
热门标签
热门文章
- 1论文阅读之Robot Learning System Based on Adaptive Neural Control and Dynamic Movement Primitives_杨辰光
- 2Python的分布式系统与Celery实战
- 3postgresql远程连接中断_postgres 连接经常断开
- 4uniapp通过custom-tab-bar 自定义tabbar导航栏(主要用于微信小程序)_uniapp自定义导航栏custom
- 5《精通PHP+MySQL动态网站开发》_php5+mysql网站开发基础与应用 心得
- 6数字化转型的人工智能与人机交互 2
- 7python中import,from……import使用方法_python中from import怎么用
- 8https://leetcode.com
- 9C语言进阶——动态内存管理
- 10输入n个字符串,进行排序,然后从小到大输出_一行内输入n个字符串,按字典序从小到大进行排序后输出。
当前位置: article > 正文
kafka初体验基础认知部署_第1关:kafka - 初体验
作者:笔触狂放9 | 2024-06-04 07:59:17
赞
踩
第1关:kafka - 初体验
kafka 基础介绍
Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发并于2011年开源。它主要用于解决大规模数据的实时流式处理和数据管道问题。
Kafka是一个分布式的发布-订阅消息系统,可以快速地处理高吞吐量的数据流,并将数据实时地分发到多个消费者中。Kafk消息系统由多个**broker(服务器)组成,这些broker可以在多个数据中心之间分布式部署,以提供高可用性和容错性。Kafka的基本架构由生产者、消费者和主题(topic)**组成。生产者可以将数据发布到指定的主题,而消费者可以订阅这些主题并消费其中的数据。同时,Kafka还支持数据流的处理和转换,可以在管道中通过Kafka Streams API进行流式计算,例如过滤、转换、聚合等。Kafka使用高效的数据存储和管理技术,能够轻松地处理TB级别的数据量。其优点包括高吞吐量、低延迟、可扩展性、持久性和容错性等。
Kafka在企业级应用中被广泛应用,包括实时流处理、日志聚合、监控和数据分析等方面。同时,Kafka还可以与其他大数据工具集成,如Hadoop、Spark和Storm等,构建一个完整的数据处理生态系统
如何部署一个单机的kafka
kafka自带的脚本
[root@localhost kafka_2.13-3.5.1]# ls bin/ connect-distributed.sh kafka-e2e-latency.sh kafka-server-stop.sh connect-mirror-maker.sh kafka-features.sh kafka-storage.sh connect-standalone.sh kafka-get-offsets.sh kafka-streams-application-reset.sh kafka-acls.sh kafka-jmx.sh kafka-topics.sh kafka-broker-api-versions.sh kafka-leader-election.sh kafka-transactions.sh kafka-cluster.sh kafka-log-dirs.sh kafka-verifiable-consumer.sh kafka-configs.sh kafka-metadata-quorum.sh kafka-verifiable-producer.sh kafka-console-consumer.sh kafka-metadata-shell.sh trogdor.sh kafka-console-producer.sh kafka-mirror-maker.sh windows kafka-consumer-groups.sh kafka-producer-perf-test.sh zookeeper-security-migration.sh kafka-consumer-perf-test.sh kafka-reassign-partitions.sh zookeeper-server-start.sh kafka-delegation-tokens.sh kafka-replica-verification.sh zookeeper-server-stop.sh kafka-delete-records.sh kafka-run-class.sh zookeeper-shell.sh kafka-dump-log.sh kafka-server-start.sh

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
启动注册中心
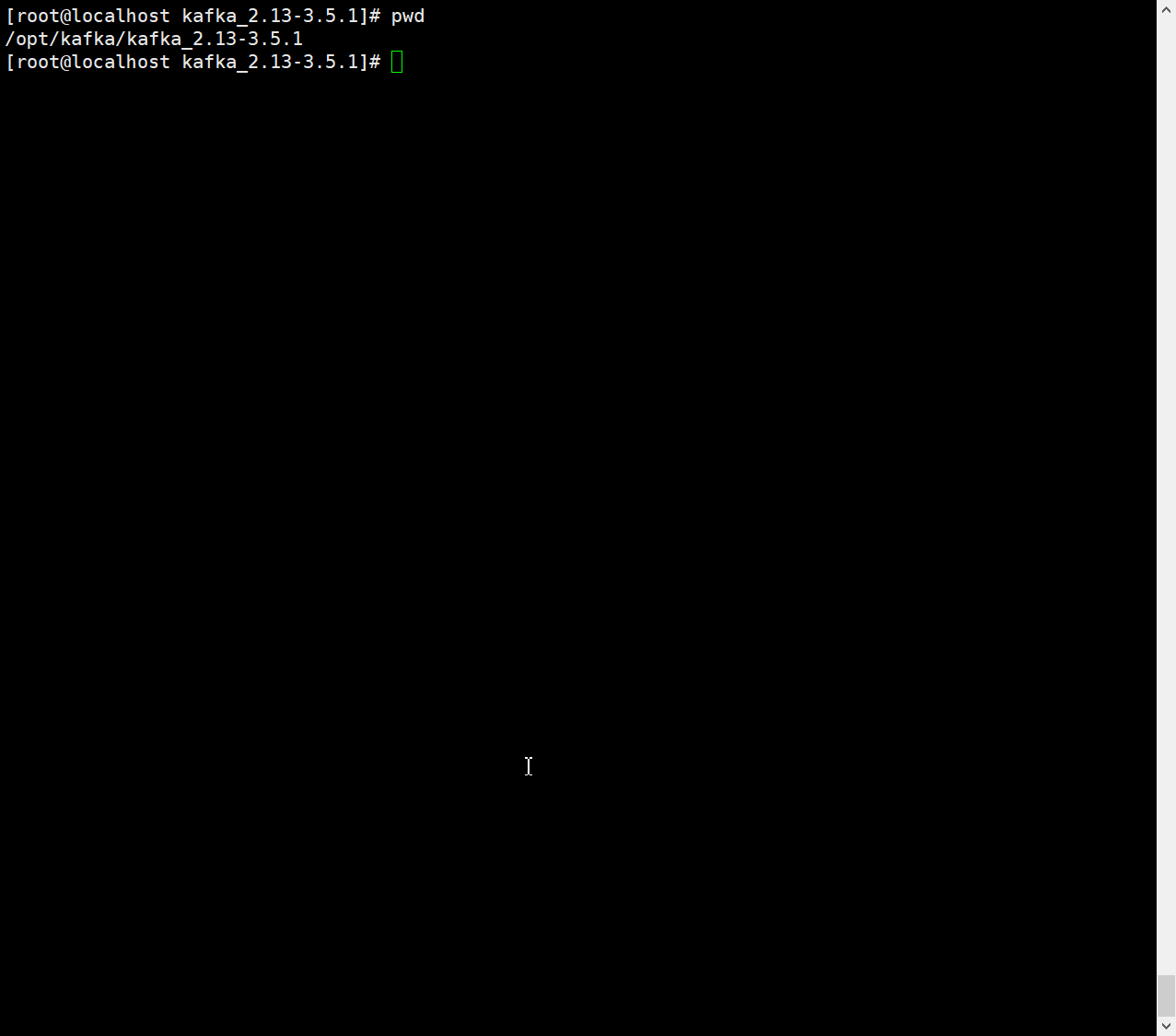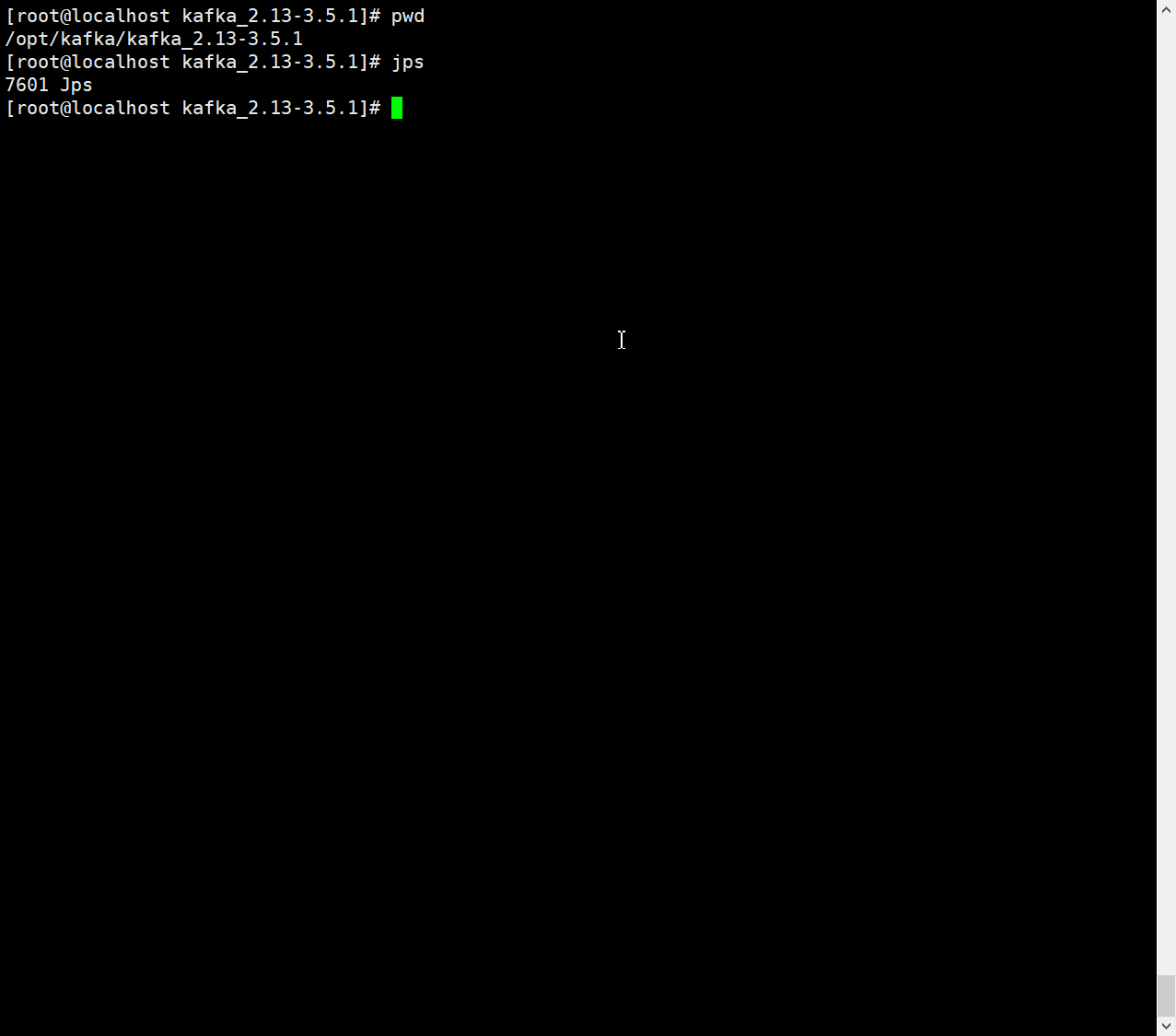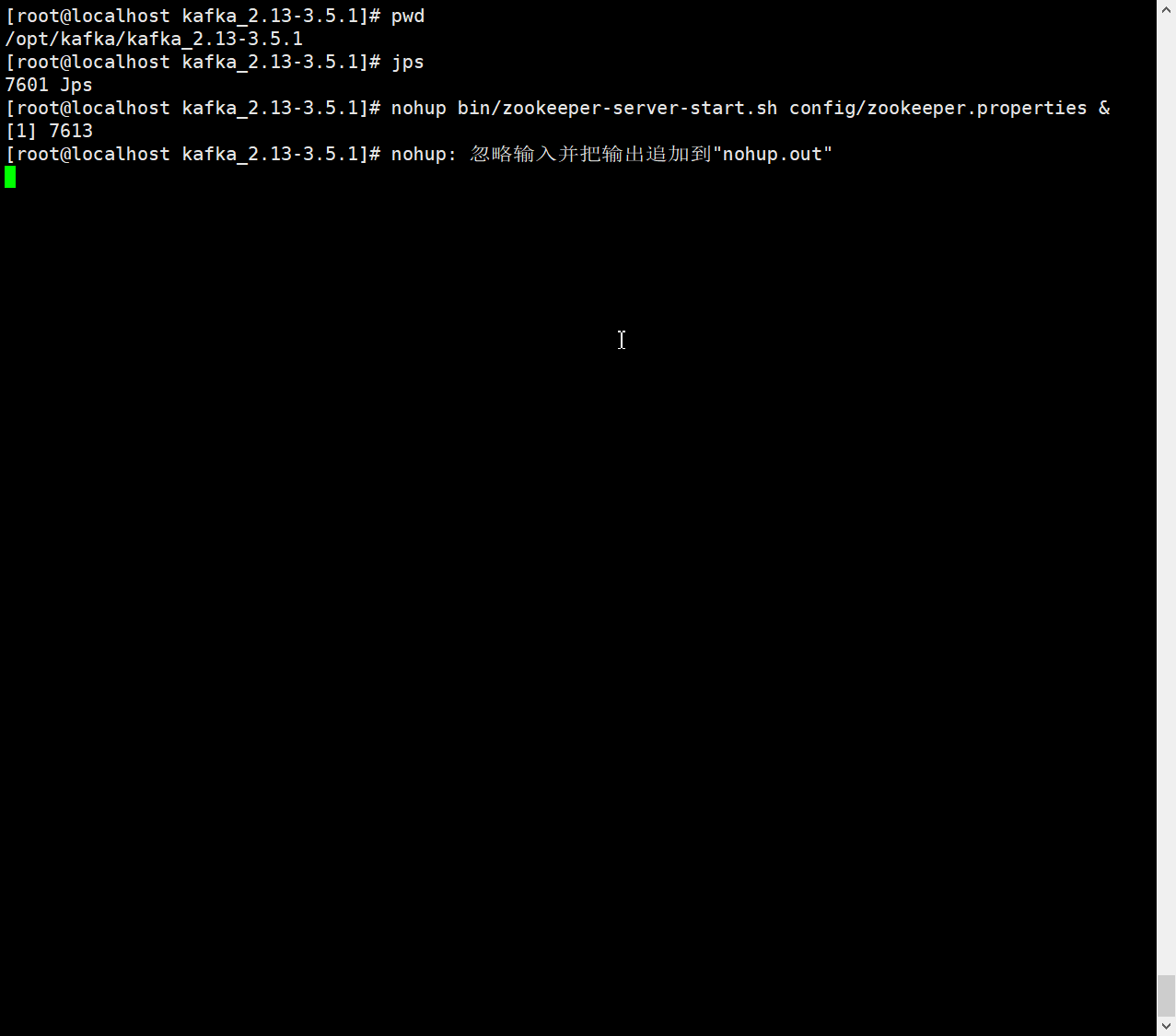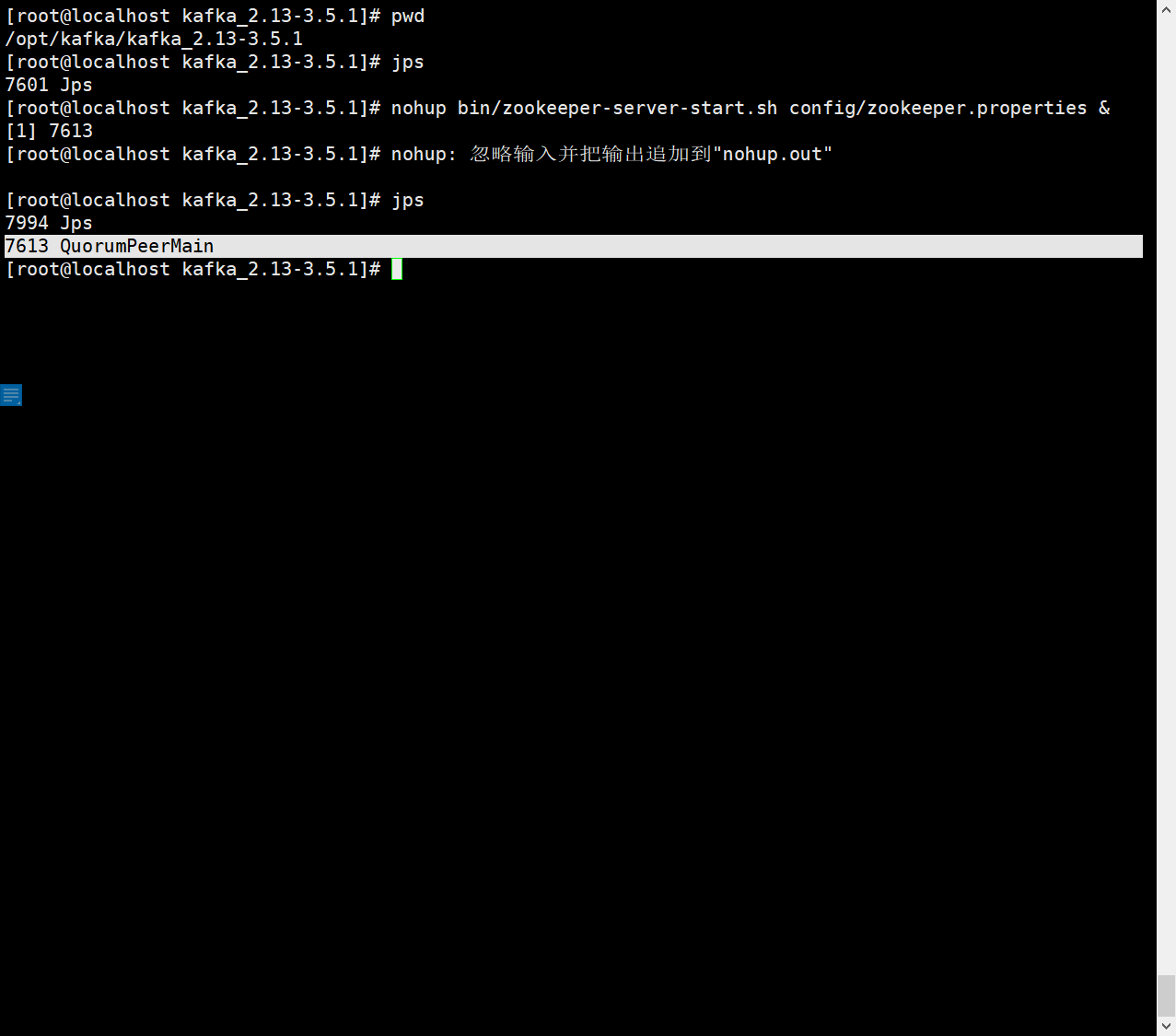
单机演示直接使用kafka内部自带的zookeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
- 1
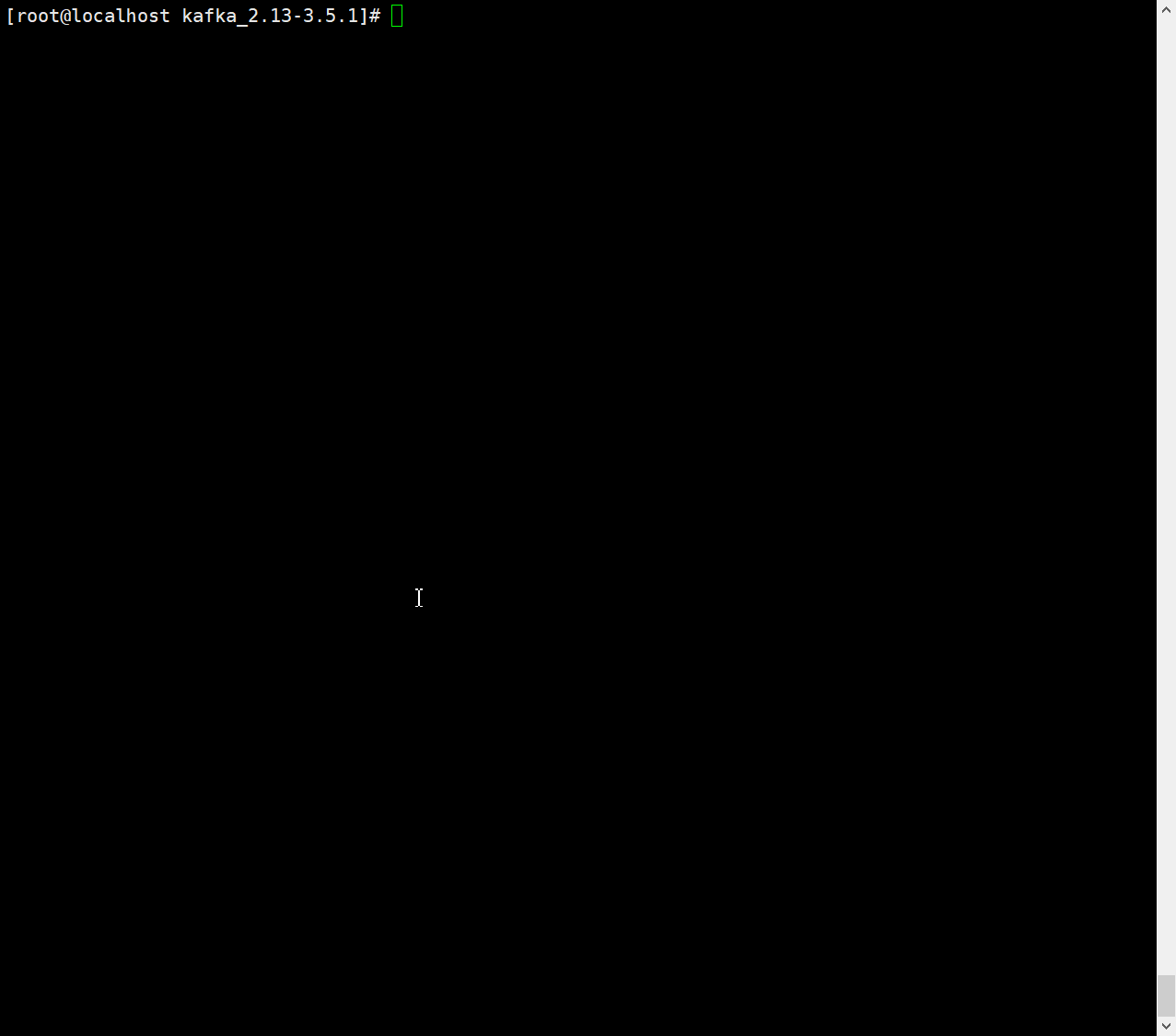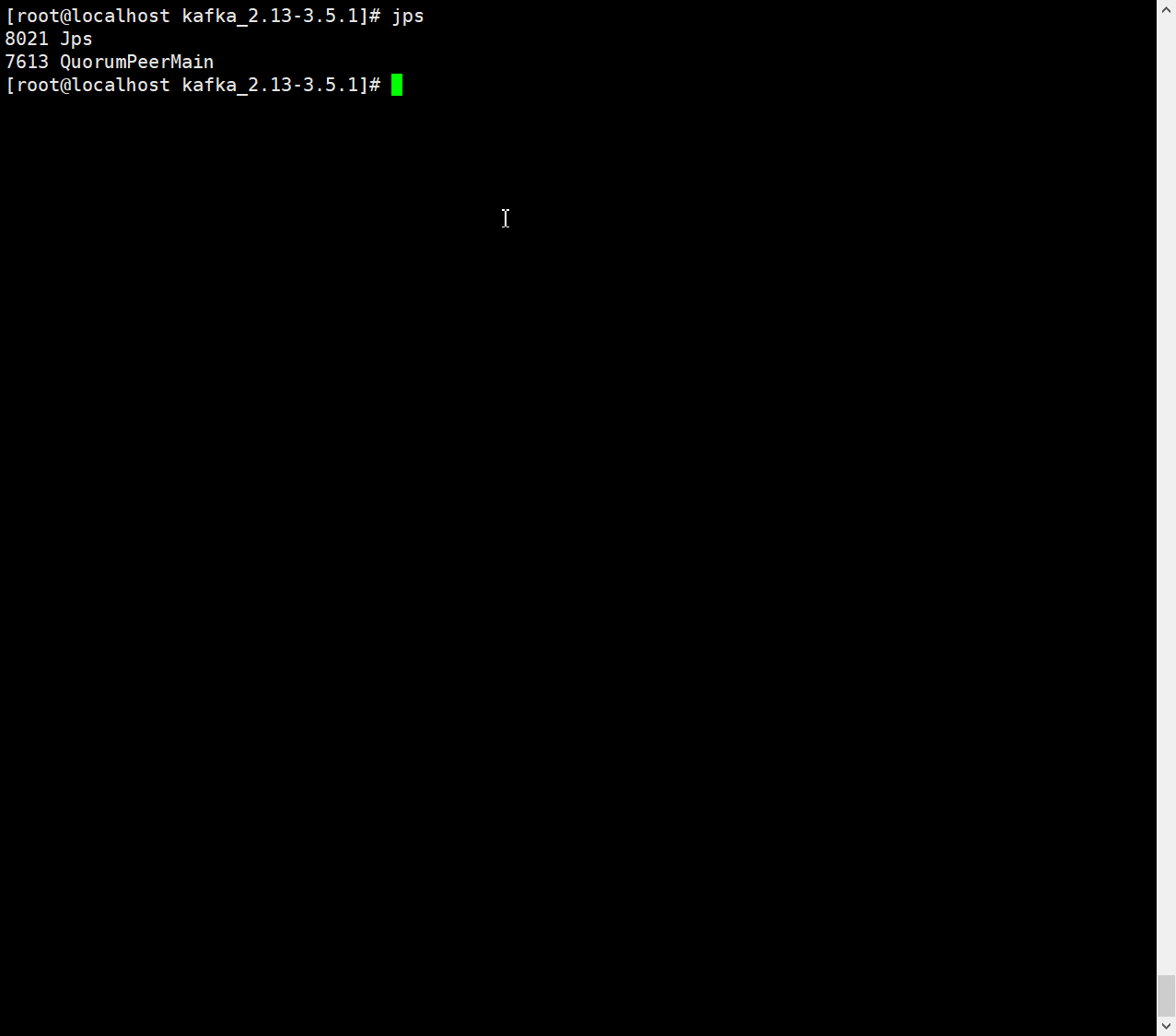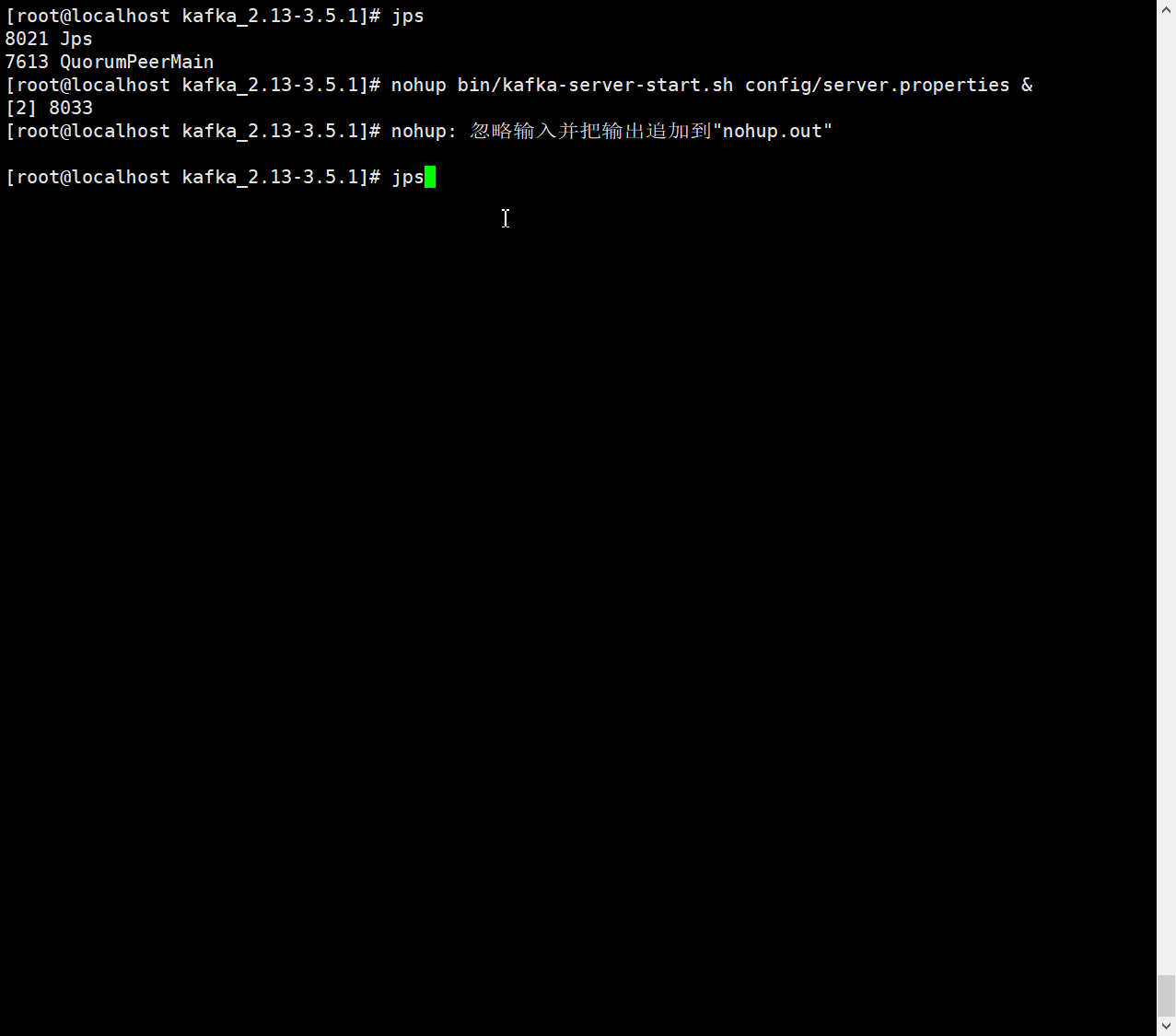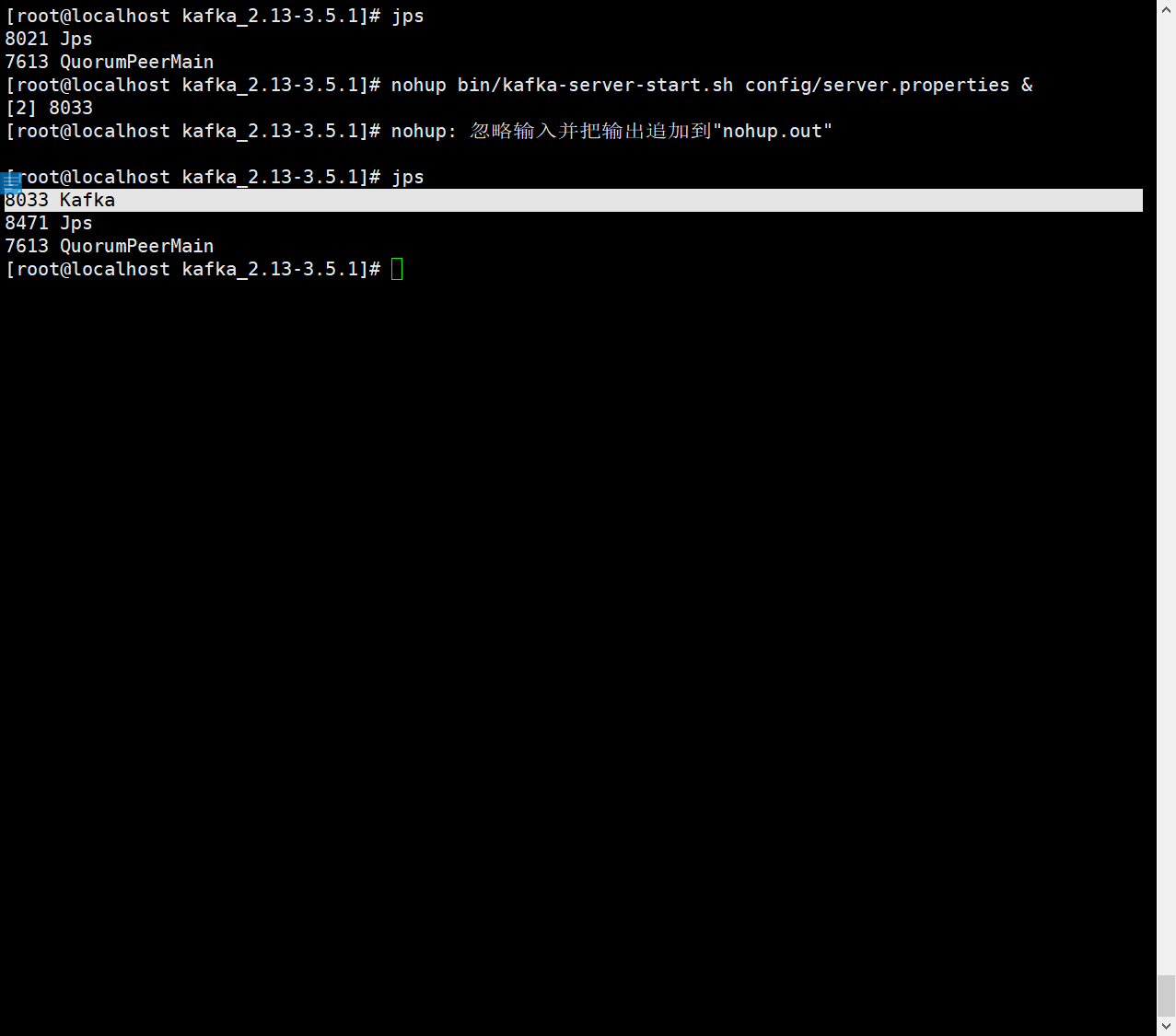
启动kafka服务(broker)
nohup bin/kafka-server-start.sh config/server.properties &
- 1
创建topic
#在机器localhost:9092上创建Topic test
bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092
#查看Topic
bin/kafka-topics.sh --describe --topic test --bootstrap-server localhost:9092
- 1
- 2
- 3
- 4

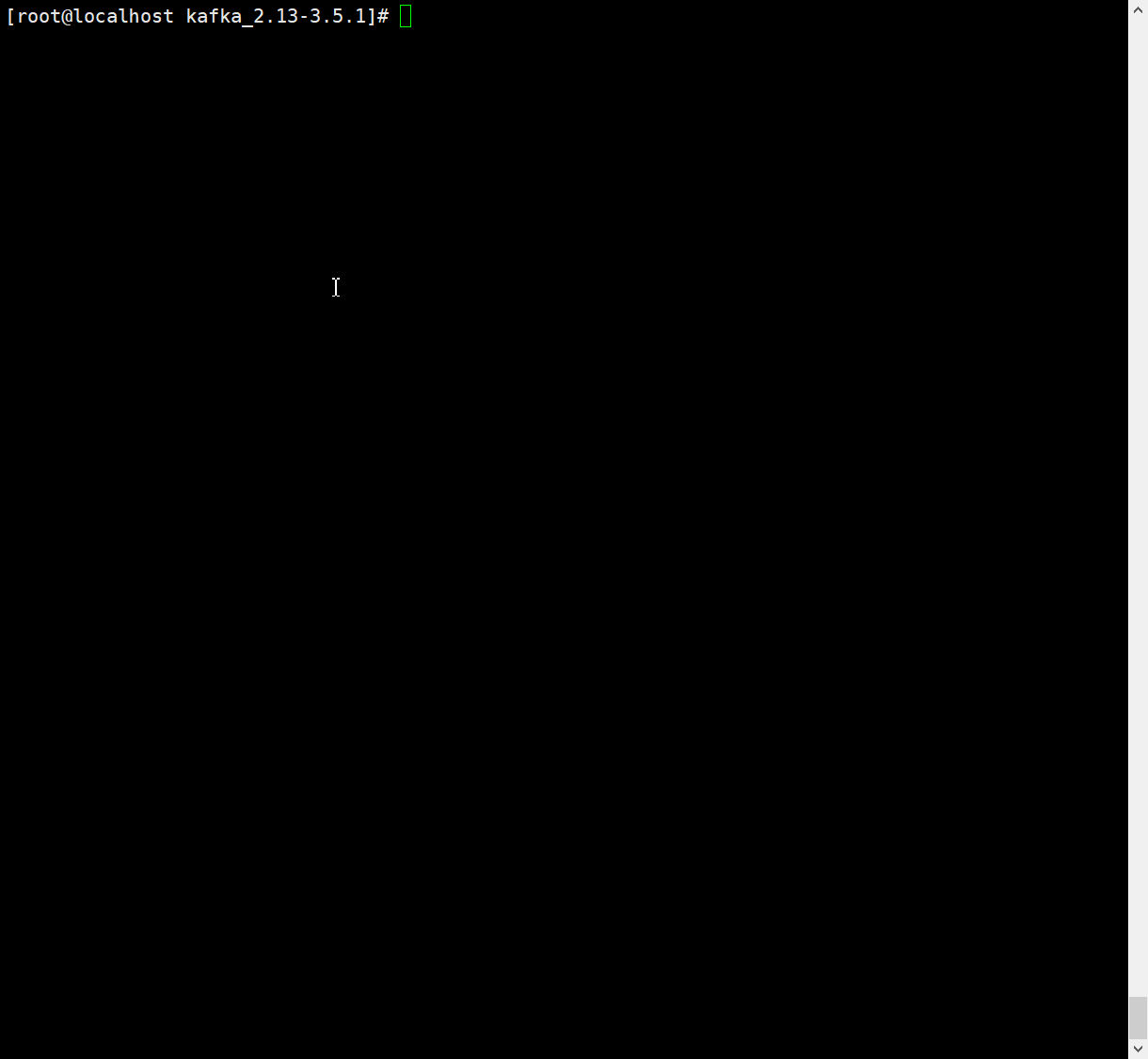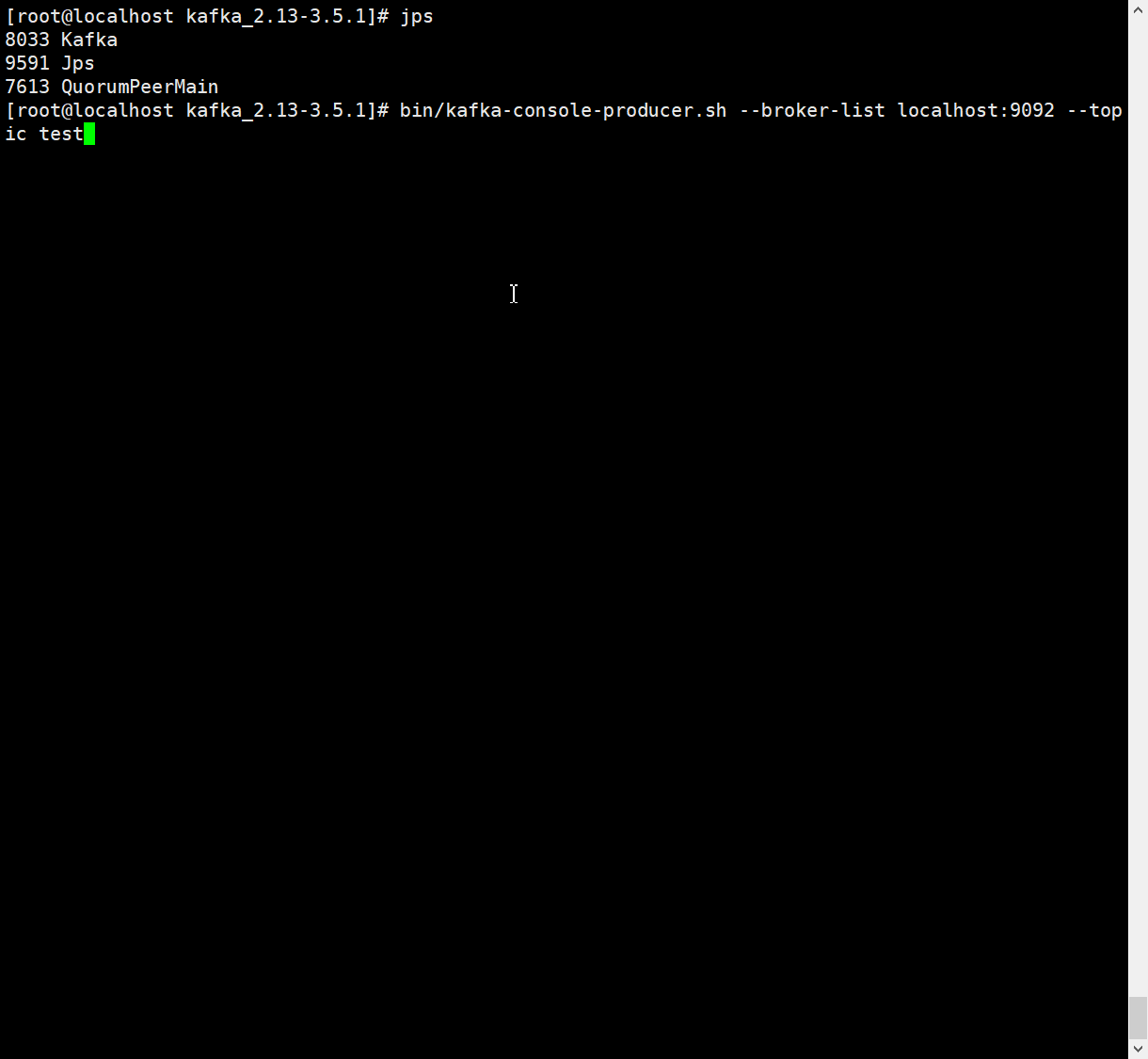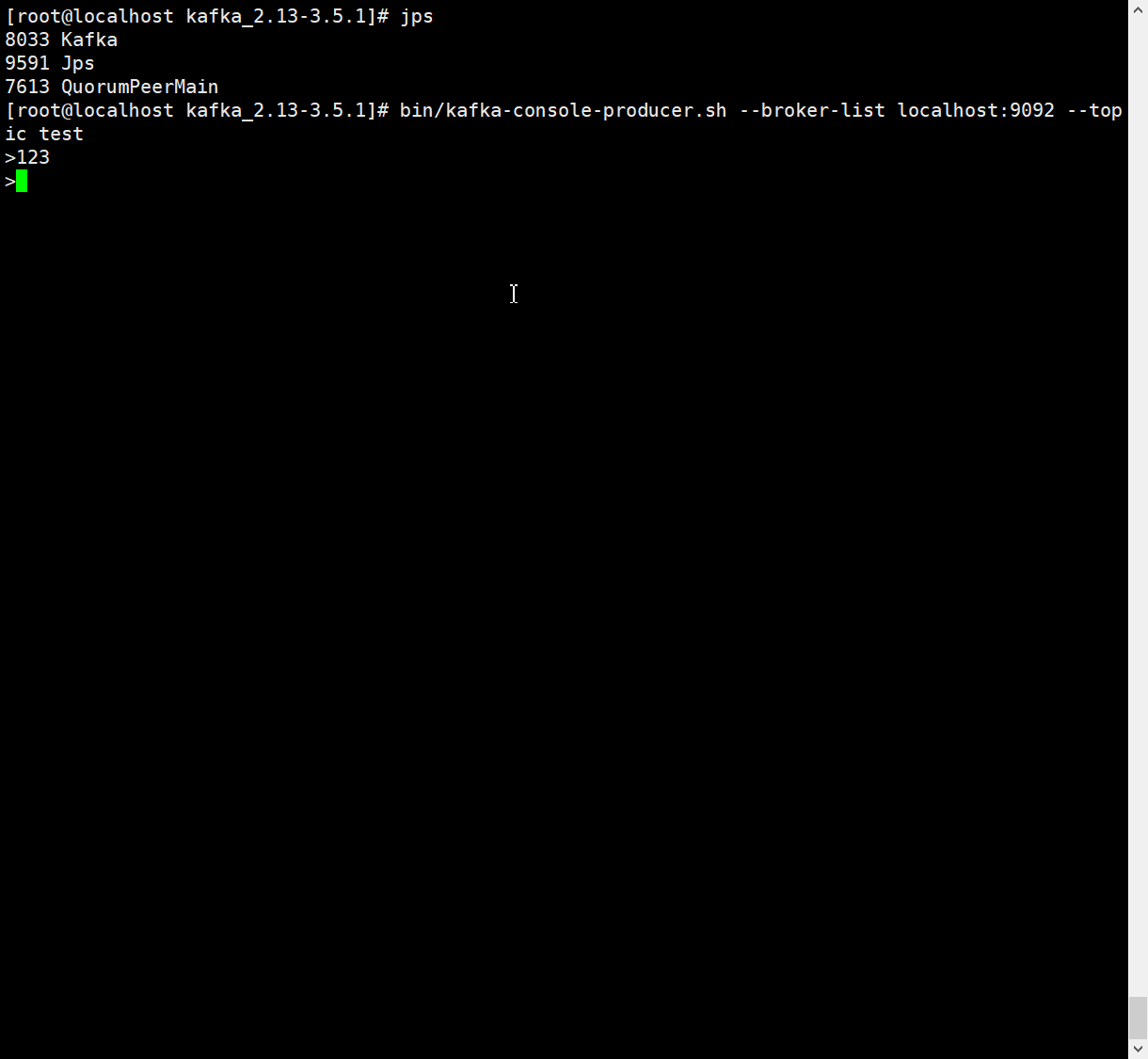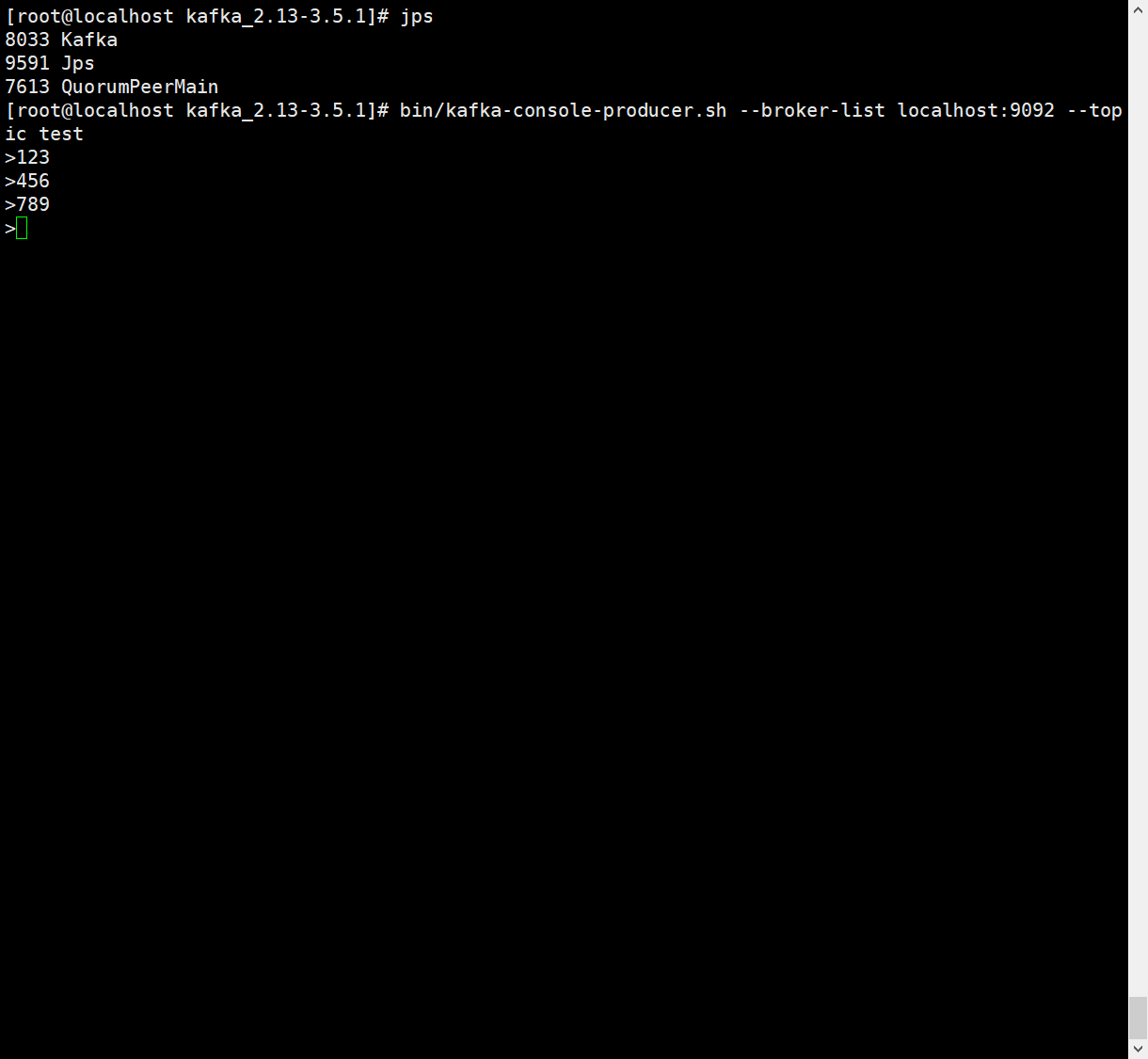
发送消息
# 生产消息topic为test 指定kafka机器为localhost:9092
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
- 1
- 2
消费消息
# 指定消费kafka机器为localhost:9092 ,topic为test的消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
- 1
- 2
从头开始消费
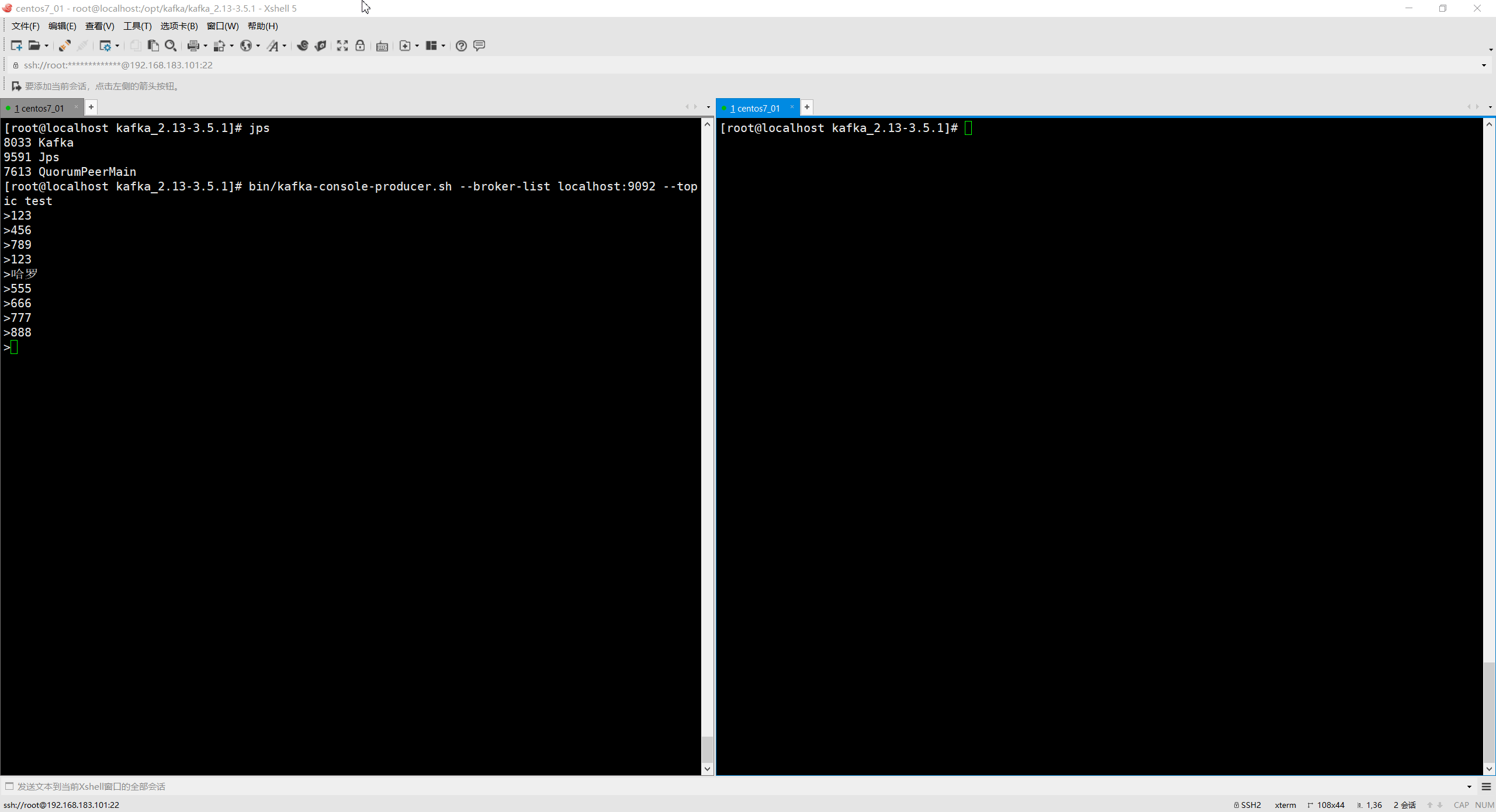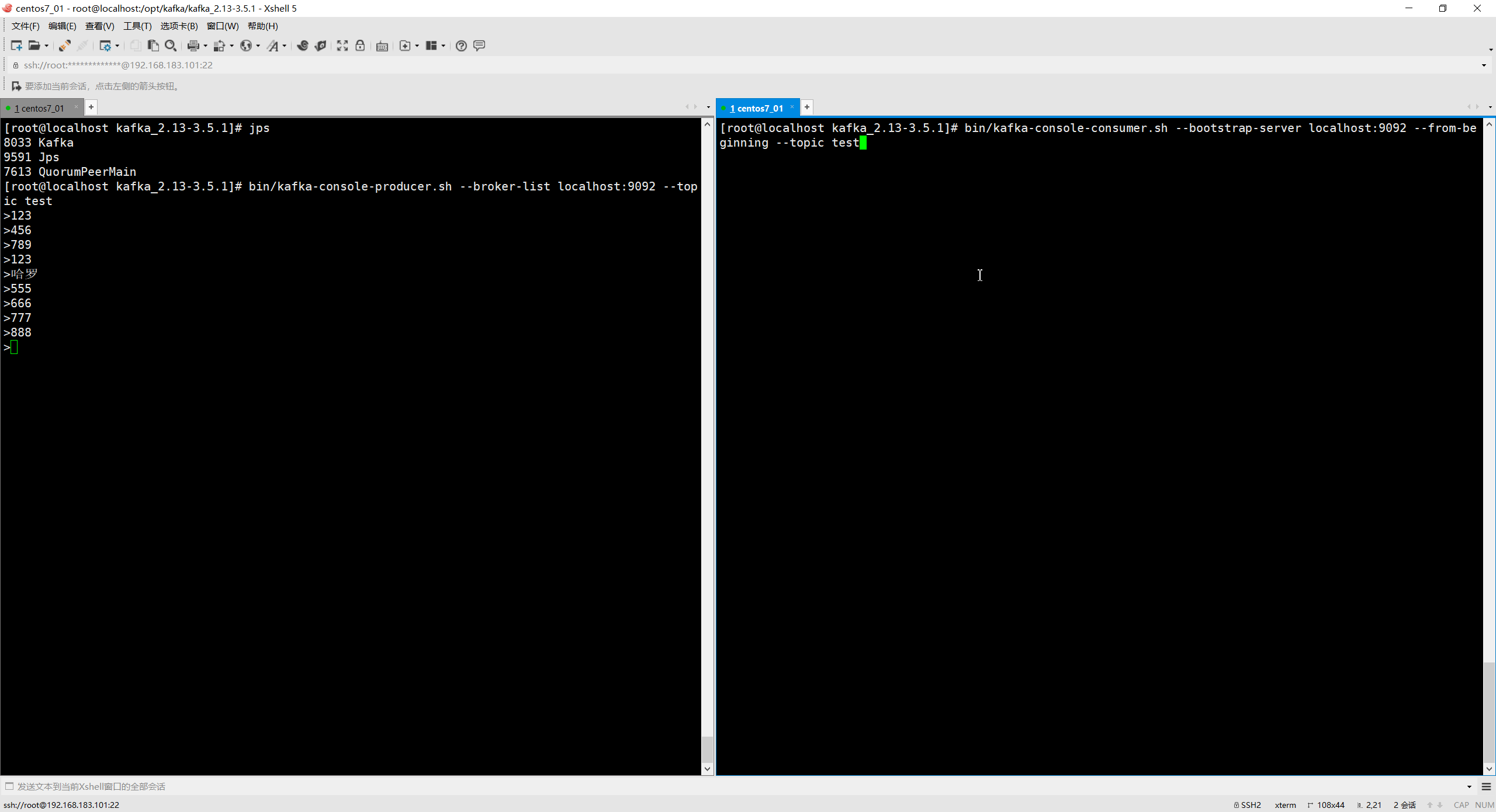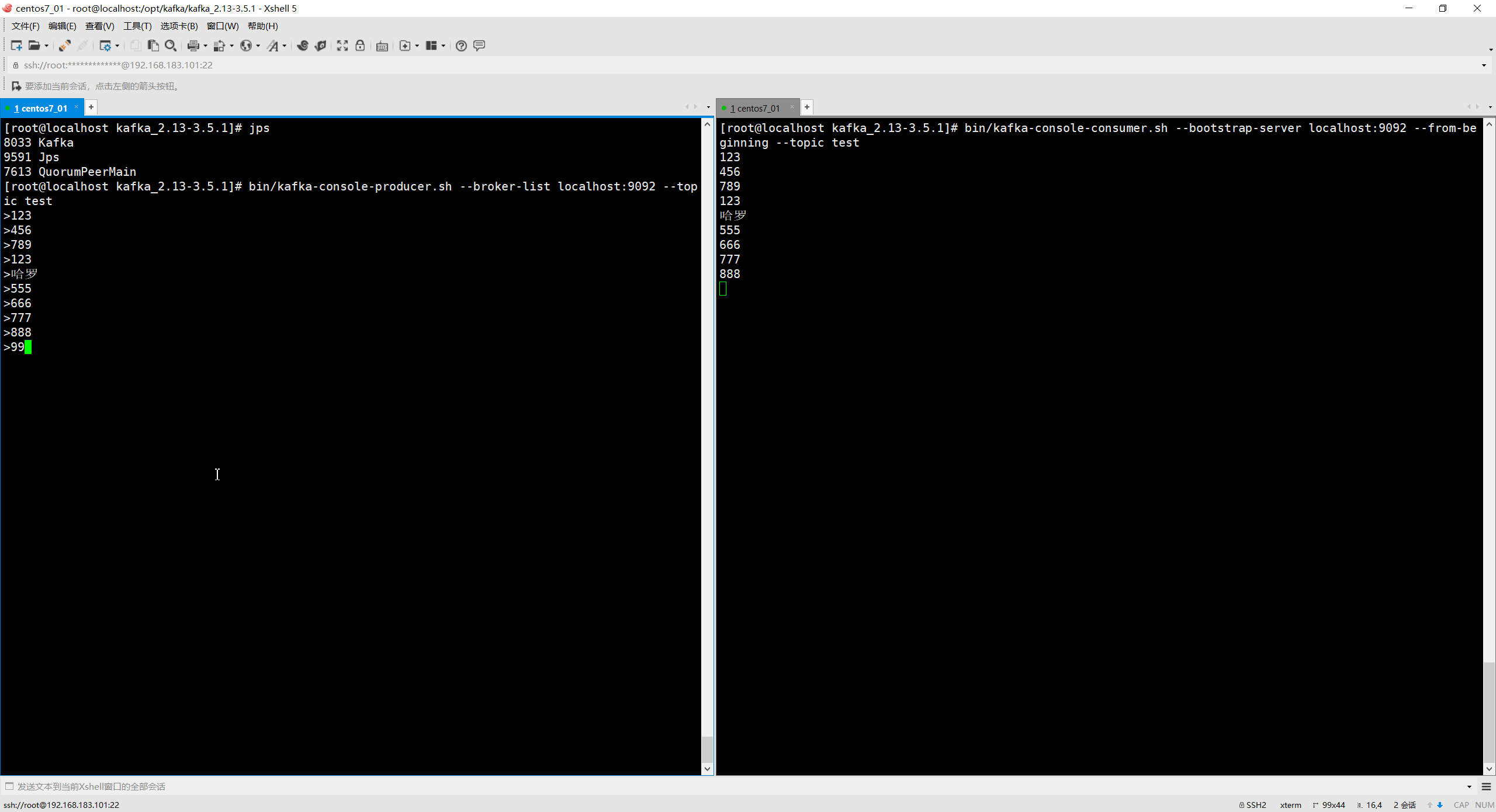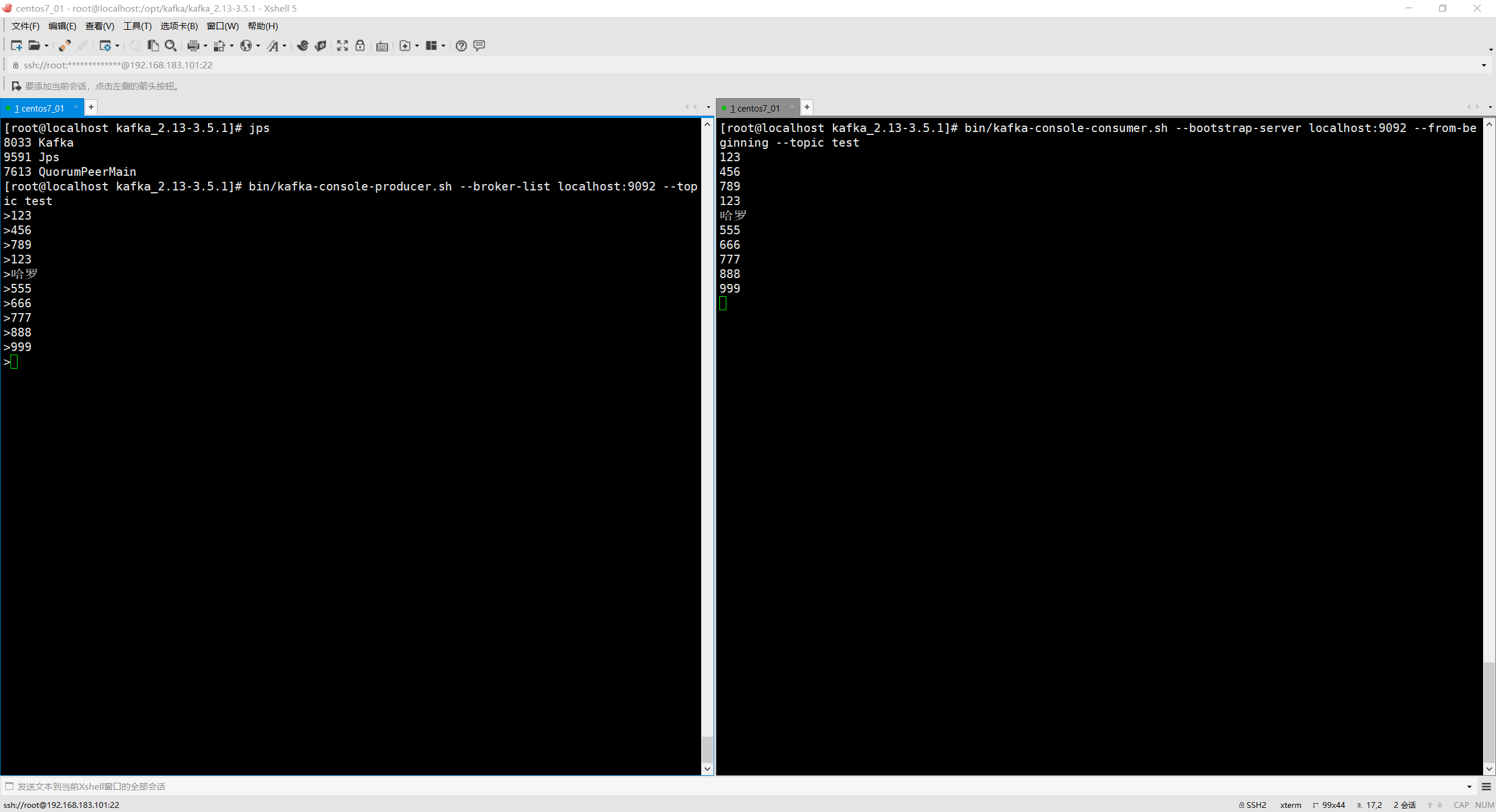
# 从头开始消费
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --
topic test
- 1
- 2
- 3
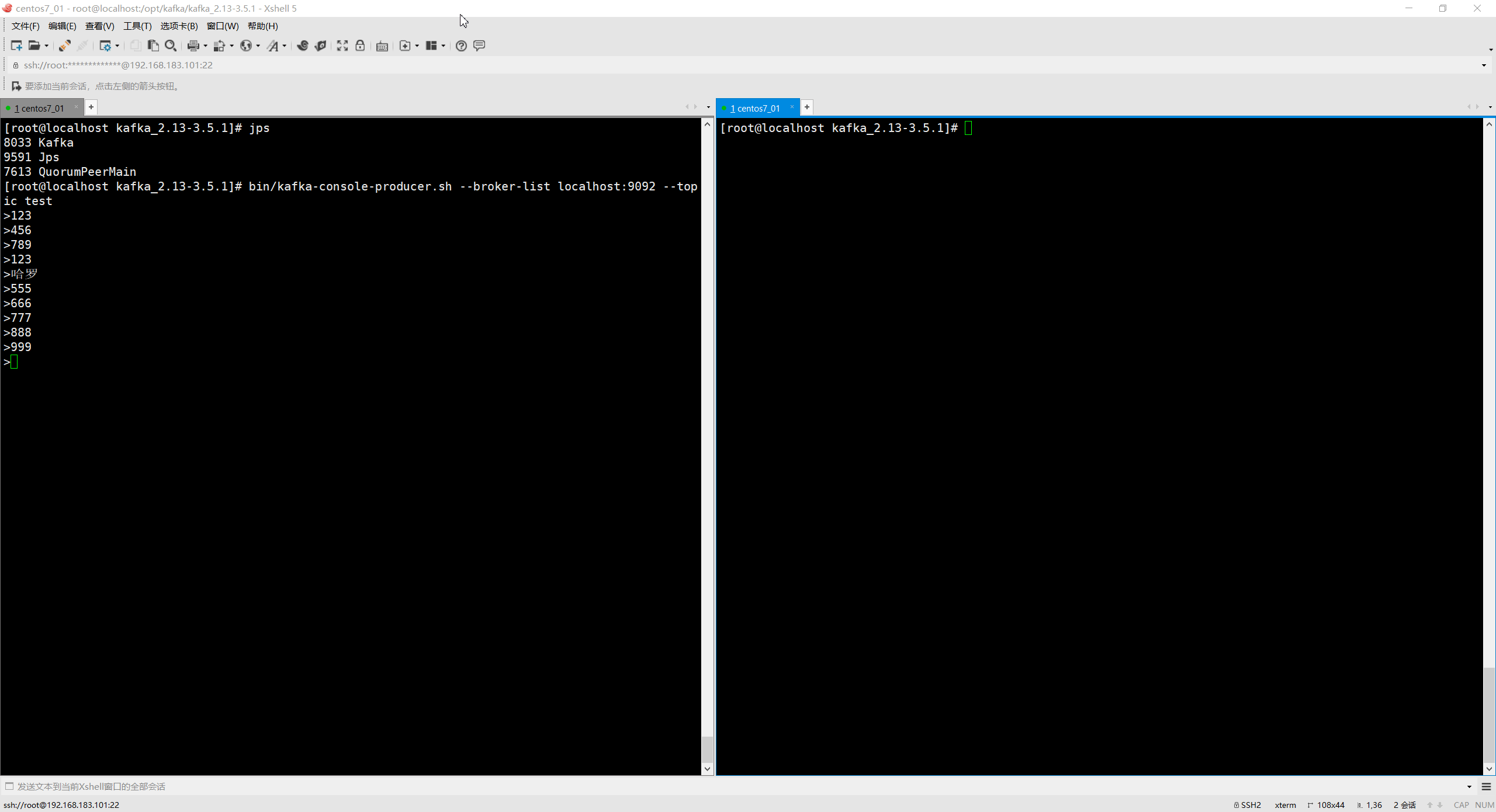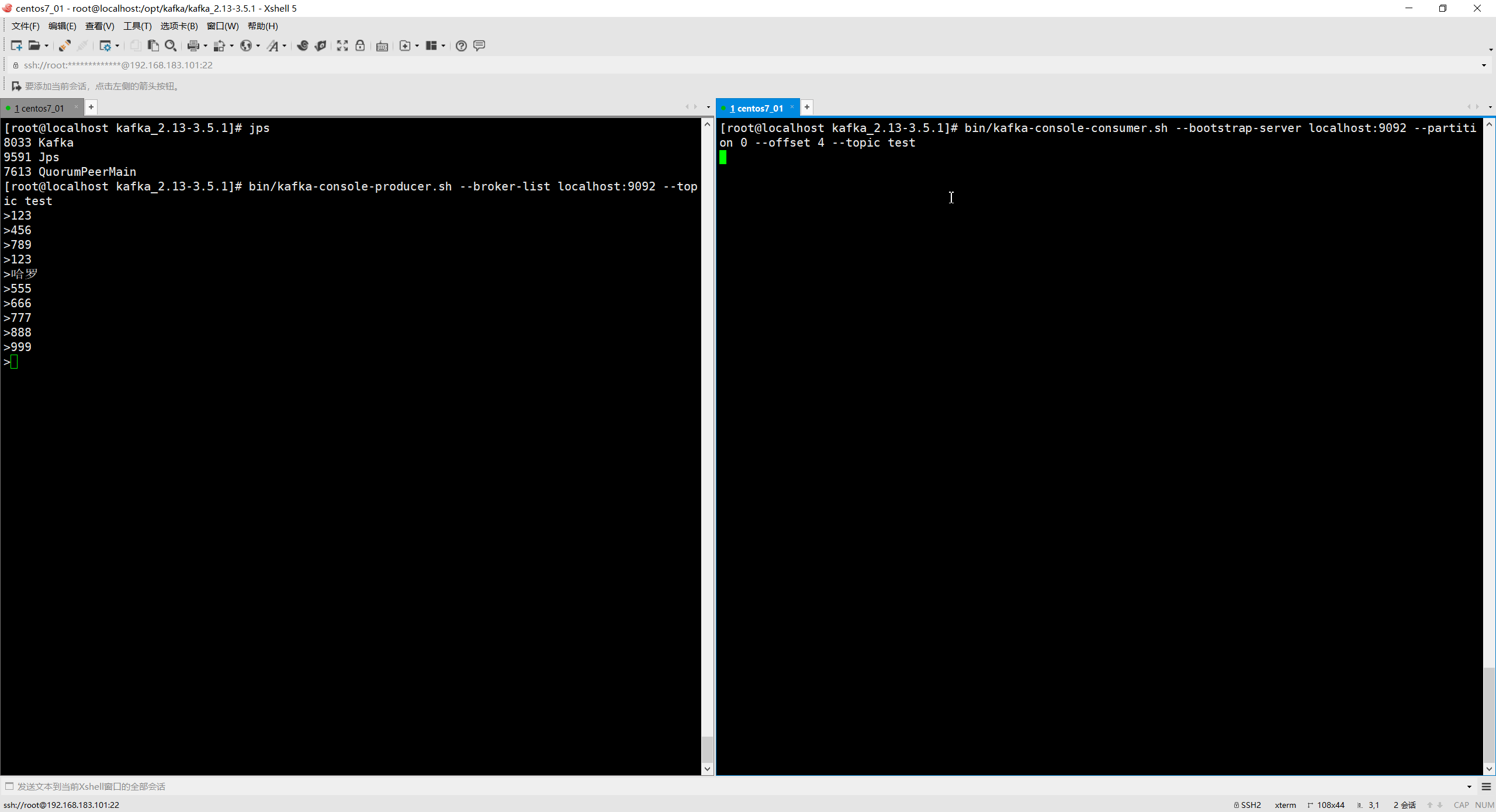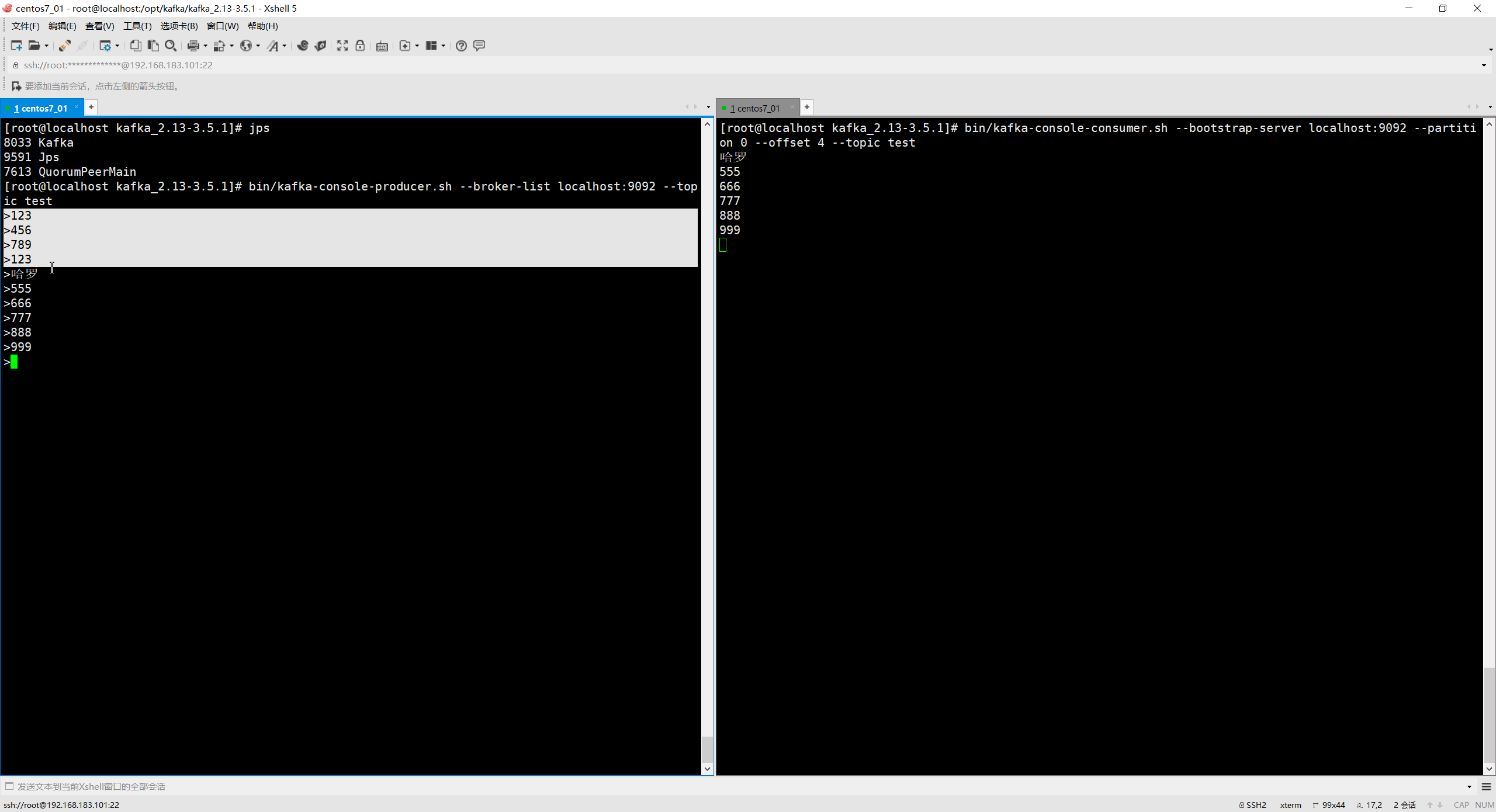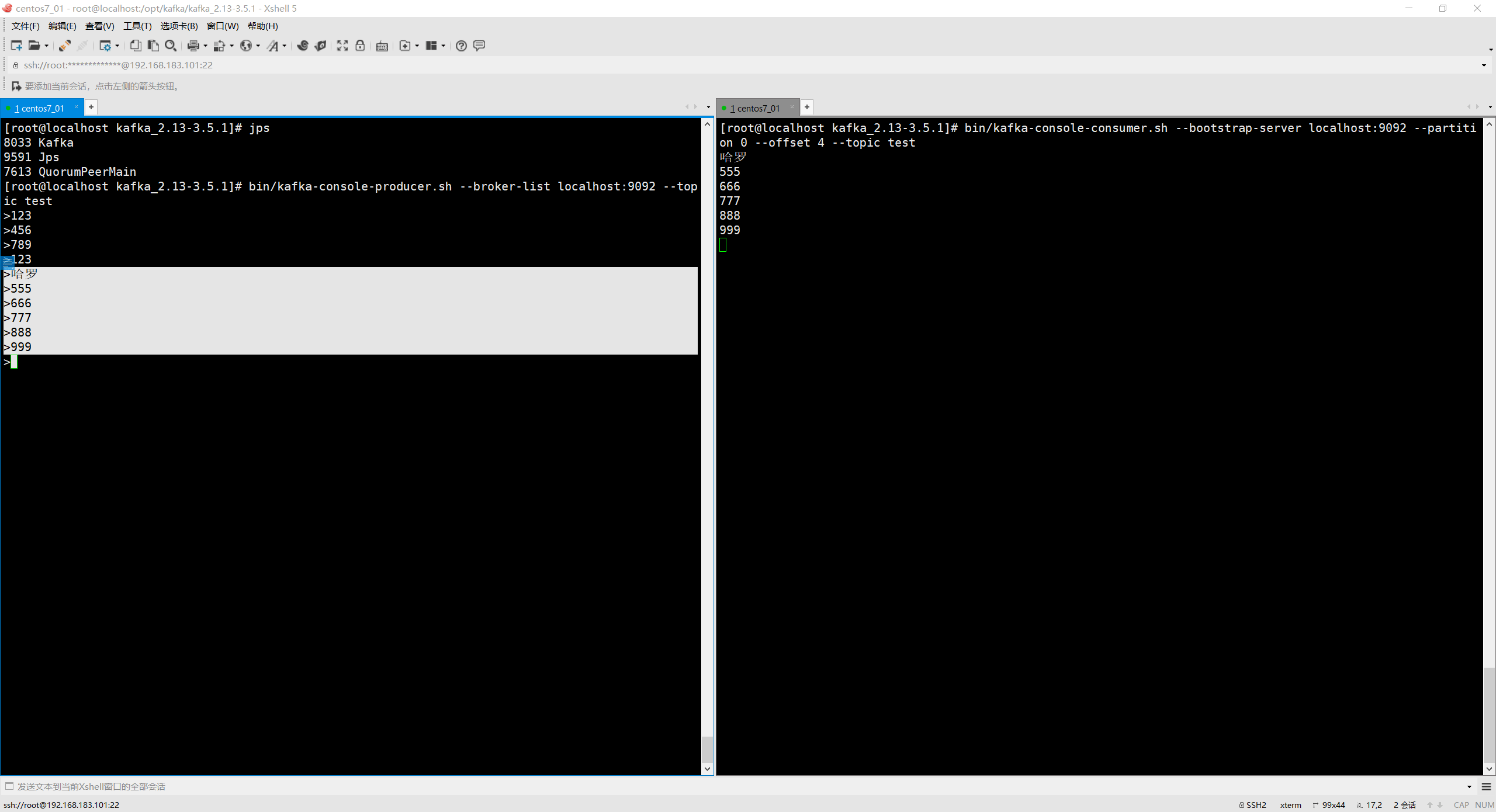
指定偏移量消费
例如用于线上故障后的消息回溯
# 从第0partition的第4个消息消费
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --partition 0 --offset 4 --topic test
- 1
- 2
分组消费
一个消费者组下包含多个消费者,消费者即是本地机器上启动的消费者线程
一个Partition只能被同一消费者组里的一个消费者消费
一个消费者却可以消费多个Partition
Kafka会记录每个Partition被每个conuser-group消费的偏移量(消费到第几条了)
#两个消费者实例属于同一个消费者组
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGrroup --topic test
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGrroup --topic test
#这个消费者实例属于不同的消费者组
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGrroup2 --topic test
- 1
- 2
- 3
- 4
- 5
查看分组消费信息

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/670992
推荐阅读
相关标签

