
- 1QT 显示USB摄像头数据_qt usb 摄像头 获取画面
- 2nodejs sqlite模块
- 3FFmpeg安装与配置(windows与mac)_ffmpeg环境配置
- 4EM算法_斯坦福CS229_学习笔记_em算法会陷入局部极小值吗
- 5推荐一款M1电脑可用的虚拟机软件_m1 你能用的虚拟机器
- 6DeepMind CEO称AI智力不如猫!LeCun持相同看法!曝光谷歌新项目AI将突破聊天限制
- 7LightGBM算法——广告收益回归预测模型_lightgbm 回归模型
- 8苹果WWDC揭晓AI系统、电脑等设备系统全线更新,iPhone将接入ChatGPT_ios18 game mode
- 9Random rand = new Random(47);
- 10AI大语言模型的模型教育与培训_大语言模型培训
脑启发遥感解译:一个全面的调查_遥感识别物体需要几个像素信号
赞
踩
Brain-inspired Remote Sensing Interpretation: A Comprehensive Survey
脑启发遥感解译:一个全面的调查
摘要:基于大脑的算法已经成为下一代人工智能的新趋势。通过对脑科学的研究,可以有效提高遥感算法的智能化。综述和分析了脑认知学习的基本性质和遥感解译研究的最新进展。本文首先介绍了大脑的结构组成和性质。然后,研究了五种代表性的脑启发算法,包括多尺度几何分析、压缩感知、注意机制、强化学习和迁移学习。其次,本文综述了遥感数据类型、遥感解译典型应用的发展和遥感实现,包括遥感数据集、软件和硬件。最后,讨论了脑启发遥感解译的十大有待解决的问题和未来的发展方向。本工作旨在全面回顾脑机制和遥感的发展,并为脑启发遥感解译的未来研究提供动力。
I. INTRODUCTION
遥感是一种利用飞机或卫星上的传感器对地球上的物体进行观测和探测的技术[1,2]。这是一种非接触式的远程探测技术,始于20世纪60年代[3]。它利用可见光、红外线和电磁波的辐射或目标本身的反射来感知和识别远距离的目标。遥感技术获取的遥感数据提高了人类对地球[4]的研究能力。同时,遥感应用涉及许多领域。广泛应用于卫星监测、国土资源调查、土地利用与土地覆盖、城市动态变化监测、气象监测、环境评估与监测、灾害调查与评价等军民领域。这极大地扩大了遥感对人类生产和生活的关键影响。
目前,遥感解译面临着许多挑战。首先,由于近年来无人机(UAV)和卫星技术的快速增长,数据量急剧增加。数据的光谱、空间和时间维度需要更多的计算资源[7]。此外,遥感中的大型标注数据集不易获得。这限制了使用更大的模型来提高算法的准确性。最后,算法的可解释性对遥感解译[8]是必要的。
近年来,人工智能技术提高了遥感解译的精度和效率。面对海量、复杂、多样的遥感数据,人工智能实现了特征的自动提取、参数学习和分类。
人工智能的目标是研究和开发能够处理需要人类智能的任务的计算机算法。它的发展与脑科学密切相关。脑科学是研究生物大脑的结构、功能和运行机制,进一步了解大脑是如何处理信息、挖掘知识、做出决策的。人工智能从脑科学中汲取灵感,设计智能算法。
1943年,神经学家W.S. mcclilloch和数学家W.S. Pitts建立了MP模型,这是一种根据生物神经元的结构和工作原理构造的抽象简化模型。所谓的“模拟大脑”诞生于[10]。1949年,赫比学习被提出。这个算法的灵感来自于生物神经系统的动力学。根据这项研究,当突触两侧的神经元(输入和输出)有高度相关的输出时,两个神经元之间的突触就会加强。Hebbian学习利用这一特性,在学习过程中提高了两个高度相关神经元之间的权值。1958年,感知器被提出,用来模拟大脑中信息的存储和组织方式[12]。1983年,物理学家John Hopfield提出了一种用于联想记忆的神经网络,叫做Hopfield网络[13]。2006年,Geoffrey Hinton提出了一种用于数据还原的多层神经网络,揭开了深度学习研究的序幕[14]。
人工智能的研究与大脑密切相关。这些算法,受到大脑结构和特征的启发,继续推动人工智能的发展。人工智能也在不断地从生物大脑中寻找新的灵感。
A. Motivation
近年来,随着越来越多的神经网络被提出,人们越来越关注脑启发算法的设计,并提出了许多脑启发算法的综述。Hassabis等人[15]分析了人工智能与神经科学领域的历史相互作用,为人工智能的发展提供了新的视角。在[16]中,对脑启发人工智能及其相关工程技术的研究进行了全面的综述。在[17]中,它专注于神经科学研究和计算机视觉进展之间的关系。Simeone等人组织了一个特别的部分来介绍机器学习(ML)和脑启发计算[18]的信号处理算法。在[9]中,研究新的大脑成像技术,探索脑科学的秘密,构建大脑动态连接图。Jiao等人的[19]讨论了生物启发计算和识别的主要问题和应用,介绍了算法实现、模型仿真和参数设置的实际应用。[20]中介绍了人工智能与神经科学的关系、脑启发智能的研究现状以及人工智能在其他领域的深远影响。
大脑和受大脑启发的算法的特点值得讨论。脑启发算法是根据最新的大脑特征研究而开发的,提高了算法的性能、效率和可解释性。这将为遥感解译提供一个新的视角。在这篇综述中,我们主要研究了大脑的特征,并介绍了相关的脑启发算法。此外,解释(遥感的数据类型和主要应用)和实现(公共数据集,软件和硬件)介绍。我们试图总结大脑的特征,讨论遥感任务,为读者提供遥感数据分析的新视角,促进脑启发算法的设计。本审查的主要贡献可概括如下:
(1)我们对大脑结构进行了全面的调查,并总结了大脑的特性,如稀疏性、学习机制、选择性、方向性、可塑性和多样性。
(2)研究了遥感数据解译的5个基本应用,包括目标分类、目标检测、变化检测、视频跟踪和三维重建。这些方法包括遥感中的图像任务,以及近年来发展起来的视频和点云数据。
(3)总结了公共数据集和相关软硬件概述。(4)提出了当前面临的挑战和未来的研究方向。
本文的组织结构如下(如图1所示)。第二节和第三节介绍了大脑的基本结构和特点以及脑启发算法。第四节对光学图像、雷达图像、机载激光雷达和遥感视频等数据类型进行了总结。此外,还介绍了遥感技术在五种应用领域的最新进展。在第五节中,讨论了实现算法所需的公共数据集、软件平台和硬件资源。最后,第六节讨论了脑机制与遥感解译相结合的未来挑战和发展方向。
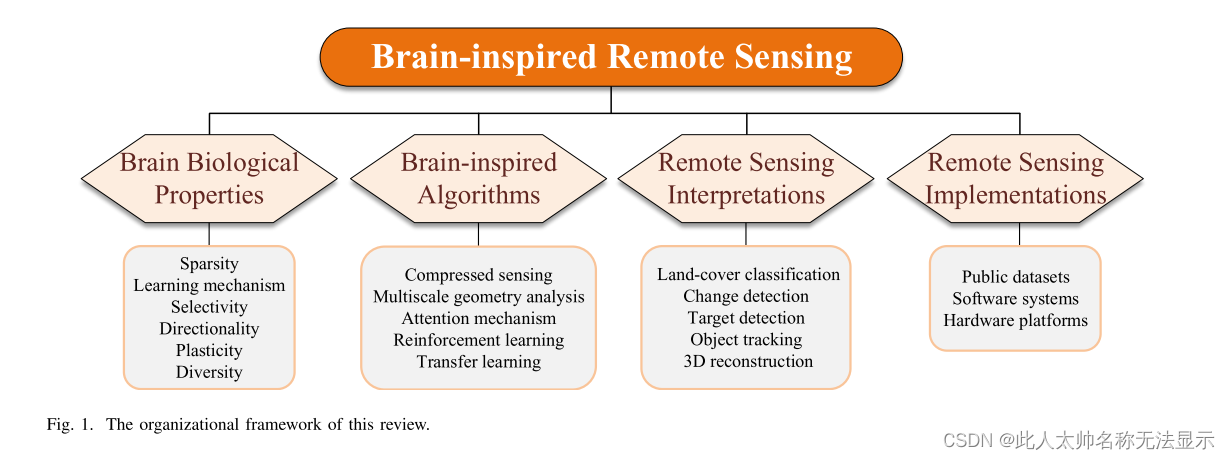
II. THE THEORY OF THE BRAIN
ii。大脑理论
A.大脑的生物结构
大脑是中枢神经系统的主要器官。它主要由大脑皮层、小脑、间脑和脑干组成。其中,大脑皮层是意识思维和感觉处理的最先进的部分,也是大脑的主要部分。它有识别、表现和学习的能力。它包括四个功能区:颞叶、枕叶、额叶和顶叶[21]。具体划分如下图2所示。
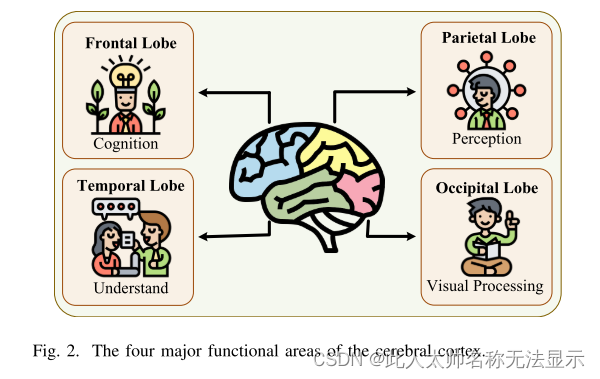
(1)枕叶:是大脑的视觉处理中心,包括低水平的视觉空间处理(位置、空间频率)、颜色辨别、运动感知。(2)颞叶:它负责处理感官输入,使用视觉记忆、语言和情感联系获得更高层次的信息。(3)顶叶:它可以处理各种感觉信息,包括触觉、嗅觉、味觉等。它也与语言和记忆有关。(4)额叶:大脑发育最先进的部分,具有先进的认知功能。它主要负责运动、认知和思考的过程。它能够完成注意力、判断、思考、分析、计算和计划等任务,与人类的需求和情感有关。大脑皮层促进神经网络的发展和计算。大脑的感知和认知是生物学的基础,为高效、准确地实现人工智能的感知和理解提供了新的思路。遗憾的是,这些天然的生物特性在目前的神经网络设计中并没有得到充分的考虑。因此,脑启发建模和算法研究具有重要意义,可以进一步推动新一代人工智能的发展。
B.大脑的生物学特性
对大脑生物学特性的研究为脑源性遥感打开了一扇新的窗口。分析人类学习机制的生物学特性,可以帮助我们建立各种模拟大脑的算法。对脑机制的认识是近年来国际学术界一个重要的新发展趋势。对于知识的感知和认知,大脑主要具有稀疏性、学习机制、选择性、方向性、可塑性和多样性等生物学特性。
1)稀疏性:生物大脑,尤其是人脑,是一个分层、稀疏、周期的结构[22],如图3所示。稀疏性在生物大脑中起着重要作用。在[23]中,Olshausen和Field提出了神经元稀疏编码理论。2007年,Svoboda和Brecht通过大鼠实验验证了神经元“稀疏编码”的假设[24,25]。生物视网膜对场景信息的处理是稀疏的,这使得学习更加高效。在大脑的初级视觉皮层(V1)中,计算神经科学研究人员认为稀疏编码是视觉系统中图像表示的主要方式。V1中的神经元在动态处理和计算信息方面也是稀疏的。同时V4区域的神经元通过稀疏编码实现视觉信息的表示。水平越高,接受域越大,即信息处理是从一个局部到一个更大的区域。当水平较低时,接收域处理的区域较小,稀疏性较强,反之亦然。
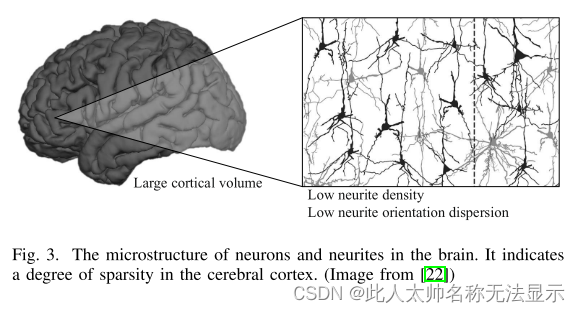
2)学习机制:人脑善于快速交叉任务学习和广义认知。2011年Tenenbaum指出,大脑具有很强的抽象表征能力,可以从少量的数据[26]中学习概括的知识。在大脑中,负责认知和学习的区域主要是海马体。海马体中的细胞相互连接成网络,每个网络由一个更抽象的细胞网格定义。在这些表达关系和符号的抽象模板的基础上,大脑在接受外界环境刺激或任务时,很容易直接应用已有的抽象模板,并将其重组以理解新的事物。人类的大脑储存了大量关于世界的知识,这些知识构成了语言、思维和推理的基础。人的大脑中有两种知识表征,一种是感官知识表征,另一种是语言知识表征。形成记忆的能力是学习和知识积累的关键。2020年,Tonegawa和Josselyn探索了铭文细胞作为记忆基础的证据(特别是在啮齿动物中),研究了新信息如何整合到现有的知识记忆[27]中。
3)选择性:peter。R指出,大脑具有注意特殊事物的能力,并在新的环境中自主控制注意区域[28]。
选择性注意调节几乎所有负责视觉处理的大脑结构中的神经元活动,包括腹侧通路(从V1到外纹皮层(V2V4)到颞下皮层)、背侧通路(从V1到V2到负责运动信息处理的中、内侧颞叶和顶叶)、前额叶、皮下结构核,如外侧曲状体、上丘、枕核、丘脑背内侧及丘脑网状核、纹状体及网状黑质等。
同时,大脑接收到大量的信息。但是,它不能以相同的优先级处理进入系统的所有信息。只有一些信息可以通过选择性的注意过滤和处理,然后进入意识。例如,初级视觉皮层可以在视觉信息加工的非常早期阶段生成视觉显著性图,以指导空间选择性注意的分布,调节感觉输入,改善人的知觉和行为。此外,选择性注意对目标刺激的神经表征具有多种调节作用,如增强神经元放电和放电同步、增强神经元选择性、增强神经元信噪比、移动和减少神经元感受野等。因此,选择性注意是一个非常复杂的认知过程,它总是协调大脑的认知处理过程。4)方向性:1971年,O’keefe在实验过程中发现,海马体中存在着能够记录位置信息的“位置细胞”,这些“位置细胞”可以被选择性地激活,赋予特定位置特殊的身份。在20世纪80年代中期和90年代早期,人们发现了决定头部取向的“头部定向细胞”,通过选择性激发来标记方向。同时,还发现了可以划分平面坐标系的“网格单元”,可以记录运动过程中产生的所有位置信息等。这些细胞相互合作,创造出大脑的二维地图,这是认知地图的物质基础。2015年,Finkelstein指出,大脑中存在方位细胞和斜角细胞,它们可以感知方向和位置信息[29]。
5)可塑性:大脑会因外界环境的需要而改变内部的神经机制,也就是说,大脑在不断地同化和适应,所以大脑具有可塑性[30]。大脑可塑性是指大脑被环境和经验所改变的能力。它可以分为结构塑性和功能塑性。大脑的结构可塑性是指大脑内的突触和神经元之间的连接,由于学习和经验的影响,可以建立新的连接,从而影响个体的行为。它包括神经元可塑性和突触可塑性。功能性可塑性可以理解为,通过学习和训练,大脑的一个代表区域的功能可以被邻近的大脑区域所替代,它也表现为脑损伤患者在学习和训练后一定程度上的脑功能恢复。大脑可塑性与学习和记忆密切相关。
6)多样性:神经元的多样性是大脑复杂而微妙的功能的基础。2021年,Ed Lein等人利用膜片钳等技术揭示了脑皮层[31]中神经元类型的丰富程度。2021年,zizzhen Yang等构建了小鼠初级运动皮层,表征了超过56种神经元类型[32],并分析了人类大脑中中间神经元多样性的发育机制。他还发现了专门存在于人类大脑中的中间神经元前体细胞类型,并揭示了与其他物种相比,人类大脑中间神经元的丰富和多样性。
iii。大脑启发算法的理论
在本节中,我们将从大脑属性的角度来讨论大脑启发式的相关理论。首先,由于大脑的稀疏性,多尺度几何分析和压缩感知得到了广泛的研究。注意力特性启发了注意力机制与深度神经网络的结合,创造了SENet[33]、Non-local[34]、Transformer[35]等网络。强化学习和迁移学习利用大脑的自然学习过程,丰富了人工智能算法的训练。本节从上面的大脑启发算法开始。它结合了遥感算法,为读者结合脑启发算法和遥感提供了新的思路。
A.压缩感知 A. Compressed Sensing
压缩感知(CS)是信息获取的一个突破性理论。当采样率大大低于“Nyquist”采样率时,CS仍能以高概率准确重构稀疏信号。它通过随机采样获得信号的离散样本,并利用非线性重构技术对其进行重构。其核心思想主要是基于信号的稀疏结构和信号的不相关特性[36,37,38]。
CS的采样方法是将一个信号与一组特定的波形相关联的一种简单操作。这些波形在稀疏空间中是独立的。压缩感知方法通过对信号进行时域变换,直接获得压缩样本,减少了信号采样过程中的冗余信息。该优化算法需要从压缩样本中恢复出原始信号。这是一个已知信号是稀疏的欠定线性逆问题。因此,实现压缩感知的前提是信号在频域是稀疏的,并采用随机子采样机制。
压缩感知有两个重要的操作来满足上述条件:稀疏表示和压缩观测。稀疏表示是将复杂信号表示为不相关稀疏信号。压缩观察是为了实现随机子采样。最后,稀疏表示、压缩观测和信号重构构成了压缩感知框架的三个部分。实现信号稀疏化是信号稀疏化的前提。压缩观测理论是CS的基础。CS的主要组成部分是重建模型和技术。
CS的采样和重构过程如图4所示。一般情况下,一个复杂信号可以表示为稀疏系数,这满足CS的前提条件。然后,利用观测矩阵进行采样,得到观测信号。在重建过程中,观测信号和感知矩阵是已知的。采用一种重构算法对稀疏系数进行重构。最后,利用稀疏系数恢复复信号。
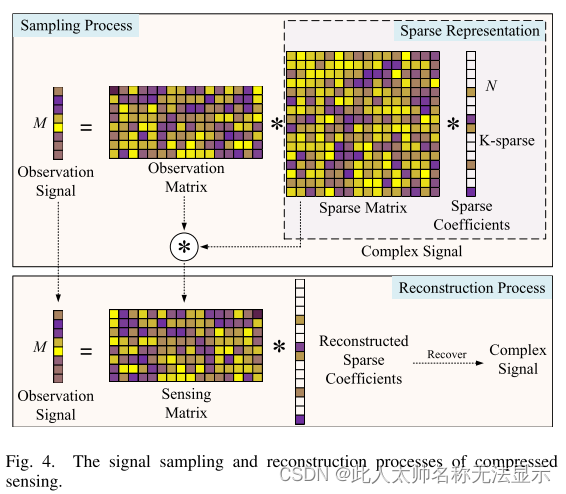
1)稀疏表示:1959年,Hubel和Wiesel在研究猫[39]视觉条纹皮层的细胞感受野时,首次提出了稀疏表示的概念。实验结果表明,“初级视觉皮层”细胞的接受域可能对视觉感知信息提供稀疏响应,为稀疏表示建立了先例。1969年,提出了一种基于Hebbian局部学习原理的稀疏表示模型[40]。网络结构中关联机制的构建得益于稀疏表示能够最大限度地提高内存容量。Houweling和Brecht等人进行的生物视觉神经生理学实验有效地支持了稀疏神经编码[24]的假设。
1)稀疏表示:1959年,Hubel和Wiesel在研究猫[39]视觉条纹皮层的细胞感受野时,首次提出了稀疏表示的概念。实验结果表明,“初级视觉皮层”细胞的接受域可能对视觉感知信息提供稀疏响应,为稀疏表示建立了先例。1969年,提出了一种基于Hebbian局部学习原理的稀疏表示模型[40]。网络结构中关联机制的构建得益于稀疏表示能够最大限度地提高内存容量。Houweling和Brecht等人进行的生物视觉神经生理学实验有效地支持了稀疏神经编码[24]的假设。根据稀疏矩阵的类型,信号的稀疏表示方法可分为以下三种:正交变换基法、多尺度几何分析方法和过完备字典方法。为了涵盖更多的信号类型,提出了字典的概念。与完备字典相比,信号在过完备字典下的表示更加稀疏。字典学习的研究在信号处理中越来越流行。构造过完备字典的方法主要有两种:使用预定义的分析字典(Heaviside、Gabor、Dirac、Fourier和Wavelet字典)或使用字典学习算法(K-means、K-SVD算法、最大似然估计、移位不变字典学习等)[41]。
2)压缩测量矩阵:压缩观测理论的研究重点是利用少量的非自适应观测来获得足够的信号信息进行重构。常用的高斯随机矩阵和伯努利矩阵都属于随机测量矩阵的范畴。这种矩阵具有较高的重构精度,但需要较大的存储空间和时间复杂度。与随机测量矩阵相比,确定性测量矩阵不仅节省了存储空间,而且相对容易确认它们是否满足限制等距性准则[42]。另外,利用一种特殊的结构,可以得到一些确定性的测量矩阵。可以设计相应的快速算法来提高重构的有效性。部分傅里叶矩阵、结构化测量矩阵和部分阿达玛矩阵通常用作确定性矩阵。
3)稀疏重建:稀疏重建是CS中恢复信号的重要部分。它需要通过对信号的压缩观察来获得原始信号。求解重构问题常用的方法有贪心法、松弛法和自然法。
贪婪法又称迭代法,是求解稀疏信号重构问题的一种重要算法。采用迭代法逐步逼近最终解。
凸松弛重构方法是一种研究和应用较为广泛的重构方法。它利用l1范数逼近l0范数,将非凸优化问题简化为凸优化问题。凸优化问题易于求解重构模型。
进化算法具有自组织、自适应和自学习能力。它可以解决传统计算方法难以解决的各种复杂问题,而不需要复杂的推理计算。
在压缩感知理论中,信号的采样和压缩可以同时进行,在高速采样时可以丢弃许多冗余数据。它极大地降低了传感器的采样率和计算成本。信号重构是压缩感知理论的关键,是解决NP-hard问题的关键。进化算法可以在字典方向上学习最优的原子组合,并利用最优的原子组合重建图像。同时,压缩感知的原始优化问题是一个非凸的组合优化问题。利用进化算法的优势解决了这一问题,增加了压缩感知重构算法的灵活性和适应性。
遥感数据压缩通常采用CS方法。例如,高光谱图像(HSIs)具有较高的光谱分辨率,给数据的存储和传输带来了巨大的挑战。Wang et al.[43]提出了一种基于光谱分解的压缩感知算法。它对HSIs进行空间和光谱采样,并联合优化端元提取和丰度估计。Xue等人[44]设计了一种用于HSIs压缩感知重构的非局部张量稀疏低秩正则化方法。针对HSIs压缩感知重构问题,提出了一种基于子空间的非局部张量环分解方法。此外,Ghahremani等人[46]利用压缩感知,利用高分辨率全色数据对低分辨率多光谱数据进行泛锐化。
B. Multiscale Geometry Analysis
多尺度几何分析
- 1
神经学家已经证明哺乳动物视觉皮层的感受区具有局部的、定向的和带通的特征。在自然环境中,神经元只能捕捉到部分关键细节。多尺度几何使用基本函数来捕获信号的部分细节。以矩形为基函数,以最小的系数逼近奇异曲线,充分利用了原始函数的几何规律。同时,基函数的支撑区间方向体现了多尺度几何分析的方向性。
多尺度几何起源于小波分析,超越了小波分析的[48]。小波分析在各种应用中取得了巨大的成功。小波分析可以比傅里叶分析更稀疏地表示一维信号。然而,在二维或高维的情况下,小波分析只能形成方向有限的可分离小波,无法实现高维信号的最佳表示。设计了多尺度几何分析来解决这一问题。如图5所示,将轮廓表示与小波分析和多尺度几何分析进行了比较。多尺度几何分析使用更稀疏的表示来捕获二维轮廓。
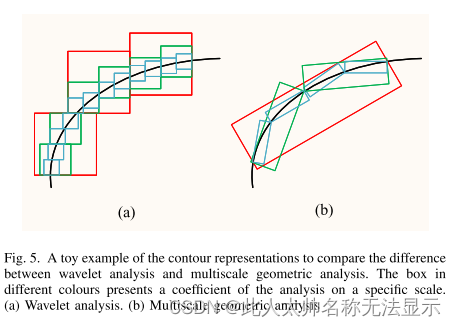
自适应和非自适应是图像多尺度几何分析的两大类。自适应算法通常从边缘检测开始,利用边缘信息准确地逼近原函数。实际上,它是边缘检测和图像表示的结合,如Bandelet[51]和Wedgelet[52]。非自适应方法不使用图像的几何特征作为先验,而是直接在一组固定的基函数上分解图像,消除了对图像结构的依赖。表示算法有Ridgelet[53]、Curvelet[54]和Contourlet[55]。
随着深度学习的出现,将多尺度几何分析与神经网络融合的努力也在不断增加。提出Contourlet CNN[56]算法,用于提取稀疏、高效的图像表示。首先利用轮廓波变换提取图像的光谱特征,然后将其与CNN网络提取的空间特征进行融合。Chen等人[57]提出了ContourletNet来实现雨水的去除。该算法利用contourlet变换的多尺度、多向和分层特征,设计出分层的多向网络,提取出不同尺度的多方向子带和语义子带。Neural Contourlet Network[58]利用Contourlet变换捕捉场景空间域的几何信息进行深度估计。
在遥感数据分析中,多尺度几何分析也起着重要作用。对于SAR图像中的无监督变化检测,Zhang et al.[59]提出了自适应Contourlet融合聚类。Li et al.[60]针对极化SAR的特点,提出了一种用于PolSAR图像分类的复杂Contourlet-CNN。该方法利用Contourlet变换帮助复杂CNN捕捉特定方向和频带的抽象特征,提取提取的特征对应的区域和方向信息。Gao等人[61]提出了一种多尺度曲波散射网络,以改善散射过程的多尺度方向信息。
C.注意机制
大脑的选择性是核心机制。人类可以迅速消除干扰,捕捉重要信息。利用这种机制,注意力已成为神经网络体系结构的重要组成部分。它在计算机视觉、统计学习、语音识别和自然语言处理中有多种用途。
注意机制之所以得到广泛的关注,一方面是因为它刺激了人脑的机制。另一方面,我们可以通过可视化注意力地图来部分解释神经网络的性能,并提高模型的有效性。
递归神经网络结构是第一个将注意机制作为RNN编解码器框架的一部分来编码长输入句子的神经网络[62]。近年来,随着注意力机制变化的增加,它已经稳步进入计算机视觉领域。在一些研究中,深度学习和视觉注意技术已经成功地结合在一起。计算机视觉中注意力机制的主要目标是训练模型专注于重要细节而忽略无关细节。目前的注意方法可分为空间注意和渠道注意。(如图6所示)
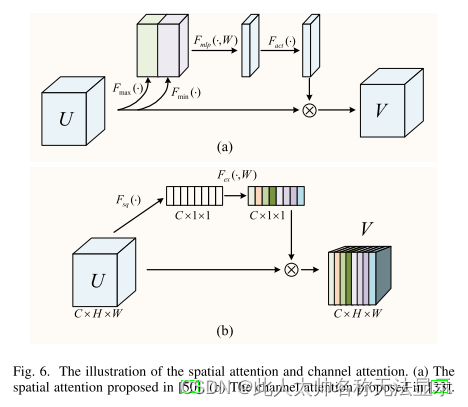 空间域注意机制背后的基本思想是对空间域信息进行适当的空间转换。它帮助神经网络从图像中提取重要信息。卷积神经网络的每一层都会输出一个特征图。卷积神经网络要实现空间注意,必须对feature map中的每个像素学习一个权值矩阵[63]。将权值矩阵与feature map相乘,平衡每个像素的影响。
空间域注意机制背后的基本思想是对空间域信息进行适当的空间转换。它帮助神经网络从图像中提取重要信息。卷积神经网络的每一层都会输出一个特征图。卷积神经网络要实现空间注意,必须对feature map中的每个像素学习一个权值矩阵[63]。将权值矩阵与feature map相乘,平衡每个像素的影响。
基于通道的注意的基本概念是通过抑制无效或小效应特征,突出有效特征来提高性能。这是通过网络[33]学习信道域中的特征权值来完成的。特别地,它通过学习自动确定每个特征通道的相关性,然后增加有益的特征,抑制对当前工作无用的特征。通常,纯粹基于渠道的注意力在空间维度上具有相同的权重。即每个信道中的信息直接全局平均池化,忽略信道中的局部信息。
该注意机制可以有效地改善各种遥感应用中的目标特征,同时解决遥感数据中特征冗余的问题。在高光谱图像分类中,传统的卷积神经网络难以提取高光谱图像的局部特征。为了加强高光谱图像空域和光谱域局部关键特征的学习,Resnet[64]在卷积网络的基础上引入了一种基于空域-光谱注意的高光谱图像特征提取方法,通过计算获得掩膜,识别分类所需的特征,提高了高光谱的表示能力。在遥感图像实例分割中,Zhang等[65]提出了语义注意模块,通过对注意进行附加的分割监督,显著提高了复杂遥感噪声背景下实例的激活值。
D.强化学习
人类学习知识的过程受到环境和历史经验的影响。这个学习过程是大脑的可塑性。为了模拟这种属性,强化学习的学习过程被设计为代理和环境之间的相互作用。代理可以通过在模拟环境中执行不同的操作并获得不同的奖励来学习[67]。深度强化学习在视觉和强化学习的决策能力等感知问题中整合了深度学习的强大理解能力,并实现了端到端学习。深度强化学习的出现使强化学习技术真正实用,可以解决现实世界中的复杂问题[68,69]。
与有监督学习和无监督学习的目标不同,该算法要解决的问题是agent如何在环境中执行动作以获得最大的累积奖励。< A,S, R, P >是典型的四重强化学习。A表示代理的所有操作。S是行为者所能感知到的世界状态。R是代表奖励或惩罚的真实值。P是agent与之交互的世界,称为模型。具体来说,策略是指agent在s状态下的行为选择。奖励信号定义了agent的学习目标。定义价值函数来判断交互中的奖励是好是坏。该模型是对自然世界的模拟,它模拟了环境的反应后,agent样本。在强化学习中,agent观察行为和奖励与环境的互动,以完成任务。
在遥感技术中,强化学习通过与环境的交互作用,使累积特征奖励最大化,从而决定序列行为。特别是在只有少数标记像素可用的情况下,强化学习可以在不使用任何标记训练数据集的情况下实现相对较高的精度。这非常适合数据较少的遥感任务,如SPRL[66]。如图7所示,SPRL采用基于增强学习的方法对polarimetric synthetic aperture radar (PolSAR)数据进行分类。根据强化学习将像素设置为“状态”和“工作”,并通过与“环境”的交互来修改像素的“动作”。从局部邻域设计一个空间极化的“奖励”函数来探索空间和极化信息,以获得更精确的分类。这就产生了一种自进化和无模型的分类器,其原理简单,对数据中的散斑噪声具有鲁棒性。通过与环境的相互作用,SPRL网络可以在标记像素较少的情况下实现较高的分类精度。
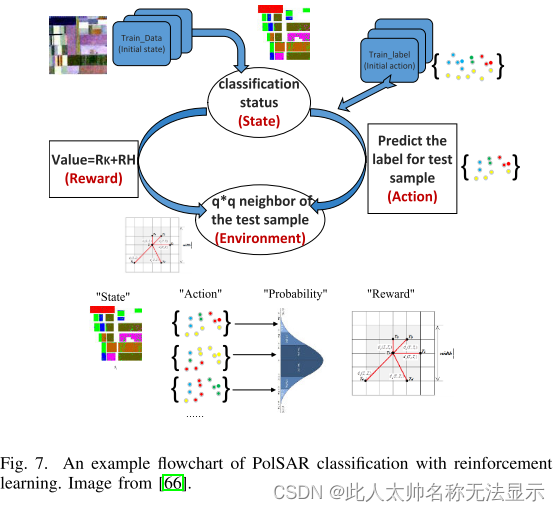
基于强化学习的PolSAR分类示例流程图。图片来自[66]。
同样,针对少镜头遥感数据,提出了一种用于PolSAR图像分类的增强深度q -网络(DQN)技术。它可以通过贪婪的方式与agent交互,提供有价值的数据[70]。在网络中,多层特征图像和分类动作分别称为环境状态和agent动作。某些条件会奖励模型预测。通过使用带注释的样本数据集给代理反馈。
为了从复杂背景中检测出密集的舰船,Fu等人提出了一种基于特征融合金字塔网络的深度强化学习(FFPN-RL)的舰船旋转检测模型,该模型将深度强化学习应用于倾斜舰船检测任务[71]。角度预测是通过动作集的三个动作进行的,在动作集中使用不同的旋转角度,可以达到更高的预测精度,减少决策动作的数量。奖励功能鼓励或惩罚角度预测者选择的行动。代理通过上述奖励积累经验,从中学习,并最终在每个决策中选择适当的行动。结果表明,该检测网络可以更有效地生成船舶斜矩形箱体。
E.迁移学习
迁移学习作为一种重要的机器学习方法,得到了广泛的研究。它可以模拟人类“推断他人”的学习能力,将过去学到的知识转移到新的任务中,加快学习新任务的成本[72]。另一方面,迁移学习可以利用部分标注数据训练有监督学习的机器学习方法,减少对大量标注数据的依赖[73]。当前迁移学习发展的主要趋势是使用大量标记分类数据对基准网络进行预训练,然后使用少量标记数据对网络进行微调以适应不同的任务。
如图8所示,迁移学习的核心思想是将从一个问题中获得的知识应用到另一个不同但相关的问题上。在进行迁移学习时,预训练模型的约束条件和设置合适的学习速率是很重要的。使用预先训练的网络可能会限制用于新数据集的体系结构。
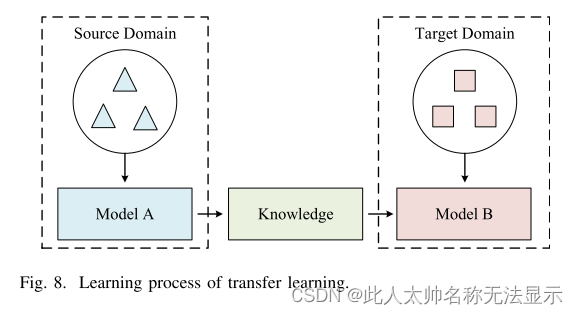
与随机初始化的卷积网络相比,被微调的卷积网络的权值通常使用较低的学习率。使用源域数据训练一个好的分类器是可能的。但是,由于源域和目标域数据之间存在细微的差异,源域模型不能很好地对目标域数据进行分类。一种常用的方法是对齐目标域和源域数据的特征分布。目标域数据可以使用与源域数据一起训练的模型进行分类。
领域适应[74]是一种独特的迁移学习类型,发生在源域和目标域的数据分布不同,但两个目标是相同的情况下。领域适应是当前迁移学习的一个重要研究热点。它的任务是学习一种映射,该映射可以同时将源域和目标域映射到公共特征空间,以便能够模拟复合映射。将仅在源域中学习到的映射和非常接近于仅在目标域中学习到的映射进行组合。
目前,将迁移学习与遥感数据相结合的相关研究较多。Xie Michael等人提出利用转移学习策略利用夜间灯光强度训练全卷积CNN模型来预测白天照片中的夜间灯光[75]。学习到的特征有助于贫困预测。陈中等人利用单一深度卷积神经网络和有限的训练样本进行迁移学习,提高了遥感数据中飞机的检测精度[76]。提出了一种变化检测驱动的迁移学习方法,利用时间序列图像更新土地覆盖地图[77]。该方法旨在利用源领域的现有知识为目标领域定义一个可靠的训练集。这是通过对目标和源域应用无监督的更改检测方法来实现的,并通过将未更改的训练样本的检测类标签从源域迁移到目标域来初始化目标域训练集。
IV. THE INTERPRETATIONS OF REMOTE SENSING 四、遥感解译
A.遥感数据类型
随着人工智能技术的发展,其应用越来越广泛,并取得了令人瞩目的成果[78]。遥感领域也不例外[79]。遥感智能解译在环境监测、土地资源[80]、作物监测[81]和产量估算、森林碳汇估算[82]、国防安全[83]等诸多领域的研究中都具有重要意义。遥感解译是国家战略发展的重要要求。
遥感图像是指记录各种地物电磁波大小的胶片或照片,主要分为航拍照片[84]和卫星照片[85]。遥感成像方法主要有航空摄影、航空扫描和微波雷达。基于各种探测技术,遥感图像可大致分为主动遥感和被动遥感[86]。根据传感器的捕获光谱范围,可分为紫外遥感、可见光遥感、红外遥感、微波遥感、多波段遥感等。[87]。本节主要总结了现有遥感数据中被广泛研究的光学遥感图像和雷达图像(如图9所示),包括光学遥感图像[88]、雷达图像[89]、激光雷达点云数据[90]、遥感视频[91]。
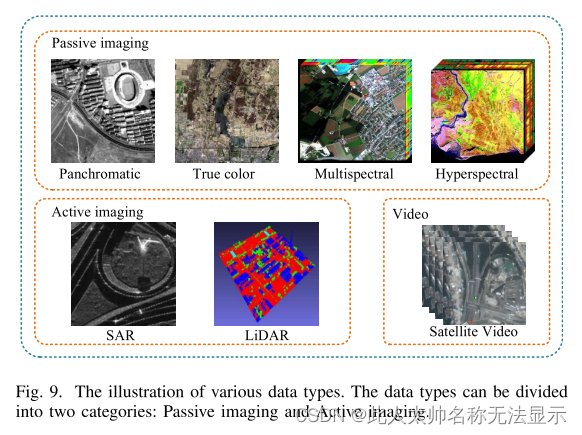
9各种数据类型的说明。数据类型可分为两类:被动成像和主动成像。
1)光学图像:光学图像是一种遥感数据,它将目标的辐射划分为几个较窄的光谱波段,获取不同光谱上的目标信息。相同的天体具有相似的光谱特征[92]。不同物体在波段的辐射能量是不同的。
根据捕获光谱波段的数量和光谱波段的窄度,光学图像可以大致分为全色、多光谱和高光谱三种类型[93]。一般来说,大多数卫星可以拍摄全色和多光谱图像。
全色图像:全色图像只有一个灰度图像波段,即特定像素的亮度与像素值成正比。像元值与目标所反射的太阳辐射强度有关。全色图像通常具有较高的空间分辨率,但其图像的光谱信息很少[94]。
多光谱图像:多光谱图像通常是指以像素表示的3 ~ 10个光谱波段。每个波段都可以使用遥感辐射计获取[95]。将全色图像与多光谱图像进行适当融合,可以得到具有较高GSD和丰富光谱信息的图像。
高光谱图像:虽然高光谱数据包含非常窄的波段(10-20 nm)[96],但高光谱图像可能有数千个波段。对于每一波段的高光谱数据,通常需要成像光谱仪进行采集。与高分辨率、多光谱图像相比,高光谱图像具有较高的光谱分辨率和丰富的波段。它包含丰富的辐射、空间和光谱信息[97],是各种细节的综合载体。在特征映射和资源勘探领域,高光谱图像得到了广泛的应用[98]。与标准的RGB图像不同,高光谱图像通常是多通道图像。高光谱富波段信息往往包含更丰富的特征。我们可以根据不同地物对不同波段的灵敏度来选择波段,来高亮某些物体[99]。
2)雷达图像:雷达是一种主动微波遥感器,它发射微波辐射,接收目标反射的电磁波[100]。雷达成像系统主要包括五个部分:脉冲发生器、发射机、雷达天线、接收机和记录仪。脉冲发生器产生高功率调频信号,并通过发射机按特定时间间隔重复发射特定波长的微波脉冲。常用的雷达图像可分为合成孔径雷达和偏振合成孔径雷达。
合成孔径雷达:合成孔径雷达(SAR)[101]是一种有源微波成像设备。其成像原理是通过飞行载体的运动形成雷达的虚拟天线,从而获得高分辨率的雷达图像。根据飞机类型的不同,合成孔径雷达可分为机载和星载两种。两者都有各自的优势和用途。机载SAR具有较高的分辨率,而星载SAR可以长时间观测更广的区域,具有全局宏观效应,具有周期性。由于其成本也比机载低,因此星载SAR得到了广泛的应用。根据是否进行合成孔径处理,成像雷达可分为真实孔径雷达(RAR)和合成孔径雷达[102,103](如图10 (a)所示)。
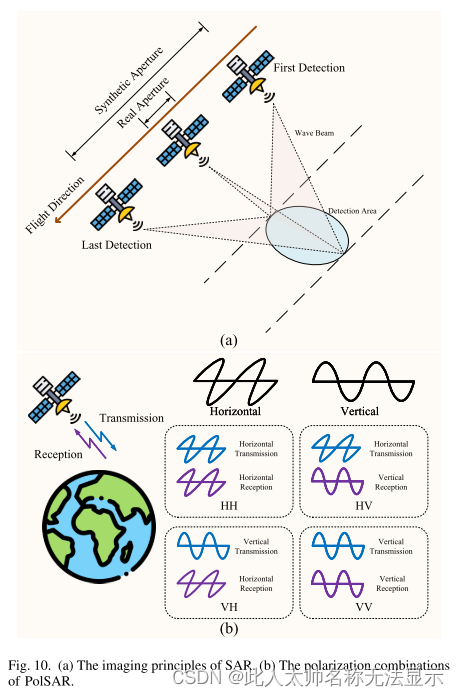
图10。(a) SAR成像原理。(b) PolSAR偏振组合。
真实孔径成像雷达发射一个脉冲无线电波束到雷达天线的一侧(称为距离方向)到飞机的旅行方向(称为方位角方向)。光束在垂直于飞行方向的地面上照射出一条狭长的长条。然后将雷达天线转换为接收工作状态,接收目标反射的后向散射波[104,105]。当飞行器移动时,发射的光束沿着飞行方向沿着这条连续的长条扫描表面。雷达图像逐行生成[106]。
雷达图像的分辨率包括距离分辨率和方位分辨率。距离分辨率是指垂直飞行方向的分辨率。方位角分辨率是指沿飞行方向的分辨率[107]。距离分辨率主要与雷达系统发射的脉冲信号有关。脉冲持续时间越短,距离分辨率越高。但是,如果脉冲宽度过小,则传输功率会下降。另外,反射脉冲的信噪比也会降低,这是矛盾的[108]。
合成孔径雷达的基本原理是将一个小天线作为一个单一的辐射单元,使其沿直线连续运动。将同一目标在不同位置的反射脉冲进行相关处理,可以获得更高的图像分辨率[108]。合成孔径雷达在距离方向上与实际孔径雷达相同,采用脉冲压缩提高分辨率。在方位方向上,利用合成孔径原理提高了分辨率[109]。当辐射单元的位置不断变化时,可以对接收到的信号进行记录和处理,获得与实际天线的虚拟天线长度(合成孔径长度)相同的观测效果。
SAR通过发射电磁脉冲和接收目标回波进行相干成像,可以全天候、全天候拍摄多极化、多波段、高分辨率图像。它获取地物的后向散射信息,实现对地观测任务。与光学和红外遥感技术相比,SAR属于微波遥感[110]。它不仅可以获取地形地貌等地表信息,还可以穿透地表,在恶劣环境下获取地下、隐蔽、高分辨率的地面数据。
极化合成孔径雷达:极化合成孔径雷达(Polarimetric Synthetic Aperture Radar, Polarimetric SAR)系统[111]是在单通道SAR系统的基础上发展起来的,可以提供目标的多维遥感信息。与传统的单通道SAR相比,极化SAR不仅利用了目标散射回波的幅度、相位和频率特性,还利用了其偏振特性[112]。例如,波长较长的l波段可以穿透森林和地表植被覆盖。它可以在军事上用于发现丛林或浅埋表面的隐藏目标[113]。
PolSAR通过发送和接收各种极化电磁波,测量地物的极化散射特性,建立极化散射矩阵。电磁波的极化对目标的物理特性非常敏感,如表面粗糙度、介电常数、几何形状和方向。因此,偏振散射矩阵包含了丰富的目标信息。
PolSAR通过测量地面上各个分辨率单元的散射回波来获得偏振散射矩阵[114]。利用这些极化散射矩阵可以完整地描述目标散射回波的振幅和相位特性。
当电磁波的电场平行于散射面时,称为水平极化波(H)。同样,垂直的波称为垂直(V)极化波。因此,PolSAR可以根据发射天线和接收天线的方向分为四种极化模式。
如图10 (b)所示,有四种偏振组合:VV、HH、VH、HV。例如,VV极化即垂直发射/垂直接收,表示极化SAR发射天线发射垂直电磁波,接收天线也接收垂直电磁波。通过获取四种基本极化组合(HH、HV、VH、VV极化)[115],可以精确计算出天线在所有可能极化状态下的接收功率值。
近几十年来,PolSAR技术发展迅速,其广泛应用也受到越来越多的关注[116]。与此同时,人们对SAR的需求也在不断增长,人们希望获得同一目标在多个频段、多个极化、多个视点的图像。此外,由于对军用无人侦察机的需求,SAR小型化也具有重要意义。极化合成孔径雷达是目前最先进的遥感传感器之一。它在民用和军事领域有许多实际应用和重要性。
3)机载激光雷达:机载光探测与测距(Airborne Light Detection and Ranging, LiDAR)[117]是一种集姿态确定、激光和高精度GPS差分定位技术于一体的探测技术。激光雷达通过测量和探测来确定扫描仪与物体之间的相对距离,并满足不同级别的分辨率要求。具体来说,LiDAR数据主要有两大类212种,分别是点云数据和波形数据。信号旅行时间[119]。与传统摄影测量获得的数据相比,点云数据可以更准确地反映地形信息。机载激光雷达收集的数据是一系列具有不规则空间分布的离散三维点,称为“点云”。
如图11所示。悬浮激光雷达系统主要包括激光扫描仪、惯性导航系统(INS)[120]和动态差分GPS接收器。激光扫描仪测量从激光发射点到地面目标的距离。惯性导航系统使用惯性测量单元(IMU)(121)来测量飞机中央光轴扫描设备的姿态参数。动态差分GPS接收器用于确定激光雷达发射点的空间位置。
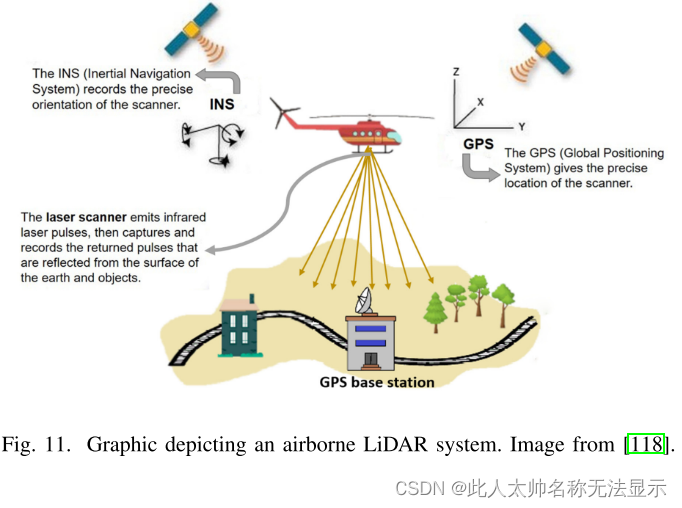
图11。图示机载激光雷达系统。图片来自[118]。
机载激光雷达系统完成激光扫描后,得到的数据包括位置、方向和激光扫描距离[122]。其中,位置定位包括差分GPS和IMU信息。这些数据记录了每个激光脉冲的信息,包括位置、方位角/角度、距离、时间、强度、回波,以及系统在飞行过程中获得的其他数据。可以计算出激光点在WGS84坐标系中的X、Y、Z坐标。这些具有精确三维坐标的离散点称为LiDAR点云[123]。
三维激光雷达点云数据包括点的空间三维坐标、回波强度、回波时间、扫描角度等信息[124]。在实际应用中,经常使用的信息是点云几何形状、激光强度和发射激光脉冲返回的激光回波数据。激光回波信号是由激光扫描仪发射的激光脉冲产生的,然后被一个接地点反射或散射。机载激光雷达系统不仅可以提供目标点的三维坐标,还可以提供激光回波信号的强度信息[125]。由于每种材料对激光信号的反射特性不同,点云数据可以方便地区分不同物体的边界,进行物体分类。
4)遥感视频:遥感视频[126]通常根据携带传感器的平台分为卫星视频和无人机(UAV)视频。卫星视频是机载视频的一种。它一般是指与空间研究和探索相关领域的卫星获得的视频。无人机视频是指无人机拍摄的视频。遥感视频示意图如图12所示。

图12。遥感影像插图。(a)卫星录象。(b)无人机视频。
卫星视频:卫星图像是指搭载图像有效载荷,能够获取地面目标区域图像的卫星平台。
卫星视频[127]能够对目标区域进行长时间连续成像,提供动态信息,实现长期动态实时监测。摄像机安装在微卫星平台上,由望远物镜、面阵焦平面探测器和电子处理电路组成[128]。由望远物镜对图像平面上二维视场内的地面场景进行成像,对位于图像平面上的区阵探测器进行光电转换和电子电路处理后,得到地面场景的遥感图像。当控制曝光的快门打开时,地面场景发出的光通过大气传输,到达相机的入口瞳孔。望远物镜聚焦在面阵焦平面探测器上,获得一帧目标视频。当卫星平台在轨道上飞行时,相机与地面场景之间存在相对运动。当快门再次打开时,得到目标的另一帧。这个循环继续形成一个帧推送过程。在逐帧成像过程中,曝光时间往往比单个像素对应的积分时间更显著。所捕获的图像在轨迹方向上容易发生位移,即图像运动,图像容易模糊。图像运动补偿装置,如反作用轮或陀螺仪,可用于调整相机姿态,消除或减少图像运动的影响。经过多帧图像压缩、帧对齐算法等软件处理,最终形成一个连续的动态视频。
卫星遥感视频作为一种获取对地观测图像数据的新方法,可以应用于大尺度动态目标变化监测及其瞬时特征分析[129]。它通过对特定区域采用“图像记录”的方法,缩短了相邻图像帧之间的时间间隔,既实现了大范围覆盖,又弥补了传统卫星再入周期的限制。与常规遥感卫星相比,卫星遥感视频的目标观测区域较小,但及时性较好[130]。它可以在小范围内实现定点、定距遥感监测,在一些重大工程领域具有独特的应用优势。例如,可以实时了解重大项目的进度和建设情况,并为其对周边生态环境的影响提供实时的视频信息支持。
与传统的视频监控图像数据相比,卫星遥感图像数据面临以下挑战[131]:
(1)在卫星遥感图像成像过程中,传感器的缓慢运动导致建筑物、树木等目标的位移发生变化,产生了许多虚假运动目标,使得背景更加复杂;
(2)由于受卫星遥感成像空间分辨率的限制,目标在图像中的大小只有几十个像素点,与背景的对比度较低,无法获得目标更详细的信息;
(3)在卫星视频中,光照变化、阴影运动等因素导致了背景的动态变化。由于分辨率较低,这些动态变化更有可能被认为是造成虚警的运动目标。在卫星视频中直接采用传统的运动目标检测方法,容易造成误检。
UAV视频:UAV[132]是一种无人机。随着硬件性能的提高和图像处理算法的发展,无人机视觉的研究已成为一个热点。由于地理条件的限制,可以获得大尺度、多角度、高分辨率的数据优势。它在目标跟踪、图像拼接、电力线检测、岛屿监测、海岸线监测、灾后监测、河流汛期监测等方面发挥着越来越重要的作用[132]。
无人机的飞行状态除起飞和降落外,大致可分为悬停状态和巡航状态,在这两种状态下获得的视频具有不同的特征。无人机在悬停状态下可以拍摄稳定的视频。尽管如此,机翼的旋转和外部风的影响会导致图片的抖动,导致视频背景的不规则运动。无人机巡航状态是指无人机前后飞行时的平移飞行状态。在视频拍摄中,图像在短时间内有较大的偏移量。除了运动的目标外,背景也有很大的运动。
与卫星视频相比,无人机承载的图像数据具有以下优点:
(1)弥补了卫星遥感和普通航空遥感的时效性不足、可操作性不足、受天气条件、时间等限制缺乏区域信息[133];
(2)无人机图像分辨率高,可以获得高分辨率的飞行区域全景图像。然而,由于卫星拍摄距离较远,图像的分辨率和精度不能满足要求;
(3)无人机系统使用成本低,维护操作简单[134];
(4)无人机系统能够快速获取中低空的可见光和红外成像,快速、实时地对地面进行检查和监控,客观、直接地记录当前的图像状态[135]。
相比其他相对稳定的摄像设备,如道路、商场的监控摄像头,无人机的高机动性使得数据采集不受地理区域的限制。在资源环境监测、森林火灾监测、车辆和人员无法到达的救援指挥等方面具有独特优势,更加灵活。由飞艇在高空携带的航空相机、卫星等获取的图像数据,利用无人机进行运动目标检测更具挑战性。表一列出了无人机视频相对于卫星视频的特点。

一般来说,视频数据在内容或时间上比单个图像包含更丰富的信息[136]。特别是卫星逐渐开始发展视频功能,视频数据来源大大扩大。
B.遥感应用
脑源遥感解译应用于遥感数据处理的各个方面,有效地处理遥感数据的复制和多样化。在本节中,我们总结了土地覆盖分类、变化检测、目标检测、目标跟踪和三维重建5个应用领域近年来的发展。
1)土地覆被分类:土地覆被分类在自然图像处理中又称为语义分割,是遥感中最基本的图像分析任务之一。它对图像中的每个像素进行分类,并为每个像素指定一个类别,从而理解图像的内容。
2015年,Jonathan Long等人首先提出了用于语义分割任务的全卷积网络(Fully Convolutional Networks, FCN)[137]。FCN网络用卷积层取代了神经网络中所有全连接层,实现了一个由所有卷积层组成的网络。由于FCN网络不能很好地利用多尺度特征,2015年,Olaf Ronneberger等人提出了U-Net网络[138]。UNet网络利用跳跃连接操作,充分利用下采样过程中产生的多尺度特征,从而获得良好的分割结果。2017年,Vijay Badrinarayanan等人提出了基于U-Net网络的SegNet网络[139]。该网络利用相应编码器的最大池化步骤计算出的池化索引对解码器进行非线性上采样。同年,高黄等人提出DenseNet[140]。DenseNet网络的卷积层以前馈的方式将每一层与每一层连接起来,使靠近输入和输出的层包含更短的连接,以恢复卷积过程中丢失的信息。由于UNet和SegNet都不能充分利用像素周围的局部邻域信息。Liang-Chieh Chen等人提出了DeepLabV3+网络[141]。DeepLab网络利用Atrous空间金字塔池(ASPP)。在降低分辨率的同时融合像素的多尺度局部接收域。
与自然图像相比,遥感图像具有以下特点:(1)同一类目标大小差异较大,需要解决大小变化问题;(2)由于卫星是在高海拔拍摄地面的,因此所获得的图像范围非常宽。对象占用的像素非常少,产生了样本不平衡的问题;(3)在大面积拍摄时,同一类物体因天气、光线等自然条件而呈现出各种不同的外观;(4)大尺度拍摄通常伴随着低分辨率,使得每个语义区域缺乏形态轮廓信息。这些特点对遥感影像的土地覆被分类提出了更高的要求。
土地覆被分类大致可分为基于目标和基于像素的方法。基于对象的方法将图像进行区域划分,并根据整个区域的特征对区域进行分类。而基于像素的方法不需要进行区域划分,直接利用像素的特征进行直接分类。由于中、低分辨率遥感图像的异质性(如图13(a,b)所示),我们认为每个像元是混合的,可能包含一个以上的语义类别。因此,对于中分辨率和低分辨率的遥感图像,基于像素的分类方法通常是无效的,而基于目标的方法可以通过对区域进行分类来实现图像的粗分割。如图13©所示,每个像素代表了该区域的特征。与基于区域的方法相比,基于像素的方法可以充分发挥像素本身的特点,更成功地完成分割任务。
基于对象的分类:基于对象的分类方法要处理的核心是段(segments),即将具有相同属性的多个像素分组成一个对象。与基于像素的分类方法不同,基于目标的方法将遥感图像划分为不同的区域,并通过空间和光谱特征评估其特征。基于对象的方法也更类似于人类的视觉理解过程,通过考虑这些对象的不同属性和空间安排来理解语义信息,然后从图像而不是单个像素直观地识别对象。目前,基于对象的特征分类还被用于考古学、冰川地貌勘探、湿地测绘等领域。基于对象的方法通常由图像分割、对象特征提取和对象分类三大部分组成,如图14(a)所示。图像分割部分是基于对象的方法的第一步,它采用基于边缘的分割、基于区域的分割等分割算法将遥感图像分割成多个均匀的分割段。目标特征提取部分弥补了基于像素的方法的不足,包括提取形状、纹理、光谱等特征。最后,在对象分类部分,分类器在其特征空间中对不同的对象进行分类。
近年来,如何将深度学习与基于对象的土地覆被分类相结合,引起了众多学者的关注。Zhang等[142]提出了一种基于对象的卷积神经网络(convolutional neural network, OCNN)方法用于土地利用分类。OCNN首先将遥感图像分割成线性目标和一般目标,然后送入神经网络进行分析。Liu等[143]提出了一种基于object-based post - classification refine (OBPR)方法与CNN相结合的新方法,该方法以光学和SAR数据为输入,利用CNN网络获得粗结果,并借助OBIA进行提取。空间、纹理和上下文特征对粗结果进行了细化。Zhang等[144]提出了一种针对高分辨率遥感图像的多层上下文引导分类方法(multilevel context-guided classification method, MLCG-OCNN)。MLCG-OCNN不是使用对象和上下文块作为输入,而是使用从光谱模式、几何特征和对象级上下文信息中学习的高级特征准确地识别对象。然后,每个对象的分类结果通过像素级上下文指导得到改善。Maria等人[145]介绍了一种新型的基于对象的深度学习系统,该系统将各向异性扩散数据预处理和额外的损失集成到基于对象的先验中。
基于像素的分类:基于像素的方法将图像像素作为分析的基本单元,将单个像素标记为单一的语义类别,如植被、建筑、车辆或道路(如图14(b)所示)。早期基于逐像素分类的方法主要采用k-means、支持向量机、神经网络等方法。随着遥感成像技术的提高,遥感图像的分辨率大大提高。基于像素的分割方法是将具有相似特征的像素聚类成一类,并通过像素的特征赋值为一类来完成分割任务。
Peng等人提出了基于UNet的交叉融合网(Cross Fusion Net, CFNet)[146]。CFNet网络以串联的方式融合和预测多尺度特征。此外,该网络设计了通道注意细化模块来选择信息特征,并设计了交叉融合模块来扩展接受域的低层特征图,以提高小尺度物体的分割精度。Konrad Heidler等人[147]提出了HED-UNet网络,该网络利用解码过程中产生的多尺度特征为语义预测和边界预测任务提供特征。
Liu等[148]在DeepLabv3+网络中,基于atrous卷积构造了一个atrous卷积模块,该模块可以任意控制不同扩张速率下模块的深度、宽度、组和步长,充分利用局部特征。Peng等[149]采用多尺度卷积核并行方法,充分利用像素的局部信息。采用密集跳跃连接,以减轻由于卷积低通滤波的性质而导致的图像高级特征丢失的后果。Shang等[150]提出了不同扩展速率、全局信息和自信息的atrous卷积来提取多尺度的背景信息,以解决遥感图像中物体大小差异的问题。Wang等[151]提出了一种用于HSI分类的双通道光谱-空间融合胶囊生成对抗网络(DcCapsGAN)。DcCapsGAN利用胶囊式和生成式对抗网络结构,克服了高维特征训练规模的限制和频谱空间开发的有效性。
为了提高位于土地覆盖类别边界区域的类像元的性能,提出了一种新型的光谱空间转换器(spectral spatial transformer, SST)-M,该转换器集空间注意力和提取光谱特征于一体[152]。Wang等人[153]提出了一种UNetFormer模型,可以对全局和局部信息进行建模,在512 × 512的输入条件下实现高效的语义分割,帧数达到322.4帧。He等人[154]受多尺度视觉变压器的启发,提出了一种跨光谱视觉变压器,用于提取像素级的多尺度特征,增强相邻光谱波段间的局部细节,进行HSI分类。
2)变化检测:遥感变化检测(Remote sensing Change Detection, RSCD)是指从同一地理区域提取和识别多时相图像之间的不同信息[155,156]。如图15所示,RSCD方法通常包括遥感图像预处理(对齐、校正、降噪等)、选择合适的变化检测方法以及对结果的评价等过程。Weismiller等[157]首先对沿海环境进行了变化检测,此后对RSCD进行了大量研究。目前,RSCD在城市化监测[158]、损害评估[159]、环境监测[160]等方面的应用十分活跃。现有的RS CD方法根据分析单元分为基于像素、基于对象和基于场景三种,各有优缺点[161]。近年来,在变化检测过程中也出现了将这些分析单元结合起来的新方法,以更好地提取变化信息。
基于像素的变化检测:由于像素是遥感图像最基本的单元,早期的RSCD方法主要采用代数方法对给定遥感图像的每个像素进行评价,如图像差分法[162]和回归分析法[163,164]。此外,RSCD还可以通过像素变换来进行,如主成分分析(PCA)[165]、变化向量分析(CVA)[164]等。在像元变换方法中,将遥感图像进行变换并结合空间投影,转换到不同的数学空间进行分析,以进一步优化各种特征。由于高分辨率遥感图像中高频分量的不可预测性以及预处理过程中几何对准和辐射校正的误差,传统的基于像元的方法难以对高分辨率遥感图像进行建模应用[166]。因此,中低分辨率图像通常采用传统的基于像素的方法[167,168]。
另外,像素分类变化检测方法是另一种基于像素的变化检测方法,它通过比较两幅分类后的图像得到图像的变化矩阵,反映了研究区域的变化信息[164]。这些方法包括后分类比较、无监督变化检测方法和基于人工神经网络的方法[167]。然而,有监督方法难以选择高质量的数据集,而无监督方法在识别和标注变化对象以及选择聚类数量方面遇到困难[164,156]。
近年来,随着深度学习的兴起,大量基于深度学习的语义分割方法被应用到基于像素的变化检测中,极大地缓解了上述困难。例如,Wang等人[169]引入了融合亚像素表示的混合亲和矩阵,并提出了用于RSCD的卷积神经网络框架。Daudt等[170]在对地观测图像上使用全卷积网络(full convolutional network, FCN)对多时相图像进行变化检测。已有研究证明,在多时相图像中获取背景信息,结合变化区域的多尺度特征,可以有效预测精细变化,提高变化检测的精度[171],因此提出了结合多尺度特征的研究。例如,Chen等人[172]设计了一种结合深度siamese卷积网络的多尺度特征卷积单元,用于有监督和无监督变化检测。此外,针对进一步的特征和信息融合。Zheng等[171]设计了一种跨层卷积神经网络(Cross-Layer Convolutional Neural Network, CLNet),该网络通过两个并行分支聚合多级上下文信息和多尺度特征。
由于基于cnn的方法不擅长获取空间中的远程信息,Transformer也被引入到遥感变化检测中。Chen等人[173]提出了双时间图像Transformer (BIT),该方法将双时间图像表示为若干标记令牌,并使用基于Transformer的转换器编码器在紧凑的基于令牌的时空中建模上下文。然后将学习到的全局上下文丰富标记反馈到像素空间,以通过基于Transformer的解码器增强原始像素级特征。为了解决CD问题,还提出了一种具有连体u形结构的纯变压器网络[174]。此外,也有学者将图卷积网络[155]、gan和dbn引入到基于像素的变化检测中[156]。
除了基于主动成像的RSCD外,SAR图像中的变化检测也受到了学者们的关注。在SAR图像变化检测中,由于局部像素是相干的,因此在保持图像细节的同时减少图像的散射噪声是至关重要的。为了解决上述挑战,如图16所示,Zhang等人提出了自适应Contourlet融合聚类算法,以及一种新的基于fgfcm的快速非局部聚类算法(FNLC)用于SAR变化检测,该算法利用ratio difference图像的变化和不变信息。具体来说,图像融合中的Contourlet融合方法首先通过Contourlet变换(CT)对两幅输入比图像进行分解,得到多分辨率、多方向的分解系数。然后,采用不同的融合规则分别对输入图像的低频和高频系数进行融合。最后对融合系数进行轮廓波反演变换(CIT)得到融合图像。此外,本文提出的FNLC方法对融合图像中的变化区域和不变区域进行分类,提高了SAR图像的噪声抑制性能。
基于对象的变化检测:类似于基于对象的分类,OBCD (object-based change detection)分析单元是图像中的对象。Chen等人[176]将OBCD定义为一种应用基于对象的分析来识别地理对象在不同时间的方差的过程。一般由以下步骤组成:在图像分割的基础上创建同构区域(即图像对象),提取变化信息,识别变化区域。OBCD方法对所采用的分割算法高度敏感,容易忽略语义信息和对象间信息[177]。此外,选择用于控制对象大小的比例参数(SP)是OBCD中的一个基本步骤。传统的基于数学方法的对象生成方法无法解决这些问题。同时,基于深度学习的加速增长,OBCD方法在一定程度上解决了这些困难。
在对象分割过程中,不充分或过度的分割都会导致不能反映真实世界的特征的出现,产生无用的对象,从而降低性能[164]。深度学习的出现使得进一步融合空间特征成为可能。Wang等人[178]提出了一种结合多种特征集成方法的变化检测方法,结果表明,在不同分割尺度和分类器的基于对象的方法中,多目标特征具有更高的准确率。此外,超像素分割方法被广泛应用于目标提取。Zhang[177]等人提出了针对VHR (Very-HighResolution)图像的超像素增强CD网络(superpixel enhanced CD network, ESCNet),利用超像素分割网络提取目标信息。为了进一步利用物体之间的上下文信息,Zhan等[179]提出了一种基于多尺度决策融合策略的VHR图像无监督尺度驱动网络。该网络通过融合基于svm的分类中不同尺度的变化检测结果来识别变化区域。充分利用图像对象的空间上下文信息。Zhang等[180]将GCN模型引入到遥感OBCD中,构建对象的图神经网络,获取相邻对象之间的上下文信息,提高了性能和计算效率。
包围框选择是另一种基于对象的方法。其中,Faster R-CNN主干等目标检测算法被广泛应用,这些算法将图像中的“变化区域”视为检测对象,将“不变区域”视为背景[161]。Zhang等人[181]提出了一种带有双相关注意引导检测器(DCA-Det)的单级变化检测模型来增强鲁棒性。输入的图像被发送到权重共享的主干,以提取不同尺度的特征。构建双相关注意模块(dual correlation attention module, DCAM),从通道和空间两个方面细化与变化相关的特征,抑制不相关的特征。Han等[182]提出了双域兴趣网络(dual region of interest networks, DRoINs),该网络由三个功能块组成:特征提取网络、变更建议网络和不同判断网络,以改善特征表示,实现更好的变更判别。Priyanto等[183]利用Faster R-CNN作为特征提取器,检测和监测渔场和海域浮动网箱数量的变化。
此外,由于基于像素和基于对象的方法各有优势,许多学者将它们结合起来以获得更好的性能。Lu等[184]提出了一种无监督算法级变化检测融合方案(UAFS-HCD),该方案利用OBCD提高了传统基于像素的变化检测算法的精度。Ji等[175]利用Mask R-CNN和MS-FCN提取建筑特征。如图17所示,建筑提取网络输出对象级和像素级的建筑变化图,并将其反馈给自训练的建筑变化检测网络,计算建筑变化图。Han等[185]提出了一种加权Dempster-Shafer理论融合方法,该方法结合多个像素的变化检测结果生成OBCD。
基于场景的变化检测:遥感场景水平变化检测(Remote sensing scene level change detection, SLSCD)旨在从语义角度分析和识别给定的同一区域的多时相遥感图像中的土地利用变化[161]。SLSCD不是基于像素和对象的变化检测方法,而是将土地使用/覆盖标签分配给图像场景,例如工业和住宅区域等。SLSCD主要应用于分析语义层面的变化,即地被覆盖类型的变化,不再仅仅关注于基态是否发生变化的问题。目前已经提出了许多方法,大致分为传统的方法和深度学习方法。
在深度学习兴起之前,利用手工特征的方法相继被提出,如尺度不变特征变换(SIFT)和一袋视觉单词模型(BOVW)等。Wu等[186]提出了一种基于BOVW模型的SLSCD框架和一种基于分类的提取语义变化信息的方法,其中场景图像由三种多时相学习词典的词频表示。为了进一步利用时间尺度信息,弥补人工特征的不足,一些学者在SLSCD中引入了无监督方法。Wu等[187]提出了一种结合核慢特征分析(KSFA)、一种基于核慢特征分析融合的无监督学习算法和后分类融合的方法,将独立场景分类与变化概率相结合,识别场景变化,识别过渡类型。而Du等[188]提出了一种用于无监督场景变化检测的潜在Dirichlet allocation (LDA)和多元变更检测(MAD)方法。
由于需要获取大量带标注的遥感场景数据样本,上述传统方法对大规模数据集的鲁棒性较低,部分传统方法的整体方案无法进行联合优化[189]。随着深度学习的发展,许多研究者将深度学习引入SLSCD以突破这些困难。Wang等[190]提出了一种名为DCCANet的场景变化检测网络。DCCANet通过CNN提取卷积特征,并利用深度典型相关分析(deep typical correlation analysis, DCCA)学习两视图数据的非线性变换,增强了时间图像的多时相关联的时间相关性,获得高度相关的特征。
3)目标检测:遥感图像目标检测的研究具有广阔的应用前景。它可以对重要区域[191]、道路、港口、机场的交通状况进行监测,进而协调对机场内飞机[192]、道路上车辆[193]、港口内船舶[194]的检测。然而,由于遥感图像信息复杂,目标体积小,基于自然图像的检测方法在遥感图像上无法取得良好的检测效果。因此,针对遥感图像解译中的目标检测任务,提出了大量的方法。对象检测集中于给定输入信息的已定义类中是否存在对象实例,如果存在,则通过边界框返回每个对象的空间位置、范围和类[195]。随着深度学习的发展,由于神经网络提取的深度特征具有强大的语义表示能力,目标检测的性能得到了迅速提高。一般来说,基于深度学习的目标检测方法主要分为两类:两阶段检测框架和一阶段检测框架[196]。它们之间的差异如图18所示。
两阶段检测框架:两阶段检测首先生成区域建议,然后对候选框进行分类。对于遥感图像中的目标检测,除了训练样本的局限性外,最大的挑战是如何有效地处理目标旋转[5]的变化。Li等[197]构建了包含附加多角度锚点和局部上下文特征融合网络的区域建议网络,以更好地提取遥感图像中空间目标的旋转和外观模糊特征。除了直接扩展经典的两级检测器,如R-CNN, Faster RCNN等。许多学者也根据遥感图像的特点提出了其他两阶段方法。Zou等[199]基于奇异值分解算法设计了SVDNet,采用特征池操作和线性SVM分类器进行船舶验证。Bai等[198]提出了一种基于时频分析的复杂背景下的大规模遥感图像目标检测方法。他们利用小波分解进行时频变换,再结合深度学习进行特征优化。并提出了一种基于深度强化学习的特征优化方法来选择主要时频信道。此外,设计了离散小波多尺度注意机制,使检测器能够聚焦于目标区域而不是背景,有效地从遥感图像中提取多尺度、多方向的特征(如图19所示)。
最近,物体检测已经取得了很大的进展。然而,目前广泛采用的水平边界框表示方法并不适用于无所不在的方向对象,如航拍图像和场景文本。在[200]中,提出了一种简单有效的框架来检测多方位目标(如图20所示)。它不是直接回归四个顶点,而是在每个对应的边缘上滑动水平边界框的顶点,以准确描述一个多方向对象。Zhou等人[201]提出了一种基于变压器的相关学习检测器。该算法充分利用目标之间的位置信息和相关性,对遥感图像中密集目标的旋转包围框进行预测。
一阶段检测框架:一阶段检测框架不生成区域建议,直接从输入信息中获取预测结果。Liu[202]等采用YOLOv2体系结构作为舰船检测的基本网络,提出了一种任意方向的遥感图像舰船检测框架。Yang[203]等人在RetinaNet的基础上提出了用于检测旋转物体的R3det探测器。该策略结合了水平锚的高召回率和旋转锚对密集场景的适应性的优点,利用设计的特征细化模块(FRM)实现了特征对齐。Wu[204]等利用空间频率通道特征、快速特征通道尺度变换等方法,提出了鲁棒性强的光学遥感图像检测器(optical remote sensing image detector, ORSIm检测器),使其能够处理图像中复杂物体的变形行为。
Ma[206]等人利用SSD[205]的思想,提出了一种端到端尺度感知的目标检测框架,用于多类目标检测任务,例如在相同的复杂场景中,地理空间目标的大小差异较大,地理空间目标分布密集等。该框架由特征分离与重新合并模块、偏移纠错模块和目标显著性增强模块组成。特征分离与重合并模块的目的是消除浅层特征图中较大物体的显著性信息,突出小物体的特征。然后将大尺度目标的有效细节特征传递到深度特征图中,以缓解多尺度目标之间容易出现特征混淆的问题。偏移量纠错模块通过提出的偏移量损失函数对多层特征图间特征空间布局的不一致性进行纠错。目标显著性增强模块通过提出的隶属度函数增强目标感兴趣特征并抑制背景信息。最后,检测包含精细目标特征的多尺度特征映射,以获得更好的检测性能(如图21所示)。
针对遥感图像目标检测中复杂背景的挑战,Zhang等[207]提出了一种前景感知的遥感图像目标检测模型,该模型从特征关系学习和网络优化的角度增强了探测器的前景感知能力。该方法通过构建前景关系学习模块,引入前景锚点损耗函数,使网络专注于优化前景锚点,增强了特征图中前景区域的识别能力。提出了一种基于Transformer架构的双网络结构,将局部特征分层嵌入到全局表示中,用于遥感目标检测[208]。
4)对象跟踪:视频对象跟踪是场景内容分析和理解高级视觉任务的基本先决条件。如图22所示,它检测和跟踪图像序列中的对象。对象跟踪是在图像序列中检测和跟踪对象的过程,在此期间,对象在第一帧中指定,并在视频的下一帧中进一步检测和跟踪[209,210]。遥感领域物体跟踪的主要目的是跟踪光学卫星视频、航空视频和无人机视频中感兴趣的物体。遥感物体跟踪用于智能交通流量监控(211),环境监测[212],紫外线检测[213)等。在本小节中,我们重点讨论卫星视频上最近出现的物体跟踪算法。卫星视频中的对象跟踪与自然视频大不相同。首先,卫星的射程很广,通常在单个视频中覆盖数千平方公里。以吉林-1为例,它的分辨率约为Im,所以视频的视频大小为几千乘几千。
在遥感视频中,感兴趣的物体通常有十几个像素大小,外观特征很少,在复杂场景中很难通过外观特征准确区分物体。因此,在设计遥感物体跟踪网络时,有必要通过运动模型等视角来补偿稀缺的外观特征。
单对象跟踪:一般来说,生成方法和判别方法是目前主流的两种单目标跟踪框架。
(1)生成模型:生成跟踪方法通常学习表示当前帧中对象的模型。在下一帧中,选择一个与目标最相似的候选对象作为跟踪结果。模型使相似度最大化或使相应的重构误差最小化[214,215]。早期生成算法的对象模型包括高斯混合模型、贝叶斯网络模型、马尔可夫模型等。Wang等[216]提出了一种由粗到细的高分辨率舰船跟踪方法。
该方法引入了约束模板匹配方法。[217]提出了一种带有形状先验的船舶跟踪模型,使用水平集分割来提高检测性能。虽然生成技术在上述大多数场景中都是有效的,但目前的方法大多只关注对象本身的特征,而忽略了其与环境或其他非对象的相关特征。因此,自2010年以来,学者们对基于歧视的方法给予了更多的关注。
(2)判别模型:判别跟踪方法通常将跟踪视为将目标与背景区分开来的二值分类问题,从而选择目标[215]。目前,以相关滤波器和深度学习为代表的判别方法已经取得了令人满意的结果,并得到了广泛的应用。基于相关滤波器的跟踪器根据视频第一帧的目标位置提取目标特征,并进行训练学习,得到相关滤波器。并对提取的特征进行傅里叶变换,乘上相关滤波器,再进行傅里叶反变换,提高了计算效率[218]。Du等[219]使用核化相关滤波器(kerized correlation filter, KCF)跟踪器[220],这是一种经典的相关滤波算法,用于遥感视频目标跟踪。根据遥感图像的特点,将KCF与三帧差分方法相结合,获得更精确的跟踪结果。Shao等[221]将KCF和光流相结合,提出了一种用于卫星视频目标跟踪的VCF跟踪器。由于物体缺乏外观特征,VCF使用光流图作为物体的速度特征图,并使用KCF在速度特征上跟踪物体。此外,设计了惯性机构,利用目标运动的特点自适应地防止模型跟踪漂移。一种基于相关滤波器的双流跟踪器被提出来探索用于小目标跟踪的空域-光谱特征融合和运动模型[222]。
Fu等[223]提出了一种基于双正则化策略的DRCF跟踪器,解决了基于dcf的视觉目标跟踪中有害的边界效应,提高了滤波器的鉴别能力。Xuan等[224]提出了一种旋转自适应相关滤波器(rotation adaptive correlation filter, RACF)跟踪算法,通过估计目标的旋转角度来解决目标旋转引起的跟踪稳定性问题。从特征的角度,Liu等人在人工特征的基础上加入深度VGG特征提取目标特征,并扩展了卫星视频的相关滤波和跟踪方法。提出了一种遮挡判断指标,利用运动轨迹对遮挡进行补偿。
然而,基于相关滤波器的跟踪算法往往使用手工制作的特征,当目标尺寸较小和背景复杂时,往往面临挑战。深度学习技术提供了一个新的研究趋势。基于深度学习的目标跟踪算法框架从预测的前一帧速率的位置提取感兴趣区域(region of interest, ROI)特征,然后建立基于深度网络的判别模型,得到目标当前帧的跟踪结果。
与相关滤波的固定目标定位方法相比,深度学习网络通过学习获得了目标跟踪的定位能力,使得算法更加灵活。深度学习最直接的实现是将预训练模型直接应用于遥感视频跟踪。如Hu等[202]提出了一种将深度学习和光流方法相结合的CRAM网络。从光学图像和光流图像中提取外观特征和运动特征,以缓解跟踪漂移问题。Feng等[225]将Siamese网络的经典算法siamrpn++与基于聚类的帧差法相结合,提出了cdf - siamrpn++。在CDFSiamRPN++中,利用聚类方法分割相邻帧间的差异映射,有效地抑制了环境噪声的干扰,保留了有效的运动信息。Shao[226]等人提出了HRSiam跟踪器,将HRNet的高分辨率特征提取步骤与SiamRPN跟踪器相结合。由于HRNet能够在保持高分辨率的同时进行特征提取和多尺度特征融合,因此将提取的高分辨率特征应用于SiamRPN进行目标跟踪,具有强大的小目标跟踪能力。
Song等人[227]也提出了一种基于SiamRPN++的跟踪器。该跟踪器集成了空间和通道注意力,以提高跟踪精度。Li等[91]提出了crfpf模块,建立并行分支提取多尺度特征,并设计了协同注意学习机制,学习相关信息,增强对象的显著性。此外,提出了一种MBLT跟踪器来学习目标的运动和背景[228]。对MBIT的跟踪过程如图23所示。首先,DCF跟踪器生成原始跟踪结果。然后,提出了一种基于FCN的预测网络来估计定位概率。第三,采用FLICM方法对可行区域进行分割。最后,结合上述三个模块的结果对跟踪结果进行预测。为了充分利用神经网络的学习能力,还引入了深度强化学习来跟踪卫星视频中的目标。Cui等人[218]提出了一种动作决策-遮挡处理网络,利用遮挡信息驱动遮挡下的动作。
多目标跟踪:与单目标跟踪相比,遥感视频中的多目标跟踪具有更大的应用前景。遥感视频中的多目标跟踪可以持续监控军队可疑目标,获取敌方情报;在民用方面,可以监测交通流量进行统计分析,为城市管理提供数据支持。在遥感视频中,多目标跟踪分为飞机、船舶和车辆三大类。由于飞机的目标尺寸较大,而在海面上运动的船舶稀疏且模糊程度较低,因此很少有论文对这两类目标进行多目标跟踪。他等[229]针对卫星视频中舰船和飞机两种类型的物体设计了算法。该算法从多任务学习的角度将多目标跟踪建模为一个图信息推理过程。该算法通过图的时空关系模块,挖掘图中潜在的高阶关系。
与飞机和船舶的跟踪相比,车辆的多目标跟踪受到了广泛的关注。Xiao等人[230]认为跟踪问题是一种关系图匹配框架。为了在广域视频中获得较高的检测和跟踪精度,提出了一种结合道路图和车辆运动的联合概率关系图方法。Zhang等[231]提出了一种两步全局数据关联算法:首先生成车辆的局部目标轨迹,然后将局部轨迹合并到全局轨迹中。轨迹关联模型定义了基于卡尔曼滤波的轨迹转移矩阵,将时间间隔较大的轨迹连接起来。同时,通过双层k最短路径优化方法,得到了关联问题的近似最优解。
Seyed Ali等[232]利用背景减法检测运动车辆,估计车辆的轨迹、速度等信息。Zhang等[233]也使用背景差法检测运动车辆,并应用动态关联方法匹配目标。Ao等[234]建立了局部噪声模型,通过指数概率分布来区分车辆目标。Jie等[235]提出了一种跨帧关键点检测网络(CKDNet)和一种时空运动信息引导跟踪网络。CKDNet通过收集帧间的互补信息来辅助关键点的检测,并通过构建双支长短时记忆来有效地跟踪密集排列的车辆。Wu等人[236]提出了slow Feature and sotion Feature来引导多目标跟踪,其中基于sf的包围盒提议引导NMS模块增强了感兴趣区域的检测。
5)遥感三维重建:三维重建是广泛的遥感应用中的一个根本性挑战[237]。本小节主要根据数据源和立体匹配算法进行遥感三维重建,如图24所示。
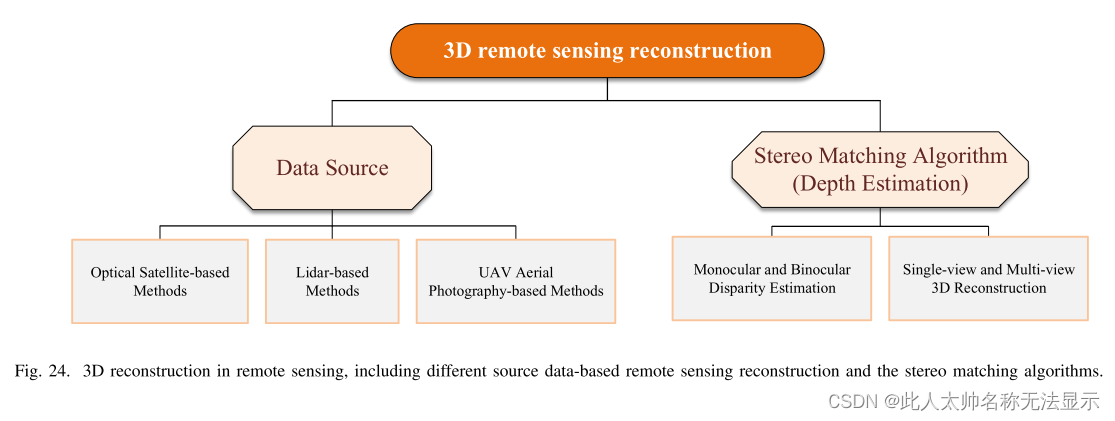
基于不同数据源的遥感重建:现有的遥感三维重建方法根据数据源可分为基于光学卫星、基于激光雷达和基于无人机航拍的重建方法[238、239、240]。
基于光学卫星技术的数字曲面模型和三维重建又称视觉立体制图。主要利用光学遥感卫星进行高精度地面立体观测,获取地面模型。类似于光学卫星图像,由UAV航空摄影方法获得的地面图像也是可视的。它已被证明是一种高效可靠的工具,可以生成高精度的地形和历史景观结构重建和模型[241]。[241]利用无人机获取木材流建造的废弃景观图像,然后进行三维重建,对水资源管理具有重要意义。
对于光学图像的三维重建,一些自监督技术可以使重建结果的二维投影与输入图像之间的距离最小化。一些非监督方法是基于生成式对抗网络来重建三维形状。相比之下,基于激光雷达扫描的遥感图像分辨率高,可靠性强。它所获得的无缝、精确的高程数据在地球科学中有着广泛的应用。激光雷达点云装置获取的数据为点云数据。每个点包含三维坐标信息,有时还包含颜色信息、反射强度信息、回波频率信息等。总之,激光雷达生成的数字高程模型(DEM)、数字地表模型(DSM)和数字正射影像(DOM)被应用于城市三维建模、自然灾害评估和资源调查等各个方面。
此外,还利用干涉合成孔径雷达层析成像技术反演了垂直地面上不同高度地物的散射强度,实现了三维雷达成像。层析成像技术可以重建地物的垂直高程和方向结构,在地形测绘、森林参数估算、城市建筑三维建模、文物成像等方面具有很大的应用潜力。
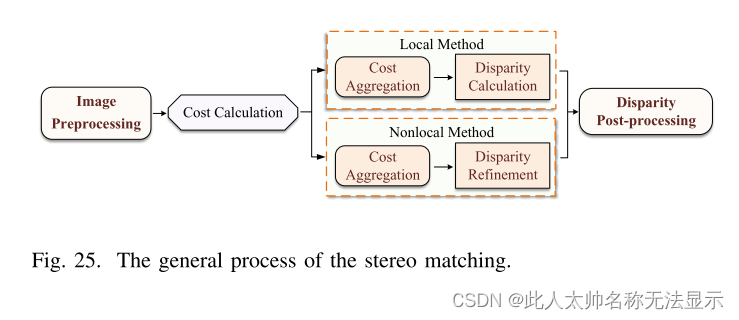
立体匹配:立体匹配在三维重建中具有特定的研究意义,具有一定的普适性,因此已成为三维重建的研究热点。立体匹配的一般过程如下:图像预处理后,全局方法(上图右侧路径)的思想是利用全局信息进行视差优化(视差优化)。它寻求每个像素的最优视差结果,以使国际和整体匹配成本最小化[242]。局部立体匹配算法中的视差计算一般比较简单,采用WTA赢者全取理论直接搜索视差。两种方法都需要在计算完视差图后进行视差后处理。在初步获得视差图后,对视差图的结果进行判断,发现可能存在的匹配误差并进行校正。常用的视差后处理方法包括左右一致性检测、遮挡填充和加权中值滤波。
立体声匹配在3D重建中具有一定的研究意义,并且具有一定的普遍性,因此它已成为3D重建的研究热点。立体声匹配的一般过程如图25所示。预处理图像后,使用全局信息进行视差优化的经典想法是找到每个像素的最佳视差结果,以尽量减少全局和整体匹配成本[242]。这一步被称为差异优化。差异计算已成为现有立体声匹配的研究重点之一。Ilepth和差异可以直接相互转换,因此深度估计也已成为立体声匹配的研究热点。
**深度估计:**深度估计,使用一个或仅/RGB图像的多个视角,估计图像中每个像素相对于拍摄源的距离。这是场景重建和理解任务的关键一步,也是3D重建的一部分。除了使用激光雷达或结构化光在物体表面反射获得深度点云的昂贵方法外,最常见的传统深度估计方法有单目和双目两种。相比之下,单目测距方法计算量复杂,精度不如双目测距方法高,且常在条件具有挑战性的情况下使用。深度学习在深度估计方法上也不断发展。
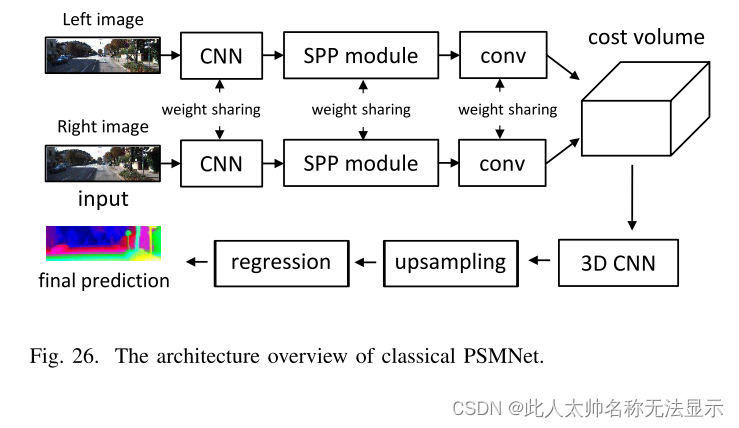
(1)单目和双目视差估计:主要有单目估计和双目估计方法。目前有许多常用的深度学习单目测距方法。例如,[243]提出CAM-Convs convolution,可以考虑相机参数,使神经网络可以学习校准感知模式。[244]是一种运动特征,被认为是人类视觉系统最重要的特征之一。该算法采用递归神经网络(RNN)训练和多视角图像repr技术来提高单目深度估计,并提出monoResMatch,结合不同角度的特征,与输入图像保持一致,并在两个线索之间进行立体匹配,从单个输入图像推断到新的深度学习框架。综述[245]研究了深度学习双目深度估计方法,并对2016年的GANet[246]、PSMNet[247]和SegStereo[248]等16种深度学习深度估计方法进行了比较。近年来,也出现了一些比较先进的方法,如PlaneMVS [249], Nerfingmvs[250],[251, 252]等。PSMNet架构概述如图26所示。它是一种典型的双目视差估计模型。左边和右边的图像是模型的输入。采用CNN作为特征提取模块和空间金字塔池(spatial pyramid pooling, SPP)模块进行特征提取。然后,将提取的特征串接在一起作为成本量模块的输入。最后,设计了具有非采样和回归模块的三维CNN,用于成本体积正则化和视差回归。
对于遥感中的视差估计[253,254,255]。其中,Yu等[253]主要利用二维离散小波变换(2D-DWT)增强现有加权α形(w - α sh)的局部不变特征。并将其应用于仿射失真小、噪声小的遥感图像中。实验表明,该方法能有效缓解立体遥感图像中几何畸变和辐射畸变的图像匹配问题。此外,在[254]中提出了一种新颖的边缘感知双向金字塔立体匹配网络,在保持原始结构的同时提高了无纹理区域的性能。该算法能有效解决高层建筑遮挡区域和无纹理区域造成的视差估计精度差的问题。[255]尝试使用CNN来匹配月球表面等无特征区域的遥感立体图像。
(2)单视图和多视图三维重建
现有的相关算法从视图角度可分为单视图和多视图的三维重建方法。单视图三维重建是指对给定的单个图像或目标实现三维重建。目前使用的大多数单视图3D理解技术都采用编码器解码器结构,编码器将输入图像转换为潜在表示,解码器必须对输出空间的3D结构进行复杂的分析[256]。
虽然单视图三维重建可以产生不同的三维结果(如点云或网格),但它也可以处理许多混乱的图像。遥感图像的三维重建是地球表面变化跟踪的关键。[257,258]从给定图像中有序地预测深度,并从同一视图下的深度估计单视图球形地图。然而,单视图三维重建结果往往缺乏完整性和准确性,特别是在有障碍物或遮挡区域的情况下。
多视图三维重建在一定程度上缓解和解决了上述问题。多视图重建主要有两种类型:一种是从两张或多张视图的图像中重建静止物体,另一种是从视频或多帧图像中重建运动物体的三维形状[259]。多视图重建具有灵活性和可扩展性,能够适应大规模场景。当然,要精确重建城市景观中的多视点纵深图,还需要克服很多障碍,比如重复纹理的存在,以及纹理较差的地方。为了解决上述问题,[260]提出了一种基于图像三角形的多视图三维重建(multi-view 3D reconstruction, IMGTR)方法。在[261]中,提出通过结合使用密集图像匹配方法计算出的许多深度图来生成高质量的数字表面模型。它在重建表面不连续、重复图案和非纹理表面方面表现良好。
五、遥感技术的实施
A.公共数据集
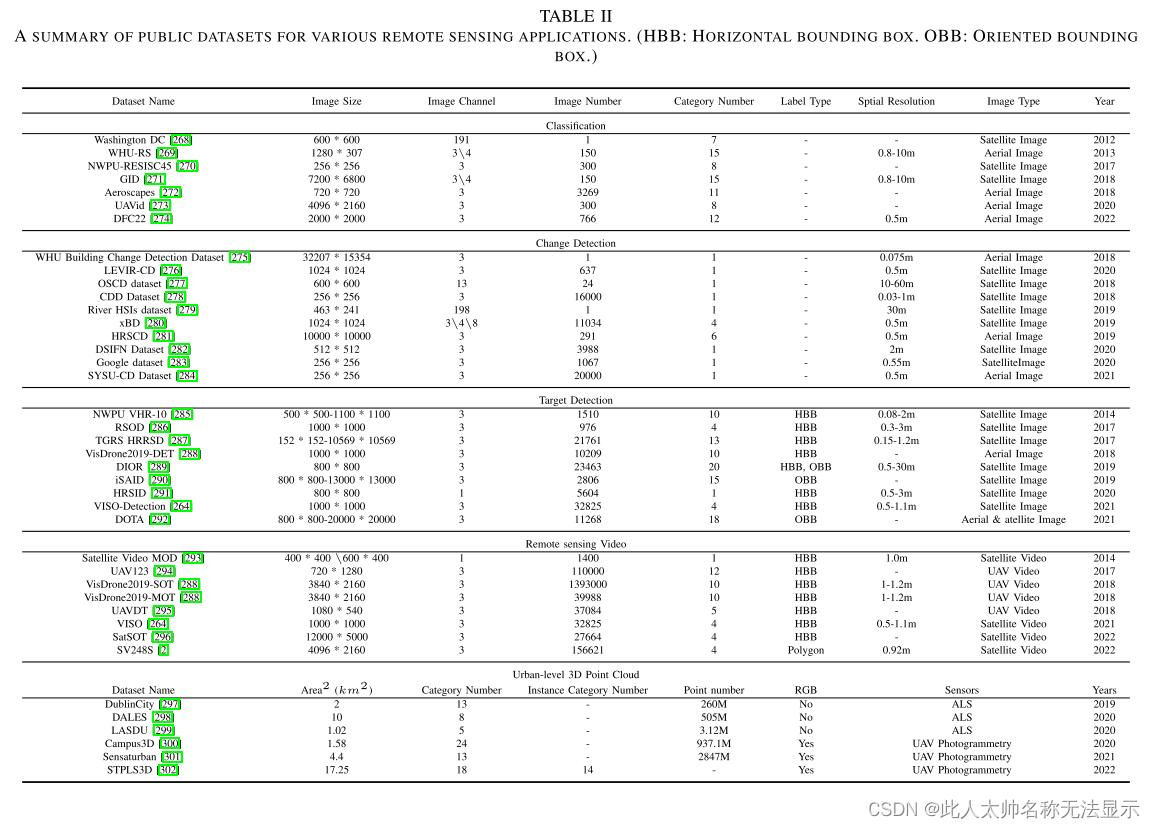
深度学习算法在各个领域都表现出了优异的性能。这与使用大量精细标记的数据进行神经网络训练是不可分割的。研究人员需要使用带标签的数据来开发算法,以满足不同的应用。表二总结了常用的遥感数据集,并根据其主要应用的任务进行了分类。
B.软件平台
近年来,对地观测技术得到了极大的发展,大规模的遥感数据被存储、记录和开发,供社会和研究人员免费使用[262,263,264]。然而,传统的遥感解译方法需要用户在本地计算机上下载和处理数据。例如,The Environment For Visualizing Images (ENVI)等图像处理平台,在用户获取数据后,可以对图像进行图像增强、正演校正、数据融合转换、基于知识的决策树分类等功能。该平台是安装在一台机器上的离线软件,可以帮助人们进行数据预处理和简单的图像识别任务[265]。随着数据的增加,本地存储和解释数据的计算能力面临着巨大的挑战。
随着互联网的发展,遥感应用平台已经开始向云方向发展。部署在云中的遥感平台具有以下特点:
(1)云平台可以提供丰富的存储和计算资源。用户可高效处理大规模遥感数据;(2)计算密集型任务通过云服务器完成,降低了用户计算机的计算能力需求,降低了软件的使用门槛。
(3)用户可通过任何可接入互联网的设备接入平台,随时随地执行遥感图像处理、分析等任务;
(4)用户通过网页访问平台,可以随时获取平台的最新数据和更新功能,并使用最新算法处理最新数据,提高工作效率。
以上优点是传统图像处理工具所不具备的。因此,各研究机构和企业纷纷投资建设遥感云平台。该平台无需本地下载数据,即可在云上执行口译服务。这些平台集成了各种工具和应用程序,为用户提供完整的数据采集和处理解决方案。从使用的角度来看,主流平台可以分为两类:一类是面向专业用户,使用编程工具的遥感数据云平台。该平台要求用户使用提供的应用程序编程接口(API)进行数据操作和处理,如谷歌地球引擎(GEE)。通过各种灵活的api,专业人员可以根据自己的需要定制函数和算法,实现不同的功能。另一类是面向普通用户的遥感数据云平台。这种类型的平台进一步封装了数据和算法。用户只需要选择或上传相应格式的数据,并选择要解释的任务。该平台将能够实现数据和结果的自动算法处理和可视化,如遥感数据智能判读平台、SenseEarth等。通过简单方便的操作,普通从业人员也可以判读遥感数据,有利于民间遥感技术的推广。在本节中,我们选择GEE平台和遥感数据智能判读平台进行介绍,并分别展示这两类平台的具体特点。
1)谷歌Earth Engine:谷歌Earth Engine (GEE)是谷歌于2010年推出的遥感解译云平台。该平台是目前最流行的大数据地理信息处理平台之一。该平台基于谷歌的计算基础设施,为用户提供发现、分析和可视化大地理空间数据的免费服务。
在GEE中,可以通过平台提供的接口实现不同的第三方网络应用。对于使用GEE平台的研究人员来说,使用GEE平台提供的API是非常必要的。GEE提供两种语言的api, JavaScript和Python,以满足大多数程序员的需求。通过不同的api,用户可以方便地访问数据,使用GEE提供的各种应用程序,并实时查看运行结果。该平台分为三个部分:数据目录和资源管理器,代码编辑器和时间间隔。
数据目录和探索者:数据目录包含大量的地理空间数据,收集了大量公众可访问的卫星图像,包括陆地卫星、MODIS和Sentinel图像,以及大量的大气、气象和矢量数据集。这些数据集包括各种卫星和空气系统的光学图像、环境变量、天气和气候预报、土地覆盖和社会经济。
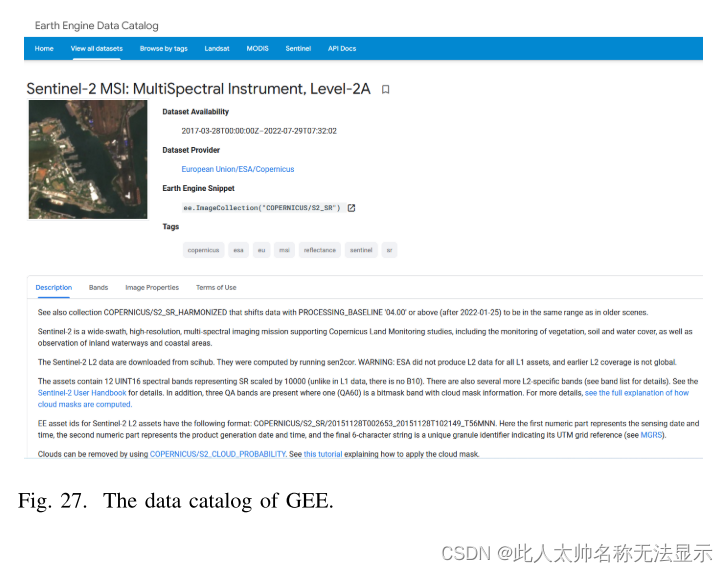
图27为《数据目录》中sentinel -2卫星多光谱仪捕获的数据内容页面。这个内容页面显示数据的可视化缩略图、数据可用的时间、数据集提供程序、用于访问数据的API,以及数据的详细描述。用户可以浏览数据目录,根据数据集描述选择所需的数据集,并使用提供的API获取数据。然后,数据可以通过GEE提供的Explore快速可视化。
代码编辑平台:代码编辑平台是GEE数据采集、处理、分析和可视化的主要平台。如图28所示,代码编辑器主要分为四个功能块:可视化区域、脚本管理器、代码编辑器和信息栏。
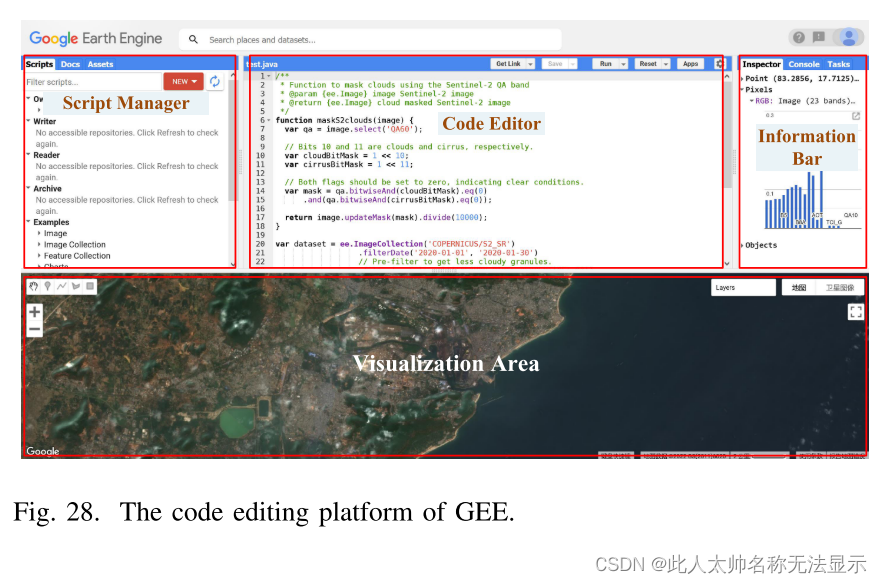
页面下方是代码编辑平台的可视区域。这是用户交互、数据和结果可视化的主要领域。本区域以世界地图为基础地图,提供基本的地理位置信息。数据和代码分析结果采用多层叠加的方式显示。用户可以在可视化区域中拖动和缩放结果,通过单击标记位置,等等。标识的位置信息将显示在信息栏的“巡检器”页面中。
页面的左侧是Script管理器,它存储用户编辑的脚本和GEE平台提供的示例脚本。通过管理员,用户可以选择或删除自己的脚本。同时,提供GEE覆盖图像采集、预处理、可视化、绘图等示例脚本,并提供分类、气候建模、地形可视化等演示,为用户提供完整的代码使用演示。
页面中间是通过谷歌提供的云平台基础设施提供的代码编辑器区域。通过编辑JavaScript和Python代码,用户无需考虑代码运行环境的问题。写完代码后,可以点击页面顶部的“运行”按钮直接运行代码。
页面右侧为信息窗口。信息窗口包括检查器、控制台等。检查器显示地图上用户标记的信息。控制台将显示正在运行的代码的输出输出。
简单的数学运算,复杂的图像处理和机器学习功能都可以在平台上使用。
通过编写代码,用户可以充分利用GEE平台的功能。GEE平台提供了丰富的数据和API,这是其广泛使用的重点。但是,由于它是免费的,并且对公众开放,所以像深度学习这样的计算密集型任务不能得到广泛的支持。用户在训练模型、数据采集、新方法和功能设计等方面受到不同程度的限制。
Timelapse项目基于存储在GEE平台上近40年的数据,生成全球范围内的可扩展视频。该项目每年将一幅图像拼接成每个地区的视频,向人们展示地球在时间和空间上的变化。在这个项目中,我们可以记录最真实的自然和人类活动的记录,如冰川融化、森林火灾和城市发展。
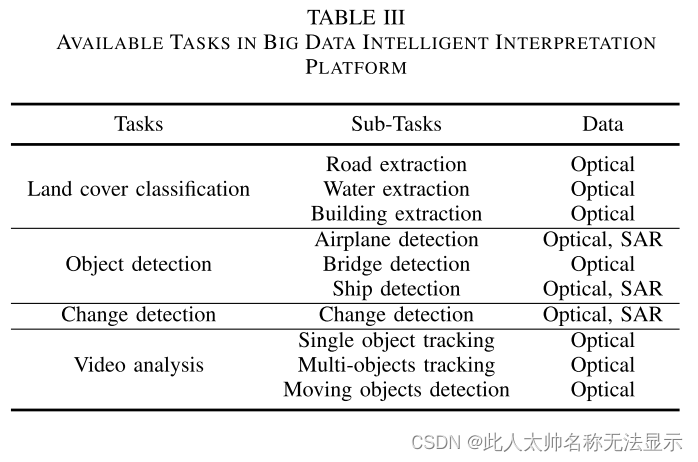
2)遥感数据智能判读平台:“遥感数据智能判读平台”与v - b1子节中的谷歌Earth Engine不同,是为了满足从业者对遥感数据的判读需求而设计的。通过封装相关功能块,用户可以直接操作平台。该平台借助人工智能算法,集成数据判读、数据管理、场景应用等可用模块,实现算法处理自动化和数据判读结果可视化。该平台能够从全色、可见光、多光谱、高光谱、合成孔径雷达图像和卫星视频等全模态遥感数据中实时提取和识别目标信息。目前,该平台已开放土地覆盖分类、目标检测与识别、元素变化检测和智能视频判读四大主要功能,为从业人员处理遥感数据提供技术支持。
“遥感数据智能判读平台”的体系结构由数据存储层、平台服务层和平台运营层三部分组成。
数据存储层主要包括用户数据、配置数据和图像数据。用户数据记录用户的相关信息。配置记录遥感数据的相关信息。图像数据包括平台提供的公共数据集和用户上传的仅对所有者可见的私有数据集。图像数据全部存储在云端,大大降低了用户数据存储的压力,可快速为解译任务提供数据支持。
平台服务层主要包括三部分:数据管理服务、数据解释服务和任务管理服务。数据管理服务管理用户数据、图像数据和解释结果。它可以借助平台操作层的指令对云中的数据进行操作。图像判读服务集成了多种人工智能算法。通过平台操作层确定解译任务,高效完成土地覆盖分类、目标检测、变化检测、视频目标跟踪等任务。任务管理服务主要负责数据检索、参数传输和任务调度;当用户通过平台操作层创建多个任务时,平台操作层需要对任务进行调度,并为其提供相应的初始化参数和图像数据。
平台操作层主要包括用户认证、用户数据和任务处理操作。用户的鉴权操作可以使用云存储的用户信息进行鉴权,赋予用户操作权限。用户数据操作可以在数据存储层读取和修改用户数据、图像数据和解释结果。任务处理层主要负责将任务分配给平台操作层,并对平台操作层的异常信息和日志信息进行反馈。
基于上述体系结构,平台包含两个关键系统:用户交互系统(UIS)和数据解释系统(DIS)。
客户端主要是用户和平台之间的接口。用户可以通过浏览器访问客户端,进行数据上传、浏览、口译任务执行、分析并显示结果等操作。服务器负责数据存储管理和执行不同的解释任务。
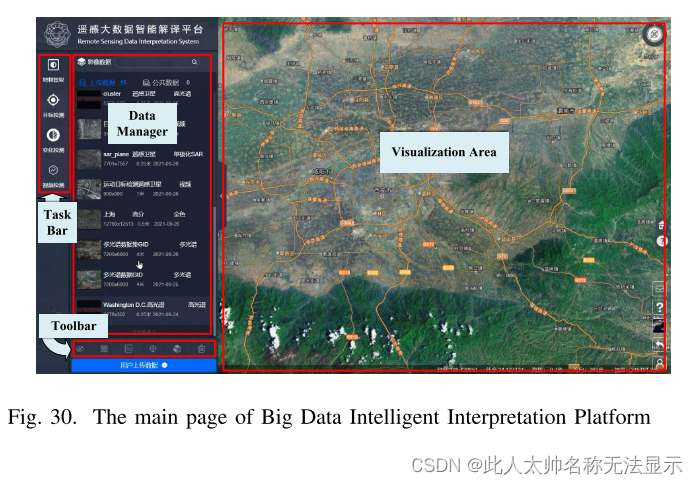
用户交互系统:ui是用户与平台交互的核心系统。用户可以通过Internet随时访问web页面,并通过登录和认证后进入ui执行翻译任务。登录后的系统操作界面如图30所示。系统操作页面分为四个区域:任务模块、数据列表、数据显示区域和功能模块。在任务模块中,用户可以选择他们想要执行的任务类型。在数据列表中,公共数据集和私人上传的遥感图像以缩略图形式显示;数据显示区将实时显示用户选择的遥感图像和相应的遥感图像。解释结果。用户可以拖拽、放大该区域,以便浏览数据。功能选项为用户提供“图像透明度选择”、“可视化通道选择”、“图像缩放”、“解释结果选择”等功能。
数据判读系统:DIS是遥感数据智能判读平台的核心,主要负责遥感图像的智能判读,高效、准确地挖掘遥感图像的充分信息,为用户提供遥感数据的实时分析服务。该平台主要包括四项任务:土地覆盖分类、目标检测与识别、元素变化检测和智能视频判读。每个任务根据目标类型和数据源划分为SAR、可见光、多光谱和高光谱等子任务。土地覆被分类分为道路分类、水分类、建筑物分类和土地覆被分类。目标检测与识别分为飞机、桥梁和船舶检测。视频智能解译分为单目标跟踪、多目标跟踪和运动目标检测。可用的任务见表三。图31显示了SAR变化检测、舰船SAR检测、HSI水体分类、目标跟踪、多机跟踪等任务的解译结果。

C.硬件系统
在传统研究中,研究者通常使用多个gpu或计算机集群进行算法研究[303,304],但忽略了能耗和计算资源的约束。虽然很多算法在GPU加速下都能取得很好的效果,但离实际行业的要求还有很长的路要走。许多复杂的模型无法部署在小型设备上或实时计算,这是困扰许多工程师的主要问题。
在遥感算法的应用中,硬件系统的研究和开发更加迫切。目前,大多数遥感算法都是在地面计算站进行计算,这对遥感技术的应用和遥感数据的完整挖掘产生了重大影响。现有的主要要求分为三点:
(1)实时性:实时性也可以称为无延迟,即要求设备在处理数据时有固定的处理时间,以保证数据流的稳定处理。
(2)数据量:遥感卫星捕获的数据量很大,并不是所有的数据都能送到地面进行处理。这就需要能够安装在飞机和卫星上的硬件设备来处理和传输必要的数据,以提高数据的利用效率。
(3)功耗:机载和卫星设备由于电池等电源的存在,功耗较低。低功耗可延长用电时间。因此,本章总结了目前主流的硬件平台,并选择了易于开发、计算稳定、低功耗的FPGA器件进行进一步的研究。
1)硬件系统的分类:所有能够运行AI算法的芯片,包括cpu,都可以称为AI芯片。在传统的冯诺依曼结构中,CPU执行的每条指令都需要从内存中读取数据,并根据该指令对数据进行操作[305]。从这个特性来看,CPU的主要职责不仅是数据操作,还包括执行诸如内存读取、指令分析和分支等命令。然而,大多数人工智能算法,尤其是深度学习算法,通常需要大量的数据处理。当CPU执行算法时,CPU被限制为串行执行,这将花费大量的时间读取和分析数据/指令。这就是为什么算法不适合并行处理密集数据,不能充分利用芯片的潜力。因此,计算框架通常是异构地执行的,它结合了CPU和计算卡。CPU对数据进行读取等操作,计算卡进行大规模、密集的数学计算。一般来说,AI芯片与cpu不同,是根据人工智能算法的特点,专门为加速而设计的芯片。按技术架构可分为GPU、ASIC、FPGA、Neuromorphic计算芯片[306]。
GPU:图形处理单元(GPU)具有相对简单的架构设计。由于大部分晶体管组成了多个专用电路和管道,GPU在计算性能上优于CPU。GPU还具有强大的浮点计算能力,可以帮助深度学习算法克服计算压力,释放AI的全部潜力。此时的GPU开发已经达到了一个相对成熟的阶段。像谷歌、Facebook、微软、TWITTER和百度这样的企业都在使用gpu来分析图像、视频和音频资产,以改进搜索引擎和图像智能软件。此外,GPU适用于各种行业,如VR/AR、无人驾驶等。但是gpu也有一些局限性。训练和推理是深度学习算法过程中的两个阶段。GPU平台是一个高效的算法训练平台。然而,当处理单个输入进行推理时,并行计算的好处不能完全实现。GPU耗电量大,无法独立工作。需要一个CPU来安排它工作。
ASIC (application-specific integrated circuit):专用集成电路(ASIC)是一种为满足特定要求而设计的专用芯片。对于高性能、低功耗的移动应用,定制特性有利于asic的性能功率比,并在可靠性和集成度方面具有优势。谷歌的TPU、Cambrian Chips、Horizon的BPU、Amazon的Inferentia都是ASIC芯片。人工智能应用是ASIC器件的理想选择。首先,ASIC完全定制的电路可以提高性能。谷歌的TPU比CPU和GPU解决方案快30到80倍,同时使用更少的电力和空间。其次,下游需求促进了人工智能芯片的专业化。由于训练数据的实时性和私密性的要求,很多应用场景的计算不能完全依赖云。本地软件和硬件必须支持它。然而,ASIC的设计周期较长,不能适应算法的发展,限制了ASIC的应用。
FPGA: FPGA的全称是“现场可编程门阵列”。在比较FPGA和CPU时,可以识别出两个特征。首先,FPGA没有内存和控制带来的存储。因此,数据读取速度更快。其次,它使用更少的能源,因为FPGA不需要读取命令。同时,FPGA不同于GPU。由于FPGA的并行管道和数据并行处理能力,它在特定应用程序中提供了更显著的效率改进。FPGA在深度学习算法的推理阶段经常被使用,因为它非常适合在硬件流水线上进行数据处理,并且具有良好的运行性能。此外,FPGA在设计灵活性和速度方面优于ASIC。算法的修改可以很容易地部署在FPGA中,而无需重新设计电路。由于其灵活性和性能,它经常在各个行业取代ASIC。
神经形态计算芯片:神经形态计算芯片是一种从结构上模拟大脑计算机制的电路。这项技术还处于发展阶段。其研究工作可进一步分为两个层次。一个是神经网络层,对应于神经形态结构和处理器。它的内存、CPU和通信组件完全集成在一起,信息处理在本地进行,消除了计算机内存和CPU之间通常的速度瓶颈。神经元可以很容易地、迅速地相互交流。只要这些神经元接收到其他神经元的脉冲(动作电位),它们就会同时被激活。IBM的Truenorth芯片和清华的Tianji芯片就是一个例子。第二是神经元和突触的层次,相应的创新是组件的层次。例如,世界上第一个能够实现高速无监督学习的人工随机相变神经元是由IBM苏黎世研究中心生产的[307]。虽然神经形态计算芯片还没有完全开发出来,而且在大规模应用之间还有一段距离,但它有可能彻底改变计算机体系结构。
2) FPGA结构与优势:早在20世纪60年代,Gerald Estrin就提出了可重构计算的概念。但是直到1985年Xilinx才推出了第一个FPGA芯片。虽然FPGA平台的并行性和功耗都很好,但由于其高重构成本和复杂的编程,一直没有引起足够的重视。与冯诺伊曼架构下的gpu和cpu不同,虽然fpga开发起来更困难,但它们仍然有很多优势。下面从五个方面进行讨论[308]。
(1)开发时间和难度。FPGA的开发时间和难度介于ASIC和GPU之间。通常,算法是使用成熟的算法框架直接在GPU上开发的。算法设计完成后,必须先准备好算法所需要的操作符,然后才能将算法部署到FPGA上。现代深层网络通常堆积了一系列固定的操作(如卷积、池化等),所以这些常用的操作符可以直接使用。Xilinx等公司提供了相应的部署工具包。用户可以使用该工具箱直接将TensorFlow等深度学习框架的编程算法进行转换,部署在FPGA上,大大减少了FPGA开发的时间和难度。
(2)灵活性。fpga可以提供更灵活的体系结构。其灵活性主要体现在可编程计算资源和IO接口上。FPGA上的计算资源是DPS和块随机访问内存模块混合的可编程硬件资源。用户可以通过配置数据通道、单指令多线程等实现大规模并行计算,以满足所需工作负载的需要。同时,任何可编程IO连接允许FPGA连接到任何设备(网络或存储设备),而无需CPU协助进行数据调度,极大地提高了FPGA的使用灵活性。
(3)实时。FPGA芯片内部由硬件通过数百万个逻辑单元来实现。逻辑单元之间的硬件连接代表了算法流程。这样FPGA就避免了读取操作指令的操作。同时,通过与硬件上的存储连接,每个逻辑单元直接配置单独的存储,避免了GPU计算中申请内存、仲裁等操作,进一步提高了FPGA的稳定性。结合以上两点,FPGA可以在硬件层面保证数据读取和算法执行。所有算法的性能都可以在一个固定的时钟周期内完成计算,可以有效满足大多数实时处理硬件系统的需求。
3) ofFPGA在遥感中的应用:根据并行处理方法(如图33所示),可分为独立并行处理数据块、内部串行计算;整体数据处理,并行内部计算;并并行处理数据块和并行内部计算。
**(1)数据并行,计算串行。**它适用于每个数据块之间的相关性较弱,可以独立操作,并且每个步骤的操作之间存在因果关系。遥感图像可以用来观察某一区域,通常图像宽度大,数据量大。遥感数据可以用来检测一个特定的位置,通常图像宽度大,数据量大。数据并行和计算序列化是流行的并行技术,它们是基础的,易于扩展。[309]在FPGA上部署大规模遥感实时树冠检测算法,将原始的大规模场景数据划分为小块。它基于最大局部滤波器对原方法进行优化调整,以减少FPGA的利用率,减少空闲周期,达到不同资源利用率的平衡。[310]提出了一种基于Fast UNmixing (FUN)算法的在轨高光谱图像并行端元提取方法。该方法将原始高光谱图像分割成固定大小的子图像,并迭代提取子图像中的端元。该技术可广泛应用于各种计算机设置,对于不同的处理性能和能源效率是可扩展的。此外,基于块的分块方案具有较高的容错能力,适用于高空间辐射、硬件脆弱的遥感卫星环境。[311]在FPGA上实现了基于正交投影算子ATGPOSP的目标检测方法。本文分析了利用高斯-约当消元法可以高度并行化矩阵反演运算的正交投影算子。在系统中设计了存储器访问模块,通过预取技术降低了输入输出通信的时延,提高了操作效率。[312]将低复杂度预测有损压缩(lplc)应用于高光谱图像压缩。图像分块并行处理,每个光谱通道的迭代优化过程高度简化。使用了大量的fifo,大大减少了DSP的使用,但略微增加了内存,实时压缩了满足多种质量要求的高光谱图像。
**(2)数据整体处理,内部计算并行。**它适用于每个数据块之间的关系,每个步进操作都可以独立执行。[313]提出了一种在FPGA上实现像素纯度指数PPI的方法。PPI方法中的端元串投影计算是独立的,可以同时执行,非常适合并行处理。此外,端成员字符串投影中的点积计算也可以逐像素地执行。即可以实现数据并行。但由于该方法处理中间结果需要额外的计算资源,使得时钟周期变长,因此只并行处理操作过程中的每个端元字符串和像素点积。
**(3)数据分块,操作并行化。**该方法在理论上可以最有效地利用计算资源。然而,在实际应用中必须考虑数据分布和集成的成本。[314]进一步分析了基于数据并行性的ATGP方法,提出了算子矩阵的向量化方法。矢量投影的运算是并行计算的,因此矢量中算子的更新只需一步完成。计算时间显著减少。卷积神经网络的执行显示了高度的并行性。不同位置的像素可以并行处理,而标准的卷积层包含多个过滤器。但由于硬件的限制,不可能充分利用所有并行模式。因此[315,316,317]将过滤器分成多组进行操作。计算时,将分组的滤波器沿通道维数移动,中间结果存储在累积缓冲区中,直到通道末端得到当前位置的卷积结果。
在不同的像素点同时进行上述的信道卷积运算,得到的结果就是当前卷积层处理过的feature map。[318]提出了一种独立的双通道DDR分层存储方案,用于存储和读取权重参数和特征数据。该方案采用乒乓缓冲技术,避免了各层输出特征图的存储与输入特征图的访问之间的冲突。
提高了算法在硬件上的处理效率,解决了CNN网络并行实现中FPGA存储和带宽难以匹配的问题。它解决了FGPA存储和处理带宽匹配不佳的问题,提高了算法在硬件上的处理效率。[319]提出了一种三层存储器访问架构,包括片外存储器、片上缓冲区和本地存储器。CNN的参数存储在芯片外的内存中。卷积处理引擎从输入缓冲区接收图像数据。由于硬件逻辑和内存资源的限制,无法建立足够的硬件模块来一次性计算整个层。每个卷积层通常都有几个卷积处理引擎,每个引擎都有一个用于存储中间结果的局部内存。
六、十大未决问题
深度神经网络在遥感领域的应用已成为一个重要趋势。然而,现代深度学习仍然存在许多无法解决的问题。由于人类可以动态地处理各种复杂的任务,大脑启发算法是新的研究范式。随着脑属性思想的研究,可以有效地弥补目前深度学习存在的问题。通过对脑性质和遥感影像解译研究现状的回顾,总结了未来10个研究方向和挑战。
A.如何设计模仿大脑结构的大脑启发算法?
人类大脑的结构是分层的、稀疏的和周期性的。目前,遥感领域设计的算法都遵循一个固定的结构。例如,卷积被广泛应用于图像处理任务中以提取特征,实现了对人脑视觉底层的简单模拟。此外,神经网络之间的连接是密集的。然而,在人类大脑中,潜在的视觉层是稀疏的。神经网络的设计能在一定程度上满足任务要求,但离大脑结构还差很远。
尖峰神经网络(SNN)[320]是一种进一步模拟人类大脑结构的神经网络。它通过信息流在神经元上积累,实现信号的激活和抑制。同时,该结构更接近于人脑的结构,从而实现信息处理中的稀疏连接。胶囊网络[321]也模拟神经元,通过向量表示特征的位姿信息。
这些模拟大脑结构的算法在自然数据中得到了广泛的研究。然而,由于遥感数据的复杂性,脑启发算法在遥感领域还需要进一步的探索。
B.脑启发遥感算法的可解释性。
目前,利用神经网络提高算法的精度和效率是主流方法。然而,神经网络的内在机理和参数的选择还没有得到很好的研究。这就导致了算法的结果在实际环境中并不完全可信和可靠。因此,脑源遥感的核心研究是模拟人脑相关的认知、感知等能力,提出具有高可解释性的算法。
现有遥感算法的可解释性研究很少。Hong等人[322]从非凸建模优化的角度讨论了可解释的高光谱人工智能算法的发展。许多浅层算法可以通过结合物理知识来解释。然而,深度算法的可解释性研究仍然是一个非常困难的问题。[323]使用可解释的CNN框架[324]对网络进行修剪。这类方法为网络中的过滤器增加了额外的损耗,以实现针对不同类的可解释性学习。此外,Transformer还利用注意力来构建神经网络。它也显示了一种能力,就像我们的大脑一样,能够成功地处理无序的信息流[325]。此外,注意图也显示出可解释性。
这些研究可以在一定程度上提高算法的可解释性。未来的遥感算法仍需要将遥感算法与大脑属性和物理知识相结合,以提高可解释性。
C.构建脑源遥感算法的因果推理能力。
大脑是一个复杂的、智能的结构,它利用知识和事实进行推理和得出结论。它根据不同器官获得的感知来推断事物。这些能力都归结为因果推理。因果推理作为一种新兴的理论,已经逐渐形成了指导人工智能算法设计的理论体系。
目前,在遥感数据的解译中,也有很多研究者试图在算法的设计中加入推理能力。Mou等[326]设计了一个空间关联模块来构建场景中物体的远程关联。该模块可以提供关系增强的特征表示,以提高语义分词的准确性。Cao等人[327]也试图对全球关系信息进行建模和推理。该方法从空间像元和通道的角度提高了HSI去噪性能。关系推理网络(RRNet)[328]是在光学遥感图像显著性目标检测中提出的。这些方法都着重于网络结构的设计、特征通道之间关系的构建和数据推理的实现。因此,基于推理的大脑启发算法仍处于早期阶段。
现在深度学习需要从基于数据的学习向基于知识的学习迈进。因果推理作为知识利用的重要途径,是脑启发算法研究的重点。因果推理有三个重要的层次:关联、干预和反事实。这些理论阐明了人类大脑的推理和决策。将这些理论与遥感数据判读任务相结合,将有效提升遥感判读任务的性能,提高遥感算法的可解释性。
D.遥感算法的泛化能力。
遥感数据具有多样性和复杂性的特点,但目前的算法只能处理单一数据集的任务,即使处理相同的任务,也无法将模型应用于不同地面采样距离(GSD)、光谱分辨率和时间的数据。因此,重复训练模型以适应不同的数据是一种资源浪费。人类的大脑具有很强的学习和泛化能力。通过模拟人脑的学习记忆能力,设计动态学习和利用各种数据的网络,提高算法在各种数据中的迁移能力。
同时,遥感图像判读涉及分类、检测、跟踪等多种任务。大多数算法都是设计来处理单一任务的。但是,每个任务之间都有一定的相关性。大脑可以利用相关任务的知识来帮助解释当前的任务,从而提高准确性和速度。例如,了解飞机和机场之间的关系可以帮助我们忽略不相关的区域,实现飞机的快速定位。这些任务的融合需要一个统一的脑源遥感对多个任务进行联合学习,模拟人类信息利用机制,实现各任务的互补性。
从另一个角度来看,遥感数据与整个地球相比总是一个小集合。在开放世界中,算法的性能仍然难以估计并受到影响。人类的大脑有辨别未知物体的能力。对于未知的对象或类别,它可以给出结果的不确定性,从而可以对不确定的数据应用不同的策略。这种不确定性的估计在遥感算法的实际应用中具有重要意义。在自然领域,已经有很多关于开放集数据的研究。这种算法可以识别未知样本,并将其划分为未知类[329,330]。因此,开放集的算法设计也是脑动遥感设计的重要组成部分。它要求算法面对训练集以外的开放世界的数据,具有自适应、自归纳、自学习和处理不确定结果的能力。判断可以根据不同地区和地区的地理条件,预测出合理的结果。
E.如何实现一种具有时间记忆和自学习的遥感算法?
遥感信息的观测是一个连续的过程。卫星以一定的周期捕捉图像。通过定期捕捉局部区域,形成一系列的时间观测。现有的遥感算法通常只考虑单幅图像的解译性能,或通过两幅图像获取变化区域。但地理信息是一种时间序列关系,不断变化。仅仅解释单个图像并不能预测未来的变化。因此,在算法中设计记忆能力和自主学习是未来脑源性遥感的探索方向。基于大脑启发的算法,从连续的数据中记忆和学习,它可以预测未来的情况。根据预测结果,我们可以动态调整卫星在不同区域的捕获频率,实现对高风险区域的更密集观测,提高遥感算法的灾害预警能力。
F.如何利用大规模无标签遥感数据?
随着卫星数量的增加,我们获得了大量的遥感数据。然而,现代深度学习算法依赖于大量标记数据进行监督训练。这需要大量的人力和资源。为了利用大量的无标记数据,半监督和自我监督学习成为一种新的研究趋势。
半监督学习结合了监督学习和非监督学习。它使用少量的标记数据来训练基本模型来探索大量的未标记数据。自监督学习就是利用数据的多视图一致性来训练网络。该算法通过随机增强或其他策略构造单个目标的多个视图,具有良好的性能。
在遥感领域,多源数据自然构成了目标的多视图表示,满足了无监督和自监督的需求。在使用未标记数据时,还需要考虑云遮挡、多源数据匹配误差等自然因素造成的干扰。
G.如何整合多模态动态数据进行解释?
为了对地球进行全面监测,卫星携带了各种地面采样距离(GSD)和成像方法的传感器。这些传感器采集的数据种类繁多,给算法的设计带来了巨大的挑战。
目前主要是采用一种数据融合算法,利用多模态数据来提高模型的性能,这已经得到了广泛的研究。灰度图像和高光谱图像是数据融合的典型例子。灰度图像具有较高的GSD,但只包含单一的光谱。HSIs具有高光谱分辨率和低GSD。因此,这两种数据可以实现更好的互补性。
数据融合可以有效地提高算法的性能。随着拍摄技术的提高,光学卫星视频、SAR遥感视频等动态数据也得到了发展。未来如何实现动态多模态数据的融合将是一个值得研究的问题。
H.遥感大模型。
随着深度学习的发展,大模型展示了前所未有的理解和创造能力,打破了传统人工智能只能处理单一任务的限制,使人类向通用人工智能的目标又迈进了一步。2020年,OpenAI发布了具有1750亿个参数的训练前模型GPT-3[331]。它不仅可以写文章、回答问题、翻译,还具有多轮对话、编码、数学计算的能力。然而,要实现大模型的所有模式和所有任务的通用性,还存在许多技术困难。同时,由于计算资源的限制,其训练和应用具有很大的挑战性。
关于遥感大模型的研究较少。利用大模型的推理能力,可以充分挖掘各种遥感数据,实现各种任务的连接。建立遥感大模型的目标是解决不同形态、不同GSD、不同时间捕获的遥感数据的融合利用问题,能够覆盖分类、检测和跟踪等一系列遥感应用。
大模型的出现打破了我们对算法的理解。然而,它昂贵的计算在这个时候并不实际。如何利用大模型是遥感研究中的一个关键问题。未来,可以利用知识蒸馏、模型剪枝等技术,将大模型的学习理解能力提取为具体任务的小模型,从而提高特殊模型的学习泛化能力。
一、遥感算法在训练和推理过程中的安全性
如今,我们利用越来越多的数据来训练一个大型模型。遥感算法的安全性也是一个值得关注的问题。遥感算法的安全性主要分为两个方面。一方面,需要利用不同区域的大量遥感数据进行训练,提高模型的泛化能力。由于遥感数据的特殊性,许多遥感数据中包含了与国家或企业相关的敏感信息。许多研究已经证明,网络在训练过程中可能会泄露数据[332]。因此,如何在训练过程中设计并保证数据的安全性,实现遥感数据多方训练的联合学习,是一个迫切需要研究的问题。
另一方面,在对模型进行正向推理时,还需要注意抵抗外部攻击的能力。在自然情况下,许多神经网络攻击研究表明,固定的神经网络容易由于轻微的干扰而误判。同样的情况也存在于遥感算法中。如果这种攻击出现在自动化决策的遥感算法中,它将产生严重的影响。微小的干扰不会影响人类大脑对物体的判断。因此,遥感算法需要模拟人类大脑的记忆和联想能力,以实现对攻击的鲁棒性。
启发大脑的遥感软件和硬件系统。
随着商业卫星产业的成熟,遥感数据解译已不仅仅是对专业人员的需求。现有的遥感数据平台软件大多需要专业人员针对不同的任务和数据设计和操作相应的算法。这些限制限制了遥感算法在民用领域的广泛应用。因此,遥感数据判读软件要求算法涵盖多种任务,适用于不同的数据,并对软件的易用性提出了要求。根据上述要求设计的遥感软件系统,可以通过简单的操作,对数据进行全面的解读。用户可根据实际需要,选择查看任意类别的目标分类、目标检测、解释结果等任务。
在硬件系统方面,数据在轨处理可以更有效地提高数据利用率,节省数据传输带宽。本文介绍了FPGA及其在遥感中的应用。为了在飞机或卫星上直接运行算法,我们可以选择在空间级FPGA上部署算法,以确保系统在极端环境下的稳定性。然而,神经形态计算芯片的计算能力和极低功耗更值得期待。如天极讯[333]实现了超低功耗、低延迟条件下的猫捉老鼠游戏实验。实验中芯片的总动态功耗仅为0.6w。在神经形态计算芯片中使用遥感算法时,在轨卫星可以实时处理数据,功耗极低。只有具有研究价值的数据经过预处理后才会传回地面。这提高了数据收集和分析的效率。然而,对神经形态计算芯片的研究还处于起步阶段,遥感算法还需要进一步的研究才能部署到神经形态计算芯片中。而神经形态计算芯片还需要进一步研究,以提高芯片在空间中的稳定性,以满足在轨数据分析的需要。
vii。结束语
在本研究中,我们系统地讨论了脑启发算法在遥感中的应用。我们首先总结大脑的结构和性质。这些特性包括稀疏性、学习性、选择性、方向性、可塑性和多样性六个方面,可以有效引导读者从这些特性出发思考脑源性遥感解译算法。在此基础上,总结了目标分类、目标检测、变化检测、目标跟踪和三维重建5个遥感任务的数据类型和发展。同时,对公共数据集、软件平台和硬件系统也进行了讨论。脑启发算法在遥感中的发展还没有得到充分的探索,它将帮助我们克服未来的挑战。

