
- 1大语言模型中的强化学习与迁移学习技术
- 2基于Python爬虫山西晋中二手房数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 3【脉冲神经网络入门教程 01】脉冲编码方法_脉冲神经网络编码方式
- 4【CSDN软件工程师能力认证学习精选】vue.js 三种方式安装(vue-cli)
- 5有监督的神经网络模型_智慧监管神经网络预测模型名称
- 6随意聊架构
- 7React | 低代码平台开发实践_react lowcode
- 8大专非科班转码成功自白
- 9python进行文本分类,基于word2vec,sklearn-svm对微博性别分类_sklearn中word2vec文本特征提取并分类预测
- 10十分钟安装Tensorflow-gpu2.6.0+本机CUDA12 以及numpy+matplotlib各包版本协调问题_tensorflow-gpu==2.6.0支持的python版本
【史上最强】还原你的声音,GPT-SoVITS在windows下安装使用技巧_gpt-sovits安装包下载
赞
踩
安装环境:
系统:Windows11
内存:32G
显卡:4060ti16G
1.下载源码到本地磁盘
git clone https://github.com/RVC-Boss/GPT-SoVITS.git2.启动双击go-webui.bat
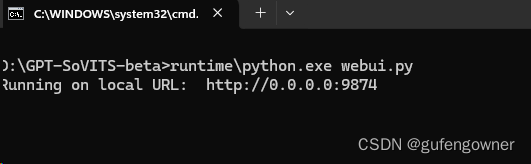
3.访问地址:http://localhost:9874
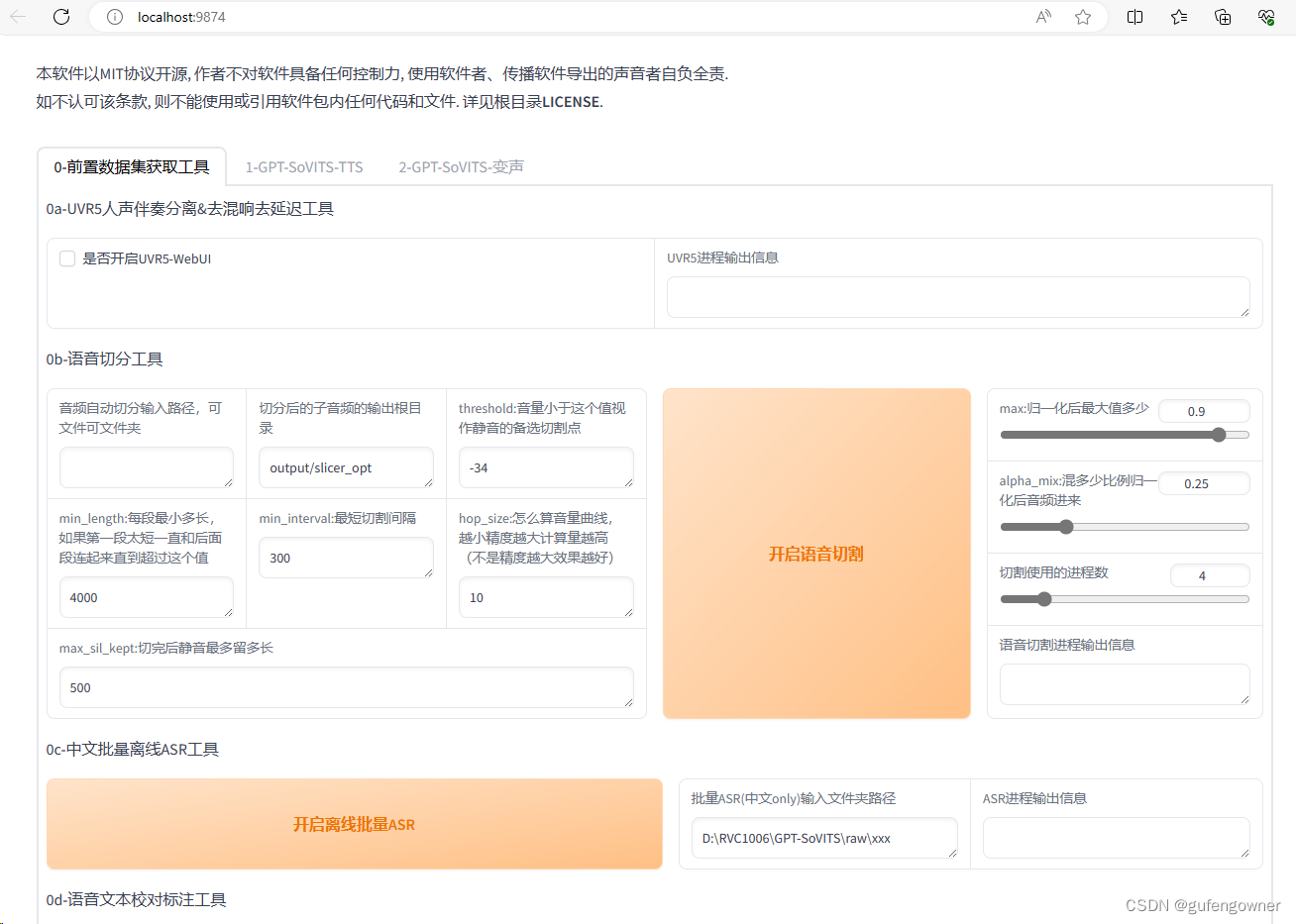
3.页签【0-前置数据获取工具】中【0a-UVR5人声伴奏分离&去混响去延迟工具】是如果需要分离人声的音频,作者提供了一个工具可以勾选使用,不需要可以跳过
4.【0b-语音切分工具】目的是将一个长音频分解成若干个短音频用于训练,在【音频自动切分输入路径,可文件可文件夹】中填入输入长音频文件路径,如:D:\GPT-SoVITS-beta\test\mike\mike的训练音频.m4a
5.【切分后的子音频的输出根目录】填入切割后文件的文件夹,如:D:\GPT-SoVITS-beta\test\mike\output\slicer_opt后其他先保持默认,点击【开启语音切割】
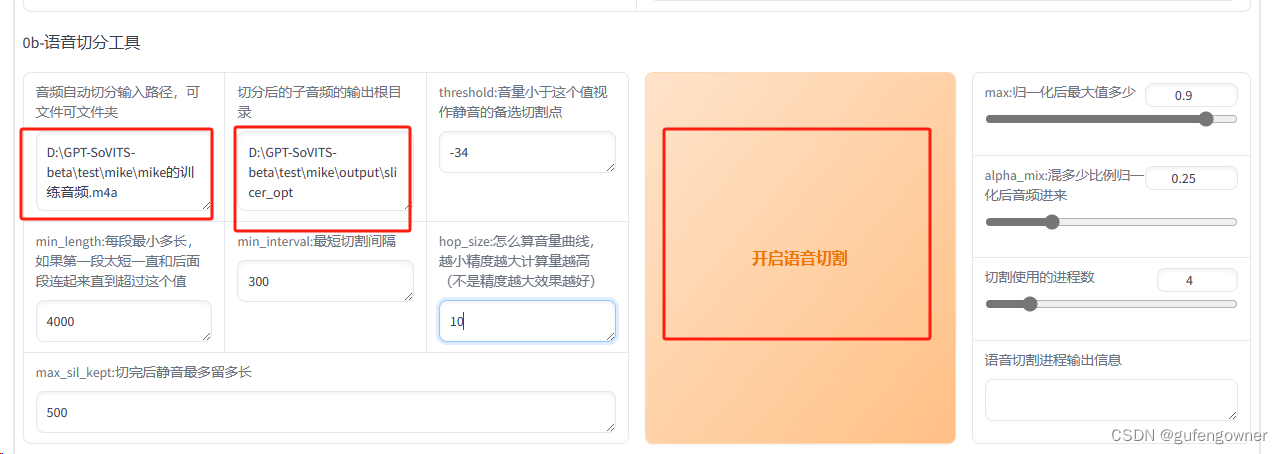
6.打开切分后的音频看下是否切成多个小段,若没有还是一个长音频,可以调整threshold值,如:-34调整到-20再点击【开启语音切割】

7.【0c-中文批量离线ASR工具】是将每小段的语音进行ASR识别文字,【批量ASR(中文only)输入文件夹路径】填入刚刚切割后小段的文件路径,如:D:\GPT-SoVITS-beta\test\mike\output\slicer_opt

点击【开启离线批量ASR】会在D:\GPT-SoVITS-beta\output\asr_opt生成一个slicer_opt.list文件,里面包含每小段音频的文字识别
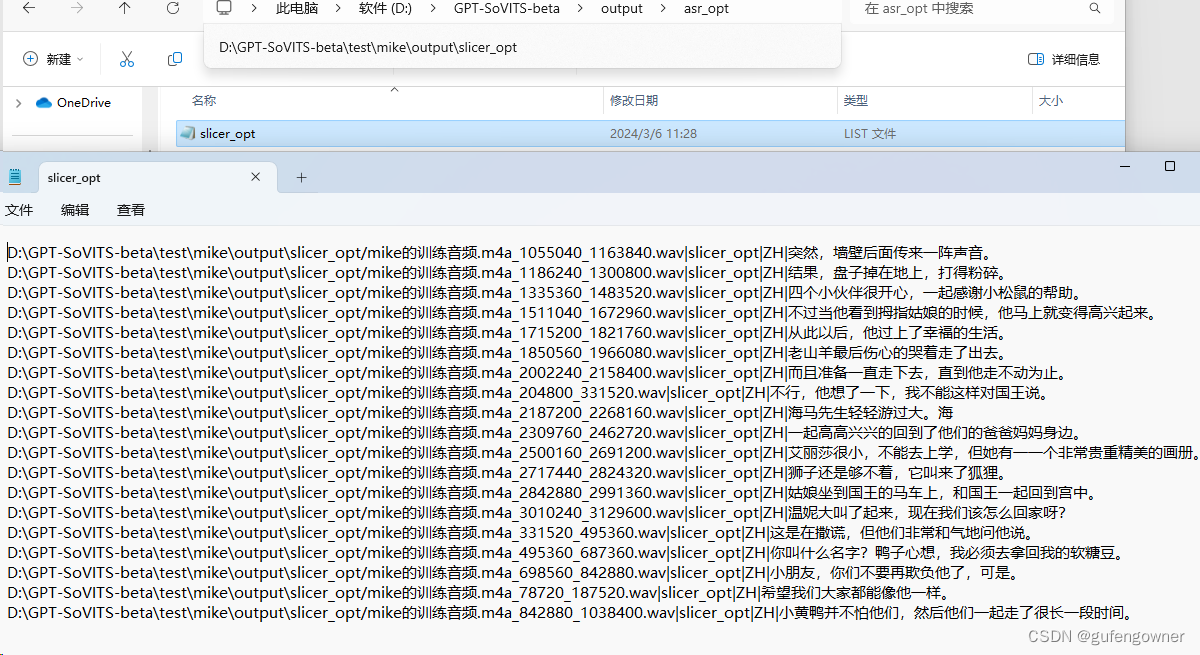
8.【0d-语音文本校对标注工具】需要对asr后的文字识别做个校准,【.list标注文件的路径】中填入刚刚生成的slicer_opt.list的路径,如:D:\GPT-SoVITS-beta\output\asr_opt\slicer_opt.list,勾选【是否开启打标WEBUI】,后会自动跳转录音文字核对页面

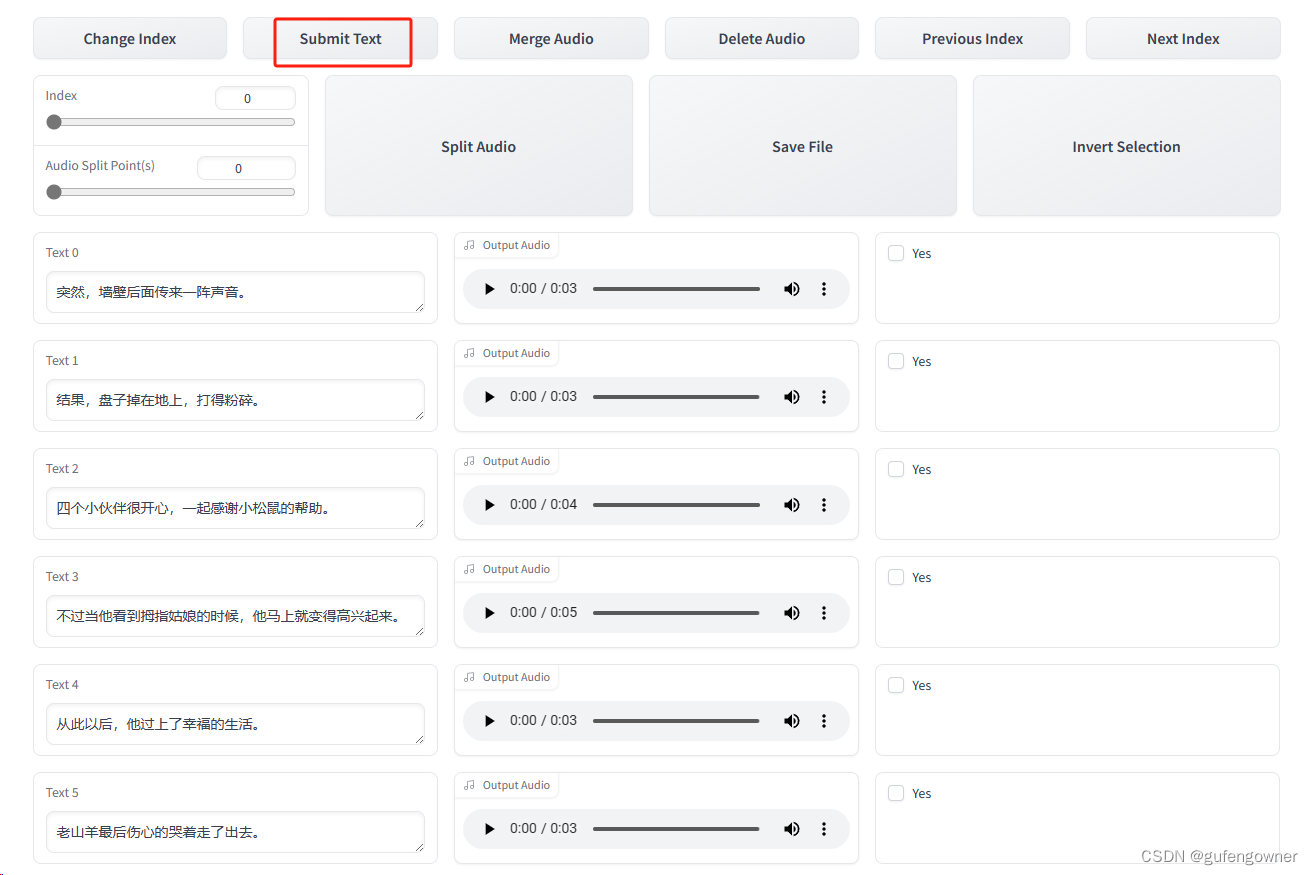
9.把录音和文字核对一边,文字识别有问题的可以更改,翻页点击NextIndex,更改完点击SubmitText,会自动更新slicer_opt.list文件
10.回到主页,点击页签【1-GPT_SoVITS-TTS】开始语音模型训练,【*实验/模型名】中帮模型起个名字

11.点击【1A】页签【*文本标注文件】中输入核对后list文件的位置D:\GPT-SoVITS-beta\output\asr_opt\slicer_opt.list,【*训练集音频文件目录】中填入切割后录音的文件夹D:\GPT-SoVITS-beta\test\mike\output\slicer_opt
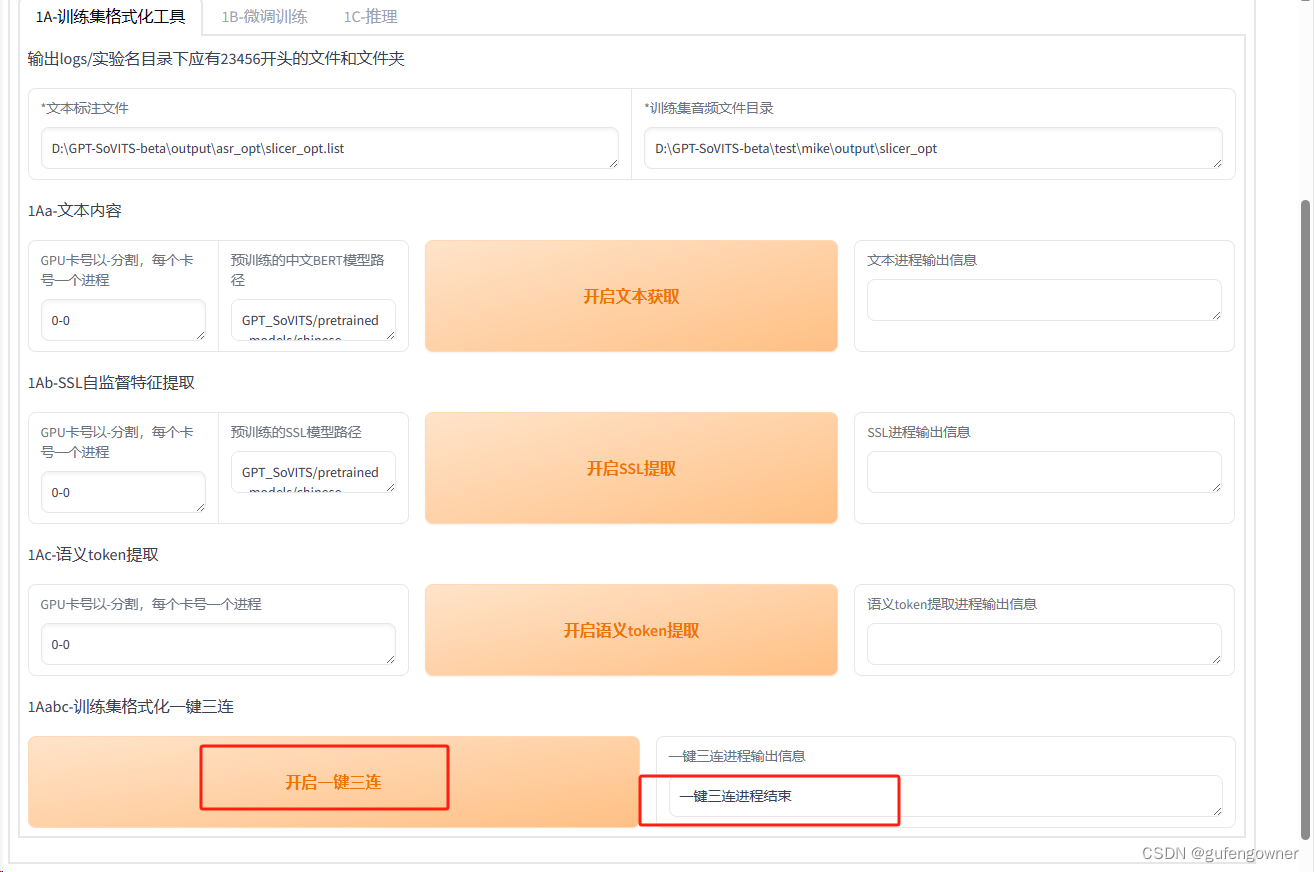
12.点击【开启一键三连】,完成后会显示一键三连进程结束
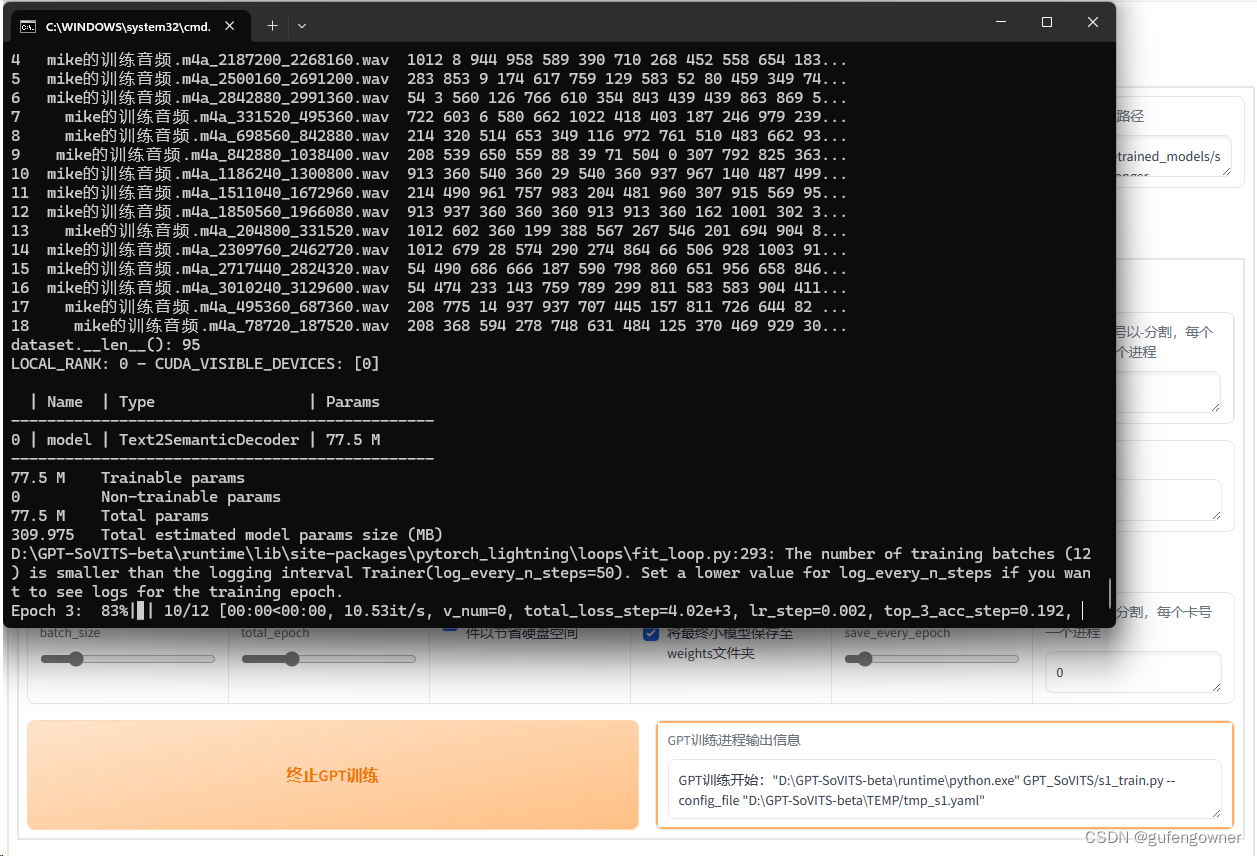
13.切换到【1B-微调训练】页签点击【开启SoVITS训练】,需要等待一段时间后提示完成

14.点击【开启GPT训练】,训练完成后语音模型生成
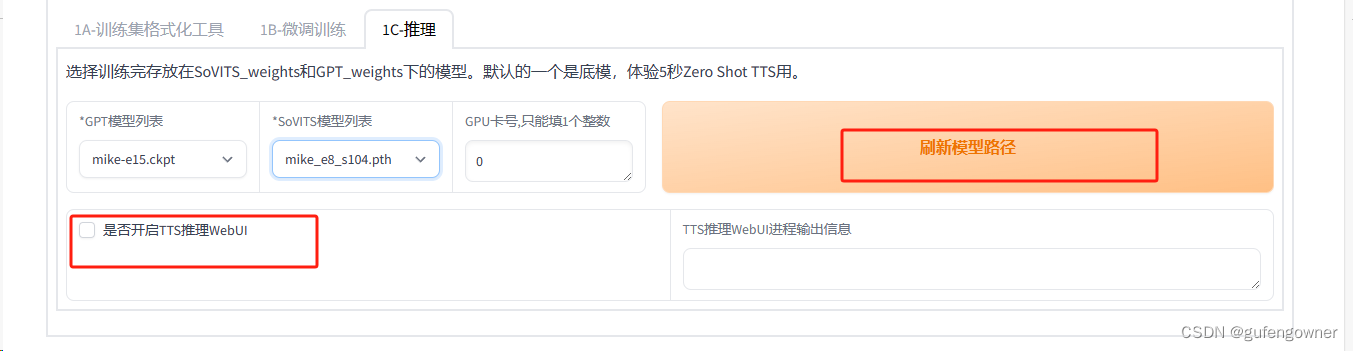
15.点击【1C-推理】,点击【刷新模型路径】,可以在下拉选项中看见新训练的模型,选中模型名-e-15.ckpt和模型名_e8_s104.pth模型,勾选【是否开启TTS推了WebUI】,会跳转到TTS合成语音页面
16.【*请上传并填写参考信息】选择上传一个3-10秒的音频,可以是刚刚切分的小音频 ,然后【参考音频的文本】中将文字识别填入

17,选择语种后,【需要合成的文本】输入需要合成语音文字,点击【语音合成】
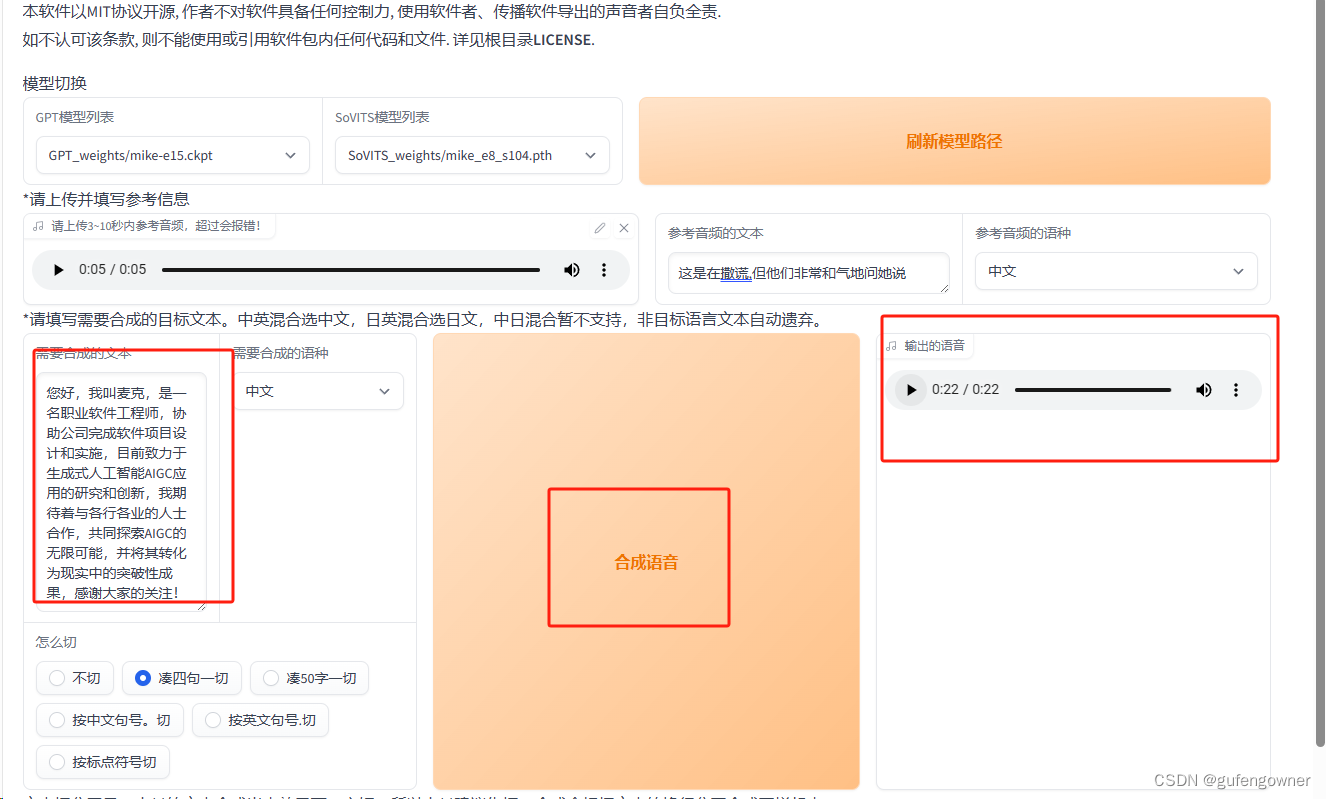
18.最后还有语句切分工具,可以用于超长文本的切分,太长的文本合成出来效果不一定好,所以太长建议先切。合成会根据文本的换行分开合成再拼起来。

小技巧:当勾选中文时,对英文的生成效果就会差很多,如果有中英混合的话所以可以将“AIGC”换成“诶爱机西”读出的效果会好些^_^。

