
- 1arcgis10.0及以上版本,使用arcpy加载在arctoolbox中批量添加同一图层_arctoolbox输入图层
- 2翻译:Mastering OpenCV with Practical Computer Vision Projects(第8章)(二)
- 3使用深度学习进行时间序列预测_深度学习 时间序列预处理
- 4Docker 部署 elasticsearch + kibana + 分词器(版本7.7.0)_elasticsearch与ik对应版本
- 5使用512KiB RAM基于单片机的实时摄像头人脸识别DNN论文解析_单片机人脸识别算法
- 6uniapp-h5文件复制链接,预览,下载等功能_uniapp 复制链接
- 7使用python处理wps表格_8个WPS表格工作必备的高效技巧!
- 8用PyTorch实现多层感知机(MLP)_pytorch新建mlp
- 9获取当前日期后五天_获取当前日期@now(yyyy-mm-dd);后5天日期
- 10Android GKI 架构简介
Centos7.6+Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建_tai9入口
赞
踩
本文转自https://mshk.top/2019/03/centos-hadoop-zookeeper-hbase-hive-spark-high-availability/,因为原链接打不开,故在此做一个记录。
1、前言
1.1、什么是 Hadoop?
1.1.1、什么是 YARN?
1.2、什么是 Zookeeper?
1.3、什么是 Hbase?
1.4、什么是 Hive
1.5、什么是 Spark?
2、环境准备
2.1、网络配置
2.2、更改 HOSTNAME
2.3、配置 SSH 免密码登录登录
2.4、关闭防火墙
2.7、安装 NTP
3. 下载应用程序及配置环境变量
3.1、创建安装目录
3.2、下载本文中用到的程序
3.3、设置环境变量
4. 安装 Oracle JDK 1.8.0
4.1 下载 Oracle JDK 1.8.0
4.2、配置 Oracle JDK 1.8.0
5、安装 Zookeeper3.4.13
5.1、修改配置文件 zoo.cfg
5.2、为每台服务器创建身份标识
5.3、在所有节点中启动 zookeeper
5.4、查看zookeeper 运行状态
5.5、测试 Zookeeper 是否启动成功
6、安装 Hadoop3.1.2
6.1、修改 Hadoop 配置文件
6.1.1、修改配置文件 core-site.xml
6.1.2、修改配置文件 hdfs-site.xml
6.1.3、修改配置文件 mapred-site.xml
6.1.4、修改配置文件 capacity-scheduler.xml
6.1.5、修改配置文件 yarn-site.xml
6.1.6、编辑 start-dfs.sh,stop-dfs.sh 脚本
6.1.7、编辑 start-yarn.sh,stop-yarn.sh 脚本
6.1.8、修改配置文件 works 文件
6.2、启动 Hadoop
6.2.1、启动JournalNode集群
6.2.2、格式化 NameNode
6.2.3、启动 zookeeper 故障转移控制器
6.2.4、格式化 zookeeper
6.2.5、启动 NameNode
6.2.6、将 NameNode 数据复制到备用 NameNode
6.2.7、启动 HDFS 进程
6.2.8、测试 HDFS 是否可用
6.2.9、启动 YARN
6.2.10、测试 YARN 的可用性
6.2.11、查看 MapReduce 运行的历史记录
6.2.12、验证 Hadoop HA 高可用性
7、安装 Hbase 1.4.9
7.1、修改 Hbase 配置文件
7.1.1、编辑配置文件 hbase-env.sh
7.1.2、编辑配置文件 hbase-site.xml
7.1.3、配置 Slaver
7.1.4、将 Hbase 复制到其他机器
7.2、启动 Hbase
7.2.1、用 Shell 测试连接 Hbase
7.2.2、测试 Hbase 故障转移
8、安装 Mysql 5.7
8.1、启动 Mysql
8.2、授权可以远程访问 Mysql
8.3、修改 Mysql 授权远程访问
9、安装 Hive2.3.4
9.1、修改 Hive配置文件
9.1.1、编辑配置文件 hive-env.sh
9.1.2、编辑配置文件 hive-site.xml
9.1.3、下载 Mysql 驱动
9.2、启动 Hive
9.2.1、初始化 MySql 数据库
9.2.2、创建测试数据,以及在hadoop上创建数据仓库目录
9.2.3、用 Shell 测试连接 Hive
9.2.4、Hive to Hbase
9.2.5、Hbase to Hive
10、安装 Spark 2.4.0
10.1、修改 Spark 配置文件
10.1.1、编辑配置文件 spark-env.sh
10.1.2、编辑配置文件 Slaves
10.2、启动spark集群
10.2.1、将 Spark 和 Scala 复制到其他机器
10.2.2、启动 Spark
10.2.3、测试 Spark 集群
10.2.4、运行 Spark on YARN
11、常见问题
11.1、Hbase
11.1.1、You have version null and I want version 8. Is your hbase.rootdir valid? If so, you may need to run ‘hbase hbck -fixVersionFile’
12. 参考资料
1、前言
1.1、什么是 Hadoop?
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,而 MapReduce 则为海量的数据提供了计算。
(以上介绍来自百度百科)
Hadoop3.1.2 是 Apache Hadoop 3.1 系列的第二个稳定版本。
它包含自 3.1.1 以来的 325 个错误修复、改进和增强功能。
1.1.1、什么是 YARN?
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统。
新版本的 YARN 的基本思想是将 JobTracker 的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。每一个应用的 ApplicationMaster 是一个详细的框架库,它结合从 ResourceManager 获得的资源和 NodeManager 协同工作来运行和监控任务。
ResourceManager–是全局的,负责对于系统中的所有资源有最高的支配权。
ApplicationMaster–每一个job有一个ApplicationMaster 。
NodeManager–是基本的计算框架。
1.2、什么是 Zookeeper?
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper 的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
(以上介绍来自百度百科)
1.3、什么是 Hbase?
HBase 是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的 Google 论文“Bigtable:一个结构化数据的分布式存储系统”。就像 Bigtable 利用了 Google 文件系统(File System)所提供的分布式数据存储一样,HBase 在 Hadoop 之上提供了类似于 Bigtable 的能力。HBase 是 Apache 的 Hadoop项目的子项目。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是 HBase 基于列的而不是基于行的模式。
(以上介绍来自百度百科)
1.3、什么是 Hbase?
HBase 是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的 Google 论文“Bigtable:一个结构化数据的分布式存储系统”。就像 Bigtable 利用了 Google 文件系统(File System)所提供的分布式数据存储一样,HBase 在 Hadoop 之上提供了类似于 Bigtable 的能力。HBase 是 Apache 的 Hadoop项目的子项目。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是 HBase 基于列的而不是基于行的模式。
(以上介绍来自百度百科)
1.4、什么是 Hive
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为 MapReduce 任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单 的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
(以上介绍来自百度百科)
1.5、什么是 Spark?
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类 Hadoop MapReduce 的通用并行框架,Spark 拥有Hadoop MapReduce 所具有的优点;但不同于 MapReduce 的是——Job中间输出结果可以保存在内存中,从而不再需要读写 HDFS ,因此 Spark 能更好地适用于数据挖掘与机器学习等需要迭代的 MapReduce 的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
(以上介绍来自百度百科)
2、环境准备
本文中的案例会有4台机器,他们的 Host 和 IP 地址如下

四台机器的 host 以 c0 为例:
[root@c0 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.100 c0
10.0.0.101 c1
10.0.0.102 c2
10.0.0.103 c3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.1、网络配置
以下以 c0 为例
[root@c0 ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth33 TYPE=Ethernet BOOTPROTO=static DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_PEERDNS=yes IPV6_PEERROUTES=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=fa3a4df3-e833-410a-9c95-94e3ee645d12 DEVICE=ens33 ONBOOT=yes IPADDR=192.168.133.20 PREFIXO=24 NTSMASK=255.255.0.0 GATEWAY=192.168.133.2 DNS1=114.114.114.114 DNS2=8.8.8.8

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
重启网络:
[root@c0 ~]# service network restart
- 1
更改源为阿里云
[root@c0 ~]# yum install -y wget
[root@c0 ~]# cd /etc/yum.repos.d/
[root@c0 yum.repos.d]# mv CentOS-Base.repo CentOS-Base.repo.bak
[root@c0 yum.repos.d]# wget http://mirrors.aliyun.com/repo/Centos-7.repo
[root@c0 yum.repos.d]# wget http://mirrors.163.com/.help/CentOS7-Base-163.repo
[root@c0 yum.repos.d]# yum clean all
[root@c0 yum.repos.d]# yum makecache
- 1
- 2
- 3
- 4
- 5
- 6
- 7
安装网络工具包和基础工具包
[root@c0 ~]# yum install net-tools checkpolicy gcc dkms foomatic openssh-server bash-completion psmisc -y
- 1
2.2、更改 HOSTNAME
在四台机器上依次设置 hostname,以下以c0为例
[root@c0 ~]# hostnamectl --static set-hostname c0
[root@c0 ~]# hostnamectl status
Static hostname: c0
Icon name: computer-vm
Chassis: vm
Machine ID: 04c3f6d56e788345859875d9f49bd4bd
Boot ID: ba02919abe4245aba673aaf5f778ad10
Virtualization: kvm
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-957.el7.x86_64
Architecture: x86-64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.3、配置 SSH 免密码登录登录
每一台机器都单独生成
[root@c0 ~]# ssh-keygen
#一路按回车到最后
- 1
- 2
将 ssh-keygen 生成的密钥,分别复制到其他三台机器,以下以 c0 为例
[root@c0 ~]# ssh-copy-id c0 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'c0 (10.0.0.100)' can't be established. ECDSA key fingerprint is SHA256:O8y8TBSZfBYiHPvJPPuAd058zkfsOfnBjvnf/3cvOCQ. ECDSA key fingerprint is MD5:da:3c:29:65:f2:86:e9:61:cb:39:57:5b:5e:e2:77:7c. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@c0's password: [root@c0 ~]# rm -rf ~/.ssh/known_hosts [root@c0 ~]# clear [root@c0 ~]# ssh-copy-id c0 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'c0 (10.0.0.100)' can't be established. ECDSA key fingerprint is SHA256:O8y8TBSZfBYiHPvJPPuAd058zkfsOfnBjvnf/3cvOCQ. ECDSA key fingerprint is MD5:da:3c:29:65:f2:86:e9:61:cb:39:57:5b:5e:e2:77:7c. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@c0's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'c0'" and check to make sure that only the key(s) you wanted were added. [root@c0 ~]# ssh-copy-id c1 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'c1 (10.0.0.101)' can't be established. ECDSA key fingerprint is SHA256:O8y8TBSZfBYiHPvJPPuAd058zkfsOfnBjvnf/3cvOCQ. ECDSA key fingerprint is MD5:da:3c:29:65:f2:86:e9:61:cb:39:57:5b:5e:e2:77:7c. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@c1's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'c1'" and check to make sure that only the key(s) you wanted were added. [root@c0 ~]# ssh-copy-id c2 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'c2 (10.0.0.102)' can't be established. ECDSA key fingerprint is SHA256:O8y8TBSZfBYiHPvJPPuAd058zkfsOfnBjvnf/3cvOCQ. ECDSA key fingerprint is MD5:da:3c:29:65:f2:86:e9:61:cb:39:57:5b:5e:e2:77:7c. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@c2's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'c2'" and check to make sure that only the key(s) you wanted were added. [root@c0 ~]# ssh-copy-id c3 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'c3 (10.0.0.103)' can't be established. ECDSA key fingerprint is SHA256:O8y8TBSZfBYiHPvJPPuAd058zkfsOfnBjvnf/3cvOCQ. ECDSA key fingerprint is MD5:da:3c:29:65:f2:86:e9:61:cb:39:57:5b:5e:e2:77:7c. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@c3's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'c3'" and check to make sure that only the key(s) you wanted were added.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
测试密钥是否配置成功,可以在任意机器上执行以下命令:
[root@c0 ~]# for N in $(seq 0 3); do ssh c$N hostname; done;
c0
c1
c2
c3
- 1
- 2
- 3
- 4
- 5
2.4、关闭防火墙
在每一台机器上运行以下命令:
# c0 [root@c0 ~]# systemctl stop firewalld && systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. # c1 [root@c1 ~]# systemctl stop firewalld && systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. # c2 [root@c2 ~]# systemctl stop firewalld && systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. # c3 [root@c3 ~]# systemctl stop firewalld && systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.7、安装 NTP
安装 NTP 时间同步工具,并启动 NTP
[root@c0 ~]# for N in $(seq 0 3); do ssh c$N yum install ntp -y; done;
- 1
在每一台机器上,设置 NTP 开机启动
# c0
[root@c0 ~]# systemctl enable ntpd && systemctl start ntpd
# c1
[root@c1 ~]# systemctl enable ntpd && systemctl start ntpd
# c2
[root@c2 ~]# systemctl enable ntpd && systemctl start ntpd
# c3
[root@c3 ~]# systemctl enable ntpd && systemctl start ntpd
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
依次查看每台机器上的时间:
[root@c0 ~]# for N in $(seq 0 3); do ssh c$N date; done;
Sat Feb 9 18:11:48 CST 2019
Sat Feb 9 18:11:48 CST 2019
Sat Feb 9 18:11:49 CST 2019
Sat Feb 9 18:11:49 CST 2019
- 1
- 2
- 3
- 4
- 5
如果时间不一致,国内的同学也可以使用下面的命令,同步阿里云时间服务器的时间,然后再用上面的命令,查看所有服务器的最新时间。
[root@c0 ~]# for N in $(seq 0 3); do ssh c$N ntpdate -u time.pool.aliyun.com; done;
10 Mar 18:34:23 ntpdate[7151]: adjust time server 182.92.12.11 offset 0.001423 sec
10 Mar 18:34:31 ntpdate[17459]: adjust time server 182.92.12.11 offset 0.003916 sec
10 Mar 18:34:40 ntpdate[17147]: adjust time server 182.92.12.11 offset 0.008576 sec
10 Mar 18:34:48 ntpdate[17423]: adjust time server 182.92.12.11 offset -0.004648 sec
- 1
- 2
- 3
- 4
- 5
- 下载应用程序及配置环境变量
3.1、创建安装目录
创建要用到的目录结构,所有的程序都统一在/home/work/_app 目录,所有下载的源码在 /home/work/_src目录 ,所有的数据在 /home/work/_data 目录,所有的日志在 /home/work/_logs 目录。
# 创建 Hadoop3.1.2 和 Zookeeper3.4.13 需要的目录 [root@c0 ~]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/{_src,_app,_logs,_data} -p; done; [root@c0 ~]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/_data/{hadoop-3.1.2,zookeeper-3.4.13} -p; done; [root@c0 ~]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/_logs/{hadoop-3.1.2,zookeeper-3.4.13} -p; done; ## 在 Hadoop3.1.2 的 NameNode 上创建 HA 共享目录 [root@c0 ~]# for N in $(seq 0 1); do ssh c$N mkdir /home/work/_data/hadoop-3.1.2/{journalnode,ha-name-dir-shared} -p; done; # 创建 Hbase1.4.9 需要的目录 [root@c0 ~]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/_logs/hbase-1.4.9 -p; done; [root@c0 ~]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/_data/hbase-1.4.9 -p; done; # 创建 Hive2.3.4 需要的目录 [root@c0 _src]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/_data/hive-2.3.4/{scratchdir,tmpdir} -p; done; [root@c0 _src]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/_logs/hive-2.3.4 -p; done; # 创建 Spark2.4.0 需要的目录 [root@c0 _src]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/_data/spark-2.4.0-bin-hadoop2.7 -p; done; [root@c0 _src]# for N in $(seq 0 3); do ssh c$N mkdir /home/work/_logs/spark-2.4.0-bin-hadoop2.7 -p; done;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.2、下载本文中用到的程序
安装 alex 多线程下载工具,可以提高下载速度
[root@c0 ~]# cd /home/work/_src/
[root@c0 _src]# wget https://download-ib01.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-7-11.noarch.rpm
[root@c0 _src]# rpm -Uvh epel-release*rpm
[root@c0 _src]# yum install axel -y
- 1
- 2
- 3
- 4
本文中用到的软件都是编译好的,所以不需要安装,解压以后,mv 到相应的目录,可以直接运行命令启动。
Hadoop3.1.2:
[root@c0 _src]# axel -n 10 -o /home/work/_src/hadoop-3.1.2.tar.gz http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
[root@c0 _src]# tar -xzvf hadoop-3.1.2.tar.gz
[root@c0 _src]# mv hadoop-3.1.2 /home/work/_app/
- 1
- 2
- 3
Zookeeper3.4.13:
[root@c0 _src]# axel -n 10 -o /home/work/_src/zookeeper-3.4.13.tar.gz http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
[root@c0 _src]# tar -xzvf zookeeper-3.4.13.tar.gz
[root@c0 _src]# mv zookeeper-3.4.13 /home/work/_app/
- 1
- 2
- 3
Hbase1.4.9:
[root@c0 _src]# axel -n 10 -o /home/work/_src/hbase-1.4.9-bin.tar.gz http://archive.apache.org/dist/hbase/stable/hbase-1.4.9-bin.tar.gz
[root@c0 _src]# tar -xzvf hbase-1.4.9-bin.tar.gz
[root@c0 _src]# mv hbase-1.4.9 /home/work/_app/
- 1
- 2
- 3
Hive2.3.4:
[root@c0 _src]# axel -n 10 -o /home/work/_src/hive-2.3.4-bin.tar.gz http://mirrors.hust.edu.cn/apache/hive/hive-2.3.4/apache-hive-2.3.4-bin.tar.gz
[root@c0 _src]# tar -xzvf hive-2.3.4-bin.tar.gz
[root@c0 _src]# mv apache-hive-2.3.4-bin /home/work/_app/hive-2.3.4
- 1
- 2
- 3
Scala-sbt2.12.8:
[root@c0 _src]# axel -n 10 -o /home/work/_src/scala-2.12.8.tgz https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz
[root@c0 _src]# tar -xzvf scala-2.12.8.tgz
[root@c0 _src]# mv scala-2.12.8 /home/work/_app/scala-2.12.8
- 1
- 2
- 3
Spark2.4.0:
[root@c0 _src]# axel -n 10 -o /home/work/_src/spark-2.4.0-bin-hadoop2.7.tgz https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
[root@c0 _src]# tar -xzvf spark-2.4.0-bin-hadoop2.7.tgz
[root@c0 _src]# mv spark-2.4.0-bin-hadoop2.7 /home/work/_app/spark-2.4.0-bin-hadoop2.7
- 1
- 2
- 3
3.3、设置环境变量
在每一台机器上设置环境变量,运行以下命令
# Hadoop 3.1.2 echo "export HADOOP_HOME=/home/work/_app/hadoop-3.1.2" >> /etc/bashrc echo "export HADOOP_LOG_DIR=/home/work/_logs/hadoop-3.1.2" >> /etc/bashrc echo "export HADOOP_MAPRED_HOME=\$HADOOP_HOME" >> /etc/bashrc echo "export HADOOP_COMMON_HOME=\$HADOOP_HOME" >> /etc/bashrc echo "export HADOOP_HDFS_HOME=\$HADOOP_HOME" >> /etc/bashrc echo "export HADOOP_CONF_DIR=\$HADOOP_HOME/etc/hadoop" >> /etc/bashrc # Zookeeper 3.4.13 echo "export ZOOKEEPER_HOME=/home/work/_app/zookeeper-3.4.13" >> /etc/bashrc # JAVA echo "export JAVA_HOME=/opt/jdk1.8.0_201" >> /etc/bashrc echo "export JRE_HOME=/opt/jdk1.8.0_201/jre" >> /etc/bashrc # HBase 1.4.9 echo "export HBASE_HOME=/home/work/_app/hbase-1.4.9" >> /etc/bashrc # Hive 2.3.4 echo "export HIVE_HOME=/home/work/_app/hive-2.3.4" >> /etc/bashrc echo "export HIVE_CONF_DIR=\$HIVE_HOME/conf" >> /etc/bashrc # Scala 2.12.8 echo "export SCALA_HOME=/home/work/_app/scala-2.12.8" >> /etc/bashrc # Spark 2.4 echo "export SPARK_HOME=/home/work/_app/spark-2.4.0-bin-hadoop2.7" >> /etc/bashrc # Path echo "export PATH=\$PATH:\$JAVA_HOME/bin:\$JRE_HOME/bin:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$ZOOKEEPER_HOME/bin:\$HBASE_HOME/bin:\$HIVE_HOME/bin:\$SCALA_HOME/bin:\$SPARK_HOME/bin:\$SPARK_HOME/sbin" >> /etc/bashrc source /etc/bashrc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 安装 Oracle JDK 1.8.0
4.1 下载 Oracle JDK 1.8.0
以下操作在每一台机器上都要安装
cd /home/work/_src
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "https://download.oracle.com/otn-pub/java/jdk/8u201-b09/42970487e3af4f5aa5bca3f542482c60/jdk-8u201-linux-x64.tar.gz"
tar -xzvf jdk-8u201-linux-x64.tar.gz
mv jdk1.8.0_201 /opt/
- 1
- 2
- 3
- 4
4.2、配置 Oracle JDK 1.8.0
alternatives 命令用于维护符号链接。此命令用于创建、删除、维护和显示有关包含备选系统的符号链接的信息。
接下来让我们使用 alternatives 命令在您的系统上配置 Java。
alternatives --install /usr/bin/java java /opt/jdk1.8.0_201/bin/java 2
alternatives --config java
- 1
- 2
新安装的 Java 版本列在第1位,因此输入1并按 Enter 键
There is 1 program that provides 'java'.
Selection Command
-----------------------------------------------
*+ 1 /opt/jdk1.8.0_201/bin/java
Enter to keep the current selection[+], or type selection number: 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
JAVA 8已成功安装在您的系统上。我们还建议使用替代方法设置javac 和 jar 命令路径
alternatives --install /usr/bin/jar jar /opt/jdk1.8.0_201/bin/jar 2
alternatives --install /usr/bin/jar jar /opt/jdk1.8.0_201/bin/jar 2
alternatives --set jar /opt/jdk1.8.0_201/bin/jar
alternatives --set javac /opt/jdk1.8.0_201/bin/javac
- 1
- 2
- 3
- 4
java 和 javac 二进制文件在 PATH 环境变量下可用。您可以在系统中的任何位置使用它们。
让我们通过执行以下命令检查系统上安装的 Java 运行时环境(JRE)版本。
[root@c0 _src]# java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
- 1
- 2
- 3
- 4
5、安装 Zookeeper3.4.13
5.1、修改配置文件 zoo.cfg
创建 /home/work/_app/zookeeper-3.4.13/conf/zoo.cfg 文件编辑并保存,内容如下:
[root@c0 ~]# cat /home/work/_app/zookeeper-3.4.13/conf/zoo.cfg # ZooKeeper使用的基本时间单位(以毫秒为单位)。它用于做心跳,最小会话超时将是tickTime的两倍。 tickTime=200 # 存储内存数据库快照的位置,除非另有说明,否则指向数据库更新的事务日志。 dataDir=/home/work/_data/zookeeper-3.4.13 # 用于事务日志的不同目录。 dataLogDir=/home/work/_logs/zookeeper-3.4.13 # 侦听客户端连接的端口 clientPort=2181 # 表示在leader选举结束后,followers与leader同步需要的时间,如果followers比较多或者说leader的数据灰常多时,同步时间相应可能会增加,那么这个值也需要相应增加。当然,这个值也是follower和observer在开始同步leader的数据时的最大等待时间(setSoTimeout) initLimit=5 # 表示follower和observer与leader交互时的最大等待时间,只不过是在与leader同步完毕之后,进入正常请求转发或ping等消息交互时的超时时间。 syncLimit=2 # server.serverid=host:tickpot:electionport # server:固定写法 # serverid:每个服务器的指定ID(必须处于1-255之间,必须每一台机器不能重复) # host:主机名 # tickpot:心跳通信端口 # electionport:选举端口 server.1=c0:2888:3888 server.2=c1:2888:3888 server.3=c2:2888:3888 server.4=c3:2888:3888
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
将 zookeeper 复制到其他机器上
[root@c0 _src]# for N in $(seq 1 3); do scp -r /home/work/_app/zookeeper-3.4.13 c$N:/home/work/_app/; done;
- 1
5.2、为每台服务器创建身份标识
通过创建名为 myid 的文件将每台服务器标识身份,每个服务器对应一个文件,用于服务器快速选举,该文件位于配置文件 /home/work/_app/zookeeper-3.4.13/conf/zoo.cfg 中的 dataDir 配置项中。
接下来,我们在配置文件 /home/work/_app/zookeeper-3.4.13/conf/zoo.cfg 中配置的 dataDir 目录,创建 myid 文件,内容为 server. 后面的数字,记住只能是数字:
# c0
[root@c0 ~]# echo 1 > /home/work/_data/zookeeper-3.4.13/myid
# c1
[root@c1 ~]# echo 2 > /home/work/_data/zookeeper-3.4.13/myid
# c2
[root@c2 ~]# echo 3 > /home/work/_data/zookeeper-3.4.13/myid
# c3
[root@c3 ~]# echo 4 > /home/work/_data/zookeeper-3.4.13/myid
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5.3、在所有节点中启动 zookeeper
在典型部署中,ZooKeeper 守护程序配置为在三个或五个节点上运行。由于 ZooKeeper 本身具有轻量级资源要求,因此可以在与 HDFS NameNode 和备用节点相同的硬件上配置 ZooKeeper 节点。
许多运营商选择在与 YARN ResourceManager 相同的节点上部署第三个 ZooKeeper 进程。建议将ZooKeeper 节点配置为将数据存储在与 HDFS 元数据不同的磁盘驱动器上,以获得最佳性能和隔离。
接下来我们在所有机器上运行 zkServer.sh start 命令启动服务,然后输入 JPS 命令,在所有节点中,您将看到 QuorumPeerMain 服务。
[root@c0 ~]# for N in $(seq 0 3); do ssh c$N zkServer.sh start; done; ZooKeeper JMX enabled by default Using config: /home/work/_app/zookeeper-3.4.13/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ZooKeeper JMX enabled by default Using config: /home/work/_app/zookeeper-3.4.13/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ZooKeeper JMX enabled by default Using config: /home/work/_app/zookeeper-3.4.13/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ZooKeeper JMX enabled by default Using config: /home/work/_app/zookeeper-3.4.13/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@c0 ~]# for N in $(seq 0 3); do ssh c$N jps; done; 14020 Jps 13980 QuorumPeerMain 13922 QuorumPeerMain 13957 Jps 13681 Jps 13639 QuorumPeerMain 4541 QuorumPeerMain 4575 Jps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Zookeeper 的停止命令为:zkServer.sh stop
5.4、查看zookeeper 运行状态
通过 zkServer.sh status 命令,可以看到在 c2 上是 leader,其他机器是 follower
# c0 [root@c0 ~]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/work/_app/zookeeper-3.4.13/bin/../conf/zoo.cfg Mode: follower # c1 [root@c1 ~]# /home/work/_app/zookeeper-3.4.13/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/work/_app/zookeeper-3.4.13/bin/../conf/zoo.cfg Mode: follower # c2 [root@c2 ~]# /home/work/_app/zookeeper-3.4.13/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/work/_app/zookeeper-3.4.13/bin/../conf/zoo.cfg Mode: leader # c3 [root@c3 ~]# /home/work/_app/zookeeper-3.4.13/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/work/_app/zookeeper-3.4.13/bin/../conf/zoo.cfg Error contacting service. It is probably not running.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
5.5、测试 Zookeeper 是否启动成功
使用ZK CLI进行连接来验证,是否安装成功
[root@c0 ~]# zkCli.sh Connecting to localhost:2181 2019-02-12 01:25:21,986 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 04:05 GMT 2019-02-12 01:25:21,991 [myid:] - INFO [main:Environment@100] - Client environment:host.name=c0 2019-02-12 01:25:21,991 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_201 2019-02-12 01:25:21,994 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation 2019-02-12 01:25:21,994 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/opt/jdk1.8.0_201/jre 2019-02-12 01:25:21,994 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/home/work/_app/zookeeper-3.4.13/bin/../build/classes:/home/work/_app/zookeeper-3.4.13/bin/../build/lib/*.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/slf4j-log4j12-1.7.25.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/slf4j-api-1.7.25.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/netty-3.10.6.Final.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/log4j-1.2.17.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/jline-0.9.94.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/audience-annotations-0.5.0.jar:/home/work/_app/zookeeper-3.4.13/bin/../zookeeper-3.4.13.jar:/home/work/_app/zookeeper-3.4.13/bin/../src/java/lib/*.jar:/home/work/_app/zookeeper-3.4.13/bin/../conf: 2019-02-12 01:25:21,994 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 2019-02-12 01:25:21,994 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp 2019-02-12 01:25:21,994 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA> 2019-02-12 01:25:21,994 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux 2019-02-12 01:25:21,994 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64 2019-02-12 01:25:21,995 [myid:] - INFO [main:Environment@100] - Client environment:os.version=4.20.7-1.el7.elrepo.x86_64 2019-02-12 01:25:21,995 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root 2019-02-12 01:25:21,995 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root 2019-02-12 01:25:21,995 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/root 2019-02-12 01:25:21,996 [myid:] - INFO [main:ZooKeeper@442] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@5ce65a89 Welcome to ZooKeeper! 2019-02-12 01:25:22,024 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1029] - Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (unknown error) JLine support is enabled 2019-02-12 01:25:22,089 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@879] - Socket connection established to localhost/0:0:0:0:0:0:0:1:2181, initiating session 2019-02-12 01:25:22,103 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1303] - Session establishment complete on server localhost/0:0:0:0:0:0:0:1:2181, sessionid = 0x100008909040002, negotiated timeout = 30000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: localhost:2181(CONNECTED) 0] ls / [zookeeper] [zk: localhost:2181(CONNECTED) 1] quit Quitting... 2019-02-12 01:25:24,897 [myid:] - INFO [main:ZooKeeper@693] - Session: 0x100008909040002 closed 2019-02-12 01:25:24,899 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@522] - EventThread shut down for session: 0x100008909040002
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
6、安装 Hadoop3.1.2
6.1、修改 Hadoop 配置文件
6.1.1、修改配置文件 core-site.xml
编译 /home/work/_app/hadoop-3.1.2/etc/hadoop/core-site.xml 文件,内容如下:
[root@c0 ~]# cat /home/work/_app/hadoop-3.1.2/etc/hadoop/core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mshkcluster</value> <description>默认文件系统的名称。一个URI,其方案和权限决定了FileSystem的实现。</description> </property> <property> <name>ha.zookeeper.quorum</name> <value>c0:2181,c1:2181,c2:2181,c3:2181</value> <description>由逗号分隔的ZooKeeper服务器地址列表,由ZKFailoverController在自动故障转移中使用。</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/work/_data/hadoop-3.1.2</value> <description>数据目录目录</description> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> <description>用于服务防护的防护方法列表。可能包含内置方法(例如shell和sshfence)或用户定义的方法。</description> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> <description>用于内置sshfence fencer的SSH私钥文件。</description> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> <description>SequenceFiles中使用的读/写缓冲区的大小。</description> </property> <property> <name>ipc.client.connect.max.retries</name> <value>100</value> <description>客户端为建立服务器连接而重试的次数。</description> </property> <property> <name>ipc.client.connect.retry.interval</name> <value>10000</value> <description>客户端在重试建立服务器连接之前将等待的毫秒数。</description> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
6.1.2、修改配置文件 hdfs-site.xml
编辑 /home/work/_app/hadoop-3.1.2/etc/hadoop/hdfs-site.xml 文件并保存,内容如下:
[root@c0 ~]# cat /home/work/_app/hadoop-3.1.2/etc/hadoop/hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.nameservices</name> <value>mshkcluster</value> </property> <property> <name>dfs.ha.namenodes.mshkcluster</name> <value>c0,c1</value> <description>给定名称服务的前缀包含给定名称服务的逗号分隔的名称节点列表。</description> </property> <property> <name>dfs.namenode.rpc-address.mshkcluster.c0</name> <value>c0:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mshkcluster.c1</name> <value>c1:8020</value> </property> <property> <name>dfs.namenode.http-address.mshkcluster.c0</name> <value>c0:50070</value> </property> <property> <name>dfs.namenode.http-address.mshkcluster.c1</name> <value>c1:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://c0:8485;c1:8485/mshkcluster</value> <description>HA群集中多个名称节点之间的共享存储上的目录。此目录将由活动写入并由备用数据库读取,以保持命名空间同步。</description> </property> <property> <name>dfs.client.failover.proxy.provider.mshkcluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> <description>配置Java类的名称,DFS客户端将使用该名称来确定哪个NameNode是当前的Active,以及哪个NameNode当前正在为客户端请求提供服务。</description> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> <description>是否启用自动故障转移。</description> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> <description>如果为“true”,则启用HDFS中的权限检查。如果为“false”,则关闭权限检查,但所有其他行为都保持不变。</description> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>${hadoop.tmp.dir}/journalnode</value> <description>指定JournalNode在本地磁盘存放数据的位置</description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/namenode</value> <description>设置namenode存放路径</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/datanode</value> <description>设置datanode存放径路</description> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> <description>大型文件系统的HDFS块大小为256MB。</description> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> <description>namenode的服务器线程数</description> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
6.1.3、修改配置文件 mapred-site.xml
编辑 /home/work/_app/hadoop-3.1.2/etc/hadoop/mapred-site.xml 文件并保存,内容如下:
[root@c0 _src]# cat /home/work/_app/hadoop-3.1.2/etc/hadoop/mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>指定mr框架为yarn方式</description> </property> <property> <name>mapreduce.map.memory.mb</name> <value>512</value> <description>每个Map任务的物理内存限制</description> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>512</value> <description>每个Reduce任务的物理内存限制</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>0.0.0.0:10020</value> <description>MapReduce JobHistory服务器IPC主机:端口</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>0.0.0.0:19888</value> <description>MapReduce JobHistory服务器Web浏览时的主机:端口</description> </property> <property> <name>mapreduce.application.classpath</name> <value> /home/work/_app/hadoop-3.1.2/etc/hadoop, /home/work/_app/hadoop-3.1.2/share/hadoop/common/*, /home/work/_app/hadoop-3.1.2/share/hadoop/common/lib/*, /home/work/_app/hadoop-3.1.2/share/hadoop/hdfs/*, /home/work/_app/hadoop-3.1.2/share/hadoop/hdfs/lib/*, /home/work/_app/hadoop-3.1.2/share/hadoop/mapreduce/*, /home/work/_app/hadoop-3.1.2/share/hadoop/mapreduce/lib/*, /home/work/_app/hadoop-3.1.2/share/hadoop/yarn/*, /home/work/_app/hadoop-3.1.2/share/hadoop/yarn/lib/* </value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
6.1.4、修改配置文件 capacity-scheduler.xml
capacity-scheduler.xml主要对 hadoop 的队列进行管理,在这里我们分test、dev、prod三个队列。
编辑 /home/work/_app/hadoop-3.1.2/etc/hadoop/capacity-scheduler.xml 文件并保存,内容如下:
<!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.scheduler.capacity.maximum-applications</name> <value>10000</value> <description> 系统中可以同时处于运行和挂起状态的最大应用程序数。 </description> </property> <property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>0.5</value> <description> 群集中可用于运行应用程序主机的最大资源百分比 - 控制并发活动应用程序的数量。 每个队列的限制与其队列容量和用户限制成正比。 </description> </property> <property> <name>yarn.scheduler.capacity.resource-calculator</name> <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> <description> The ResourceCalculator implementation to be used to compare Resources in the scheduler. The default i.e. DefaultResourceCalculator only uses Memory while DominantResourceCalculator uses dominant-resource to compare multi-dimensional resources such as Memory, CPU etc. </description> </property> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>dev,test,prod</value> <description> CapacityScheduler有一个名为root的预定义队列。系统中的所有队列都是根队列的子节点。可以通过使用逗号分隔的子队列列表配置yarn.scheduler.capacity.root.queues来设置更多队列。 </description> </property> <property> <name>yarn.scheduler.capacity.root.test.capacity</name> <value>10</value> <description>每个级别的所有队列的容量总和必须等于100.如果有空闲资源,则队列中的应用程序可能比队列容量消耗更多资源,从而提供弹性。.</description> </property> <property> <name>yarn.scheduler.capacity.root.test.user-limit-factor</name> <value>1</value> <description> 队列容量的倍数,可配置为允许单个用户获取更多资源。默认情况下,此值设置为1可确保单个用户永远不会超过队列配置的容量,无论群集的空闲程度如何。 </description> </property> <property> <name>yarn.scheduler.capacity.root.test.maximum-capacity</name> <value>20</value> <description> 最大队列容量,以百分比(%)表示为浮点数。这限制了队列中应用程序的弹性。默认为-1,禁用它。 </description> </property> <property> <name>yarn.scheduler.capacity.root.prod.capacity</name> <value>60</value> <description>每个级别的所有队列的容量总和必须等于100.如果有空闲资源,则队列中的应用程序可能比队列容量消耗更多资源,从而提供弹性。.</description> </property> <property> <name>yarn.scheduler.capacity.root.prod.user-limit-factor</name> <value>1</value> <description> 队列容量的倍数,可配置为允许单个用户获取更多资源。默认情况下,此值设置为1可确保单个用户永远不会超过队列配置的容量,无论群集的空闲程度如何。 </description> </property> <property> <name>yarn.scheduler.capacity.root.prod.maximum-capacity</name> <value>70</value> <description> 最大队列容量,以百分比(%)表示为浮点数。这限制了队列中应用程序的弹性。默认为-1,禁用它。 </description> </property> <property> <name>yarn.scheduler.capacity.root.prod.state</name> <value>RUNNING</value> <description> 队列的状态。可以是RUNNING或STOPPED之一。如果队列处于STOPPED状态,则无法将新应用程序提交给自身或其任何子队列。因此,如果根队列是STOPPED,则不能将任何应用程序提交给整个群集。 </description> </property> <property> <name>yarn.scheduler.capacity.root.dev.capacity</name> <value>30</value> <description>每个级别的所有队列的容量总和必须等于100.如果有空闲资源,则队列中的应用程序可能比队列容量消耗更多资源,从而提供弹性。.</description> </property> <property> <name>yarn.scheduler.capacity.root.dev.user-limit-factor</name> <value>1</value> <description> 队列容量的倍数,可配置为允许单个用户获取更多资源。默认情况下,此值设置为1可确保单个用户永远不会超过队列配置的容量,无论群集的空闲程度如何。 </description> </property> <property> <name>yarn.scheduler.capacity.root.dev.maximum-capacity</name> <value>40</value> <description> 最大队列容量,以百分比(%)表示为浮点数。这限制了队列中应用程序的弹性。默认为-1,禁用它。 </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_submit_applications</name> <value>*</value> <description> The ACL of who can submit jobs to the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_administer_queue</name> <value>*</value> <description> The ACL of who can administer jobs on the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name> <value>*</value> <description> The ACL of who can submit applications with configured priority. For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}] </description> </property> <property> <name>yarn.scheduler.capacity.root.default.maximum-application-lifetime </name> <value>-1</value> <description> 在几秒钟内提交到队列的应用程序的最长生命周期。任何小于或等于零的值都将被视为已禁用。对于此队列中的所有应用程序,这将是一个艰难的时间限制。如果配置了正值,那么提交到此队列的任何应用程序将在超过配置的生存期后被终止。用户还可以在应用程序提交上下文中指定每个应用程.但如果超过队列最长生命周期,则会覆盖用户生命周期。 </description> </property> <property> <name>yarn.scheduler.capacity.root.default.default-application-lifetime </name> <value>-1</value> <description> 在几秒钟内提交到队列的应用程序的默认生存期。任何小于或等于零的值都将被视为已禁用。如果用户尚未提交具有生命周期值的应用程序,则将采用此值。 </description> </property> <property> <name>yarn.scheduler.capacity.node-locality-delay</name> <value>40</value> <description> Number of missed scheduling opportunities after which the CapacityScheduler attempts to schedule rack-local containers. When setting this parameter, the size of the cluster should be taken into account. We use 40 as the default value, which is approximately the number of nodes in one rack. Note, if this value is -1, the locality constraint in the container request will be ignored, which disables the delay scheduling. </description> </property> <property> <name>yarn.scheduler.capacity.rack-locality-additional-delay</name> <value>-1</value> <description> Number of additional missed scheduling opportunities over the node-locality-delay ones, after which the CapacityScheduler attempts to schedule off-switch containers, instead of rack-local ones. Example: with node-locality-delay=40 and rack-locality-delay=20, the scheduler will attempt rack-local assignments after 40 missed opportunities, and off-switch assignments after 40+20=60 missed opportunities. When setting this parameter, the size of the cluster should be taken into account. We use -1 as the default value, which disables this feature. In this case, the number of missed opportunities for assigning off-switch containers is calculated based on the number of containers and unique locations specified in the resource request, as well as the size of the cluster. </description> </property> <property> <name>yarn.scheduler.capacity.queue-mappings</name> <value></value> <description> A list of mappings that will be used to assign jobs to queues The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]* Typically this list will be used to map users to queues, for example, u:%user:%user maps all users to queues with the same name as the user. </description> </property> <property> <name>yarn.scheduler.capacity.queue-mappings-override.enable</name> <value>false</value> <description> If a queue mapping is present, will it override the value specified by the user? This can be used by administrators to place jobs in queues that are different than the one specified by the user. The default is false. </description> </property> <property> <name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name> <value>1</value> <description> Controls the number of OFF_SWITCH assignments allowed during a node's heartbeat. Increasing this value can improve scheduling rate for OFF_SWITCH containers. Lower values reduce "clumping" of applications on particular nodes. The default is 1. Legal values are 1-MAX_INT. This config is refreshable. </description> </property> <property> <name>yarn.scheduler.capacity.application.fail-fast</name> <value>false</value> <description> Whether RM should fail during recovery if previous applications' queue is no longer valid. </description> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
6.1.5、修改配置文件 yarn-site.xml
编辑 /home/work/_app/hadoop-3.1.2/etc/hadoop/yarn-site.xml 文件并保存,内容如下:
[root@c0 sbin]# cat /home/work/_app/hadoop-3.1.2/etc/hadoop/yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> <description>启动后启用RM以恢复状态。如果为true,则必须指定yarn.resourcemanager.store.class。</description> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> <description>用作持久存储的类。</description> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>c0:2181,c1:2181</value> <description>ZooKeeper服务的地址,多个地址使用逗号隔开</description> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> <description>启用RM高可用性。启用时,(1)默认情况下,RM以待机模式启动,并在提示时转换为活动模式。(2)RM集合中的节点列在yarn.resourcemanager.ha.rm-ids中(3)如果明确指定了yarn.resourcemanager.ha.id,则每个RM的id来自yarn.resourcemanager.ha.id或者可以通过匹配yarn.resourcemanager.address。</description> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> <description>启用HA时群集中的RM节点列表。最少2个</description> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>c0:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>c1:8088</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>mshk-yarn-ha</value> <description>集群HA的id,用于在ZooKeeper上创建节点,区分使用同一个ZooKeeper集群的不同Hadoop集群</description> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>c0</value> <description>主机名</description> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>c1</value> <description>主机名</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>reducer取数据的方式是mapreduce_shuffle</description> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> <discription>每个节点可用内存,单位MB</discription> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value> <discription>每个节点可用cpu</discription> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> <discription>单个任务可申请最少内存,默认1024MB</discription> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>1024</value> <discription>单个任务可申请最大内存,默认8192MB</discription> </property> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> <discription>最小的cores 1 个,默认的就是一个</discription> </property> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>2</value> <discription>最多可分配的cores 2 个</discription> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <discription>是否开启聚合日志</discription> </property> <property> <name>yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds</name> <value>-1</value> <discription>定义NM唤醒上载日志文件的频率。默认值为-1。默认情况下,应用程序完成后将上载日志。通过设置此配置,可以在应用程序运行时定期上载日志。可设置的最小滚动间隔秒数为3600。</discription> </property> <property> <name>yarn.log.server.url</name> <value>http://c0:19888/jobhistory/logs</value> <discription> 配置日志服务器的地址</discription> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>-1</value> <discription> 在删除聚合日志之前保留多长时间。-1禁用。单位是秒</discription> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/home/work/_data/hadoop-3.1.2/yarn/container-logs/</value> <discription>nodemanager存放container日志的本地路径</discription> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/tmp/logs</value> <discription>nodemanager存放container日志的本地路径</discription> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
6.1.6、编辑 start-dfs.sh,stop-dfs.sh 脚本
编辑 /home/work/_app/hadoop-3.1.2/sbin/start-dfs.sh 和 /home/work/_app/hadoop-3.1.2/sbin/stop-dfs.sh文件,在开始处 #!/usr/bin/env bash 的下面,增加以下内容:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_ZKFC_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 1
- 2
- 3
- 4
- 5
- 6
6.1.7、编辑 start-yarn.sh,stop-yarn.sh 脚本
编辑 /home/work/_app/hadoop-3.1.2/sbin/start-yarn.sh 和 /home/work/_app/hadoop-3.1.2/sbin/stop-yarn.sh文件,在开始处 #!/usr/bin/env bash 的下面增加以下内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 1
- 2
- 3
6.1.8、修改配置文件 works 文件
设置主从配置,如果不设置,集群将不知道主从配置。编辑 /home/work/_app/hadoop-3.1.2/etc/hadoop/workers 文件并保存,内容如下:
[root@c0 _src]# cat /home/work/_app/hadoop-3.1.2/etc/hadoop/workers
c2
c3
- 1
- 2
- 3
6.2、启动 Hadoop
6.2.1、启动JournalNode集群
在启动前,我们先将配置好的 hadoop 复制到其他机器
[root@c0 ~]# for N in $(seq 1 3); do scp -r /home/work/_app/hadoop-3.1.2 c$N:/home/work/_app/; done;
- 1
- 2
备用 NameNode 和活动 NameNode 通过一组独立的节点或守护进程(称为JournalNode)保持同步。JournalNodes 遵循环形拓扑,其中节点彼此连接以形成环。JournalNode 服务于它的请求并将信息复制到环中的其他节点。这在 JournalNode 失败的情况下提供容错。
在所有机器上使用 hdfs --daemon start journalnode 命令来启动Journalnode。输入 JPS 命令后,您将在所有节点中看到 JournalNode 守护程序。
[root@c0 ~]# for N in $(seq 0 3); do ssh c$N hdfs --daemon start journalnode;jps; done;
14450 JournalNode
13980 QuorumPeerMain
14494 Jps
14450 JournalNode
13980 QuorumPeerMain
14510 Jps
14450 JournalNode
13980 QuorumPeerMain
14526 Jps
14450 JournalNode
13980 QuorumPeerMain
14542 Jps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
关闭命令为:hdfs --daemon stop journalnode
6.2.2、格式化 NameNode
一旦启动了 JournalNodes,就必须首先同步两个HA NameNodes的磁盘元数据。
在新版本的 HDFS 集群中,应首先在其中一个 NameNode 上运行 format 命令格式化。格式化一个 NameNode 有两种方法,任意方法都可以,本文中的示例,在 c0 上使用方法一
[root@c0 ~]# hdfs namenode -format 2019-03-10 19:09:01,704 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = c0/10.0.0.100 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.1.2 ... 2019-03-10 19:09:02,399 INFO util.GSet: VM type = 64-bit 2019-03-10 19:09:02,399 INFO util.GSet: 0.029999999329447746% max memory 546 MB = 167.7 KB 2019-03-10 19:09:02,399 INFO util.GSet: capacity = 2^14 = 16384 entries 2019-03-10 19:09:02,419 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1652020860-10.0.0.100-1552216142413 2019-03-10 19:09:02,432 INFO common.Storage: Storage directory /home/work/_data/hadoop-3.1.2/namenode has been successfully formatted. 2019-03-10 19:09:02,435 INFO common.Storage: Storage directory /home/work/_data/hadoop-3.1.2/ha-name-dir-shared has been successfully formatted. 2019-03-10 19:09:02,442 INFO namenode.FSImageFormatProtobuf: Saving image file /home/work/_data/hadoop-3.1.2/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2019-03-10 19:09:02,511 INFO namenode.FSImageFormatProtobuf: Image file /home/work/_data/hadoop-3.1.2/namenode/current/fsimage.ckpt_0000000000000000000 of size 391 bytes saved in 0 seconds . 2019-03-10 19:09:02,520 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2019-03-10 19:09:02,526 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at c0/10.0.0.100 ************************************************************/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
方法二:
hdfs namenode -format -clusterId c1
- 1
6.2.3、启动 zookeeper 故障转移控制器
Apache ZooKeeper 是一种高可用性服务,用于维护少量协调数据,通知客户端该数据的更改以及监视客户端是否存在故障。自动 HDFS 故障转移的实现依赖于 ZooKeeper 来实现以下功能:
故障检测 – 集群中的每个 NameNode 计算机都在 ZooKeeper 中维护一个持久会话。如果计算机崩溃,ZooKeeper 会话将过期,通知其他 NameNode 应该触发故障转移。
Active NameNode选举 – ZooKeeper 提供了一种简单的机制,可以将节点专门选为活动节点。如果当前活动的 NameNode 崩溃,则另一个节点可能在 ZooKeeper 中采用特殊的独占锁,指示它应该成为下一个活动的。
ZKFailoverController(ZKFC)是一个新组件,它是一个 ZooKeeper 客户端,它还监视和管理 NameNode 的状态。每台运行 NameNode 机器也运行 ZKFC,ZKFC 主要做以下工作:
运行状况监视 – ZKFC定期使用运行状况检查命令对其本地 NameNode 进行 ping 操作。只要 NameNode 及时响应健康状态,ZKFC 就认为该节点是健康的。如果节点已崩溃,冻结或以其他方式进入不健康状态,则运行状况监视器会将其标记为运行状况不佳。
ZooKeeper会话管理 – 当本地 NameNode 运行正常时,ZKFC 在 ZooKeeper 中保持会话打开。如果本地 NameNode 处于活动状态,它还拥有一个特殊的“锁定”znode。此锁使用 ZooKeeper 对“短暂”节点的支持; 如果会话过期,将自动删除锁定节点。
基于ZooKeeper的选举 – 如果本地 NameNode 是健康的,并且 ZKFC 发现没有其他节点当前持有锁 znode ,它将自己尝试获取锁。如果成功,那么它“赢得了选举”,并负责运行故障转移以使其本地 NameNode 处于活动状态。故障转移过程类似于上述手动故障转移:首先,必要时对先前的活动进行隔离,然后本地 NameNode 转换为活动状态。
6.2.4、格式化 zookeeper
在一台 NameNode 机器 c0 上执行 hdfs zkfc -formatZK 命令,格式化 zookeeper 故障转移控制器
[root@c0 ~]# hdfs zkfc -formatZK 2019-03-10 19:16:17,737 INFO tools.DFSZKFailoverController: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting DFSZKFailoverController STARTUP_MSG: host = c0/10.0.0.100 STARTUP_MSG: args = [-formatZK] STARTUP_MSG: version = 3.1.2 ... 2019-03-10 19:16:18,088 INFO zookeeper.ClientCnxn: Opening socket connection to server c2/10.0.0.102:2181. Will not attempt to authenticate using SASL (unknown error) 2019-03-10 19:16:18,092 INFO zookeeper.ClientCnxn: Socket connection established to c2/10.0.0.102:2181, initiating session 2019-03-10 19:16:18,105 INFO zookeeper.ClientCnxn: Session establishment complete on server c2/10.0.0.102:2181, sessionid = 0x30000397e480000, negotiated timeout = 4000 2019-03-10 19:16:18,106 INFO ha.ActiveStandbyElector: Session connected. 2019-03-10 19:16:18,134 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mshkcluster in ZK. 2019-03-10 19:16:18,137 INFO zookeeper.ZooKeeper: Session: 0x30000397e480000 closed 2019-03-10 19:16:18,141 INFO zookeeper.ClientCnxn: EventThread shut down for session: 0x30000397e480000 2019-03-10 19:16:18,142 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down DFSZKFailoverController at c0/10.0.0.100 ************************************************************/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
验证 zkfc 是否格式化成功,如果多了一个 hadoop-ha 包就是成功了
[root@c0 ~]# zkCli.sh Connecting to localhost:2181 2019-03-10 19:16:45,026 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 04:05 GMT 2019-03-10 19:16:45,028 [myid:] - INFO [main:Environment@100] - Client environment:host.name=c0 2019-03-10 19:16:45,028 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_201 2019-03-10 19:16:45,030 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation 2019-03-10 19:16:45,030 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/opt/jdk1.8.0_201/jre 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/home/work/_app/zookeeper-3.4.13/bin/../build/classes:/home/work/_app/zookeeper-3.4.13/bin/../build/lib/*.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/slf4j-log4j12-1.7.25.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/slf4j-api-1.7.25.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/netty-3.10.6.Final.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/log4j-1.2.17.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/jline-0.9.94.jar:/home/work/_app/zookeeper-3.4.13/bin/../lib/audience-annotations-0.5.0.jar:/home/work/_app/zookeeper-3.4.13/bin/../zookeeper-3.4.13.jar:/home/work/_app/zookeeper-3.4.13/bin/../src/java/lib/*.jar:/home/work/_app/zookeeper-3.4.13/bin/../conf: 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA> 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:os.version=4.20.7-1.el7.elrepo.x86_64 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root 2019-03-10 19:16:45,031 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root 2019-03-10 19:16:45,032 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/home/work/_src 2019-03-10 19:16:45,033 [myid:] - INFO [main:ZooKeeper@442] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@5ce65a89 Welcome to ZooKeeper! 2019-03-10 19:16:45,047 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1029] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) JLine support is enabled 2019-03-10 19:16:45,102 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@879] - Socket connection established to localhost/127.0.0.1:2181, initiating session 2019-03-10 19:16:45,110 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1303] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x100004e77950001, negotiated timeout = 4000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: localhost:2181(CONNECTED) 0] ls / [zookeeper, hadoop-ha] [zk: localhost:2181(CONNECTED) 1] quit Quitting... 2019-03-10 19:16:59,687 [myid:] - INFO [main:ZooKeeper@693] - Session: 0x100004e77950001 closed 2019-03-10 19:16:59,688 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@522] - EventThread shut down for session: 0x100004e77950001
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
6.2.5、启动 NameNode
指定 c0 节点上使用 hdfs --daemon start namenode 命令启动 HDFS NameNode
[root@c0 ~]# hdfs --daemon start namenode
[root@c0 ~]# jps
7393 QuorumPeerMain
7541 JournalNode
7768 NameNode
7919 Jps
- 1
- 2
- 3
- 4
- 5
- 6
关闭 NameNode 的命令为:hdfs --daemon stop namenode
浏览 http://c0:50070/ 能够看到以下效果:

6.2.6、将 NameNode 数据复制到备用 NameNode
在另一台 NameNode 机器 c1 上执行 hdfs namenode -bootstrapStandby 命令,将 Meta 数据从 Active NameNode 复制到 Standby NameNode。
[root@c1 ~]# hdfs namenode -bootstrapStandby 2019-03-10 19:25:07,903 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = c1/10.0.0.101 STARTUP_MSG: args = [-bootstrapStandby] STARTUP_MSG: version = 3.1.2 ... ===================================================== About to bootstrap Standby ID c1 from: Nameservice ID: mshkcluster Other Namenode ID: c0 Other NN's HTTP address: http://c0:50070 Other NN's IPC address: c0/10.0.0.100:8020 Namespace ID: 1312946599 Block pool ID: BP-1652020860-10.0.0.100-1552216142413 Cluster ID: CID-0da1c4b1-00cc-4da7-b381-0c29fca87ebf Layout version: -64 isUpgradeFinalized: true ===================================================== 2019-03-10 19:25:08,971 INFO common.Storage: Storage directory /home/work/_data/hadoop-3.1.2/namenode has been successfully formatted. 2019-03-10 19:25:09,015 INFO namenode.FSEditLog: Edit logging is async:true 2019-03-10 19:25:09,054 INFO namenode.TransferFsImage: Opening connection to http://c0:50070/imagetransfer?getimage=1&txid=0&storageInfo=-64:1312946599:1552216142413:CID-0da1c4b1-00cc-4da7-b381-0c29fca87ebf&bootstrapstandby=true 2019-03-10 19:25:09,096 INFO common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /home/work/_data/hadoop-3.1.2/namenode/current/fsimage.ckpt_0000000000000000000 took 0.00s. 2019-03-10 19:25:09,097 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 391 bytes. 2019-03-10 19:25:09,112 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at c1/10.0.0.101 ************************************************************/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
然后在 c1 使用 hdfs --daemon start namenode 命令启动 HDFS NameNode
[root@c1 ~]# hdfs --daemon start namenode
[root@c1 ~]# jps
17568 QuorumPeerMain
17984 NameNode
17685 JournalNode
18138 Jps
- 1
- 2
- 3
- 4
- 5
- 6
浏览 c1 的 50070 端口,http://10.0.0.101:50070/ 能够看到以下效果:

这个时候在网址上可以看到 c0 和 c1 的状态都是 standby
通过下面的命令,也可以查看 NameNode 的状态
[root@c0 ~]# hdfs haadmin -getServiceState c0
standby
[root@c0 ~]# hdfs haadmin -getServiceState c1
standby
- 1
- 2
- 3
- 4
也可以通过 hdfs haadmin -getAllServiceState 命令,查看所有 NameNode 的状态
6.2.7、启动 HDFS 进程
由于在配置中启用了自动故障转移,start-dfs.sh 脚本现在将在任何运行 NameNode 的计算机上自动启动 zkfc 守护程序和 datanodes 。当 zkfc 启动时,它们将自动选择一个要激活的名称节点。
在 c0 上使用 start-dfs.sh 启动所有 HDFS 进程。
[root@c0 ~]# start-dfs.sh
Starting namenodes on [c0 c1]
Last login: Mon Mar 4 22:14:22 CST 2019 from lionde17nianmbp on pts/3
c0: namenode is running as process 7768. Stop it first.
c1: namenode is running as process 17984. Stop it first.
Starting datanodes
Last login: Sun Mar 10 19:40:52 CST 2019 on pts/3
Starting ZK Failover Controllers on NN hosts [c0 c1]
Last login: Sun Mar 10 19:40:52 CST 2019 on pts/3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
关闭命令为:stop-dfs.sh
您通过 hdfs haadmin -getAllServiceState 命令,也可以查看 NameNode 的状态,可以发现 c0 是 standby,c1 是active
[root@c0 ~]# hdfs haadmin -getAllServiceState
c0:8020 standby
c1:8020 active
- 1
- 2
- 3
6.2.8、测试 HDFS 是否可用
创建 /home/work/_data/test.mshk.top.txt 测试文件,输入以下内容并保存:
[root@c0 ~]# cat /home/work/_data/test.mshk.top.txt
hello hadoop
hello mshk.top
welcome mshk.top
hello world
- 1
- 2
- 3
- 4
- 5
我们在 HDFS 上创建一个 mshk.top 的文件夹,并将 /home/work/_data/test.mshk.top.txt 文件放入到 HDFS 的 mshk.top 目录
[root@c0 ~]# hdfs dfs -ls /
[root@c0 ~]# hdfs dfs -mkdir /mshk.top
[root@c0 ~]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2019-03-10 19:44 /mshk.top
[root@c0 ~]# hdfs dfs -put /home/work/_data/test.mshk.top.txt /mshk.top
[root@c0 ~]# hdfs dfs -ls /mshk.top
Found 1 items
-rw-r--r-- 3 root supergroup 57 2019-03-10 19:44 /mshk.top/test.mshk.top.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
打开 http://c1:50070 的管理界面,能够看到我们添加的文件

6.2.9、启动 YARN
运行 start-yarn.sh 脚本来启动 YARN, start-yarn.sh 会根据配置文件,自动在所配置的所有 Master 上启动 ResourceManager 守护进程,在其他节点上启动 NodeManager 守护进程
# c0 [root@c0 ~]# start-yarn.sh Starting resourcemanagers on [ c0 c1] Last login: Sun Mar 10 19:40:58 CST 2019 on pts/3 Starting nodemanagers Last login: Sun Mar 10 19:48:25 CST 2019 on pts/3 [root@c0 ~]# jps 7393 QuorumPeerMain 9460 DFSZKFailoverController 7541 JournalNode 10437 Jps 7768 NameNode 10109 ResourceManager # c1 [root@c1 ~]# jps 17568 QuorumPeerMain 17984 NameNode 18256 DFSZKFailoverController 18368 ResourceManager 17685 JournalNode 18423 Jps # c2 [root@c2 ~]# jps 17378 JournalNode 17603 NodeManager 17732 Jps 17256 QuorumPeerMain 17484 DataNode # c3 [root@c3 ~]# jps 18024 Jps 17530 QuorumPeerMain 17786 DataNode 17916 NodeManager 17647 JournalNode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
关闭 YARN 的命令为:stop-yarn.sh
在 c0 上,通过 http://c0:8088 能够看到资源管理界面

6.2.10、测试 YARN 的可用性
测试 YARN 是否可用,我们来做一个经典的例子,统计刚才放入 HDFS 中 mshk.top 目录下面的 /home/work/_data/test.mshk.top.txt 的单词频率
[root@c0 ~]# yarn jar /home/work/_app/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /mshk.top/test.mshk.top.txt /output 2019-03-10 19:54:57,588 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1552218514522_0001 2019-03-10 19:54:57,947 INFO input.FileInputFormat: Total input files to process : 1 2019-03-10 19:54:58,085 INFO mapreduce.JobSubmitter: number of splits:1 2019-03-10 19:54:58,377 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552218514522_0001 2019-03-10 19:54:58,378 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2019-03-10 19:54:58,729 INFO conf.Configuration: resource-types.xml not found 2019-03-10 19:54:58,729 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2019-03-10 19:54:59,150 INFO impl.YarnClientImpl: Submitted application application_1552218514522_0001 2019-03-10 19:54:59,229 INFO mapreduce.Job: The url to track the job: http://c0:8088/proxy/application_1552218514522_0001/ 2019-03-10 19:54:59,230 INFO mapreduce.Job: Running job: job_1552218514522_0001 2019-03-10 19:55:09,368 INFO mapreduce.Job: Job job_1552218514522_0001 running in uber mode : false 2019-03-10 19:55:09,369 INFO mapreduce.Job: map 0% reduce 0% 2019-03-10 19:55:16,477 INFO mapreduce.Job: map 100% reduce 0% 2019-03-10 19:55:21,517 INFO mapreduce.Job: map 100% reduce 100% 2019-03-10 19:55:22,533 INFO mapreduce.Job: Job job_1552218514522_0001 completed successfully 2019-03-10 19:55:22,718 INFO mapreduce.Job: Counters: 53 File System Counters FILE: Number of bytes read=72 FILE: Number of bytes written=438627 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=167 HDFS: Number of bytes written=46 HDFS: Number of read operations=8 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=5083 Total time spent by all reduces in occupied slots (ms)=2448 Total time spent by all map tasks (ms)=5083 Total time spent by all reduce tasks (ms)=2448 Total vcore-milliseconds taken by all map tasks=5083 Total vcore-milliseconds taken by all reduce tasks=2448 Total megabyte-milliseconds taken by all map tasks=5204992 Total megabyte-milliseconds taken by all reduce tasks=2506752 Map-Reduce Framework Map input records=4 Map output records=8 Map output bytes=89 Map output materialized bytes=72 Input split bytes=110 Combine input records=8 Combine output records=5 Reduce input groups=5 Reduce shuffle bytes=72 Reduce input records=5 Reduce output records=5 Spilled Records=10 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=141 CPU time spent (ms)=1360 Physical memory (bytes) snapshot=524554240 Virtual memory (bytes) snapshot=5584596992 Total committed heap usage (bytes)=337117184 Peak Map Physical memory (bytes)=311808000 Peak Map Virtual memory (bytes)=2788454400 Peak Reduce Physical memory (bytes)=212746240 Peak Reduce Virtual memory (bytes)=2796142592 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=57 File Output Format Counters Bytes Written=46
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
查看统计结果:
[root@c0 ~]# hadoop fs -cat /output/part-*
hadoop 1
hello 3
mshk.top 2
welcome 1
world 1
- 1
- 2
- 3
- 4
- 5
- 6
6.2.11、查看 MapReduce 运行的历史记录
运行 mapred --daemon start historyserver 命令启动 JobHistory Server可以查看 MapReduce 运行的历史记录:
[root@c0 ~]# mapred --daemon start historyserver
- 1
关闭 JobHistory Server 的命令为:mapred --daemon stop historyserver
运行以后,通过 http://c0:19888 端口查看,能够看到我们刚才运行的 word count 统计
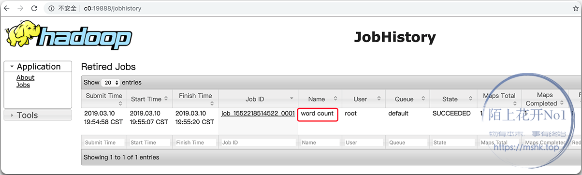
6.2.12、验证 Hadoop HA 高可用性
故障转移,通过 hdfs haadmin -getAllServiceState 命令,已经看到 c0 的状态是 standby,c1 的状态是 active
[root@c0 ~]# hdfs haadmin -getAllServiceState
c0:8020 standby
c1:8020 active
- 1
- 2
- 3
我们在 c1 上 kill 掉 namenode 进程
[root@c1 ~]# jps
17568 QuorumPeerMain
17984 NameNode
18256 DFSZKFailoverController
18368 ResourceManager
17685 JournalNode
18477 Jps
[root@c1 ~]# kill -9 17984
[root@c1 ~]# jps
17568 QuorumPeerMain
18256 DFSZKFailoverController
18368 ResourceManager
17685 JournalNode
18492 Jps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
再次通过 hdfs haadmin -getAllServiceState 命令,已经看到 c0 的状态是 active,c1 连接不上
[root@c0 ~]# hdfs haadmin -getAllServiceState
c0:8020 active
2019-03-10 20:22:41,388 INFO ipc.Client: Retrying connect to server: c1/10.0.0.101:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
c1:8020 Failed to connect: Call From c0/10.0.0.100 to c1:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
- 1
- 2
- 3
- 4
- 5
这时我们通过 http://c0:50070 端口查看,可以看到,在前面 c1 是 Active NameNode 的时候,我们上传和测试的数据,已经通过 JournalNode 同步了元数据,同样当现在 c0 是 Active NameNode 时,也可以看到 HDFS 操作过的文件。自此,我们实现了 Hadoop HA 高可用集群的方案。

7、安装 Hbase 1.4.9
7.1、修改 Hbase 配置文件
7.1.1、编辑配置文件 hbase-env.sh
编辑 /home/work/_app/hbase-1.4.9/conf/hbase-env.sh 文件并保存,内容如下:
[root@c0 _src]# cat /home/work/_app/hbase-1.4.9/conf/hbase-env.sh #!/usr/bin/env bash # #/** # * Licensed to the Apache Software Foundation (ASF) under one # * or more contributor license agreements. See the NOTICE file # * distributed with this work for additional information # * regarding copyright ownership. The ASF licenses this file # * to you under the Apache License, Version 2.0 (the # * "License"); you may not use this file except in compliance # * with the License. You may obtain a copy of the License at # * # * http://www.apache.org/licenses/LICENSE-2.0 # * # * Unless required by applicable law or agreed to in writing, software # * distributed under the License is distributed on an "AS IS" BASIS, # * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # * See the License for the specific language governing permissions and # * limitations under the License. # */ # Set environment variables here. # This script sets variables multiple times over the course of starting an hbase process, # so try to keep things idempotent unless you want to take an even deeper look # into the startup scripts (bin/hbase, etc.) # The java implementation to use. Java 1.8+ required. # export JAVA_HOME=/usr/java/jdk1.8.0/ # Extra Java CLASSPATH elements. Optional. # export HBASE_CLASSPATH= # The maximum amount of heap to use. Default is left to JVM default. # export HBASE_HEAPSIZE=1G # Uncomment below if you intend to use off heap cache. For example, to allocate 8G of # offheap, set the value to "8G". # export HBASE_OFFHEAPSIZE=1G # Extra Java runtime options. # Below are what we set by default. May only work with SUN JVM. # For more on why as well as other possible settings, # see http://hbase.apache.org/book.html#performance export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC" # Uncomment one of the below three options to enable java garbage collection logging for the server-side processes. # This enables basic gc logging to the .out file. # export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps" # This enables basic gc logging to its own file. # If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR . # export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>" # This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+. # If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR . # export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M" # Uncomment one of the below three options to enable java garbage collection logging for the client processes. # This enables basic gc logging to the .out file. # export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps" # This enables basic gc logging to its own file. # If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR . # export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>" # This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+. # If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR . # export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M" # See the package documentation for org.apache.hadoop.hbase.io.hfile for other configurations # needed setting up off-heap block caching. # Uncomment and adjust to enable JMX exporting # See jmxremote.password and jmxremote.access in $JRE_HOME/lib/management to configure remote password access. # More details at: http://java.sun.com/javase/6/docs/technotes/guides/management/agent.html # NOTE: HBase provides an alternative JMX implementation to fix the random ports issue, please see JMX # section in HBase Reference Guide for instructions. # export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false" # export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10101" # export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10102" # export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10103" # export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10104" # export HBASE_REST_OPTS="$HBASE_REST_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10105" # File naming hosts on which HRegionServers will run. $HBASE_HOME/conf/regionservers by default. # export HBASE_REGIONSERVERS=${HBASE_HOME}/conf/regionservers # Uncomment and adjust to keep all the Region Server pages mapped to be memory resident #HBASE_REGIONSERVER_MLOCK=true #HBASE_REGIONSERVER_UID="hbase" # File naming hosts on which backup HMaster will run. $HBASE_HOME/conf/backup-masters by default. # export HBASE_BACKUP_MASTERS=${HBASE_HOME}/conf/backup-masters # Extra ssh options. Empty by default. # export HBASE_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HBASE_CONF_DIR" # Where log files are stored. $HBASE_HOME/logs by default. export HBASE_LOG_DIR=/home/work/_logs/hbase-1.4.9 # Enable remote JDWP debugging of major HBase processes. Meant for Core Developers # export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8070" # export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8071" # export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8072" # export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8073" # export HBASE_REST_OPTS="$HBASE_REST_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8074" # A string representing this instance of hbase. $USER by default. # export HBASE_IDENT_STRING=$USER # The scheduling priority for daemon processes. See 'man nice'. # export HBASE_NICENESS=10 # The directory where pid files are stored. /tmp by default. # export HBASE_PID_DIR=/var/hadoop/pids export HBASE_PID_DIR=/home/work/_data/hbase-1.4.9 # Seconds to sleep between slave commands. Unset by default. This # can be useful in large clusters, where, e.g., slave rsyncs can # otherwise arrive faster than the master can service them. # export HBASE_SLAVE_SLEEP=0.1 # Tell HBase whether it should manage it's own instance of ZooKeeper or not. # 使用hbase自带的zookeeper export HBASE_MANAGES_ZK=true # The default log rolling policy is RFA, where the log file is rolled as per the size defined for the # RFA appender. Please refer to the log4j.properties file to see more details on this appender. # In case one needs to do log rolling on a date change, one should set the environment property # HBASE_ROOT_LOGGER to "<DESIRED_LOG LEVEL>,DRFA". # For example: # HBASE_ROOT_LOGGER=INFO,DRFA # The reason for changing default to RFA is to avoid the boundary case of filling out disk space as # DRFA doesn't put any cap on the log size. Please refer to HBase-5655 for more context.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
7.1.2、编辑配置文件 hbase-site.xml
编辑 /home/work/_app/hbase-1.4.9/conf/hbase-site.xml 文件并保存,内容如下:
[root@c0 ~]# cat /home/work/_app/hbase-1.4.9/conf/hbase-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- /** * * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ --> <configuration> <property> <name>hbase.rootdir</name> <!-- hbase存放数据目录 --> <value>hdfs://mshkcluster:8020/hbase/hbase_db</value> <description>端口要和Hadoop的fs.defaultFS端口一致</description> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> <description>集群将处于的模式。可能的值是对于独立模式为false,对于分布式模式为true</description> </property> <property> <name>hbase.zookeeper.quorum</name> <value>c0,c1,c2,c3</value> <description>逗号分隔的ZooKeeper集合中的服务器列表个</description> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/work/_data/hbase-1.4.9</value> <description>zookooper配置、日志等的存储位置,必须为以存在</description> </property> <property> <name>hbase.master.port</name> <value>16000</value> <description>HBase Master应绑定的端口</description> </property> <property> <name>hbase.master.info.port</name> <value>16010</value> <description>hbase web 端口</description> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
7.1.3、配置 Slaver
编辑 /home/work/_app/hbase-1.4.9/conf/regionservers 文件并保存,内容如下:
[root@c0 ~]# cat /home/work/_app/hbase-1.4.9/conf/regionservers
c2
c3
- 1
- 2
- 3
删除掉与 Hadoop 重复的 jar 包
[root@c0 ~]# rm -rf /home/work/_app/hbase-1.4.9/lib/slf4j-log4j12-1.7.10.jar
- 1
7.1.4、将 Hbase 复制到其他机器
将 Hbase 复制到其他机器上
[root@c0 ~]# for N in $(seq 1 3); do scp -r /home/work/_app/hbase-1.4.9 c$N:/home/work/_app/; done;
- 1
7.2、启动 Hbase
在 NameNode 的 c0和c1 上分别通过 start-hbase.sh 启动 Hbase,会看到在 Master 上有 HMaster 的守护进程,同时会自动启动其他节点的 HRegionServer 服务
# c0 [root@c0 ~]# start-hbase.sh c3: starting zookeeper, logging to /home/work/_logs/hbase-1.4.9/hbase-root-zookeeper-c3.out c2: starting zookeeper, logging to /home/work/_logs/hbase-1.4.9/hbase-root-zookeeper-c2.out c0: starting zookeeper, logging to /home/work/_logs/hbase-1.4.9/hbase-root-zookeeper-c0.out c1: starting zookeeper, logging to /home/work/_logs/hbase-1.4.9/hbase-root-zookeeper-c1.out starting master, logging to /home/work/_logs/hbase-1.4.9/hbase-root-master-c0.out c3: starting regionserver, logging to /home/work/_logs/hbase-1.4.9/hbase-root-regionserver-c3.out c2: starting regionserver, logging to /home/work/_logs/hbase-1.4.9/hbase-root-regionserver-c2.out [root@c0 _src]# jps 7617 Jps 13459 JournalNode 14404 DFSZKFailoverController 15974 JobHistoryServer 15191 ResourceManager 9900 QuorumPeerMain 13677 NameNode 7327 HMaster # c1 [root@c1 ~]# start-hbase.sh c2: starting zookeeper, logging to /home/work/_logs/hbase-1.4.9/hbase-root-zookeeper-c2.out c3: starting zookeeper, logging to /home/work/_logs/hbase-1.4.9/hbase-root-zookeeper-c3.out c1: starting zookeeper, logging to /home/work/_logs/hbase-1.4.9/hbase-root-zookeeper-c1.out c0: starting zookeeper, logging to /home/work/_logs/hbase-1.4.9/hbase-root-zookeeper-c0.out starting master, logging to /home/work/_logs/hbase-1.4.9/hbase-root-master-c1.out c3: regionserver running as process 26117. Stop it first. c2: regionserver running as process 26915. Stop it first. [root@c1 ~]# jps 22640 HQuorumPeer 11315 NameNode 10613 DFSZKFailoverController 22775 HMaster 10074 JournalNode 10700 ResourceManager 8141 QuorumPeerMain 23007 Jps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
关闭的命令为:stop-hbase.sh
启动后浏览 http://c0:16010 ,可以看到 c0 是 Master 而 c1 是 Backup Master

7.2.1、用 Shell 测试连接 Hbase
在 c0 上用 shell 测试连接 Hbase
[root@c0 ~]# hbase shell HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. Version 1.4.9, rd625b212e46d01cb17db9ac2e9e927fdb201afa1, Wed Dec 5 11:54:10 PST 2018 hbase(main):001:0> list TABLE 0 row(s) in 0.2440 seconds => [] hbase(main):002:0> version 1.4.9, rd625b212e46d01cb17db9ac2e9e927fdb201afa1, Wed Dec 5 11:54:10 PST 2018 hbase(main):003:0> create 'mshk_top','uid','name' 0 row(s) in 1.4720 seconds => Hbase::Table - mshk_top hbase(main):004:0> list TABLE mshk_top 1 row(s) in 0.0090 seconds => ["mshk_top"] hbase(main):005:0> put 'mshk_top','10086','name:mshk.top-name','mshk.top-value' 0 row(s) in 0.2150 seconds hbase(main):006:0> get 'mshk_top','10086' COLUMN CELL name:mshk.top-name timestamp=1552229501956, value=mshk.top-value 1 row(s) in 0.0350 seconds hbase(main):007:0> scan 'mshk_top' ROW COLUMN+CELL 10086 column=name:mshk.top-name, timestamp=1552229501956, value=mshk.top-value 1 row(s) in 0.0250 seconds hbase(main):008:0> quit
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
7.2.2、测试 Hbase 故障转移
我们在 c0 上停止掉 Hbase 的进程
[root@c0 ~]# jps 13459 JournalNode 14404 DFSZKFailoverController 15974 JobHistoryServer 19270 Jps 15191 ResourceManager 18185 HMaster 9900 QuorumPeerMain 13677 NameNode [root@c0 ~]# kill 18185 [root@c0 ~]# jps 13459 JournalNode 14404 DFSZKFailoverController 15974 JobHistoryServer 15191 ResourceManager 19291 HMaster 9900 QuorumPeerMain 19404 Jps 13677 NameNode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这时再浏览 http://c0:16010 已经无法访问,浏览 http://c1:16010 已经切换到了 master

8、安装 Mysql 5.7
CentOS 的 yum 源中没有 Mysql,需要到 Mysql 的官网下载 yum repo 配置文件
[root@c0 ~]# cd /home/work/_src
[root@c0 _src]# wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
[root@c0 _src]# rpm -ivh mysql57-community-release-el7-9.noarch.rpm
[root@c0 _src]# yum install mysql-server -y
- 1
- 2
- 3
- 4
8.1、启动 Mysql
通过以下命令,启动Mysql
[root@c0 _src]# systemctl start mysqld
- 1
8.2、授权可以远程访问 Mysql
查看安装时的临时密码
[root@c0 _src]# grep 'temporary password' /var/log/mysqld.log
2019-03-10T14:55:05.727483Z 1 [Note] A temporary password is generated for root@localhost: B#ZJGyK,,1/)
- 1
- 2
上面的B#ZJGyK,1/)是密码,密码中带),要使用\进行转义
修改 Mysql5.7 默认密码为 123456
[root@c0 _src]# mysql -uroot -pB#ZJGyK,,1/\) mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.25 Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> set global validate_password_policy=0; Query OK, 0 rows affected (0.00 sec) mysql> set global validate_password_length=1; Query OK, 0 rows affected (0.00 sec) mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '123456'; Query OK, 0 rows affected (0.00 sec) mysql>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
8.3、修改 Mysql 授权远程访问
执行下面的命令,让 Mysql 授权远程访问
mysql> grant all on *.* to 'root'@'%' identified by '123456' WITH GRANT OPTION;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> quit
Bye
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
9、安装 Hive2.3.4
9.1、修改 Hive配置文件
9.1.1、编辑配置文件 hive-env.sh
将 /home/work/_app/hive-2.3.4/conf/hive-env.sh.template 复制为 /home/work/_app/hive-2.3.4/conf/hive-env.sh 文件
[root@c0 ~]# cp /home/work/_app/hive-2.3.4/conf/hive-env.sh.template /home/work/_app/hive-2.3.4/conf/hive-env.sh
- 1
- 2
在本文上面,我们对系统的环境变量已经做了统一设置,这里就不再编辑 /home/work/_app/hive-2.3.4/conf/hive-env.sh 文件
9.1.2、编辑配置文件 hive-site.xml
创建并编辑 /home/work/_app/hive-2.3.4/conf/hive-site.xml 文件,内容如下:
[root@c0 ~]# cat /home/work/_app/hive-2.3.4/conf/hive-site.xml <?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --> <configuration> <property> <name>system:java.io.tmpdir</name> <value>/home/work/_data/hive-2.3.4/tmpdir</value> </property> <property> <name>system:user.name</name> <value>root</value> <description>指定HDFS中的hive仓库地址</description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive/warehouse</value> <description>指定HDFS中的hive仓库地址</description> </property> <property> <name>hive.exec.scratchdir</name> <value>/home/work/_data/hive-2.3.4/scratchdir</value> <description>Hive作业的划痕空间</description> </property> <property> <name>hive.metastore.uris</name> <value /> <description>远程元存储的节俭URI。该属性为空表示嵌入模式或本地模式,否则为远程模式 </description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://c0:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> <description>jdbc连接字符串</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>jdbc的连接驱动</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>用户名</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>指定密码</description> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> <description>强制元存储架构版本一致性。</description> </property> <property> <name>hive.aux.jars.path</name> <value>/home/work/_app/hive-2.3.4/lib</value> <description>包含用户定义函数和serde实现的插件jar的位置.</description> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
9.1.3、下载 Mysql 驱动
Hive 默认是没有带 Mysql 驱动程序的,我们需要下载并上传到 /home/work/_app/hive-2.3.4/lib
[root@c0 ~]# curl -Ls https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.47.tar.gz | tar -xz --directory /home/work/_src/ --strip-components=1 --no-same-owner
[root@c0 ~]# cp -r /home/work/_src/mysql-connector-java-5.1.47-bin.jar /home/work/_app/hive-2.3.4/lib/
[root@c0 ~]# ll /home/work/_app/hive-2.3.4/lib | grep mysql
-rw-r--r--. 1 root root 1007505 Mar 10 22:59 mysql-connector-java-5.1.47-bin.jar
-rw-r--r--. 1 root root 7954 Oct 25 14:51 mysql-metadata-storage-0.9.2.jar
- 1
- 2
- 3
- 4
- 5
删除掉与 Hadoop 重复的 jar 包
[root@c0 ~]# rm -rf /home/work/_app/hive-2.3.4/lib/log4j-slf4j-impl-2.6.2.jar
- 1
- 2
9.2、启动 Hive
9.2.1、初始化 MySql 数据库
使用 Hive schematool 初始化当前 Hive 版本的 Metastore 架构。该工具尝试从 Metastore 中找到当前架构(如果它在那里可用)。
schematool 确定初始化或升级架构所需的SQL脚本,然后针对后端数据库执行这些脚本。从 Hive 配置中提取 Metastore 数据库连接信息,例如 JDBC URL,JDBC driver 和数据库凭据。
[root@c0 ~]# schematool -dbType mysql -initSchema
Metastore connection URL: jdbc:mysql://c0:3306/hive?createDatabaseIfNotExist=true&useSSL=false
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
9.2.2、创建测试数据,以及在hadoop上创建数据仓库目录
创建 /home/work/_app/hive-2.3.4/testdata001.dat 文件编辑并保存,内容如下:
[root@c0 ~]# cat /home/work/_app/hive-2.3.4/testdata001.dat
12306,mname,yname
10086,my.mshk.top,you.mshk.top
- 1
- 2
- 3
在 Hadoop 上创建数据仓库目录
[root@c0 _src]# hadoop fs -mkdir -p /hive/warehouse
- 1
9.2.3、用 Shell 测试连接 Hive
[root@c0 _src]# hive Logging initialized using configuration in jar:file:/home/work/_app/hive-2.3.4/lib/hive-common-2.3.4.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> show databases; OK default Time taken: 4.071 seconds, Fetched: 1 row(s) hive> create database testmshk; OK Time taken: 0.261 seconds hive> show databases; OK default testmshk Time taken: 0.031 seconds, Fetched: 2 row(s) hive> use testmshk; OK Time taken: 0.1 seconds hive> create external table testtable(uid int,myname string,youname string) row format delimited fields terminated by ',' location '/hive/warehouse/testtable'; OK Time taken: 0.247 seconds hive> LOAD DATA LOCAL INPATH '/home/work/_app/hive-2.3.4/testdata001.dat' OVERWRITE INTO TABLE testtable; Loading data to table testmshk.testtable OK Time taken: 1.017 seconds hive> select * from testtable; OK 12306 mname yname 10086 my.mshk.top you.mshk.top Time taken: 1.377 seconds, Fetched: 2 row(s) hive> quit;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
9.2.4、Hive to Hbase
Hive 中的表数据导入到 Hbase 中去,先创建 Hbase 可以识别的表
[root@c0 _src]# hive Logging initialized using configuration in jar:file:/home/work/_app/hive-2.3.4/lib/hive-common-2.3.4.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> show databases; OK default testmshk Time taken: 3.614 seconds, Fetched: 2 row(s) hive> CREATE TABLE hive2hbase_mshk(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "hive2hbase_mshk"); OK Time taken: 2.71 seconds hive> show tables; OK hive2hbase_mshk Time taken: 0.056 seconds, Fetched: 1 row(s) hive>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
创建本地表,用来存储数据,然后插入到 Hbase 用的,相当于一张中间表了。同时将之前的测试数据导入到这张中间表。
hive> create table hive2hbase_mshk_middle(foo int,bar string)row format delimited fields terminated by ',';
OK
Time taken: 0.139 seconds
hive> load data local inpath '/home/work/_app/hive-2.3.4/testdata001.dat' overwrite into table hive2hbase_mshk_middle;
Loading data to table default.hive2hbase_mshk_middle
OK
Time taken: 0.733 seconds
hive>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
将本地中间表 hive2hbase_mshk_middle 导入到表 hive2hbase_mshk 中,会自动同步到 Hbase。
hive> insert overwrite table hive2hbase_mshk select * from hive2hbase_mshk_middle; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Query ID = root_20190310230625_a285d829-93a3-47c1-8aa6-6430a792c10c Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1552228449632_0002, Tracking URL = http://c1:8088/proxy/application_1552228449632_0002/ Kill Command = /home/work/_app/hadoop-3.1.2/bin/hadoop job -kill job_1552228449632_0002 Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0 2019-03-10 23:06:53,294 Stage-3 map = 0%, reduce = 0% 2019-03-10 23:07:04,258 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 4.35 sec MapReduce Total cumulative CPU time: 4 seconds 350 msec Ended Job = job_1552228449632_0002 MapReduce Jobs Launched: Stage-Stage-3: Map: 1 Cumulative CPU: 4.35 sec HDFS Read: 10643 HDFS Write: 0 SUCCESS Total MapReduce CPU Time Spent: 4 seconds 350 msec OK Time taken: 40.76 seconds hive> select * from hive2hbase_mshk; OK 10086 my.mshk.top 12306 mname Time taken: 0.315 seconds, Fetched: 2 row(s) hive>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
用 Shell 连接 Hbase,查看 Hive 过来的数据是否已经存在
[root@c0 _src]# hbase shell HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. Version 1.4.9, rd625b212e46d01cb17db9ac2e9e927fdb201afa1, Wed Dec 5 11:54:10 PST 2018 hbase(main):001:0> list TABLE hive2hbase_mshk mshk_top 2 row(s) in 0.2150 seconds => ["hive2hbase_mshk", "mshk_top"] hbase(main):002:0> scan "hive2hbase_mshk" ROW COLUMN+CELL 10086 column=cf1:val, timestamp=1551874886611, value=my.mshk.top 12306 column=cf1:val, timestamp=1551874886611, value=mname 2 row(s) in 0.1280 seconds hbase(main):003:0> get "hive2hbase_mshk",'10086' COLUMN CELL cf1:val timestamp=1551874886611, value=my.mshk.top 1 row(s) in 0.0310 seconds hbase(main):004:0>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
9.2.5、Hbase to Hive
在 Hbase 下创建表 hbase2hive_mshk
[root@c0 _src]# hbase shell HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. Version 1.4.9, rd625b212e46d01cb17db9ac2e9e927fdb201afa1, Wed Dec 5 11:54:10 PST 2018 hbase(main):001:0> create 'hbase2hive_mshk',{ NAME => 'cf', COMPRESSION => 'SNAPPY' } 0 row(s) in 1.3120 seconds => Hbase::Table - hbase2hive_mshk hbase(main):002:0> put 'hbase2hive_mshk','1','cf:name','mshk.top 1' 0 row(s) in 0.5320 seconds hbase(main):003:0> put 'hbase2hive_mshk','2','cf:name','mshk.top 2' 0 row(s) in 0.0250 seconds hbase(main):004:0> put 'hbase2hive_mshk','3','cf:name','mshk.top 3' 0 row(s) in 0.0080 seconds hbase(main):005:0> scan 'hbase2hive_mshk' ROW COLUMN+CELL 1 column=cf:name, timestamp=1551877176349, value=mshk.top 1 2 column=cf:name, timestamp=1551877186366, value=mshk.top 2 3 column=cf:name, timestamp=1551877191913, value=mshk.top 3 3 row(s) in 0.0500 seconds hbase(main):006:0>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
Hive 下创建表连接 Hbase 中的表
[root@c0 _src]# hive Logging initialized using configuration in jar:file:/home/work/_app/hive-2.3.4/lib/hive-common-2.3.4.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> create external table default.hbase2hive_mshk(id int, name string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,cf:name") TBLPROPERTIES ("hbase.table.name"="hbase2hive_mshk"); OK Time taken: 22.888 seconds hive> use default; OK Time taken: 3.592 seconds hive> show tables; OK hbase2hive_mshk hive2hbase_mshk hive2hbase_mshk_middle Time taken: 16.7 seconds, Fetched: 3 row(s) hive> select * from hbase2hive_mshk; OK 1 mshk.top 1 2 mshk.top 2 3 mshk.top 3 Time taken: 250.526 seconds, Fetched: 3 row(s) hive>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
10、安装 Spark 2.4.0
10.1、修改 Spark 配置文件
10.1.1、编辑配置文件 spark-env.sh
创建 /home/work/_app/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh 文件编辑并保存,内容如下:
[root@c0 ~]# cat /home/work/_app/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh #!/usr/bin/env bash export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=c0:2181,c1:2181,c2:2181,c3:2181 -Dspark.deploy.zookeeper.dir=/spark-2.4.0-bin-hadoop2.7" export SPARK_LOG_DIR=/home/work/_logs/spark-2.4.0-bin-hadoop2.7 # Spark Work内存使用量 export SPARK_WORKER_MEMORY=512M # 该参数决定了yarn集群中,最多能够同时启动的EXECUTOR的实例个数。 export SPARK_EXECUTOR_INSTANCES=3 # 设置每个EXECUTOR能够使用的CPU core的数量。 export SPARK_EXECUTOR_CORES=3 # 该参数设置的是每个EXECUTOR分配的内存的数量 export SPARK_EXECUTOR_MEMORY=512M #该参数设置的是DRIVER分配的内存的大小 export SPARK_DRIVER_MEMORY=1G # Spark Application在Yarn中的名字 export SPARK_YARN_APP_NAME="lion.Spark-2.4.0" # 指定在yarn中执行,提交方式为client #MASTER=yarn-cluster # # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # This file is sourced when running various Spark programs. # Copy it as spark-env.sh and edit that to configure Spark for your site. # Options read when launching programs locally with # ./bin/run-example or ./bin/spark-submit # - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files # - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node # - SPARK_PUBLIC_DNS, to set the public dns name of the driver program # Options read by executors and drivers running inside the cluster # - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node # - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program # - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data # - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos # Options read in YARN client/cluster mode # - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf) # - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files # - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN # - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1). # - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G) # - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G) # Options for the daemons used in the standalone deploy mode # - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname # - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master # - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y") # - SPARK_WORKER_CORES, to set the number of cores to use on this machine # - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g) # - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker # - SPARK_WORKER_DIR, to set the working directory of worker processes # - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y") # - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g). # - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y") # - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y") # - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y") # - SPARK_DAEMON_CLASSPATH, to set the classpath for all daemons # - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers # Generic options for the daemons used in the standalone deploy mode # - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf) # - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs) # - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp) # - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER) # - SPARK_NICENESS The scheduling priority for daemons. (Default: 0) # - SPARK_NO_DAEMONIZE Run the proposed command in the foreground. It will not output a PID file. # Options for native BLAS, like Intel MKL, OpenBLAS, and so on. # You might get better performance to enable these options if using native BLAS (see SPARK-21305). # - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL # - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
-Dspark.deploy.recoveryMode #说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复也是通过zookeeper来维护的。
-Dspark.deploy.zookeeper.url 有可能做master(Active)的机器都配置进来
-Dspark.deploy.zookeeper.dir 保存spark的元数据,保存了spark的作业运行状态
10.1.2、编辑配置文件 Slaves
创建 /home/work/_app/spark-2.4.0-bin-hadoop2.7/conf/slaves 文件编辑并保存,内容如下:
[root@c0 ~]# cat /home/work/_app/spark-2.4.0-bin-hadoop2.7/conf/slaves
c2
c3
- 1
- 2
- 3
10.1.3、编辑配置文件 spark-defaults.conf
创建 /home/work/_app/spark-2.4.0-bin-hadoop2.7/conf/spark-defaults.conf 文件编辑并保存,内容如下:
[root@c0 ~]# cat /home/work/_app/spark-2.4.0-bin-hadoop2.7/conf/spark-defaults.conf # 如果没有适合当前本地性要求的任务可供运行,将跑得慢的任务在空闲计算资源上再度调度的行为,这个参数会引发一些tmp文件被删除的问题,一般设置为false spark.speculation false # 如果设置为true,前台用jdbc方式连接,显示的会是乱码 spark.sql.hive.convertMetastoreParquet false # 应用程序上载到HDFS的复制份数 spark.yarn.submit.file.replication 3 # Spark application master给YARN ResourceManager 发送心跳的时间间隔(ms) spark.yarn.scheduler.heartbeat.interal-ms 5000 # 仅适用于HashShuffleMananger的实现,同样是为了解决生成过多文件的问题,采用的方式是在不同批次运行的Map任务之间重用Shuffle输出文件,也就是说合并的是不同批次的Map任务的输出数据,但是每个Map任务所需要的文件还是取决于Reduce分区的数量,因此,它并不减少同时打开的输出文件的数量,因此对内存使用量的减少并没有帮助。只是HashShuffleManager里的一个折中的解决方案。 spark.shuffle.consolidateFiles true # 一个partition对应着一个task,如果数据量过大,可以调整次参数来减少每个task所需消耗的内存. spark.sql.shuffle.partitions 100 # Spark SQL在每次执行次,先把SQL查询编译JAVA字节码。针对执行时间长的SQL查询或频繁执行的SQL查询,此配置能加快查询速度,因为它产生特殊的字节码去执行。但是针对很短的查询,可能会增加开销,因为它必须先编译每一个查询 spark.sql.codegen true # 我们都知道shuffle默认情况下的文件数据为map tasks * reduce tasks,通过设置其为true,可以使spark合并shuffle的中间文件为reduce的tasks数目。 spark.shuffle.consolidateFiles true # 是否记录Spark事件,对于在应用程序完成后重建Web UI非常有用。 spark.eventLog.enabled true # 是否压缩已记录的事件,如果spark.eventLog.enabled为true。压缩将使用spark.io.compression.codec。 spark.eventLog.compress true # 如果spark.eventLog.enabled为true,则记录Spark事件的基目录。在此基本目录中,Spark为每个应用程序创建一个子目录,并将特定于该应用程序的事件记录在此目录中。用户可能希望将其设置为统一位置(如HDFS目录),以便历史记录服务器可以读取历史记录文件。 spark.eventLog.dir hdfs://mshkcluster:8020/tmp/logs/spark_logs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
10.2、启动spark集群
10.2.1、将 Spark 和 Scala 复制到其他机器
# 复制 Spark
[root@c0 ~]# for N in $(seq 1 3); do scp -r /home/work/_app/spark-2.4.0-bin-hadoop2.7 c$N:/home/work/_app/; done;
# 复制 Scala
[root@c0 ~]# for N in $(seq 1 3); do scp -r /home/work/_app/scala-2.12.8 c$N:/home/work/_app/; done;
- 1
- 2
- 3
- 4
- 5
10.2.2、启动 Spark
在 c0 输入 $SPARK_HOME/sbin/start-all.sh 来启动 Spark Master,同时会自动启动在 c2、c3 的 Spark Worker
然后 c1 输入 $SPARK_HOME/sbin/start-master.sh 来单独启动 Spark Master
# c0 [root@c0 ~]# $SPARK_HOME/sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /home/work/_logs/spark-2.4.0-bin-hadoop2.7/spark-root-org.apache.spark.deploy.master.Master-1-c0.out c3: starting org.apache.spark.deploy.worker.Worker, logging to /home/work/_logs/spark-2.4.0-bin-hadoop2.7/spark-root-org.apache.spark.deploy.worker.Worker-1-c3.out c2: starting org.apache.spark.deploy.worker.Worker, logging to /home/work/_logs/spark-2.4.0-bin-hadoop2.7/spark-root-org.apache.spark.deploy.worker.Worker-1-c2.out [root@c0 ~]# jps 7296 DFSZKFailoverController 7106 JournalNode 12467 ResourceManager 6820 NameNode 6615 QuorumPeerMain 13000 Jps 12906 Master # c1 [root@c1 ~]# $SPARK_HOME/sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /home/work/_logs/spark-2.4.0-bin-hadoop2.7/spark-root-org.apache.spark.deploy.master.Master-1-c1.out [root@c1 ~]# jps 5568 DFSZKFailoverController 7667 ResourceManager 5397 NameNode 8165 Jps 8102 Master 5480 JournalNode 5306 QuorumPeerMain # c2 [root@c2 ~]# jps 6342 Worker 6090 NodeManager 4748 QuorumPeerMain 4847 DataNode 6399 Jps # c3 [root@c3 ~]# jps 13937 QuorumPeerMain 15555 Jps 15253 NodeManager 15498 Worker 14013 DataNode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
关闭所有节点的 Spark 命令为:$SPARK_HOME/sbin/stop-all.sh
查看Web界面 端口是 http://c0:8080 能够看到,只有 c0 的 Status: ALIVE,而其他机器则是 Status: STANDBY
10.2.3、测试 Spark 集群
在 Spark Shell 中用 Scala 语言编写 Spark 程序
[root@c0 ~]# spark-shell 2019-03-07 16:28:34 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://c0:4040 Spark context available as 'sc' (master = local[*], app id = local-1551947322590). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.0 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201) Type in expressions to have them evaluated. Type :help for more information. scala> sc.textFile("/mshk.top/test.mshk.top.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/spark/out")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
sc是 SparkContext 对象,该对象是提交 Spark 程序的入口
textFile(“/spark/hello.txt”)是在 HDFS 中读取数据
.split(” “)).map((,1) 是用空格做间隔符,将结果 和数字1,应用到集合中的每个元素,并产生一个结果集合
flatMap(.split(” “))把生成的多个集合“拍扁”成为一个集合
reduceByKey(+_) 合并具有相同键的值,按照key进行reduce,并将value累加
saveAsTextFile(“/spark/out”) 将结果写入到 HDFS 中
在 HDFS 中查看结果
[root@c0 ~]# hadoop fs -cat /spark/out/p*
(mshk.top,2)
(hello,3)
(welcome,1)
(world,1)
(hadoop,1)
- 1
- 2
- 3
- 4
- 5
- 6
10.2.4、运行 Spark on YARN
Spark on YARN的原理就是依靠 yarn 来调度 Spark,比默认的 Spark 运行模式性能要好的多
[root@c0 ~]# spark-shell --master yarn --deploy-mode client 2019-03-07 16:38:08 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 2019-03-07 16:38:16 WARN Client:66 - Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME. Spark context Web UI available at http://c0:4040 Spark context available as 'sc' (master = yarn, app id = application_1551946215357_0002). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.0 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201) Type in expressions to have them evaluated. Type :help for more information. scala> var array=Array(1,2,3,4,5,6,7,8,9) array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) scala> var i=sc.makeRDD(array) i: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:26 scala> i.count res0: Long = 9 scala>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
打开 YARN WEB 页面:http://c0:8088 点击左侧的 RUNNING 可以看到 Spark Shell 应用程序正在运行,然后点击右侧 ID,再点击 ApplicationMaster ,能够看到我们刚才运行的

11、常见问题
11.1、Hbase
11.1.1、You have version null and I want version 8. Is your hbase.rootdir valid? If so, you may need to run ‘hbase hbck -fixVersionFile’
重建一下 HBase 文件,执行以下命令,先删除,然后再启动 Hbase 即可解决
hadoop fs -rm -r /hbase
- 1
11.1.2、如何为 Yarn 的 Web 界面增加权限访问限制?
在本文中 Hadoop 的 /home/work/_app/hadoop-3.1.2/etc/hadoop/core-site.xml 文件最后面增加内容,完整的文件内容如下:
[root@c0 ~]# cat /home/work/_app/hadoop-3.1.2/etc/hadoop/core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mshkcluster</value> <description>默认文件系统的名称。一个URI,其方案和权限决定了FileSystem的实现。</description> </property> <property> <name>ha.zookeeper.quorum</name> <value>c0:2181,c1:2181,c2:2181,c3:2181</value> <description>由逗号分隔的ZooKeeper服务器地址列表,由ZKFailoverController在自动故障转移中使用。</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/work/_data/hadoop-3.1.2</value> <description>数据目录目录</description> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> <description>用于服务防护的防护方法列表。可能包含内置方法(例如shell和sshfence)或用户定义的方法。</description> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> <description>用于内置sshfence fencer的SSH私钥文件。</description> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> <description>SequenceFiles中使用的读/写缓冲区的大小。</description> </property> <property> <name>ipc.client.connect.max.retries</name> <value>100</value> <description>客户端为建立服务器连接而重试的次数。</description> </property> <property> <name>ipc.client.connect.retry.interval</name> <value>10000</value> <description>客户端在重试建立服务器连接之前将等待的毫秒数。</description> </property> <property> <name>hadoop.http.filter.initializers</name> <value>org.apache.hadoop.http.lib.StaticUserWebFilter</value> <description>逗号分隔的类名列表。列表中的每个类都必须扩展org.apache.hadoop.http.FilterInitializer。将初始化相应的过滤器。然后,Filter将应用于所有面向用户的jsp和servlet Web页面。</description> </property> <property> <name>hadoop.http.authentication.type</name> <value>simple</value> <description>定义用于Oozie HTTP端点的身份验证。支持的值是:simple |kerberos |#AUTHENTICATION_HANDLER_CLASSNAME#</description> </property> <property> <name>hadoop.http.authentication.token.validity</name> <value>12000</value> <description>指示身份验证令牌在必须续订之前的有效时间(以秒为单位)。</description> </property> <property> <name>hadoop.http.authentication.token.validity</name> <value>12000</value> <description>指示身份验证令牌在必须续订之前的有效时间(以秒为单位)。</description> </property> <property> <name>hadoop.http.authentication.simple.anonymous.allowed</name> <value>false</value> <description>指示使用“简单”身份验证时是否允许匿名请求。</description> </property> <property> <name>hadoop.http.authentication.signature.secret.file</name> <value>/home/work/_app/hadoop-3.1.2/etc/hadoop/hadoop-http-auth-signature-secret</value> <description>用于签署身份验证令牌的路径。</description> </property> <property> <name>hadoop.http.staticuser.user</name> <value>dr.who</value> <description>要在呈现内容时在静态Web过滤器上过滤的用户名。示例用途是HDFS Web UI(用于浏览文件的用户)。</description> </property> <property> <name>hadoop.http.authentication.cookie.domain</name> <value></value> <description>用于存储身份验证令牌的HTTP cookie的域。为了使身份验证在所有Hadoop节点Web控制台上正常工作,必须正确设置域。重要提示:使用IP地址时,浏览器会忽略具有域设置的cookie。 要使此设置正常工作,必须将群集中的所有节点配置为生成具有hostname.domain名称的URL。</description> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
其中 hadoop.http.authentication.signature.secret.file 配置项,是要登录的用户名,向文件中添加用户名hadoop:
[root@c0 ~]# echo "hadoop" > /home/work/_app/hadoop-3.1.2/etc/hadoop/hadoop-http-auth-signature-secret
[root@c0 ~]# cat /home/work/_app/hadoop-3.1.2/etc/hadoop/hadoop-http-auth-signature-secret
hadoop
- 1
- 2
- 3
将配置项,重新复制到全部机器上面,然后重启 Yarn,运行后,在浏览器 http://c0:8080 后面加上 user.name=hadoop ,合并后的网址为:http://c0:8088/cluster?user.name=hadoop
12. 参考资料
how-to-set-up-hadoop-cluster-with-hdfs-high-availability
HDFS High Availability Using the Quorum Journal Manager
HDFS High Availability

