
- 1合合信息分享数据资产管理经验,释放数据要素价值,发展新质生产力
- 2计算机网络(谢希仁版)思维导图_计算机网络思维导图谢希仁
- 3华为OD机试 Python -开源项目热度榜单
- 42024不可不会的StableDiffusion之图生图(七)_stable diffusion图生图 2024
- 5基于Spring Boot的宠物咖啡馆平台的设计与实现
- 6MySQL前缀索引(3/16)
- 712.FastAPI响应状态码_python fastapi 定义 返回结果 code
- 8转: 深入理解MSTP域和端口角色
- 9Vue.js介绍以及优缺点_大学生对vue.js 框架简介
- 102023 CCF中国软件大会(CCF ChinaSoft)“工业嵌入式基础软件”成功召开
【机器学习300问】75、如何理解深度学习中Dropout正则化技术?
赞
踩
一、Dropout正则化的原理是什么?
Dropout(随机失活)正则化是一种用于减少神经网络中过拟合现象的技术。Dropout正则化的做法是:
在训练过程中的每次迭代中,随机将网络中的一部分权重临时"丢弃"(即将它们的值设为0),确保它们不参与前向传播和后向传播。换句话说,每个神经元有一定的概率被暂时从网络中移除。通过这种方式,网络的每次训练迭代都是在一种略微不同的架构下完成的。这相当于在训练一个由多个不同网络组成的大型网络组合。
通常,丢弃的概率(dropout rate)是一个预先设定的值,如0.5,意味着在每一轮训练中,大约有一半的隐藏层神经元会被暂时忽略。有时候也反过来设置一个保留概率(keep-prob)操作和上面类似。

二、如何具体实现Dropout?
用下面这幅图为例来详细说明一下Dropout的步骤
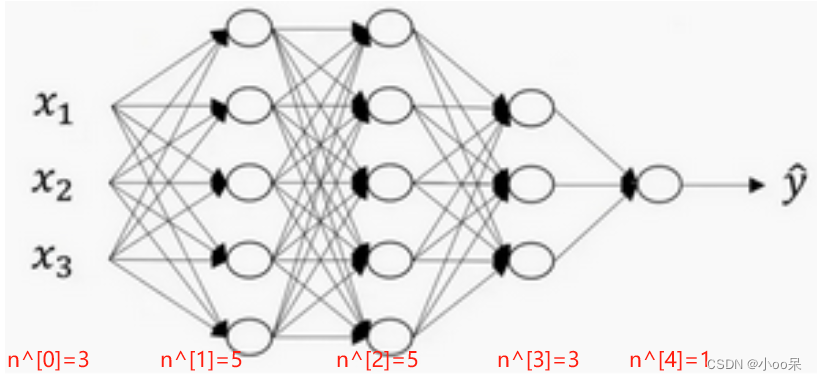
(1)确定Dropout率
dropout_rate是一个超参数,表示在每次训练迭代中神经元被丢弃的概率。设定为 p,通常在0.2到0.5之间。
keep_prob = 1 - dropout_rate(2)生成随机的Dropout掩码
Dropout最常用的方法,即inverted dropout(反向随机失活),首先要定义Dropout掩码向量dropout_mask。然后看它是否小于某数,我们称之为keep_prob,keep_prob是一个具体数字,而本例将它设为0.8,它表示保留某个隐藏单元的概率,此处keep-prob等于0.8,它意味着消除任意一个隐藏单元的概率是0.2,它的作用就是生成随机矩阵。
dropout_mask = np.random.rand(activations.shape[0], activations.shape[1]) < keep_prob接下来要做的就是从某一层中获取激活函数,这里我叫它activations,activations其中含有要计算的激活函数。
(3)应用掩码
将activations和dropout_mask相乘,它的作用就是让dropout_mask中所有等于0的元素(输出),而各个元素等于0的概率只有20%,乘法运算最终把dropout_mask中相应元素输出,即让dropout_mask中0元素与activations中相对元素归零。
activations *= dropout_mask # 将神经元的输出乘以0或1(4)Dropout缩放
在测试或使用神经网络进行预测时,通常不会应用Dropout。但是,为了平衡那些在训练时被“保留下来”的权重,我们对网络中每个权重乘以保留(未丢弃)概率,或者是在测试时使用所有权重的平均值。这种方法称为“Dropout缩放”,它确保了训练时和测试时网络的表现是一致的。
activations /= keep_prob # 缩放未丢弃的神经元的输出(5)总结
将上面的步骤总结起来,可以写成这样:
- def apply_dropout(activations, dropout_rate):
- # Step 1: 确定保留的神经元的概率
- keep_prob = 1 - dropout_rate
-
- # Step 2: 生成随机的Dropout掩码
- dropout_mask = np.random.rand(activations.shape[0], activations.shape[1]) < keep_prob
-
- # Step 3: 应用掩码并缩放
- activations *= dropout_mask # 将神经元的输出乘以0或1
- activations /= keep_prob # 缩放未丢弃的神经元的输出
-
- return activations
需要特别说一下的是,不同层的keep_prob是可以不同的,因为不同层的W权重矩阵的大小不同,一般我们担心这些层更容易发生过拟合,对很大的权重矩阵设置比较低的keep_prob假设是0.5。对于其它层,过拟合的程度可能没那么严重,它们的keep-prob值可能高一些,可能是0.7。如果在某一层,我们不必担心其过拟合的问题,那么keep-prob可以为1意味着保留所有单元,并且不在这一层使用dropout。
三、为什么Dropout会起作用?它是怎么解决过拟合的?
这种随机性的丢弃操作带来了几个重要的好处。
(1)抑制神经元对单一特征的过度依赖
如果某些神经元对应的权重值过大,它们对输入信号的响应将显著超过其他神经元,使得模型在做决策时过度依赖这些神经元所代表的特征,形成了对单一特征的过度敏感。
Dropout通过随机失活隐藏层神经元,打破了神经元对单一特征的固定依赖关系,迫使模型在不同训练迭代中学习不同的特征组合,降低了对特定特征的敏感度。
(2)抑制神经元之间过度依赖
在没有Dropout的情况下,某些神经元可能会形成过于紧密的协作关系,对训练数据中的特定模式过拟合,导致模型在遇到未见过的数据时表现不佳。
Dropout通过随机移除部分神经元,迫使剩余神经元独立地学习更通用、更稳健的特征表示,降低模型对个别特征或特征组合的敏感度,强制网络在训练时不能过度依赖任何一组特定的神经元,因为特定的神经元随时有可能被失活。从而减轻过拟合现象。
(3)模拟集成学习
Dropout过程可以被视为对神经网络进行集成学习的一种近似。由于每次前向传播时神经元的失活是随机的,网络在训练过程中实际上经历了大量不同的子网络配置。这些子网络可以看作是原始网络的多个变体,每个变体以不同的方式对输入数据进行处理。
尽管在测试阶段所有神经元都会恢复工作,但经过Dropout训练的网络权重实际上是众多子网络权重的加权平均,类似于集成学习中的模型平均,有助于减少模型的方差,提高泛化性能。

