
- 12021年G3锅炉水处理报名考试及G3锅炉水处理模拟考试_臭屁的玻璃件及其电位与溶液中氢离子浓度成
- 2网页适配 iPhoneX,就是这么简单_chrome调试ios安全距离
- 3手机免root安装kali linux 步骤,离线版(最终可行版)_kali linux手机版安装
- 4Android/iOS APP备案流程指南
- 5vue错误:Property or method "**" is not defined 和 Invalid handler for event "click"_property or method is not defined
- 6android viewpager 内容有的不能滑动,关于viewpager无法滑动
- 7欧拉操作系统在线安装mysql8数据库并用navicat premium远程连接_欧拉系统安装mysql数据库
- 8单神经元自适应控制算法,bp神经网络缺点及克服_bp神经网络能优化单个的因素吗
- 9spring-framework-3.2.16.RELEASE源码编译并导入eclipse_org.springframework:spring-beans:3.2.16.release
- 10组合式(Composition)API_组合式api
Capture, Learning, and Synthesis of 3D Speaking Styles_CVPR2019
赞
踩
0 Abstract
由于缺少可用的3D数据集、模型和评估指标,导致语音驱动的3D面部动画逼真性和人性化有待提高。
因此本文提出了一个新的数据集。提出的VOCA在训练过程中可调节说话风格,同时提供了动画师控制改变说话风格,面部形状和姿势等。
1 Introduction
许多面部动作是由语言直接引起的,因此研究语音驱动生成很有意义。
语音信号和面部表情是强相关的,但在两个不同的空间。因此需要非线性回归函数将两者联系起来。
集成DeepSpeech对音频特诊进行提取,使得VOC具有鲁棒性。
基于FLAME模型对头部、脸部建模,编辑相关的形状和姿态
2 Related work
面部动画生成领域主要有三类:基于语音,基于文本,基于视频。
语音驱动面部动画:
分为传统基于机器学习的和深度学习的方法。尽管有方法和VOCA相似,但他们都是为普通人脸设计动画,但本文重点是为逼真的人脸网格设置动画,因此在高分辨率人脸扫描上训练模型。
文本驱动面部动画
性能驱动面部动画
3 Preliminaries
3.1 DeepSpeech
为了获得对不同音频的鲁棒性,无论噪声、录音伪影或者别的语言。DeepSpeech是一种基于端到端深度学习的自动语音识别模型。前三层是非循环全连接层和ReLU,第四层是双向RNN,第五层是全连接层。然后被送到softmax输出字符概率。
3.1 Flame
面部形状和头部运动差别很大,并且每个人的说话风格不同。这种大的变化促使采用共同的学习空间。通过引入FLAME来解决这些问题,采用线性变换描述身份和表情相关的形状变化,并使用LBS模拟颈部、下把和眼球旋转建模。给定零姿态T,混合型状被建模为从T的定点偏移。
4 VOCA
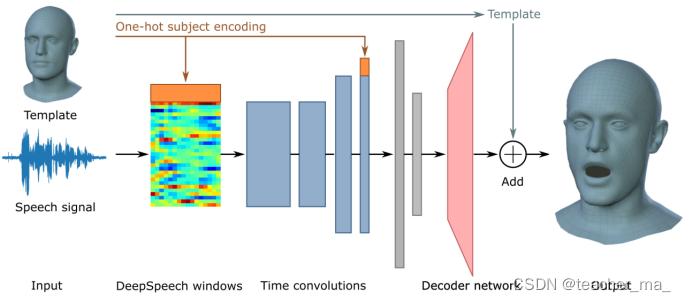
VOCA接收主题模板和原始音频为输入,使用DeepSpeech提取特征。期望的输出是一个3D网格。VOCA的编码器学习音频特征到低维嵌入,解码器将特征映射到3D高维空间。
4.1 语音特征提取
给定一段T秒的音频,提取之后的输出是未归一化的对数概率,长度为0.02s帧(每秒50帧)的字符。这一部分音频提取还不太明白,需要学学音频处理。
4.2 Encoder
编码器由四层卷积层和两层全连接层组成。当多个主题训练,学习特定主体的风格。八个训练对象被编码为一个独热向量,并连接到最终卷积层输出。
4.3 Decoder
解码器是一个全连接层,输出维度是5023*3的顶点位移矩阵。
4.4 动画控制
推理过程中,改变八维独热编码将会改变说话风格。可以使用FLAME来改变各种姿态和表情。
5 VOCASET数据集
本文数据集包含一组从六名女性和六名男性采集的音频4D扫描对。每个主题收集了40个英语句子序列,长度3-5秒。使用FLAME注册原始3D头部扫描。所有网格取消着色,消除了围绕颈部的全局旋转、平移和头部旋转的影响。所有网格处于零姿态。

