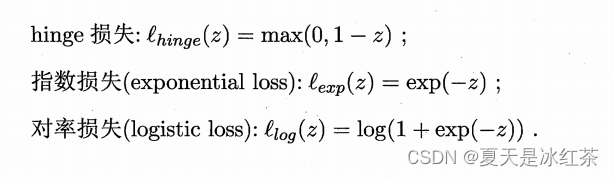- 1Spark的生态系统概览:Spark SQL、Spark Streaming_spark生态系统
- 2机器学习之MATLAB代码--IWOA_BILSTM(基于改进鲸鱼算法优化的BiLSTM预测算法)(十六)_bilstm代码
- 3单机版 hadoop 云平台(伪分布式)搭建 统计单词_单机能够搭建的云计算
- 4Flutter 修改生成的 APK 名称/自动命名_打包自动生成名称格式
- 5Linux 小技巧:在 CentOS7 安装 XRDP 远程桌面服务器_centos xrdp
- 6【kali】windows安装kali虚拟机教程 kali虚拟机桥接模式_kali桥接模式
- 7软件介绍——文件属性批量修改工具(绿色版)_bulkfilechange
- 8游族马寅龙:常见信息安全风险及应对方案_互联网收口
- 9stable-diffusion-webui环境部署_stable-diffusion-webui repositories git clone
- 10Github学习笔记
机器学习算法:支持向量机(SVM)_机器学习方法 李航 支持向量机 代码
赞
踩
参考书籍:
Solem《python计算机视觉编程》、李航《统计学习方法》、周志华《机器学习》
要理解好支持向量机需要较好的数学功底,且能不被公式以及文字绕晕,这里我们就理清楚支持向量机的大体过程。具体的数学计算推导其实已经封装好了,那么理解算法的原理也对我们将来的学习很有帮助,比如以后做科研的时候,大家冥思苦想找不到方法的时候,你走上前去说,唉这个方法就能解决,是不是特别能得到满足。
0、概念提前知
超平面:三维空间中,平面是到两个点距离相同的点的轨迹,可把空间分割成两部分。超平面是维度大于三维的时候仍然满足前面的要求,且它的自由度比空间维度小1。
正定与半正定矩阵:如何理解正定矩阵和半正定矩阵 - 知乎 (zhihu.com)
软间隔:在这个区间内允许出现一定数量的样本
硬间隔:划分非常清晰,在间隔中间没有任何样本的理想状态下。
拉格朗日乘子:(1条消息) 拉格朗日乘子法详解_Trisyp的博客-CSDN博客_拉格朗日乘子法
空间概念:(2条消息) 【机器学习概念笔记】:空间概念_夏天是冰红茶的博客-CSDN博客
1、算法介绍
支持向量机(SVM)是一类按监督学习的方式对数据进行二类分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;支持向量机还包括核技巧,这使它成为实质上的非线性分类器。SVM的学习策略是间隔最大化,可形式化为求解一个凸二次规划问题,也等价于正则化的合页损失函数的最小化问题。
其学习方法包含构建由简至繁的模型:线性可分支持向量机、线性支持向量机以及非线性支持向量机。
- 当训练数据可分时,通过硬间隔支持向量机,学习一个线性的分类器,即线性可分支持向量机,又称硬间隔支持向量机;
- 当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,即线性支持向量机,又称软间隔支持向量机;
- 当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
具体内容请看李航老师的《统计学习方法》。
2、间隔与支持向量y
给定训练样本集 D = {(x1,y1) ,(x2,y2) , . . . , (xm,ym)} , yi属于{-1,+1},分类学习最基本的想法就是基于训练集 D 在样本空间中找到一个划分超平面、将不同类别的样本分开但能将训练样本分开的划分超平面可能有很多。我们要找的就是最合适的那一个。请看下面:
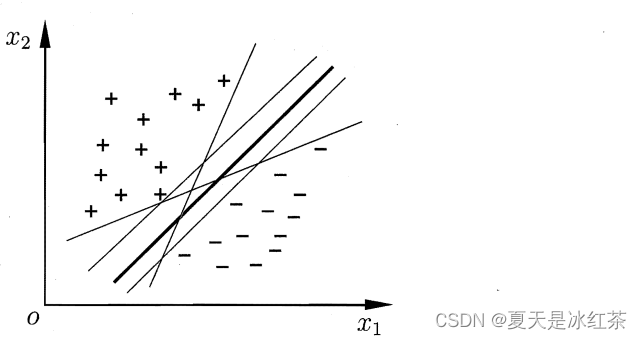
哪一个是最合适的呢?似乎里面的深黑线看起来最好,我想大多数人第一次看这图都会有这样的想法吧,好像这种近似对称的分类更符合我们看待事物的想法,实际上,中间那一条深黑线对于样本的“容忍性”最好,我们要明白的是在上图的叫训练样本集,我们最终要进行预测,可能有很多的点会在划分超平面附近,其他的划分超平面出现错误更大,而深黑线的超平面受影响最小。换言之,这个划分超平面所产生的分类结果是最鲁棒的,对未见示例的泛化能力最强。
样本空间中,划分超平面可通过如下线性方程来描述:
其中
为法向量,决定了超平面的方向 ;
b 为位移项,决定了超平面与原点之间的距离。
显然,划分超平面可被法向量 ω 和位移 b 确定,下面我们将其记为(w,b)。样本空间中任意点 x到超平面(w,b)的距离可写为:
假设超平面(w,b)能将训练样本正确分类,则有下列的式子:
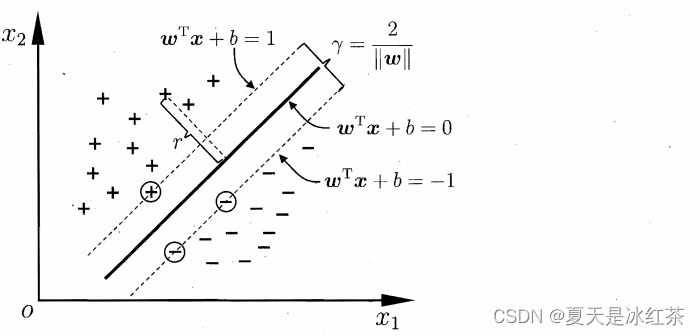
距离超平面最近的这几个训练样本点使上式的等号成立,它们被称为"支持向量" 。
其中
表示的是两个异类支持向量到超平面的距离之和为
,被称为"间隔" 。
我们需要找到最大间隔,则有
,显然为了最大化问隔,仅需最大化
,这等价于最小化
。
这就是支持向量机(Support Vector Machine ,简称 SVM) 的基本型。
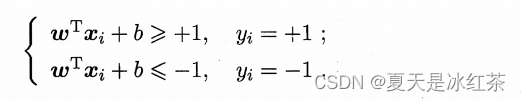
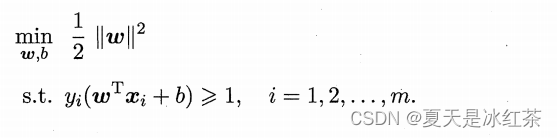
3、对偶问题
我们希望求解式:
来得到大间隔划分超平面所对应的模型,其中 ω 与 b 是模型参数。我们看到上面的SVM的基本型本身是一个凸二次规划问题。这里采用拉格朗日乘子法可得到其"对偶问题",也就是每条约束添加拉格朗日乘子ai>=0;
其中 α=(α1,α2,... ,αm). 令 L(ω,b,α) 对 ω 和 b 的偏导为零可得

将上式代回,即可得式,“对偶问题”:
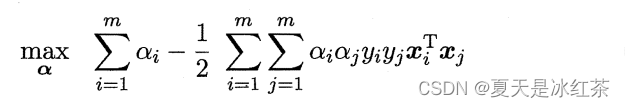
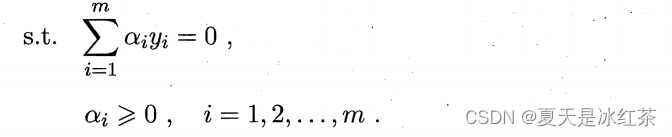
解出 α 后,求出 ω 与 b 即可得到模型
这显示出支持向量机的一个重要性质:训练完成后?大部分的训练样本都不需
保留,最终模型仅与支持向量有关。
4、核函数
我们假设训练样本是线性可分的,即存在一个划分超平面能将训练样本正确分类。然而在现实任务中,原始的样本空间内,也许并不存在一个能正确划分两类样本的超平面。比如下面"异或"问题就不是线性可分的:
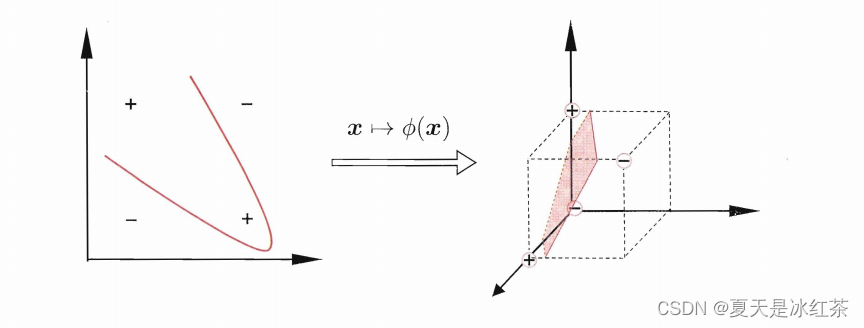
这时可将样本从原始空间映射到更高维的特征空间,使得样本在这个特征空间内线性可分。例如在上图,若将原始的二维空间映射到一个合适的三维空间,就能找到一个合适的划分超平面。对于任意维度,只要原始样本空间为有限维,那么就一定有一个更高维特征空间使样本可分。
令 表示将 x 映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为:
同理,与上面得式子类似,就是将单个x换为
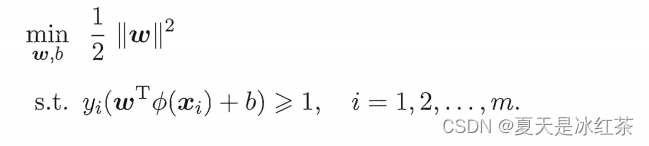
其对偶问题则是
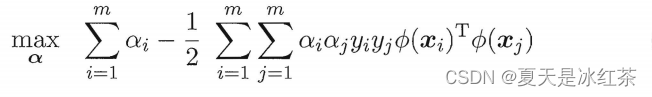
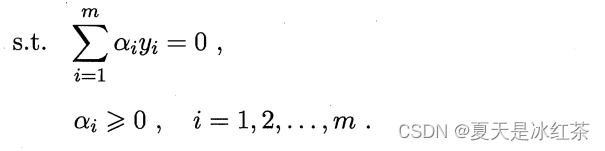
这里涉及了,这是样本xi和yi映射到特征空间之后得内积,如果遇到了高维空间,那么这个不是那么的好算的,这里就用到了核函数,也就是{\color{Red} k(x_{i},y_{i})=\Phi (x_{i})^{T}\Phi (y_{i}){\color{Red} }}
最终的式子为:
这里便显示出了模型最优解可通过训练样本的核函数展开,这一展式亦称"支持向量展式 "。
但问题是xi的映射是什么样的,我们这里还是不能确定形式,我们继续向下看。
这里给出一个定理:
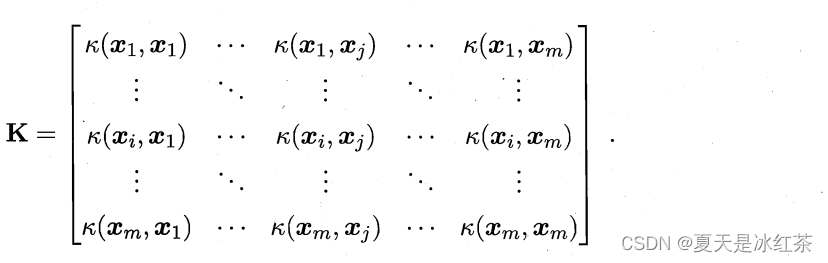
只要一个对称函数所对应的核矩阵半正定,它就能作为核函数使用.事实上,对于一个半正定核矩阵,总能找到一个与之对应的映射。换言之,任何一个核函数都隐式地定义了一个称为"再生核希尔伯特空间" (Reproducing Kernel Hilbert Space ,简称 RKHS) 的特征空间.
我们希望样本在特征空间内线性可分,因此特征空间的好坏对支持向量机的性能至关重要。需注意的是,在不知道特征映射的形式时,我们并不知道什么样的核函数是合适的,而核函数也仅是隐式地定义了这个特征空间。于是,"核函数选择"成为支持向量机的最大变数。如果核函数选择不合适,则意味着将样本映射到了一个不太合适的特征空间,它的性能不佳。
在这里,列出了几种常用的核函数。

此处之外,函数的组合也是核函数
- κ1 和 κ2 为核函数,则对于任意正数
其线性组合为:
也是核函数;
- κ1 和 κ2 为核函数,则核函数的直积:
也是核函数;
- κ1 和 κ2 为核函数,则对于任意函数 g(x):
也是核函数;
5、软间隔与正则化
我们在之前讨论的都是线性可分的情况,即存在了一个超平面能将不同类的样本完全的划分开。 但是,在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分;退一步说,即使恰好找到了 某个核函数使训练集在特征空间中线性可分,也很难断定这个貌似线性可分的结果不是由于过拟合所造成的(即存在预测效果差)。既然无法避免,那就只有缓解该问题,那么就是允许支持向量机在一些样本上出错。为此,在这里要引入"软间隔"的概念。
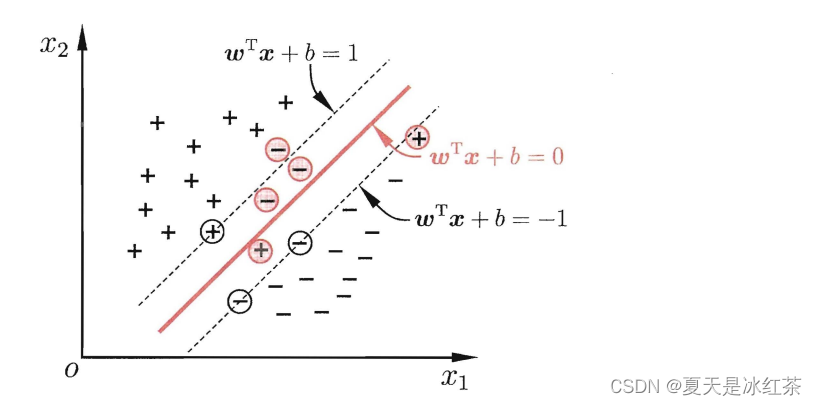
前面虽然没有明说,但大家从概念上理解,也应该明白上面是“硬间隔”,这里是“软间隔”,它就是让某些样本不需要满足:
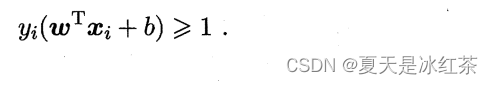
当然,在最大化间隔的同时,不满足约束的样本应尽可能少.于是,优化目标可写为:
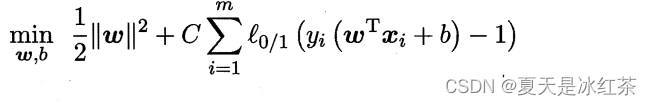
其中 C>0 是二个常数, 是 "0/1损失函数"
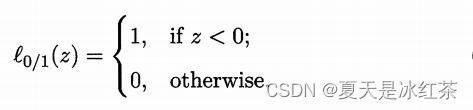
非凸、非连续,数学性质不太好,使得式优化目标函数不易直接求解.于是,人们通常用其他一些函数来代替
, 称为"替代损失" (surrogate 10ss).。替代损失函数一般具有较好的数学性质,如它们通常是凸的连续函数且是
的上界。下面给出了三种常用的替代损失函数: