
- 1拉链表和快照表的选择_快照表和拉链表的区别
- 2Electron Security Warning (Insecure Content-Security-Policy) 告警解决
- 3C语言-结构体 字节对齐_c语言结构体字节对齐
- 4数据结构(图,树)
- 5大话设计模式九:状态模式_private istate currentstate;
- 6C++征途 --- Vector容器_c++如何判断一个泛型是vector
- 7唯品会Redis cluster大规模生产实践经验_redis cluster pipeline max redirect
- 8Git客户端Sourcetree工具安装使用详解&命令_sourcetree配置git
- 9《大前端进阶 Node.js》系列 多进程模型底层实现(字节跳动被问)_node大前端进阶
- 10Python爬虫中如何通过post发请求,浏览器控制台抓包教程,有道翻译爬虫程序,通过python伪装翻译(post案例)_爬虫post
CNN入门+猫狗大战(Dogs vs. Cats)+PyTorch入门_dogs vs cats
赞
踩
一些修改(修改后的代码)
- 修改原网络的输出方式。原网络采用的交叉熵
torch.nn.CrossEntropyLoss()进行Loss计算,而这个函数内部是已经进行了softmax处理的(参考),所以网络中的输出再进行F.softmax(x, dim=1)就重复了,故改正。 - 增加epoch的训练机制,就是重复的读取数据集n次进行训练,然后保存最后的参数
- 优化了
test.py,每次可以加载多个图像测试 - 调整了image的裁剪方式,先按比例进行图像缩放,然后进行中心裁剪,可以使训练数据更精准,最大可能保证输入图像包含一个完整的猫或狗
- 文中用到的模型是自己随意写的,所以性能差,如需提高精度,可以参考我用torchvision自带的ResNet18进行的代码
1.pytorch损失函数之nn.CrossEntropyLoss()、nn.NLLLoss()
2.ResNet18实现猫狗大战
写在前面
深度学习入门教程,参考了许多资料,在PyTorch框架下实现了深度网络的设计和实现,在此总结一下,给初学者提供一点学习思路。
运行环境:
硬件:Intel-6400,16G,GTX960
软件:win10+anaconda3+Python 3.6+cuda 9.0+PyTorh 0.4.1+Pycharm 2018
猫狗大战介绍
Dogs vs. Cats(猫狗大战)来源Kaggle上的一个竞赛题,任务为给定一个数据集,设计一种算法对测试集中的猫狗图片进行判别。
 图1 训练集 图1 训练集
|
 图2 测试集 图2 测试集
|
训练集:训练集由标记为cat和dog的猫狗图片组成,各12500张,总共25000张,图片为24位jpg格式,即RGB三通道图像,图片尺寸不一
测试集:测试集由12500张的cat或dog图片组成,未标记,图片也为24位jpg格式,RGB三通道图像,图像尺寸不一
CNN介绍
CNN(Convolutional Neural Networks)即卷积神经网络,顾名思义是一种神经网络,其基本运算方式为卷积。因网上有大量的CNN原理介绍、中心思想和使用说明,在此只做简要介绍。
卷积结构
如下图所示,一个简单的CNN由输入层,卷积层,池化层,全连接层组成
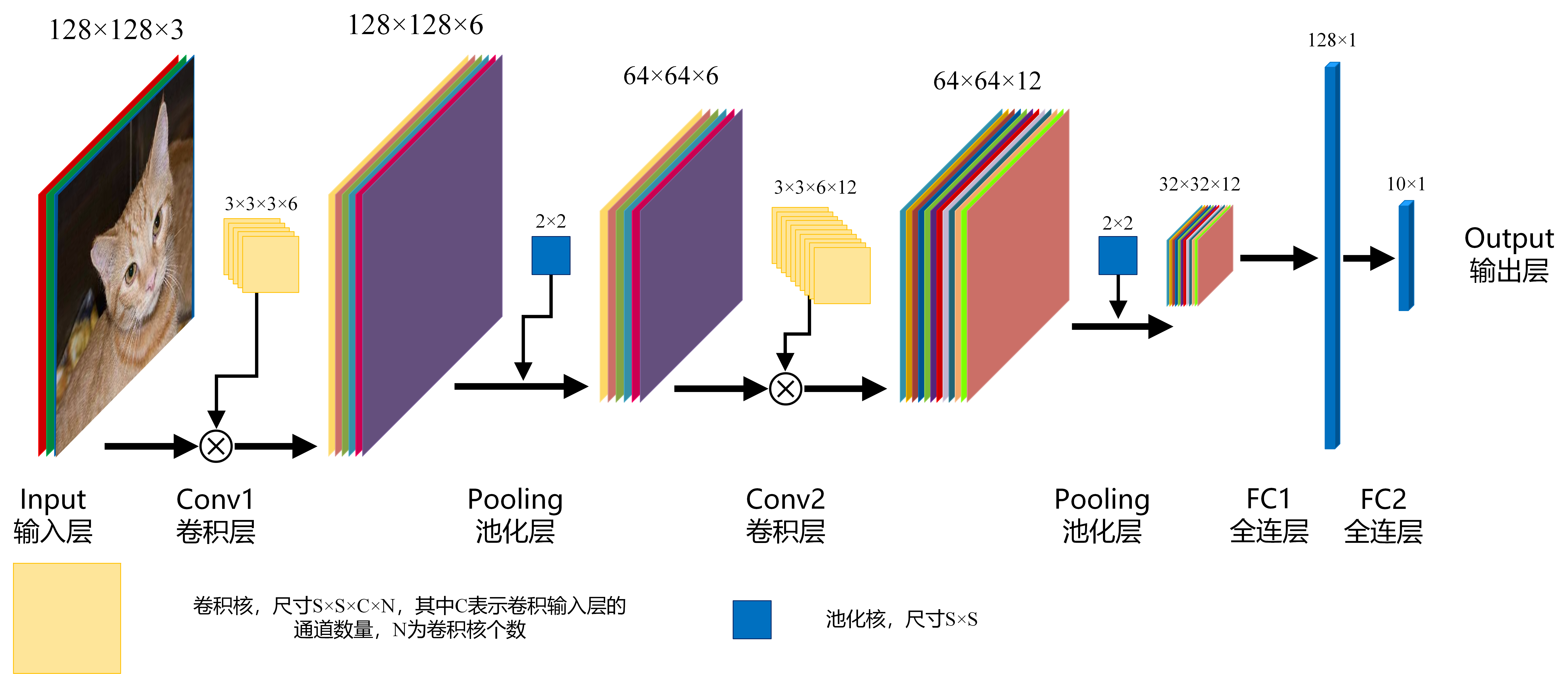 图3 CNN 图3 CNN
|
输入层(Input):指输入的图像数据,以矩阵形式的数据存在,如果输入一张尺寸为(H, W)的彩色图像,则输入层的数据为一个(H×W×3)的矩阵,数值范围为[0, 255],其中,3表示RGB三个通道,一般称作该输入层为3通道(channel),或者说包含3个feature map,如果是灰度图像,则数据表示为(H×W×1),1个通道或者1个feature map。从数值上讲,此处的3通道或者1通道与后续每一层卷积结果的feature map数量是等价的。
卷积层(Conv):CNN基本运算,由卷积核对输入层图像进行卷积操作以提取图像特征,1个卷积核生成1个feature map,即卷积输出的图像通道数与卷积核的个数一致,卷积核的尺寸为(S×S×C×N),其中C表示卷积核深度,必须与输入层图像的通道数一致,即如果输入图像是3通道,则C为3,如果是1通道,则C为1,在上图Conv2中,因为其输入图像的通道(feature map)数为12,所以Conv2的卷积核深度为12,N表示卷积核的数量。
池化层(pooling):主要用于图像下采样,降低图像分辨率(注意:对图像层的通道(feature map)数没有影响),减少区域内图像的特征数。常用的池化方法有max pooling,max pooling就是在池化核大小区域内选择最大的数值作为输出结果。
全连层(Fully connected):图像经过多次卷积和池化后,通过全连层完成分类操作,设卷积后的图像尺寸为(h×w×c),需分成n类,则全连层的作用为将[h×w×c]的矩阵转换成[n×1]的矩阵。传统的分类方法一般操作为图像预处理,ROI定位,目标定位,特征提取,SVM或BP分类,在基于CNN的分类方法中,可以把卷积和池化操作看作传统方法的图像预处理到特征提取过程,因此CNN的操作结果就是网络自主学习并提取了一个[h×w×c]大小的特征值,然后在FC层中进行了n目标分类任务。(FC的结构跟BP很相似)
卷积(convolution)
图像的卷积就是让卷积核(卷积模板)在原图像上依次滑动,在两者重叠的区域中,把对应位置的像素值和卷积模板值相乘,最后累加求和得到新图像(卷积结果)中的一个像素值,卷积核每滑动一次获得一个新值,当完成原图像的全部遍历,便完成原图像的一次卷积
下图所示为网络搜集的一些卷积操作示意图(侵删)
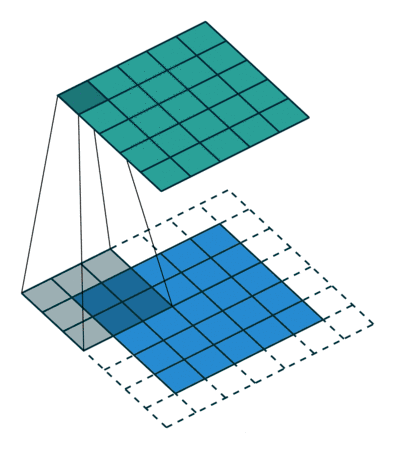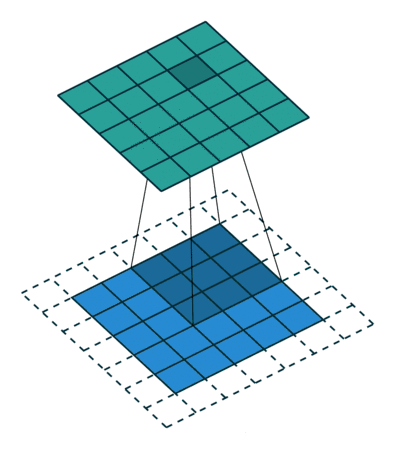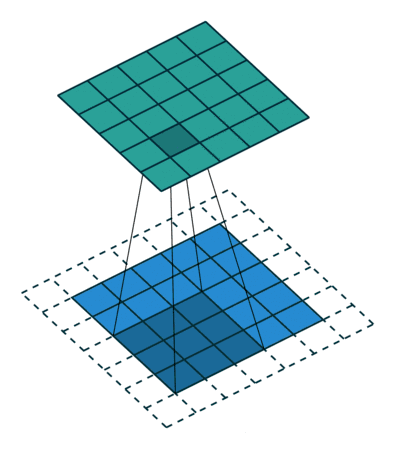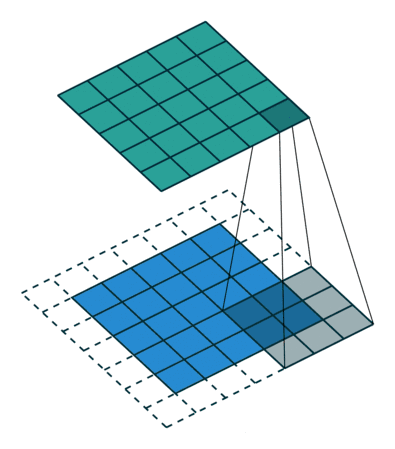 图4 图4
|
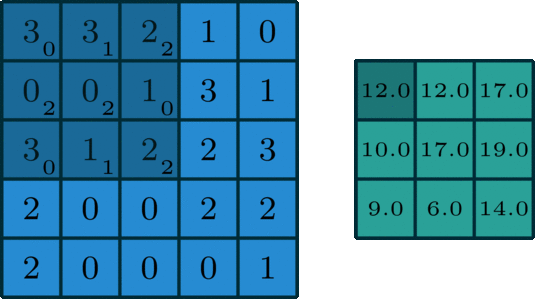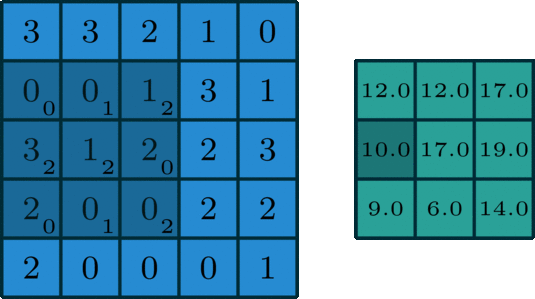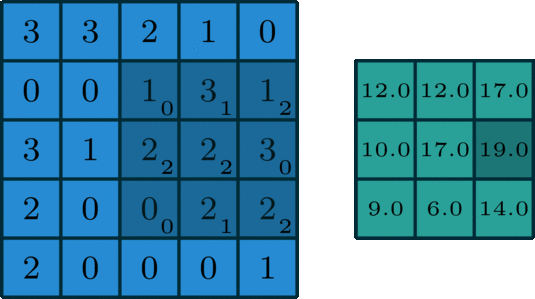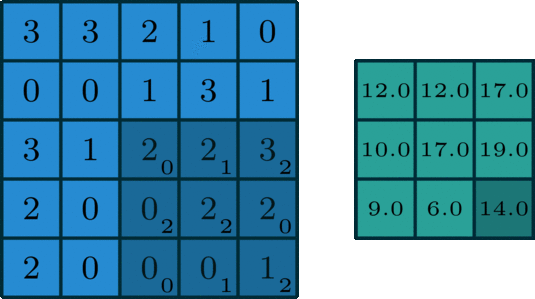 图5 图5
|
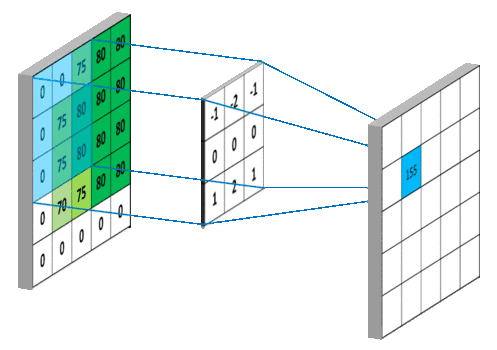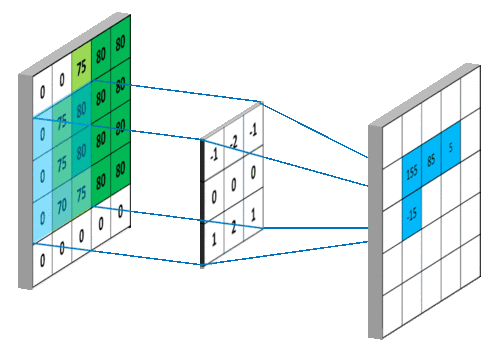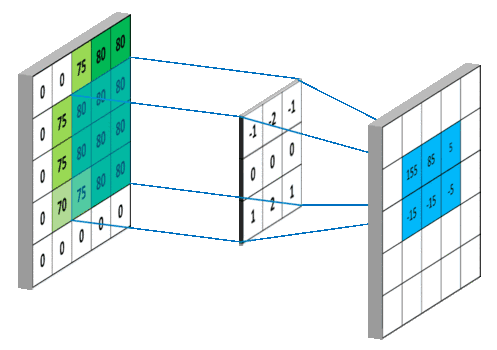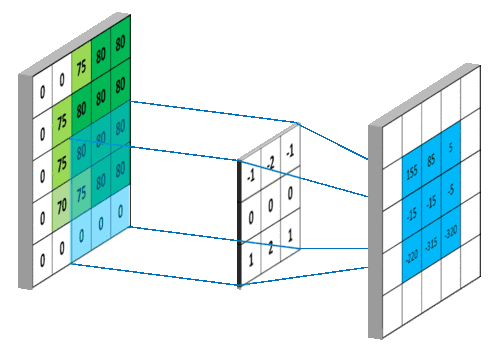 图6 图6
|
 图7 图7
|
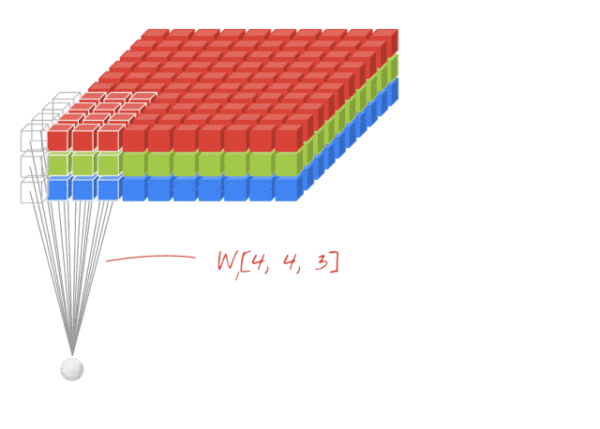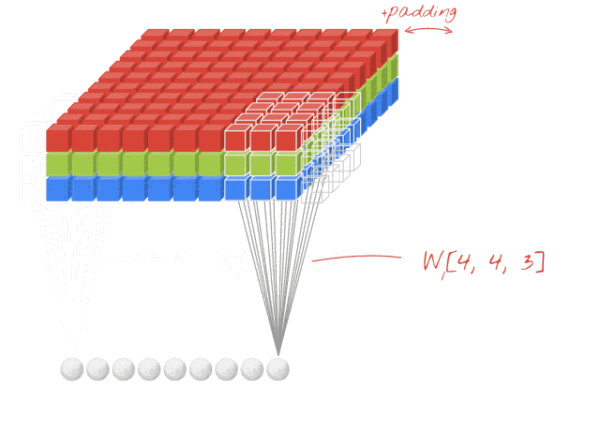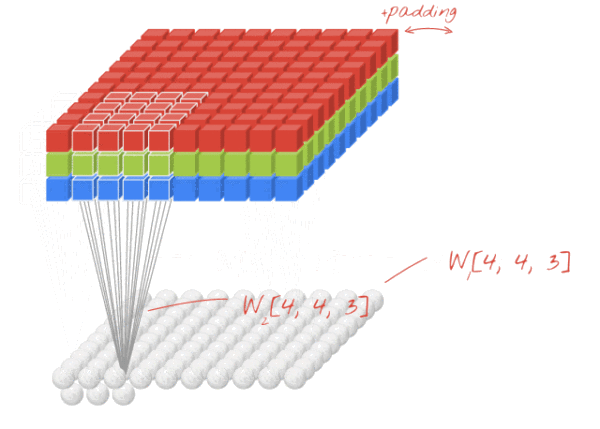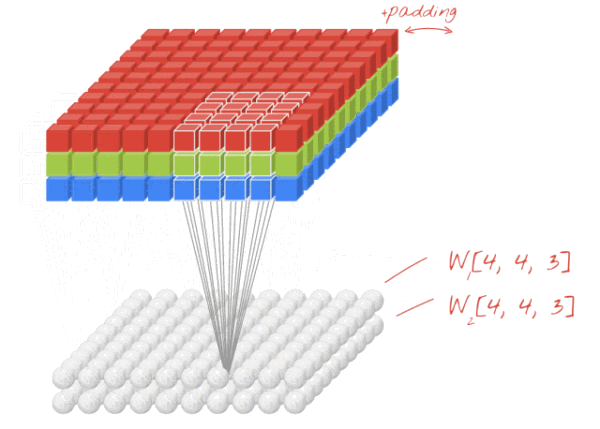 图8 图8
|
传统数字图像处理方法中,一般输入图像为灰度图像,通道为1,因此图像卷积操作中卷积核深度为1,为一个(s×s)的二维矩阵,而在CNN中,由于每一层(包含彩色图像输入层)图像存在多个通道(feature map),每一个通道图像均需要一个卷积核,分别对各自通道进行卷积,然后将各个通道卷积的结果线性叠加形成新的图像作为卷积结果(feature map),例:设卷积输入层图像为[128×128×12],输出层图像为[128×128×24](假设padding,stride,dilation设置满足需求),卷积核size为5,则卷积核的规模为[5×5×12],卷积核的个数为24。
padding:原图像的补0边数,卷积操作中,为了满足原图像边缘位置在卷积后的图像中存在一个对应位置,给原图像增加几条补0边。第一个卷积示意图中虚线边。
stride:卷积操作中每次卷积核滑动的步长
dilation:卷积核的间隔,如一个[3×3]的卷积核,如果dilation为1,则实际卷积过程中卷积核覆盖的区域为[5×5]
图像卷积输出大小计算:不同的卷积核参数导致输出的图像(feature map)大小存在多种可能(指图像的H和W,C不受影响),以PyTorch框架下的设置为例,PyTorch中卷积核需要设置的参数有size,padding,stride和dilation,每个参数包括H,W两个方向。具体如下:
H
o
u
t
=
[
H
i
n
+
2
×
p
a
d
d
i
n
g
h
−
d
i
l
a
t
i
o
n
h
×
(
s
i
z
e
h
−
1
)
−
1
s
t
r
i
d
e
h
]
+
1
H_{out}=[\frac{H_{in}+2{\times}{\rm padding}_{h}-{\rm dilation_{h}{\times}({\rm size}_{h}-1)-1}}{{\rm stride}_{h}}]+1
Hout=[stridehHin+2×paddingh−dilationh×(sizeh−1)−1]+1
W
o
u
t
=
[
W
i
n
+
2
×
p
a
d
d
i
n
g
w
−
d
i
l
a
t
i
o
n
w
×
(
s
i
z
e
w
−
1
)
−
1
s
t
r
i
d
e
w
]
+
1
W_{out}=[\frac{W_{in}+2{\times}{\rm padding}_{w}-{\rm dilation_{w}{\times}({\rm size}_{w}-1)-1}}{{\rm stride}_{w}}]+1
Wout=[stridewWin+2×paddingw−dilationw×(sizew−1)−1]+1
激活函数(activation function)
激活函数主要引入非线性特性,简单的说就是在卷积过程中,所有的运算都是线性运算和线性叠加,无论网络多复杂,输入输出关系都是线性关系,没有激活函数,网络就无法拟合非线性特性的输入输出关系,常用的激活函数有Sigmoid,Tanh,ReLU等。
在CNN中,卷积核的每一次卷积在累加模板内各个位置的乘积后,将累加值输入激活函数,然后将输出值作为卷积结果。
池化(pooling)
下图所示为一个2×2 Max pooling计算示意图
 图9 池化 图9 池化
|
全连接(fully connected)
上文所述,全连接就是将输入的所有节点数据与输出的所有节点数据相连,其结构类似BP神经网络,在CNN中体现为将卷积图像映射至一个n维向量,通过设置多个全连接关系,起到从特征到分类的作用。在上图FC1层中,输入为一个[32×32×12]矩阵,输出为一个[128×1]的矩阵,则输出矩阵中的每1个节点都与输入矩阵32×32××12=12288个节点建立了映射关系,总共为12288×128=1572864个映射关系,可见所需的参数非常大。
一个简单的CNN
还是以下图CNN结构为例,介绍其每一层的计算过程
|
图10 CNN
|
- 输入一张128×128的彩色图像,以RGB格式解析数据的话,其形式为一个[
128×128×3]的矩阵; - conv1中,卷积核size为3×3,共6个卷积核,所以conv1的输出图像为6通道(6个feature map)128×128图像(假设padding,stride,dilation设置合理),即conv1的输出为一个[
128×128×6]的矩阵,因为conv1的输入为3通道图像,所以conv1中卷积核的深度为3 - 池化层,采用了一个2×2的Max pooling,所以输入图像的通道数不变,尺寸÷2,即输出图像为一个[64×64×6]的矩阵
- conv2中,卷积核size为
3×3,共12个卷积核,所以conv2的输出图像为12通道(12个feature map)64×64图像,一个[64×64×12]的矩阵,conv2的卷积核深度和conv1输出图像通道数一致为6 - 池化,
2×2的Max pooling,输出为一个[32×32×12]的矩阵 - FC1,输入为一个[
32×32×12]的矩阵,输出为一个[128×1]的矩阵,该层首先将输入矩阵展开成一个32×32×12=12288的一维列向量(数组形式),然后将每个数据对128个输出数据做映射,总共是12288×128=1572864个映射关系,每个映射需要一个权重系数,总共是1572864个 - FC2,和FC1一样,将
128维列向量映射至10维列向量,10维表示输出目标有10种,每个维度的值表示CNN结构输入图像属于该维目标的可能性(若输出值做了softmax计算)
网络设计
回到Dogs vs. Cats问题,其任务为设计一个分类算法,对猫狗图像进行识别。目前,有许多成熟的分类学习方法,本文主要介绍CNN的入门,因此选择了最简单的CNN结构进行讲解,具体网络层设计参考了Guoqing Xu的Github代码。
具体网络结构如下图所示,由2个卷积层和3个全连层组成:
 图11 本文用到的CNN结构 图11 本文用到的CNN结构
|
- Input:图像尺寸为
200×200像素,由于训练集和测试集中的图片大小尺寸多样,因此在送入网络前,须将图片调整至200×200像素 - conv1:卷积核的规模为[
3×3×3×16],size大小3×3,深度3,数量16 - 第一次卷积结果:
16个卷积图像(feature map),200×200像素 - Pooling:第一次池化,size大小
2×2,Max pooling - 第一次池化结果:图像缩小为
100×100像素 - conv2:卷积核的规模为[
3×3×16×16],size大小3×3,深度16,数量16 - 第二次卷积结果:
16个卷积图像(feature map),100×100像素 - Pooling:第二次池化,size大小
2×2,Max pooling - 第二次池化结果:图像缩小为
50×50像素 - FC1:第一次全连接,输入节点数为50×50×16=
40000,输出节点数为128,输出数据为[128×1] - FC2:第二次全连接,输入节点数为
128,输出节点数为64,输出数据为[64×1] - FC3:第三次全连接,输入节点数为
64,输出节点数为2,即两个数值,分别表示猫和狗的概率(通过softmax方法进行了转换)
注:上述卷积过程中通过设置padding,stride,dilation,size的参数,使得输入输出图像尺寸一致
PyTorch实现
PyTorch一点介绍
PyTorch和TensorFlow,caffe一样,是一种深度学习框架,简单的说就是python编程环境下的一个函数库,通过调用函数接口可以方便的搭建各种网络,进行训练,测试和分析。(深度网络在学习中的主要两个步骤是前向计算误差和误差反向传播,如在复杂的网络中,如果没有上述框架,自己写代码实现是十分复杂和困难的)
PyTorh中一个基本的概念是数据以Tensor(张量)形式存在,刚接触时理解可能有些困难,网上有很多关于张量的介绍,本质上讲,Tensor就是一个存数据的地方,0维Tensor是标量(单个数值),1维Tensor是向量,2维Tensor是矩阵,……,因此可以把Tensor理解为一个N维数组。
实现步骤
在深度学习框架下,搭建一个网络进行训练和测试十分方便,主要包括三个步骤:
- 准备数据,将数据集中的数据整理成程序代码可识别读取的形式
- 搭建网络,利用PyTorch提供的API搭建设计的网络
- 训练网络,把1中准备好的数据送入2中搭建的网络中进行训练,获得网络各节点权值参数
- 测试网络,导入3中获取的参数,并输入网络一个数据,然后评估网络的输出结果
代码实现
开始下文之前,确保电脑能够正确运行Python和PyTorch环境,并且已经下载好Dogs vs. Cats的训练集和测试集,然后下载程序代码,代码主要包括4个文件,getdata.py,network.py,train.py,test.py
准备数据
关于网络的学习思想,通俗一点的说法是:给网络一个输入,并告诉它输出应该是什么,然后网络按照特定的规则去调整自己的内部参数,使得自己实际计算的输出不断逼近给定的输出。因此,在准备数据阶段,需要做的就是把训练集中所有的数据整理成[输入, 给定输出]的形式,在Dogs vs. Cats中,输入为一张张猫狗图片(input),给定输出是对应的猫或者狗信息(label)。
在图1训练集中,可以看出,训练集的图片有25000张,猫狗各125000张,猫的图片命名方式为“cat.0.jpg”“cat.1.jpg”“cat.2.jpg”……“cat.12499.jpg”,狗的图片命令方式为“dog.0.jpg”“dog.1.jpg”“dog.2.jpg”……“dog.12499.jpg”,因此需要记录每一张照片的内容和其所属类别(猫或狗)。
代码如下 :
# getdata.py import os import torch.utils.data as data from PIL import Image import numpy as np import torch import torchvision.transforms as transforms # 默认输入网络的图片大小 IMAGE_H = 200 IMAGE_W = 200 # 定义一个转换关系,用于将图像数据转换成PyTorch的Tensor形式 data_transform = transforms.Compose([ transforms.ToTensor() # 转换成Tensor形式,并且数值归一化到[0.0, 1.0] ]) class DogsVSCatsDataset(data.Dataset): # 新建一个数据集类,并且需要继承PyTorch中的data.Dataset父类 def __init__(self, mode, dir): # 默认构造函数,传入数据集类别(训练或测试),以及数据集路径 self.mode = mode self.list_img = [] # 新建一个image list,用于存放图片路径,注意是图片路径 self.list_label = [] # 新建一个label list,用于存放图片对应猫或狗的标签,其中数值0表示猫,1表示狗 self.data_size = 0 # 记录数据集大小 self.transform = data_transform # 转换关系 if self.mode == 'train': # 训练集模式下,需要提取图片的路径和标签 dir = dir + '/train/' # 训练集路径在"dir"/train/ for file in os.listdir(dir): # 遍历dir文件夹 self.list_img.append(dir + file) # 将图片路径和文件名添加至image list self.data_size += 1 # 数据集增1 name = file.split(sep='.') # 分割文件名,"cat.0.jpg"将分割成"cat",".","jpg"3个元素 # label采用one-hot编码,"1,0"表示猫,"0,1"表示狗,任何情况只有一个位置为"1",在采用CrossEntropyLoss()计算Loss情况下,label只需要输入"1"的索引,即猫应输入0,狗应输入1 if name[0] == 'cat': self.list_label.append(0) # 图片为猫,label为0 else: self.list_label.append(1) # 图片为狗,label为1,注意:list_img和list_label中的内容是一一配对的 elif self.mode == 'test': # 测试集模式下,只需要提取图片路径就行 dir = dir + '/test/' # 测试集路径为"dir"/test/ for file in os.listdir(dir): self.list_img.append(dir + file) # 添加图片路径至image list self.data_size += 1 self.list_label.append(2) # 添加2作为label,实际未用到,也无意义 else: return print('Undefined Dataset!') def __getitem__(self, item): # 重载data.Dataset父类方法,获取数据集中数据内容 if self.mode == 'train': # 训练集模式下需要读取数据集的image和label img = Image.open(self.list_img[item]) # 打开图片 img = img.resize((IMAGE_H, IMAGE_W)) # 将图片resize成统一大小 img = np.array(img)[:, :, :3] # 数据转换成numpy数组形式 label = self.list_label[item] # 获取image对应的label return self.transform(img), torch.LongTensor([label]) # 将image和label转换成PyTorch形式并返回 elif self.mode == 'test': # 测试集只需读取image img = Image.open(self.list_img[item]) img = img.resize((IMAGE_H, IMAGE_W)) img = np.array(img)[:, :, :3] return self.transform(img) # 只返回image else: print('None') def __len__(self): return self.data_size # 返回数据集大小

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
数据的准备过程为自定义一个数据集类,需要继承PyTorch的data.Dataset父类,然后在类的构造方法中载入数据集中全部数据,这一步可以只导入数据文件名,不用将数据全部导入内存中。需要注意的是,必须要重载父类的__getitem__()方法,因为默认的PyTorch数据集读取就是通过这个方法来实现的,在这个方法中需要返回PyTorch的Tensor形式数据。
新手在写PyTorch代码时,遇到的最大困难应该是各个类型数据之间的转换,像Python基本数据,整型,数组,PyTorch中的张量,不同维度之间的读取,数据的创建,等等,这些内容可以参考网上资料,但最重要的是一定要自己手动敲代码,多去尝试,这样的理解才会深刻。
需要注意的是数据集label的设定,本代码采用了one-hot编码方式,猫的编码为"[1,0]",狗的编码为"[0, 1]",网络输出两个值,分别为属于猫和狗的概率(两者相加恒等于1),如[0.9, 0.1],猫的概率为90%,狗的概率为10%,在数值上十分相似,在训练阶段也是采用交叉熵作为损失函数Loss,衡量两者之间的差异。按理说,猫的label应该是[1, 0],狗的label是[0, 1],但在本文采用的损失函数CrossEntropyLoss()中,第二个参数target(输入的label参数)是1维Tensor,其长度为输入样本的个数,每个值表示样本中出现1的索引,比如在一个4类别分类方法中,
输入[2, 3, 0],表示3个样本,分别为[0, 0, 1, 0],[0, 0, 0, 1]和[1, 0, 0, 0]
输入[3, 1, 1, 2, 0],表示5个样本,分别为[0, 0, 0, 1],[0, 1, 0, 0],[0, 1, 0, 0],[0, 0, 2, 0]和[1, 0, 0, 0]
因此,数据集中,猫的label为0,狗的label为1,这样做是为了便于计算。
搭建网络
按照网络设计中的CNN结构,调用PyTorch语句搭建网络
# network.py import torch import torch.nn as nn import torch.utils.data import torch.nn.functional as F class Net(nn.Module): # 新建一个网络类,就是需要搭建的网络,必须继承PyTorch的nn.Module父类 def __init__(self): # 构造函数,用于设定网络层 super(Net, self).__init__() # 标准语句 self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1) # 第一个卷积层,输入通道数3,输出通道数16,卷积核大小3×3,padding大小1,其他参数默认 self.conv2 = torch.nn.Conv2d(16, 16, 3, padding=1) # 第二个卷积层,输入通道数16,输出通道数16,卷积核大小3×3,padding大小1,其他参数默认 self.fc1 = nn.Linear(50*50*16, 128) # 第一个全连层,线性连接,输入节点数50×50×16,输出节点数128 self.fc2 = nn.Linear(128, 64) # 第二个全连层,线性连接,输入节点数128,输出节点数64 self.fc3 = nn.Linear(64, 2) # 第三个全连层,线性连接,输入节点数64,输出节点数2 def forward(self, x): # 重写父类forward方法,即前向计算,通过该方法获取网络输入数据后的输出值 x = self.conv1(x) # 第一次卷积 x = F.relu(x) # 第一次卷积结果经过ReLU激活函数处理 x = F.max_pool2d(x, 2) # 第一次池化,池化大小2×2,方式Max pooling x = self.conv2(x) # 第二次卷积 x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理 x = F.max_pool2d(x, 2) # 第二次池化,池化大小2×2,方式Max pooling x = x.view(x.size()[0], -1) # 由于全连层输入的是一维张量,因此需要对输入的[50×50×16]格式数据排列成[40000×1]形式 x = F.relu(self.fc1(x)) # 第一次全连,ReLU激活 x = F.relu(self.fc2(x)) # 第二次全连,ReLU激活 x = self.fc3(x) # 第三次激活 return F.softmax(x, dim=1) # 采用SoftMax方法将输出的2个输出值调整至[0.0, 1.0],两者和为1,并返回
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
新建的网络必须要继承PyTorch的nn.Module父类,并在构造函数中新建CNN中的各个计算层,包括卷积层,池化层,全连层和激活函数等。此外,需要重载父类的forward()方法,该方法就是网络运算中的前向计算
训练网络
在训练网络前,需要了解训练过程中涉及到的几个概念,epoch,batch size和iteration。从通俗的角度出发,网络学习可以理解成给网络一个输入(image)一个输出(label),然后让调整网络的参数(参数优化),使其内部输出值(网络的前向计算)和给定的输出值差异(损失Loss)最小,显然每给定一个输入都可以完成一次参数调整。但如果对每个输入都做一次调整,参数调整的波动会比较大,一些包含噪声的输入会产生错误的参数调整,网络难以取得较好效果,因此,就会想到给网络输入一些训练数据,累加它们的输出,再与给定的label比较计算Loss,最后做一次调整,而这一些的大小就是batch size。在Dogs vs. Cats训练集中,一共有25000个图片,都可以拿来做训练,如果全部图片都训练过了,就认为完成了1个epoch,即epoch表示整个数据集进了多少次重复训练,如果batch size设为100,那么网络参数总共调整的参数为25000/100=250次,而250就是指的是iteration,也即1个epoch中网络参数调整(迭代)的次数。当然,batch size也不是越大越好,太大了会使网络参数调整缓慢,收敛慢,并且资源消耗也会提高。
训练代码如下,因为仅作测试,代码的epoch为1,即全部数据只做了一次训练。
# train.py from getdata import DogsVSCatsDataset as DVCD from torch.utils.data import DataLoader as DataLoader from network import Net import torch from torch.autograd import Variable import torch.nn as nn dataset_dir = './data/' # 数据集路径 model_cp = './model/' # 网络参数保存位置 workers = 10 # PyTorch读取数据线程数量 batch_size = 16 # batch_size大小 lr = 0.0001 # 学习率 def train(): datafile = DVCD('train', dataset_dir) # 实例化一个数据集 dataloader = DataLoader(datafile, batch_size=batch_size, shuffle=True, num_workers=workers) # 用PyTorch的DataLoader类封装,实现数据集顺序打乱,多线程读取,一次取多个数据等效果 print('Dataset loaded! length of train set is {0}'.format(len(datafile))) model = Net() # 实例化一个网络 model = model.cuda() # 网络送入GPU,即采用GPU计算,如果没有GPU加速,可以去掉".cuda()" model.train() # 网络设定为训练模式,有两种模式可选,.train()和.eval(),训练模式和评估模式,区别就是训练模式采用了dropout策略,可以放置网络过拟合 optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 实例化一个优化器,即调整网络参数,优化方式为adam方法 criterion = torch.nn.CrossEntropyLoss() # 定义loss计算方法,cross entropy,交叉熵,可以理解为两者数值越接近其值越小 cnt = 0 # 训练图片数量 # 读取数据集中数据进行训练,因为dataloader的batch_size设置为16,所以每次读取的数据量为16,即img包含了16个图像,label有16个 for img, label in dataloader: # 循环读取封装后的数据集,其实就是调用了数据集中的__getitem__()方法,只是返回数据格式进行了一次封装 img, label = Variable(img).cuda(), Variable(label).cuda() # 将数据放置在PyTorch的Variable节点中,并送入GPU中作为网络计算起点 out = model(img) # 计算网络输出值,就是输入网络一个图像数据,输出猫和狗的概率,调用了网络中的forward()方法 loss = criterion(out, label.squeeze()) # 计算损失,也就是网络输出值和实际label的差异,显然差异越小说明网络拟合效果越好,此处需要注意的是第二个参数,必须是一个1维Tensor loss.backward() # 误差反向传播,采用求导的方式,计算网络中每个节点参数的梯度,显然梯度越大说明参数设置不合理,需要调整 optimizer.step() # 优化采用设定的优化方法对网络中的各个参数进行调整 optimizer.zero_grad() # 清除优化器中的梯度以便下一次计算,因为优化器默认会保留,不清除的话,每次计算梯度都回累加 cnt += 1 print('Frame {0}, train_loss {1}'.format(cnt*batch_size, loss/batch_size)) # 打印一个batch size的训练结果 torch.save(model.state_dict(), '{0}/model.pth'.format(model_cp)) # 训练所有数据后,保存网络的参数 if __name__ == '__main__': train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
在代码中,DataLoader()的作用是对定义好的数据集类做一次封装,由PyTorch内部执行,有以下几个作用:
- 可以定义为打乱数据集分布,使各个类型的样本均匀地参与网络训练;
- 可以设定多线程数据读取(指数据载入内存),提高训练效率,因为训练过程中文件的读取是比较耗时的
- 可以一次获得batch size大小的数据,并且是Tensor形式,比如读取4个训练数据,需要调用
__getitem__()4次,但是封装好后,在for img, label in dataloader:中,一次img可以获得4个(假设batch size为4)数据,这也就是为什么代码中img的size是[16×3×200×200],而直接调用__getitem__()是[3×200×200]的原因,因为DataLoader封装过程中加入了一维数据个数
当然,不用DataLoader封装也是可以的(测试代码中就没有),只是处理起来比较麻烦
Variable()的理解,在代码出现了这个,可以把它理解为定义一个符号,一个未知数,然后网络中的所有计算方式都用这个符号来表示,最终网络计算形成一个由Variable()组成的复杂计算公式,只要将实际数据代入Variable,便可快速求出结果,并且,求导也十分方便,因为都是符号,可以调用求导公式,当然这些都是内部计算过程,外部看不到,有点类似一元一次线性回归问题中,先定义X,Y,在把k,b的计算表示X,Y的计算公式,最后带入数据,求得k,b值。
需要注意的是代码loss = criterion(out, label.squeeze())中的.squeeze()方法,因为从dataloader中获取的label是一个[batch size ×1]的Tensor,而实际输入的应是1维Tensor,所以需要做一个维度变换。
另外,如果没有GPU做计算的话,可以去掉代码中的.cuda()
训练完成后,就得到了网络的参数,可以做后续测试实验
测试网络
将训练好的网络参数导入新定义的网络中,然后输入图像完成猫狗分类任务,代码如下
from getdata import DogsVSCatsDataset as DVCD from network import Net import torch from torch.autograd import Variable import numpy as np import matplotlib.pyplot as plt from PIL import Image dataset_dir = './data/' # 数据集路径 model_file = './model/model.pth' # 模型保存路径 def test(): model = Net() # 实例化一个网络 model.cuda() # 送入GPU,利用GPU计算 model.load_state_dict(torch.load(model_file)) # 加载训练好的模型参数 model.eval() # 设定为评估模式,即计算过程中不要dropout datafile = DVCD('test', dataset_dir) # 实例化一个数据集 print('Dataset loaded! length of train set is {0}'.format(len(datafile))) index = np.random.randint(0, datafile.data_size, 1)[0] # 获取一个随机数,即随机从数据集中获取一个测试图片 img = datafile.__getitem__(index) # 获取一个图像 img = img.unsqueeze(0) # 因为网络的输入是一个4维Tensor,3维数据,1维样本大小,所以直接获取的图像数据需要增加1个维度 img = Variable(img).cuda() # 将数据放置在PyTorch的Variable节点中,并送入GPU中作为网络计算起点 out = model(img) # 网路前向计算,输出图片属于猫或狗的概率,第一列维猫的概率,第二列为狗的概率 print(out) # 输出该图像属于猫或狗的概率 if out[0, 0] > out[0, 1]: # 猫的概率大于狗 print('the image is a cat') else: # 猫的概率小于狗 print('the image is a dog') img = Image.open(datafile.list_img[index]) # 打开测试的图片 plt.figure('image') # 利用matplotlib库显示图片 plt.imshow(img) plt.show() if __name__ == '__main__': test()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
因为测试集数据没有经过DataLoader封装,在数据送入网络计算时需要增加1维样本数量信息
代码运行步骤
- 先将代码中各个文件夹路径进行修改
- 训练时,运行
train.py - 测试时,运行
test.py
实验结果
训练结果
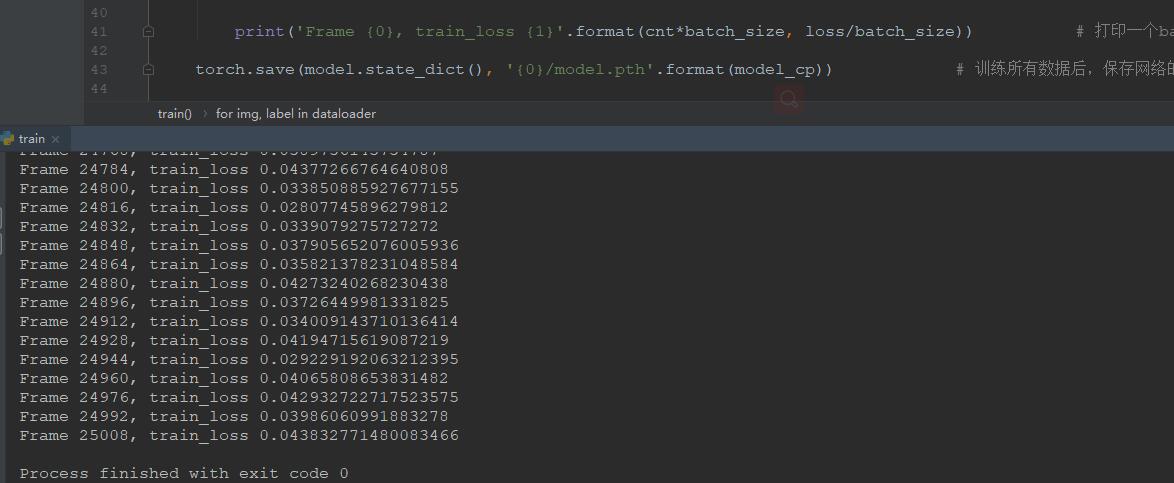 图12 训练结果 图12 训练结果
|
测试结果
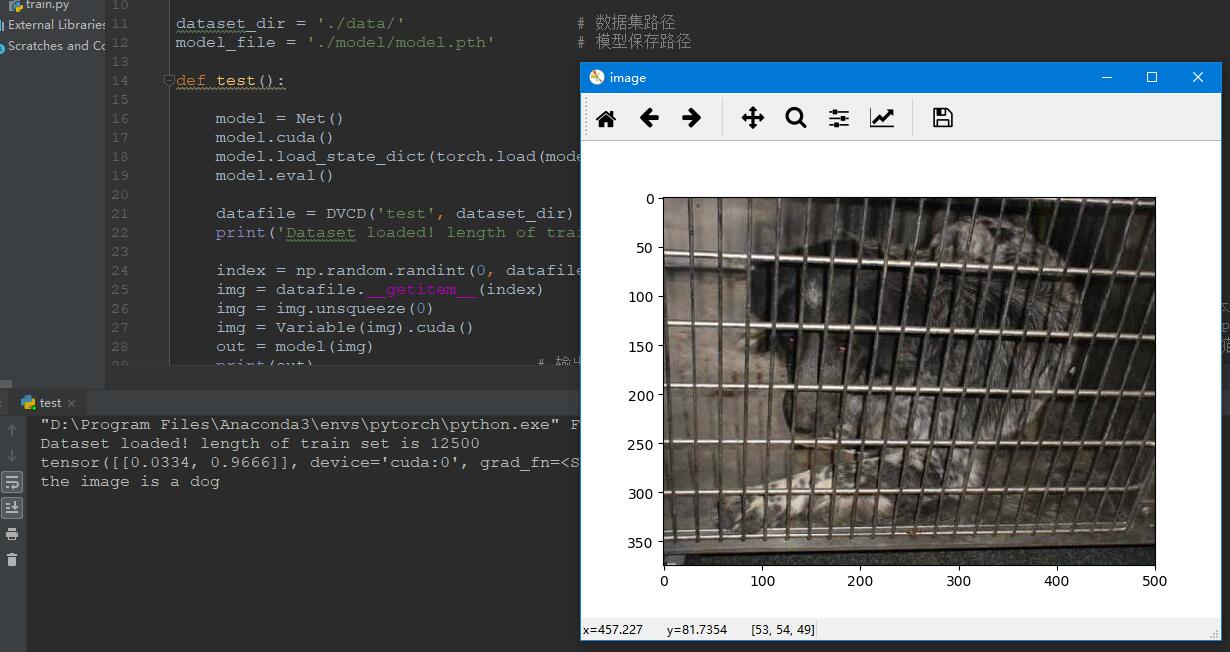 图13 正确分类 图13 正确分类
|
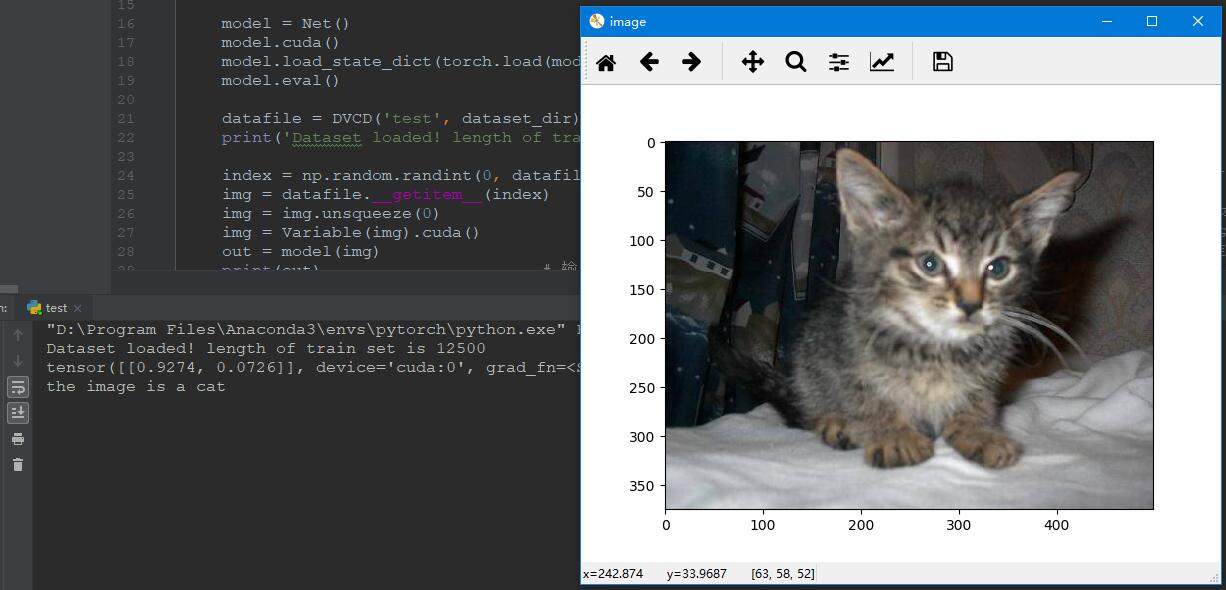 图14 正确分类 图14 正确分类
|
当然也有判断错误的情况
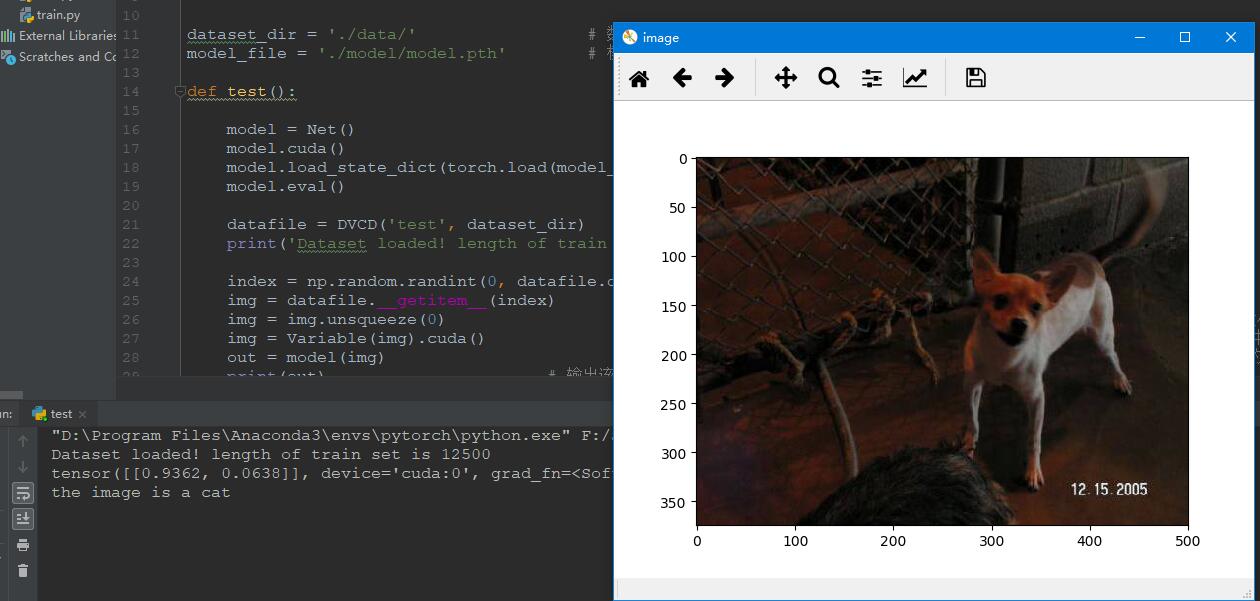 图15 分类错误 图15 分类错误
|
参考
- pytorch学习笔记(1)—基本类型、运算和简单模型
- PyTorch中的nn.Conv1d与nn.Conv2d
- CNN中feature map、卷积核、卷积核个数、filter、channel的概念解释,以及CNN 学习过程中卷积核更新的理解
- 直观地学习并理解用于深度学习的卷积
- CNN的学习笔记(一)
- 一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉
- 卷积神经网络CNN(1)——图像卷积与反卷积(后卷积,转置卷积)
- Pytorch之Variable
- pytorch之dataloader深入剖析
- 【学习笔记】pytorch中squeeze()和unsqueeze()函数介绍
- 卷积神经网络系列之softmax,softmax loss和cross entropy的讲解

