
热门标签
热门文章
- 1Spark MLlib之朴素贝叶斯_贝叶斯调参spark实现
- 2hive除数取整_hive 除法取整
- 3以太坊的演变:EIP、ERC 概念以及革命性的 ERC20、ERC721 和 ERC115 标准_nft erc20
- 4软件系统建模与UML(一):UML概述 -- 期末重点_uml模型概述
- 5PyTorch 数据处理详解:从数据加载到预处理_数据预处理与批标准化 pytorch
- 6C++初阶学习第四弹——类与对象(中)——刨析类与对象的核心点
- 7Hugging Face Transformers 萌新完全指南
- 8RocketMQ(四):重复消费、消息重试、死信消息的解决方案_springboot中的rocketmq的死信队列如何重新消费?
- 9Exchange Server部署搭建_exchange服务器搭建
- 10从零开始开发企业培训APP:在线教育系统源码剖析
当前位置: article > 正文
「Python大数据」LDA主题分析模型_python lde模型
作者:羊村懒王 | 2024-05-13 02:22:46
赞
踩
python lde模型
前言
本文主要介绍通过python实现数据聚类、脚本开发、办公自动化。读取voc数据,聚类voc数据。
一、业务逻辑
- 读取voc数据采集的数据
- 批处理,使用jieba进行分词,去除停用词
- LDA模型计算词汇和每个词的频率
- 将可视化结果保存到HTML文件中
二、具体产出
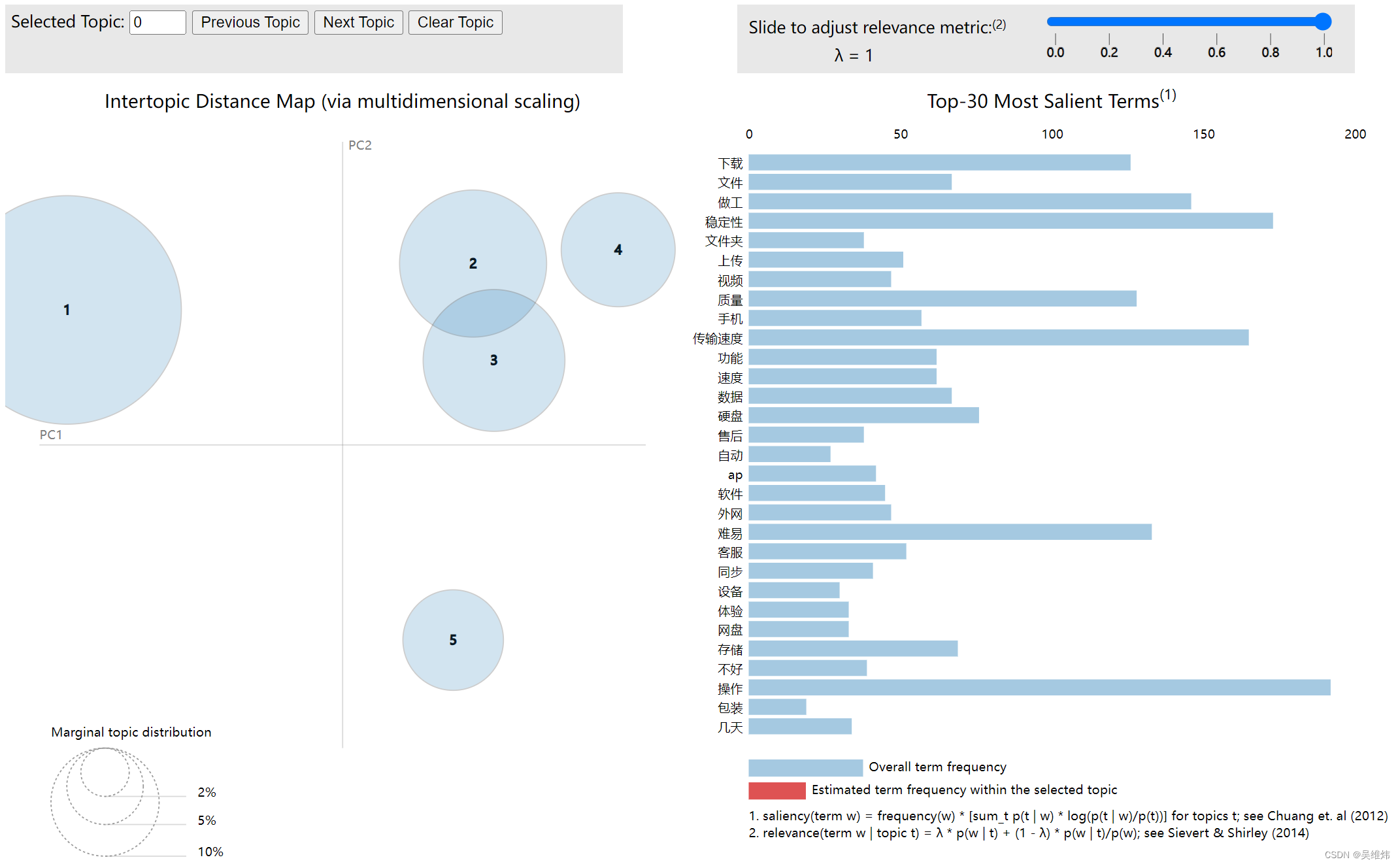
三、执行脚本
python lda.py
- 1
四、关键代码
# LDA主题分析模型 import pandas as pd import jieba from sklearn.feature_extraction.text import CountVectorizer from sklearn.decomposition import LatentDirichletAllocation import pyLDAvis fileName = "100005785591" # 文件名 # 加载停用词 with open('stopwordsfull', 'r', encoding='utf-8') as f: stopwords = set([line.strip() for line in f]) # 加载业务域名词 with open('luyouqi.txt', 'r', encoding='utf-8') as f: business_terms =

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/561497
推荐阅读
相关标签

