
- 1Failed toconnect to github.com port 443: 拒绝连接 Could not resolve host: github.com_github 443拒绝连接
- 2cubemx移植事件标志组These IPs still have some not configured or wrong parameter values:[FREERTOS]_- main config: these peripherals still have some n
- 3Python全栈笔记(一)_python全栈学习笔记
- 4【科普】-求素数为什么只需要求到平方根就行?_数论求素数 平方根
- 5HTML:常用标签
- 6[manifest_router.cpp(GetPagePath)-(0)] [Engine Log] can‘t find this page pages/AuthPage path
- 7文本离散表示(二):新闻语料的one-hot编码
- 8基于docker的wekan部署
- 9图解最常用的 10 个机器学习算法!
- 10Idea 插件下载缓慢,无法下载的解决方式_jetbrains插件安装缓慢
YOLO-YOLOV5训练自己模型过程记录_如何训练模型做一个yaml
赞
踩
注意:本文为记录,非教程
一、配置yaml文件:
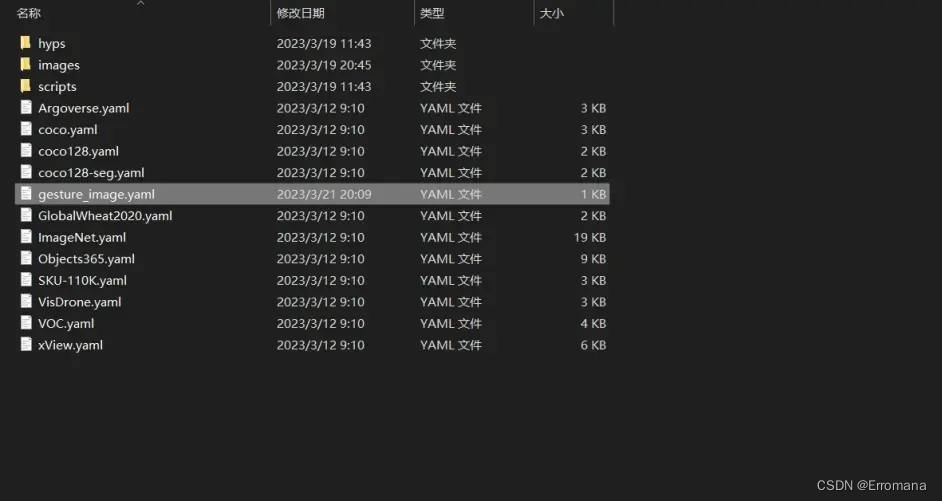
1、创建了gesture_image.yaml文件:
yaml的作用在于将要训练的数据集文件结构位置以及具有的类别,知会给yolov5模型,所以在yolov5项目下的data文件夹中新建自己的yaml文件。
2、添加配置需要参量:
包括数据集文件夹路径,数据集中train和val图片路径以及Classes,即标签类名。
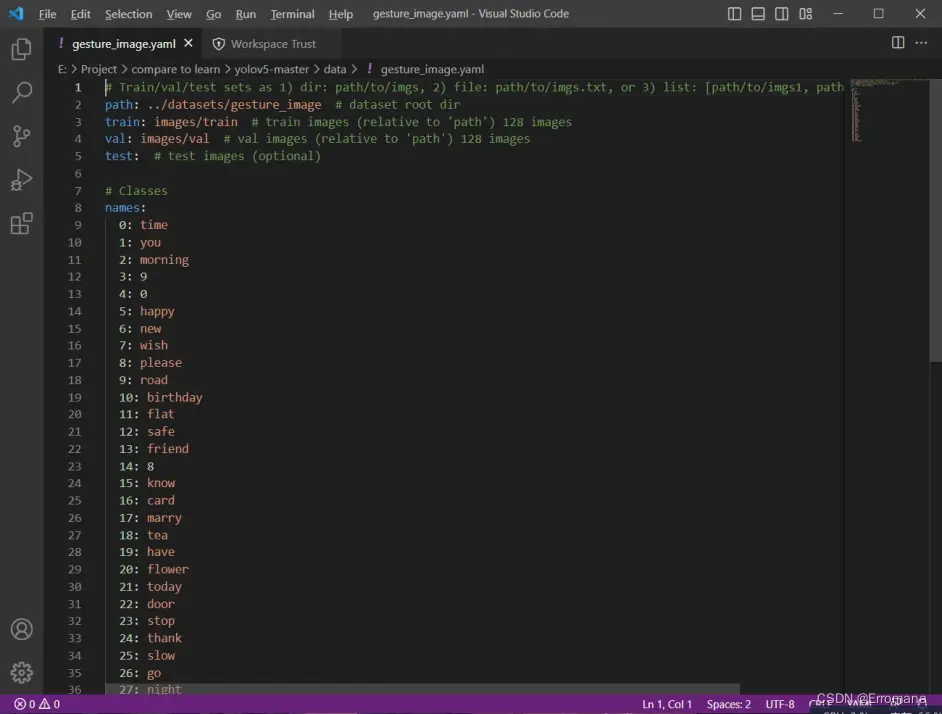
二、修改train.py接收参数函数parse_opt()的默认值
包括:
–weights 选择yolov5s.pt
–data 上一步配置好的gestrue_image.yaml文件路径
–epochs 训练迭代次数,先来100轮
–batch-size 一次训练分批每批次数量,先设置48
–works 设置为0
–name 保存名字,使用默认exp
三、训练:
开始训练,
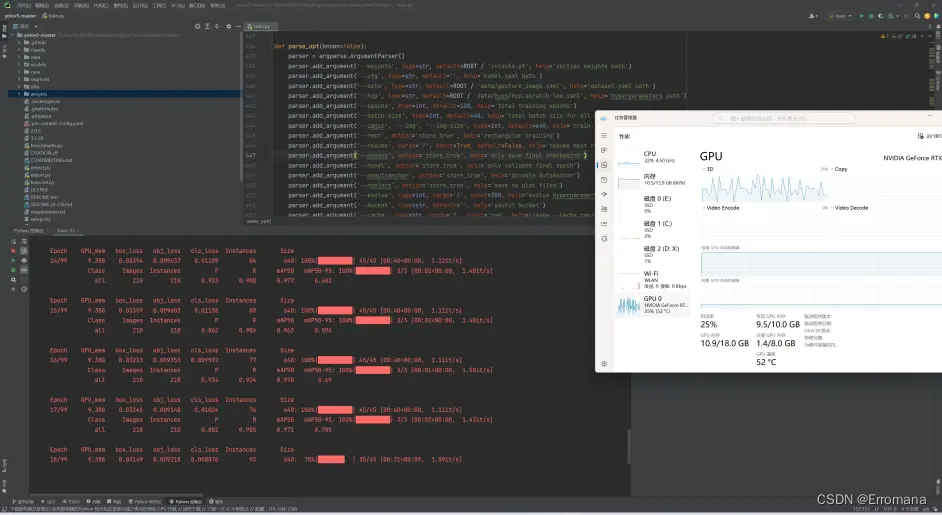
实验室兄弟说训练过拟合,结果并不好,
运行起来也不行。收拾收拾,再来吧。
四、数据增强:
使用b站up主@啥都生的数据增强软件,有现成的轮子就是方便,链接:https://www.bilibili.com/video/BV1Sv4y1S7yb/?spm_id_from=333.788.top_right_bar_window_history.content.click&vd_source=fbf62db090250cc27ce97b468689ee38
不过,支持xml、json格式,非不支持yolo的txt格式,所以先进行格式转换。
1、格式转换:yolo2xml
使用了csdn论坛一篇博客的脚本,链接:脚本链接
修改完代码中的类别字典和自己的数据集图片、txt标签、要输出xml路径,后运行即可。图为代码运行:
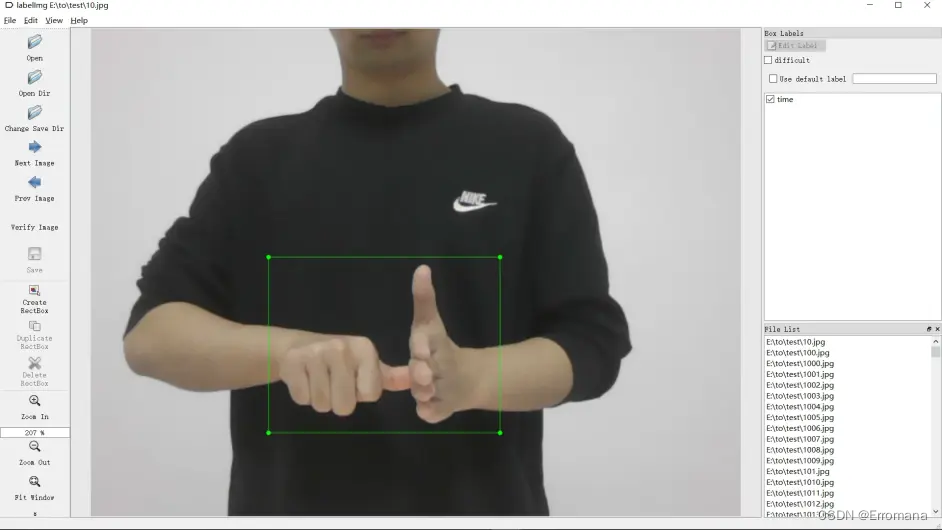
从txt标注转为xml标注,通过labelimg软件,抽查了几张,位置及对应类别都正确,效果不错:

2、开始增强:
选择好路径,因为我的数据集图片过少(2365张,35类),所以增强后要与原先的图片混在一起,所以初始编号设置为2366。点击确认,准备批量操作。
忽然意识到不对,一共所有图片才2358张,最高编号怎么是2365?得,要是跳了还好说,要是错位就真傻眼了。赶紧去检查了一遍,好在基本上图片与对应标注都没啥问题,看来没有错位。继续。
使用了旋转,缩放,噪点等手段,把数据集拓展到一万七千多张,这回应该效果会好些。
3、格式转换:xml2yolo:
被网上乱七八糟的玩意折磨死,项目结构看的人头疼。除此之外,最意外的bug是忘记了在文件路径后的/,然后显示怎么都找不到文件。我简直是……
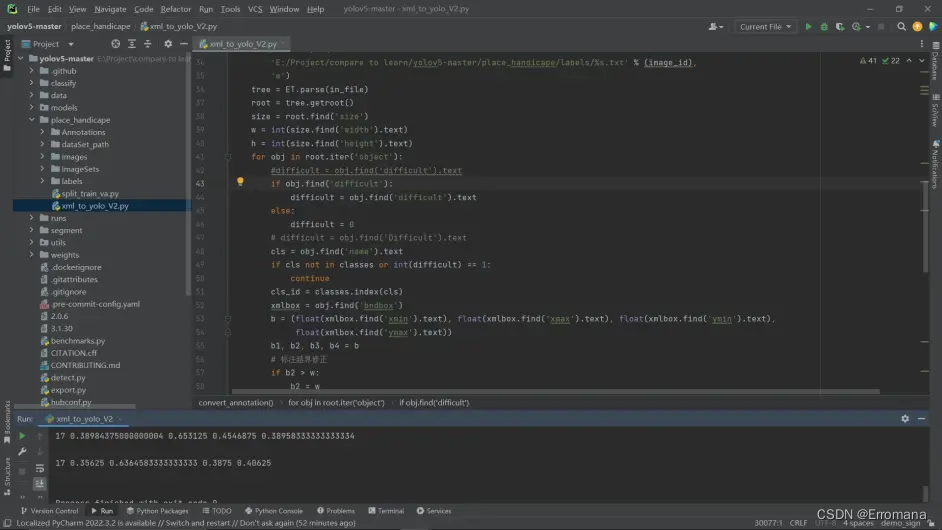
实验室某位不知名老哥给的转换文件,终于还不错,虽然没给教程,不过还是用起来了。之后得读读代码,基础的脚本还是看看。
五、再训练:
增强并转换完数据,就又开始训练我的模型了。
不过打开tensorborad界面,显示出错,仔细看了下,是该指令指定的文件路径并不能在python所在位置找到,
(yjh) PS X:\temp\compare to learn> tensorboard --logdir runs\train 出错
在终端中进入yoolov5项目后,再运行该指令,
(yjh) PS X:\temp\compare to learn\yolov5-master> tensorboard --logdir runs\train
运行成功,显示训练过程:
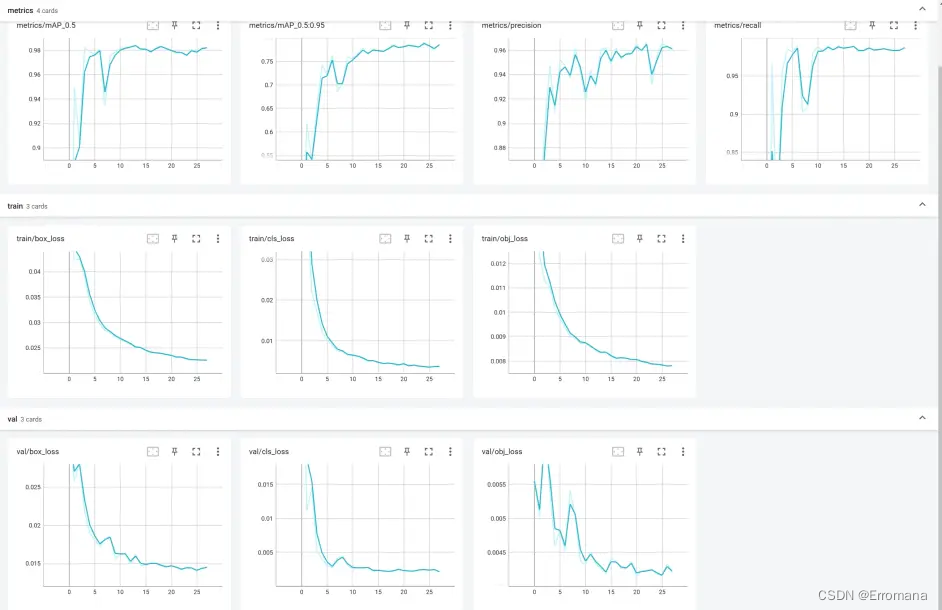
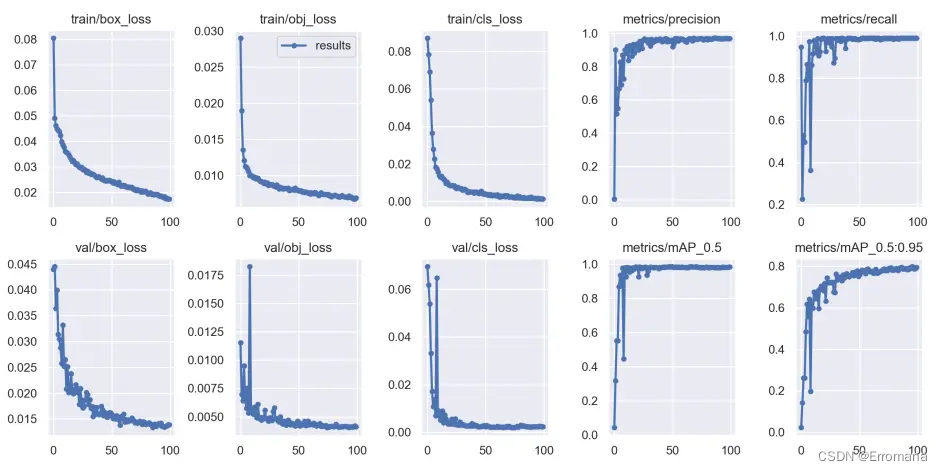
又开始漫长的训练过程了,借了实验室老哥的3080,估计也要跑11个小时。终于有一点了解AI炼丹一词如何而来了。训练结果要是不行,增加数据,修改参数,再训练,直到得到一个合用的模型。即便有调参的方向,也往往需人力穷举调整配方,再加上每次漫长的等待。这确实有些炼丹的意味了。科研民工和码农这样的词也许也是如此得来的吧。怪不得听闻chatgpt说程序员是会被它先淘汰的职业,有些工作确实有点机械劳作的意味了,还是得再动动脑子。
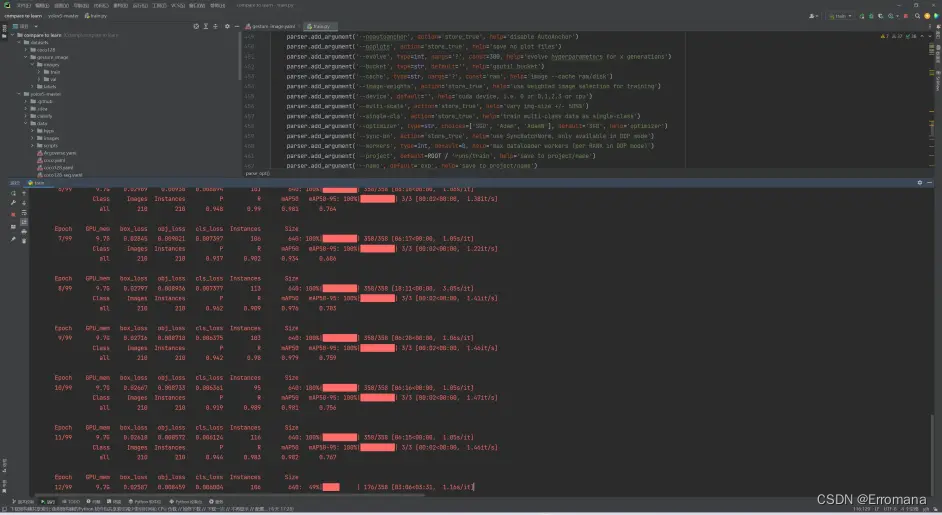
六、再结果:
比上次好了些,但依旧会做出类似于把猫识别成狗的事,把我的脑袋识别成了表示门的手势。恭喜我,训练出了个高明了一点点的人工智障。


我其实是不大明白,为什么会把我的脑袋识别成door,置信率还高达0.82。还是得再学习学习,看看问题出在哪里了。感觉可能是与训练权重用yolov5s.pt不大行,或许可以试试更大一点的模型。又或者事训练轮数多了些,才导致过拟合。不过都先不急,下一步先去学会如何看训练效果的文件吧,看看这轮的模型到底怎么样在说别的,不能盲目的再走了。顺便再把没看完的吴恩达的入门课程也看完吧。

