
- 1计算机辅助教学在教育教学中有哪些作用,计算机辅助教学在课堂中的应用
- 2【PyQt5】Python在PyQt5中使用ECharts绘制图表
- 3vue+element作用域插槽_el-tree slot
- 4mysql添加datetime字段_添加DATE和TIME字段以在MySQL中获取DATETIME字段?
- 5ubuntu16.04系统gcc下降和升级_ubuntu 升级gcc
- 6如何解决国标GB28181视频平台EasyGBS运行中端口不够用的情况?_视频控制器输出口不够如何解决
- 7微信小程序接入阿里云直播_小程序嵌入三方直播需要什么条件
- 8ROS | ROS机器人开发案例(古月)学习
- 9鸿蒙 DevEco-Studio 运行报错 Error while Deploying HAP_deveco error while deploying hap
- 10ios学习临时笔记-NSLocalizedString使用_nslocalizedstring 调用
谷歌发布最强AI大模型Gemini(超越chatgpt4)_google开源ai大模型
赞
踩
1 Gemini介绍
美国科技巨头谷歌宣布推出其认为规模最大、功能最强大的AI智能模型Gemini。此次谷歌发布的Gemini模型可实现多模态,性能大幅提升,Gemini是基于Transformer decoder构建的多模态模型,这种技术能够处理视频、音频和文本等不同内容形式的信息。最新的Gemini模型对比之前的技术,能够进行更复杂的推理,理解更加细微的信息。它通过阅读、过滤和理解信息,可以从数十万份文件中提取要点,将有助于在从科学到金融的许多领域实现新的突破。
Gemini官网:https://deepmind.google/technologies/gemini/#introduction
论文地址:https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf

Gemini模型根据体量大小可分为Gemini Ultra、Gemini Pro、以及Gemini Nano三个版本,都支持上下文32K理解,其中:
-
Ultra版本是性能最强的版本,在对应的TPU基础设施中能够展现出最高效率,在多项测试中Ultra版本性能超过GPT4V;
-
Pro版本是性价比优化的版本,在推理、多模态等方面也有较强能力,Pro版本具有良好延展性,可以在几周内完成预训练,在多项测试中仅次于GPT4V,强于PaLM2、Claude2、LLaMA2、GPT3.5等主流大模型;
-
Nano:是通过对其他模型蒸馏得来的4位模型,有1.8B和3.25B两个版本,分别针对低内存和高内存设备,支持在本地部署
Gemini是由谷歌开发的一系列高效能多模态模型。这些模型通过联合训练,覆盖了图像、音频、视频和文本数据。希望建立一个具有强大的通用能力模型,同时在每个特定领域内展现出优秀的理解和推理性能。
Gemini 1.0是一种多模态AI模型,具有三种不同规模:Ultra、Pro和Nano,分别针对不同的任务复杂度和应用需求设计。这些模型在一系列内外部基准测试中展现了出色的性能,覆盖了语言、编程、推理和多模态任务。Gemini在大规模语言建模方面取得了显著成果,其在图像理解、音频处理、视频理解等领域的表现也非常出色。此外,Gemini的发展还得益于序列模型、基于神经网络的深度学习和机器学习分布式系统等领域的长期研究。
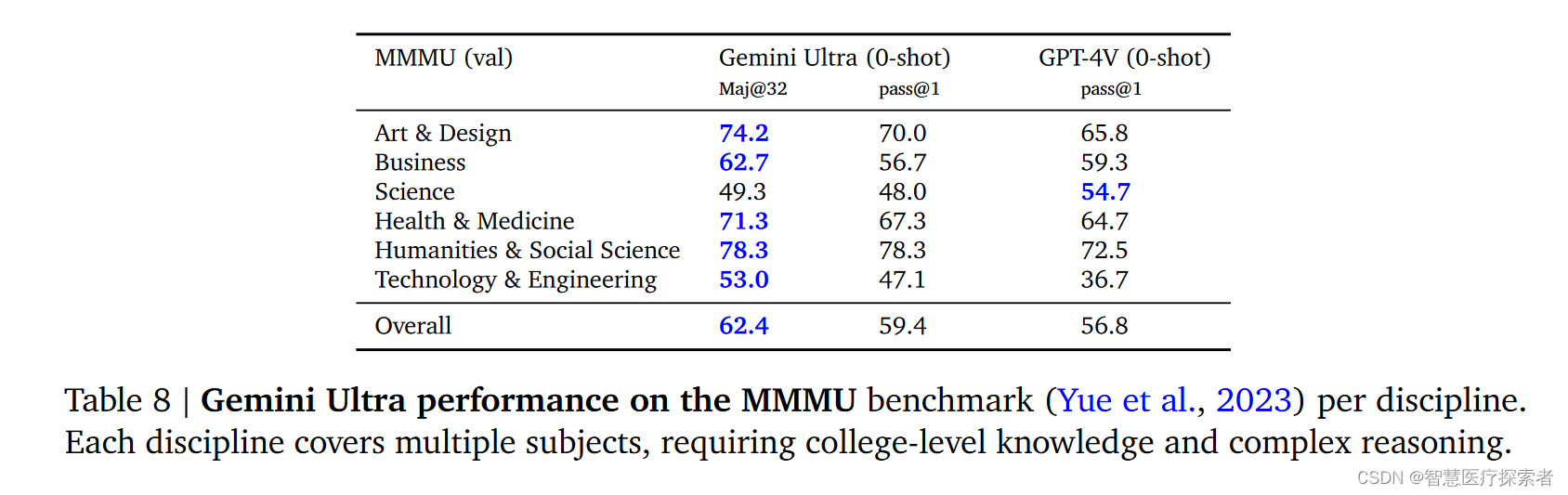
本报告中最强大的模型Gemini Ultra遥遥领先。在32个基准测试中的30个中取得了新的最先进成果。它在文本理解、图像理解、视频理解、语音识别和语音翻译等领域展现了出色的能力。尤其值得注意的是,Gemini Ultra在MMLU考试基准测试中首次达到了人类专家水平,其得分超过90%。此外,在MMMU这一最新的多模态推理基准测试中,Gemini Ultra也取得了62.4%的高分,超越了以往模型。这表明了它在视频问答和音频理解等多模态领域的统一性能提升。
Gemini模型的定性评估显示了其在跨模态推理方面的显著能力,能够理解涉及音频、图像和文本的复杂输入序列。以图1的教育场景为例,Gemini能够理解杂乱手写的物理问题,准确分析问题和学生的解决方案,识别错误步骤,并提供正确的解答。这些能力不仅表现出模型对复杂问题的理解和处理能力,还为教育等多个领域带来新的应用前景。

而且,由Gemini提供技术支持,AlphaCode团队开发了一个新的Agent,AlphaCode 2。它集成了Gemini的推理能力、搜索功能和工具使用技术,专门用于解决竞赛编程问题。在Codeforces这一著名的竞赛编程平台上,AlphaCode 2的表现非常出色,其排名位于前15%,远超其前代产品的前50%的最佳成绩。这一进步展示了大型语言模型在解决复杂多步骤问题方面的显著潜力。
而且,团队也注重模型的效率,所以推出了Gemini Nano系列,它们在提升设备内任务的效率方面取得了显著进展。这些模型特别擅长执行如摘要、阅读理解和文本完成等任务。此外,尽管模型体积较小,它们在推理、STEM领域、编程、多模态和多语言任务上的表现仍然令人印象深刻。这些特点使得Gemini Nano在体积和性能之间取得了良好的平衡。
接下来的章节中,首先概述了Gemini模型的架构、训练基础设施和训练数据集,然后对Gemini模型家族进行了详细的评估,涉及文本、代码、图像、音频和视频等领域的众多基准测试和人类偏好评估。论文还讨论了负责任的部署方法(他们会在Gemini正式面向大众之前更新这篇技术报告以提供更多细节),包括影响评估、模型政策的制定、评估和风险缓解措施。最后,论文探讨了Gemini的广泛影响、局限性和潜在应用,预示着AI研究和创新的新时代。
2 模型架构
Gemini模型的架构基于Transformer解码器(Decoder),并通过架构和模型优化的改进,使其能够在大规模上进行稳定训练并优化在谷歌张量处理单元上的推理性能。这些模型能够处理高达32k的上下文长度,并采用了高效的注意力机制,如多查询注意力(multi-query attention,https://arxiv.org/abs/1911.02150)。如表1,Gemini 1.0的第一版包括三种不同规模的模型,以适应各种不同的应用场景。

Gemini模型被训练以处理与各种音频和视觉输入交织的文本输入,例如自然图像、图表、截图、PDF和视频,并能产生文本和图像输出(参见图2)。
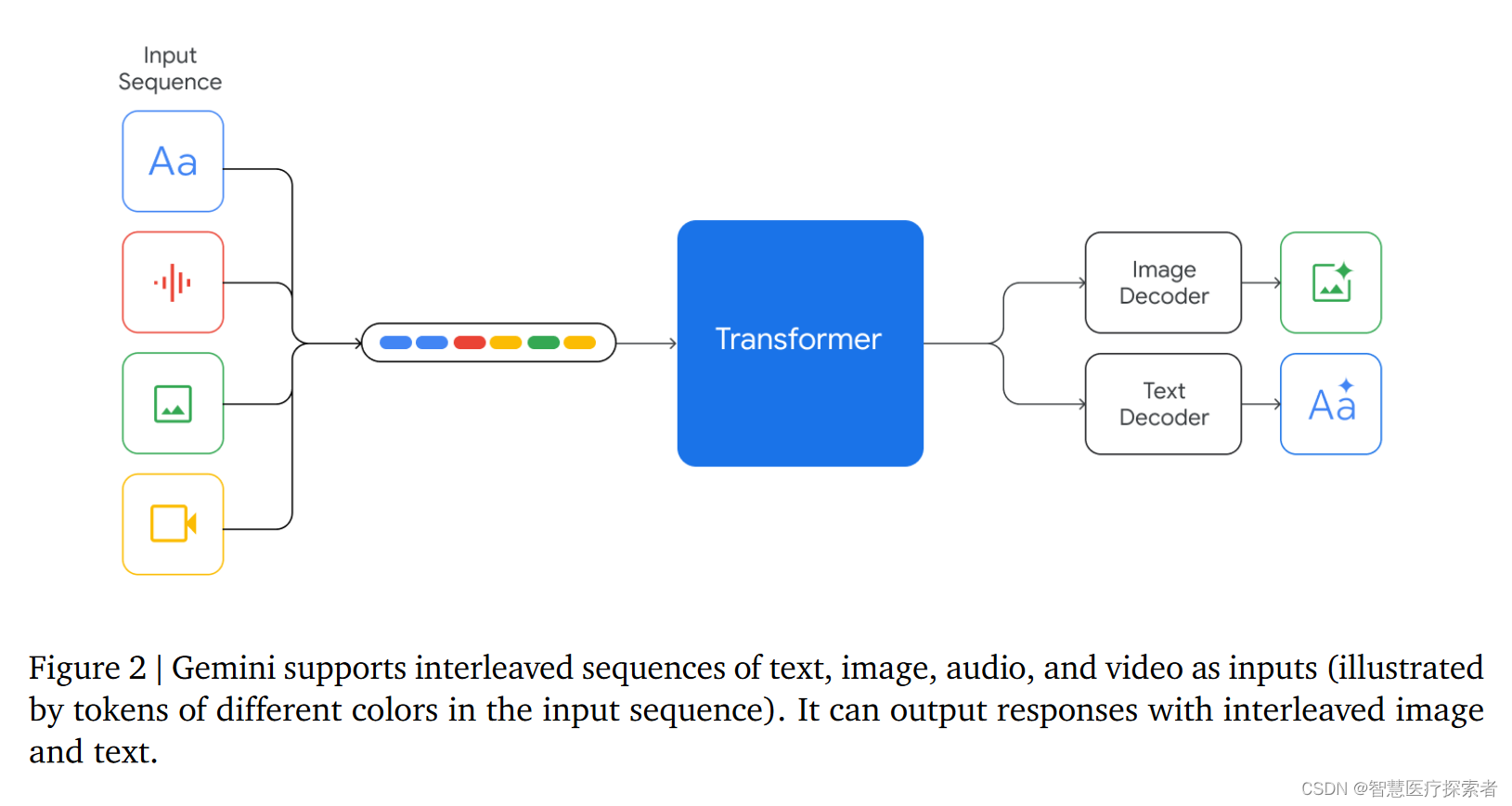
其视觉编码灵感来源于先前的Flamingo、CoCa和PaLI项目,并具有独特之处:模型本身就是多模态的,能够使用离散图像token直接输出图像。此外,Gemini能够将视频作为一系列帧编码并处理可变的输入分辨率。它还能直接处理16kHz的音频信号(USM模型作为提取器),提升音频理解的细节捕捉能力。这些特性使Gemini成为一个高度灵活和多功能的AI模型。
3 训练的基础设施
针对不同规模和配置的Gemini模型,作者选择了TPUv5e或TPUv4作为训练硬件。尤其对于大型的Gemini Ultra模型,作者使用了多个数据中心的大量TPUv4加速器,这在规模上超越了之前的PaLM-2模型。然而,这种规模的扩展也带来了新的挑战,尤其是在硬件故障率方面。尽管作者努力减少计划内的重调度和抢占,但由于外部因素如宇宙射线,大规模硬件加速器中的机器故障仍然是一个普遍现象。
TPUv4加速器被部署在包含4096个芯片的“SuperPods”中,每个芯片都连接到一个可以快速重配置芯片立方体为3D环面拓扑结构的光学开关。此外,为了Gemini Ultra项目,作者们在每个SuperPod中故意保留了少量的立方体,目的是为了实现热备用和便于进行滚动式维护。
(Gemini Ultra的网络通信策略)为了处理Gemini Ultra的大规模数据和计算需求,作者们采用了Google的高级网络技术,连接多个数据中心中的SuperPods。这种网络配置不仅支持高速的芯片间通信,而且还适应了同步训练范式,即在SuperPods内部利用模型并行性,在SuperPods之间实现数据并行性。Google网络的低延迟和高带宽特点是实现这种高效通信的关键。
Jax和Pathways采用了“单一控制器”编程模型,允许开发者通过单一Python进程管理整个训练过程,显著简化了AI开发流程。此外,文本还提到了XLA编译器中的GSPMD分区器和MegaScale XLA编译器的应用。GSPMD分区器负责划分训练过程中的计算任务,而MegaScale XLA编译器则确保集群操作与计算过程的高度重叠,并减少了训练步骤时间的波动。
传统的周期性权重检查点保存方法在大规模训练环境中效率较低。为了解决这个问题,Gemini项目采用了冗余的内存中模型状态副本,以便在发生硬件故障时能够迅速恢复。与以往的PaLM和PaLM-2项目相比,尽管Gemini使用的训练资源更为庞大,但其恢复时间显著缩短,最终使得最大规模训练作业的整体吞吐量从85%增加到97%。
在Gemini项目大规模训练中遇到的新的系统故障模式:“静默数据腐败(Silent Data Corruption, SDC)”。
(SDC通常是由于硬件上的微小电流波动导致计算错误,如计算失误1+1=3。随着芯片变得更加先进和紧凑,这一问题变得更加突出。虽然大多数由制造缺陷引起的错误会被供应商筛选出来,但仍有部分错误可能不被硬件错误检测系统发现,因此需要依赖于检测软件来预防和解决这些问题。)
尽管SDC事件非常罕见,但由于项目的大规模性,这些事件对训练的影响变得频繁。为了应对这一挑战,Gemini项目采用了多种新技术,包括利用确定性重放技术隔离错误计算,以及在闲置和热备用机器上部署主动SDC扫描器。这些措施,加上完全确定性的基础设施,使团队能够在开发过程中迅速识别并解决根本原因,从而确保了训练的稳定性。
4 训练数据
Gemini模型的训练数据集具有多模态和多语言的特性,包括来自网页、书籍和编程代码的图像、音频和视频等多种数据类型。在训练过程中,使用SentencePiece分词器对大量训练语料进行处理,有效提高了词汇表质量,进而提升模型性能。Gemini模型在处理非拉丁文字时表现出了高效的分词能力,这不仅提升了模型质量,还加快了训练和推理的速度。同时,根据模型的规模,采用了不同的标记数量训练策略,以实现更好的性能优化。
具体来说,最大的模型遵循:https://arxiv.org/abs/2203.15556
其他的小一些的模型遵循:LlaMa
训练高性能AI模型时的数据集质量管理和训练策略:首先,所有数据集都经过质量过滤,包括启发式规则和基于模型的分类器的应用,以及安全过滤以排除有害内容。评估集是从训练语料库中精心筛选出的。研究团队通过在小型模型上进行消融实验,确定了数据混合和权重的最终方案。在训练过程中,特别是在后期,逐渐增加与领域相关数据的权重,这是训练策略的一部分。数据质量对于构建高性能模型至关重要(因为重要,所以没有细写),并且意识到在确定预训练最佳数据集分布方面,还存在许多值得探讨的问题(因为重要,所以也没有细写)。
5 评估
Gemini模型因其在多个模态上的联合训练而具有显著的多模态特性。该模型在评估中显示出在文本、图像、音频和视频等多个领域的强大能力,这一点甚至超越了那些专门针对单一模态进行优化的模型和方法。
5.1 文本
5.1.1 学术领域基准测试
在文本领域的学术基准测试中,Gemini Pro和Ultra模型与其他大型语言模型(包括PaLM 2)进行了比较。这些测试覆盖了推理、阅读理解、STEM和编程等多个方面。如表2的结果显示,Gemini Pro在性能上超越了以推理优化为特色的模型,如GPT-3.5,并且在某些数据集(如HumanEval)上与市场上一些最先进的模型(GPT-4)相媲美。
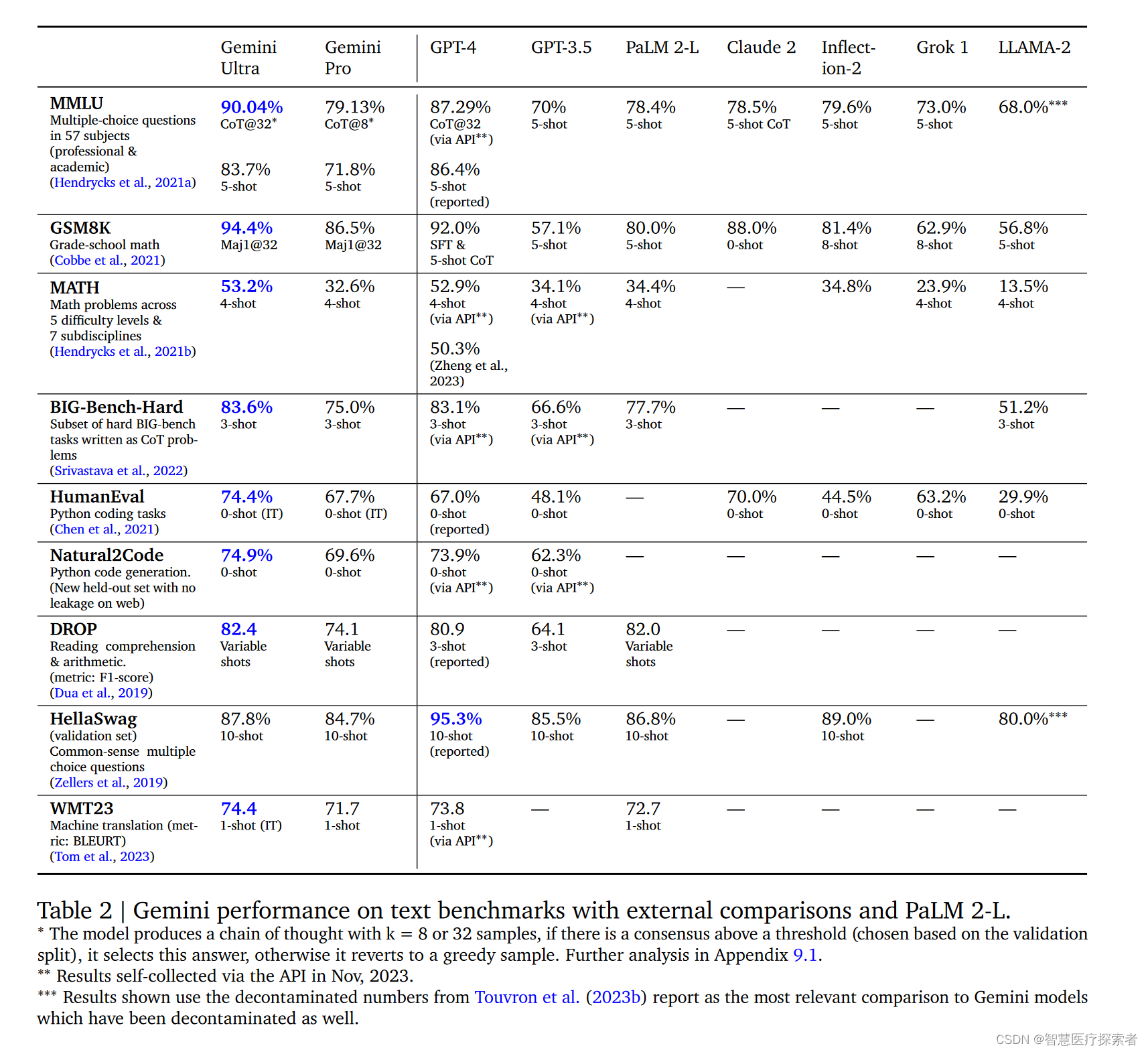
Gemini Ultra在MMLU这一综合性考试基准测试中表现卓越,其准确率达到90.04%,超越了所有现有模型和人类专家的表现(89.8%)。MMLU测试涵盖了57个学科领域,对参与者的知识水平进行全面评估。Gemini Ultra的高性能反映了它在多个学科领域的专业知识,以及出色的阅读理解和推理能力。此外,研究表明,当Gemini Ultra与基于模型不确定性的思维链提示方法结合使用时,可以达到更高的准确率。这种方法依赖于生成多个样本的思维链,并根据共识或最大可能性选择答案。
Gemini Ultra在数学领域的表现证明了其强大的分析和解题能力。在GSM8K小学数学基准测试中,Gemini Ultra通过使用思维链提示和自我一致性策略,取得了94.4%的准确率,超越了以往的分数。在MATH基准测试中,面对来自中高等数学竞赛的复杂问题,Gemini Ultra的表现同样出色,准确率达到53.2%。此外,在美国数学竞赛的高难度任务中,Gemini Ultra解决了32%的问题,表现优于GPT-4。这些结果显示,尽管较小的模型在这些高难度任务上几乎无法胜任,但Gemini Ultra通过先进的技术和策略,成功地解决了这些挑战。
Gemini Ultra在编程这一大型语言模型的关键应用领域表现出众。该模型在多种常规和内部基准测试中表现良好,并且在更复杂的推理系统(例如AlphaCode 2)中也展现了强大的能力。特别是在HumanEval这一代码补全基准测试中,Gemini Ultra能够根据功能描述正确实现74.4%的Python代码。此外,在新的Python代码生成任务评估基准Natural2Code中,Gemini Ultra实现了74.9%的高得分,这一成绩在确保无网络泄露的情况下达到了最高。
在对Gemini模型进行基准测试评估时,面临数据污染的挑战。为确保结果的科学性和可靠性,进行了广泛的泄露数据分析,并决定不报告某些测试(如LAMBADA)的结果。特别是在对HellaSwag测试的评估中,通过对Gemini模型进行额外微调,显著提高了验证准确率,显示出优于GPT-4的性能。这表明基准测试结果可能受到预训练数据集组成的影响。因此,我们选择在更严格的评估设置中报告去污染的HellaSwag结果。此外,为了确保评估的健壮性和准确性,Gemini模型在多个新发布的评估数据集上进行了测试,如WMT23、Math-AMC 2022-2023问题和非网络来源生成的Natural2Code。
Gemini Ultra在基准测试中的表现不仅展示了模型的潜在能力,也揭示了其可能对现实世界的任务产生的积极影响。这一表现特别在推理和STEM领域中尤为突出,为大型语言模型在教育领域的应用和发展提供了新的方向。Gemini Ultra在处理复杂数学和科学概念方面的能力尤其引人注目,为个性化学习和智能辅导系统带来了新的、令人兴奋的应用前景。
5.1.2. 能力趋势
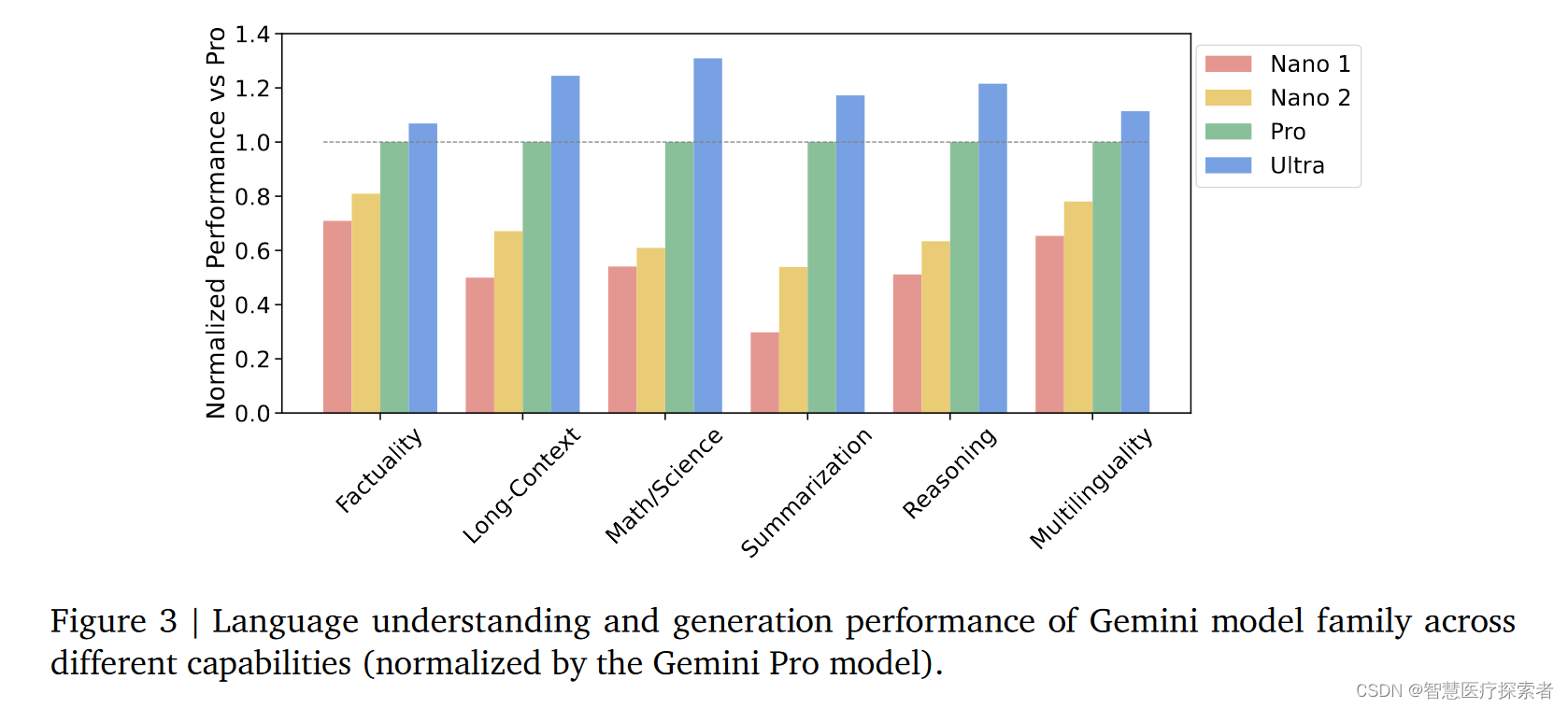
团队从Gemini模型家族的能力趋势进行分析,主要通过对超过50个不同基准测试的全面评估来研究六种不同能力的表现(图3)。这些能力包括事实性、长文本理解、数学/科学、推理和多语言等。其中,Gemini Ultra在所有六个能力方面表现最佳,而Gemini Pro作为第二大模型,也展现出了强大的竞争力和高效率。整体上,随着模型大小的增加,在多个领域中表现得到显著提升。
5.1.3. Nano
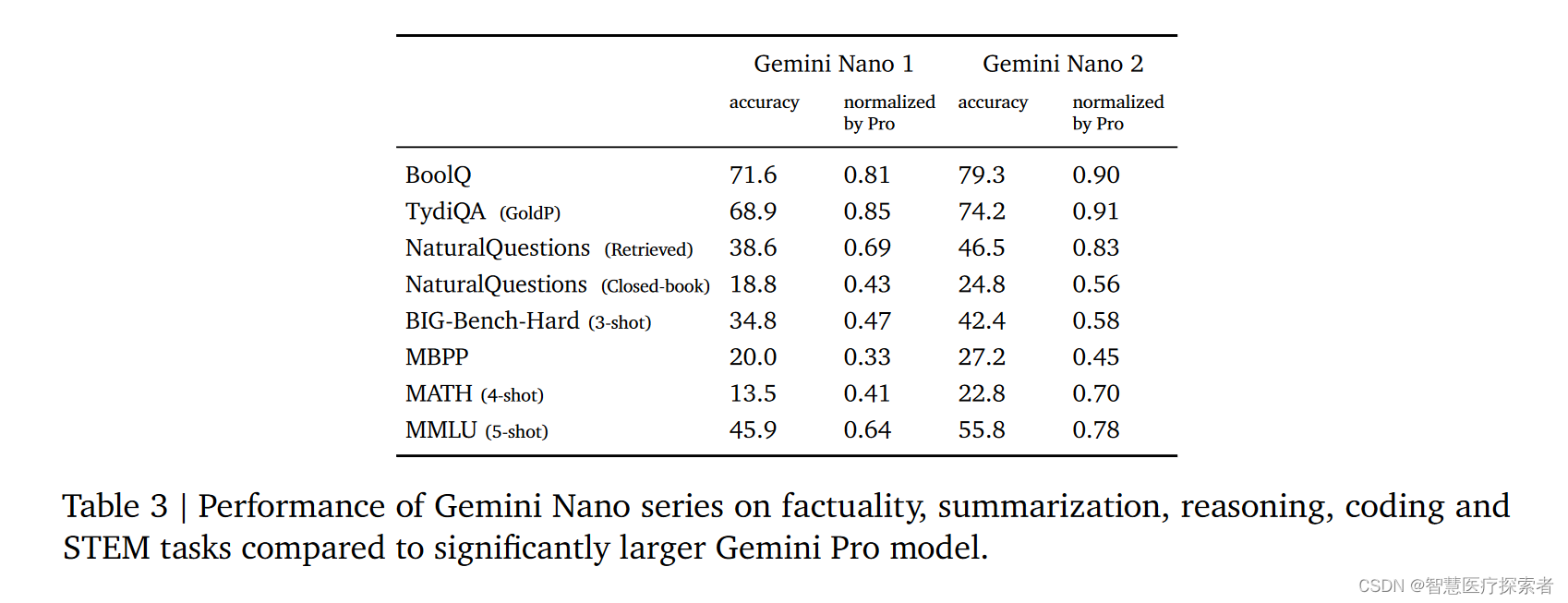
团队专门打造了Gemini Nano 1和Nano 2模型,这些模型被设计用于设备上的部署,从而使人工智能更加贴近用户。它们在总结和阅读理解任务上尤其擅长,并且在每个任务上进行了细致的微调。通过对比图3和表3的数据,我们可以看出,尽管Nano模型(1.8亿和3.25亿参数)的规模远小于Gemini Pro模型,它们在事实性、推理、STEM、编程、多模态和多语言任务上仍展现出强大的性能。这些模型的推出,使得更多的平台和设备能够接入先进的人工智能功能,从而使人工智能技术更广泛地服务于公众。
5.1.4 多语言
这个章节主要介绍了Gemini模型在多语言处理方面的能力评估。评估任务涵盖了多种类型,包括机器翻译、文本摘要以及跨语言文本生成。具体来说,机器翻译评估覆盖从资源丰富到资源匮乏的各种语言,而文本摘要和基准测试的翻译则涉及多种语言,显示出该模型在处理不同类型的多语言任务上的能力和灵活性。
机器翻译。Gemini Ultra在多种资源水平的语言翻译任务中表现出众,特别是在将英语翻译成其他语言方面,其表现优于传统的大型语言模型方法。如表4,在WMT 23翻译基准测试中,Gemini Ultra在英语以外的翻译任务上取得了最高的LLM基础翻译质量,其平均BLEURT得分超过了GPT-4和PaLM 2。此外,Gemini Ultra还在极低资源语言的翻译方面进行了评估,涵盖了一些较少使用的语言,如塔马齐格语和克丘亚语。
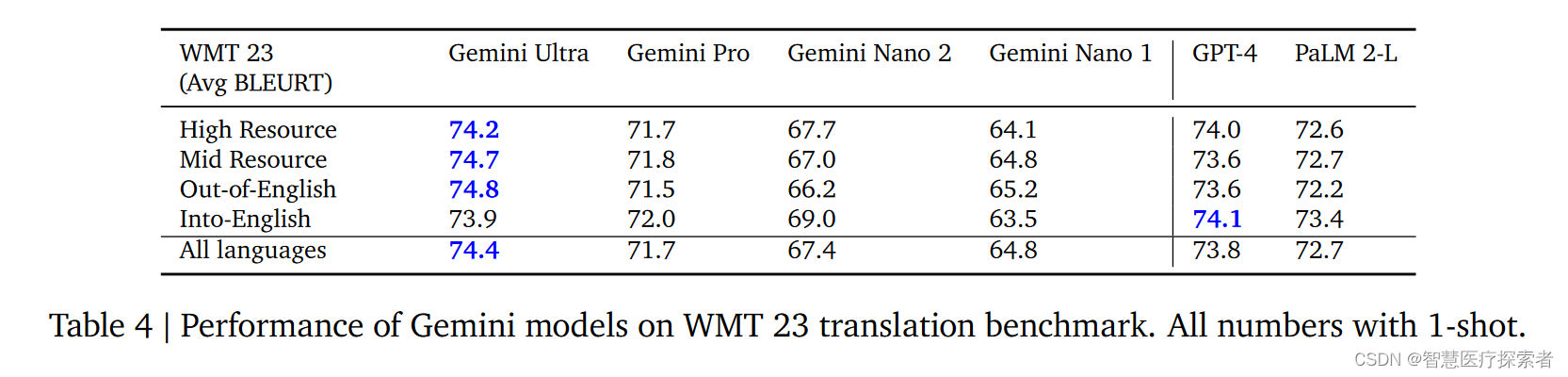
多种语言环境下进行数学问题求解和文本摘要。表5特别指出了Gemini Ultra在MGSM(一种数学基准测试的翻译版本)中的表现,准确率高达79.0%,超过了PaLM 2-L。此外,在多语言摘要方面,Gemini Ultra在XLSum基准测试中的表现优于PaLM 2,但在WikiLingua测试中略逊一筹。整体而言,Gemini模型展示了在处理多种语言任务上的广泛能力,特别是在资源较少的语言和地区。

5.1.5 长文本
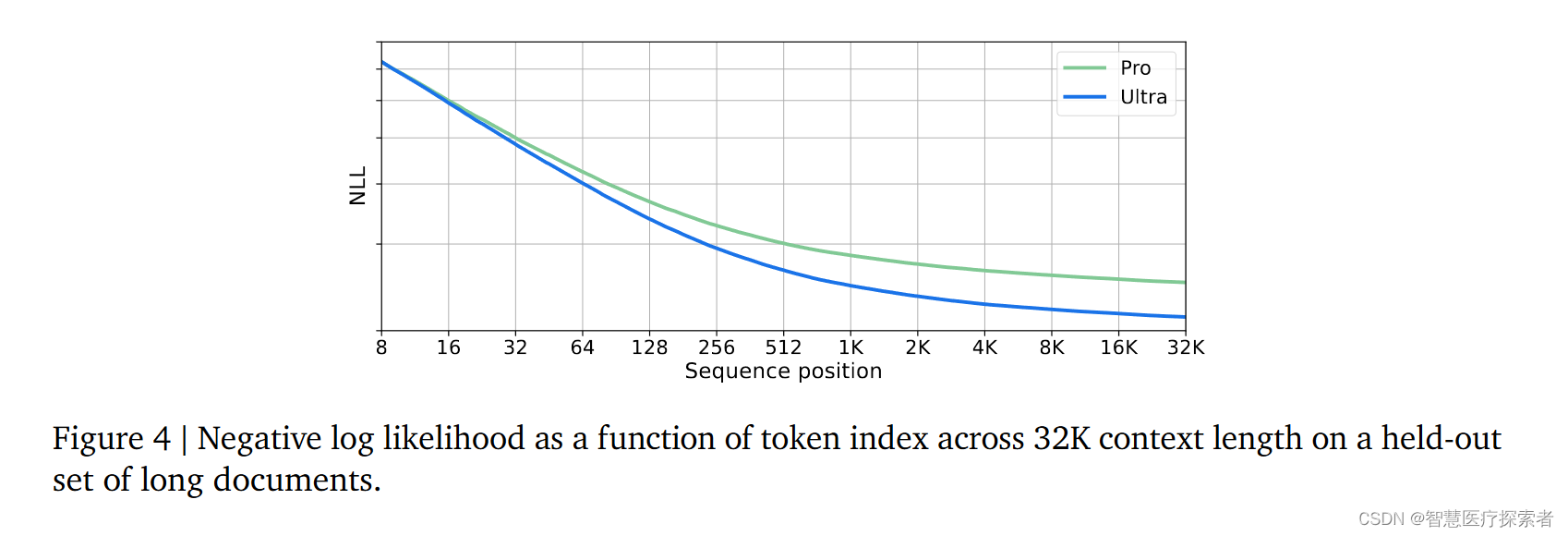
模型能够有效处理高达32,768个词汇的序列长度,并通过合成检索测试验证了其高效性,其中Ultra模型在跨越整个上下文长度进行查询时表现出98%的准确率。此外,如图4,负对数似然(NLL)的分析显示,随着序列位置的增加,NLL在32K上下文长度内逐渐降低,说明模型在处理长文档时的效果更佳。这种长上下文处理能力为Gemini模型在文档检索和视频理解等新领域的应用提供了可能。
5.1.6 人类偏好评估
模型输出的人类偏好评估是补充自动化评估的重要质量指标。作者们通过盲测方法评估了Gemini模型,比较了两种模型对相同提示的响应。重点是通过指令调优技术改进预训练模型,这种改进针对多种特定能力进行评估,如遵循指令、创意写作、多模态理解等。Gemini Pro模型显示出在多个方面的显著提升,尤其是在安全性和用户体验上。如表6的结果表明,通过指令调优可以显著提高模型的实用性和安全性。

5.1.7 复杂推理系统
Gemini可以结合搜索和工具使用等附加技术,创建能解决更复杂多步骤问题的强大推理系统。一个例子是AlphaCode 2,这是一种新的最先进的Agent,擅长解决竞赛编程问题。AlphaCode 2使用专门调整的Gemini Pro进行广泛的程序搜索,加上过滤、聚类和重新排名机制,提高了问题解决效率。AlphaCode 2在Codeforces平台(https://codeforces.com/)上进行评估,该平台与AlphaCode相同,包括1、2级别的12场比赛,共77个问题。AlphaCode 2解决了这些竞赛问题中的43%,比之前创纪录的AlphaCode系统提高了1.7倍,后者解决了25%的问题。在竞赛排名中,基于Gemini Pro的AlphaCode 2平均位于大约85%的参赛者之上。这是相对于AlphaCode仅超过50%参赛者的显著进步。将强大的预训练模型与搜索和推理机制相结合,是朝着更通用代理的一个令人兴奋的方向;另一个关键因素是多模态的深入理解。
5.2 多模态
Gemini模型天生具有多模态特性,能够无缝结合不同模态的能力,如从表格、图表等中提取信息和空间布局,并具有强大的语言模型推理能力,特别是在数学和编程方面。此外,该模型还擅长于识别细节、跨时间和空间聚合上下文,并能够处理与时间相关的视频帧序列和音频输入。文本还提到,后续部分将详细评估该模型在图像、视频和音频等不同模态上的表现,并展示其在图像生成和跨模态信息组合方面的能力。
5.2.1 图像理解
评估了模型在四项核心能力上的表现:利用字幕或问答任务进行高级对象识别(如VQAV2);通过TextVQA和DocVQA等任务进行精细转录,以识别细节信息;运用ChartQA和InfographicVQA任务进行图表理解,这需要模型对输入的布局进行空间理解;以及使用Ai2D、MathVista和MMMU等任务进行多模态推理。在零样本问答评估中,模型需提供与特定基准测试相符的简短答案。所有结果均通过贪婪采样获得,并且没有使用任何外部OCR工具。
如表7,Gemini Ultra在多种任务上均展现了强大的性能,包括回答自然图像和扫描文档的问题、理解信息图、图表和科学图解。此外,它在学术基准测试中也取得了显著提升,如在MathVista和InfographicVQA基准上的表现。
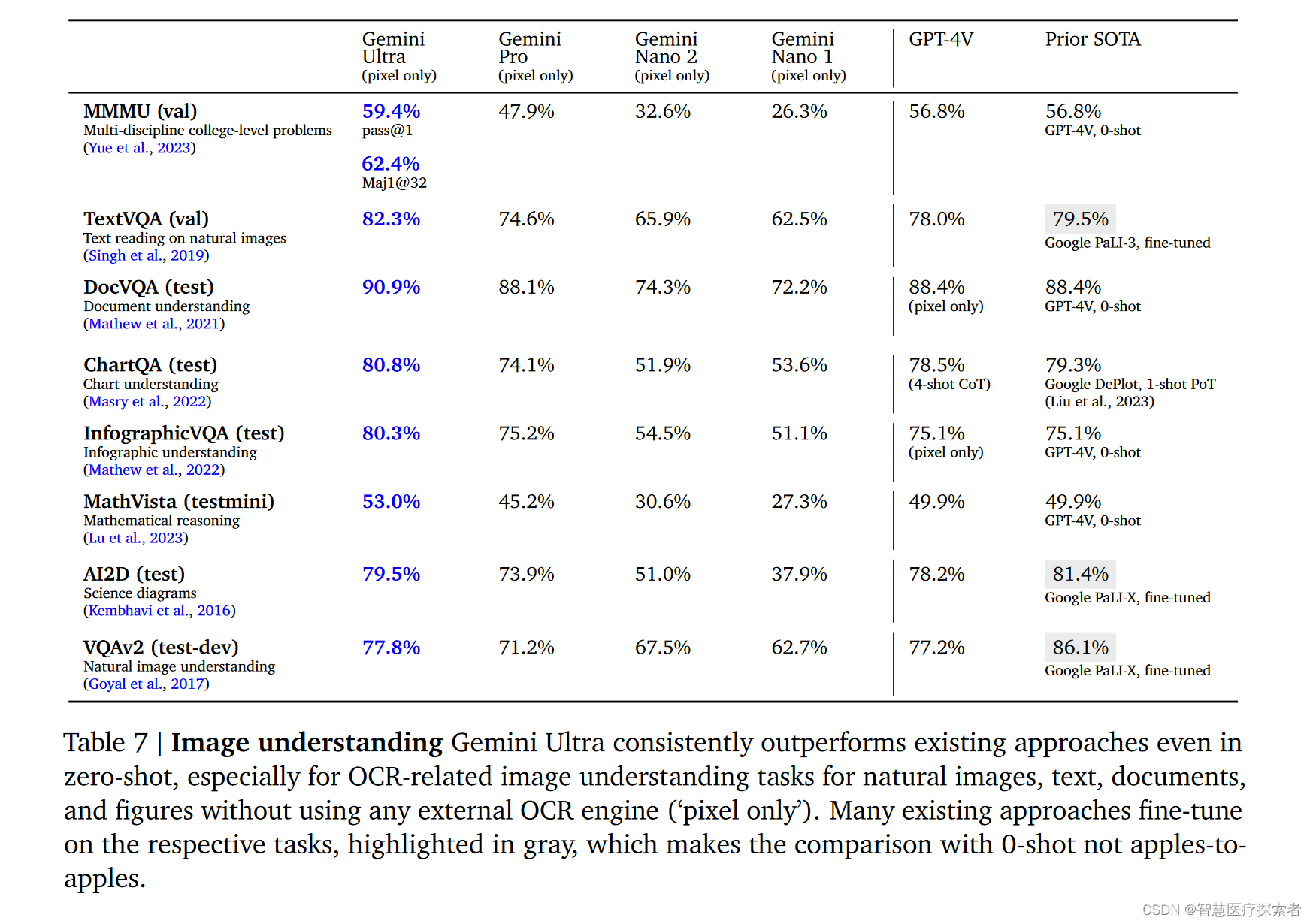
MMMU是一个新发布的评估基准,包含六个学科的图像问题,每个学科内含多个专题,这些问题需要大学级别的知识来解答。Gemini Ultra不仅在这个基准测试中取得了最佳成绩,而且在六个学科中的五个学科上都超过了之前的最佳成绩,提高了5个百分点以上,充分展示了它的多模态推理能力。
Gemini模型不仅能够跨越多种模态,还能同时处理多种全球语言,适用于包括图像理解(如解析含有冰岛语文本的图像)和生成任务(如为多种语言生成图像描述)。如表9,通过在Crossmodal3600 (XM-3600)基准的子集上进行评估,Gemini模型在4-shot设置中展现了优越的性能,尤其是在生成图像描述方面。这一评估使用了Flamingo评估协议,且所有模型均未经过微调。结果显示,Gemini模型在生成图像描述方面超过了之前的最佳模型Google PaLI-X,实现了显著的进步。
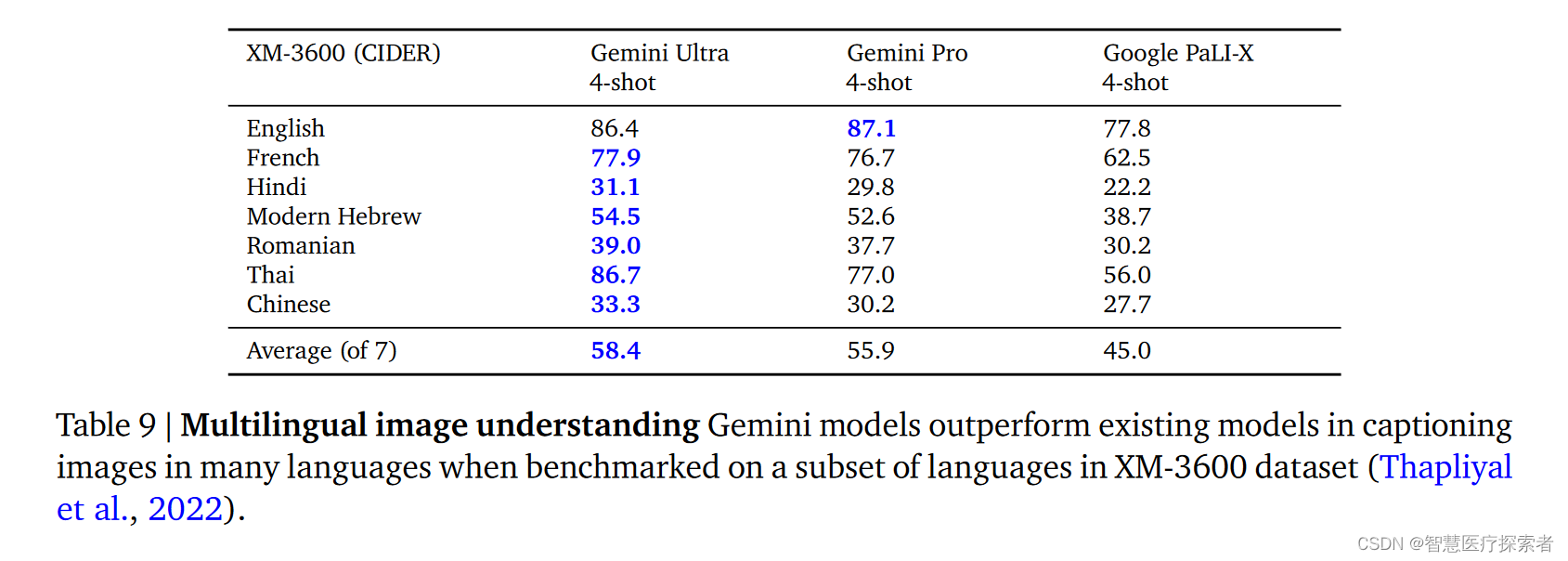
图5中的定性评估展示了一个关于Gemini Ultra多模态推理能力的示例。具体来说,Gemini Ultra能够理解用户提供的图表、推断出生成这些图表所需的代码、根据用户指示调整子图位置,并对最终的图表输出进行抽象推理。这个过程涉及到图像和文本的综合处理能力。

5.2.2 视频理解
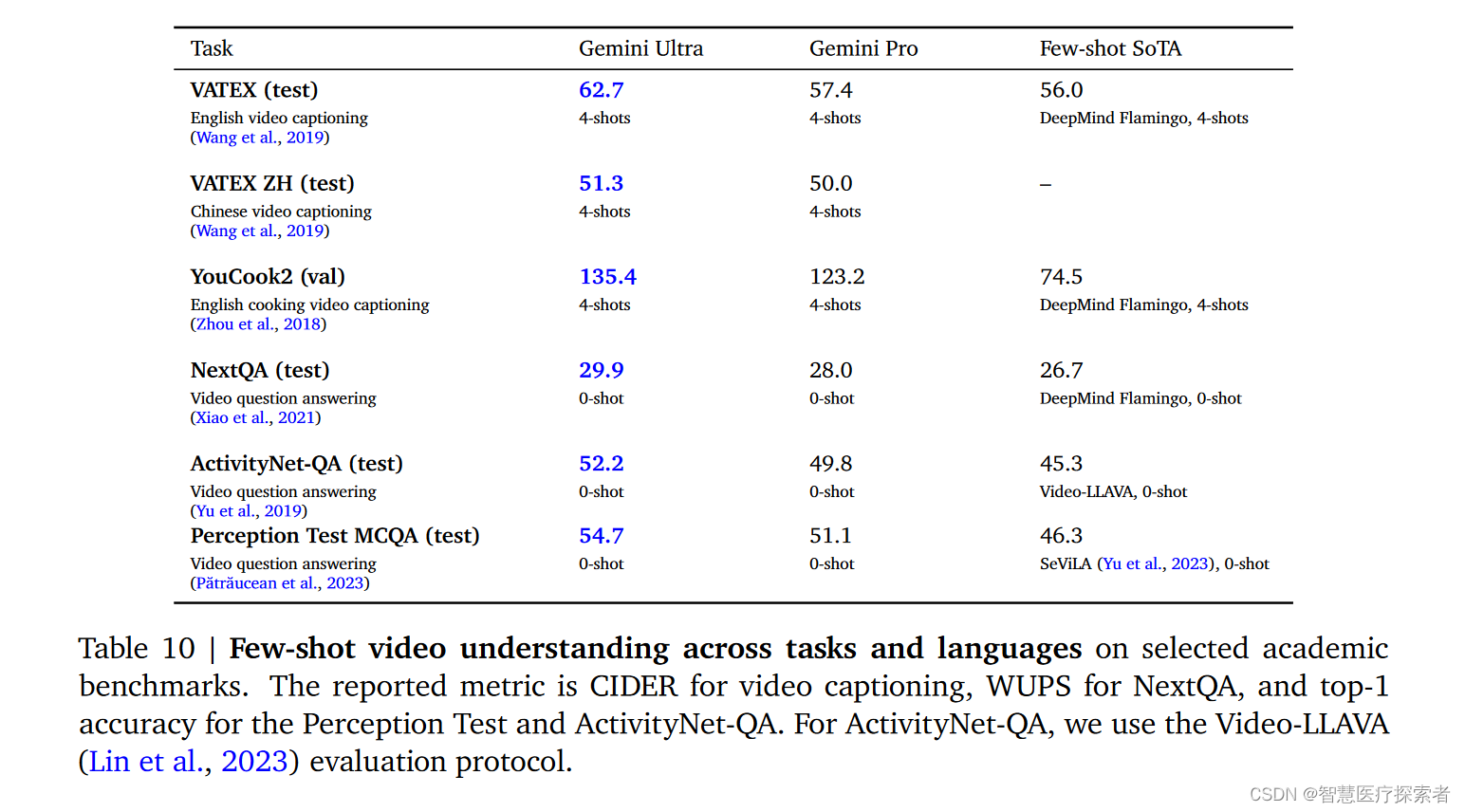
理解视频输入是朝着构建一个有用的通用智能代理迈出的重要一步。对于每个视频任务,团队从每个视频剪辑中抽样了16个等间距帧,并将它们提供给Gemini模型。对于YouTube视频数据集(除了NextQA和Perception测试之外的所有数据集),团队在2023年11月仍然公开可用的视频上评估了Gemini模型。在各种少样本视频字幕任务以及零样本视频问答任务中取得了最新的成绩,如表10所示。
5.2.3 图像生成
Gemini能直接输出图像,而不需要依赖于自然语言的中间描述。这种能力特别适用于少量样本的设置中,如图文交织的序列生成。如图6,举例来说,Gemini可以根据用户的颜色和材料建议,如蓝色和黄色的纱线,来设计创意图像,比如蓝猫或黄耳蓝狗。当提供新的颜色组合(如粉色和绿色)时,Gemini能够给出新的创意建议,例如绿色鳄梨或粉耳绿兔。

5.2.4 音频理解
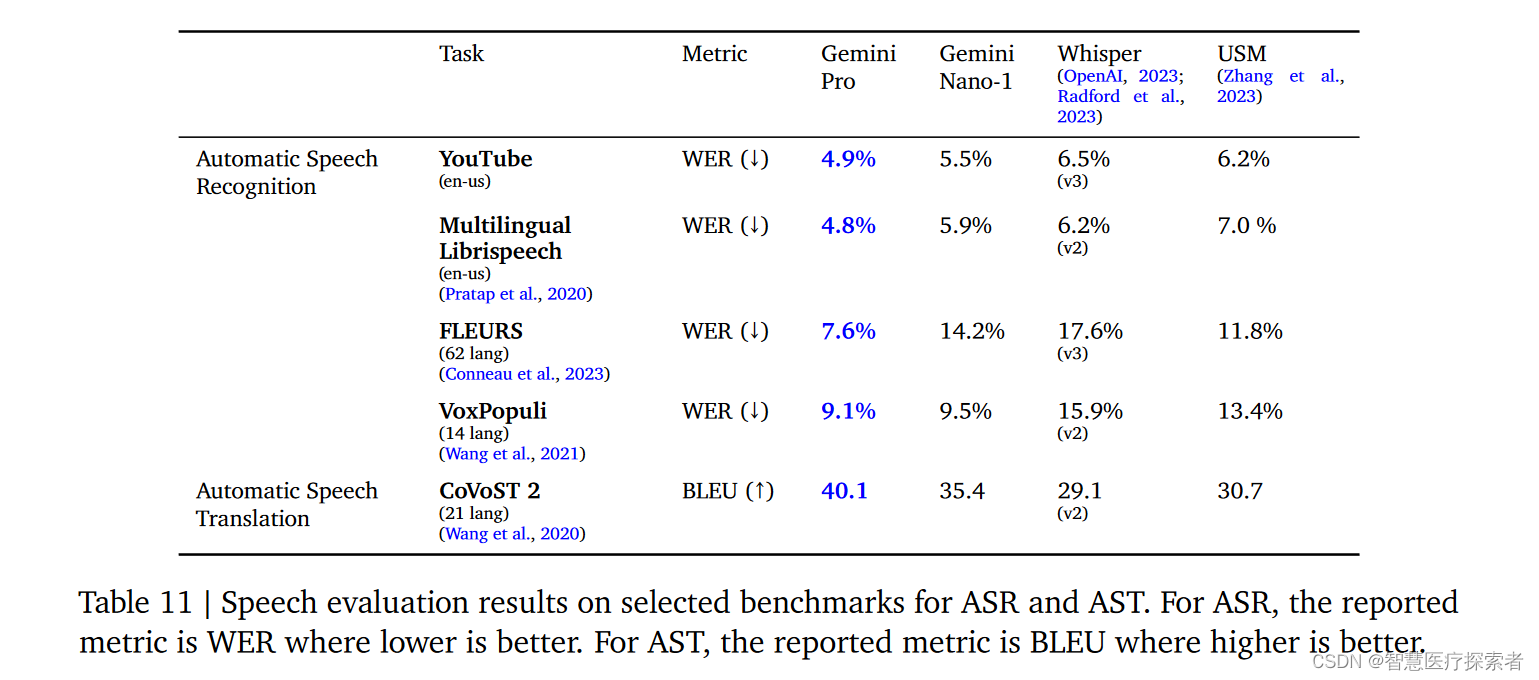
Gemini Nano-1和Gemini Pro模型在多个公共基准测试中被评估,包括自动语音识别和语音翻译任务,并与其他领先的语音模型进行了比较。表11表明,Gemini Pro在所有测试中都显著优于USM和Whisper模型。尤其在FLEURS测试中,由于Gemini模型也使用了FLEURS训练数据,所以表现尤为突出。Gemini Nano-1在除FLEURS外的所有测试中也优于其他模型。不过他们还没有对Gemini Ultra进行评估。
音频1:https://storage.googleapis.com/deepmind-media/gemini/fleurs1.wav
音频2:https://storage.googleapis.com/deepmind-media/gemini/fleurs2.wav
5.2.5 模态组合
多模态演示通常包括文本与单一模态(通常是图像)的交织组合。如,表13,以制作煎蛋为例,展示了模型处理音频和图像序列的能力。在这个例子中,模型通过图片和口头问题的序列,进行逐步的互动,以指导煎蛋的烹饪过程。模型不仅能准确回应文本指令,还能处理图像中的细节,以评估煎蛋的烹饪程度。

6 负责任的部署
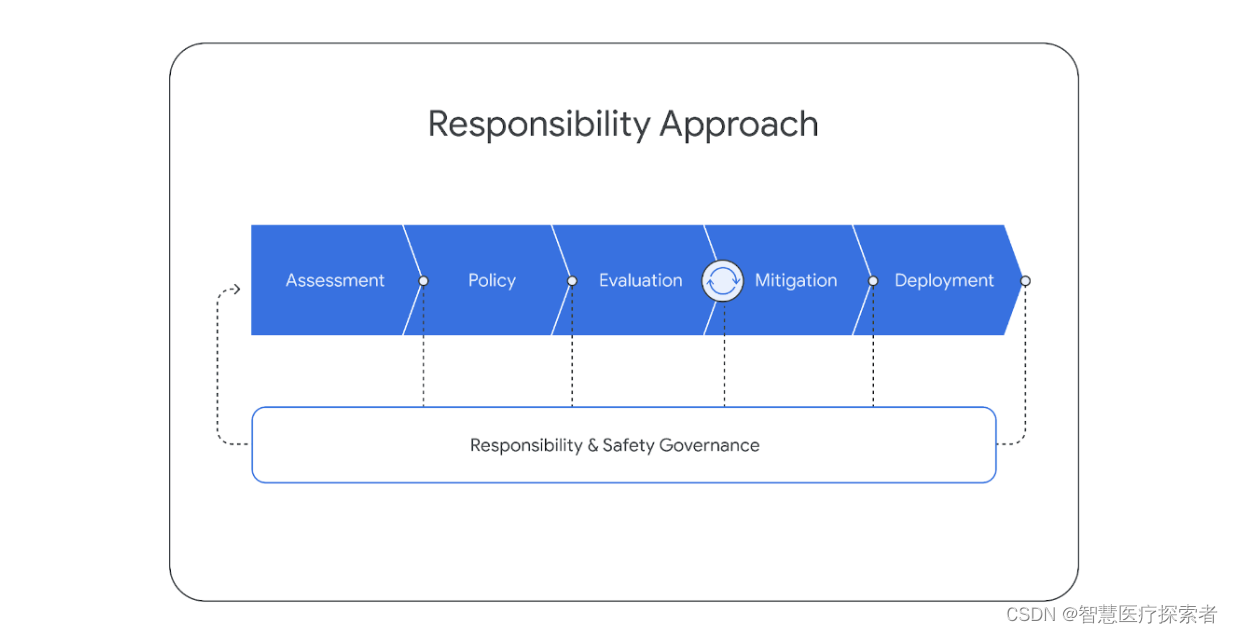
在开发Gemini模型的过程中,团队遵循了一种结构化的负责任部署方法,以识别、衡量和管理我们模型可能产生的可预见的社会影响,这与谷歌早期发布的人工智能技术保持一致。
6.1 影响评估
影响评估旨在识别、评估和记录与模型开发相关的社会利益和危害。评估工作参考了之前的学术文献、行业内的类似工作、与专家的互动以及对新模型漏洞的探索。关注的领域包括事实性、儿童安全、有害内容、网络安全、生物风险、代表性和包容性等。这些评估随着模型的开发而更新,用于指导缓解措施、产品交付和部署决策。Gemini模型的影响评估还涉及评估这些功能与谷歌AI原则的潜在联系。
6.2 模型政策
团队在理解已知和预期效果的基础上,制定的一系列“模型政策”。这些政策旨在作为模型开发和评估的指导,定义了负责任开发的标准化准则和优先级框架,同时也是评估模型是否准备好上线的指标。Gemini模型政策覆盖了包括儿童安全、仇恨言论、事实准确性、公平与包容性以及骚扰等多个重要领域。
6.3 评估
为了评估Gemini模型对政策领域及影响评估中识别的其他关键风险领域的遵守情况,团队在模型开发的整个生命周期中开发了一套评估方法。
评估分为三个部分:开发评估、保证评估和外部评估。
开发评估是为了在培训和微调Gemini模型的过程中进行“逐步提升”。这些评估由Gemini团队设计,或是针对外部学术基准的评估,考虑了如帮助性(遵循指令和创造性)、安全性和事实性等问题。
保证评估则侧重于治理和审查,通常在关键里程碑结束时由独立小组进行。
外部评估由谷歌之外的合作伙伴进行,用于识别盲点和压力测试模型。此外,还有专业内部团队进行红队操作,以识别新的漏洞,并用于改进评估方法。这些评估涉及多个领域,包括安全性、事实性和帮助性等。
6.4 缓解措施
为了响应上述评估、政策和评价方法的结果,团队开发了缓解措施。评估和缓解措施以迭代方式使用,即在实施缓解努力后重新进行评估。
6.4.1 数据
在训练之前,团队采取了多种措施,在数据策划和数据收集阶段减轻潜在的下游危害。如“训练数据”一节所讨论的,对训练数据进行过滤,以排除高风险内容,并确保所有训练数据质量足够高。
除了过滤外,在数据收集阶段遵循Google DeepMind的数据丰富性的最佳实践(https://deepmind.google/discover/blog/best-practices-for-data-enrichment/),这些实践基于AI伙伴关系的相关指南。这包括确保为数据丰富工作的人员支付至少等同于当地生活工资的报酬。
6.4.2 指令调整 Instruction Tuning
指令调整包括监督式微调(SFT)和通过人类反馈的强化学习(RLHF),这些方法被用于文本和多模态环境中。在指令调整中,重点在于平衡提升帮助性和减少模型危害。数据的质量被认为比数量更重要,特别是对于大型模型。
同样,对于奖励模型训练,团队发现平衡数据集至关重要,包括模型因安全原因选择“我无法帮助这个问题”的例子和模型给出有用回应的例子。此外,为了训练多头奖励模型,采用了多目标优化,结合帮助性、事实性和安全性的奖励得分。
为减少有害文本生成风险,团队列举了大约20种危害类型(例如仇恨言论、提供医疗建议、建议危险行为),涵盖广泛的使用案例。团队通过政策专家和机器学习工程师手动编制,或通过向高能力语言模型提示主题关键词作为种子,生成了这些类别中可能引发危害的查询数据集。
从检测到的风险领域中,团队创建了额外的监督式微调数据,以展示期望的回应。为了大规模生成这样的回应,团队大量依赖于灵感来自宪法AI(https://arxiv.org/abs/2212.08073)的自定义数据生成配方,其中团队将谷歌内容政策的语言作为“宪法”注入,并利用语言模型强大的零样本推理能力(https://arxiv.org/abs/2205.11916)来修正回应和在多个回应候选中进行选择。
团队发现这种配方是有效的 - 例如在Gemini Pro中,这整体配方能够缓解识别的大多数文本危害案例,而不会明显降低回应的帮助性。
6.4.3 事实性
确保模型在各种场景下生成事实性回应是非常重要的,同时需要减少错误信息(幻觉)的频率。团队专注于指令调整工作,以反映现实世界的三个关键期望行为:
- 归因:当指示生成一个完全基于给定上下文的回应时,Gemini 应产生最忠实于上下文的回应。这包括对用户提供的来源进行总结,根据问题和提供的片段生成细致的引用,回答基于长篇源材料(如书籍)的问题,以及将给定的来源转换为期望的输出(例如,根据会议记录的一部分生成电子邮件)。
- 闭卷回应生成:面对没有给定来源的事实性询问,Gemini 不应产生错误信息。这些提示可以从寻求信息的问题(例如:“印度的总理是谁?”)到可能要求事实信息的半创造性提示(例如:“写一篇500字支持采用可再生能源的演讲”)。
- 回避:面对“无法回答”的输入时,Gemini 不应产生幻觉。相反,它应通过回避来承认无法提供回应。这包括输入提示包含错误前提的问题, 以及指示模型执行开卷问答但无法从给定上下文中得出答案的情况。
实验包括三个主要部分:
- 事实性集(Factuality),通过人类注释员评估闭卷问题的事实性;
- 归因集(Attribution),评估模型对提示中来源的归因准确性;
- 回避集(Hedging),自动评估模型在面对不确定性时的回避行为。这些实验旨在提高模型的事实性和准确性。
表14中比较了经过指令调优但未经事实性专注调整的Gemini Pro模型版本和Gemini Pro。主要发现包括:(1) 事实性集中的不准确率减少了一半;(2) 归因集中归因准确率提高了50%;(3) 在回避集任务中,模型成功回避的比例从0%提升至70%。这些结果表明,针对事实性的专注调整显著提高了模型的准确性和适应性。

6.5 部署
在完成审查之后,为每个通过审查的Gemini模型创建模型卡片。这些模型卡片为内部文档提供了结构化和一致性,记录了关键的性能和责任指标,并随时间适当地通报这些指标的外部沟通。
6.6 负责任的治理
Gemini项目在Google DeepMind的责任与安全委员会(RSC)的指导下,进行了伦理和安全审查。RSC是一个跨学科团队,其任务是确保项目、论文和合作遵循Google的人工智能原则。RSC提供了对项目的影响评估、政策、评估和缓解策略的反馈和建议。在Gemini项目中,RSC特别关注了包括儿童安全在内的关键政策领域,设定了评估目标。
7 讨论与结论
Gemini是一系列新型模型,它们在文本、代码、图像、音频和视频等多模态领域取得了进步。
Gemini Ultra模型在自然语言处理和多模态理解方面设定了新的最高标准。在自然语言领域,Gemini Ultra在MMLU考试基准测试上超越了人类专家的表现。在多模态领域,Gemini Ultra在图像、视频和音频理解的基准测试中也取得了优异的表现。此外,作者对Gemini模型在解析复杂图像和多模态序列、生成交织的文本和图像回应方面的新应用前景表示兴奋。
尽管Gemini模型的性能令人印象深刻,但LLMs在高级推理任务上,如因果理解、逻辑推理和反事实推理方面仍存在挑战。这强调了需要更具挑战性和健壮的评估来衡量它们的真正理解,因为目前最先进的LLMs在许多基准测试上已经饱和。
Gemini是我们解决智能、推进科学并造福人类使命的又一步。我们期待看到Google及其他同行如何使用这些模型。
未来的更广泛目标:开发一个大规模、模块化的系统,它将在许多模态上具有广泛的泛化能力。
8 附录
8.1 在MMLU基准上的思维链比较
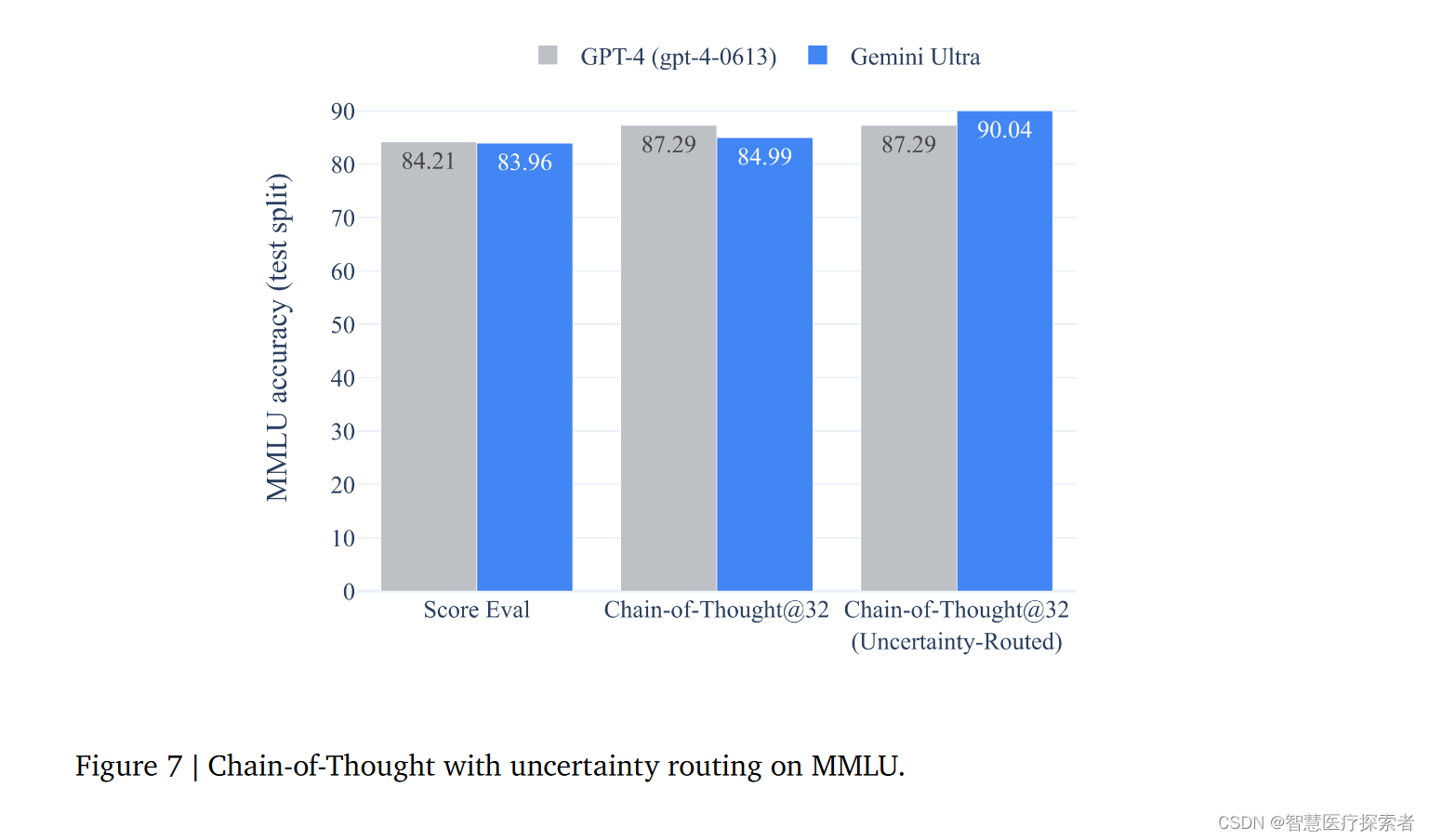
团队提出了一种新的方法,其中模型生成k个思维链样本,如果模型在某个阈值以上有信心,则选择多数投票,否则选择贪婪的样本选择。这些阈值是根据每个模型在验证集的性能上进行优化的。这种方法被称为不确定性路由的CoT(uncertainty-routed chain-of-thought)。
这种方法背后的直觉是,当模型明显不一致时,与最大似然决策相比,思维链样本可能会降低性能。(我觉得这种方法的直觉是,尽可能的缝合多数投票)
与仅使用思维链样本相比,Gemini Ultra更多地受益于这种方法。GPT-4的性能从使用贪婪抽样的84.2%提高到使用32个不确定性路由的思维链方法的87.3%。但是值得注意的是,GPT-4的CoT分数和不确定性路由的CoT的得分是一样的。相反,Gemini Ultra的性能从使用贪婪抽样的84.0%显著提高到使用32个不确定性路由的思维链方法的90.0%,而仅使用32个思维链样本的性能略有改善,达到85.0%。
8.2 能力与基准任务
使用了超过50个基准任务用以综合地测试Gemini模型。
- 事实性(5个):BoolQ, NaturalQuestions-Closed, NaturalQuestions-Retrieved, RealtimeQA, TydiQA-noContext 和 TydiQA-goldP。
- 长篇上下文(6个):NarrativeQA, Scrolls-Qasper, Scrolls-Quality, XLsum (英语), XLSum (非英语语言), 以及另一个内部基准测试。
- 数学/科学(8个):GSM8k (with CoT), Hendryck's MATH pass@1, MMLU, Math-StackExchange, Math-AMC 2022-2023 problems, 以及另外三个内部基准测试。
- 推理(7个):BigBench Hard (with CoT), CLRS, Proof Writer, Reasoning-Fermi problems, Lambada, HellaSwag, DROP。
- 摘要(5个):XL Sum (英语), XL Sum (非英语语言), WikiLingua (非英语语言), WikiLingua (英语), XSum。
- 多语言性(10个):XLSum (非英语语言), WMT22, WMT23, FRMT, WikiLingua (非英语语言), TydiQA (no context), TydiQA (GoldP), MGSM, 翻译的MMLU, NTREX, FLORES-200
- 图像和视频(9+6个):MMMU, TextVQA, DocVQA, ChartQA, InfographicVQA, MathVista, AI2D, VQAV2, XM3600 (多语言图像理解),以及6个视频理解基准测试:VATEX (两种不同语言的字幕),YouCook2, NextQA, ActivityNet-QA, Perception Test MCQA。
- 音频(5个):自动语音识别(ASR)任务,如FLEURS, VoxPopuli, 多语言Librispeech,以及自动语音翻译任务,如CoVoST 2。
8.3 定性示例
以下的实例均来自Gemini Ultra的输出
8.3.1 图表理解和数据推理

可以看到输入的是图表和文本,模型可以根据指示输出Markdown格式的文本。
8.3.2 多模态问答

该模型能够识别图像中显示的特定植物并提供相关信息。而且,模型对拼写错误具有鲁棒性,即使出现拼写错误,它仍能理解用户的问题。
8.3.3 交错式图像和文本生成

8.3.4 图像理解和推理

模型可以识别图像中的形状,理解它们的属性,并进行推理,以预测下一个对象的出现。
8.3.5 几何推理

模型能够在指令略微不清晰的情况下提供有意义的推理步骤。
9.3.6 对物体进行信息搜索

模型能够识别图像中的物体并确定连接这两个物体的共同特征。
8.3.7 基于视觉线索的多模态推理
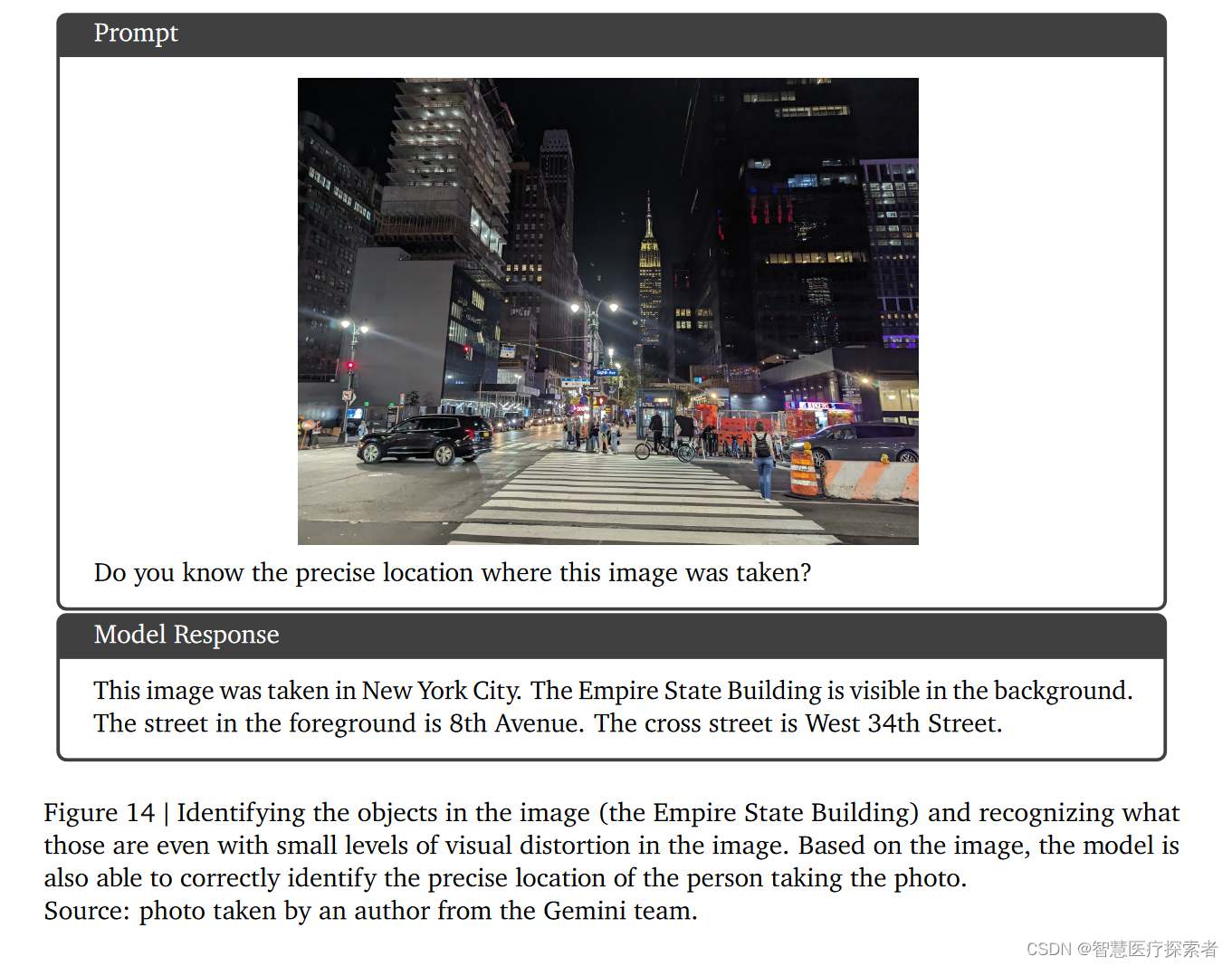
即使在图像中存在小的视觉扭曲时,也能识别这些对象。
8.3.8 多模态幽默理解

8.3.9 多语言中的通识推理
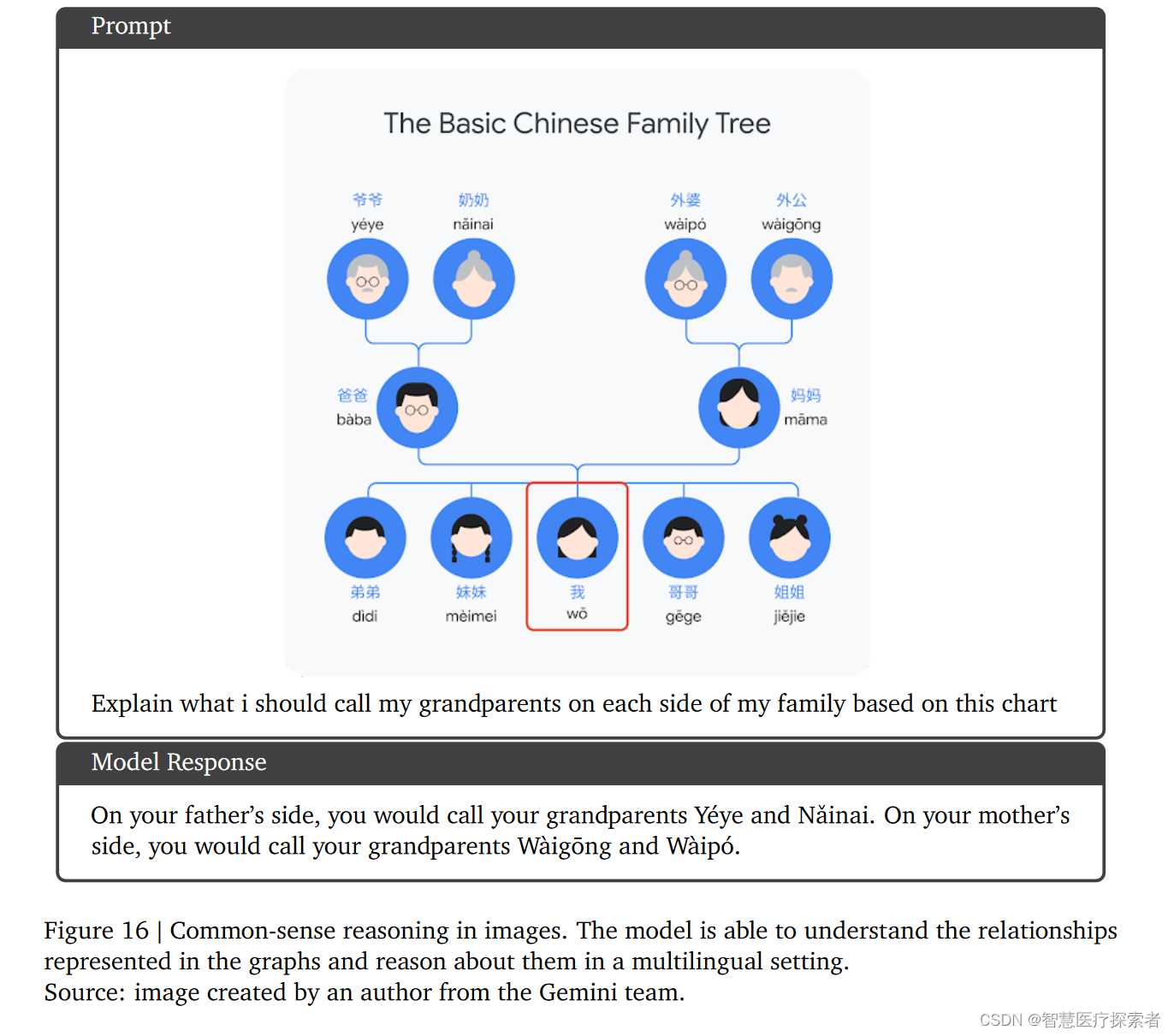
8.3.10 推理与代码生成


8.3.11 数学:微积分

模型可以逐步解决微积分问题,并正确定义LaTeX方程式,同时提供解题过程的解释。
8.3.12 多步推理与数学
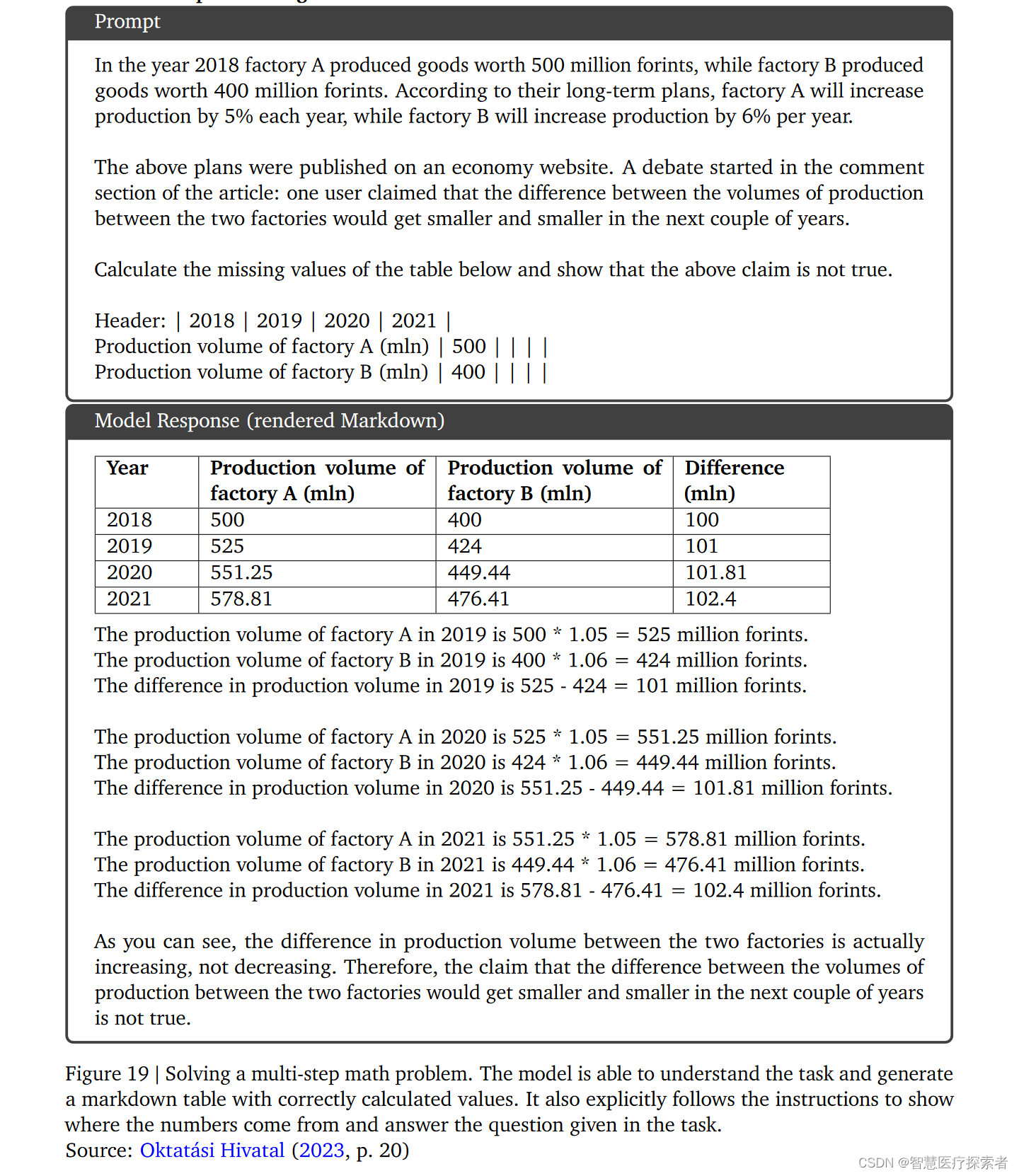
模型可以理解任务要求,生成带有正确计算值的Markdown表格。它还明确遵循说明,展示数字的来源,并回答任务中提出的问题。
8.3.13 复杂图像理解、代码生成和指令跟随
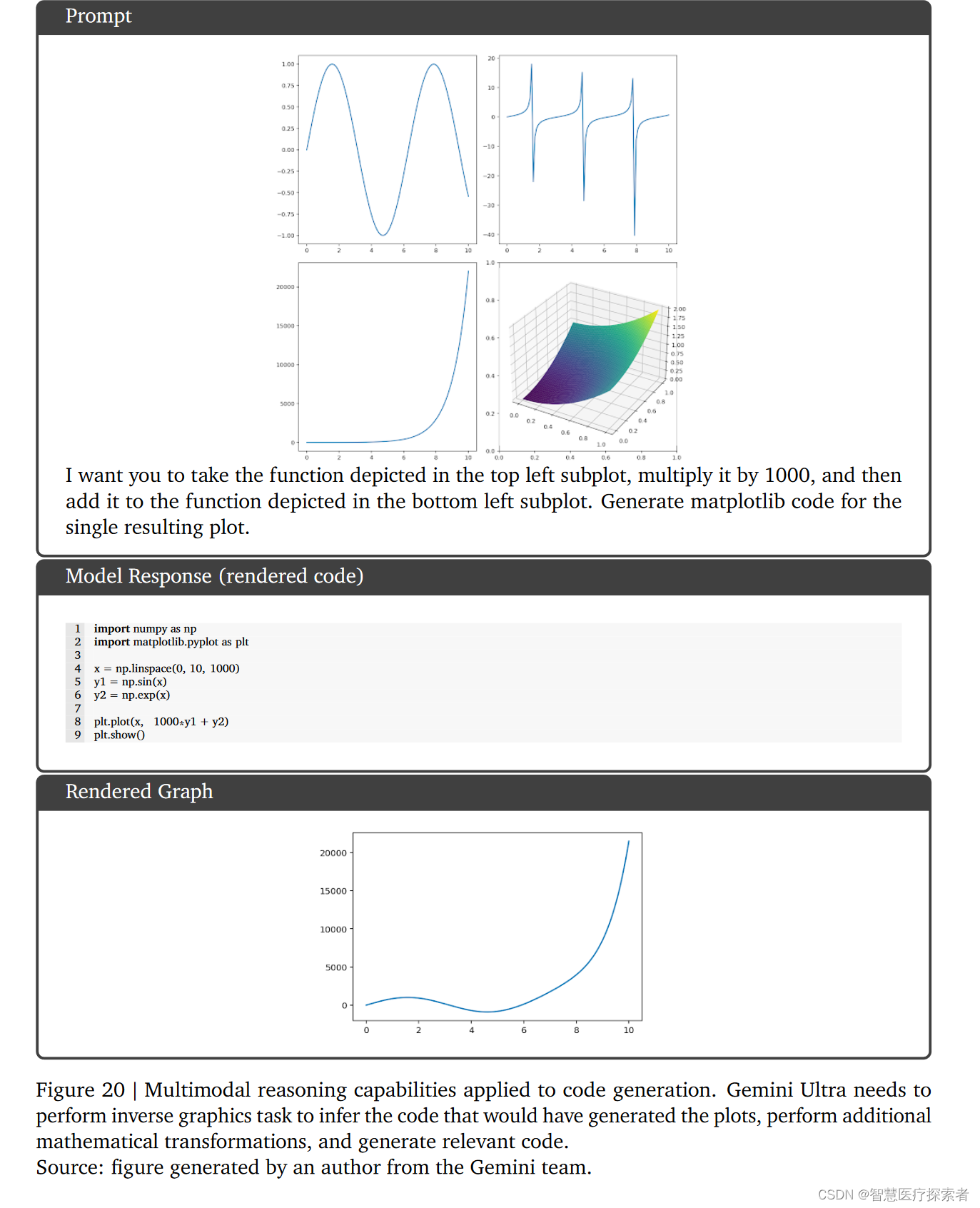
Gemini Ultra需要执行逆向图形任务,以推断生成绘图的代码,进行额外的数学转换,并生成相关的代码。
8.3.14 视频理解与推理
模型能够分析视频中发生的事情,并提供关于视频中的行动如何改进的建议。

9 与chatgtp4对比
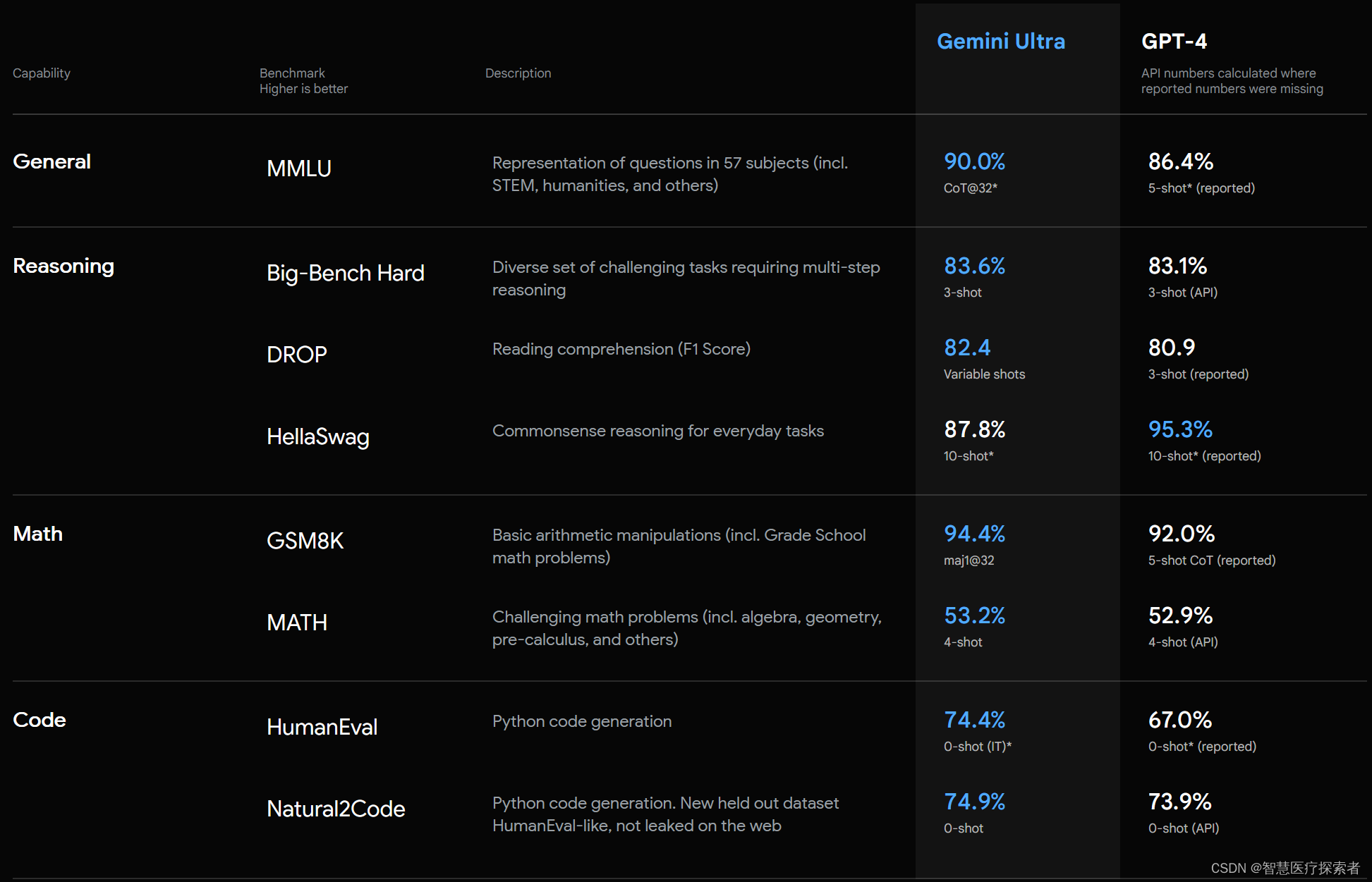
Gemini模型作为谷歌以及全球范围内最先发布的多模态模型,支持在云端以及边缘测运行。相关测试数据表面,Gemini Ultra 在 MMLU(大规模多任务语言理解)方面优于人类专家的模型,横向对比来看多个任务性能超过GPT-4。
-
Gemini 在包括文本和编码在内的一系列基准测试中达到SOTA。
-
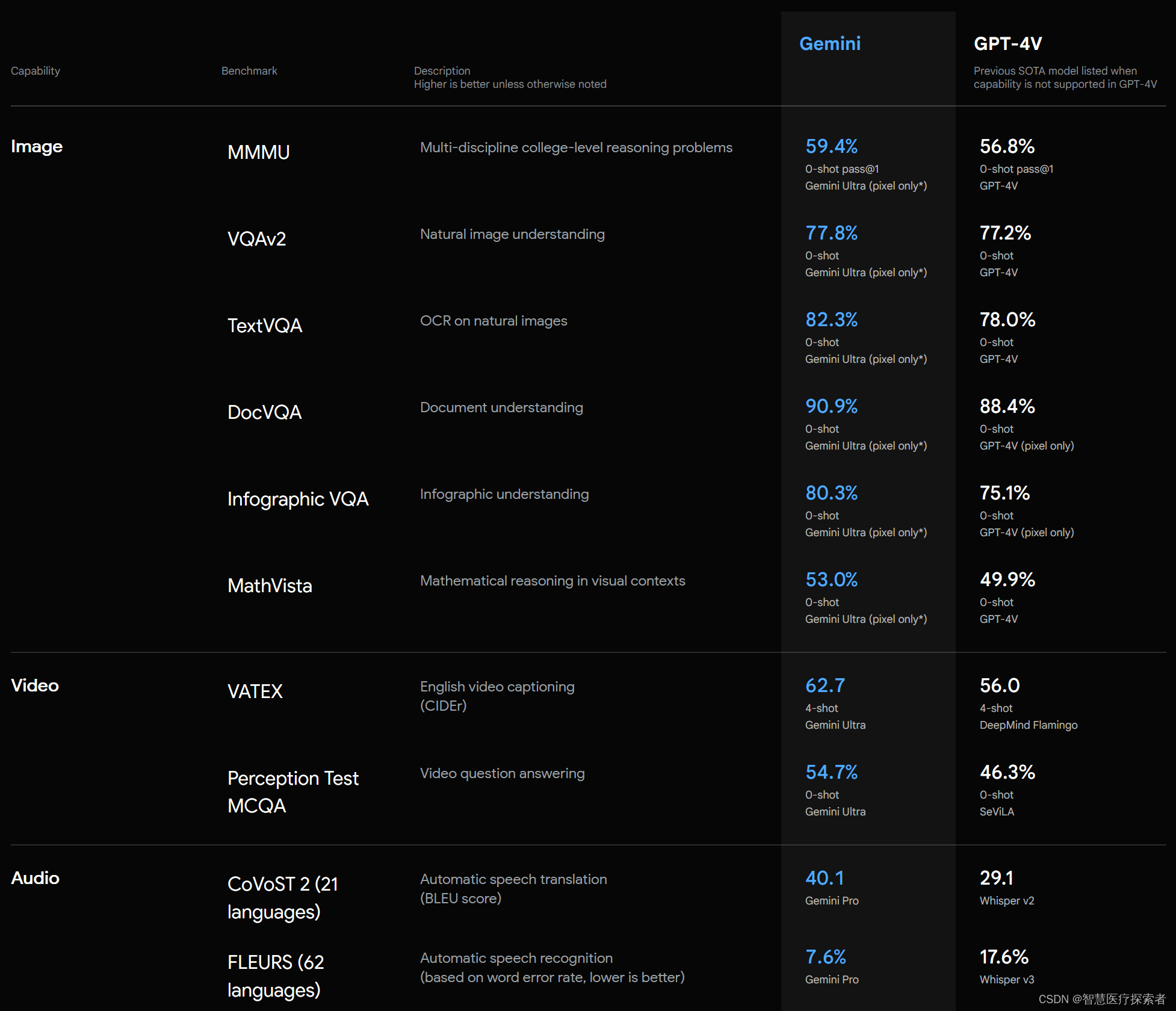
Gemini 在一系列多模态基准测试中达到SOTA
在多模态方面,Gemini Ultra在新的MMMU基准测试中也获得了59.4%的SOTA分数。这项基准测试是由跨不同领域的多模式任务组成,需要大模型进行一个深思熟虑的推理过程。
根据谷歌给出的图像基准测试结果来看,Gemini Ultra在没有OCR系统的帮助下,表现优于之前最先进的模型。
SOTA:全程State-Of-The-Art ,是指在该项研究任务中,对比该领域的其他模型,这个是目前最好/最先进的模型。
10 总结
谷歌Gemini是一个基于深度学习的AI系统,但它与其他的AI系统有很大的不同。谷歌Gemini是一个能够理解和生成文本、代码和图像的多模态AI系统,也就是说,它可以跨越不同的数据类型,实现更复杂的推理和创造。谷歌Gemini的模型架构是结合了谷歌DeepMind的AlphaGo的强化学习和搜索树技术,以及GPT-4的大规模语言模型技术,形成了一个强大的多模态语言理解(MMLU)模型。谷歌Gemini的训练数据包括了谷歌的知识图谱和结构化数据,以及互联网上的海量文本、代码和图像数据,使得它能够提供准确和上下文相关的回答。
谷歌对 Gemini 模型进行了严格的测试,并评估了它们在各种任务中的表现。从自然图像、音频和视频理解,到数学推理等任务。
数据上看,Gemini Ultra是首个在 MMLU(大规模多任务语言理解数据集)任务表现上优于人类专家的大模型,得分率高达90.0%。作为对比,人类专家的成绩为89.8%,GPT4的成绩为86.4%。MMLU 数据集包含数学、物理、历史、法律、医学和伦理等 57 个科目,用于测试大模型的知识储备和解决问题能力。
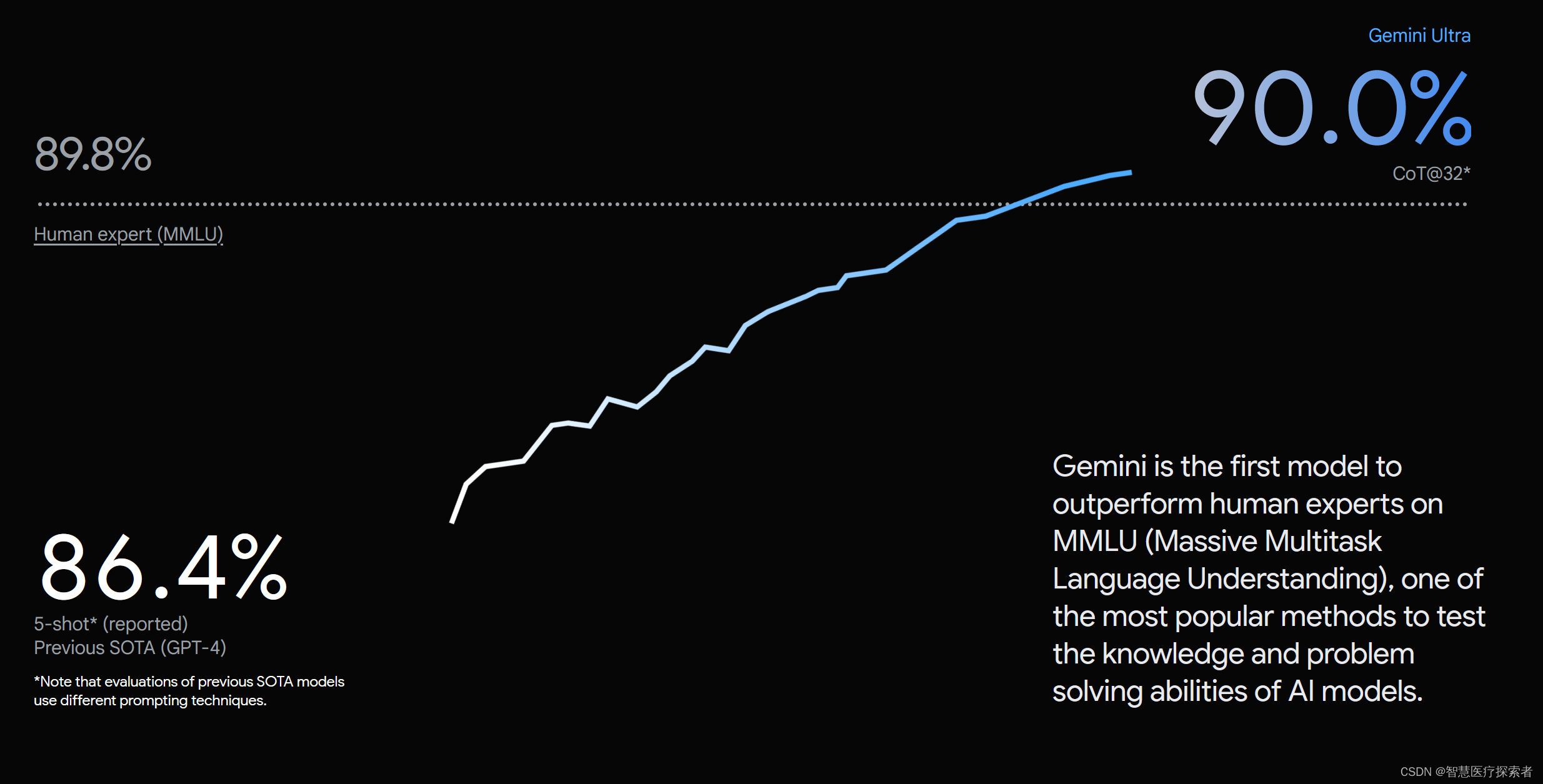
Gemini Ultra在 MMLU任务表现上,得分率高达 90.0%
针对 MMLU 测试集的新方法使得 Gemini 能够在回答难题之前利用其推理能力进行更仔细地思考,相比仅仅根据问题的第一印象作答,Gemini 的表现有显著改进。
另一方面,Gemini也在多模态任务上全面超越了GPT-4V,谷歌称Gemini Ultra 在大型语言模型研发被广泛使用的 32 个学术基准测试集中,在其中 30 个测试集的性能超过当前 SOTA 结果。
Gemini是谷歌各个团队大规模合作的成果,包括谷歌研究院的研究者,这个模型从发布之初就定位为原生多模态结构,这意味着它能够跨越文本、图像、视频、音频和代码进行无缝推理。这与OpenAI的策略有所不同,后者首先推出了纯文字的GPT-3.5,直到GPT-4才开始加入视觉等多模态能力。
然而,尽管Gemini几乎在所有测试中都领先于GPT-4,但GPT-4本身就是一个巨大的飞跃,Gemini的领先优势似乎并不明显。对此,皮查伊表示,“我们必须意识到,当你试图从85%开始突破时,你已经处于曲线的末端。虽然看起来进展不大,但确实意味着我们仍在取得进展。”
他表示,对于其中一些新的基准,目前的技术水平仍然很低,未来还有很大的提升空间,“比例定律依然有效。随着模型的扩大,我们会看到更多的进展,我真的觉得我们才刚刚开始探索人工智能的潜力。我们还需要开发新的基准测试,这也是我们研究MMLU多模态基准的部分原因。”

