
- 1智慧的疆界读书笔记_智慧的疆界:从图灵机到人工智能 读书笔记
- 2【Transformer系列】深入浅出理解Tokenization分词技术_文字token化
- 3【NLP】近期必读ICLR 2021相关论文
- 4Redis实战篇-利用逻辑过期解决缓存击穿问题
- 5新版Redis不再“开源”,对使用者都有哪些影响?
- 6车载以太网AVB交换机 gptp透明时钟 5口 全千兆 SW1500
- 7我收藏的!!_阿里云盘 python全栈
- 8AAAI 2024 | 通用图扩散框架:建立不同图神经网络与扩散方程之间的关系
- 9超详细百度翻译js逆向(token 和 sign)_百度翻译逆向
- 10spyder安装pyqt5_spyder怎么安装pyqt5
UA-DETRAC BITVehicle车辆检测数据集(含下载地址)_ua-detrac数据集
赞
踩
UA-DETRAC BITVehicle车辆检测数据集(含下载地址)
目录
UA-DETRAC BITVehicle车辆检测数据集使用说明和下载
考虑到自动驾驶算法开发,经常要用到车辆检测数据集;这里分享鄙人整合的三个车辆检测数据集:UA-DETRAC,Vehicle-Dataset和BIT-Vehicle车辆检测数据集
【尊重原则,转载请注明出处】:https://panjinquan.blog.csdn.net/article/details/127907325
更多项目《智能驾驶 车牌检测和识别》系列文章请参考:
- 智能驾驶 车牌检测和识别(一)《CCPD车牌数据集》:https://blog.csdn.net/guyuealian/article/details/128704181
- 智能驾驶 车牌检测和识别(二)《YOLOv5实现车牌检测(含车牌检测数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/128704068
- 智能驾驶 车牌检测和识别(三)《CRNN和LPRNet实现车牌识别(含车牌识别数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/128704209
- 智能驾驶 车牌检测和识别(四)《Android实现车牌检测和识别(可实时车牌识别)》:https://blog.csdn.net/guyuealian/article/details/128704242
- 智能驾驶 车牌检测和识别(五)《C++实现车牌检测和识别(可实时车牌识别)》:https://blog.csdn.net/guyuealian/article/details/128704276
- 智能驾驶 红绿灯检测(一)《红绿灯(交通信号灯)数据集》:https://blog.csdn.net/guyuealian/article/details/128222850
- 智能驾驶 红绿灯检测(二)《YOLOv5实现红绿灯检测(含红绿灯数据集+训练代码)》:https://blog.csdn.net/guyuealian/article/details/128240198
- 智能驾驶 红绿灯检测(三)《Android实现红绿灯检测(含Android源码 可实时运行)》:https://blog.csdn.net/guyuealian/article/details/128240334
-
智能驾驶 车辆检测(一)《UA-DETRAC BITVehicle车辆检测数据集》:https://blog.csdn.net/guyuealian/article/details/127907325
-
智能驾驶 车辆检测(二)《YOLOv5实现车辆检测(含车辆检测数据集+训练代码)》:https://blog.csdn.net/guyuealian/article/details/128099672
-
智能驾驶 车辆检测(三)《Android实现车辆检测(含Android源码 可实时运行)》:https://blog.csdn.net/guyuealian/article/details/128190532
一、车辆检测数据集介绍
1. UA-DETRAC车辆检测数据集
UA-DETRAC 是一个具有挑战性的现实世界多目标检测和多目标跟踪基准。该数据集包含使用佳能 EOS 550D 相机在中国北京和天津的 24 个不同地点拍摄的 10 小时视频。视频以每秒 25 帧 (fps) 的速度录制,分辨率为 960×540 像素。UA-DETRAC 数据集中有超过 14 万帧和 8250 辆手动标注的车辆,总共有 121 万个标记的对象边界框,其中训练集约82085张图片,测试集约56167张图片。该数据集可用于多目标检测和多目标跟踪算法开发。
官方网站:The UA-DETRAC Benchmark Suite

下图展示了 DETRAC 数据集中带注释的帧。边界框的颜色反映遮挡状态,包括完全可见(红色)、部分被其他车辆遮挡(蓝色)或部分被背景遮挡(粉红色)。车辆 ID、方向、车辆类型和截断率显示在边界框中。其中浅灰色区域代表被忽略区域,这在基准测试中会被忽略。另外在每帧的左下角还显示了天气状况、摄像头状态和车辆密度。
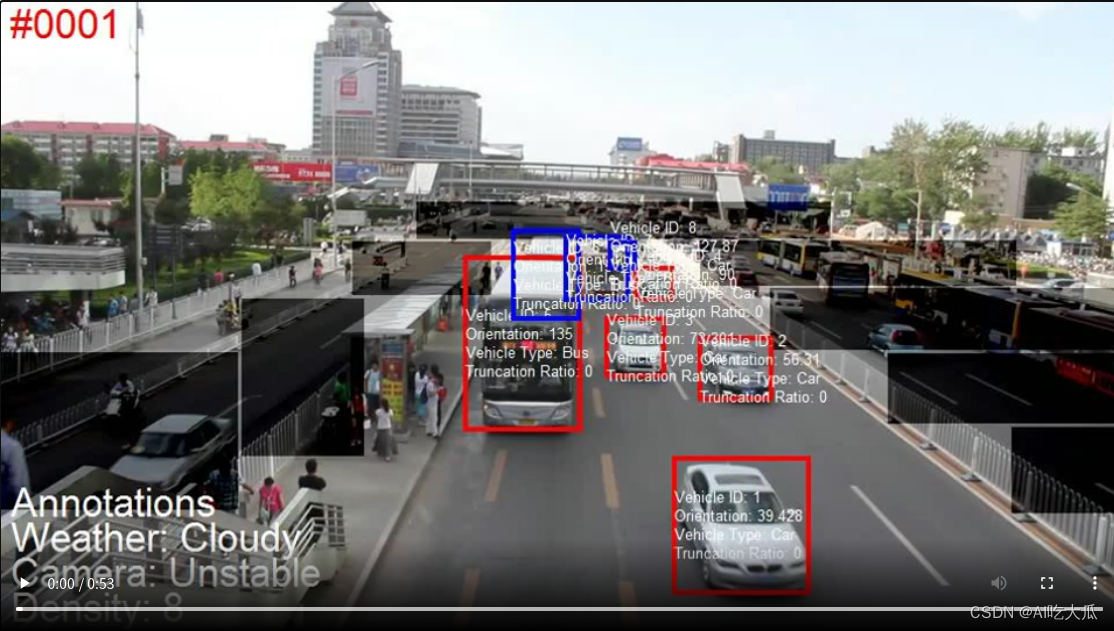
- 车辆类别 我们将车辆分为四类,即小汽车(car)、公共汽车(bus)、货车(van)和其他(others)。
- 天气 我们考虑四类天气条件,即多云、夜晚、晴天和下雨。
- 比例 我们将带注释的车辆的比例定义为其面积的平方根(以像素为单位)。我们将车辆分为三个等级:小型(0-50 像素)、中型(50-150 像素)和大型(超过 150 像素)。
- 遮挡率 我们使用被遮挡的车辆边界框的分数来定义遮挡程度。我们将遮挡程度分为三类:无遮挡、部分遮挡和严重遮挡。具体来说,我们定义部分遮挡,如果车辆的遮挡率在 1%-50% 之间,如果遮挡率大于 50%,则定义为重度遮挡。
- 截断率 截断率表示车辆部件超出框架的程度,用于训练样本选择。
为了方便可视化DETRAC数据集的目标检测框的效果,这里提供一个可视化Python脚本
需要用的几个python依赖包,pip安装即可:
- pip install pybaseutils
- pip install xmltodict

- 这里没有区分可见和被遮挡的车辆,统一用蓝色框表示
- 黑色框表示被忽略的区域(ignored_region)
- 共有四个类别:['car', 'bus', 'others', 'van']
- # -*-coding: utf-8 -*-
- """
- @Author : panjq
- @E-mail : pan_jinquan@163.com
- @Date : 2022-10-12 16:21:55
- @Brief :
- """
- import os
- import cv2
- import xmltodict
- from tqdm import tqdm
- from pybaseutils.maker import maker_voc
- from pybaseutils import file_utils, image_utils
-
-
- def read_xml2json(xml_file):
- """
- import xmltodict
- :param xml_file:
- :return:
- """
- with open(xml_file, encoding='utf-8') as fd: # 将XML文件装载到dict里面
- content = xmltodict.parse(fd.read())
- return content
-
-
- def get_objects_info(objects):
- """
- 解析标注信息
- """
- rects = []
- labels = []
- targets = objects['target_list']['target'] # collections.OrderedDict
- if not isinstance(targets, list): targets = [targets]
- for data in targets:
- box = data['box']
- attribute = data['attribute']
- label = attribute['@vehicle_type']
- rect = [box['@left'], box['@top'], box['@width'], box['@height']]
- rect = [float(r) for r in rect]
- rects.append(rect)
- labels.append(label)
- bboxes = image_utils.rects2bboxes(rects)
- num = objects['@num']
- image_id = "img{:0=5d}.jpg".format(int(num)) # img00002.jpg
- return image_id, bboxes, labels
-
-
- def get_ignored_region(objects):
- """获得ignored区域"""
- rects = []
- labels = []
- if not "box" in objects: return rects, labels
- for data in objects["box"]:
- label = "ignored_region"
- rect = [data['@left'], data['@top'], data['@width'], data['@height']]
- rect = [float(r) for r in rect]
- rects.append(rect)
- labels.append(label)
- bboxes = image_utils.rects2bboxes(rects)
- return bboxes, labels
-
-
-
- def show_ua_detrac_dataset(image_dir, annot_dir, out_draw="", vis=False):
- """
- 可视化车辆检测数据集
- class_set:['car', 'bus', 'others', 'van']
- :param image_dir: UA-DETRAC数据集图片(*.jpg)根目录
- :param annot_dir: UA-DETRAC数据集标注文件(*.xml)根目录
- :param vis: 是否可视化效果
- """
- print("image_dir:{}".format(image_dir))
- print("annot_dir:{}".format(annot_dir))
- xml_list = file_utils.get_files_list(annot_dir, postfix=["*.xml"])
- class_set = []
- for annot_file in tqdm(xml_list):
- print(annot_file)
- # 将xml转换为OrderedDict格式,方便解析
- annotations = read_xml2json(annot_file)
- subname = annotations['sequence']['@name'] # UA-DETRAC子目录
- # 被忽略的区域
- ignore_bboxes, ignore_labels = get_ignored_region(annotations['sequence']['ignored_region'])
- # 遍一帧图像,获得车辆目标框
- frame_info = annotations['sequence']['frame']
- for i in range(len(frame_info)):
- image_name, bboxes, labels = get_objects_info(frame_info[i])
- image_id = image_name.split(".")[0]
- image_file = os.path.join(image_dir, subname, image_name)
- class_set = labels + class_set
- class_set = list(set(class_set))
- if not os.path.exists(image_file):
- print("not exist:{}".format(image_file))
- continue
- image = cv2.imread(image_file)
- image = image_utils.draw_image_bboxes_text(image, ignore_bboxes, ignore_labels,
- color=(10, 10, 10), thickness=2, fontScale=1.0)
- image = image_utils.draw_image_bboxes_text(image, bboxes, labels,
- color=(255, 0, 0), thickness=2, fontScale=1.0)
- if out_draw:
- dst_file = file_utils.create_dir(out_draw, None, "{}_{}.jpg".format(subname, image_id))
- cv2.imwrite(dst_file, image)
- if vis:
- image_utils.cv_show_image("det", image, use_rgb=False)
- print("class_set:{}".format(class_set))
-
-
- if __name__ == "__main__":
- """
- pip install pybaseutils
- pip install xmltodict
- """
- image_dir = "UA-DETRAC/DETRAC-train-data/Insight-MVT_Annotation_Train"
- annot_dir = "UA-DETRAC/DETRAC-Train-Annotations-XML"
- out_draw = os.path.join(os.path.dirname(image_dir), "result")
- show_ua_detrac_dataset(image_dir, annot_dir, out_draw=out_draw, vis=True)

目标检测中,我们常使用VOC数据格式,这里实现将UA-DETRAC数据集转换为VOC数据格式,
需要特别注意的是:
- 这里没有区分可见和被遮挡的车辆,按照原始标注,分为四个类别:['car', 'bus', 'others', 'van']
- 原始标注文档中的ignored_region表示被忽略区域,即使有车辆,也没有检测框,因此转换VOC格式时,这部分也被忽略了(由于ignored_region也可能存在车辆,因此对目标检测会有点影响)
- 很可惜,UA-DETRAC没有标注非机动车(如摩托车,三轮车,电动车)都没有标注
- # -*-coding: utf-8 -*-
- """
- @Author : panjq
- @E-mail : pan_jinquan@163.com
- @Date : 2022-10-12 16:21:55
- @Brief :
- """
- import os
- import cv2
- import xmltodict
- from tqdm import tqdm
- from pybaseutils.maker import maker_voc
- from pybaseutils import file_utils, image_utils
-
-
- def read_xml2json(xml_file):
- """
- import xmltodict
- :param xml_file:
- :return:
- """
- with open(xml_file, encoding='utf-8') as fd: # 将XML文件装载到dict里面
- content = xmltodict.parse(fd.read())
- return content
-
-
- def get_objects_info(objects):
- """
- 解析标注信息
- """
- rects = []
- labels = []
- targets = objects['target_list']['target'] # collections.OrderedDict
- if not isinstance(targets, list): targets = [targets]
- for data in targets:
- box = data['box']
- attribute = data['attribute']
- label = attribute['@vehicle_type']
- rect = [box['@left'], box['@top'], box['@width'], box['@height']]
- rect = [float(r) for r in rect]
- rects.append(rect)
- labels.append(label)
- bboxes = image_utils.rects2bboxes(rects)
- num = objects['@num']
- image_id = "img{:0=5d}.jpg".format(int(num)) # img00002.jpg
- return image_id, bboxes, labels
-
-
- def get_ignored_region(objects):
- """获得ignored区域"""
- rects = []
- labels = []
- if not "box" in objects: return rects, labels
- for data in objects["box"]:
- label = "ignored_region"
- rect = [data['@left'], data['@top'], data['@width'], data['@height']]
- rect = [float(r) for r in rect]
- rects.append(rect)
- labels.append(label)
- bboxes = image_utils.rects2bboxes(rects)
- return bboxes, labels
-
-
- def converter_ua_detrac2voc(image_dir, annot_dir, out_voc, vis=True):
- """
- 将车辆检测数据集UA-DETRAC转换为VOC数据格式(xmin,ymin,xmax,ymax)
- class_set:['car', 'bus', 'others', 'van']
- :param image_dir: UA-DETRAC数据集图片(*.jpg)根目录
- :param annot_dir: UA-DETRAC数据集标注文件(*.xml)根目录
- :param out_voc: 输出VOC格式数据集目录
- :param vis: 是否可视化效果
- """
- print("image_dir:{}".format(image_dir))
- print("annot_dir:{}".format(annot_dir))
- print("out_voc :{}".format(out_voc))
- xml_list = file_utils.get_files_list(annot_dir, postfix=["*.xml"])
- out_image_dir = file_utils.create_dir(out_voc, None, "JPEGImages")
- out_xml_dir = file_utils.create_dir(out_voc, None, "Annotations")
- class_set = []
- for annot_file in tqdm(xml_list):
- print(annot_file)
- # 将xml转换为OrderedDict格式,方便解析
- annotations = read_xml2json(annot_file)
- subname = annotations['sequence']['@name'] # UA-DETRAC子目录
- # 被忽略的区域
- ignore_bboxes, ignore_labels = get_ignored_region(annotations['sequence']['ignored_region'])
- # 遍一帧图像,获得车辆目标框
- frame_info = annotations['sequence']['frame']
- for i in range(len(frame_info)):
- image_name, bboxes, labels = get_objects_info(frame_info[i])
- image_id = image_name.split(".")[0]
- image_file = os.path.join(image_dir, subname, image_name)
- class_set = labels + class_set
- class_set = list(set(class_set))
- if not os.path.exists(image_file):
- print("not exist:{}".format(image_file))
- continue
- image = cv2.imread(image_file)
- image_shape = image.shape
- new_image_id = "{}_{}".format(subname, image_id)
- new_name = "{}.jpg".format(new_image_id)
- xml_path = file_utils.create_dir(out_xml_dir, None, "{}.xml".format(new_image_id))
- objects = maker_voc.create_objects(bboxes, labels)
- maker_voc.write_voc_xml_objects(new_name, image_shape, objects, xml_path)
- dst_file = file_utils.create_dir(out_image_dir, None, new_name)
- file_utils.copy_file(image_file, dst_file)
- # cv2.imwrite(dst_file, image)
- if vis:
- image = image_utils.draw_image_bboxes_text(image, ignore_bboxes, ignore_labels,
- color=(10, 10, 10), thickness=2, fontScale=1.0)
- image = image_utils.draw_image_bboxes_text(image, bboxes, labels,
- color=(255, 0, 0), thickness=2, fontScale=1.0)
- image_utils.cv_show_image("det", image, use_rgb=False)
- print("class_set:{}".format(class_set))
-
-
-
-
- if __name__ == "__main__":
- """
- pip install pybaseutils
- pip install xmltodict
- """
- image_dir = "UA-DETRAC/DETRAC-train-data/Insight-MVT_Annotation_Train"
- annot_dir = "UA-DETRAC/DETRAC-Train-Annotations-XML"
-
- # 将车辆检测数据集UA - DETRAC转换为VOC数据格式
- out_voc = os.path.join(os.path.dirname(image_dir), "VOC")
- converter_ua_detrac2voc(image_dir, annot_dir, out_voc, vis=True)
运行完成后,会生成 Annotations和JPEGImages两个文件夹,后面就可以用于目标检测
2. Vehicle-Dataset车辆检测数据集
这是来自美丽印度的车辆检测数据集,共3000张,共标注了21个类别,包含自行车(bicycle),公共汽车(bus),汽车(car),摩托车(motorbike)等常见的车辆类别;已经将标注格式转换其VOC数据格式了,可以直接用于深度学习目标检测模型训练
21个车辆类别如下:
- human hauler # 人力搬运工
- bicycle # 自行车
- bus 公 # 共汽车
- suv # 越野车
- policecar # 警车
- ambulance # 救护车
- truck # 卡车
- auto rickshaw # 自动人力车
- three wheelers (CNG) # 三轮车 (CNG)
- van # 货车
- scooter # 小型摩托车
- minibus # 小巴
- army vehicle # 军车
- taxi # 出租车
- rickshaw # 黄包车
- garbagevan # 垃圾车
- car # 汽车
- pickup # 皮卡
- motorbike # 摩托车
- wheelbarrow # 独轮手推车
- minivan # 小货车
 |  |
 |  |
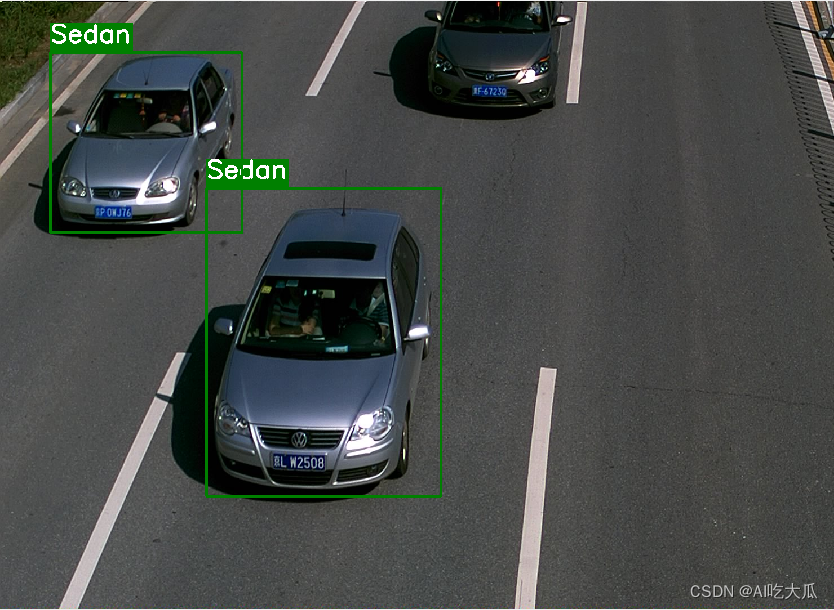
3.BIT-Vehicle车辆检测数据集
BIT-Vehicle数据集是国内车辆检测数据集,包含9850个车辆图像。数据集中有两个摄像头在不同时间和地点拍摄的大小为1600*1200 和1920*1080的图像。 图像包含照明条件、比例、车辆表面颜色和视点的变化。
由于捕获延迟和车辆的大小,某些车辆的顶部或底部未包含在图像中。一幅图像中可能有一两辆车,因此每辆车的位置都被预先标注。 该数据集还可用于评估车辆检测的性能。 数据集中的所有车辆分为6类:公共汽车(Bus)、微型客车(Microbus)、小型货车(Minivan)、轿车(Sedan)、SUV(SUV) 和卡车(Truck)。 每种车型的车辆数量分别为558辆、883辆、476辆、5922辆、1392辆和822辆;
原始标注文档是Matlab数据格式保存(VehicleInfo.mat),现已经将标注格式转换其VOC数据格式了,可以直接用于深度学习目标检测模型训练。
- Bus # 公共汽车
- Microbus # 微型客车
- Minivan # 小型货车
- SUV # SUV车
- Sedan # 轿车
- Truck # 卡车
 |  |
 |  |
二.车辆检测数据集下载地址
车辆检测数据集下载资源内容包含:UA-DETRAC车辆检测数据集+Vehicle-Dataset车辆检测数据集+BITVehicle车辆检测数据集:UA-DETRAC BITVehicle车辆检测数据集下载
1. UA-DETRAC车辆检测数据集
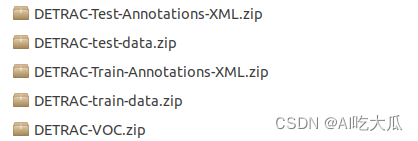
- UA-DETRAC车辆检测数据集: 包含原始官网下载的Train和Test数据集,以及标注文档Annotations,训练集约82085张图片,测试集约56167张图片
- 共4个类别:小汽车(car)、公共汽车(bus)、货车(van)和其他(others)。
- UA-DETRAC车辆检测数据集VOC数据格式(DETRAC-VOC): 已经将原始官网下载的Train和Test数据集转换为VOC数据格式,可以直接用于深度学习检测模型训练
2. Vehicle-Dataset车辆检测数据集
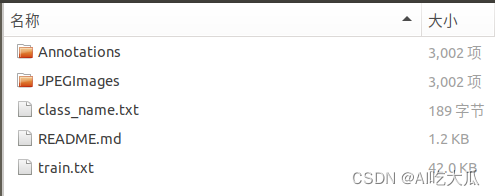
- Vehicle-Dataset车辆检测数据集:总共3000张,共标注了21个类别,包含自行车(bicycle),公共汽车(bus),汽车(car),摩托车(motorbike)等常见的车辆类别;
- 已经将标注格式转换其VOC数据格式了,可以直接用于深度学习目标检测模型训练
3. BITVehicle车辆检测数据集
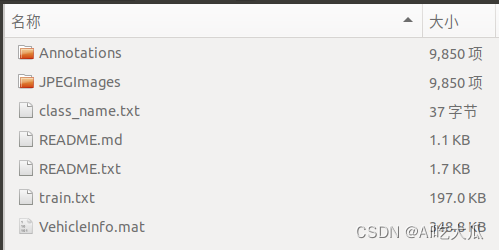
- BITVehicle车辆检测数据集:总共9850张图片,标注了6个类别:公共汽车(Bus)、微型客车(Microbus)、小型货车(Minivan)、轿车(Sedan)、SUV(SUV) 和卡车(Truck)
- 已经将标注格式转换其VOC数据格式了,可以直接用于深度学习目标检测模型训练
三.基于YOLOv5的车辆检测(Python)
《YOLOv5实现车辆检测(含车辆检测数据集+训练代码)》
Python版本车辆检测Demo效果:
 |  |
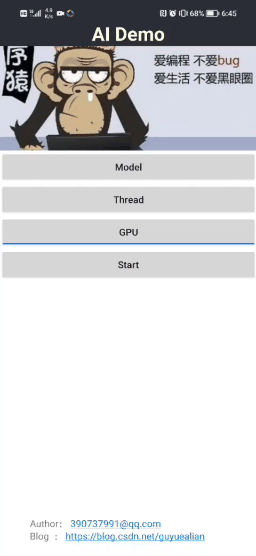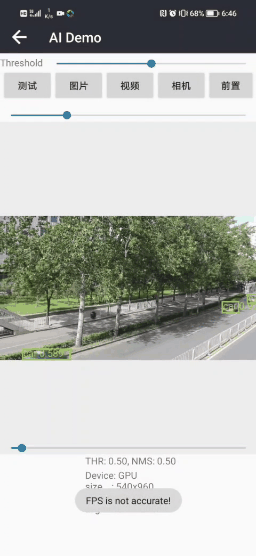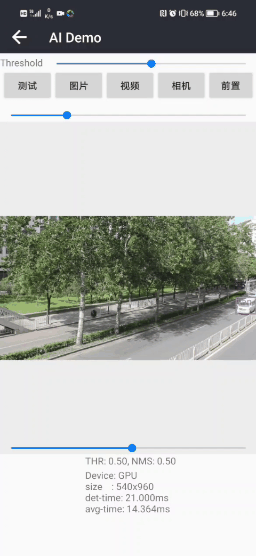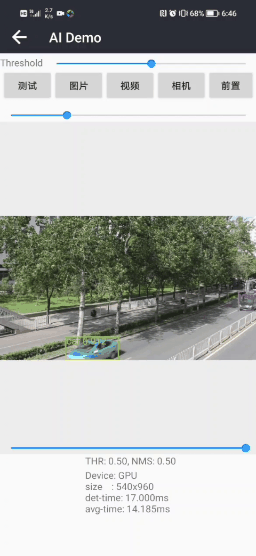
四.手机实现车辆检测(Android)
Android APP体验 : Android实现车辆检测(可实时运行)APPDemo-Android文档类资源-CSDN下载
APP在普通Android手机上可以达到实时的车辆检测效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
 |  |
|
更多项目《智能驾驶 车牌检测和识别》系列文章请参考:
- 智能驾驶 车牌检测和识别(一)《CCPD车牌数据集》:https://blog.csdn.net/guyuealian/article/details/128704181
- 智能驾驶 车牌检测和识别(二)《YOLOv5实现车牌检测(含车牌检测数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/128704068
- 智能驾驶 车牌检测和识别(三)《CRNN和LPRNet实现车牌识别(含车牌识别数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/128704209
- 智能驾驶 车牌检测和识别(四)《Android实现车牌检测和识别(可实时车牌识别)》:https://blog.csdn.net/guyuealian/article/details/128704242
- 智能驾驶 车牌检测和识别(五)《C++实现车牌检测和识别(可实时车牌识别)》:https://blog.csdn.net/guyuealian/article/details/128704276
- 智能驾驶 红绿灯检测(一)《红绿灯(交通信号灯)数据集》:https://blog.csdn.net/guyuealian/article/details/128222850
- 智能驾驶 红绿灯检测(二)《YOLOv5实现红绿灯检测(含红绿灯数据集+训练代码)》:https://blog.csdn.net/guyuealian/article/details/128240198
- 智能驾驶 红绿灯检测(三)《Android实现红绿灯检测(含Android源码 可实时运行)》:https://blog.csdn.net/guyuealian/article/details/128240334
-
智能驾驶 车辆检测(一)《UA-DETRAC BITVehicle车辆检测数据集》:https://blog.csdn.net/guyuealian/article/details/127907325
-
智能驾驶 车辆检测(二)《YOLOv5实现车辆检测(含车辆检测数据集+训练代码)》:https://blog.csdn.net/guyuealian/article/details/128099672
-
智能驾驶 车辆检测(三)《Android实现车辆检测(含Android源码 可实时运行)》:https://blog.csdn.net/guyuealian/article/details/128190532

