
- 1Python机器学习之LogisticRegression——鸢尾花分类_sklearn logistregression 鸢尾花
- 2Notion AI 进阶【help me write】_notion prompt
- 3linux中函数使用,Linux中likely 函数的使用分析
- 4城市郊野公园“风筝节”AI识别技术与视频监控技术的应用
- 5解决pyqt5过段时间自己崩了,打不开QT designer的问题_pyqt5太容易崩溃了
- 6深度学习识别 验证码_深度学习易分割验证码识别
- 72023华为软件精英挑战赛笔记心得(Python实现)_华为软挑
- 8python熵权法过程中,权重出现nan值问题_熵权法求权重时,结果为nan怎么解决matlab
- 9关于嵌入式学习的前期路线规划_龙顺宇
- 10将树莓派设置为AP的方法_dhcpcd dnsmasq
Transformer位置编码(Position Embedding)理解_transformer的位置编码是绝对还是相对位置编码
赞
踩
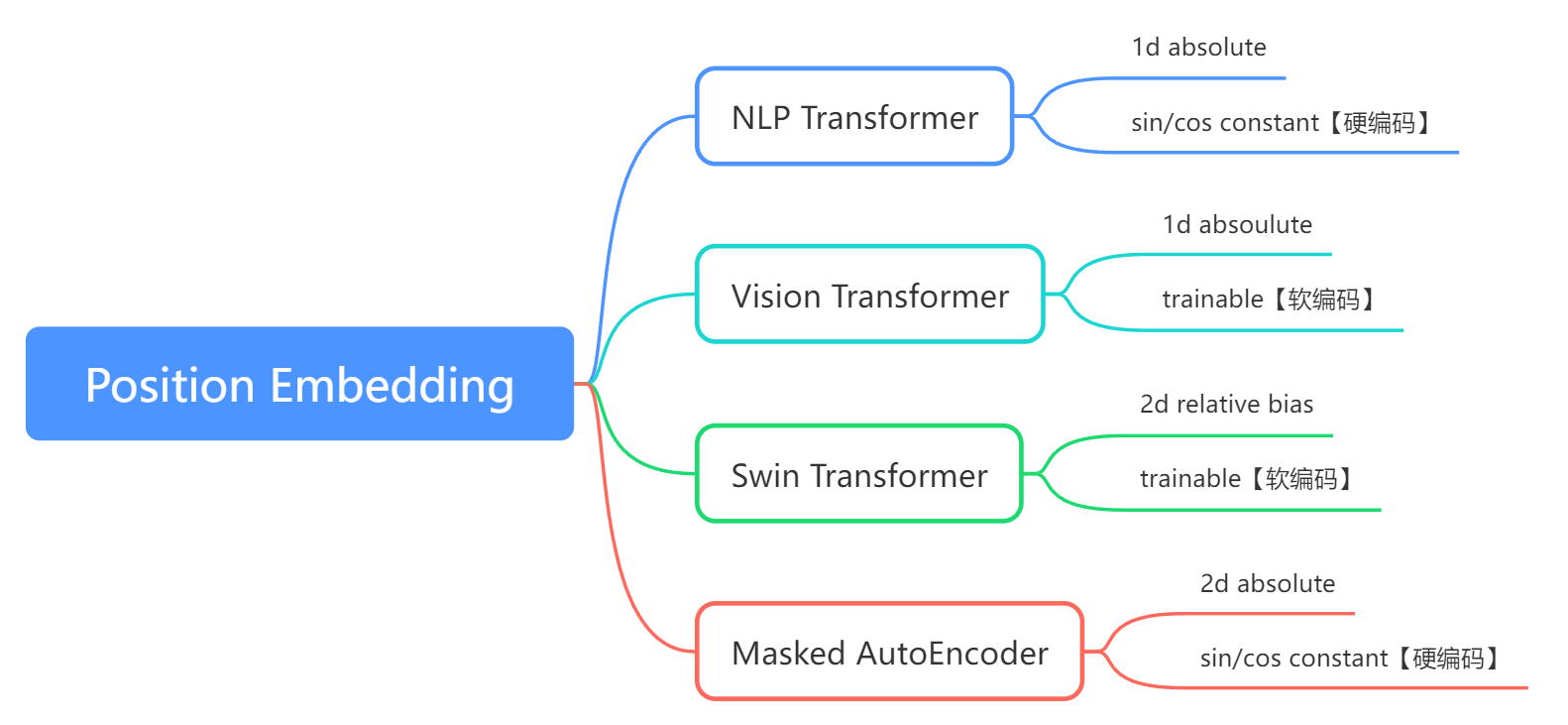
本文主要介绍4种位置编码,分别是NLP发源的transformer、ViT、Sw-Transformer、MAE的Position Embedding
一、NLP transformer
使用的是1d的绝对位置编码,使用sin+cos将每个token编码为一个向量【硬编码】
Attention Is All You Need
在语言中,单词的顺序及其在句子中的位置非常重要。 如果重新排列单词,整个句子的意思可能会发生变化。 因此,位置信息被明确地添加到模型中,以保留有关句子中单词顺序的信息。

1、why 位置编码?
位置编码描述了序列中每个单词(token)的位置或位置,以便为每个位置分配一个唯一的表示。 不使用单个数字(例如索引值)来表示位置的原因有很多。 对于长序列,索引的幅度可能会变大, 如果将索引值规范化为介于 0 和 1 之间,则可能会为可变长度序列带来问题,因为它们的规范化方式不同。
Transformers 将每个单词的位置都映射到一个向量。 因此,一个句子的位置编码是一个矩阵,其中矩阵的每一行代表序列中的一个token与其位置信息相加。 下图显示了仅对位置信息进行编码的矩阵示例:
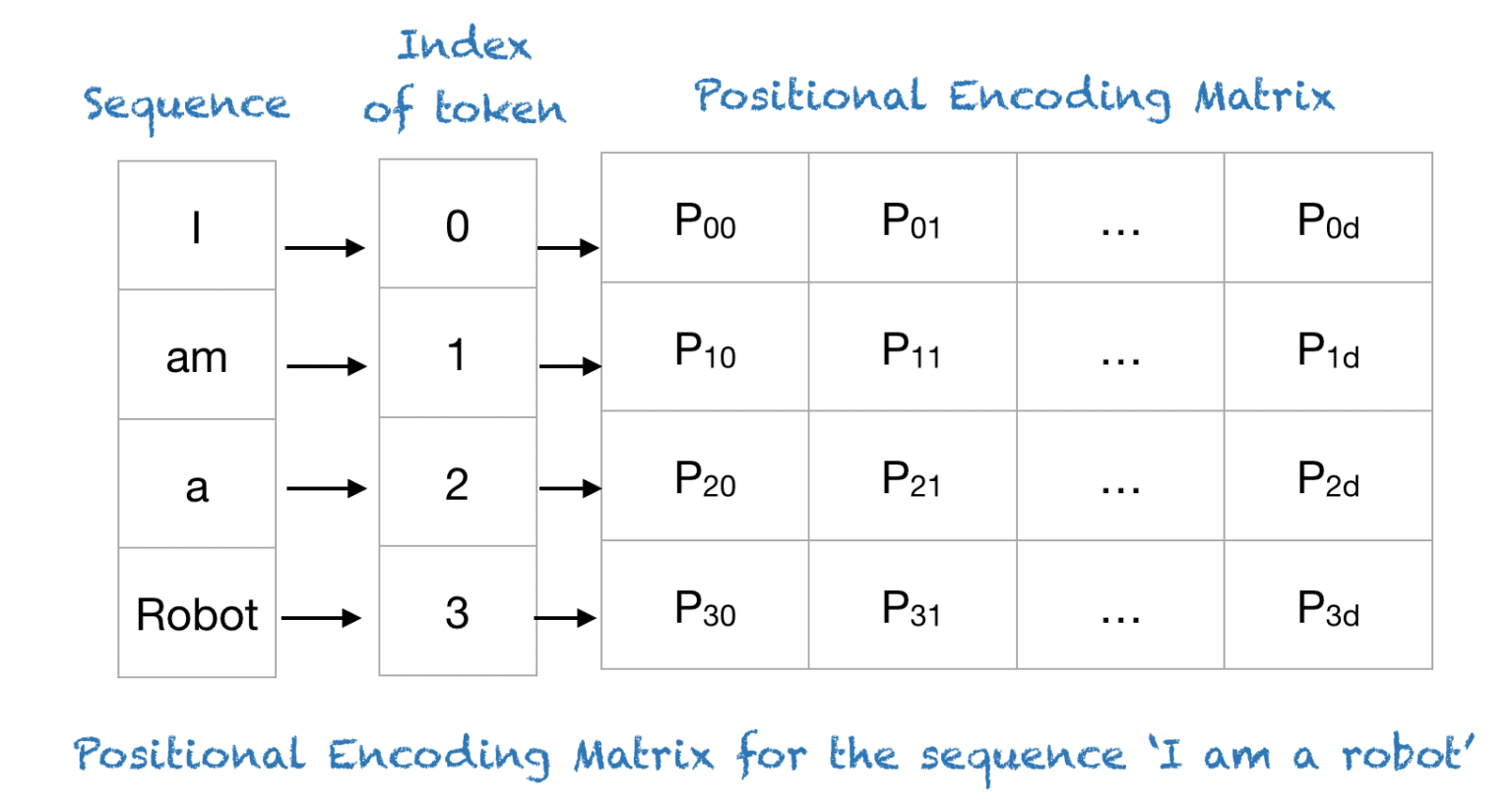
2、位置编码计算公式:
1D absolute sincos constant position embedding 位置编码的计算公式:
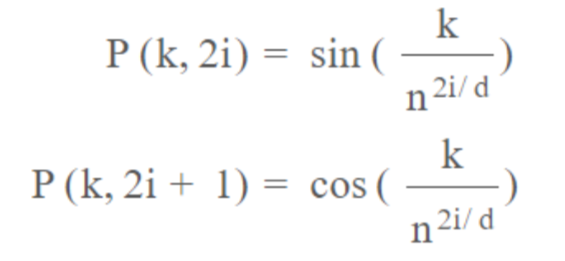
- k:token在输入序列中的位置,0<=k<=L-1
- d: 位置编码嵌入空间的维度
- P(k,j): 位置函数,用于映射输入序列中k处的元素到位置矩阵的(k,j)处
- n:用户定义的标量,由 Attention Is All You Need 的作者设置为 10,000。
- i: 用于映射到列索引,0<=i<d/2,单个值i映射到正弦和余弦函数【这是因为使用了sin+cos,所以一次可以给张量的两个维度计算position value,所以只需要d/2个i就可以了】
3、位置编码计算示例
让我们以 n=100 和 d=4 的短语“I am a robot”为例。
这样就将每个单词的position映射到一个4维度的张量中了,并且每个单词对应的张量是不同的

一个简单的实现:
- import torch
-
- # Section : 1. 1D absolute sincos constant position embedding
- def create_1d_absolute_sincos_embedding(n_pos_vec, dim):
- # n_pos_vec: torch.arange(n_pos, dtype=torch.float)
- # dim: torch.arange(dim)
- assert dim % 2 == 0, "dim must be even"
- # 常数初始化一下position_embedding
- position_embedding = torch.zeros(n_pos_vec.numel(), dim, dtype=torch.float)
- # 完成指数部分的初始化
- omege = torch.arange(dim // 2, dtype=torch.float)
- omege /= dim / 2.
- omege = 1./(100 ** omege)
- # 扩充列向量和行向量:行数为pos, 列数为dim/2
- out = n_pos_vec[:, None] @ omege[None, :]
- emb_sin = torch.sin(out)
- emb_cos = torch.cos(out)
- # 交替填充:偶数列为sin, 奇数列为cos
- position_embedding[:, 0::2] = emb_sin
- position_embedding[:, 1::2] = emb_cos
-
- return position_embedding
-
- if __name__ == "__main__":
- n_pos = 4
- dim = 4
- n_pos_vec = torch.arange(n_pos, dtype=torch.float)
- position_embedding = create_1d_absolute_sincos_embedding(n_pos_vec, dim)
- print(position_embedding.shape)
- print(position_embedding)
输出:

二、Vision Transformer
使用的是1d的绝对位置编码,但是这个位置编码是可训练的(可学习的)。【软编码】
其实我感觉这种软编码,相对于硬编码来说不是很好,因为它并没有将位置的归纳偏置给模型,这种方式更像是增加了模型参数量的感觉。
【ICLR 2021】An Image is Worth 16x16 Words + Transformers for Image Recognition at Scale
代码实现:
- import torch
- import torch.nn as nn
-
- # Section : 2. 1D absolute trainable position embedding
- def create_1d_absolute_trainable_embedding(n_pos_vec, dim):
- # 创建一个n_pos_vec * dim维度的绝对位置编码的embedding,这个embedding是可以训练的。【与torch.nn.Parameter()用法有一些类似】
- position_embedding = nn.Embedding(n_pos_vec.numel(), dim)
- # 初始化嵌入层的权重为0
- nn.init.constant_(position_embedding.weight, 0)
- return position_embedding
-
- if __name__ == "__main__":
- n_pos = 3
- dim = 4
- n_pos_vec = torch.arange(n_pos, dtype=torch.float)
- position_embedding = create_1d_absolute_trainable_embedding(n_pos_vec, dim)
- print(position_embedding)
三、Swin Transformer
四、Masked AutoEncoder(MAE)
# TODO:待更新...懒得写了,大概你知道PE的意思就行了
transformer计算位置编码的过程示例_哔哩哔哩_bilibili
46、四种Position Embedding的原理与PyTorch手写逐行实现(Transformer/ViT/Swin-T/MAE)_哔哩哔哩_bilibili

