
- 1React Native macOS 环境搭建_mac os 10.14.6 配置react native 开发环境
- 2git在不同系统上的安装,及其常用的命令_git 只能在liniux吗
- 3Chatbox 使用 DeepSeek-V2_deepseek的apikey怎么使用
- 4pytorch使用 基础解惑
- 5渗透测试之sql注入验证安全与攻击性能
- 6使用Automake、autoconf、Libtool自动生成Makefile_automake生成动态库
- 7读书笔记 -公司改造 和 紧迫感_公司改造三枝匡
- 8用IDEA构建一个简单的Java程序范例_idea简单代码
- 9图解如何使用cmake 完整交叉编译Qt项目_cmake编译qt源码
- 10java -jar no access_java的包运行时 出现Unable to access jarfile adbc.jar
hadoop面试题
赞
踩
0. 思维导图
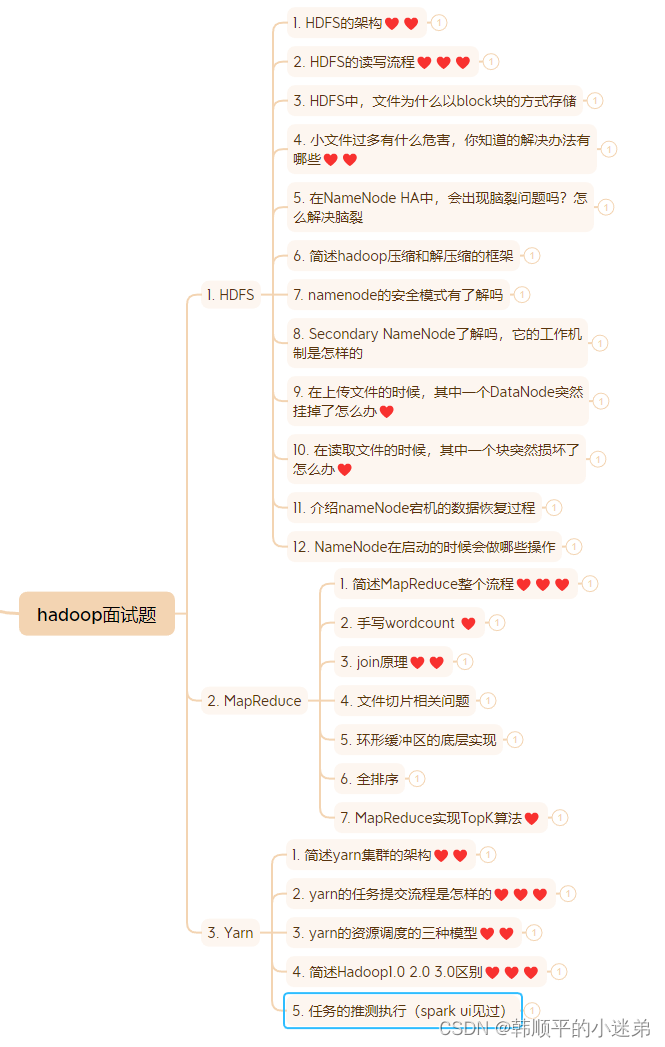
1. HDFS
1. HDFS的架构♥♥
HDFS主要包括三个部分,namenode,datanode以及secondary namenode。这里主要讲一下他们的作用:namenode主要负责存储数据的元数据信息,不存储实际的数据块,而datanode就是存储实际的数据块,secondary namenode主要是定期合并FsImage和edits文件(这里可以进行扩展,讲一下为什么有他们的存在?首先namenode存储的元数据信息是会放在内存中,因为会经常进行读写操作,放在磁盘的话效率太低了,那么这时候就会有一个问题,如果断电了,元数据信息不就丢失了吗?所有也需要将元数据信息存在磁盘上,因此就有了用来备份元数据信息的FsImage文件,那么是不是每次更新元数据信息,都需要操作FsImage文件呢?当然不是,这样效率不就又低了吗,所以我们就引入了edits文件,用来存储对元数据的所有更新操作,并且是顺序写的方式,效率也不会太低,这样,一旦重启namenode,那么首先就会进行FsImage文件和edits文件的合并,形成最新的元数据信息。这里还会有一个问题,但是如果一直向edits文件进行写入数据,这个文件就会变得很大,那么重启的时候恢复元数据就会很卡,所有这里就有了secondary namenode在namenode启动的时候定期来进行FsImage和edits文件的合并,这样在重启的时候就会很快完成元数据的合并)
2. HDFS的读写流程♥♥♥
-
读数据流程:hadoop fs -get a.txt /opt/module/hadoop/data/
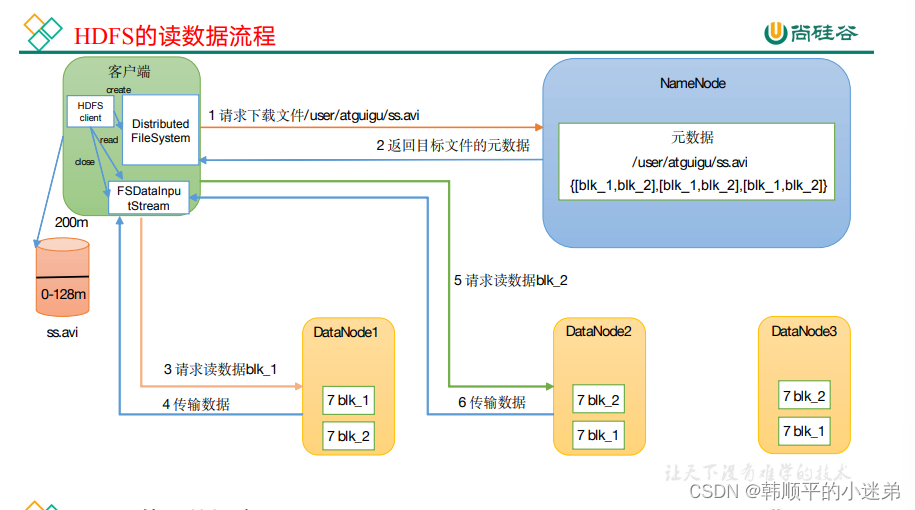
首先客户端向namenode进行请求,然后namenode会检查文件是否存在,如果存在,就会返回该文件所在的datanode地址,这些返回的datanode地址会按照集群拓扑结构得出datanode与客户端的距离,然后进行排序;然后客户端会选择排序靠前的datanode来读取block,客户端会以packet为单位进行接收,先在本地进行缓存,然后写入目标文件中。【读的时候是并行读取的数据块】 -
写数据流程: hadoop fs -put a.txt /user/sl/
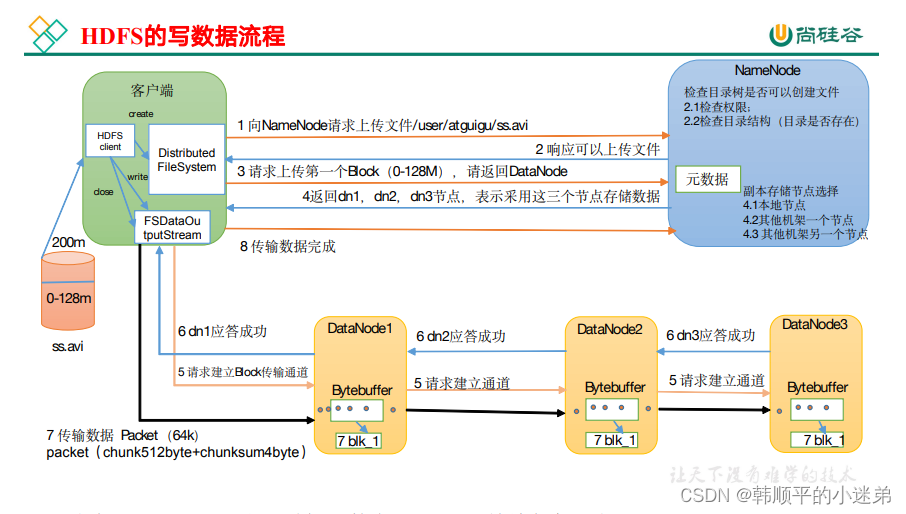
- 首先客户端会向namenode进行请求,然后namenode会检查该文件是否已经存在,如果不存在,就会允许客户端上传文件;
- 客户端再次向namenode请求第一个block上传到哪几个datanode节点上,假设namenode返回了三个datanode节点;
- 那么客户端就会向datanode1请求上传数据,然后datanode1会继续调用datanode2,datanode2会继续调用datanode3,那么这个通信管道就建立起来了,紧接着datanode3,datanode2,datanode1,逐级应答客户端。
- 然后客户端就会向datanode1上传第一个block,以packet为单位(默认64K),datanode1收到后就会传给datanode2,datanode2传给datanode3
- 当第一个block传输完成之后,客户端再次请求namenode上传第二个block。【写的时候,是串行的写入数据块】
3. HDFS中,文件为什么以block块的方式存储
- 只要是减少硬盘寻道时间
- 不设置block;因为数据是分散存放磁盘上的,读取数据时需要不停的进行磁盘寻道,开销比较大。
- 使用block;一次可以读取一个block中的数据,减少磁盘寻道的次数和时间。
4. 小文件过多有什么危害,你知道的解决办法有哪些♥♥
- 危害:
- 存储大量的小文件,会占用namenode大量的内存来存储元数据信息
- 在计算的时候,每个小文件需要一个maptask进行处理,浪费资源
- 读取的时候,寻址时间超过读取时间
- 解决方法:
- 在上传到hdfs之前,对小文件进行合并之后再上传
- 采用har归档的方式对小文件进行存储,这样能够将多个小文件打包为一个har文件
- 在计算的时候,采用combineinputformat的切片方式,这样就可以将多个小文件放到一个切片中进行计算
- 开启uber模式,实现JVM的重用,也就是说让多个task公用一个jvm,这样就不必为每一个task开启一个JVM
5. 在NameNode HA中,会出现脑裂问题吗?怎么解决脑裂
-
假设NameNode1当前为Active状态,NameNode2当前为Standby状态。如果某一时刻NameNode1对应的ZKFailoverController进程发生了“假死”现象,那么Zookeeper服务端会认为NameNode1挂掉了,NameNode2会替代NameNode1进入Active状态。但是此时NameNode1可能仍然处于Active状态正常运行,这样NameNode1和NameNode2都处于Active状态,都可以对外提供服务。这种情况称为脑裂
-
Zookeeper对这种问题的解决方法叫做fencing(隔离),也就是想办法把旧的Active NameNode隔离起来,使它不能正常对外提供服务
- 首先尝试调用这个旧Active NameNode的HAServiceProtocol RPC接口的transitionToStandby 方法,看能不能把它转换为Standby状态
- 如果transitionToStandby 方法调用失败,那么就执行Hadoop配置文件之中预定义的隔离措施,Hadoop目前主要提供两种隔离措施,通常会选择sshfence;
- sshfence:通过SSH登录到目标机器上,执行命令fuser将对应的进程杀死
- shellfence:执行一个用户自定义的shell脚本来将对应的进程隔离
6. 简述hadoop压缩和解压缩的框架
- gzip压缩:压缩率比较高,而且压缩/解压速度也比较快,hadoop本身支持,但是不支持切片
- bzip2压缩:比gzip的压缩率更高,hadoop本身支持,而且还支持切片,但是压缩/解压缩速度很慢
- lzo压缩:合理的压缩率,压缩/解压速度也比较快,而且支持切片,但是hadoop本身不支持,需要安装,压缩率要比gzip低一些,为了支持切片,还需要手动为lzo压缩文件创建索引
- snappy压缩:合理的压缩率,压缩/解压速度也比较快,但是不支持切片,badoop本身不支持,需要安装,压缩率要比gzip低一些
7. namenode的安全模式有了解吗
-
安全模式是指hdfs对于客户端来说是只读的
-
什么时候进入安全模式?
- namenode启动的时候,首先会进行fsimage和edits的合并,然后namenode监听datanode,datanode汇报最新的数据块信息,这个过程namenode就会处于安全模式
-
什么时候会退出安全模式?
- 如果整个文件系统中99.9%的数据块满足最小的副本级别(默认为1),namenode会在30秒之后退出安全模式。刚初始化HDFS的时候,因为系统中没有任何块,所以namenode不会进入安全模式。
-
命令:bin/hdfs dfsadmin -safemode get/enter/leave/wait
8. Secondary NameNode了解吗,它的工作机制是怎样的
- Secondary Namenode主要是用于edit logs 和 FsImage的合并,edit logs记录了对namenode元数据的增删改操作,FsImage记录了最新的元数据检查点,在namenode重启的时候,会把edit logs和Fsimages进行合并,形成新的FsImage文件
- 工作机制:
- Secondary NameNode 询问NameNode是否需要checkpoint。直接带回NameNode是否需要检查结果
- Secondary NameNode 请求执行checkpoint
- NameNode滚动正在写的edits日志
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
- Secondary NameNode 加载编辑日志和镜像文件到内存,并合并
- 生成新的镜像文件fsimage.checkpoint
- 拷贝fsimage.checkpoint到NameNode
- NameNode将fsimage.checkpoint重新命名为fsimage
所以如果NameNode中的元数据丢失,是可以从Secondary NameNode恢复一部分元数据信息的,但不是全部,因为NameNode正在写的edits日志还没有拷贝到Secondary NameNode,这部分恢复不了
9. 在上传文件的时候,其中一个DataNode突然挂掉了怎么办♥
客户端上传文件时与DataNode建立pipeline管道,管道正向是客户端向DataNode发送的数据包,管道反向是DataNode向客户端发送ack确认,也就是正确接收到数据包之后发送一个已确认收到的应答,当DataNode突然挂掉了,客户端接收不到这个DataNode发送的ack确认,客户端会通知NameNode,NameNode检查该块的副本与规定的不符,NameNode会通知DataNode去复制副本,并将挂掉的DataNode作下线处理,不再让它参与文件上传与下载。
10. 在读取文件的时候,其中一个块突然损坏了怎么办♥
客户端读取完DataNode上的块之后会进行checksum验证,也就是把客户端读取到本地的块与HDFS上的原始块进行校验,如果发现校验结果不一致,客户端会通知NameNode,然后再从下一个拥有该block副本的DataNode继续读。
11. 介绍nameNode宕机的数据恢复过程
当NameNode发生故障宕机时,Secondary NameNode会保存所有的元数据信息,在NameNode重启的时候,Secondary NameNode 会将元数据信息发送给NameNode
12. NameNode在启动的时候会做哪些操作
- 读取fsimage和edits文件,然后通知Secondary NameNode进行合并生成新的fsimage文件,然后创建新的空的edits文件
- 首次启动NameNode
- 格式化文件系统,为了生成fsimage镜像文件
- 启动NameNode
- 读取fsimage文件,将文件内容加载进内存
- 等待DataNode注册于发送block report
- 启动DataNode
- 向NameNode注册
- 发送block report(每3S发送一次心跳包:本节点的存储容量信息,块信息)
- 检查fsimage中记录的块的数量和block report中块的总数是否相同
- 对文件系统进行操作(创建目录,上传文件,删除文件等)
- 此时内存中已经有文件系统改变的信息,但是磁盘中没有文件系统改变的信息,此时会将这些改变信息写入edits文件中,edits文件中存储的时文件系统元数据改变的信息。
- 第二次启动NameNode
- 读取fsimage和edits文件
- 将fsimage和edits文件合并新的fsimage文件
- 创建新的edits文件,内容为空
- 启动DataNode
- 首次启动NameNode
2. MapReduce
1. 简述MapReduce整个流程♥♥♥
1. map阶段:首先通过InputFormat把输入目录下的文件进行逻辑切片,默认大小等于block大小,并且每一个切片由一个maptask来处理,同时将切片中的数据解析成<key, value>的键值对,k表示偏移量,v表示一行内容;紧接着调用Mapper类中的map方法。将每一行内容进行处理,解析为<k,v>的键值对,在wordCount案例中,k表示单词,v表示数字1;
2. shuffle阶段:map端shuffle:将map后的<k,v>写入环形缓冲区【默认100m】,一半写元数据信息(key的起始位置,value的起始位置,value的长度,partition号),一半写<k,v>数据,等到达80%的时候,就要进行溢写操作,溢写之前需要对key按照分区进行快速排序【分区默认算法是HashPartitioner,分区号是根据key的hashcode对reduce task个数取模得到的。这时候有一个优化方法可选,combiner合并,就是预聚合的操作,将有相同key的Value合并起来,减少溢写到磁盘的数据量,只能用来累加,最大值使用,不能在平均值的时候使用】;然后溢写到文件中,并且进行merge归并排序(多个溢写文件);reduce端shuffle:reduce会拉取copy同一分区的各个maptask的结果到内存中,如果放不下,就会溢写到磁盘上;然后对内存和粗盘上的数据进行merge归并排序(这样就可以满足将key相同的数据聚合在一起)。
3. reduce阶段:key相同的数据会调用一次reduce方法,每次调用会产生一个键值对,最后将这些键值对写入到HDFS文件中。
2. 手写wordcount ♥



3. join原理♥♥
- Reduce端join:
- map阶段的主要工作:对来自不同表的数据打标签,然后用连接字段作为key,其余部分和标签作为value,最后进行输出
- shuffle阶段:根据key的值进行hash,这样就可以将相同的key送入一个reduce中
- reduce阶段的主要工作:同一个key的数据会调用一次reduce方法,就是对来自不同表的数据进行join(笛卡尔积)
- Map端join:
- 原理:将小表复制多份,让每个map task内存中存在一份(比如存放到HashMap中),然后只扫描大表,对于大表中的每一条记录key/value,在HashMap中查找是否有相同key的记录,如果有,则join连接后输出即可。
- 应用场景:一张表很小,一张表很大
- 优点:增加Map端业务,减少Reduce端数据的压力,尽可能减少数据倾斜
- 具体方法:
- 使用DistributedCache缓存文件到Task运行节点
- 在mapper的setup方法中,将文件读取到缓存集合中
4. 文件切片相关问题
-
区分数据切片和数据块:
- 数据切片:只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储
- 数据块:默认是128M,hdfs物理上把数据分成一块一块。
-
MapTast并行度决定机制:
- 一个job的map阶段并行度由客户端在提交job时的
切片数决定 - 每一个切片分配一个MapTask进行处理
- 默认情况下,
切片大小=blocksize - 切片时不考虑数据集整体,而是逐个针对
每一个文件单独切片
- 一个job的map阶段并行度由客户端在提交job时的
5. 环形缓冲区的底层实现
- 环形缓冲区底层就是一个数组,默认大小是100M
- 数组中存放着Key和value的数据,以及关于key和value的元数据信息。每个key,value对应一个元数据,元数据由4个int组成,第一个int存放value的起始位置,第二个int存放key的起始位置,第三个int存放partition,第四个int存放value的长度。
- key/value数据和元数据在环形缓冲区中的存储是由equator(赤道)分隔的,key/value按照索引递增的方向存储,元数据则按照索引递减的方向存储。将数组抽象为一个环形结构之后,以equator为界,key/value顺时针存储,元数据逆时针存储。
6. 全排序
补充知识:MapTask和ReduceTask都会对数据按照key进行排序。该操作属于hadoop的默认行为。(字典顺序,快速排序)
区内排序:
- 在全排序的基础上自定义分区(继承Partitioner类,重写getPartition方法)
- job驱动中设置自定义分区类,并且设置ReduceTask个数
-
定义:最终输出结果只有一个文件,且文件内部有序,实现方式是
只设置一个ReduceTask【慎用】 -
关键步骤:
- 新建一个javabean类,用来存储输入的数据
- bean对象作为key传输,实现WritableComparable接口,重写compareTo方法,序列化和放序列化方法。
-
补充题:辅助排序(二次排序)
- 二次排序:有两个字段参与排序
- 跟一次排序实现的步骤一样,就在于逻辑上的不同,多以一个if…else…就可以了
- 辅助排序:ReduceTast对从map端拉取过来数据再次进行分组排序
- 自定义类继承WritableComparator,重写compare方法
- job驱动中设置reduce端的自定义分组类
- 二次排序:有两个字段参与排序
7. MapReduce实现TopK算法♥
- 自定义排序比较器(这里可以讲一下步骤),全局排序就行了
- 优化手段:在map阶段加上TreeMap集合,当集合大小超过K时,删除最小的元素,然后在cleanup方法中发送topk的元素;同时在reduce阶段也是一样的,因为会有不同的maptaks发送topk过来,我们还需要再次去找topK。
3. Yarn
1. 简述yarn集群的架构♥♥
- Yarn的基本思想就是将Hadoop1.0中的jobTraacker拆分了两个独立的服务:
ResourceManager和ApplicationMaster。 - ResourceManager负责整个系统的资源管理和分配,ApplicationMaster负责当个应用程序的管理。除了这两个部分之外,还包括NodeManager和Container,其中NodeManager是单个节点上的资源和任务管理器,Container是Yarn的资源抽象,封装了各种资源,比如内存CPU磁盘。
2. yarn的任务提交流程是怎样的♥♥♥

3. yarn的资源调度的三种模型♥♥

4. 简述Hadoop1.0 2.0 3.0区别♥♥♥
-
hadoop1.0 和 hadoop2.0的区别:
- 新增了YARN框架,1.0的时候,MapReduce既负责资源调度又负责计算,到了2.0,资源调度就交给了yarn框架:
- 新增HDFS高可用机制,通过配置Active和Standby两个NameNode实现在集群中对NameNode的热备,解决了1.0存在的单点故障问题
-
hadoop2.0和hadoop3.0的区别:
- hadoop3.0要求最低的java版本为jdk1.8;
- hadoop3.0的MapReduce进行了优化,性能提高了30%;
- hadoop3.0支持两个以上的namenode,也就是可以设置一个active和多个standby
- hadoop3.0支持hdfs的纠删码机制,作用就是节省存储空间。
5. 任务的推测执行(spark ui见过)


