磁盘I/O操作,从而影响查询效率。
- 索引维护成本增加:对于海量数据集,B+树索引的维护成本也会逐渐增加,例如插入、删除或者更新操作会导致索引的重构,从而影响数据处理的效率。
- 节点分裂频繁:在B+树索引中,节点分裂的次数与数据的分布情况有关。如果数据分布不均匀,节点分裂的频率就会增加,从而导致索引的重构和磁盘I/O负载增加。
…
SO,从数据结构设计上的差异而言,Apache Doris 适合做大数据的复杂计算,MySQL不适合。
四、存储结构差异
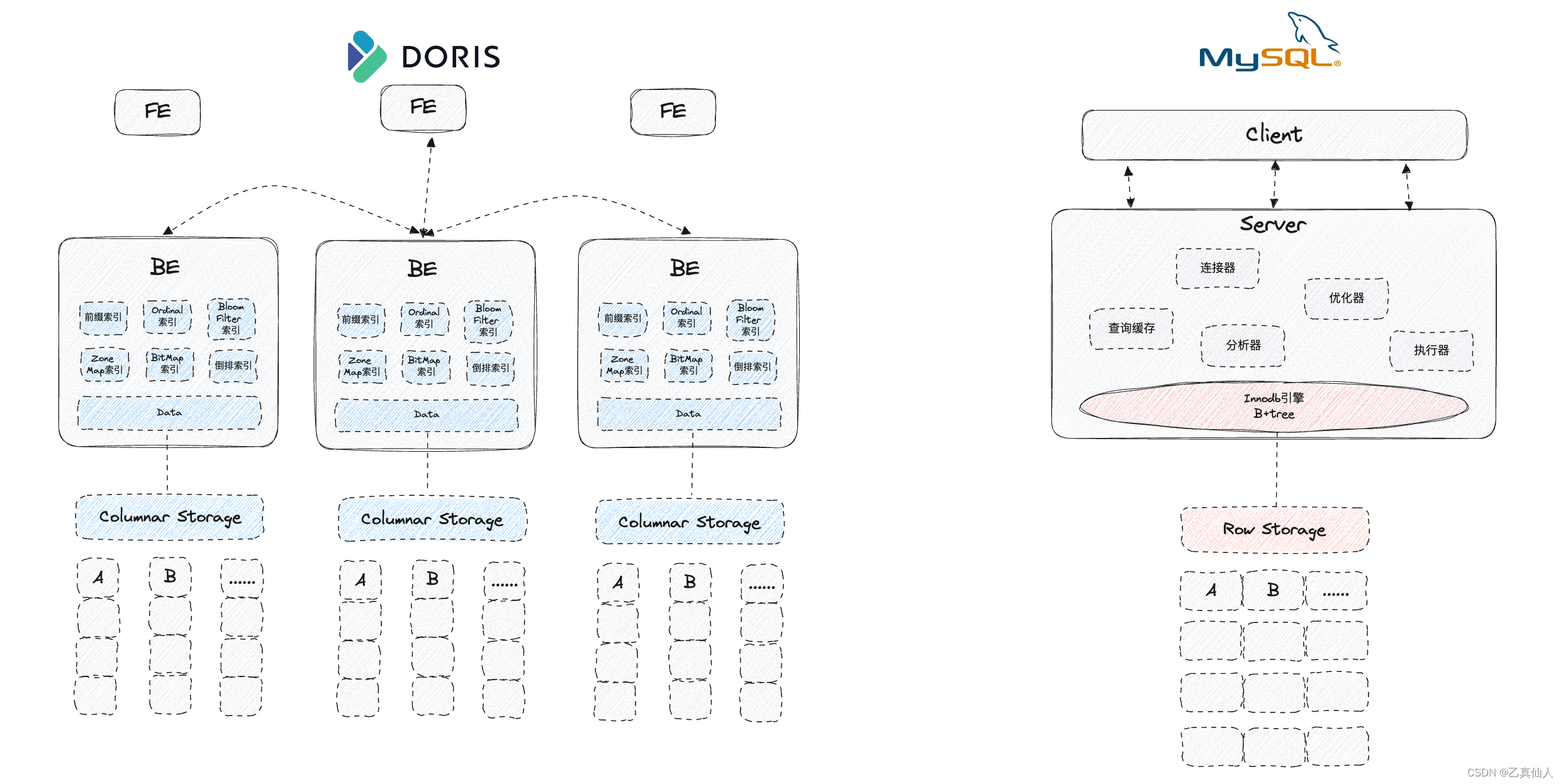
Apache Doris 默认为例存储(2.0支持行存高并发点查特性),相较于Mysql 主要是行存储模式,在大规模数据的复杂计算中更具优势:
- 数据压缩效率:列存储模式可以对每一列的数据进行独立的压缩,这样可以通过更好的压缩算法和跳过无关数据来减小存储空间,并且可以提高读取数据时的I/O效率。在行存储模式下,当使用通用的压缩算法对整行数据进行压缩时,由于不同列之间的数据类型和取值范围差异较大,通常较难获得很高的压缩比。
- 查询性能优化:在复杂计算中,通常需要对大量的列进行聚合、过滤和统计操作。列存储模式可以只读取涉及到的列数据,避免了读取不必要的数据,从而提高查询性能。在行存储模式中,进行聚合、过滤或者统计某些特定列的数值时,需要读取整行数据,包括不相关的列,导致读取了不必要的数据,影响了查询性能。
- 数据排列连续:列存储模式将同一列的数据放在一起存储,这样相同的数据类型可以连续存储,减少了存储的冗余。同时,列存储模式还可以使用更加紧凑的数据编码方式,进一步减少存储空间的占用。在行存储模式中,每行数据都包含多个列的数值,当表中存在大量的重复数据时,这些数据会被存储多次,从而导致存储冗余,影响查询效率。
- 并行处理能力:列存储模式可以更好地支持并行计算,在大规模数据复杂计算时可以充分利用多核和分布式计算资源,加速数据处理的速度。在行存储模式中,需要对大量行进行扫描和过滤的复杂查询场景下,由于每行数据都包含多个列的数值,需要同时访问大量行数据,可能会导致并行查询的效率下降。
…
SO,从存储结构设计上的差异而言,Apache Doris 适合做大数据的复杂计算,MySQL不适合。
五、总结
SO,Apache Doris 由于是分布式列存架构,且具有丰富的索引支撑,非常适用用于大数据场景下复杂的分析查询和决策支持等;MySQL 基于C/S 行存架构,结合 B+tree 能够高效地支持小规模数据频繁读写、快速响应在线业务,主要用于处理实时事务和业务操作,各有千秋!
【为什么Apache Doris适合做大数据的复杂计算,MySQL不适合?】 分享至此结束,查阅过程中若遇到问题欢迎留言交流。

