
- 1【语义分割】分层多尺度注意力 Hierarchical multi-scale attention for semantic segmentation_跨尺度分层注意力网络
- 2彻底卸载微软拼音输入法
- 3论文《Exploring to Prompt for Vision-Language Models》阅读
- 4jvm - Arthas java诊断工具 - 线程相关(thread -b找出当前阻塞其他线程的线程)_arthas thread -b
- 5算法工程师-机器学习-分类回归模型面试常见题_假设一个数据集可以分成g个集合,每个集合中的数据是相似的,g的取值在2和g之间,y是
- 6Spring Boot集成JSch快速入门demo
- 7现在学python容易就业吗?_python好就业吗?
- 8Transformer、Bert、GPT简介_transformer, bert, and gpt including chatgpt and p
- 9探索ORACLE之ASM概念(完整版)_oracleasmlib
- 1020211220使用Hiburn给小熊派刷机_ready to load at 0x10a000 ccstartburn total size:0
生成式AI - 基于大模型的应用架构与方案_基于大模型的应用系统设计
赞
踩
这篇文章探讨了使用文档加载器、嵌入、向量存储和提示模板构建基于语言模型(LLM)应用程序的过程。由于其生成连贯且上下文相关的文本的能力,LLM在自然语言处理任务中变得越来越受欢迎。本文讨论了LLM的重要性,比较了微调和上下文注入方法,介绍了LangChain,并提供了构建LLM应用程序的逐步过程。在适用的情况下,包括了Python代码片段。
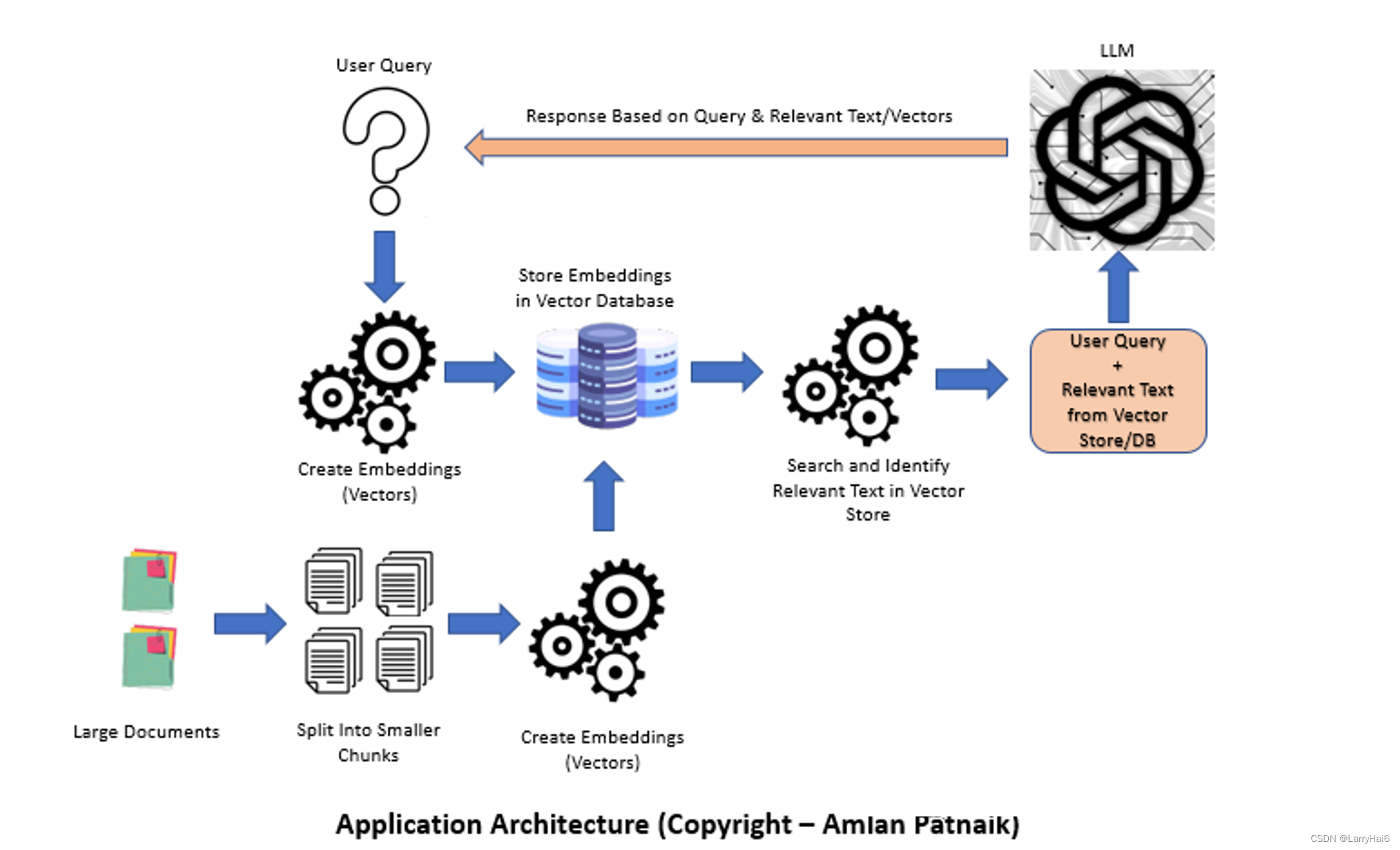
语言是人类交流和表达思想和想法的主要媒介。理解和处理人类语言一直是人工智能领域的基本挑战。随着自然语言处理(NLP)的进步,复杂语言模型的发展为各种NLP任务带来了重大突破。
基于语言模型的学习(LLM)已成为解决这些挑战的强大方法。LLM利用深度学习技术来建模和理解人类语言的复杂模式和结构。这些模型在生成连贯且上下文相关的文本方面表现出了非凡的能力,使它们能够在文本生成、摘要、翻译和问答系统等任务中表现出色。
大模型在自然语言处理任务中应用
LLM在自然语言处理任务中的集成,彻底改变了我们与文本数据互动的方式。这些模型可以从大量的文本信息中学习,捕捉单词、短语和概念之间的复杂关系。通过利用这种知识,LLM可以生成符合给定上下文的类似人类的文本。
LLM的关键优势之一是其生成连贯且上下文相关的文本的能力。与传统的基于规则或统计的方法不同,LLM具有生成遵循语法规则、保留上下文并展示深刻语义关系能力的文本的能力。这使得应用程序,如文本摘要成为可能,其中LLM可以通过从给定文档中提取关键信息来生成简洁而有信息的摘要。
此外,LLM已应用于机器翻译系统中,学习将输入文本从一种语言映射到另一种语言,产生高质量的翻译。这些模型表现出令人印象深刻的性能,优于先前的机器翻译方法,并弥合了语言之间的差距。
文本生成
LLMs能够生成连贯且上下文相关的文本,这是由于它们在大量多样化的文本数据上进行了训练。这些模型从数据中捕捉模式、依赖关系和上下文线索,使它们能够生成与输入上下文相一致的文本。
例如,在文本补全任务中,LLMs可以生成给定句子最可能的后续内容,确保生成的文本连贯且与前文相关。这在自动补全功能中有实际应用,其中LLMs可以根据用户输入预测下一个单词或短语,并提供实时建议。
此外,LLMs已被应用于聊天机器人系统中,使得对话代理能够生成类似人类的响应。这些模型从对话数据集中学习并生成上下文相关的响应,考虑对话历史以保持整个对话的连贯性和相关性。
LLMs在自然语言处理任务中变得非常宝贵,能够生成连贯且上下文相关的文本。深度学习技术的进步以及大规模的训练数据为LLMs在文本生成、摘要、翻译和对话系统等任务中的卓越表现铺平了道路。利用LLMs的力量打开了自动化语言相关任务和创建更具交互性和智能应用程序的新可能性。
微调大模型
Fine-tuning是一种在LLM开发中流行的方法,涉及将预训练的语言模型调整为执行特定任务。微调始于利用已预训练的LLM,该模型已在大量通用语言数据上进行过训练。预训练阶段使模型能够学习丰富的语言表示并捕捉自然语言的统计模式。
为了微调一个特定的LLM以执行某个任务,我们从预训练模型开始,并进一步在其上针对特定任务的数据集上进行训练。这个数据集包含与目标任务相关的标记示例。在微调过程中,模型的参数会调整以优化其在特定任务上的性能。
Python代码用于微调LLM通常涉及几个步骤:
加载预训练的LLM模型
准备特定任务的数据集
对输入数据进行分词
微调模型
- from transformers import TFAutoModelForSequenceClassification, TFAutoTokenizer
-
- model_name = "bert-base-uncased" # Example pre-trained model
- model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
- tokenizer = TFAutoTokenizer.from_pretrained(model_name)
-
- task_dataset = ... # Load or preprocess the task-specific dataset
-
- tokenized_data = tokenizer(task_dataset["text"], padding=True, truncation=True, max_length=128)
-
- model.compile(optimizer="adam", loss="binary_crossentropy")
- model.fit(tokenized_data, task_dataset["labels"], epochs=3)
微调提供了许多优势。首先,它允许更快的开发,因为它利用了预训练模型的语言理解能力。其次,与从头开始训练相比,微调需要相对较少的任务特定训练示例,因此在标记数据有限的场景中是一种实用的选择。最后,微调后的模型通常比从头开始训练的模型在下游任务上表现出更好的性能。
然而,微调可能会非常耗费计算资源,因为整个模型需要在任务特定的数据集上进行训练。此外,微调可能会受到一种称为灾难性遗忘的现象的影响,在该过程中,模型在微调过程中忘记了之前学到的知识。
LLMs中的上下文注入(Context Injection)
上下文注入(Context Injection),也称为提示工程,是一种利用预训练LLMs而不进行大量微调的替代方法。与微调整个模型不同,上下文注入涉及将特定的上下文或提示注入到预训练的LLM中,以指导其特定任务的输出生成。
提示工程相对于微调提供了灵活性和更快的迭代周期。开发人员可以设计包含所需输入-输出行为的提示,并编码特定的任务指令。通过仔细设计提示,可以在不进行大量重新训练的情况下从预训练的LLM生成特定于任务的输出。
上下文注入的Python代码包括以下步骤:
加载预训练的LLM模型。定义提示基于提示生成文本评估生成的输出。
-
- from transformers import GPT2LMHeadModel, GPT2Tokenizer
-
- model_name = "gpt2" # Example pre-trained model
- model = GPT2LMHeadModel.from_pretrained(model_name)
- tokenizer = GPT2Tokenizer.from_pretrained(model_name)
-
- prompt = "Translate the following English text to French: "
-
- input_text = prompt + "Hello, how are you?" # Example input text
- input_ids = tokenizer.encode(input_text, return_tensors="pt")
- output = model.generate(input_ids)
- decoded_output = tokenizer.decode(output[0], skip_special_tokens=True)
-
- print(decoded_output)
上下文注入通过提示提供明确的指令,使生成的文本具有细粒度的控制。开发人员可以通过试验不同的提示并快速迭代来实现特定任务所需的期望输出。上下文注入的一个挑战是设计有效的提示。提示应该仔细制作以引导期望的响应,同时保持连贯性和语境。这需要对LLM的能力以及手头的任务有深刻的理解,才能设计出产生高质量输出的提示。
比较微调与上下文注入
微调和上下文注入都有其优点和权衡。微调提供的优势是可以专门针对任务训练LLM,从而获得更好的性能。然而,它需要特定于任务的标记数据,并且计算成本可能很高。
另一方面,上下文注入可以实现更快的迭代周期并利用预训练的LLM知识。通过注入特定于任务的上下文,它提供了更多的灵活性来指导输出生成。然而,当需要广泛的任务适应时,它可能无法达到与微调相同的性能水平。
在微调和上下文注入之间进行选择取决于任务的具体要求、标记数据的可用性、计算资源以及在性能和开发时间之间的期望权衡。


